
عزيزي القارئ هذه هي المقالة الثانية في سلسلتنا المكونّة من ثلاث مقالات والتي سنتعلم من خلالها كيفية استخدام النماذج المدرّبة مُسبقاً. بداية لتوضيح الفكرة من هذه المقالة، دعنا نفترض أننا نريد صُنع رجل آلي منزلي household robot يمكنه طهي الطّعام. إن أول خطوة يجب على رجُلنا الآلي القيام بها هي تحديد الخضراوات المختلفة اللازمة. من أجل تحقيق ذلك، سنحاول بناء نموذج يستطيع التعرّف على البندورة و الجبس و اليقطين. ربما تتساءل عزيزي القارئ عن سبب اختيارنا لهذه الخضراوات بالذات، السبب في ذلك، أننا قد رأينا في المقالة السابقة [4] أن النماذج المدرّبة مسبقاً لم تستطع التعرّف على هذه الأصناف الثلاثة (لم تكن موجودة في قاعدة بيانات تحدّي إيمج-نت للتعرُّف البصري واسع النطاق للرؤية الحاسوبية Imagenet Large Scale Visual Recognition Challenge ILSVRC) لأنه لم يتم تدريب تلك النماذج للتعرّف عليها.
المحتويات
لقد تعلّمنا في المقالة السابقة كيفية استخدام النماذج المدرّبة مسبقاً من أجل تنفيذ مهمة تصنيف الصور على بيانات ILSVRC. واليوم في هذه المقالة، سوف نتعلّم كيف يمكننا استخدام هذه النماذج كمُستخرج مزايا Feature Extractor و تدريب نموذج جديد من أجل تنفيذ مهمة تصنيف مختلفة.
نقل التعلّم Transfer Learning ضد الضبط الدقيق Fine-tuning
يتم تدريب النماذج المُدرّبة مسبقاً على نطاق واسع جداً من مسائل تصنيف الصور. تعمل طبقات الطّي كمستخرج للمزايا بينما تعمل الطبقات كاملة الاتصال كمصنّفات كما هو واضح في الشكل (1).
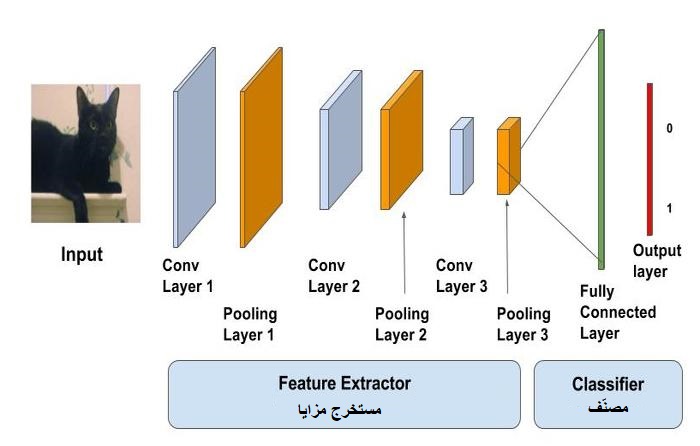
تميل هذه النماذج لتعلّم مزايا تمييزيّة فاصلة جيدة للغاية لأنه تم تدريبها على عدد كبير من الصور. يمكننا إمّا إستخدام طبقات الطّي كمستخرج للمزايا أو تعديل طبقات الطّي المدرّبة مسبقاً لتلائم مسألتنا. يُعرّف النهج الأول بنقل التعلّم والأخير بالضبط الدقيق.
كقاعدة عامّة متعارف عليها، عندما يكون لدينا مجموعة بيانات تدريب صغيرة والمسألة المُراد حلّها مشابهة للمهمة التي تمّ تدريب النماذج المدرّبة مسبقاّ بالأساس عليها، يمكننا عندئذ استخدام نهج نقل التعلُّم. بينما إذا كانت لدينا بيانات كافية، فعندها يمكننا أن نحاول تعديل طبقات الطّي بحيث تتعلّم المزيد من المزايا القويّة المتعلّقة بالمسألة المُراد حلّها. يمكنك عزيزي القارئ الحصول على المزيد من التفاصيل حول الضبط الدقيق ونقل التعلّم من [5]. سنناقش في هذه المقالة نقل التعلّم في كيراس keras.
قاعدة بيانات إيمج-نت ImageNet
تعتمد قاعدة بيانات إيمج-نت على قاعدة البيانات المُعجميّة وورد-نت WordNet التي تُجمّع الكلمات في مجموعات من المرادفات (synsets). يتم تعيين مُعرّف لكل مجموعة مرادفات. تجدر الإشارة إلى أنه يمكن أن تضم الفئات العامّة العديد من الفئات الفرعيّة وكل منها ينتمي إلى مجموعة مرادفات مختلفة. كمثال عن ذلك:
يعتبر الكلب العامل (مجموعة مرادفات رقم =n02103406) والكلب المُرشد (مجموعة مرادفات رقم =n02109150) و الكلب الشرطي (مجموعة مرادفات رقم =n02106854) ثلاث مجموعات مختلفة.
فيما يلي مُعرّف وورد-نت “wnid” للأصناف الثلاثة التي نهتم بها في هذه المقالة:
- n07734017 -> بندورة
- n07735510 -> يقطين
- n07756951 -> جبس
تحميل وإعداد البيانات
من أجل تنزيل صور من إيمج-نت بواسطة wind، يمكنك عزيزي القارئ زيارة مستودع الشيفرة البرمجية التالي المتاح على جيت هب github. يمكنك زيارة صفحة جيت هب واتباع التعليمات لتنزيل الصور باستخدام مُعرّفات وورد-نت محدّدة. ولكن هذه الطريقة لن تعمل معك إلا إذا كان لديك حساب مُفعّل على موقع قاعدة البيانات الرسمي.
في حال أنك لا تملك حساب أو تريد طريقة سهلة وسريعة لتنزيل الصور، يمكنك استخدام مكتبة بايثون التالية المتاحة على جيت هب. هذه المكتبة سهلة الاستخدام وتؤمّن عدة خيارات، يمكنك من خلالها تنزيل الصور مباشرة من محرك البحث بينغ Bing الخاص بشركة مايكروسوفت.
يمكن ملاحظة أن الصور التي قمنا بتنزيلها تحتوي على ضجيج وغير مرتبة (تحتوي على العديد من الصور غير المناسبة وغير المرغوبة). لذلك يمكنك عزيزي القارئ اختيار حوالي 250 صورة جيدة لكل صنف. سنقوم بقسم البيانات إلى قسمين هما “التدريب” و”التحقّق” و سنقوم باستخدام كيراس لتنزيل الصور على دفعات.
تحميل النموذج المدرّب مسبقاً
from keras.applications import VGG16
vgg_conv = VGG16(weights='imagenet’,
include_top=False,
input_shape=(224, 224, 3))
في الشيفرة البرمجية أعلاه قمنا بتحميل نموذج مجموعة الهندسة المرئية VGG مع تهيئته بأوزان إيمج-نت بشكل مشابه لما قمنا به في مقالتنا السابقة. لكن مع ذلك فإنّ هناك تغييراً واحداً هذه المرة و هو عدم تحميل آخر طبقتين كاملتي الاتصال التي تعمل كمصنّفات، و لكن قمنا بتحميل طبقات الطّي فقط. تم ذلك من خلال إسناد القيمة False للمُعامل include_top.
include_top=False
تجدر الإشارة هنا إلى أنّ أبعاد الطبقة الأخيرة 7x7x512.
استخراج المزايا
تم تقسيم البيانات وحفظها في مجلدين منفصلين بنسبة 80:20 (%80 بيانات تدريب و %20 بيانات تحقّق)، يحتوي كل مجلد منها على ثلاثة مجلدات فرعية (واحد لكل صنف).
train_dir = './clean-dataset/train'
validation_dir = './clean-dataset/validation'
nTrain = 600
nVal = 150
سنستخدم الصنف ImageDataGenerator من مكتبة كيراس من أجل تحميل الصور و الدالة flow-from-directory من مكتبة كيراس أيضاً لتوليد دفعات من الصور مع عناوينها.
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
train_features = np.zeros(shape=(nTrain, 7, 7, 512))
train_labels = np.zeros(shape=(nTrain,3))
train_generator = datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=shuffle)
بعد ذلك سنستخدم الدالة model.predict() من أجل تمرير الصورة أمامياً عبر شبكة VGG، و هذا سيعطينا مصفوفة متعددة الأبعاد Tensor لها البعد التالي 7x7x512. ثم نقوم بإعادة تشكيل المصفوفة المتعددة الأبعاد إلى شعاع، يمثل هذا الشعاع مزايا بيانات التدريب. نقوم بتطبيق نفس الخطوات على بيانات التحقّق من أجل الحصول على مزايا التحقّق.
i = 0
for inputs_batch, labels_batch in train_generator:
features_batch = vgg_conv.predict(inputs_batch)
train_features[i * batch_size : (i + 1) * batch_size] = features_batch
train_labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= nImages:
break
train_features = np.reshape(train_features, (nTrain, 7 * 7 * 512))
إنشاء النموذج الخاص بك Create the Model
سنقوم بإنشاء شبكة تغذية أمامية مع طبقة خرج سوفت ماكس softmax لها ثلاثة أصناف. سنستخدم مكتبة كيراس لبناء شبكتنا. في البداية قمنا باستيراد النماذج، الطبقات، و المُحسّنات المتوفرة في مكتبة كيراس. تم إنشاء نموذج تسلسلي عن طريق استخدام طبقة كاملة الاتصال ذات 256 عصبون وتابع تفعيل “وحدة التصحيح الخطي” (Relu) و بأبعاد دخل 7x7x512، تليها طبقة تعطيل عمل العصبونات Dropout ذات احتمالية تعطيل 50%، وأخيراً طبقة كاملة الاتصال بثلاثة عصبونات وتابع تفعيل سوفت ماكس. الشيفرة البرمجية التالية توضّح طريقة إنشاء نموذجنا.
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=7 * 7 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(3, activation='softmax'))
تدريب النموذج Train the Model
يتم تدريب الشبكة العصبونية في كيراس عن طريق استدعاء الدالة model.fit() كما رأينا في مقالتنا السابقة. في البداية نقوم بترجمة النموذج حيث تم استخدام مُحسّن أر ام اس بروب RMSprop و تابع خسارة “الانتروبيا المتقاطعة الفئويّة” categorical_crossentropy. بعد ذلك نقوم بتدريب النموذج باستخدام الدالة fit() التي تقبل بيانات التدريب والتحقّق، عدد دورات التدريب، و حجم الدفعة.
model.compile(optimizer=optimizers.RMSprop(lr=2e-4),
loss='categorical_crossentropy',
metrics=['acc'])
history = model.fit(train_features,
train_labels,
epochs=20,
batch_size=batch_size,
validation_data=(validation_features, validation_labels))
يبين الشكل (3) نتائج تدريب النموذج بعد 20 دورة تدريب.

اختبار الأداء Check the Performance
نقوم في هذه المرحلة بالتنبُّؤ بأصناف صور بيانات التحقّق عن طريق استدعاء الدّالة model.predict_classes أو model.predict وتمرير بيانات التحقّق كمُعامل دخل. حيث تعطينا الدّالة predict_classes الصنف المتنبّأ به لصورة الدخل مثلا (بندورة، يقطين) بينما تعطينا الدّالة predict قيمة احتمالية للأصناف المُتنبّأ بها مثلا (بندورة 0.7 ويقطين 0.3). من أجل معرفة الصور التي تمّ تصنيفها بشكل خاطئ، يتم مقارنة الأصناف المُتنبأ بها مع الحقائق المرجعية Ground-Truth (الأصناف الفعليّة لصور التحقّق). الشيفرة البرمجية التالية تُمكننا من معرفة الصور التي تمّ تصنيفها بشكل خاطئ.
fnames = validation_generator.filenames
ground_truth = validation_generator.classes
label2index = validation_generator.class_indices
# Getting the mapping from class index to class label
idx2label = dict((v,k) for k,v in label2index.iteritems())
predictions = model.predict_classes(validation_features)
prob = model.predict(validation_features)
errors = np.where(predictions != ground_truth)[0]
print("No of errors = {}/{}".format(len(errors),nVal))
بعد تنفيذ الشيفرة البرمجية السابقة سنحصل على عدد الصور التي تم تصنيفها بشكل خاطئ. بحالتنا حصلنا على 14/150 أي أن نسبة الخطأ 9% تقريباً.
عن طريق تنفيذ الشيفرة البرمجية التالية ستتمكن عزيزي القارئ من رؤية الصور التي تم تصنيفها بشكل خاطئ كما هو واضح في الشكل (4).
for i in range(len(errors)):
pred_class = np.argmax(prob[errors[i]])
pred_label = idx2label[pred_class]
print('Original label:{}, Prediction :{}, confidence : {:.3f}'.format(
fnames[errors[i]].split('/')[0],
pred_label,
prob[errors[i]][pred_class]))
original=load_img('{}/{}'.format(validation_dir,fnames[errors[i]]))
plt.imshow(original)
plt.show()
يمكنك عزيزي القارئ الاطلاع على الشيفرة البرمجية التي قمنا بشرحها في هذه المقال عن طريق زيارة مستودع الجيت هب الخاص بمنصة الذكاء الاصطناعي باللغة العربية.
سنحاول في مقالتنا القادمة تحسين محدوديّة نقل التعلّم عن طريق استخدام منهج أخر يُدعى الضبط الدقيق.





تعليق واحد