
وصلنا عزيزي القارئ إلى المقالة الثالثة في سلسلة استخدام النماذج المدرّبة مُسبقاً. تعلّمنا في المقالتين السابقتين [1، 2] كيف يمكننا استخدام النماذج المدربة مُسبقاً من أجل تنفيذ مهمة تصنيف الصور وكيف يمكننا استخدام هذه النماذج كمُستخرج مزايا Feature Extractor و تدريب نموذج جديد من أجل تنفيذ مهمة تصنيف مختلفة. والآن في هذه المقالة، سوف نتعلم كيف نقوم بعملية ضبط دقيق Fine-tune لنموذج مدرب مُسبق من أجل مهمة مختلفة تماما عن المهمة التي تم التدريب عليها بالأساس.
سنحاول في هذه المقالة تحسين النتائج التي حصلنا عليها في المقالة السابقة عندما قمنا ببناء نموذج للتعرّف على البندورة و الجبس و اليقطين. كما سنستخدم لهذا الغرض نفس البيانات.
ولكن بداية ما هو الضبط الدقيق؟!
المحتويات
1- الضبط الدقيق لشبكة Fine-Tuning a Network
سبق وقمنا بشرح أهمية استخدام الشبكات المدرّبة مسبقاً في مقالتنا الأولى [1]، مُلخّص ذلك أنه عند تدريب شبكة عصبونية من البداية (غير مدربة مسبقأ) سنواجه الحالتين الحديّتين التاليتين:
- الحاجة إلى بيانات ضخمة: وذلك لأن الشبكة العصبونية يمكن أن تمتلك ملايين المُعاملات وبالتالي من أجل الوصول إلى الأوزان المثالية لتلك المُعاملات، يجب أن نمتلك كمية كبيرة من البيانات.
- الحاجة إلى قدرة حوسبة كبيرة: فحتى لو كان لدينا الكثير من البيانات، يحتاج تدريب الشبكات العصبونية بالعادة إلى عدة دورات تدريب و يؤثر على الموارد الحاسوبية.
عزيزي القارئ، إن فكرة الضبط الدقيق لشبكة ما ليست معقدة، فهي عبارة عن تعديل مُعاملات شبكة مدرّبة مسبقاً بحيث تتلاءم مع المهمة الجديدة المُراد تنفيذها. كما هو معروف، تميل الطبقات الأولى من الشبكة العصبونية لأن تتعلم مزايا عامة جداً وكلما تقدمنا باتجاه النهاية تميل الطبقات لتعلّم مزايا محددة وخاصة بالمهمة التي نقوم بالتدريب عليها. ولذلك من أجل عملية الضبط الدقيق، يجب أن نحافظ على طبقات الشبكة الأولية سليمة (تجميدها) و أن نقوم بإعادة تدريب الطبقات اللاحقة.
بالتالي يجنبنا الضبط الدقيق الحالتين الحديّتين المذكورتين أعلاه:
- حجم البيانات المطلوب من أجل التدريب ليس كبيراً لسببين: الأول، نحن لا نقوم بتدريب كامل الشبكة. الثاني، إن الجزء الذي يتم تدريبه لا يتم تدريبه من الصفر.
- الوقت اللازم لتدريب الشكبة أقل باعتبار أن عدد المُعاملات التي تحتاج إلى تحديث أقل.
2- الضبط الدقيق في كيراس Fine-Tuning in Keras
سنستخدم في هذا المقال نفس البيانات التي استخدمناها في المقال السابق عندما قمنا بتطبيق نقل التعلّم. كما سنستخدم شبكة مجموعة الهندسة البصريّة في جي جي VGG. يمكنك عزيزي القارئ استخدام بيانات تدريب أكبر في حال كان لديك وحدة معالجة رسوميّة GPU باعتبار أن التدريب سيحتاج إلى وقت تدريب أقل فيما لو قمنا بالاعتماد على وحدة المعالجة المركزيـّة CPU.
3- تعزيز البيانات Data Augmentation
هو استراتيجية تُمكّن الباحثين والمطورين من زيادة عدد و تنوُّع البيانات (وبالأخص بيانات التدريب) بشكل كبير من أجل استخدامها في تدريب نماذج تعلُّم عميق من دون الحاجة إلى جمع وإضافة بيانات جديدة. من الأمثلة عن تقانة تعزيز البيانات: قص الصور، الحشو، القلب الأفقي أو العمودي للصور، التدوير، الإمالة، التغيير العشوائي لبعض بكسلات الصور، …. إلخ
4- التجربة الأولى: تدريب الطبقات الأربع الأخيرة من دون تعزيز للبيانات
تحميل النموذج المدرّب مسبقاً
في البداية سنقوم بتحميل نموذج في جي جي VGG كاملاً باستثناء الطبقة العليا (الطبقة ذات الاتصال الكامل)
from keras.applications import VGG16
#Load the VGG model
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
سنقوم بعمليّتي ضبط دقيق لنموذج في جي جي VGG الذي قمنا بتحميله، الأولى من دون إجراء تعزيز للبيانات Data Augmentation والثانية مع إجراءها.
تجميد الطبقات المطلوبة
تمتلك كل طبقة في كيراس مُعامل يُسمى “قابليّة التدريب” Trainable، أي أنه إذا أردنا تجميد أوزان طبقة ما (جعل هذه الطبقة غير قابلة للتدريب وبالتالي لن يتم تحديث أوزانها)، نقوم بإسناد القيمة false لمُعامل قابليّة التدريب الخاص بهذه الطبقة، كما هو واضح في الشكل (1). وبهذه الطريقة يمكننا التحكم واختيار الطبقات التي نريد تدريبها. وذلك ما تقوم به الشيفرة البرمجية التالية.
# Freeze the layers except the last 4 layers
for layer in vgg_conv.layers[:-4]:
layer.trainable = False
# Check the trainable status of the individual layers
for layer in vgg_conv.layers:
print(layer, layer.trainable)

إنشاء نموذج جديد
بعد أن قمنا بتجميد المُعاملات القابلة للتدريب في شبكتنا الأساسية، سنقوم بإضافة مُصنّف (طبقة تصنيف) يلي طبقات الطّي للشبكة الأساسية. أي أنه سيتم وصل نموذج الشبكة الأساسية مع طبقة التسطيح ثم مع المُصنّف على التسلسل. تُوضّح الشيفرة البرمجية التالية ذلك، حيث تم إنشاء نموذج تسلسلي فارغ وإضافة نموذج في جي جي للشبكة الأساسية إليه، بعد ذلك تم إضافة طبقة تسطيح ثم طبقة طّي ذات 1024 مرشّح طّي وأخيراً طبقة تصنيف ذات ثلاثة أصناف وتابع تفعيل سوفت ماكس softmax.
from keras import models
from keras import layers
from keras import optimizers
# Create the model
model = models.Sequential()
# Add the vgg convolutional base model
model.add(vgg_conv)
# Add new layers
model.add(layers.Flatten())
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(3, activation='softmax'))
# Show a summary of the model. Check the number of trainable parameters
model.summary()
يبين الشكل (2) ملخّص النموذج التسلسلي الناتج، حيث يبين العمود الأول اسم النموذج أو الطبقة، ويبين العمود الثاني حجم الخرج لتلك الطبقة، بينما يبين العمود الأخير عدد المُعاملات القابلة للتدريب في تلك الطبقة.

تدريب النموذج
في البداية سنقوم بتحميل بيانات التدريب والتحقق كل على حدى على دفعات عن طريق استخدام مولِّد بيانات الصور ImageDataGenerator المُعرّف ضمن صف الصورة التابع لحزمة المعالجة المسبقة في كيراس keras.preprocessing.image. سنقوم بتقييس الصور عن طريق تقسيم جميع بكسلات الصورة على 255 وتغيير حجمها إلى الحجم المرغوب (image_size) أثناء تحميلها من دون تطبيق أي عملية تعزيز للبيانات.
# No Data augmentation
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Change the batchsize according to your system RAM
train_batchsize = 100
val_batchsize = 10
# Data Generator for Training data
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(image_size, image_size),
batch_size=train_batchsize,
class_mode='categorical')
# Data Generator for Validation data
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(image_size, image_size),
batch_size=val_batchsize,
class_mode='categorical',
shuffle=False)
فيما يلي تتم عملية ترجمة النموذج باستخدام تابع الخسارة “الإنتروبيا المُتقاطِعةُ الفِئَويِّة” Categorical Crossentropy وتابع التحسين “الجذر التربيعي لمتوسط مربعات الانتشار RMSprop”.
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
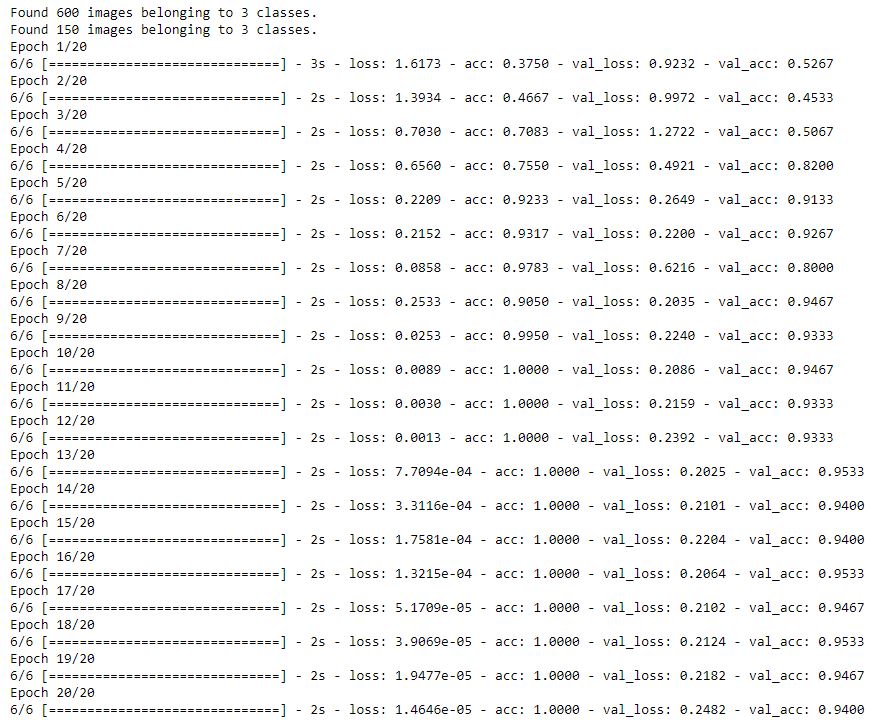
تم تدريب النموذج لـ 20 دورة تدريب عن طريق استدعاء الدالة fit_generator. يبين الشكل (3) تفاصيل دقة/خسارة التدريب و دقة/خسارة التحقق لكل دورة تدريب.
# Train the Model
history = model.fit_generator(
train_generator,
steps_per_epoch=train_generator.samples/train_generator.batch_size ,
epochs=20,
validation_data=validation_generator,
validation_steps=validation_generator.samples/validation_generator.batch_size,
verbose=1)
يمكنك عزيزي القارئ حفظ النموذج المُدرّب كما هو واضح في الشيفرة البرمجية التالية
# Save the Model
model.save('last4_layers_no_aug.h5')
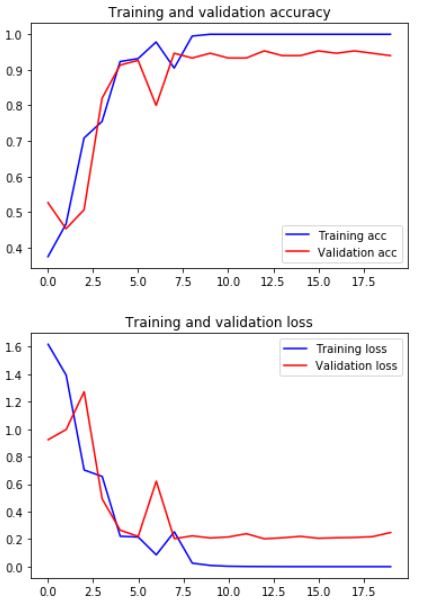
كما يمكنك طباعة مخططي الدقة والخسارة في كل خطوة من خطوات التدريب كما هو مبين في الشيفرة البرمجية التالية و الشكل (4)
# Plot the accuracy and loss curves
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
اختبار النموذج المُدرّب
من أجل اختبار النموذج الذي قمنا بتدريبه، سنقوم أولاً بتحميل بيانات الاختبار باستخدام موًّلد بيانات الصور كما فعلنا مع بيانات التدريب، تم بعد ذلك تقييس الصور عن طريق تقسيم جميع بكسلات الصورة على 255 وتغيير حجمها إلى الحجم المرغوب.
# Create a generator for prediction
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(image_size, image_size),
batch_size=val_batchsize,
class_mode='categorical',
shuffle=False)
في الشيفرة البرمجية التالية، نقوم بالاحتفاظ بأسماء صور الاختبار في المتغيّر fnames حيث سنستخدم هذا المتغير لاحقاً للوصول إلى الصور التي تم تصنيفها بشكل خاطئ، كما سنقوم بالاحتفاظ بأسماء أصناف الصور كحقائق مرجعية في المتغيّر ground_truth ليتم استخدامه عند المقارنة مع نتائج التصنيف. وأخيراً يتم الاحتفاظ بتخطيط mapping بين فهارس الأصناف وأسمائها (اسم_الصنف_إلى_الفهرس) وبتخطيط عكسي بين أسماء الأصناف وفهارسها (الفهرس_إلى_اسم_الصنف).
# Get the filenames from the generator
fnames = validation_generator.filenames
# Get the ground truth from generator
ground_truth = validation_generator.classes
# Get the label to class mapping from the generator
label2index = validation_generator.class_indices
# Getting the mapping from class index to class label
idx2label = dict((v,k) for k,v in label2index.items())
في الشيفرة البرمجية التالية، يتم التنبؤ بصنف صور الاختبار باستخدام النموذج المُدرّب عن طريق استدعاء الدالة “predict_generator”. تأخذ هذه الدالة كمُعاملات: مُولّد صور بيانات الاختبار و خطوة التدريب (وهي عدد الخطوات اللازمة للمرور على كافة صور الاختبار في دورة التدريب الواحدة و تساوي عدد صور الاختبار / حجم الدفعة. تقوم الدالة argmax بإيجاد الصنف الذي يملك أعلى قيمة احتمالية، حيث يتم الحصول على شعاع من ثلاث قيم احتمالية (واحدة لكل صنف).
# Get the predictions from the model using the generator
predictions = model.predict_generator(validation_generator, steps=validation_generator.samples/validation_generator.batch_size,
verbose=1)
predicted_classes = np.argmax(predictions,axis=1)
أخيراً تقوم الشيفرة البرمجية التالية بإيجاد الصور التي تم تصنيفها بشكل خاطئ عن طريق المقارنة بين الحقائق المرجعية و الأصناف التي تم التنبؤ بها. حيث نقوم أولاً بإيجاد الفهارس الموافقة للصور خاطئة التصنيف و من أجل كل صورة من تلك الصور، يتم إيجاد قيمة احتمال الصنف من مصفوفة التنبؤات واسم الصنف باستخدام تخطيط الفهرس_إلى_اسم_الصنف.
errors = np.where(predicted_classes != ground_truth)[0]
print("No of errors = {}/{}".format(len(errors),validation_generator.samples))
# Show the errors
for i in range(len(errors)):
pred_class = np.argmax(predictions[errors[i]])
pred_label = idx2label[pred_class]
title = 'Original label:{}, Prediction :{}, confidence : {:.3f}'.format(
fnames[errors[i]].split('/')[0],
pred_label,
predictions[errors[i]][pred_class])
original = load_img('{}/{}'.format(validation_dir,fnames[errors[i]]))
plt.figure(figsize=[7,7])
plt.axis('off')
plt.title(title)
plt.imshow(original)
plt.show()
تُبيّن الشيفرة البرمجية التالية كيفية اختبار النموذج الذي قمنا بتدريبه إضافة إلى طباعة الصور التي تم تصنيفها بشكل خاطئ كما في الشكل (5).

يمكنك عزيزي القارئ أن تلاحظ أن دقة النموذج الجديد المُدرّب من دون تعزيز البيانات 94% باعتبار أن خطأ التصنيف هو 9/150 أي 6%.
5- التجربة الثانية: تدريب الطبقات الأربع الأخيرة مع تعزيز للبيانات
في هذه التجربة، سنقوم بتطبيق خطوات التجربة الأولى نفسها باستثناء أننا سنقوم هذه المرة بتطبيق تعزيز البيانات. تبين الشيفرة البرمجية التالية تطبيق تعزيز البيانات أثناء تحميلها. أما ما تبقى من الشيفرة البرمجية فهي نفس التجربة الأولى:
- تحميل نموذج في جي جي
- تجميد الطبقات الأربع الأخيرة من نموذج في جي جي الأساسي
- إنشاء نموذج جديد بإضافة مُصنّف إلى الشبكة العصبونية الأساسية
- تحميل البيانات وتطبيق تعزيز البيانات
- تدريب النموذج الجديد
- حفظ النموذج
- طباعة مخططات الدقة والخسارة بالنسبة لدورات التدريب
- تحميل بيانات التدريب، التنبؤ بأصناف صور الاختبار.
- طباعة الصور التي تم تصنيفها بشكل خاطئ.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1./255)
# Train the Model
# NOTE that we have multiplied the steps_per_epoch by 2. This is because we are using data augmentation.
history = model.fit_generator(
train_generator,
steps_per_epoch=2*train_generator.samples/train_generator.batch_size ,
epochs=40,
validation_data=validation_generator,

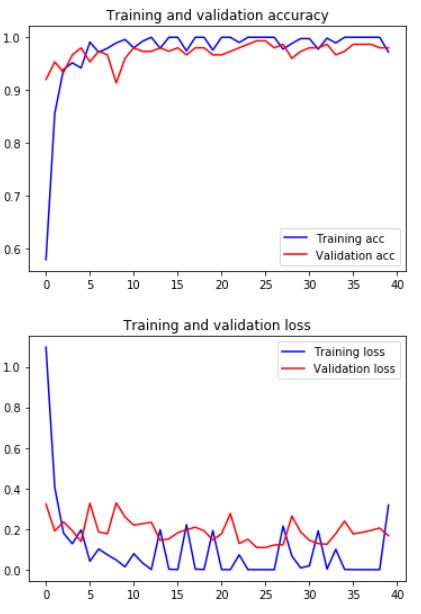
يبين الشكل (6) تفاصيل دقة/خسارة التدريب و دقة/خسارة التحقق لدورات التدريب الـ 20 الأخيرة بعد إضافة خطوة تعزيز البيانات.
كما يمكن طباعة مخططي الدقة والخسارة في كل خطوة من خطوات التدريب كما هو مبين بالشكل (7)
اختبار النموذج المُدرّب بعد إضافة تعزيز البيانات
تم اختبار النموذج الذي قمنا بتدريبه بنفس خطوات التجربة الأولى، يبين الشكل (8) الصور التي تم تصنيفها بشكل خاطئ وهي ثلاث صور.

يمكنك عزيزي القارئ أن تلاحظ أن دقة النموذج الجديد المُدرّب مع تعزيز البيانات 98% باعتبار أن خطأ التصنيف هو 3/150 أي 2%. أنصحك عزيزي القارئ بالاطلاع على كامل الشيفرة البرمجية في مستودع الجيت هب.
6- خلاصة التجارب
عزيزي القارئ، لقد قمنا في هذا المقال بتنفيذ تجربتين لنرى تأثير الضبط الدقيق لشبكة مع وبدون تعزيز البيانات. تم استخدام نفس بيانات الاختبار في كلا التجربتين.
- تدريب آخر ثلاث طبقات طّي، حصلنا على 9 صور خاطئة التصنيف من أصل 150 صورة
- تدريب آخر ثلاث طبقات طّي مع تعزيز البيانات، حصلنا على 3 صور خاطئة التصنيف من أصل 150 صورة
حاول عزيزي القارئ أن تقوم بتنفيذ كلا التجربتين بنفسك وضع لنا النتائج التي حصلت عليها في التعليقات.
7- الخاتمة
وصلنا عزيزي القارئ إلى نهاية سلسلتنا “استخدام النماذج المدرّبة مُسبقاً”، حيث بدأنا السلسلة بمقال بيّنا فيه طريقة استخدام النماذج المدرّبة مسبقاً وعزّزنا ذلك بمثال قمنا فيه ببناء نموذج لتصنيف البندورة و الجبس و اليقطين. لم يستطع ذلك النموذج المدرّب مسبقاً والمُهيّأ بأوزان إيمج-نت من التعرف على البندورة والجبس واليقطين بدقة جيدة. من أجل تحسين دقة التصنيف، تكلمنا في مقالتنا الثانية عن نقل التعلم وقلنا أنه على اعتبار أن النماذج المدرّبة مسبقاً لم تستطع التعرّف على هذه الأصناف الثلاثة (لم تكن موجودة في قاعدة بيانات تحدّي إيمج-نت للتعرُّف البصري واسع النطاق للرؤية الحاسوبية Imagenet Large Scale Visual Recognition Challenge ILSVRC) لأنه لم يتم تدريب تلك النماذج للتعرّف عليها، فإننا سنقوم باستخدام هذه النماذج كمُستخرج مزايا Feature Extractor و تدريب نموذج جديد (تدريب المُصنف فقط) من أجل تنفيذ مهمة تصنيف البندورة والجبس واليقطين. حيث تم تجميد جميع طبقات الشبكة العصبونية و إضافة مُصنّف فوقها. تم تدريب الشبكة الجديدة وحصلنا على دقة تصنيف 90.5% وبالتالي خطأ تصنيف 9.5%. وأخيراً وصلنا إلى محطتنا الأخيرة حيث قمنا بتطبيق عملية الضبط الدقيق على نفس الشبكة وباستخدام نفس البيانات من أجل زيادة الدقة أكثر. حيث عوضاً عن تدريب المُصنّف فقط كما في نقل التعلّم، قمنا بتدريب طبقات الطّي الأربع الأخيرة مع وبدون تطبيق تعزيز البيانات، ورأينا كيف أن عملية الضبط الدقيق أدت إلى زيادة دقة التصنيف إلى 96% بدون تطبيق تعزيز البيانات و 98% مع تطبيقها.
وفي النهاية، عزيزي القارئ، أتمنى أن تكون هذه السلسلة أعجبتك وأضافت المزيد إلى معرفتك وخبراتك. ريثما يتم تجهيز سلسلة أو مقال جديد أرجو أن تبقى مترقباً!
8- المراجع
- استخدام النماذج المدرّبة مسبقاً على قاعدة البيانات إيمج-نت ImageNet
- نقل التعلُّم باستخدام النماذج المدرّبة مُسبقاً
- Keras Tutorial : Fine-tuning using pre-trained models




