
التدّقيق العلمي: د. م. حسن قزّاز، م. محمد سرميني
التدّقيق اللّغوي: هبة الله فلّاحة
المحتويات
المقدمة:
البيتكوين غالبًا ما توصف بأنّها عملة مشفّرة أو افتراضيّة أو رقميّة فهي نوع من الأموال الافتراضيّة مثل نسخة إلكترونيّة من النّقود، ومن الجيّد التنبّؤ بأسعار هذه العملات ممّا يعود بالفائدة على الاقتصاد و الاستثمار.
سنقوم بمقالتنا ببناء نموذج تعلّم عميق مُعتمد على الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى للتنبّؤ بأسعار البيتكوين على مدار 10 أيام بناءً على 30 من الأيّام السّابقة
بناء الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى LSTM:
ما هو نموذج الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى بالضّبط؟[5]
إنّه شكل من أشكال الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة Recurrent Neural Networks RNN القادرة على تعلّم التّبعيّات طويلة المدى، بطريقة مماثلة نستخدم فيها الخبرة السّابقة للإبلاغ عن النّتائج المستقبليّة، تستخدم نماذج الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى بوّابات التّحديث update gates وبوّابات النّسيان forget gates،
بواسطة بوابات النّسيان تستطيع الشبكة تذكّر ونسيان أجزاء من المعلومات التّاريخيّة بشكل منظّم للإبلاغ عن تنبّؤاتها.
والشّكل (1) يوضّح بنية الشّبكة LSTM.
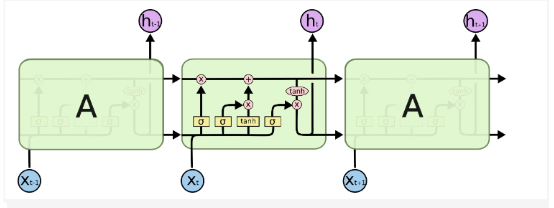
الشّكل (1) بنية الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى [4]
إنّ المقدرة على استخدام المعلومات التّاريخيّة “السّياق”، تتيح لهذه النّماذج أن تكون مناسبة بشكل خاصّ لأغراض التنبُّؤ.
ويتمّ استخدام RNNs وخاصة LSTM لأنّها أكثر ملاءمة من حيث بنيتها للبيانات المتسلسلة المسمّاة sequence data مثل بيانات أسعار البيتكوين التّاريخيّة.
للمزيد عن عمل الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى يمكنك قراءة المقال التّالي على المدوّنة
الشّبكة العصبونيَّة ذات الذَّاكرة الطَّويلة قصيرة المدى Long-Short Term Memory LSTM
ما هي الأدوات التي سنستخدمها في التّطبيق العملي[1][2]
في هذا التّطبيق سنستخدم مكتبة بايثون العدديَّة Numpy و مكتبة تحليل البيانات في بايثون (بانداس) Pandas للتّعامل مع البيانات، ومكتبة تنسور فلو للتَّعلُّم العميق من جوجل Keras / Tensorflow كيراس لوظائف التّعلّم الآليّ، و سنستخدم ورقة جوبيتر Jupyter Notebooks لتصحيح الأخطاء وقدرتها على تقديم الكود بشكل جيّد
جمع البيانات المطلوبة: [1][2]
من أجل تدريب نموذجنا نحتاج إلى بيانات التّدريب، ستكون أي بيانات تسعير ماليّ كافية هنا طالما أنّها متوفّرة في فترات زمنيّة قصيرة (مجال دقيقة واحدة) وذات حجم معقول، سنقوم بتحميل ملفّ CSV الذي يحتوي على بيانات أسعار Bitcoin التّاريخيّة، والتي مصدرها من Yahoo Finance.
لمزيد عن مصدر الشّيفرة البرمجيّة و البيانات يرجى الاطلاع على الرّابط التّالي :
أوّلًا نبدأ باستيراد جميع الحزم المطلوبة وتحميل مجموعة البيانات
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import Activation
from keras.models import load_model
df= pd.read_csv("BTC-USD.csv")
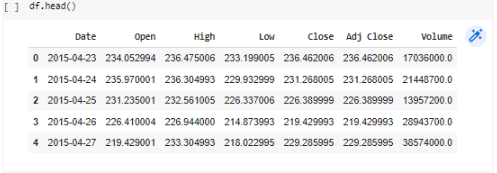
وفيما يلي شرح مختصر لأعمدة قاعدة البيانات المستخدمة و سنهتم فقط بعمود الDate, Close :
Date :التّاريخ اليوميّ.
Open : سعر الافتتاح ويتغيّر هذا السّعر صعودًا أو نزولًا أثناء اليوم.
High : أعلى سعر للبيتكوين سُجّل في ذلك اليوم
Low : أقلّ سعر سُجّل للبيتكوين في ذلك اليوم
Close السّعر الذي أغلق عنده البيتكوين و هو الذي سنتنبّأ به
Adj close(adjusted close ) : سعرالإغلاق المعدّل وآليّة حسابه موضّحة في الرّابط التّالي.
Volume : حجم التّداول.
ثانيًا : عمود التّاريخ Date تمّ تحويله ك مرجع index بدلًا من index الافتراضيّ الذي يبدأ من 0، ليصبح عندها ال index هو التّاريخ وهي خطوة مهمّة في time series
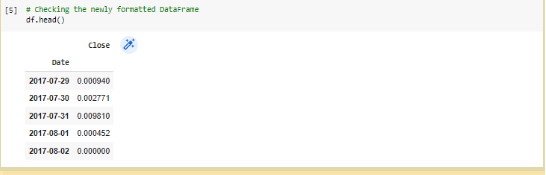
عمود Close أخذ آخر 1000 عنصر من عمود Close؛ و هو العمود الذي نريد التنبّؤ به و هو السّعر الذي سيغلق عنده سعر البيتكوين في اليوم
ليتشكّل لدينا سطر يحتوي تاريخ يوم ما وسعر الإغلاق في هذا اليوم، كما هو موضّح في الشّكل (3):
df = df.set_index("Date")[['Close']].tail(1000)
df = df.set_index(pd.to_datetime(df.index))
ثالثًا: من أجل تحسين الأداء، نقوم بتطبيق تقييس البيانات ضمن مجال واحد باستخدام تقييس الحدّ الأدنى/الحد الأعلى MinMaxScaler
scaler = MinMaxScaler()
df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns, index=df.index
رابعًا : سنستخدم بعض التّوابع المساعدة، والتي ستمكّننا من تدريب الشّبكة العصبيّة بشكل مناسب وفعّال.
تابع visualize_training_results :
يرسم هذا التّابع خسارة التّدريب/الاختبار لشبكتنا العصبيّة؛ حيث يتيح لنا ذلك التّحقّق من نتائج شبكتنا العصبيّة.
def visualize_training_results(results):
"""
Plots the loss for the training and testing data
"""
history = results.history
plt.figure(figsize=(12,4))
plt.plot(history['val_loss'])
plt.plot(history['loss'])
plt.legend(['val_loss', 'loss'])
plt.title('Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
تابع split_sequence :
ينشئ هذا التّابع مصفوفتين: X و y؛ وهي متغيّرات الإدخال والإخراج على التّوالي لشبكتنا العصبونيّة الإدخال هو عدد الفترات التي يجب الرّجوع إليها للماضي، والإخراج هو عدد الفترات المقبلة التي سنتنبّأ بها، ببساطة تُستخدم فترات الإدخال لمعرفة الأنماط والتّسلسلات التي تؤدّي إلى فترات الإخراج، يمكن أن يكون كلاهما أي رقم ولكن من المحتمل أن يكون مفيدًا إذا كان عدد فترات الإدخال أكبر من فترات الإخراج؛ مثلًا فترات الإدخال 30 أي سنرجع 30 يومًا و فترات الإخراج 10 أي سنتنبّأ ب بسعر البيتكوين لـ 10 أيّام قادمة.
[1][2][3]
def split_sequence(seq, n_steps_in, n_steps_out):
"""
Splits the univariate time sequence
"""
X, y = [], []
for i in range(len(seq)):
end = i + n_steps_in
out_end = end + n_steps_out
if out_end > len(seq):
break
seq_x, seq_y = seq[i:end], seq[end:out_end]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
تابع layer_maker :
ينشئ هذا التّابع عددًا محدّدًا من الطّبقات المخفيّة (و تعطيل عمل العُصبُونات بين كلّ طبقة من تلك الطّبقات المخفيّة dropout) لشبكتنا العصبيّة إذا لزم الأمر، و تشكّل هذه الوظيفة الجزء الأكبر من شبكتنا. سيتمّ شرح أهمّية هذه الوظيفة لاحقًا.
def layer_maker(n_layers, n_nodes, activation, drop=None, d_rate=.5):
"""
Create a specified number of hidden layers for an RNN
Optional: Adds regularization option, dropout layer to prevent potential overfitting if necessary
"""
# Creating the specified number of hidden layers with the specified number of nodes
for x in range(1,n_layers+1):
model.add(LSTM(n_nodes, activation=activation, return_sequences=True))
# Adds a Dropout layer after every Nth hidden layer (the 'drop' variable)
try:
if x % drop == 0:
model.add(Dropout(d_rate))
except:
pass
تحضير / تقسيم البيانات [1][2][3]
خطوتنا التّالية هي تنفيذ تابع split_sequence على بيانات أسعار البيتكوين الخاصّة بنا.
# كم عدد الفترات التي ننظر فيها إلى الوراء للتّدريب وهي 30 يومًا
n_per_in = 30
# كم عدد الفترات المقبلة للتنبّؤ وهي 10 أيام
n_per_out = 10
# الميزات (في هذه الحالة هو 1 لأنّ هناك ميزة واحدة فقط: السّعر)
n_features = 1
# تقسيم البيانات إلى تسلسلات مناسبة
X, y = split_sequence(list(df.Close), n_per_in, n_per_out)
# إعادة تشكيل المتغيّر X من ثنائيّ الأبعاد إلى ثلاثيّ الأبعاد
(عدد الأسطر، عدد الفترات، عدد الميزات )
X = X.reshape((X.shape[0], X.shape[1], n_features))
يمكن أن يكون عدد فترات الإدخال والإخراج بأي عدد من اختيارنا، ولكن من أجل هذا المثال سنختار الرّجوع إلى 30 يومًا من تاريخ الأسعار للتنبّؤ بالأيّام العشرة القادمة، ولكن هذا لا يعني أنّنا ننظر فقط إلى آخر 30 يومًا لمعرفة الأيّام العشرة القادمة لمدة 40 يومًا فقط، هذا يعني أنّ لكلّ يوم من الألف يومًا اخترناه، يتمّ استخدام الثّلاثين يومًا السّابقة لتحديد أيّ أنماط أو تسلسلات تؤدّي إلى الأيّام العشرة التّالية، تُستخدم هذه القيم لتدريب الشّبكة العصبونية حتى نتمكّن من التنبّؤ بالأيّام العشرة القادمة من أسعار البيتكوين اعتبارًا من اليوم.
بناء النّموذج: [1][2]
لتدريب نموذجنا نختار نوع النّموذج الذي نريد استخدامه وهو متسلسل sequential في حالتنا. بعد الكثير من التّجارب تُبيّن أنّ أفضل تابع تنشيط هو “softsign” أو “tanh”. ربّما يرجع هذا إلى حقيقة أنّ المجال الخاص بكلا التابعين يتراوح بين القيمة -1 إلى 1 وتعالج القيم السّالبة و الموجبة من المدخلات بشكل أفضل من توابع التنشيط التي تمتلك مجالاً يتراوح بين القيمة 0 والقيمة 1.
# Instantiating the model
model = Sequential()
# Activation
activ = "softsign"
# Input layer
model.add(LSTM(30, activation=activ, return_sequences=True, input_shape=(n_per_in, n_features)))
# Hidden layers
layer_maker(n_layers=6, n_nodes=12, activation=activ)
# Final Hidden layer
model.add(LSTM(10, activation=activ))
# Output layer
model.add(Dense(n_per_out))
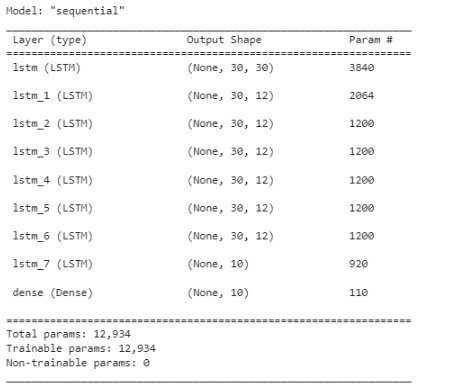
# Model summary
model.summary()
طبقة الإدخال
model.add(LSTM(30, activation=activ, return_sequences=True, input_shape=(n_per_in, n_features)))
ستكوّن الطّبقة الأولى في شبكتنا هي طبقة الإدخال، والتي يمكن إضافتها إلى الشّبكة ببساطة عن طريق استدعاء model.add() حيث يمكن تضمين ما يلي كبارامترات للتابع add:
- طبقة LSTM لإنشاء الطبقة الخاصّة بنا.
- عدد العقد (هنا يتمّ تعيينها على 30).
- التّنشيط هو تابع التّنشيط التي قمنا بتعيينه كمتغيّر من قبل.
- يتم إسناد القيمة True لreturn_sequence بحيث يحتوي كلّ تسلسل بين طبقات LSTM على الأبعاد المناسبة.
- يتمّ تعيين input_shape على أنّه عدد المدخلات والميزات، يتمّ ذلك حتّى تعرف الشّبكة الشّكل الذي تتوقّعه و تمّ تعينهم من قبل.
طبقات مخفيّة
بالنّسبة للعنصر التّالي يمكننا البدء في إنشاء طبقاتنا المخفيّة داخل الشّبكة العصبيّة، من أجل تجنّب كتابة model.add عدّة مرّات سوف نستخدم الدّالة layer_maker الخاصّة بنا، يؤدّي هذا إلى إنشاء حلقة “for” بسيطة بنطاق محدّد ينتج عنه العديد من الطّبقات كما نرغب، كما أنّ لديها خيار إضافة طبقات تعطيل عمل العُصبُونات Dropout بين كلّ طبقة من تلك الطّبقات المخفيّة، وهو أمر مهمّ للتّنظيم و طريقة لتجنّب المُلاءمة الزَّائدة Overfitting في شبكتنا العصبيّة.
بعد ذلك ننتهي من الطّبقات المخفيّة بطبقة مخفيّة واحدة أخيرة دون تعيين return_sequence إلى True، يتمّ ذلك بحيث يمكن للأبعاد من الطّبقة المخفيّة النّهائية أن تنتقل بسلاسة إلى طبقة الخرج بدون أخطاء.
layer_maker(n_layers=6, n_nodes=12, activation=activ)
طبقة الخرج وملخّص النّموذج
يوضح الشكل (4) البنية العامة للشبكة التي تم بناؤها مع ملاحظة أنّ طبقة الخرج ليست طبقة LSTM وإنما هي طبقة عاديّة تسمّى Dense layer، حيث تحتوي هذه الطّبقة على عدد الفترات / الأيام التي نرغب توقّع سعر البيتكوين فيها.
تجميع Compile و تدريب النّموذج [1][2]
قبل أن ننتقل إلى تدريب الشّبكة العصبونيّة الخاصّة بنا، يجب علينا تجميعها بالمواصفات المناسبة:
- المُحسِّنُ optimizer: هو خوارزميّة التّحسين التي نريد استخدامها لتدريب الشّبكة العصبونيّة.
- الخسارة loss: هي مقياس لحساب الخطأ الحاصل داخل النموذج المقترح، ونسعى أن تكون قريبة من القيمة صفّر.
تم استخدام تابع الخسارة loss function الخطأ التّربيعيّ المتوسّط mean-squared-error،المُحسِّنُ optimizer هو خوارزمية آدم Adam
model.compile(loss="mse", optimizer="adam")
model.fit(x, y, batch_size = 32, epochs = epochs)
تدريب النّموذج:[1][2]
يتم تدريب النموذج عن طريق استدعاء التابع fit() على النموذج الذي قمنا بإنشاءه. يأخذ هذا التابع البارامترات التالية:
- X ، y هي المتغيّرات التي قمنا بتعيينها والتي تحتوي على بيانات أسعار البيتكوين Bitcoin التّاريخيّة.
- دورة التدريب epochs هي عدد المرّات التي ستتدرّب فيها الشّبكة العصبونيّة على مجموعة البيانات بأكملها.
- حجم الدّفعة batch_size هو عدد العيّنات ضمن دورة تدريب epoch التي سيعمل النّموذج من خلالها قبل تحديث أوزان الشبكة.
- Validation_split هي النّسبة المئويّة لمجموعة البيانات الموضوعة جانبًا لتقييم الخسائر
res = model.fit(X, y, epochs=800, batch_size=32, validation_split=0.1)
يوضح الشكل (5) الخسارة الناتجة عند كل دورة تدريبية للنموذج المقترح.:
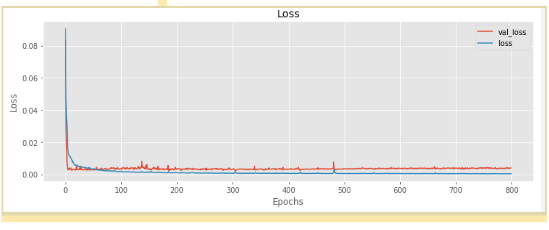
يبين الشّكل (5) الخسارة لكلّ من مجموعة التّدريب والتّحقّق من الصّحة، من أجل معرفة ما إذا كانت الشّبكة العصبونيّة الخاصّة بنا تتدرّب جيّدًا، سنرغب في رؤية كلّ من الخسارة لمجموعة التّحقّق من الصّحّة والتّدريب تتقاربان مع زيادة عدد دورات التّدريب؛ خلاف ذلك إذا تباعدت الخسارة والدّقّة عن بعضهما البعض فقد تكون هناك علامة على المُلاءمة الزَّائدة Overfitting من الشّبكة العصبونيّة، و يتمّ حلّ هذا من خلال إدخال بعض طبقات تعطيل عمل العُصبُونات Dropout، وتقليل عدد العصبونات، أو تغيير كمّيّة الطّبقات، أو تغيير مقدار التعلّم learning rate في خوارزمية آدم Adam وما إلى ذلك. قد تتطلّب هذه الخطوة عدّة محاولات وتجارب إضافيّة وضبطًا من أجل مراقبة تقارب مجموعة التّدريب والتّحقّق من الصّحّة.
التّحقّق من صحّة شبكتنا العصبيّة : [1][2]
بمجرد اكتمال التّدريب ونحن راضون عن كيفيّة تقارب الخسارة، سنحتاج إلى المضيّ قدمًا في اختبار نموذجنا مقابل البيانات الفعليّة لمعرفة مدى أدائه الجيّد. يمكننا القيام بذلك ببساطة عن طريق تصوّر أسعار البيتكوين المتوقّعة من الشّبكة العصبونيّة ورسمها بيانيًّا مع قيم البيتكوين الفعليّة.
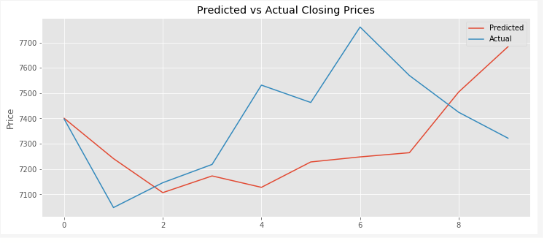
عندما يتعلّق الأمر بالتنبّؤ الدّقيق تماماً للسّعر فإنّ نموذجنا يفشل عدّة مرّات، على الرّغم من أنّ الاتّجاه بالصعود أو الهبوط ينجح نموذجنا في ذلك
والشكل 6 يوضّح مقارنة الأسعار الحقيقة و الأسعار المتوقعة خلال 10 أيام
التنبّؤ بالمستقبل: [1][2]
للتنبّؤ بالأيّام العشرة القادمة من أسعار البيتكوين، كلّ ما علينا فعله هو إدخال أسعار آخر 30 يومًا في التابع model.predict .
باستخدام الكود التّالي يمكننا طباعة الأسعار للأيّام العشرة القادمة، بالإضافة إلى رسم بيانيّ لتلك التّوقعات من أجل تفسير أفضل.
من أجل قيام النموذج بعملية التنبؤ سوف يتم إدخال بيانات 30 يوماً الأخيرة وتحويلها إلى الشكل التالي:
(1, n_per_in, n_features)
باستخدام reshape ومن ثم إسنادها ل yhat :
yhat = model.predict(np.array(df.tail(n_per_in)).reshape(1, n_per_in, n_features)).tolist()[0]
إعادة القيم المتوقعة yhat إلى أسعارها الأصلية بعد تطبيق تقييس البيانات ضمن مجال واحد باستخدام تقييس الحد الأدنى/الحد الأعلى MinMaxScaler
yhat = scaler.inverse_transform(np.array(yhat).reshape(-1,1)).tolist()
إنشاء داتا فريم DataFrame للقيم المتوقعة بطول ال yhat
preds = pd.DataFrame(yhat, index=pd.date_range(start=df.index[-1], periods=len(yhat), freq="D"), columns=df.columns
عدد الفترات التي سنعرضها لتصور القيم الفعلية
pers = 10
إعادة القيم الحقيقة actual إلى أسعارها الأصلية بعد تطبيق تقييس البيانات ضمن مجال واحد باستخدام تقييس الحد الأدنى/الحد الأعلى MinMaxScaler
actual = pd.DataFrame(scaler.inverse_transform(df[["Close"]].tail(pers)), index=df.Close.tail(pers).index, columns=df.columns).append(preds.head(1))
# Plotting
plt.figure(figsize=(16,6))
plt.plot(actual, label="Actual Prices")
plt.plot(preds, label="Predicted Prices")
plt.ylabel("Price")
plt.xlabel("Dates")
plt.title(f"Forecasting the next {len(yhat)} days")
plt.legend()
plt.savefig("BTC_predictions.png")
plt.show()
تصوّر نتائج التنبّؤ: [1][2]
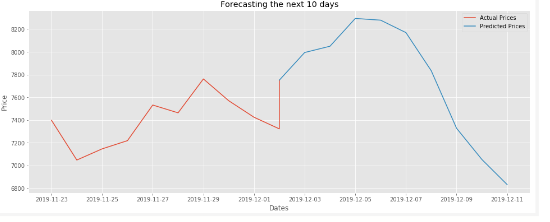
الشكل(7) يوضّح توقع النموذج المقترح لأسعار البتكوين لعشرة أيام قادمة اعتماداً على ثلاثين يوماً ماضية.
الخاتمة:
تعرّفنا في مقالنا على البيتكوين وعلى تدريب نموذج الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى و أهمّيتها وعلى كيفيّة التنبّؤ بسعر البيتكوين لمدة زمنيّة مقدارها عشرة أيام بالإعتماد على بيانات ثلاثين يوماً سابقة مثلاً
ومع ذلك هل هذه الأرقام دقيقة ٌ تماماً ؟ بالطبع لا! يمكن أن تعطينا الشّبكة العصبونيّة الاتّجاه العامّ الذي قد تتّجه إليه الأسعار في المستقبل، إذا فشلت الشبكة العصبونية في التوقع الحقيقي الدقيق للسعر فهو أمر متوقّع لأنّه لا يمكن لأيّ شخص أو آلة التنبّؤ بالمستقبل بشكل صحيح تماماً ، وربّما يكون استخدام الشّبكة العصبونيّة أفضل من التّخمين الأعمى.





تعليق واحد
السلام عليكم اختى نور .. بارك الله فى علمك ..س/ هل ممكن استعمال هذه التقنية على الاسهم فى البورصة وخاصا التداول بنظام (plus 0) وهو نظام شراء وبيع السهم فى نفس ذات الجلسة ؟ واذا كان ذلك كذلك فما هو افضل برومبت يمكن اعطاءه لل chat GPT اولا: ليدخل على احدى منصات التداول مثل تريدنج فيو او تيكرشارت ويقرأ التحرك اللحظى للسهم واختيار افضل سعر ووقت البيع وافضل وقت وسعر للبيع والتنفيذ آلى او يدوى ؟ واشكرك مقدما سواء رديتى او لم تردى.