
المحتويات
غالباً ما يتطلّب التعلّم العميق الكثير من الوقت وموارد قويّة للحواسيب للقيام بعمليّة التدريب، وهو أيضاً سببٌ رئيسي يعيق تطوير خوارزميّات التعلّم العميق، فعلى الرغم من مقدرتنا على استخدام التدريب الموزّع على عدة حواسيب لتسريع التعلّم النموذجي، إلّا أنَّه لم يتم تقليل موارد الحوسبة المطلوبة على الإطلاق لذا تمّ خوارزميّات تحسين.
تتطلّب خوارزميّات التّحسين موارد أقل وتجعل النموذج يتقارب بشكل أسرع ويمكنها التّأثير على التعلّم الآلي بشكل أساسي وذلك من خلال ضبط مُعاملات التعلّم بالشّكل الأمثلي لتسريع عمليّة التعلّم واستهلاك موارد أقل.
ولهذا ولدت خوارزميّة آدم
خوارزميّة التحسين آدم هي امتداد لخوارزميّة انحدار المُشتقّ العشوائيّ (SGD=Stochastic Gradien Descent)، وتستخدم مؤخراً على نطاق واسع في تطبيقات التعلّم العميق وخاصّةً الرؤية الحاسوبيِّة ومهام معالجة اللّغة الطبيعيّة.
سنتحدث في هذه المقالة عن المحاور التالية:
●خوارزميّة آدم Adam ومزاياها.
●مبدأ وآلية عمل خوارزميّة آدم, واختلافها عن خوارزميّتي “آدا جراد AdaGrad و آر إم إس بروب RMSProp“.
●كفاءة خوارزميّة آدم.
●ضبط مُعاملات التهيئة لخوارزميّة آدم.
خوارزميّة التحسين آدم
تمَّ اقتراح خوارزمية آدم في الأصل من قِبَل الباحث ديدريك كينغ من أوبن آي آيي, و جيمي با من جامعة تورونتو في ورقة بعنوان:
(آدم: طريقة للتحسين العشوائي)[2]
وهي خوارزميّة تحسين من الدّرجة الأولى يمكن أن تحلَّ محل عمليّة انحدار المشتق العشوائي التقليدية SGD “حيث تقوم عملية انحدار المشتق العشوائيّ بالإنطلاق من نقطة عشوائيّة وتعمل على الانتقال بخطوات ثابتة للوصول إلى لحظة التّدرُّب ولكنّ ذلك يتطلّب عدداً كبيراً من التكرارات بسبب العشوائيّة”، ويمكنها تحديث أوزان الشبكة العصبونية بشكل متكرّر بناءاً على بيانات التدريب[1].
مزايا خوارزميّة التحسين آدم
- ذاكرة أقل.
- حسابات فعّالة.
- ثبات التدرّج من خلال عملية تصحيح mt و vt لجعل القيم متقاربة “تم ذِكر عمليّة التصحيح في تهيئة الخوارزميّة”.
- مناسبة لحل مشاكل التحسين مع البيانات والمُعاملات واسعة النطاق.
- مناسبة للأهداف الثابتة (أي بيانات التعلّم ثابتة ولا يتم تحديثها ضمن عمليّة التعلّم، مثلاً: عمليّة تصنيف الصور).
- مناسبة للمشاكل ذات الضوضاء العالية أو التدرجات المتفرّقة.
- تتطلّب القليل من الضبط للمُعاملات الأساسية.
الآليّة الأساسيّة لخوارزميّة التحسين آدم
تختلف خوارزميّة آدم عن انحدار المُشتقّ العشوائيّ SGD، حيث يُحافِظ الأخير على مُعامل تعلّم واحد (ألفا α) لتحديث جميع الأوزان، ولا يتغيّر معدّل التعلّم أثناء عمليّة التدريب.
وفي الجّهة المقابلة تقوم آدم بحساب معدّلات التعلّم التكيّفيّة المستقلّة للمعاملات المختلفة عن طريق حساب تقديرات اللحظة الأولى والثانية للتدرج “حسابات خاصّة لهذه الخوارزميّة”.
ولقد حصلت خوارزميّة آدم على مزايا خوارزميتي “آدا جراد AdaGrad و آر إم إس بروب RMSProp و مومنتوم Momentum” في نفس الوقت، كما يظهر في الشّكل(1):

حيث تتمثّل خوارزميّة التدرّج التكيّفي (AdaGrad=Adaptive Gradient) في ضبط المعاملات المناسبة لمعدّل التعلّم، لإجراء تحديثات كبيرة لمعاملات متفرّقة وتحديثات صغيرة للمعاملات المتكرّرة ففي كل خطوة زمنيّة t، تحدّد هذه الخوارزمية معدّلاً مختلفاً للتعلّم لكل معامل تيتا “θ” وتحديث المعاملات المقابلة ثم تقوم بإجراء التدريب وهي مناسبة لمعالجة البيانات المتفرّقة لكنّ المشكلة تكمن في بعض الحالات حيث أنّ معدّل التعلّم سينخفض بسبب تراكم التدرّجات من بداية التدريب وأنّ هنالك نقطة لن يتعلمها النموذج مرة أخرى لإنّ معدّل التعلّم يكاد أن يكون صفراً، عملت على حلها خوارزميّة آدم بجعل معدل التعلّم يتّجه نحو الإستقرار[4].
أما خوارزميّة (RMSProp=Root Mean Square Propagation) آر إم إس بروب (جذر متوسط مربع الإنتشار)، هي اشتقاق من خوارزميّة التدرّج التكيّفي “آدا جراد” فهي تعتمد على تقسيم معدّل التعلّم للوزن على المتوسّط الحالي لقيم التدرّجات الحديثة لهذا الوزن، وتحافظ على معدّل التعلّم لكل مُعاملة تعتمد في حسابها عليه (أي معدّل التعلّم الإجمالي فيها ثابت تقريباً)، لكنها تحسب التدرّج بمتوسّط الإنحدار بشكل أسّي بدلاً من مجموع تدرجاته، لذا تتكيّف وتلبي معدلات التعلّم المحدّدة المتغيّرة تلقائياً لمنع معدّل التعلّم الإجمالي للنموذج من الابتعاد عن الحافة والارتداد وهذا يعني أن الخوارزمية تتمتع بأداء ممتاز في المشكلات غير المستقرّة.
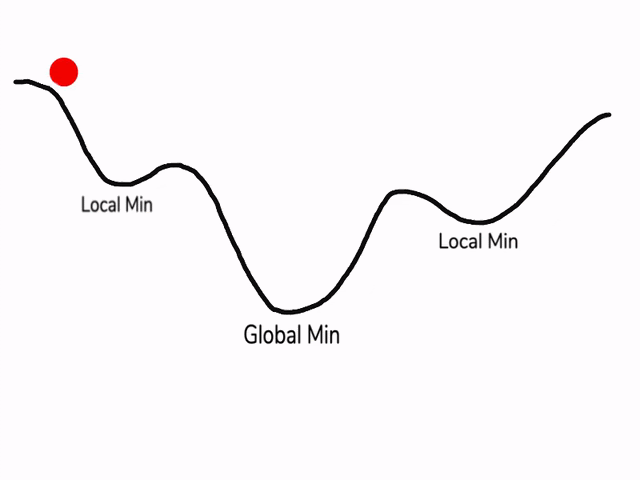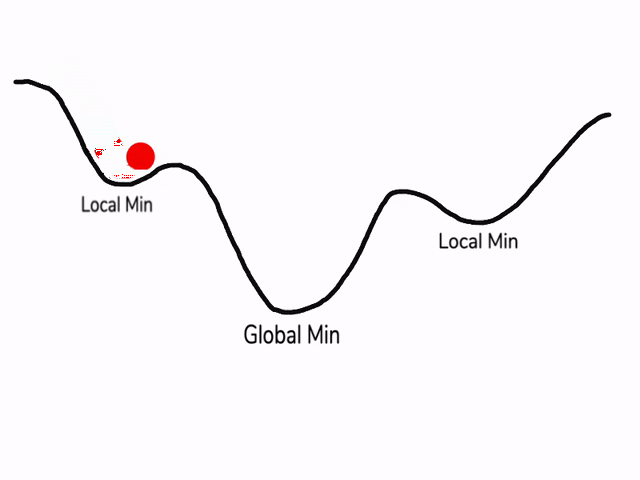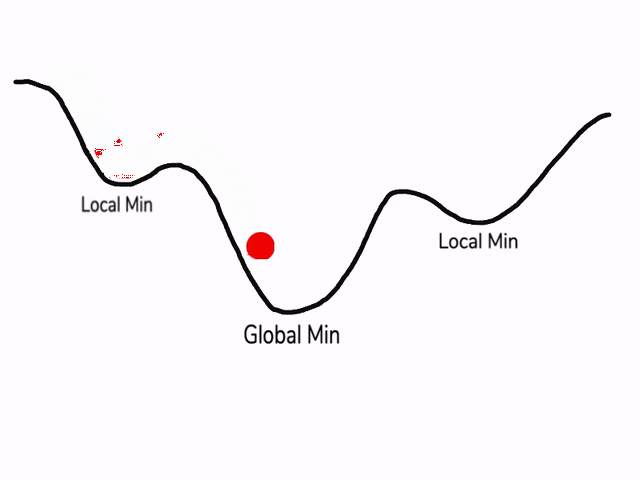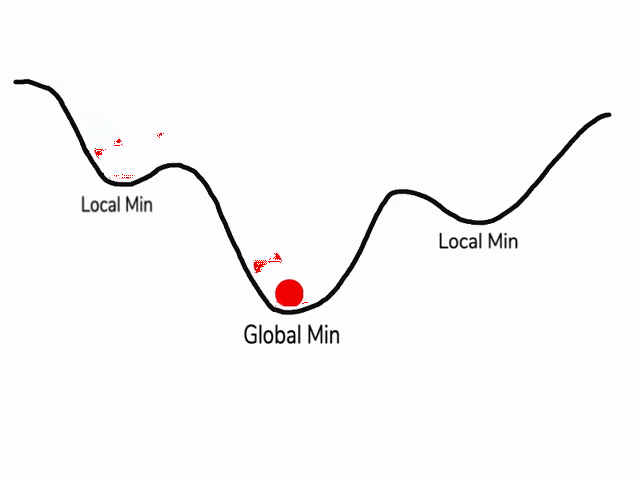
يظهر الشّكل(2) سرعة التعلّم في حال تطبيق خوارزميّة آر إم إس بروب:
*النقطة الصغرى المحليّة Local_Min هي القيمة الأصغر في المنحني ضمن مجال محدّد “جزء من المنحني” قبل أن يعود للازدياد وتعبّر عن تقارب ناتج التعلّم “تصغير نسبة الخطأ” ولكن لن يتوقف التدريب إلّا عند الوصول إلى النقطة الصغرى العامّة Global_Min وهي أصغر قيمة على طول المنحني “أصغر نسبة خطأ”، أما النقطة الحمراء المتحرّكة فهي تعبِّر عن مسار التدريب ونلاحظ تباطُؤَها وثباتها عند النقطة الصغرى العامّة*[4]

الشّكل(2): يظهر عمليّة تدريب النّموذج باستخدام “آر إم إس بروب” وثباته عند النقطة الصغرى العامّة[3]
علاوةً على ذلك، لا تقوم خوارزمية آدم فقط بحساب معدّل تعلّم المعاملة التكيّفيّة استناداً إلى متوسّط قيمة اللّحظة الأولى مثل خوارزميّة “آر إم إس بروب”، بل تستخدم أيضاً وبشكل كامل متوسط قيمة اللّحظة الثانية للتدرّج (أي التباين الغير مركّب).
على وجه التحديد، تحسب الخوارزميّة المتوسّط المتحرّك الأسّي للتدرّج “أي mt و vt بكل خطوة حيث تمّ تهيئتهما في الخطوة الأولى بصفر”، وتتحكّم المُعاملات بيتا1 ،بيتا2 (β1,β2) في تخفيض معدّل التعلّم لهذه المتوسّطات، وهو سريع الاستقرار.
كفاءة خوارزميّة آدم
في الورقة الأصليّة، أُثْبِتَ تجريبيّاً أن تقارب خوارزميّة آدم يتّسق مع التحليل النظري[٢].
يمكن تطبيق خوارزميّة آدم على مجموعات بيانات التعرّف على الحروف المكتوبة بخط اليد من “إم نيست MNIST” ومجموعة بيانات تحليل المشاعر من “آي إم دي بي IMDB” لتحسين خوارزميّات الانحدار اللّوجستي.
المخطّط في الشّكل(3) يظهر قيم معدّل التعلّم عند كل عدد لمجموعة من البيانات المُختبرة:

إنّ خوارزميّة “آدا جراد AdaGrad و آر إم إس بروب RMSProp و آدا ديلتا AdaDelta و آدم Adam” جميعها خوارزميّات تحسين متشابهة، وجميعها تعمل بشكلٍ جيد جدًا في حالات مماثلة.
نلاحظ في الشّكل(4) عند تطبيق خوارزميّة آدم أصبحت سرعة التعلّم أكبر مقارنةً مع خوارزميّة “آر إم إس بروب”.
ضبط المُعاملات
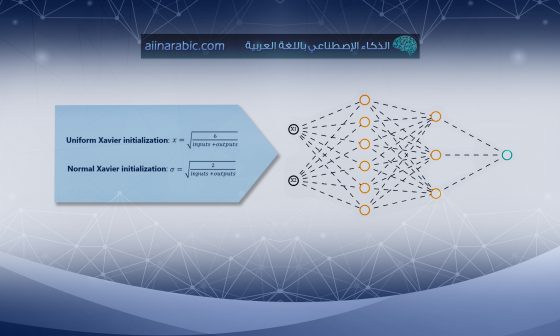
ألفا α: معدّل التعلّم أو معامل الخطوة، يتحكّم في معدّل تحديث الأوزان (على سبيل المثال يأخذ القيمة 0,001)، في حال القيم الأكبر مثل 0,3 سيكون التعلّم الأولي أسرع قبل تحديث معدّل التعلّم، في حين أن القيم الأصغر مثل 0,1E-5 ستجعل التدريب يتقارب إلى أداء أفضل ولكن بشكل أبطئ.
بيتا١ β1: معدّل التناقص الأسّي لتقدير اللّحظة الأولى.
بيتا٢ β2: معدّل التناقص الأسّي لتقدير اللّحظة الثانية.
إبسيلون ε: هو رقم صغير جداً لمنع القسمة على صفر.
يمكن أيضًا تطبيق تخفيض لمعدّل التعلّم على آدم، حيث تستخدم الورقة الأصلية معدّل التعلّم (α=α ∕ √t) “حيث t تعبّر عن دورة التدريب”.
أفضل قيم للمُعاملات الافتراضيّة المختبرة لمسائل التعلّم الآلي هي:
- 0.001=α
- β1=0.9
- β2=0.999
- ε=10E-8
وهنا يمكنكم الاطّلاع على بعض المكتبات التي تستخدم ذات القيم السابقة لتلك المعاملات:
تنسور فلو، كيراس، بلوكس، لازانيا، كافيه، إم إكس نت، بايتورش
خطوات تهيئة خوارزميّة آدم
تتم تهيئة خوارزميّة آدم وفق الخطوات التالية[3]:
- α: معدّل التعلّم (حجم الخطوة)
- [0,1]β1,β2 : معدّل الإنخفاض الأسّي لتقدير اللّحظة الأولى والثانية
- (F(θ: دالة موضوعيّة عشوائيّة مع المعامل θ
- θ0: تهيئة شعاع التوجيه
- m0⇐0: تهيئة شعاع لقيمة اللّحظة الأولى في الخطوة الإبتدائيّة
- v0⇐0: تهيئة شعاع لقيمة اللّحظة الثانية في الخطوة الإبتدائيّة
- t⇐0: تهيئة العدّاد
طالما t غير متقاربة يتم تكرار مايلي:

بعد تحديد المُعاملات ألفا (α) و بيتا1 (β1) و بيتا2 (β2) ودالة الهدف العشوائية (f(θ نحتاج إلى متّجه المعاملات ومتّجه اللّحظة من الدرجة الأولى ومتّجه اللّحظة من الدرجة الثانية والخطوة الزمنيّة، وعندما لا تتقارب المعاملات تيتا “θ” ،يتم تحديث كل جزء بشكل متكرّر في الحلقة.
يمكن تحسين كفاءة الخوارزميّة بتغيير ترتيب الحساب مثل استبدال الأسطر الثلاث الأخيرة بالسطرين التاليين:

الخُلاصة
تعد خوارزميّة آدم أحد أفضل خوارزميات التحسين للتعلّم العميق وتنمو شعبيتها بسرعة كبيرة.
وهي بديلة لخوارزميّة انحدار المُشتقّ العشوائيّ لتدريب نماذج التعلّم العميق، حيث تجمع بين أفضل خصائص خوارزميّات “آدا جراد و آر إم إس بروب” لتوفير خوارزميّة تحسين يمكنها التعامل مع التدرجات المتفرقة في مشكلات الضجيج فهي:
-
- سهلة التنفيذ.
- فعّالة.
- متطلباتها الذاكريّة قليلة.
- مناسبة لمشاكل التدرّجات المتفرّقة (مثل “آدا جراد”).
- مناسبة للأهداف غير الثّابتة (مثل “آر إم إس بروب”).
من السهل نسبياً تكوين محسّن آدم حيث تعمل معاملات التهيئة الافتراضيّة بشكل جيّد في معظم المشكلات.
ومازالت في تطوّر مستمر ….




4 تعليقات
مقال جميل، بالتوفيق يا رب
تسلم إستاذ محمد
وبالتوفيق بالدكتوراه يارب
مقال مفيد جدا جدا
بوركت جهودكم
اتمنا لكم التوفيق
شكراً على الجهود المبذولة..
معلومات قيمة..