التدّقيق العلمي: د. م. حسن قزّاز، م. محمد سرميني
التدّقيق اللّغوي: هبة الله فلّاحة
المحتويات
مقدّمة:
لطالما لاحظنا استجابة الهاتف المحمول لحركة الجسم أثناء اللّعب ببعض الألعاب على الهاتف، كما بإمكاننا أن نشاهد مقاطع الفيديو أو الصّور بكلّ الاتّجاهات وفقًا لحركة الجسم، ويعود ذلك بسبب تضمين الهواتف الذّكية للعديد من الحسّاسات المتطوّرة مثل حسّاسات التّسارع accelerometers وحسّاسات سرعة الزّاوية (الجيروسكوب) gyroscopes، وبالإضافة لدعم الألعاب المتطوّرة تُستخدم هذه القراءات في العديد من التّطبيقات الصّحيّة؛ كتطبيقات مراقبة الصّحّة واللّياقة البدنيّة وذلك من خلال التّعرّف على النّشاط البشرّي Human Activity Recognition عن طريق تحليل القراءات وتصنيفها لاكتشاف النّشاطات البشريّة باستخدام تقنيّات الذّكاء الاصطناعيّ، ممّا يفسح المجال أمام تطوير تقنيّات الواقع المعزّز والعديد من تطبيقات تشخيص الأمراض ومراقبة المسنّين والأطفال، في هذه المدوّنة سنتعرّف على تقنيّة التّعرّف على النّشاطات البشريّة وأجهزتها وخطواتها، بالإضافة إلى نموذج عن الخوارزميّات الهجينة بين شبكات الطيّ العصبونيّة CNN والإرجاعيّة RNN الذي أظهر أداءً فائقًا في العديد من التّطبيقات مع تطبيق عمليّ بسيط عنها.
التّعرّف على النّشاط البشريّ (HAR):
يعرّف بأنّه تحليل الأنشطة والحركات كالمشي والقفز وصعود الدّرج أو هبوطه وغيرها من الأنشطة البشريّة؛ وتصنيفها من خلال دراسة القراءات المتغيّرة لحسّاسات التّسارع والحركات الدّورانيّة واستخراج الميزات الخاصّة بكلّ حركة من خلال تقنيّات الذّكاء الاصطناعيّ، ويمكن من خلاله تطوير العديد من التّطبيقات المهمّة التي تستخدم على نطاق واسع في المجالات الطّبيّة كتشخيص الأمراض من خلال المشي، والمراقبة الحركيّة لكبار السّنّ ومرضى الزّهايمر ومراقبة سلوك الأطفال لتحديد أمراض التّوحّد والصّرع، وتطبيقات اللّياقة البدنيّة والنّشاطات الحركيّة، كما يتمّ من خلالها تطوير الألعاب التّفاعليّة وتطوير تقنيّات الواقع المعزّز ودمجها مع تقنيّات إنترنت الأشياء والمنازل الذّكيّة.
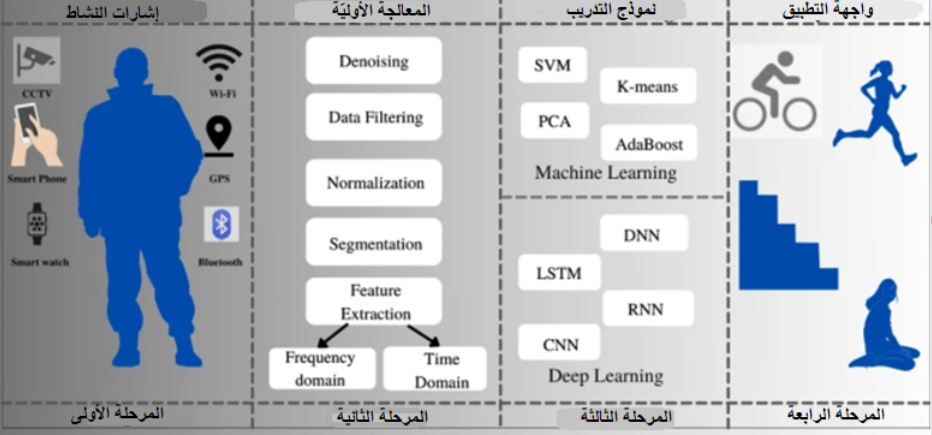
ويتمّ التّعرّف على النّشاط البشريّ HAR من خلال أربع مراحل موضّحة بالشّكل (1)؛ الأولى التقاط الإشارة النّاتجة عن النّشاط من خلال الأجهزة التي تناسب نوع التّطبيق الذي سيتمّ توظيفه للتّعرّف على النّشاط كالكاميرات أو الحسّاسات، ثمّ المرحلة الثّانية ويتمّ من خلالها المعالجة المسبقة للبيانات من أجل إزالة الضّجيج أو تحسين الصّورة، ثمّ التّعرّف على النّشاط من خلال نموذج الذّكاء الاصطناعيّ المطبّق باستخدام تقنيّات التّعلّم الآليّ ML أو التّعلّم العميق DL، وأخيرًا واجهة التّطبيق الذي يتمّ استخدامه لتطبيق النّموذج على البيانات الحقيقيّة والاستفادة منه بشكل فعليّ، كما قد يختلف أداء هذه النّماذج بين البيانات الحقيقيّة والمدروسة اعتمادًا على العوامل الماديّة مثل العمر واللّياقة البدنيّة وأسلوب أداء المهمّة، يكون نموذج HAR فعّالًا إذا كان أداؤه مستقلًّا عن العوامل الفيزيائيّة بحيث يكون أقلّ تأثيرًا على أداء النّموذج المدروس [1],[2].
الأجهزة المستخدمة للتّعرّف على النّشاط البشريّ (HAR):
يعتمد نوع الجهاز المستخدم في المرحلة الأوليّة لالتقاط الإشارات على طبيعة التّطبيق الذي يتطلّب التعرّف على النّشاط البشريّ من خلاله، وقد تكون هذه الأجهزة حسّاسات أو كاميرات أو أجهزة تعريف التّردّد اللّاسلكيّ RFID أو أجهزة WI-FI.
- الحسّاسات: يمكن تصنيف أنواع الحسّاسات إلى نوعين: حسّاسات قابلة للارتداء wearable sensors والحسّاسات الطّرفيّة device sensors في نمط الحسّاسات القابلة للارتداء، تمّ تصميم حسّاسات بحيث تتّصل مع جسم الإنسان لالتقاط إشارات محدّدة، وتتضمّن حسّاسات ذاتيّة الممانعة inertial sensors؛ وهي حسّاسات تقوم بقياس التّسارع و الزّاوية (الجيروسكوب) للجسم على طول المحاور الإحداثيّة المتعامدة، والتي يتمّ قياسها بناءً على القوانين الأساسيّة للحركة إلّا أنّ هذه الحسّاسات من الممكن أن تكون مزعجة أثناء الاستخدام؛ لذا يفضّل أن يتمّ الاعتماد على الحسّاسات المضمنّة في الهواتف الذّكيّة.
- الكاميرات: يمكن تصنيفها إلى نوعين أساسييّن: كاميرا ثلاثيّة الأبعاد 3D camera وكاميرا عميقة depth camera، حيث تعتمد دقّة التّعرّف على نشاط من خلال بيانات الكاميرا ثلاثيّة الأبعاد على عوامل ماديّة مثل الإضاءة ولون الخلفيّة، في حين تعتمد الكاميرات العميقة على تدفّقات بيانات مختلفة مثل عمق الصّورة depth والألوان الأساسيّة RGB والصّوت، حيث يعطي بارامتر العمق إحداثيّات مفاصل الجسم وبناءً على الإحداثيّات المشتركة يمكن تطوير نموذج HAR معتمدًا على حركة الهيكل العظميّ.
- أجهزة تعريف التّردّد اللّاسلكيّ RFID (القارئات والعلامات tags and readers): يمكن التقاط إشارات الإنسان من خلال وضع العلامات tags على مقربة من جسم الإنسان، ثمّ التقاط الإشارات من خلال قارئات readers أجهزة تعريف التّردّد اللّاسلكيّ [1].
قواعد البيانات الخاصّة بتطبيقات التّعرّف على النّشاط البشريّ (HAR):
في هذه الفقرة سوف نستعرّض أهمّ قواعد البيانات الخاصّة بتطبيقات التّعرّف على النّشاط البشريّ، كما يوضّح الفيديو التّالي آليّة تسجيل قراءات الحسّاسات لتخزينها في قاعدة البيانات.
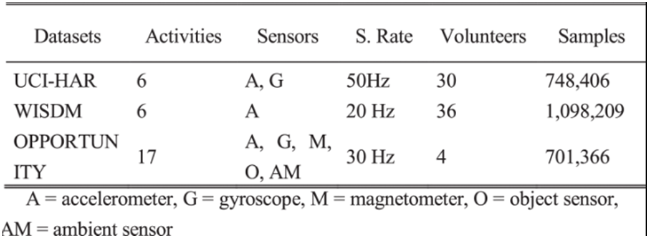
ويوضّح الجدول (1) مقارنة عامّة بين قواعد البيانات هذه من حيث عدد النّشاطات المدروسة وأنواع الحسّاسات المستخدمة (حسّاسات التّسارع، السّرعة الزّاويّة -الجيرسكوب-، حسّاسات الأغراض، والحسّاسات المحيطيّة)، وعدد العيّنات في كلّ منها وعدد المتطوّعين، كما سيتمّ شرح كلّ قاعدة منها بشكل مستقلّ.
الجدول (1): مقارنة بين قواعد البيانات المستخدمة في التّعرّف على النّشاط البشريّ.
UCI-HAR:
تمّ بناء قاعدة بيانات UCI-HAR من خلال تسجيل نشاطات لحوالي 30 شخصًا تتراوح أعمارهم بين 19 و 48 عامًا، باستخدام هواتف ذكيّة (Samsung Galaxy S II) مع حسّاسات ذاتيّة الممانعة المضمّنة متموضعة حول الخصر. إن الأنشطة السّتّة للحياة اليوميّة هي الوقوف (Stand up (Std، الاستلقاء (lay)، المشي (Walk)، نزول الدّرج (Down) وصعود الدّرج (Up)، كما تتضمّن التّغيّرات في الأنشطة التي تحدث بين النّشاطات الثّابتة: الوقوف إلى الجلوس، والجلوس إلى الوقوف، والجلوس إلى الاستلقاء، والاستلقاء إلى الجلوس، الوقوف إلى الاستلقاء والاستلقاء إلى الوقوف. في هذه المقالة تمّ اختيار ستّة أنشطة أساسيّة ولم تدرس الوضعيّات الانتقاليّة، عدد العيّنات في مجموعة البيانات هذه هو 748406، وتمّت عنونة هذه البيانات يدويًّا، وتمّ عرض المعلومات التّفصيليّة حول قاعدة البيانات هذه في الجدول (2) [4].
الجدول (2): معلومات تفصيليّة حول قاعدة البيانات UCI-HAR.
WISDM:
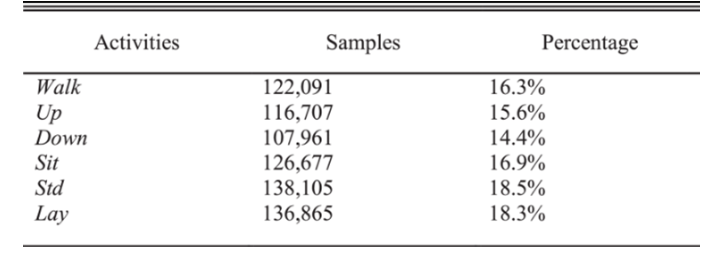
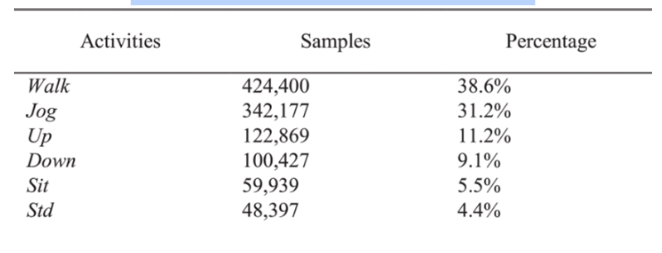
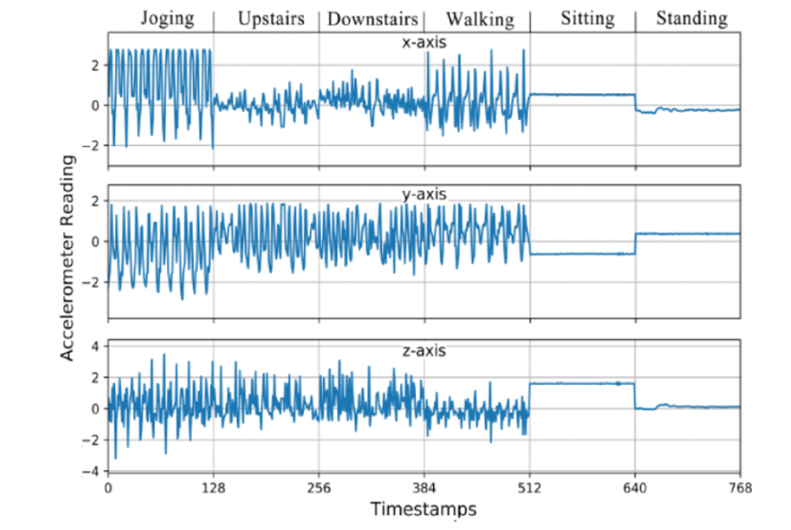
تحتوي مجموعة بيانات WISDM على حوالي 1098209 عيّنة، وتمّ عرض النّسبة المئويّة للعيّنات الكليّة المرتبطة بكلّ نشاط في الجدول (3). يمكن ملاحظة أنّ WISDM هي مجموعة بيانات غير متوازنة من حيث نسب العيّنات لكلّ نشاط، حيث يصل نشاط المشي إلى 38.6 ٪ بينما يمثّل الوقوف فقط 4.4 ٪، تمّ تسجيل النّشاطات لحوالي 36 متطوّعًا مزوّدين بهاتف Android في جيوب السّاق الأماميّة، الحسّاس المستخدم هو حسّاس التّسارع مع تردّد أخذ العيّنات يساوي 20 هرتز، تمّ تسجيل ستّة أنشطة: الوقوف (STD)، الجلوس (SIT)، المشي (Walk)، الطّابق العلويّ (Up)، الطّابق السّفليّ (Down)، والرّكض (Jog)، كما يوضّح الشّكل (2) الشّكل الموجيّ للتّسارع البالغ 2.56 ثانية (128 نقطة بشكل كلّيّ) من كلّ نشاط؛ بهدف تصوّر خصائص البيانات الأوّلية على كلّ محور[5].
الجدول (3): معلومات تفصيليّة حول قاعدة البيانات WISDM.
Opportunity:
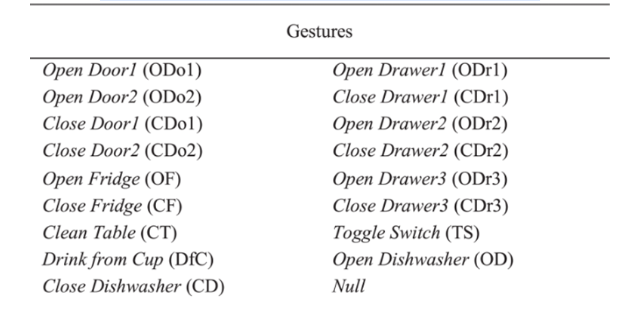
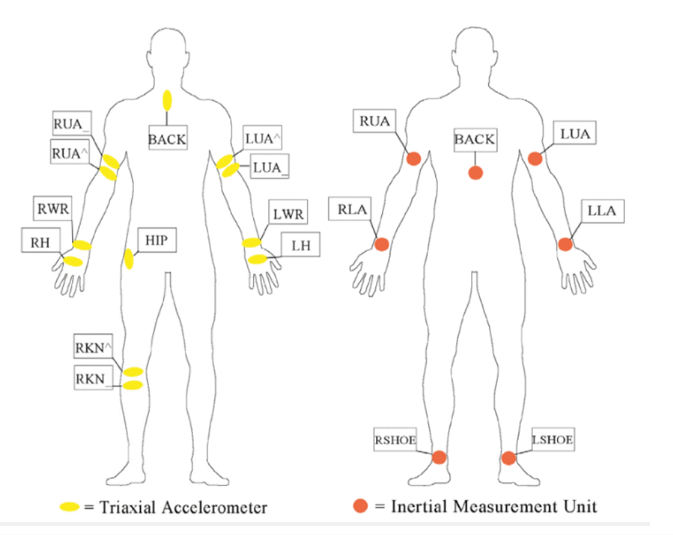
تمّ جمع بيانات قاعدة البيانات Opportunity في بيئة غنيّة بالحسّاسات، والتي تشمل 17 متطوّعًا يؤدّون نشاطات معقّدة وأنماط حركة مختلفة، تمّ الاعتماد على عدّة أنواع من الحسّاسات، ولكن تمّ التّركيز فقط على الحسّاسات المتعلّقة بجسم الإنسان، وتشمل خمسة حسّاسات ذاتيّة الممانعة inertial sensors، وحسّاسين من النّوع InertiaCube على القدمين _وهي تقنيّة MEMS لقياس معدّل الزّاوية للدّوران والجاذبيّة والمجال المغناطيسيّ الأرضيّ على طول ثلاثة محاور متعامدة_، 12 حسّاسًا تسارع ثلاثيّ الأبعاد مزوّد بتقنيّة بلوتوث Bluetooth. كما هو موضّح في الشّكل (3) تشير النّقاط البيضاويّة الصّفراء إلى حسّاسات التّسارع ثلاثيّة الأبعاد، والنّقاط المستديرة الحمراء تمثّل حسّاسات ذاتيّة الممانعة inertial ،sensors يعتبر كلّ محور حسّاس قناة منفصلة ممّا يؤدّي إلى حجم الدّخل 113 قناة. تمّ تلخيص الحركات المدرجة في مجموعة البيانات هذه في الجدول (4) وتشير الأحرف بين قوسين إلى رموز الحركات [2]، [6].
الجدول (4): معلومات تفصيليّة حول قاعدة البيانات Opportunity.
تطبيق عمليّ:
فيما يأتي تطبيق عمليّ للتّعرّف على النّشاط البشريّ باستخدام نموذج هجين يجمع بين شبكات الطّيّ العصبونيّة CNN والشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة RNN، وسيتمّ توضيح خطوات هذا التّطبيق في كلّ مرحلة مع الشّيفرات البرمجيّة والتّوابع الخاصّة بها:
المرحلة الأولى : استدعاء المكتبات الأساسيّة:
المرحلة الأولى هي استدعاء المكتبات الأساسيّة، حيث يتمّ استخدام مكتبات اس-كي للتّعلُّم Sklearn و تينسور فلو TensorFlow و كيراس Keras و مكتبة الحَوسَبة العلميَّة SciPy و مكتبة بايثون العدديَّة NumPy لبناء النّموذج وإجراء المعالجة المسبقة للبيانات، لتحميل البيانات نستخدم مكتبة تحليل البيانات في بايثون (بانداس) Pandas ولرسم البيانات يتمّ استخدام مكتبة الرَّسم الرِّياضيّ في بايثون (ماتبلوت) Matplotlib.
from pandas import read_csv, unique
import numpy as np
from scipy.interpolate import interp1d
from scipy.stats import mode
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from tensorflow import stack
from tensorflow.keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, GlobalAveragePooling1D, BatchNormalization, MaxPool1D, Reshape, Activation
from keras.layers import Conv1D, LSTM
from keras.callbacks import ModelCheckpoint, EarlyStopping
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
المرحلة الثّانية: هي مرحلة تحميل قاعدة البيانات:
سيتمّ التّعامل مع قاعدة البيانات WISDM والتي يمكن تحميلها من خلال الرّابط https://www.cis.fordham.edu/wisdm/dataset.php؛ حيث سيتمّ تحميل مجموعة البيانات الخاصّة في DataFrame، وسيتمّ إزالة “؛” من العمود الأخير وإجراء عمليّة تقريب للقيم الموجودة فيها [3].
def read_data(filepath):
df = read_csv(filepath, header=None, names=['user-id',
'activity',
'timestamp',
'X',
'Y',
'Z'])
## removing ';' from last column and converting it to float
df['Z'].replace(regex=True, inplace=True, to_replace=r';', value=r'')
df['Z'] = df['Z'].apply(convert_to_float)
# df.dropna(axis=0, how='any', inplace=True)
return df
def convert_to_float(x):
try:
return np.float64(x)
except:
return np.nan
df = read_data('Dataset/WISDM_ar_v1.1/WISDM_ar_v1.1_raw.txt')
df
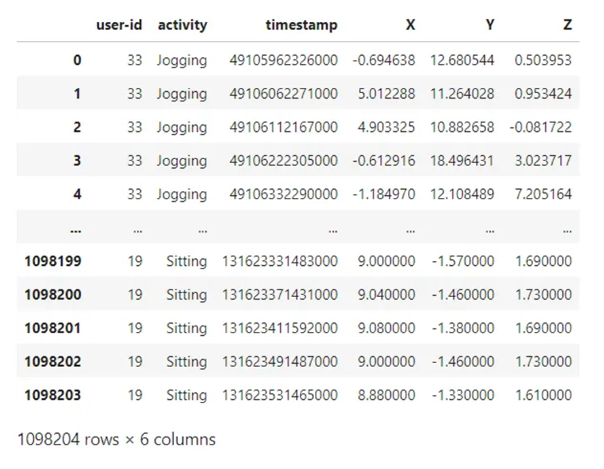
وباستعراض جزء من قاعدة البيانات المستخدمة نلاحظ معرّف أو رقم المستخدم، النّشاط، الخطوة الزّمنية أو الطّابع الزّمني، وقراءات الحسّاسات من أجل المحاور الثّلاثة على التّرتيب فنجد القيم التّالية، كما سيتمّ استعراض عدد الأسطر والأعمدة في قاعدة البيانات هذه.
ومن أجل رسم شكل يوضّح العدد الكلّيّ لكلّ نشاط ضمن قاعدة بيانات التّدريب WISDM نستخدم الشّيفرة البرمجيّة التّالية:
plt.figure(figsize=(15, 5))
plt.xlabel('Activity Type')
plt.ylabel('Training examples')
df['activity'].value_counts().plot(kind='bar',
title='Training examples by Activity Types')
plt.show()
plt.figure(figsize=(15, 5))
plt.xlabel('User')
plt.ylabel('Training examples')
df['user-id'].value_counts().plot(kind='bar',
title='Training examples by user')
plt.show()
والشّكل (4) يوضّح العدد الخاصّ بكلّ نوع من أنواع الأنشطة الموجودة ضمن قاعدة البيانات WISDM:
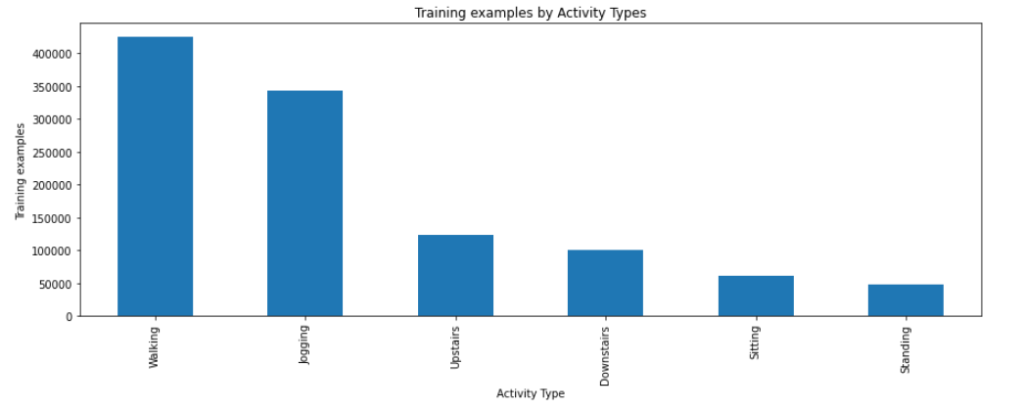
الشّكل (4) يوضّح العدد الخاصّ بكلّ نوع من أنواع الأنشطة الموجودة ضمن قاعدة البيانات WISDM.
المرحلة الثّالثة: هي معالجة البيانات
تعدّ المعالجة المسبقة للبيانات مهمّة للغاية في إعداد البيانات الأوّلية لتحليل النّموذج بسهولة أكبر، ولتغذية النّموذج المقترح بأبعاد بيانات مناسبة يجب معالجة البيانات الأوّلية التي تمّ جمعها بواسطة حسّاسات الحركة مسبقًا على النّحو التّالي، طرق معالجة البيانات التي سنستخدمها هي:
- ترميز العنونة Label Encoding
- الاستيفاء الخطّيّ Linear Interpolation
- تقسيم البيانات Data Split
- التّقييس Normalization
- تجزئة Segmentation
- ترميز ون هوت One-Hot Encoding
أوّلًا: ترميز العنونة Label Encoding
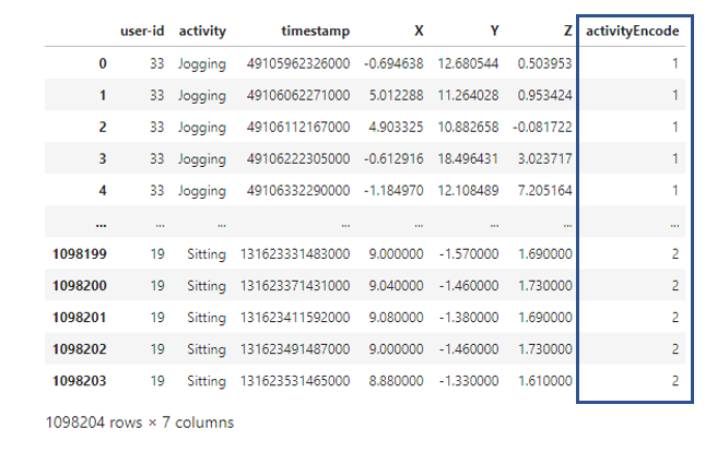
النّموذج لا يمكن أن يأخذ عناوين غير رقميّة كمداخل، عندها ستضاف عناوين مرمّزة في خانة “activity” وذلك في عمود آخر ونطلق عليه “activityEncode”، حيث يكون التّرميز على النّحو التّالي:
- Downstairs [0]
- Jogging [1]
- Sitting [2]
- Standing [3]
- Upstairs [4]
- Walking [5]
والشّيفرة البرمجيّة التّالي من أجل تنفيذ عمليّة ترميز العنونة:
label_encode = LabelEncoder()
df['activityEncode'] = label_encode.fit_transform(df['activity'].values.ravel())
df
وباستعراض جزء من قاعدة البيانات بعد إجراء عمليّة ترميز العنونة، نلاحظ إضافة العمود الأخير على النّحو التّالي:
ثانيًا: : مرحلة الاستيفاء الخطّيّ Linear Interpolation
مجموعات البيانات المستخدمة هي مجموعة بيانات حقيقيّة، والحسّاسات التي يتمّ قياس الإشارة منها هي حسّاسات لاسلكيّة، لذلك ممكن أن يحدث ضياعًا وقد تُفقد بعض البيانات أثناء عمليّة التّجميع، وعادة ما يشار إلى البيانات المفقودة بـ NaN / 0 لذلك تمّ استخدام خوارزميّة الاستيفاء الخطّيّ لملء القيم المفقودة، ويتمّ ذلك من خلال الكود التّالي:
interpolation_fn = interp1d(df['activityEncode'] ,df['Z'], kind='linear')
interpolation_fn
null_list = df[df['Z'].isnull()].index.tolist()
null_list
for i in null_list:
y = df['activityEncode'][i]
value = interpolation_fn(y)
df['Z']=df['Z'].fillna(value)
print(value)
ثالثًا: تقسيم وتقييس البيانات Data Split and Normalization
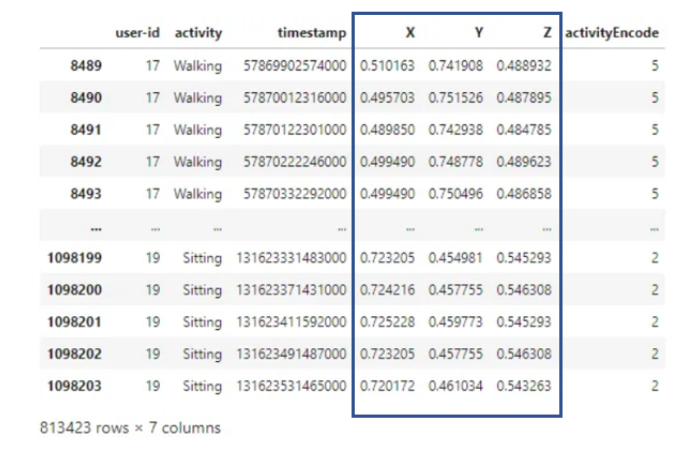
يتمّ تقسيم البيانات وفقًا لأرقام التّعريف الخاصّة بالمستخدمين لتجنّب تقسيم البيانات الخاطئ، يتمّ اختيار أرقام تعريف المستخدمين أقلّ من أو تساوي 27 من أجل مجموعة التّدريب والباقي من أجل مجموعة الاختبار، وقد يؤدّي استخدام القيم الكبيرة من القنوات مباشرة لتدريب النّماذج إلى انحياز التّدريب، لذلك من الضّروري تحجيم بيانات الإدخال إلى النّطاق من 0 إلى 1 وذلك من خلال التّعليمات التّالية:
df_test = df[df['user-id'] > 27]
df_train = df[df['user-id'] <= 27]
df_train['X'] = (df_train['X']-df_train['X'].min())/(df_train['X'].max()-df_train['X'].min())
df_train['Y'] = (df_train['Y']-df_train['Y'].min())/(df_train['Y'].max()-df_train['Y'].min())
df_train['Z'] = (df_train['Z']-df_train['Z'].min())/(df_train['Z'].max()-df_train['Z'].min())
df_train
رابعًا: مرحلة التّجزئة Segmentation:
مدخل النّموذج هو عبارة عن سلسلة بيانات زمنيّة قصيرة مستخرجة من بيانات الحسّاسات، أثناء عمليّة تجميع قاعدة البيانات يتمّ تسجيل البيانات بشكل مستمرّ من أجل الحفاظ على العلاقة الزّمنيّة بين نقاط البيانات في النّشاط، ولذلك يتمّ استخدام نافذة منزلقة sliding window بمعدّل تداخل overlap rat بنسبة 50٪ لتقسيم البيانات التي تمّ جمعها بواسطة حسّاسات الحركة، بالنّسبة لمجموعة بيانات WISDM و UCI-HAR يبلغ طول النّافذة المنزلقة 128، أمّا بالنّسبة لمجموعة بيانات OPPORTUNITY يستمرّ تسجيل كلّ نشاط لفترة قصيرة، ويوضّح الشّكل (4) عمليّة التّجزئة.
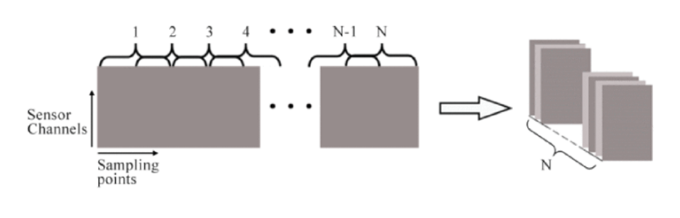
وهنا سيتمّ إنشاء تابع التّجزئة من أجل إعادة تشكيل البيانات بما يتناسب مع دخل النّموذج كما سيتمّ فصل الميزات (تسارع X، تسارع Y، تسارع Z) والعناوين في المجموعتين هما x_train و y_train على التّوالي وفقًا للتّعليمات التّالية:
def segments(df, time_steps, step, label_name):
N_FEATURES = 3
segments = []
labels = []
for i in range(0, len(df) - time_steps, step):
xs = df['X'].values[i:i+time_steps]
ys = df['Y'].values[i:i+time_steps]
zs = df['Z'].values[i:i+time_steps]
label = mode(df[label_name][i:i+time_steps])[0][0]
segments.append([xs, ys, zs])
labels.append(label)
reshaped_segments = np.asarray(segments, dtype=np.float32).reshape(-1, time_steps, N_FEATURES)
labels = np.asarray(labels)
return reshaped_segments, labels
TIME_PERIOD = 80
STEP_DISTANCE = 40
LABEL = 'activityEncode'
x_train, y_train = segments(df_train, TIME_PERIOD, STEP_DISTANCE, LABEL)
print('x_train shape:', x_train.shape)
print('Training samples:', x_train.shape[0])
print('y_train shape:', y_train.shape)
x_train shape: (20334, 80, 3)
Training samples: 20334
y_train shape: (20334,)
خامسًا: ترميز ون هوت One-Hot Encoding:
يعدّ One Hot Encoding طريقة شائعة للمعالجة المسبقة للمميّزات التي تكون على شكل فئات لنماذج التّعلّم الآليّ، يُنشئ هذا النّوع من التّرميز ميزة ثنائيّة جديدة لكلّ فئة محتملة ويعيّن قيمة 1 لميزة كلّ عيّنة تتوافق مع فئتها الأصليّة، من السّهل فهمه في المثال الموضّح بالشكل (5) حيث نقوم بتشفير One Hot لميزة لونيّة تتكوّن من ثلاث فئات (أحمر وأخضر وأزرق).
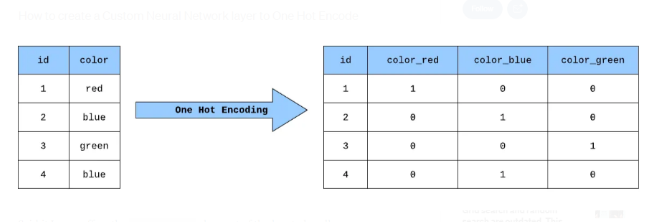
وبنفس الآلية نقوم بترميز عناوين قاعدة البيانات وتكون هذه هي الخطوة الأخيرة في المعالجة المسبقة للبيانات ثم يتم تخزينها في y_train_hot و تطبيقها على دخل النموذج.
y_train_hot = to_categorical(y_train, num_classes)
print("y_train shape: ", y_train_hot.shape)
المرحلة الرّابعة: النّموذج المقترح:
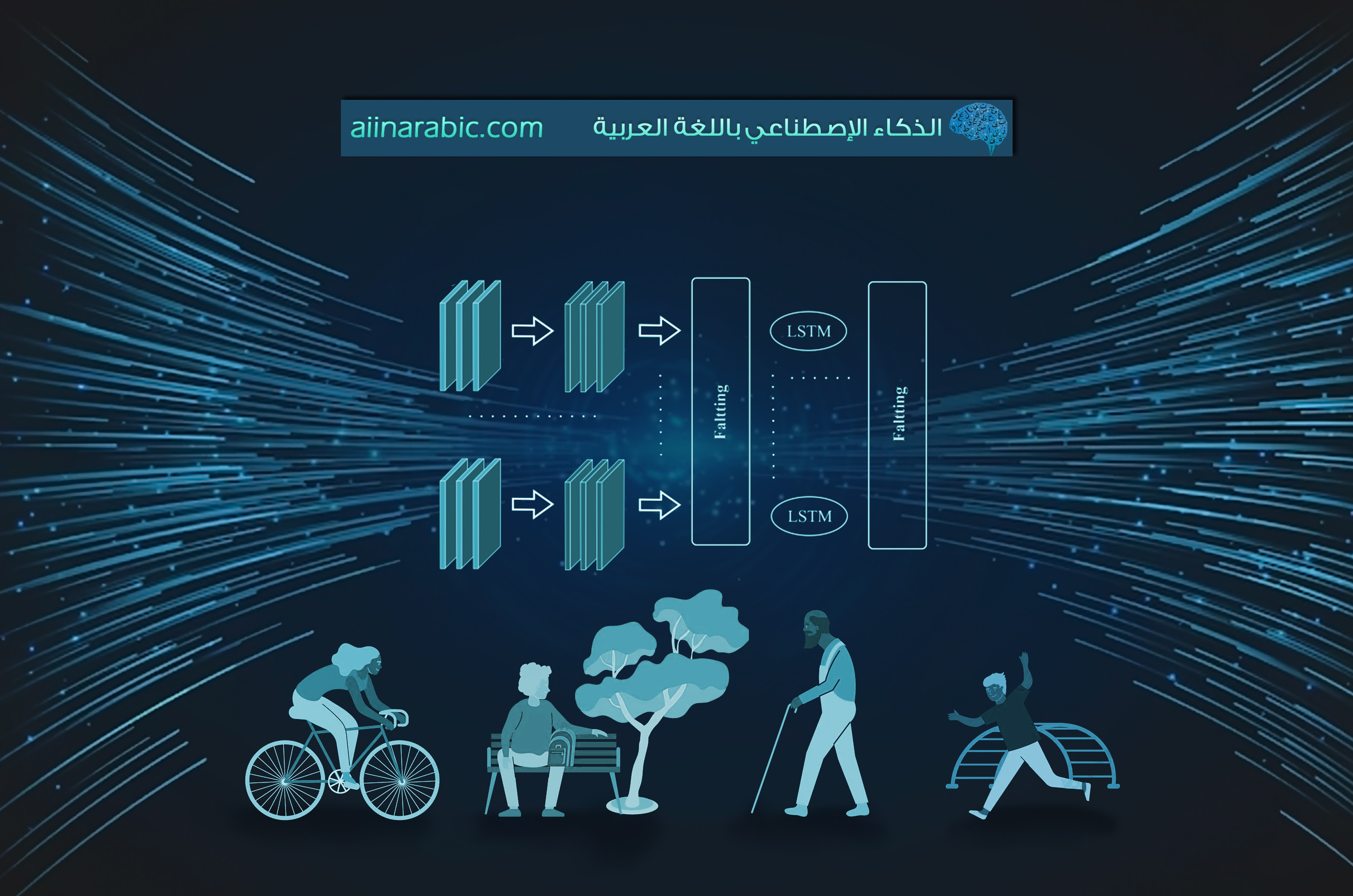
نستعرض نموذجًا مقترحًا في ورقة بحثيّة [2]؛ وهو نموذج هجين بين شبكات الطيّ العصبونيّة CNN والشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة RNN، ويوضّح الشّكل (6) البنية العامّة لها حيث تتألّف من ثماني طبقات، أوّلًا يتمّ إدخال البيانات التي تمّت معالجتها إلى الدّخل المكوّن من طبقتين من الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى (Long Shot Term Memory (LSTM، كلّ طبقة منها تتألّف من 64 خليّة عصبونيّة. والتي يتمّ من خلالها استخراج المميّزات الزّمنيّة، تليها طبقتين من طّبقات الطّيّ العصبونيّة، ويتمّ استخدامها لاستخراج المميّزات المكانيّة. تحتوي طّبقة الطّيّ الأولى على 64 مرشحًا بينما تحتوي الطّبقة الأخرى على 128 مرشحًا، كما يوجد بينهما طبقة التّجميع وفق القيمة الكبرى max-pooling layer. في نهاية النّموذج توجد طبقة التّجميع وفق القيمة المتوسّطة العامّة global average pooling layer (GAP) متبوعة بطبقة تقييس الدّفعة Batch Normalization، وأخيرًا يتمّ الحصول على خرج النّموذج عن طريق طبقة الخرج.
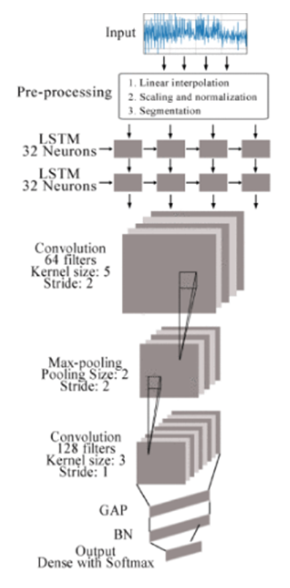
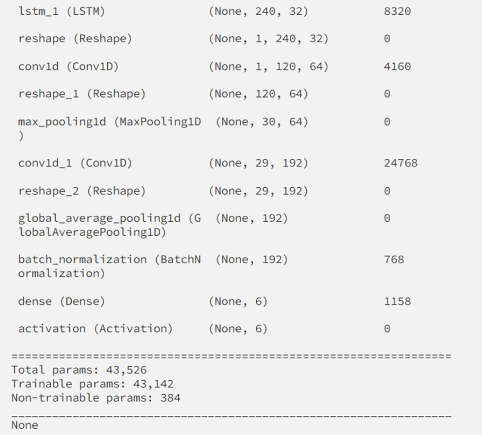
نقوم باستخدام الشّيفرة البرمجيّة التّالية لبناء النّموذج حيث يتمّ إضافة طبقتين من الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى LSTM، ثمّ ثلاث طبقات طيّ عصبونيّة مع ضبط بارامتراتهم الأساسيّة من خلال الشّيفرة البرمجيّة لكلّ طبقة:
model = Sequential()
model.add(LSTM(32, return_sequences=True, input_shape=(input_shape,1), activation='relu'))
model.add(LSTM(32,return_sequences=True, activation='relu'))
model.add(Reshape((1, 240, 32)))
model.add(Conv1D(filters=64,kernel_size=2, activation='relu', strides=2))
model.add(Reshape((120, 64)))
model.add(MaxPool1D(pool_size=4, padding='same'))
model.add(Conv1D(filters=192, kernel_size=2, activation='relu', strides=1))
model.add(Reshape((29, 192)))
model.add(GlobalAveragePooling1D())
model.add(BatchNormalization(epsilon=1e-06))
model.add(Dense(6))
model.add(Activation('softmax'))
print(model.summary())
المرحلة الخامسة: مرحلة التّدريب
يتمّ تجميع الشّبكة من خلال إضافة تابع compile حيث يحدّد قيمة الضّياع والمُحسّن والمقاييس، ولا علاقة له بالأوزان ويمكنك تجميع نموذج عدّة مرّات كما تريد دون التّسبب في أيّ مشكلة في الأوزان الجاهزة، كما يتمّ اختيار محسّن من نوع adam وهو المحسّن الأمثليّ من أجل حالات التّصنيف، فيتمّ تدريب الشّبكة العصبونيّة المتشكّلة على 100 مرحلة تدريب في كلّ مرحلة يكون حجم العينات المتدربة حوالي 192 عيّنة وأثناء التّدريب يتمّ عرض زمن تدريب كلّ دفعة ونسبة accuracy ومقدار الضّياع بعد مرحلة التّدريب يعطي النّموذج دقّة بمقدار 98.02 ٪ وخسارة بمقدار 0.58٪، كما هو موضّح.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train,
y_train_hot,
batch_size= 192,
epochs=100
)
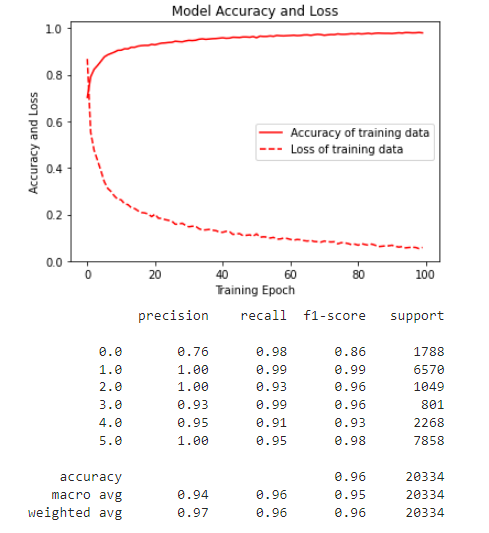
وبرسم منحني الدّقّة والخسارة للنّموذج من خلال التّوابع المذكورة تاليًا، نحصل على الشّكل (7):
plt.figure(figsize=(6, 4))
plt.plot(history.history['accuracy'], 'r', label='Accuracy of training data')
plt.plot(history.history['loss'], 'r--', label='Loss of training data')
plt.title('Model Accuracy and Loss')
plt.ylabel('Accuracy and Loss')
plt.xlabel('Training Epoch')
plt.ylim(0)
plt.legend()
plt.show()
y_pred_train = model.predict(x_train)
max_y_pred_train = np.argmax(y_pred_train, axis=1)
print(classification_report(y_train, max_y_pred_train))
المرحلة السادسة: مرحلة الاختبار
ثمّ نقوم باختبار النّموذج على قاعدة بيانات الاختبار التي تمّ تعينها في البداية، كما تخضع لعمليّة تقييس وتقسيم للبيانات قبل تطبيقها على النّموذج، ثمّ تتمّ عمليّة تقييم أداء النّموذج ونحصل على دقّة 89.14٪ وخسارة 46.47٪. وفقًا للتّعليمات البرمجيّة التّالية:
score = model.evaluate(x_test, y_test)
print("Accuracy:", score[1])
print("Loss:", score[0])

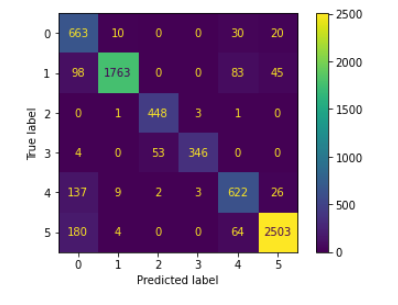
وبرسم مصفوفة الالتباس Confusion matrix نحصل على الشّكل (8):
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=1)
y_test_pred = np.argmax(y_test, axis=1)
cm = confusion_matrix(y_test_pred, predictions)
cm_disp = ConfusionMatrixDisplay(confusion_matrix= cm)
cm_disp.plot()
plt.show()
الخاتمة:
هناك العديد من التّطبيقات اليوميّة المهمّة تعتمد بشكل أساسيّ على تقنيّة التّعرّف على النّشاط البشريّ (HAR)، والتي تستخدم في التّطبيقات الطّبيّة والمراقبة وتتبّع المرضى وتدعم تطبيقات الواقع المعزّز المختلفة، وترتكز هذه التّقنية بشكل أساسيّ على خوارزميّات الذّكاء الاصطناعيّ التي حسّنت بشكل كبير من أداء هذه التّطبيقات؛ ولا سيّما النّموذج المذكور في هذه المدوّنة المعتمد على الدّمج بين الشّبكات المطويّة والإرجاعيّة، ويتمّ العمل على تطوير خوارزميّات أخرى تطوّر من أداء هذه التّطبيقات وتقييمها.




