
مع ظهور تطبيقات جديدة تسمح للمستخدمين بالتفاعل مع العالم الحقيقي في الوقت الفعلي ظهرت الحاجة لشبكات عصبونية أكثر كفاءة من أي وقت مضى. وقد أتاح تشغيل الشبكات العميقة على الأجهزة الشخصية تحسين تجربة المستخدم من خلال توفير الوصول في أي وقت وأي مكان مع وجود مزايا إضافية كالأمن والخصوصية واستهلاك الطاقة.
تحدثنا في مقالتنا السابقة عن الإصدار الأول من شبكات موبايل-نت وهي من الشبكات العصبونية التي تعمل بكفاءة عالية على الأجهزة المحمولة وقد أثبت هذه الشبكة نجاحها في العديد من التطبيقات مثل مصنف للصور أو كمستخرج مزايالشبكة عصبونية أكبر.
أعلن مؤخرًأ الباحثون في جوجل عن الإصدار الثاني من هذه الشبكات MobileNetv2 موبايل-نت 2 لتشغيل الجيل الثاني من تطبيقات الرؤية على الموبايل ولتكون أكثر كفاءة وفعالية من الإصدار الأول. وقد تم إصدار هذه النسخة كجزء من مكتبة تنسرفلو سليم TensorFlow-Slim لتصنيف الصور. كما يمكن البدء باستكشافه مباشرة في منصة كولاب أو كبديل يمكن تحميل ورقة جوبيتر وفتحها باستخدام جوبيتر. تتوفر العديد من نماذج موبايل- نت 2 المدربة مسبقًأ على الجيت هوب. سنقوم في هذه المقالة بإثبات فعالية وكفاءة الإصدار الثاني من موبايل-نت مقارنة مع الإصدار الأول بعد معرفة الفرق في البنية بين الإصدارين.
المحتويات
– تلخيص سريع للإصدار الأول من موبايل – نت
الفكرة الأساسية في الإصدار الأول كانت استبدال عملية الطيّ الاعتيادية والتي تعتبر ضرورية لإنجاز مهام الرؤية الحاسوبية لكن بتكلفة حساب عالية بما يسمى الطيّ بالعمق المنفصل وفيه يتم تقسيم عملية الطيّ إلى مرحلتين منفصلتين الأولى هي الطيّ بالعمق والتي تقوم بترشيح الدخل يليها الطيّ النقطيّ والتي تقوم بتجميع القيم المرشحة لإنشاء مزايا جديدة وقد حققت هذه العملية كلفة حساب أقل بنحو 9 مرات تقريبًا مع تقليل الذاكرة المستهلكة بالتالي سرعة أكبر بكثير كل ذلك مع الحصول على الدقة نفسها.
البنية الكاملة لشبكة موبايل-نت الإصدار الأول تتكون من الطيّ الاعتيادي 3×3 في الطبقة الأولى يليها تكرار بعدد 13 مرة للكتلة التي في الشكل (1).
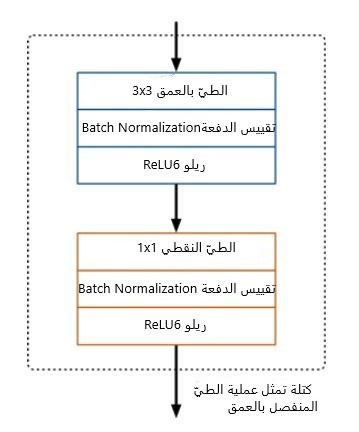
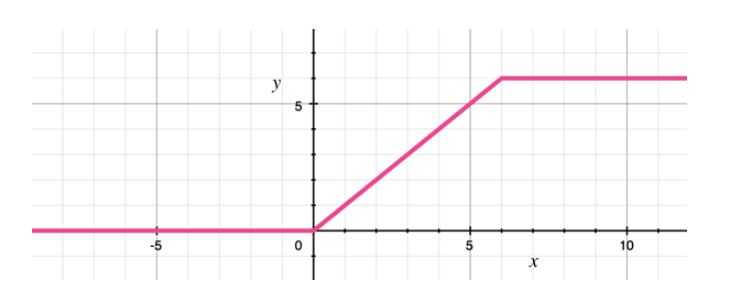
كما أنه لا يوجد طبقات تجميع بين هذه البلوكات وإنما بدلًا من ذلك كانت بعض طبقات الطيّ بخطوة تحريك 2 وذلك لتقليل أبعاد البيانات المكانية وبعدها طبقة الطيّ النقطي المقابلة ستكون مضاعفة لعدد قنوات الخرج. وتُتبع طبقات الطيّ بمقييس الدفعةBatch Normalization وتابع التفعيل ريلو ReLU6 وهو شبيه بتابع التفعيل ReLU ولكنه يمنع عمليات التفعيل من أن تصبح كبيرة جدًأ والخط البياني لتابع التفعيل يصبح أقرب لتابع سيغمويد sigmoid ويعطى بالعلاقة: (y = min(max(0, x), 6
– الإصدار الجديد من شبكات موبايل-نت
لقد استخدم في هذا الإصدار أيضًا الطيّ بالعمق المنفصل لكن الكتلة هذه المرة مختلفة وتبدو كما في الشكل (3):
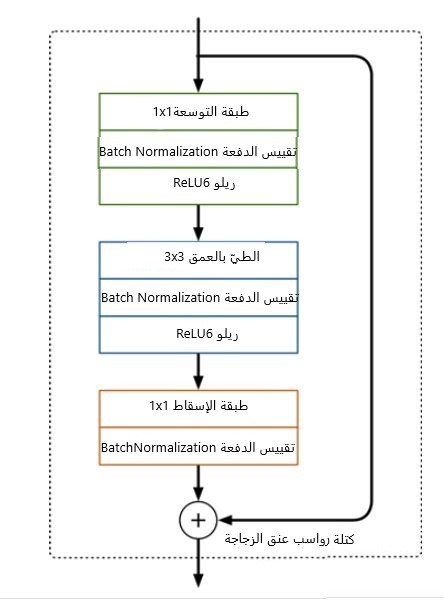
الكتلة السابقة تحوي ثلاث طبقات طيّ أخر طبقتين منها مشابهة لما هو موجود في كتلة الإصدار السابق وهما طبقة الطيّ بالعمق المنفصل التي تقوم بترشيح الدخل متبوعة بطبقة الطيّ النقطي إلا أن عمل الأخيرة هنا مختلف ففي الإصدار الأول كانت مهمتها إمّا المحافظة على عدد القنوات أو مضاعفتها أما هنا تقوم بإنقاص عدد القنوات لذلك دعيت بطبقة الإسقاط حيث تقوم بإسقاط البيانات التي لها عدد كبير من (الأبعاد) القنوات في مصفوفة ذات أبعاد أقل بكثير.
على سبيل المثال طبقة الطيّ بالعمق قد تعمل على مصفوفة بـ 144 قناة بينما ستقلص طبقة الإسقاط هذا العدد إلى 24 قناة فقط. يدعى هذه النوع من الطبقات أيضًا بعنق الزجاجة باعتبارها تقلل كمية البيانات التي تتدفق عبر الشبكة (ومن هنا جاءت تسمية هذه الكتلة ” كتلة رواسب عنق الزجاجة” حيث أن خرج كل كتلة هو عنق الزجاجة”).
أّمّا بالنسبة للطبقة الأولى في هذه الكتلة فهي عبارة عن عملية طيّ 1×1 والتي تهدف إلى زيادة عدد القنوات في البيانات قبل تمريرها إلى الطيّ بالعمق وبالتالي طبقة التوسعة دائمًا لها قنوات خرج أكثر من قنوات الدخل على عكس طبقة الإسقاط. هناك عامل للتوسعة يُحدد من خلاله مقدار التوسعة الذي سيطرأ على البيانات القيمة الافتراضية له هي 6.
فعلى سبيل المثال في حال تم تمرير مصفوفة ذات 24 قناة إلى الكتلة السابقة عندها ستقوم طبقة التوسعة بتحويلها إلى مصفوفة جديدة بأبعاد 24*6=144 قناة ثم تمرر بعدة ذلك إلى طبقة الطيّ بالعمق التي ستطبق بدورها المرشحات على 144 قناة وفي النهاية تأتي طبقة الإسقاط لتسقط الـ 144 قناة إلى عدد أصغر مثًلا 24 مرة ثانية كما في الشكل (4)

نرى من الشكل السابق أن الدخل والخرج للكتلة هي مصفوفات ذات أبعاد صغيرة بينما في خطوة الترشيح التي تكون داخل الكتلة تتم على مصفوفة أبعاد كبيرة. الشيء الأخر المميز في هذا الإصدار هو استخدام الوصلات المختصرة residual connection والتي تعمل كما في شبكة الرواسب وقد وجدت لتساعد على تدفق المشتق عبر الشبكة دون مرورها عبر توابع التفعيل غير الخطية والتي قد تتسبب في تضخم المشتقات أو تلاشيها بحسب أوزان الشبكة. يتم استخدام هذا الاتصال فقط عندما تكون عدد القنوات الداخلة إلى الكتلة هي نفس عدد القنوات الخارجة منها. وهذه ليست حالة دائمة حيث يتم زيادة عدد قنوات الخرج بعد كل عدة كتل).
وفي كل طبقة يتم تقييس الدفعة وتطبيق تابع التفعيل ReLU6. إلا في طبقة الإسقاط لا يتم تطبيق تابع تفعيل على خرجها كونها تعطي بيانات بأبعاد قليلة بالتالي استخدام تابع غير خطي بعدها قد يتسبب في خسارة المعلومات المفيدة.
البنية الكاملة للإصدار الثاني من شبكة موبايل-نت تتألف من 17 كتلة من الكتلة السابقة على التوالي ومن ثم يتبعها الطيّ الاعتيادي 1×1 وطبقة تجميع وطبقة تصنيف. ومع وجود اختلاف بسيط في الكتلة الأولى حيث يتم استخدام الطيّ الاعتيادي 3×3 مع 32 قناة بدلًا من طبقة التوسعة.
– ماهي دوافع القيام بهذه التغييرات في الإصدار الثاني؟
التغيير الذي قام به الإصدار الأول كان استبدال عمليات الطيّ المكلفة حسابيا بعمليات طيّ أقل كلفة حتى لو كانت تعني استخدام المزيد من الطبقات وقد كان ذلك نجاحًا كبيرا. أمّا التغييرات الرئيسية في الإصدار الثاني كانت استخدام طبقات الإسقاط والتوسعة وكذلك الوصلات المختصرة.
بالنظر إلى الشكل التالي ومتابعة تدفق البيانات عبر الشبكة نلاحظ بقاء عدد القنوات قليل إلى حد ما بين الكتل.

كما هو معروف عن هذا النوع من النماذج تزداد عدد القنوات بمرور الوقت وتنقص الأبعاد إلى النصف. ولكن بالمجمل تبقى المصفوفة ذات أبعاد صغيرة نسبيًا وذلك بفضل طبقات عنق الزجاجة التي شكّلت الاتصالات بين الطبقات. ومقارنة بمصفوفات الإصدار الأول فقد كانت بأبعاد أكبر بكثير (7x7x1024).
أي استخدام مصفوفات قليلة الأبعاد كان المفتاح لتقليل عدد الحسابات بالتالي مصفوفة بحجم أصغر يعني حسابات أقل على طبقات الطيّ القيام بها.
إلا أن استخدام مصفوفات قليلة الأبعاد لا يعمل بشكل جيد. حيث أن تطبيق طبقة الطيّ لترشيح مصفوفة قليلة الأبعاد لن يكون قادر على استخراج الكثير من المعلومات. لذلك لترشيح البيانات يجب استخدام مصفوفات بأبعاد أكبر بهذا يكون الإصدار الثاني قد حقق التوافق بين الأمرين.
فكر في المصفوفة قليلة الأبعاد المتدفقة عبر الشبكة بين الكتل كأنها نسخة مضغوطة من البيانات ولتطبيق المرشحات على البيانات سنحتاج لإعادة فك ضغطها أولأ هذا مايحدث فعلًا ضمن كل كتلة.

تعمل طبقة التوسعة كبرنامج فك الضغط الذي يقوم بإستعادة البيانات إلى شكلها الكامل لتقوم بعد ذلك طبقة الطيّ بالعمق بتطبيق المرشحات الضرورية في هذه المرحلة من الشبكة وفي النهاية يأتي دور طبقة الإسقاط لتعيد ضغط البيانات لجعلها أصغر ثانية.
الخدعة التي جعلت هذا ينجح هي عمليات التوسعة والإسقاط التي تمت باستخدام طبقات الطيّ مع معاملات قابلة للتعلم. بهذا يصبح النموذج قادر على معرفة أفضل طريقة لضغط وفك ضغط البيانات في كل مرحلة في الشبكة.
– صراع الإصدارات
سنقوم بالمقارنة بين الإصدارين بدءًا من حجم النماذج وذلك من حيث المعاملات والعدد المطلوب من العمليات الحسابية. تم أخذ أرقام المقارنة من الرابطين 1 و2 وهي لإصدارات النماذج ذات مضاعف عمق depth multiplier مساوي لـ 1.0
يعبر الMACs عن العدد التراكمي لعمليات الجداء. وهو يقيس عدد العمليات الحسابية المطلوبة لإجراء الاستدلال على صورة أر جي بي وحيدة ذات أبعاد 224×224 (كل ما كانت الصور بأبعاد أكبر كل ما عدد العمليات المطلوب أكبر).
من عدد العمليات وحده يجب أن يكون الإصدار الثاني أسرع مرتين من الإصدار الأول. لا يتعلق الأمر بعدد العمليات فقط فالوصول إلى الذاكرة في الأجهزة المحمولة أيضًا أبطأ من القيام بالحسابات بالتالي عدد المعاملات الأقل يضيف ميزة أخرى للإصدار الثاني فهي تحتوي فقط على 80% من عدد المعاملات التي يملكها الإصدار الأول.

وبقياس فرق السرعة الفعلي بين النموذجين على بعض الأجهزة المختارة مع تشغيل الاستدلال على سلسلة من الصور ذات الأبعاد 224×224. ويظهر الجدول التالي العدد الأعظمي لعدد الإطارات بالثانية FPS.

لنتائج أفضل تم استخدام التخزين المؤقت double-buffering حيث يكون الطلب التالي جاهز من وحدة المعالجة المركزية CPU في الوقت الذي يكون فيه الطلب الحالي يعالج من قبل وحدة معالجة الرسومات بهذه الحالة لا تنتظر أي من الوحدتين الأخرى. وقد كان الأمر بالنسبة للإصدار الثاني يستحق فعلًا التخزين المؤقت لكن بالنسبة للإصدار الأول لم يُحدث أي فرق في السرعة وهذا يعني أن الإصدار الثاني أكثر كفاءة.
الحصول على نموذج سريع شيء عظيم! لكن بشرط أن يقوم بما هو مطلوب. لذلك ما هي درجة نجاح هذه النماذج؟

تم قياس الدقة على مجموعة بيانات إيمج نت ImageNet. قد يكون من الصعب مقارنة أرقام الدقة بين النماذج حيث سنكون بحاجة إلى الفهم الدقيق لكيفية تقييم النموذج. وللحصول على الأرقام أعلاه تم اقتصاص المنطقة المركزية من الصورة إلى منطقة تحتوي على 87.5% من الصورة الأصلية ومن ثم تغيير حجم الجزء المقصوص إلى الأبعاد 224×224 بكسل وأخيرًأ استخدام قصاصة واحدة فقط لكل صورة.
كخلاصة نرى أنه في جميع المقاييس كان الإصدار الثاني أفضل من الإصدار الأول. والأهم أن عدد المعاملات هو الأقل كونه يعتبر العامل الأساسي لتحقيق سرعة أكبر على أجهزة الموبايل.
– أكثر من مجرد تصنيف!
باعتبار أن التصنيف تم على مجموعة بيانات إيمج نت فمن الممكن أن لا يتم استخدام هذا المصنف في تطبيقك. و سيتطلب الأمر إما إعادة تدريب المصنف على مجموعة بياناتك الخاصة أو استخدام الشبكة الأساسية كمستخرج مزايا لمهمة أخرى والتي قد تكون الكشف عن الأغراض (إيجاد عدة أغراض في نفس الصورة) أو تجزئة الصورة (بناء صف تنبؤ لكل بيكسل بدلًا من تنبؤ وحيد لكل الصورة) أو أي مهمة أخرى في مجال الرؤية الحاسوبية
بعد استخدام يولو في الكشف عن الأغراض في الزمن الحقيقي تم تقديم كاشف الخطوة الواحدة SSD ليحل المشكلة لكن بشكل أفضل فالاختلاف الأساسي في يولو يكمن في أن التنبؤ يتم من أجل خريطة مزايا واحدة فقط بينما في كاشف الخطوة الواحدة المستخدم في الكشف عن الأغراض تم جمع مجموعة من التنبؤات عبر خرائط معالم متعددة وبأحجام مختلفة. بذلك يمكن القول أن استخدام كلا من موبايل-نت وكاشف الخطوة الواحدة معًا يشكلان تركيبة رائعة.
وقد تم تصميم كاشف الخطوة الواحدة بشكل مستقل عن الشبكة الأساسية لذلك يمكن أن يعمل مع أي شيء تقريبا بما في ذلك شبكات الموبايل-نت. والأفضل من ذلك هو الـ SSDLite الذي يستخدم طبقات الطيّ بالعمق المنفصل بدلأ من الطي الاعتيادي في جزء الشبكة الخاص بالكشف عن الغرض. بالتالي من خلال استخدام SSDLite مع شبكات الموبايل-نت يمكن بسهولة الحصول على نتائج دقيقة في الزمن الحقيقي.
لكن كيف يعمل هذا؟ عند القيام بالتصنيف ستبدو الطبقات الأخيرة من الشبكة العصبونية على الشكل التالي:
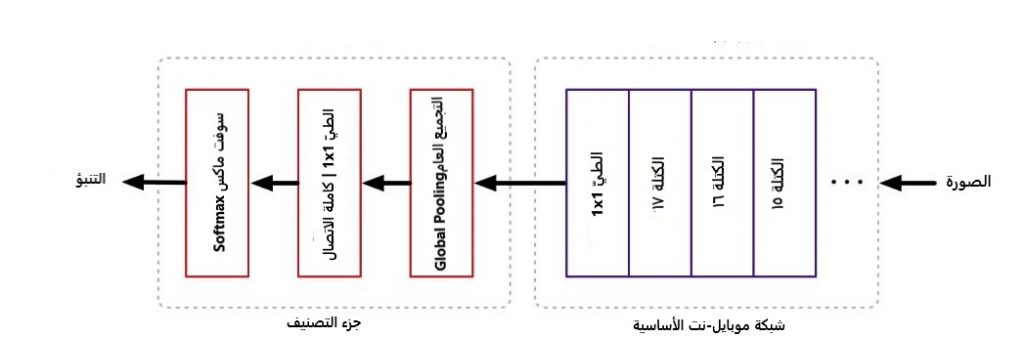
عندما يكون خرج الشبكة الأساسية صورة 7×7 بيكسل المصنف يستخدم أولًا طبقة التجميع العام global pooling لتقليل الحجم إلى 1×1 بيكسل(بشكل أساسي مع 49 متنبأ مختلف) متبوعة بطبقة التصنيف وسوفت ماكس softmax. أمّا لاستخدام SSDLite مع موبايل -نت الطبقة الأخيرة ستبدو على الشكل التالي:
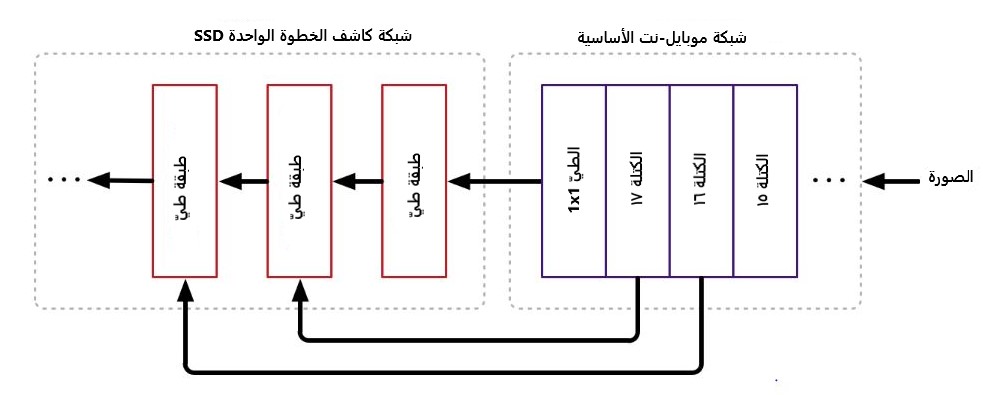
لا يكون ذلك بأخذ فقط خرج الطبقة الأخيرة من شبكة موبايل-نت الأساسية لكن ايضًا خرج عدة طبقات سابقة ومن ثم نمرر كل هذه المخرجات إلى طبقات كاشف الخطوة الواحدة. تتمثل مهمة طبقات الموبايل-نت في تحويل بيكسلات صورة الدخل إلى المزايا التي تصف محتوى الصورة ومن ثم تمررها عبر الطبقات الأخرى وبالتالي موبايل-نت تستخدم هنا كمستخرج مزايا لشبكة عصبونية ثانية.
وفي حالة التصنيف ستكون مهمتها الحصول على المزايا التي تصف مفاهيم الطبقات عالية المستوى مثل “هناك وجه” و ” وهناك فرو” والتي ستسخدمها طبقة التصنيف لرسم الاستنتاج النهائي “هذه الصورة تحوي قطة”
أمّا في حال الكشف عن الأغراض باستخدام كاشف الخطوة الواحدة نحن بحاجة إلى المزايا قليلة المستوى وليس فقط عالية المستوى لذلك تمت قراءة المزايا أيضًا من الطبقات السابقة. على اعتبار أن مهمة كشف الكائن أكثر تعقيدًا من التصنيف, بالتالي فإن كاشف الخطوة الواحدة يضيف العديد من طبقات الطيّ الإضافية للشبكة الأساسية. لذا من المهم أن يكون مسخرج المزايا سريع وهذا بالضبط شبكة موبايل-نت الإصدار الثاني.
كما ان ورقة موبايل-نت الإصدار الثاني تظهر أنه من الممكن تشغيل نموذج التجزئة الدلالية مثل DeepLabV3 بعد المزايا المستخرجة من شبكات موبايل-نت.
الخاتمة
في حال كنت ترغب في بناء شبكة عصبونية ليتم استخدامها على أجهزة الموبايل أو حتى على أنظمة تشغيل ماك عندها سيكون استخدامك لموبايل-نت كمستخرج مزايا للنموذج فكرة جيدة وخاصة إذا كان الهدف هو تحسين السرعة واستخدام ذاكرة أقل والتقليل من استهلاك البطارية. وقد وجدنا في هذه المقالة بعد مقارنة أكثر من مقياس تفوق الإصدار الثاني من موبايل-نت على الإصدار الأول وعرفنا السبب بمقارنة بنية كل من الشبكتين معًا واختلاف أسلوب تدفق البيانات عبر الشبكة.
يتوفر على الجيت هوب مكتبة لنظامي ماك و iOS تحوي على تطبيقات بلغة الميتل لشبكة موبايل-نت بالاصدارين وأيضًا لـ SSDLite و DeepLabv3+. تعمل هذه المكتبة على تسهيل إضافة موبايل-نت إلى تطبيقاتك (إمّا كمصنف أو مكتشف عن الأغراض أو مستخرج مزايا كجزء من نموذج.
المراجع
[1]- MobileNetV2: The Next Generation of On-Device Computer Vision Networks
[2]- Inverted Residuals and Linear Bottleneckscom,2019,
[3]- MobileNet version 2.




