المحتويات
مقدمة
في عام 2016 تمكّن الذَّكاءُ الاصطِناعيُّ المتمثل بالبرنامج ألفا-جو AlphaGo من التغلب على أفضل لاعب عالمي في العقد الأخير السيد لي سيدول في اللعبة الصينية المشهورة جو Go. كانت هذه اللحظة نقلة نوعيّة في نظرتنا للذكاء الصنعي. لم يستطع الإنسان التغلب على هذا البرنامج بعد ذلك، وقد قامت نيتفليكس بإنتاج فيلم بهذا الخصوص . نقف هنا لنتساءل عن التقنية التي سمحت للآلة بالتغلب على أمهر اللاعبين بشكل مستمر في هذه اللعبة التي تعد أكثر الألعاب التقليدية تعقيداً. وكيف استطاع الباحثون نمذجتها أو برمجتها للقيام بهذه العمليات المعقدة والتغلب على الإنسان في هذا المجال وفي مجالات أخرى. في الحقيقة يقف التعلم المعزّز Reinforcement learning وراء هذه القفزة. أمكننا هذا المجال من الذَّكاء الاصطِناعي من نمذجة وحل مشاكل مختلفة تماماً عن التي كانت تُحلّ باستخدام التعلم الآلي المتمثلة بالتعلم بالإشراف والتعلم بغير إشراف. لم تستطع الخوارزميات التي عمل عليها الباحثون لعقود قبل التعلم المعزّز إلّا على اللعب في مستوى المبتدئين في لعبة جو Go. هذا المقال سوف يكون حجر الأساس لبناء نظرة عامة عن هذا المجال ونقطة انطلاق لتعلم بعض المقاربات المهمة في التعلم المعزّز لكي تبدأ عزيزي القارئ بحل طيف جديد من المشاكل وكذلك ربط العديد من المواضيع المنتشرة حالياً في الذكاء الاصطناعي لفهمها بشكل أعمق [1].
أصول التعلم المعزّز عند الإنسان والحيوان
كلنا قد درس في المدرسة أو سمع عن تجربة بافلوف الشهيرة حول المنعكس الشرطي. تتلخص هذه التجربة بأن الكلب في الحالة الطبيعية يفرز اللعاب عند قدوم الطعام كما هو معروف. هدف هذه التجربة كان فيما إذا كان يمكن تنبيه إفراز اللعاب عند الكلب بوجود عوامل أخرى مثلاً عن طريق جرس أي بغير الطعام. قام العالم بافلوف برن الجرس كل مرة عند قدوم الطعام وذلك لعدة مرات. بعد ذلك قام برن الجرس بدون تقديم الطعام وكانت النتيجة أن هذا الكلب الذي لم يكترث لرنّ الجرس قبل إجراء التجربة على الإطلاق، بدأ بإفراز اللعاب وكأنّ الطعام أمامه. نقف هنا لنتسائل ماذا حدث؟ كان تفسير ذلك أن الكلب قام بربط عملية رن الجرس بقدوم الطعام بعد تكرار العملية لعدة مرات. يمكن الاستفادة من هذه التجربة في تدريب الكلاب أو الحيوانات الأخرى على القيام بأعمال معينة في السيرك مثلاً، حيث يتم ربط القيام بعملية معينة بنجاح بالحصول على مكافأة مثل الطعام. تُلاحظ عملية التعلم المعزّز أيضاً عند الإنسان و بشكل واضح عند الأطفال. أساس عملية التعلم عند الأطفال وفقا لنظرية التعلم السلوكي هي الوصول إلى هدف معين عن طريق المحاولة والخطأ وذلك بالمحاولة المستمرة والتفاعل مع البيئة. مثالاً على ذلك تعلم المشي الذي يتحقق بعد مئات المحاولات والأخطاء والتحسينات [8].
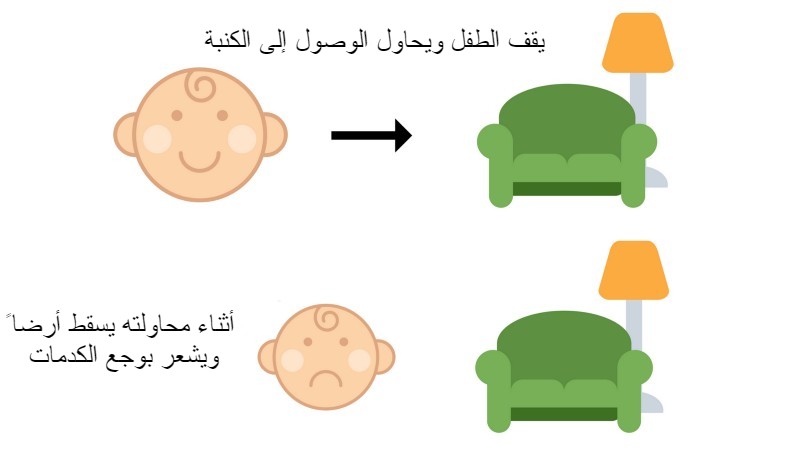
يحاول الطفل هنا الوقوف ويبدأ بالمشي للوصول إلى الكنبة. أثناء العملية يفشل في الوصول إلى حالة توازن مناسبة فتكون النتيجة السقوط على الأرض والشعور بالألم.

في هذه الحالة وبعد العديد من المحاولات وصل الطفل الى طريقة يستطيع فيها الوقوف والتوازن أثناء المشي. فتكون النتيجة وصوله الى الهدف بنجاح.
يجدر بالذكر هنا أنّ هذا المثال يمثل جوانب من إحدى النظريات الحاليّة للتعلّم. عملية التعلّم عند الإنسان هي عملية معقدة لم يُعرف حتى الآن كل جوانبها تستند إلى الكثير من العوامل وتتم على مستويات عدة لن نتطرق لها في هذا المقال. في الحقيقة كانت العديد من هذه الأفكار حول التعلم عند الإنسان أساس الإلهام في مجال التعلم المعزّز والتي تمت صياغتها بطرق رياضية مختلفة لتتم عملية حوسبتها. يُستخدم التعلم المعزّز لحل طيف جديد من المشاكل التي لا تستطيع الخوارزميات التقليدية للتعلم الآلي حلّها وخاصة تلك التي تحتاج لعميل يتفاعل مع بيئة محيطة به.
التعلم المعزّز في سياق التعلم الآلي
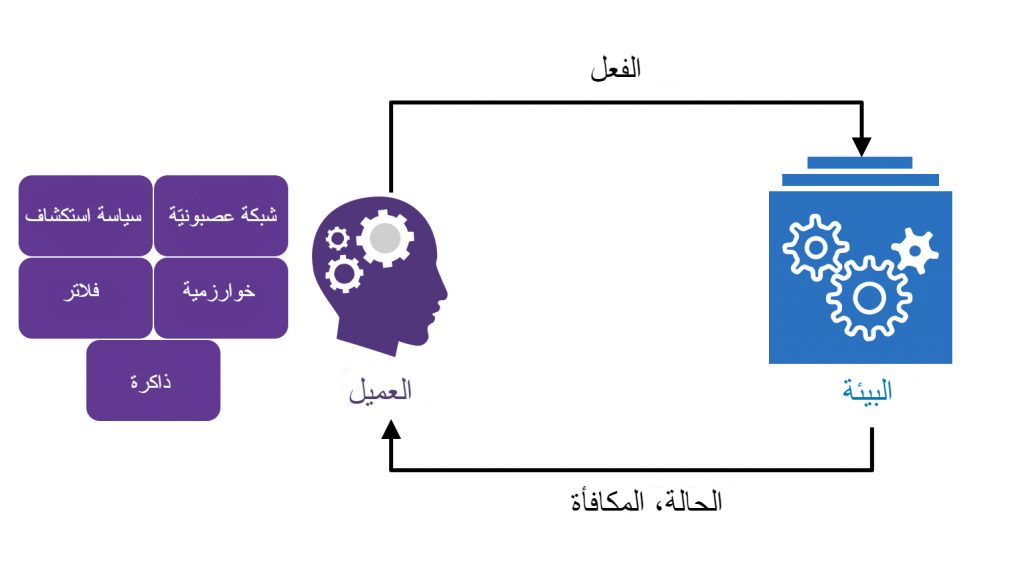
التعلم المعزّز هو أحد أهم مجالات التعلم الآلي حالياً، يتلخّص بأنّ العميل agent يتبادل التأثير مع بيئته المحيطة وعلى أساس تفاعله مع هذه البيئة يقوم بالتعلم بحيث يؤدي أخيراً الأفعال التي تعطيه المكافأة الأكبر. التفاعل مع البيئة يتم عندما يقوم العميل استناداً الى سياسة policy بفعل معين action وبالنتيجة يحصل على مكافأة reward والتحويل إلى حالة جديدة state. عملية التعلم المعزّز هي عملية تعلم تستند إلى التجربة لا إلى بيانات التدريب training data، أي أنّه يجب للعميل أن يقوم بمحاولات عديدة واستكشاف بيئته من أجل الحصول على مكافآت ثم تحديث السياسة تبعاً لذلك. لك الحق عزيزي القارئ بالحصول على صدمة الآن بسبب كثرة المصطلحات التي تبدو غريبة بعض الشيء والتي سوف نوضحها مباشرة في القسم التالي ثم نذكر بعض الأمثلة لتقريبها على الفهم والحصول على صورة لكيفية تطبيقها.
تعاريف هامّة
ذكرنا للتو العديد من المصطلحات التي تبدو غريبة بعض الشيء عن المصطلحات التقليدية لتعلم الآلة. سأوضح هنا هذه المصطلحات.
البيئة Environment: تمثل العالم المحيط (حقيقي أو افتراضي) الذي يتفاعل مع العميل. تُنتِج البيئة ضمن عملية التعلم الحالات والمكافأة للعميل لكي يتحسسها ويعالجها.
العميل: هو العنصر (مثلاً برنامج) الذي يتعلم تحقيق الهدف المنوط به من خلال تفاعله مع البيئة. يتحسس العميل الحالة والمكافأة ويقوم باتخاذ الفعل تبعاً لذلك.
المكافأة: تمثل قيمة تعيدها البيئة عندما يختار العميل القيام بفعل معين. تحدد هذه القيمة من قبل الشخص المصمِّم لمشكلة التعلم بالتعزيز.
الحالة: يطلق على كل سيناريو مختلف يواجه العميل في البيئة حالة. ينتقل العميل بين هذه الحالات بأداء الأفعال. قد تكون الحالة إحدى المربعات في لعبة الشطرنج أو وضعية معينة لروبوت في فضاء ثلاثي الأبعاد.
الفعل: هو الطريقة التي تسمح للعميل بالتفاعل وتغيير بيئته وبالتالي التحويل بين الحالات المختلفة. كل فعل يتخذه العميل يحتوي على مكافأة. يتم اتخاذ قرار فعل معين استنادا إلى السياسة.
تابع القيمة Value Function: هو التابع الذي يربط بين الحالة وقيمتها. تمثل هذه القيمة (رقم) المكافأة بعيدة الأمد التي سنحصل عليها إذا بدأنا بهذه الحالة.
السياسة: هي تابع اتخاذ القرار (استراتيجية التحكم) للعميل والتي تمثل تخطيط بين كل حالة والفعل المناسب لاتخاذه في هذه الحالة.
أمثلة عن التعلم المعزّز
تحديد عدد الاعلانات على صفحة انترنت
العميل: هو البرنامج الذي يقوم باتخاذ قرار عدد الإعلانات المناسب للصفحة
البيئة: صفحة الإنترنت
الفعل: واحد من ثلاثة 1) وضع إعلان جديد على الصفحة 2) إسقاط إعلان من الصفحة 3) عدم إضافة أو اسقاط أي إعلان
المكافأة: إيجابي عندما تزداد الإيرادات، سلبي عندما تنخفض الإيرادات
في هذا السيناريو يقوم العميل بمراقبة البيئة ويحصل على حالة، يتخذ العميل بعد ذلك أحد الأفعال المذكورة سابقاً. بعد اتخاذ فعل معين يحصل العميل على مكافأة. تكون المكافأة إيجابية عندما تزداد الإيرادات ومكافأة سلبية عندما تنخفض هذه الإيرادات. يقوم البرنامج بتحديث السياسة لاتخاذ الأفعال التي تؤدي للحصول على أكبر قدر من المكافآت.
التحكم بروبوت متحرك
العميل: البرنامج الذي يتحكم بالروبوت
البيئة: العالم الحقيقي
الفعل: واحدة من إحدى الحركات الأربعة التالية أمام، خلف، يمين، يسار
المكافأة: إيجابي عندما يتحرك الروبوت باتجاه الهدف، سلبي عندما يتحرك بالاتجاه الخطأ أو يسقط.
في هذا المثال يستطيع الروبوت تعليم نفسه التحرك بفعالية بتكييف السياسة اعتماداً على المكافآت التي يحصل عليها.
مقارنات بين أنواع التعلم الآلي
- مقارنة بين تقنيات التعلم الآلي من حيث الديناميكية والثبات
الهدف من التعلم بإشراف وبدون إشراف هو تعلم أنماط في بيانات التدريب. هذه في المجمل عملية ثابتة. في مقابل ذلك يتمثل الهدف من التعلم المعزّز بتطوير السياسة بحيث تخبر العميل بالفعل المناسب لاتخاذه في كل خطوة. ذلك يجعلها من هذا المنظور أكثر ديناميكية.
- لا يوجد جواب صحيح واضح في التعلم المعزّز
إن الجواب الصحيح في التعلم بالإشراف معطى مسبقاً في بيانات التدريب. مقابل ذلك في التعلم المعزّز الإجابة الصحيحة أو الأفعال الصحيحة غير مقدمة مسبقاً ويجب تعلمها من خلال عملية التجربة والخطأ. ماهو معروف في التعلم المعزّز هو المكافأة والتي تُري العميل فيما إذا كان يصنع تقدماً أو فشلاً في خياراته
- يتطلب التعلم المعزّز الاستكشاف
يحتاج العميل إلى إيجاد التوازن الصحيح بين استكشاف البيئة والبحث عن مصادر جديدة للمكافأة وفي نفس الوقت الاستفادة من مصادر المكافأة وهي الأفعال الصحيحة التي تعلمها مسبقاً. على عكس ذلك في التعلم بالإشراف وبدون إشراف يتعلم النظام الإجابة مباشرة من بيانات التدريب بدون الحاجة لاستكشاف أجوبة جديدة.
مقاربات التعلم المعزّز
لتطبيق التعلم المعزّز في حل المشكلات يجب تخطي التحديات الأربعة التالية [4]:
- التمثيل representation وهي القدرة على تمثيل الحالات والانتقال بينها رياضياًَ.
- التعميم generalization قدرة النظام على التصرف بشكل جيد مع الحالات غير المعروفة إلى حد الآن.
- الاستكشاف exploration: يتمثل في السؤال هل هناك فعل لم نجربه وكان من الممكن أن يقود إلى خرج أفضل في المجمل.
- إسناد الرصيد المؤقت temporal credit assignment: وهي مشكلة تحديد الأفعال التي قادت إلى خرج معين.
سوف نتحدث هنا عن بعض المقاربات المستخدمة لحل طيف واسع من مشاكل التعلم المعزّز. تختلف فيما بينها بأن إحداها أفضل من الأخرى لحل مشكلة معينة.
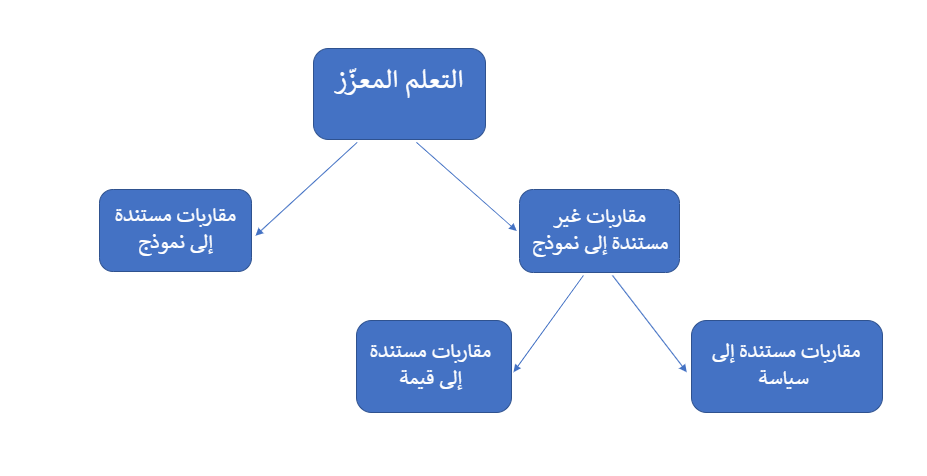
التعلم المعزّز غير المستند إلى نموذج Model-free RL
1. مقاربات مستندة إلى السياسة Policy-based.
في هذه المقاربة يتم تعلم تابع السياسة Policy Function. هذا التابع هو ربط بين كل حالة والفعل المناسب لاتخاذه في هذه الحالة. كما نرى في الشكل رقم 5 في الأسفل، يتم ربط كل مربع (حالة) بالاتجاه المناسب لاتخاذه (الفعل). تتم عملية التعلم بنجاح عندما يرتبط كل مربع من المربعات باتجاه يؤدي إلى الوصول إلى الهدف في النهاية. لاحظتم أنّنا لا نستخدم في هذه المقاربة تابع القيمة. لكن يمكن استخدامه في بعض الأحيان من أجل تحسين optimize أداء تابع السياسة [6][3].
a = π (s)
a : الفعل
π : تابع السياسة
s : الحالة
قد يأخذ الربط في تابع السياسة شكلين إما :
- تابع سياسة ذو طابع حتمي deterministic: يعني ذلك أنّ تابع السياسة لحالة معينة سيعطي بالنتيجة فعل واحد فقط. كما في المثال شكل 5، نرى أن كل مربع من المربعات مرتبط باتجاه واحد ولا نملك خيارات أخرى.
- تابع سياسة ذو طابع عشوائي stochastic: يعني أنّ تابع السياسة لحالة معينة سيعطي توزع احتمالي لأفعال مختلفة. بدلاً من أن نكون متأكدين من اتخاذ فعل معين 100% سيكون لدينا احتمال اتخاذ أفعال متعددة مثلا فعل أ 30% والفعل ب 70%.
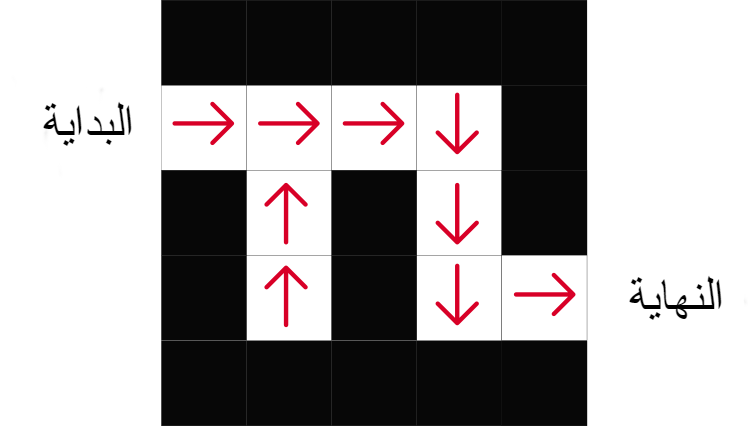
تحدد السياسة كما في الشكل أفضل فعل في كل خطوة حسب إتجاه السهم وذلك بعد عملية تدريب السياسة.
2. مقاربات مستندة إلى القيمة Value-based
يتمثل هدف العميل هنا بتحسين تابع القيمة ( V( s . يُعرَّف تابع القيمة بأنّه التابع الذي يعطينا المكافأة المستقبلية المتوقعة الأكبر التي يمكن أن يحصل عليها العميل في حال تواجده في حالة معينة. يتم تعلم قيمة كل حالة أو قيمة العلاقة بين كل حالة-فعل كما في التعلم المعتمد على الجودة Q-Learning.

سوف يستخدم العميل هذه المعادلة ليختار الحالة التي تعطيه القيمة الأكبر في كل خطوة، بالتالي عندما يكون لدى العميل في كل خطوة يخطوها مجموعة من الخيارات يختار الحالة ذات القيمة الأكبر.
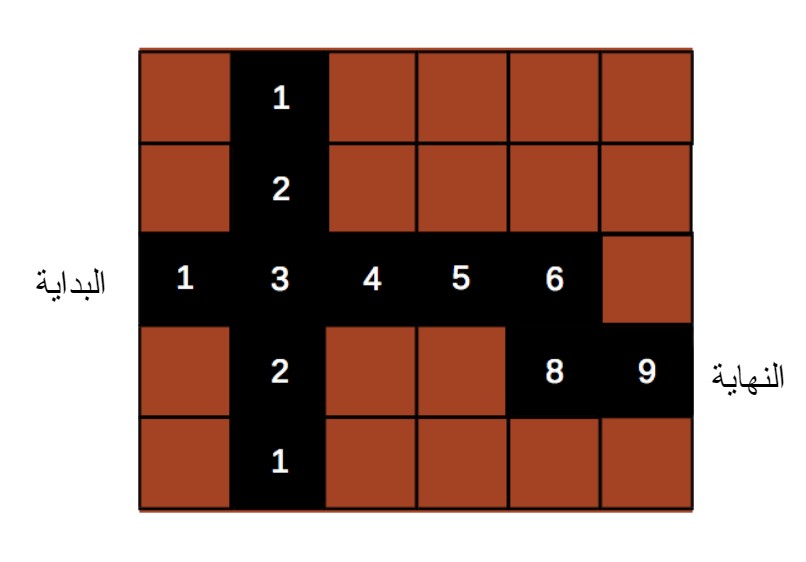
عزيزي القارئ، في هذا المثال نرى أنه يجب في كل خطوة اختيار القيمة الأكبر لتحقيق الهدف. فمثلاً عند الوصول إلى المربع ذو القيمة 3 يكون لدينا ثلاث خيارات لاختيار المربع الذي يليه. يكون الاختيار في هذه الحالة للمربع ذو القيمة الأعلى لأننا بذلك سوف نصل إلى الهدف. تتم عملية التعلم في هذا المثال بربط كل حالة والتي تتمثل هنا بكل مربع من المربعات بقيمة معينة والتي تتمثل برقم. تكون عملية التعلم ناجحة عندما يرتبط الطريق الموصل للهدف بالقيم الأعلى وبذلك يتم الوصول للهدف بنجاح من قبل العميل [3][6].
يجدر بالذكر أنه توجد أيضاً خوارزميات هجينة تدمج بين المقاربة المستندة إلى السياسة والمقاربة المستندة إلى القيمة.
التعلم المعزّز المستند إلى نموذج Model-based RL
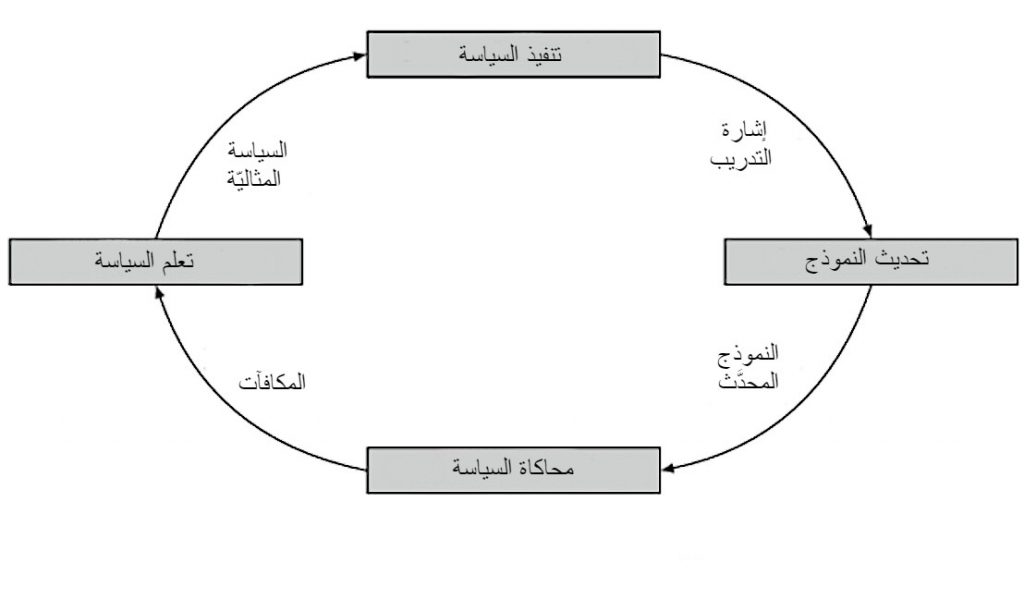
الهدف من التعلم المعزّز بشكل عام هو تحديد سياسة تعطينا أفضل النتائج على المدى البعيد. ولتحقيق ذلك لدينا العديد من الطرق و الخوارزميات. إنّ الفرق الرئيسي بين التعلم المعزّز غير المستند إلى نموذج و المستند إلى نموذج أنه في التعلم المستند إلى نموذج يتم نمذجة البيئة أي صنع نموذج لتصرف البيئة المحيطة تؤثر في كيفية تحديد السياسة. الشكل في الأسفل يعطي نظرة في كيفية تبادل التأثير بين النموذج والسياسة. هذا النمط من التعلم المعزز ليس له انتشار واسع كالبقية، لأن كل بيئة جديدة تحتاج إلى نموذج مختلف، وهذا يمثل صعوبة للقيام به دائماً [7].
الخلاصة
اصبح التعلم المعزّز أكثر شيوعاً في السنوات الأخيرة نظراً إلى الطيف الواسع من المشاكل التي يمكن أن تُحل باستخدامه في التحكم و الأتمتة الصناعية و الربوتكس والصحة والاقتصاد وغيرها من المجالات الكثيرة. لهذا السبب يؤكد الكثير من الباحثين أن التعلم المعزّز سوف يكون أحد أهم الطرق للوصول إلى الذكاء الاصطناعي العام Artificial General Intelligence. كان هذا المقال نقطة بداية لتعلم أهم المصطلحات والمقاربات المتعلقة بالتعلم المعزّز. الخطوة الأولى لتطبيق التعلم المعزّز هي فهم المشكلة وتحليلها وتأطير العناصر الأساسية مثل العميل والبيئة ونوعية الأفعال والحالات الممكنة والمكافأة. بعد ذلك يتم اختيار أفضل مقاربة يمكن أن تحل هذه المشكلة. يندرج تحت كل مقاربة من المقاربات التي ذكرتها العديد من الخوارزميات التي تختلف في أدائها ونوعية المشاكل التي يمكن أن تحلها. يوجد حالياً العديد من المنصات على الانترنت تؤمن أدوات يمكن أن تساعد في تعلم وتطبيق خوارزميات مختلفة للتعلم المعزّز مثل OpenAI Gym و DeepMind Lab و Amazon SageMaker.
المراجع
- DeepMind-AlphaGo
- Reinforcement Learning, Part 1: A Brief Introduction
- A Brief Introduction to Reinforcement Learning
- Edx Course: Reinforcement Learning Explained
- Introduction to Deep Reinforcement Learning from MIT
- An Introduction to Reinforcement Learning
- What is Model-Based Reinforcement Learning?
- نظريات التعلم السلوكي