إعداد: م. عمّار وضّاح
التّدقيق العلميّ: م. حمادة حمادة
المَحتويَات
المقدّمة
أصبحت نماذج المحوّلات (Transformer) هي التصميم الأكثر شيوعًا في مجالات مثل تصنيف الصور (Image Classification) ومعالجة اللغات الطبيعية (Natural language processing). ومع تطور نماذج المحولات فقد أصبحت أعمق وأكبر، ولكن نظرًا لأن وحدة الاهتمام الذّاتي (self-attention) في جوهرها لها تعقيد زمني وذاكرة تربيعي في طول التسلسل، فلا يزال من الصعب تزويدها بسياق أطول. وهنا يأتي دور أحد الموضوعات المهمة فيما إذا كان بإمكان نماذج المحولات التغلب على مشاكل وقت التشغيل والذاكرة الخاصة بها بالنسبة للتسلسلات الطويلة من خلال تحسين سرعة الاهتمام وكفاءة الذاكرة [1].
كان الحد من المتطلبات الحسابية والذاكرة للاهتمام (attention) هو هدف العديد من تقنيات الاهتمام التقريبي (approximate attention). تتضمن هذه التقنيات التقريب منخفض الرتبة (low-rank approximation) والتقريب المتناثر (sparse approximation) ومجموعاتها. لا تُظهر العديد من هذه التقنيات تسريعًا على مدار الساعة مقارنةً بالاهتمام العادي، على الرغم من أنها تقلل من متطلبات الحوسبة إلى خطي (linear) أو شبه خطي (almost linear) في طول التسلسل. لكن لم يتم تبنيها على نطاق واسع. تتمثل إحدى المشكلات الرئيسية في أنها تميل إلى التغاضي عن النفقات العامة للوصول إلى الذاكرة (IO) لصالح تقليل عدد عمليات الفاصلة العائمة (FLOPs)، والتي قد لا تكون مرتبطة بسرعة ساعة الحائط (wall-clock speed) [1].
إن تحويل خوارزميات الاهتمام إلى خوارزميات تراعي الإدخال/الإخراج (IO-aware)، أي التي تأخذ بعين الاعتبار حساب عمليات القراءة والكتابة بدقة عبر مستويات الذاكرة المختلفة، سواء السريعة أو البطيئة (مثل الذاكرة المرتبطة بوحدات معالجة الرسومات)، يُعد مبدأً أساسياً مفقوداً حتى الآن [1].
ومن هنا ظهرت تقنية الاهتمام فائق السرعة (Flash Attention)، وهي خوارزمية حديثة تهدف إلى تسريع حساب الاهتمام في نماذج المحولات، مع تقليل استهلاك الذاكرة بشكل كبير، و ذلك دون أي تقارب في النتائج [2].
الدافع: التسلسلات الطويلة
أحد التحديات التي تواجه نماذج المحوِّلات تمثل بتوسيع نطاق طول السياق الذي يمكنها التعامل معه. فطبقة الاهتمام مُتعدّد الرؤوس (Multi-Headed Attention) تعتمد بطبيعتها على حسابات وذاكرة تتزايد بشكل تربيعي (quadratic) مع طول تسلسل الإدخال، وهو ما يجعل معالجة سياقات طويلة أمرًا مكلفًا جدًا [2].
آلية الاهتمام بالضرب النقطي المقيَّس
تُعرف آلية الاهتمام المستخدمة في نماذج المحولات باسم الاهتمام النقطي المتدرج (scaled dot-product Attention). تكون صيغة الاهتمام بالضرب النقطي المقيَّس (SDPA) على النحو التالي حيث Q و K و V هي مصفوفات الاستعلام والمفتاح والقيمة، و dₖ هو بُعد متجهات المفاتيح، وذلك وفقاّ للمعادلة (1) [3]:
المعادلة (1) [3]:
Attention(Q, K, V) = Softmax((QK^T)/√dₖ)V
يسمح نموذج الاهتمام بالضرب النقطي المقيَّس للنموذج بالتركيز على مناطق مختلفة من بيانات الإدخال أثناء توليد كل عنصر من عناصر المخرجات، مما يمنحه القدرة على التقاط العلاقات بعيدة المدى والتعامل بكفاءة مع تسلسلات إدخال ذات أطوال متباينة [3].
كلفة الاهتمام بالضرب النقطي المقيَّس (SDPA)
على الرغم من أن الاهتمام بالضرب النقطي المقيَّس قد أثبتت فعاليّتها، إلا أنها تواجه تحديات عند نمذجة التسلسلات الأطول، لكن في الواقع نتيجة للتكلفة الحسابية الكبيرة لـ الاهتمام بالضرب النقطي المقيَّس [3] نطمح إلى تجاوز الحد التقليدي لطول التسلسل الذي يقف عادةً عند نحو ألفي رمز وبالتالي نتمكن من تدريب النماذج على فهم نصوص طويلة مثل الكتب، والصور عالية الدقة، وصفحات الويب المعقدة، وتفاعلات المستخدم المتعددة، ومقاطع الفيديو الممتدة [2].
خُصِّصت العديد من الأبحاث لمحاولة تقريب آلية الاهتمام عبر استخدام أساليب متناثرة وأخرى منخفضة الرتبة بهدف تقليل التكلفة الحسابية العالية [3].
تعتمد تقنيات الاهتمام المتناثرة على تجاهل بعض العناصر في مصفوفة الاهتمام، في حين تقوم الأساليب منخفضة الرتبة على تفكيك (تحليل) مصفوفة الاهتمام إلى مكونات أصغر ذات رتب محدودة [3].
ورغم أن هذه الطرق تسهم في خفض المتطلبات الحسابية إلى زمن شبه خطي بالنسبة لطول التسلسل، فإنها لم تلقَ اعتمادًا واسعًا بسبب المفاضلة في جودة النتائج وضعف التسريع الفعلي في زمن التنفيذ (wall-clock) مقارنةً بآلية الاهتمام بالضرب النقطي المقيَّس القياسية [3].
حالة عٌنق الزُجاجة للذاكرة (Memory Bottleneck)
يُعزى التحسّن المحدود في تسريع زمن التنفيذ لدى خوارزميات الاهتمام التقريبي إلى تركيزها على تقليل عدد عمليات الفاصلة العائمة دون معالجة تكاليف الوصول إلى الذاكرة (Memory Access Overhead) [3].
ومن المثير للاهتمام، أنّه عند تحليل أداء آلية الاهتمام بالضرب النقطي المقيَّس على وحدة معالجة الرسومات (GPU)، يتّضح أنّ الجزء الأكبر من زمن التنفيذ يُستنزَف في عمليات تعطيلُ عملِ العُصبُوناتِ (Dropout)، والدالة سوفت ماكس (Softmax)، وعمليات التقنيع (Masking Operations)، أكثر من استهلاكه في عمليات ضرب المصفوفات كثيفة الحساب [3].
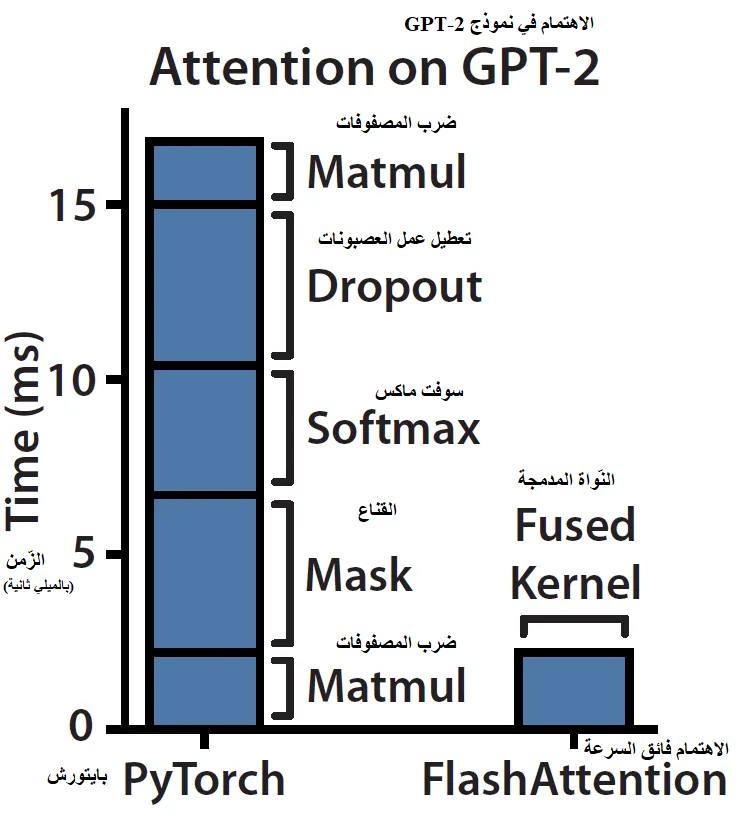
الشكل (1): مقارنة أداء آلية الاهتمام في نموذج GPT-2 بين التنفيذ القياسي و الاهتمام فائق السرعة
يوضح الشكل (1) [1] توضّح مقارنة في زمن تنفيذ عملية الاهتمام في نموذج GPT-2 بين طريقتين:
- تنفيذ بايتورش (PyTorch) العادي
- تنفيذ الاهتمام فائق السرعة المحسَّن (سنتعرف عليه لاحقاً)
عند النظر إلى الشريط الأيسر، يمكن ملاحظة أن العمليات التي تستهلك الجزء الأكبر من الزمن ليست عمليات ضرب المصفوفات (MatMul)، على الرغم من أنها المسؤولة عن النسبة الأكبر من عدد العمليات الحسابية. في الواقع، العمليات مثل التقنيع وسوفت ماكس وتعطيل العصبونات هي التي تمثل العبء الزمني الأكبر أثناء التنفيذ [5].
ومع ذلك، لا يعني هذا أن الأداء قد فُقد بالكامل. فأنظمة الذاكرة في الحواسيب ليست كيانًا متجانسًا(أحاديًَا)، بل تُنظَّم بشكل هرمي يوازن بين السرعة والسعة والتكلفة. وتُعتبر القاعدة العامة في هذا السياق هي أن كلما كانت الذاكرة أسرع، كانت أكثر تكلفة وتمتلك سعةً أقل. هذا التدرج في خصائص الذاكرة يُعدّ من العوامل الحاسمة في تصميم وتنفيذ النماذج العميقة بكفاءة عالية [5].
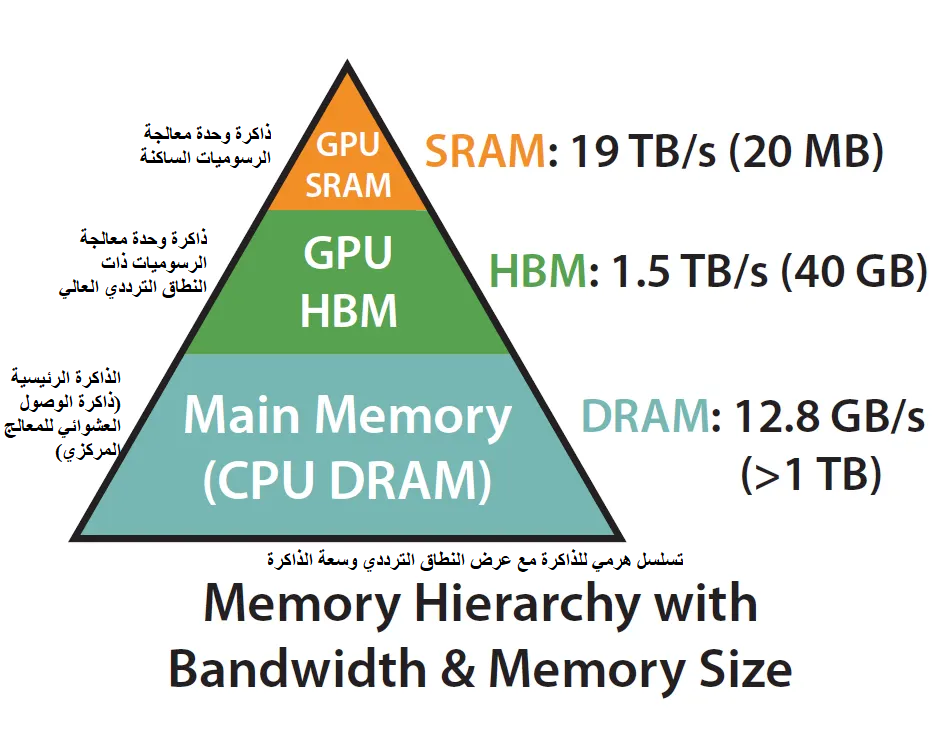
الشكل (2): تسلسل هرمي للذاكرة في أنظمة الحوسبة مع عرض النطاق الترددي والسعة
يبين الشكل (2) [1]: الهرمية الذاكرية في أنظمة الحوسبة الحديثة.
يوضح الشكل العلاقة بين عرض النطاق الترددي للذاكرة (Bandwidth) وسعتها (Size) [5].
حيث أنّ ذاكرة وحدة معالجة الرسوميات الساكنة (SRAM) داخل وحدة معالجة الرسوميات سريعة جدًا ولكنها صغيرة السعة، بينما ذاكرة وحدة معالجة الرسوميات ذات النطاق الترددي العالي (HBM) أبطأ نسبيًا لكنها أكبر بكثير، وذاكرة النظام الرئيسية (DRAM) أبطأ وأكبر حجمًا [5].
يساعد هذا التنظيم الهرمي على تحقيق توازن بين الأداء والسعة، ويبرز أهمية تحسين الوصول إلى الذاكرة السريعة لتقليل اختناقات الإدخال والإخراج في النماذج العميقة [5].
تُفسَّر هذه الملاحظة بواقع أنّ أداء المحوّلات لا يتقيّد عادةً بقوة المعالجة الحسابية، بل بـ عرض النطاق الترددي للذاكرة [3].
إذ تُظهر القياسات أنّ عمليات ضرب المصفوفات تمثّل أكثر من %99.8 من إجمالي عمليات عمليات الفاصلة العائمة، لكنها تستهلك نحو %61 فقط من زمن التنفيذ الكلي [3].
في المقابل، تستهلك العمليات المعتمدة على الذاكرة، مثل التقييس الإحصائي (Statistical Normalization) والعمليات على مستوى العنصر (Element-wise Operations) بما في ذلك تعطيلُ عملِ العُصبُوناتِ والتقنيع ما يقارب %40 من زمن التشغيل، على الرغم من أنّها لا تمثّل سوى %0.02 من إجمالي عمليات الفاصلة العائمة [3].
ببساطة، يُقضى جزءٌ أكبر من زمن التنفيذ في عمليات القراءة والكتابة من الذاكرة أكثر مما يُستهلك في العمليات الحسابية الفعلية. وتُبرز هذه النتائج أهمية معالجة اختناقات الذاكرة في النماذج المعتمدة على المحوّلات لتحسين كفاءتها التشغيلية [3].
الاهتمام القياسي (standard attention implementation)
يُظهر التنفيذ القياسي لآلية الاهتمام (Standard Attention Implementation) أنه لا يراعي خصائص الأجهزة المادية (Hardware) بالشكل الأمثل، إذ يتعامل مع عمليات التحميل والتخزين إلى الذاكرة ذات النطاق الترددي العالي (HBM) كما لو أنها بلا تكلفة تُذكر، أي أنه غير مدرك للإدخال والإخراج [5].
يمكن ملاحظة ذلك بوضوح في الشكل أدناه، حيث تتم كتابة المصفوفة الوسيطة S إلى ذاكرة HBM ثم تُعاد قراءتها مجددًا لحساب دالة الـ سوفت ماكس، في عمليةٍ غير فعّالة من ناحية الزمن والاستهلاك الذاكري [5].

الشكل (3): الشكل القياسي لتطبيق آلية الاهتمام
الشكل (3) [1]: تنفيذ الاهتمام القياسي يكتب المصفوفات الوسيطة إلى ذاكرة HBM ثم يعيد تحميلها لاحقًا لحساب سوفت ماكس، مما يؤدي إلى عبء كبير في عمليات الإدخال والإخراج [5].
لتحسين الكفاءة الزمنية والذاكرية، يمكن إعادة التفكير في التصميم من المبادئ الأولى [5].
أبسط خطوة هي إزالة عمليات القراءة والكتابة الزائدة إلى HBM. بدلاً من إعادة كتابة المصفوفة S إلى HBM ثم تحميلها مرة أخرى، يمكن الاحتفاظ بها مؤقتًا في ذاكرة SRAM وتنفيذ جميع الخطوات الوسيطة هناك، ثم كتابة النتيجة النهائية فقط إلى HBM[5].
تُعرف هذه الاستراتيجية باسم دمج النواة (Kernel Fusion)، وهي إحدى أهم تقنيات التحسين منخفضة المستوى في التعلم العميق.
الفكرة الأساسية هي دمج عدة عمليات متتالية في نواة واحدة، بحيث يتم [5]:
- التحميل من HBM مرة واحدة فقط،
- تنفيذ العمليات المدمجة داخل SRAM،
- ثم الكتابة إلى HBM مرة واحدة فقط.
بهذه الطريقة يُقلَّل عبء الاتصال بين مستويات الذاكرة بشكل كبير، مما يرفع كفاءة التنفيذ. ويُطلق على هذه الفكرة أحيانًا التجسيد (Materialization)، أي تجنّب إنشاء مصفوفات وسيطة كاملة (مثل S وP) بحجم N×N، وهو ما يُشكّل عنق الزجاجة في التنفيذ القياسي [5].
تقنيات مثل الاهتمام الفائق السرعة (Flash Attention) تعالج هذا الاختناق مباشرة، حيث تقلل تعقيد الذاكرة من (O(N^2 إلى
(O(N عبر تنفيذ الاهتمام بطريقة أكثر وعيًا بالبنية الذاكرية [5].
الاهتمام فائق السرعة (Flash Attention)
اقترح تراي داو (Tri Dao)[1] خوارزمية الاهتمام فائق السرعة (Flash Attention) لمعالجة اختناقات الذاكرة في نماذج المحوّلات، وهي خوارزمية اهتمام مدركة للعتاد(Hardware-Aware Attention) تُجري حسابات الاهتمام بدقّة كاملة مع تحسين كفاءة التنفيذ على مستوى العتاد [3].
تعالج هذه الخوارزمية عنق الزجاجة المرتبط بالذاكرة عبر تقليل عدد عمليات القراءة والكتابة لمصفوفة الاهتمام من وإلى ذاكرة وحدة معالجة الرسومات، مع تنفيذ أكبر قدر ممكن من العمليات الحسابية على الرقاقة (On-Chip)[3].
يتطلّب هذا النهج حساب دالة سوفت ماكس دون الحاجة إلى الوصول الكامل لجميع المدخلات، وكذلك الاستغناء عن تخزين مصفوفة الاهتمام الناتجة من مرحلة الانتشارالأمامي (Forward Pass)[3].
وتحقّق خوارزمية الاهتمام فائق السرعة ذلك من خلال تقسيم المدخلات إلى كُتل (Blocks)، ثم حساب دالة سوفت ماكس تدريجيًا كتلةً تلو الأخرى باستخدام تقنية تقسيم البيانات الى أجزاء صغيرة (Tiling) على الرقاقة [3].
إضافةً إلى ذلك، تعتمد الخوارزمية على إعادة الحوسبة (Recomputation) لإعادة حساب قيم الاهتمام بسرعة، مع تخزين عامل التقييس الخاص بـ” سوفت ماكس” فقط أثناء الانتشارالأمامي [3].
تُدمَج جميع هذه الخطوات في نواة وحدة معالجة الرسومات واحدة، مما يؤدي إلى تسريعٍ كبيرٍ في الأداء وانخفاضٍ ملحوظ في استهلاك الذاكرة [3].
كيف يعمل الاهتمام فائق السرعة
تستخدم العديد من نماذج المحوّلات الحديثة آلية تُعرف باسم الاهتمام لتركّز على الأجزاء الأكثر أهمية في بيانات الإدخال. تشبه هذه الآلية الطريقة التي ينتبه بها الإنسان إلى الكلمات المفتاحية في الجملة أثناء القراءة، متجاهلًا التفاصيل الأقل صلة [4].
أما الاهتمام فائق السرعة، فيعيد التفكير في الطريقة التي تُنفَّذ بها حسابات الاهتمام على وحدات معالجة الرسومات. فهو يوظّف تقنيات متقدمة لإدارة الذاكرة تتيح تنفيذ العمليات الحسابية نفسها بشكل أسرع بكثير مع استهلاك أقل للذاكرة، وعلى وجه التحديد، يقوم بتنظيم حركة البيانات بذكاء بين مستويات الذاكرة المختلفة داخل وحدة المعالجة الرسومية لتحقيق أعلى كفاءة ممكنة [4].
تقسيم البيانات إلى أجزاء صغيرة (Tiling) وتقسيم المصفوفات
- مصفوفات الاهتمام Q,K,V تُقسَّم إلى كتل أصغر تُحمَّل كل واحدة إلى الذاكرة الداخلية السريعة (on-chip SRAM).
- يُحسب الاهتمام داخل كل كتلة جزئيًا، ثم تُجمع النتائج لاحقًا.
- بهذه الطريقة، لا نحتاج لتخزين مصفوفة الاهتمام الكاملة (التي حجمهاN×N) في الذاكرة البطيئة HBM [1].

الشكل (4): خوارزميّة الاهتمام فائق السرعة
الشكل (4) [1] تمثيل مرئي لآلية عمل خوارزمية الاهتمام فائق السرعة، حيث تُقسَّم المصفوفات إلى كتل تُعالَج تدريجيًا على الذاكرة الداخلية لتقليل الوصول إلى الذاكرة الخارجية، وتحقيق توازن بين الأداء واستهلاك الذاكرة.
إعادة الحساب بدل التخزين (Recomputation)
في الوضع العادي، الخوارزميات كانت تخزن نتائج وسيطة كثيرة (مثل مصفوفة سوفت ماكس الكاملة)، والذي كان يشاهد كشكل من أشكال نقاط تحقّق التّدرّج (Gradient Checkpointing)، لكن خوارزمية الاهتمام فائق السرعة تحفظ فقط بعض القيم الصغيرة المهمة، ثم تعيد حساب ما تحتاجه لاحقاً عندما يأتي وقت الانتشار الخلفي (backward pass)[1].
التنفيذ خطوة بخطوة
الخوارزمية تتبع ترتيب معين لكل كتلة سنذكرها بشكل مبسط [1]:
- تحميل جزء من Q وK وV من الذاكرة السريعة.
- حساب الضرب QK^T للكتلة فقط.
- تطبيق تابع سوفت ماكس على هذه الكتلة.
- ضرب الناتج في V للحصول على ناتج الاهتمام الجزئي.
- دمج النتائج مع ما سبق ثم الانتقال إلى الكتلة التالية.
متى ينبغي التفكير في استخدام تقنية الاهتمام فائق السرعة
يُوصى باستخدام آلية الاهتمام فائق السرعة في الحالات التي تتطلب كفاءة عالية في استخدام الذاكرة وتسريع عمليات التدريب أو الاستدلال، خصوصًا في النماذج المعتمدة على آليات الاهتمام مثل المحوّلات [4].
يمكن أن يكون هذا الخيار مناسبًا بشكل خاص في السيناريوهات التالية [4]:
- عند العمل مع نماذج لغوية كبيرة أو أي أنظمة ذكاء اصطناعي تعتمد على بنية المحولات، وتحتاج إلى تحسين زمن التدريب أو الاستدلال.
- عندما تتعامل مع تسلسلات إدخال طويلة جدًا (تصل إلى آلاف أو حتى عشرات الآلاف من الوحدةٌ لفظيَّةٌ (tokens)).
- في البيئات التي تكون فيها ذاكرة وحدة معالجة الرسومات هي العامل المقيِّد للأداء.
باستخدام هذه التقنية في مثل هذه الحالات، يمكنك تحقيق مجموعة من الفوائد المهمة، من أبرزها [4]:
- تسريع عمليات التدريب والاستدلال بشكل ملحوظ.
- إمكانية معالجة تسلسلات أطول دون مواجهة مشكلة نفاد الذاكرة.
- زيادة حجم النموذج أو حجم الدفعات (Batch Size) ضمن نفس حدود الذاكرة المتاحة.
تطور آلية الاهتمام فائق السرعة: من الإصدار الأول إلى الجيل الثالث
شهدت آلية الاهتمام فائق السرعة عدة إصدارات متتالية، كل منها قدّم تحسينات ملحوظة في الأداء وكفاءة الذاكرة[4].
فبعد الإصدار الأول الذي أُطلق عام 2022 [1]، جاء الإصدار الثاني في مطلع عام 2023 [6] ليقدّم تحسينات جوهرية في أنماط الوصول إلى الذاكرة ودعم الاهتمام السببي (Causal Attention)، مما أدى إلى تحقيق تسريع يصل إلى ضعفي أداء الإصدار السابق[4].
أما الإصدار الثالث، وهو الأحدث حتى الآن [7]، فقد صُمم خصيصًا للاستفادة من بنية وحدات معالجة الرسومات Hopper من شركة NVIDIA (مثل سلسلة H100)، حيث يقدّم تحسينات متقدمة في استغلال موارد المعالجة [4].
يستفيد هذا الإصدار من تقنيات متطورة لإدارة الذاكرة وزيادة كفاءة استخدام وحدات المعالجة الرسومية، مما يتيح أداءً أعلى واستفادة قصوى من قدرات العتاد المتاح [4].
استخدام تقنية الاهتمام فائق السرعة
تُعد أبسط طريقة للاستفادة من تقنية الاهتمام فائق السرعة هي استخدام إطار عمل (framework) تدريبي (training) أو استدلالي (inference) يدعمها بشكل مدمج مسبقًا، دون الحاجة إلى إعدادات معقدة أو تعديلات يدوية [4].
فيما يلي نظرة على أبرز الأطر الشائعة وحالة تكاملها مع تقنية الاهتمام فائق السرعة:
بايتورش (PyTorch)
يقدّم بايتورش دعمًا مدمجًا لتقنية الاهتمام فائق السرعة بدءًا من الإصدار 2.2 [8]، مما يتيح للمطورين استخدامها مباشرة ضمن النماذج دون الحاجة إلى مكتبات خارجية [4].
ولتمكين الاهتمام فائق السرعة في بايتورش، يمكن ببساطة تحديده كآلية الاهتمام الافتراضية في الواجهة الخلفية الاهتمام بالضرب النقطي المقيَّس (Scaled Dot-Product Attention backend)، ليتم استخدامه أثناء التدريب أو الاستدلال تلقائيًا لتحسين الأداء وكفاءة الذاكرة [4].
محولات Hugging Face
تدعم مكتبة Transformers من Hugging Face تقنية الاهتمام فائق السرعة في عدد من النماذج المختارة. ويمكن تفعيلها بسهولة أثناء تهيئة النموذج [4] من خلال تمرير المعلمة:attn_implementation=”flash_attention_2″ [9].
vLLM
يستفيد إطار vLLM افتراضيًا من تقنية ” الاهتمام الفائق السرعة 2″ ابتداءً من الإصدار 0.1.4، مما يعني أنه لا يتطلب أي تفعيل يدوي أو إعداد إضافي من جانب المستخدم [4].
تم دمج هذه التقنية بشكل مباشر في بنية vLLM لضمان تحقيق أقصى أداء ممكن في عمليات الاستدلال، مع تحسين كفاءة الذاكرة وتقليل زمن الاستجابة أثناء التعامل مع النماذج الكبيرة [4].
استدلال توليد النص (TGI)
يُفعَّل الاهتمام فائق السرعة افتراضيًا في نظام ((TGI (Text Generation Inference)، مما يتيح الاستفادة من مزاياه دون الحاجة إلى إعدادات إضافية [4].
ومع ذلك، قد يختلف مستوى استخدامه بحسب النموذج المستخدم، حتى في حال تجميع النماذج مسبقًا [4].
يهدف النظام إلى تطبيق الاهتمام فائق السرعة تلقائيًا متى ما كان ذلك ممكنًا، نظرًا لفوائده الكبيرة في تسريع عمليات الاستدلال وتحسين كفاءة الذاكرة، لكنه يعود إلى أساليب بديلة في حال مواجهة أي مشكلات في التوافق أو الأداء أثناء التنفيذ [4].
التطبيق المستقل لتقنية الاهتمام فائق السرعة
على الرغم من أن العديد من الأطر الحديثة تتضمن دعمًا مدمجًا لتقنية الاهتمام فائق السرعة أو لعمليات تحسين مماثلة، يمكن أيضًا تثبيت المكتبة بشكل مستقل عند الحاجة إلى تخصيص الإعداد أو استخدامها خارج هذه الأطر [4].
يمكن تثبيتها بسهولة باستخدام مدير الحزم pip:
pip install flash-attn
كما يمكن استنساخ المستودع (Repository) وتثبيت المكتبة من الشيفرة المصدرية مباشرة [10].
قبل التثبيت، يجب التأكد من توفر المتطلبات التالية: [4]
- PyTorch: يجب أن تكون النسخة 1.12 أو أحدث.
- CUDA Toolkit: ضروري لدعم وحدات وحدة معالجة الرسومات، ويجب أن تكون النسخة متوافقة مع إصدار PyTorch المستخدم.
- NVIDIA cuDNN: يُوصى بتثبيته لتحقيق أداء محسن على وحدات معالجة الرسومات من NVIDIA [11].
للحصول على مثال عملي يوضح كيفية تشغيل نموذج من Transformers باستخدام Flash Attention 3 على بيئة سحابية (Cloud Compute)، فيمكن الرجوع إلى دليل Flux التعليمي [12].
التقييم: نماذج لغوية أفضل مع أطوال تسلسلية أطول
تمتدريب نماذج GPT-3 التي تحتوي على 1.3 مليار و2.7 مليار معلمة، باستخدام مجموعة بيانات The Pile بحجم 400 مليار وٍحدِة لفظية، تم إجراء التجارب مع أطوال سياق مختلفة بلغت 2K و8K [2].
وقد أظهرت النتائج أنه عبر جميع المقاييس الرئيسية بما في ذلك التحقق من الحيرة (Validation Perplexity) ومؤشرات الأداء النهائي مثل الدقة على مجموعة بيانات ChapterBreak Challenge ، تفوقت النماذج ذات السياق الأطول على نظيراتها ذات السياق الأقصر [2].
جدول (1): مقارنة أداء نماذج GPT-3 باستخدام مقياس الحيرة (Perplexity)
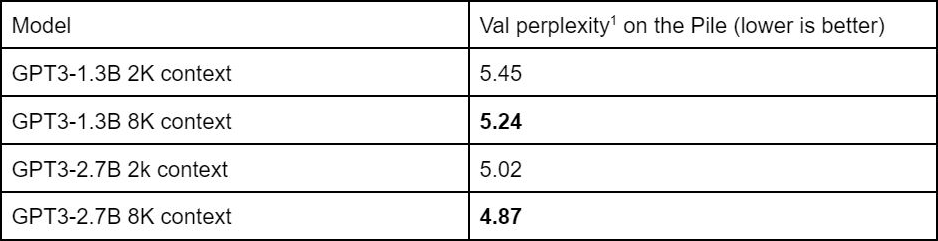
تم تقييم هذه النماذج باستخدام مجموعة بيانات ChapterBreak، وهي مجموعة تحدٍ مخصصة لتقييم النماذج اللغوية ذات النافذة الكبيرة (long-range)، حيث يُطلب من النموذج تمييز النص الصحيح الذي يلي فاصل الفصل ضمن تسلسل سردي. وقد أظهرت النتائج أنه مع زيادة طول السياق، تحسّنت دقة النماذج بشكل ملحوظ، مما يشير إلى أن النماذج ذات السياق الأطول تمتلك قدرة أفضل على التقاط العلاقات طويلة المدى وفهم الترابط النصي عبر المقاطع المتتابعة [2].
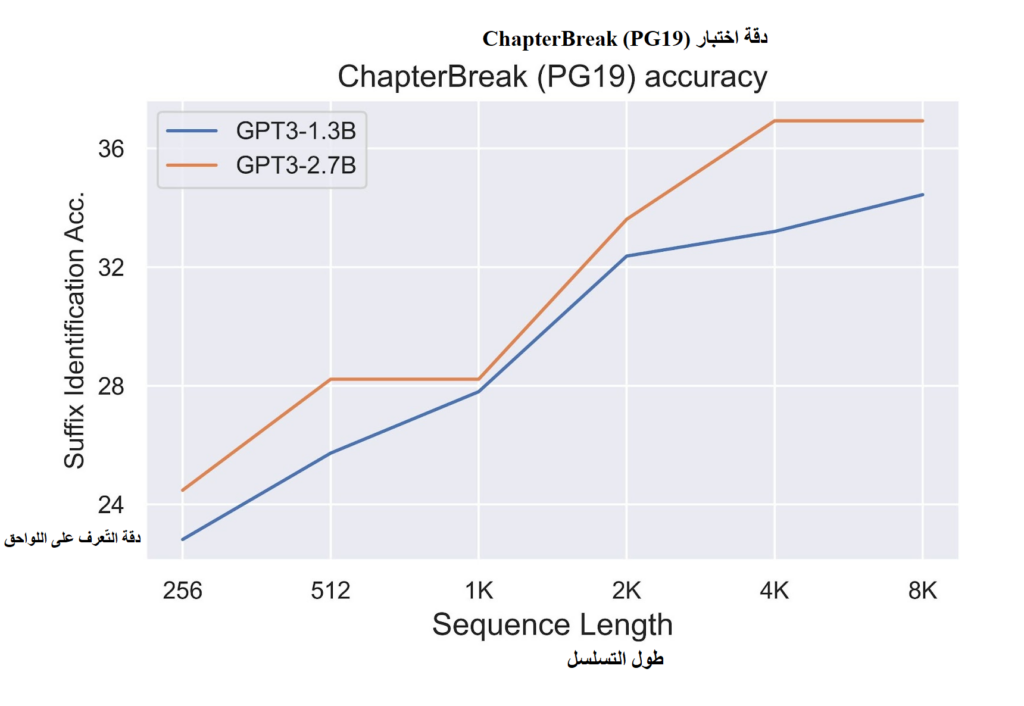
الشكل (5): تأثير طول التسلسل على دقة النموذج اللغوي
في كلتا الحالتين، أظهرت النتائج كما في الشكل (5) أن زيادة طول السياق إلى ما يتجاوز الحد القياسي البالغ 2K تؤدي إلى تحسين مستمر وثابت في جودة النموذج عبر مختلف المقاييس المستخدمة في التقييم [2].
الخاتمة
طرحت الورقة خوارزمية الاهتمام فائق السرعة حيث تراعي الإدخال/الإخراج لتقليل عمليات القراءة/الكتابة بين الذاكرة عالية النطاق (HBM) وذاكرة الـ SRAM داخل وحدة معالجة الرسومات. وذلك باستخدام تقسيم البيانات إلى أجزاء صغيرة وإعادة الحساب، تقلل الخوارزمية من عدد الوصول إلى HBM مقارنة بطريقة الاهتمام التقليدية [1].
من الناحية النظرية، يظهر أن تقنية الاهتمام الفائق السرعة تحتاج إلى عدد أقل من عمليات الوصول إلى HBM، وتكون مثالية لمجموعة من أحجام SRAM. أمّا على الصعيد التطبيقي، تشير التجارب إلى أن استخدامها في تدريب نماذج المحوّلات يحقّق تسريعًا ملحوظًا مع الحفاظ على الدقة الكاملة. حيث أن الخوارزمية تمكّن النماذج من التعامل مع سياقات أطول، مما يحسّن الأداء في مهام مثل التصنيف طويل المدى ويحقّق قدرات كانت صعبة في السابق [1].
إن تقنية الاهتمام الفائق السرعة تمثل تطبيقًا سريعًا وفعالًا من حيث الذاكرة لآلية الاهتمام الذّاتي، مع المحافظة على الدقة والملاءمة مع خصائص الأجهزة [3].
تشير النتائج إلى أن تقنية الاهتمام فائق السرعة يقدّم تحسينًا كبيرًا في سرعة التنفيذ مقارنةً بالنهج التقليدي البسيط (naive attention)، ويكون هذا التحسن ملحوظًا بشكل خاص عند معالجة التسلسلات الطويلة على وحدات معالجة الرسومات من AMD [3].
المراجع
- arxiv.org/pdf/2205.14135
- FlashAttention: Fast Transformer training with long sequences
- Accelerating Large Language Models with Flash Attention on AMD GPUs
- https://modal.com/blog/flash-attention-article
- ELI5: FlashAttention. Medium
- FlashAttention-2
- FlashAttention-3
- High-Performance Transformers with Scaled Dot Product Attention (SDPA)
- GPU
- Run Flux fast on H100s with torch.compile | Modal Docs
- Run Flux fast on H100s with torch.compile | Modal Docs
- Using CUDA on Modal | Modal Docs




