
في منشور المدونة اليوم، سوف ننفذ أول شبكة طي عصبونية –LeNet – باستخدام البايثون Python وحزمة التعلم العميق كيراس (keras).
المحتويات
قُدِّمت شبكة LeNet في البداية من قبل LeCun وباحثون آخرون، في مقالتهم عام 1998. Gradient-Based Learning Applied to Document Recognition كما يوحي اسم المقالة فإن تنفيذ المؤلفين لـ LeNet تم استخدامه في التعرف البصري على المحارف (Optical Character Recognition OCR)، والتعرف على المحارف في المستندات.
- إن بنية LeNet بسيطة وصغيرة (من حيث الذاكرة) مما يجعلها مثالية لتعلم أساسيات شبكات الطّي العصبونية. يمكن تشغيل الشبكة على وحدة المعالجة المركزية CPU (إذا كان نظامك لا يملك وحدة المعالجة الرسومية GPU المناسبة) مما يجعلها شهيرة/بارزة كأول شبكة طّي عصبونية.
لكن إذا كان لديك دعم لوحدة المعالجة الرسومية وتستطيع الولوج إليها بواسطة كيراس Keras، فإن الوقت اللازم لتدريب الشبكة العصبونية سيكون قصيراً جداً (حوالي 3-10 ثواني لكل دورة epoch معتمداً على وحدة المعالجة الرسومية).
في مقالتنا اليوم سنتناول كيفية تنفيذ بنية شبكة الطّي العصبونية LeNet باستخدام بايثون وكيراس keras. وسأوضح لك أيضاً عزيزي القارئ كيفية تدريب LeNet على مجموعة بيانات MNIST للتعرف على الأرقام.
هل أنت متحمس لبناء شبكة LeNet؟!! أذاً تابع القراءة!!!
LeNet- شبكة الطّي العصبونية باستخدام بايثون
سيكون هذا الدرس التعليمي موجهاً بشكل أساسي للبرمجة، و لمساعدتك لتتعلم الأساسيات في التعلم العميق وشبكات الطّي العصبونية، ولهذا السبب لن أصرف وقتاً لمناقشة توابع التفعيل، طبقات التجميع Pooling، أو طبقات كاملة الاتصال Dense.
للتذكير مرة أخرى، فإن الغاية من هذه المقالة هي بناء وتدريب شبكة عصبونية باستخدام قاعدة بيانات حقيقية بحيث يمكن استخدامها بشكل عملي.
رغم أنك يجب أن تعرف مسبقاً أساسيات عن كيفية عمل عملية الطّي، لكن أثناء ذلك، تابع الدرس وتعلم كيف تنفذ أول شبكة طي عصبونية باستخدام البايثون وكيراس Keras.
مجموعة البيانات MNIST

يمكن القول أن مجموعة البيانات MNIST هي مجموعة البيانات الأكثر دراسة والأكثر فهمًا في مجال الرؤية الحاسوبية وتعلم الآلة، مما يجعلها ممتازة لتستخدمها في رحلتك في التعلم العميق.
ملاحظة: سنكتشف أنه من السهل جدًا الحصول على دقة تصنيف 98% في مجموعة البيانات هذه مع الحد الأدنى من وقت التدريب، حتى على وحدة المعالجة المركزية CPU .
الهدف من مجموعة البيانات هذه هو تصنيف الأرقام المكتوبة بخط اليد من 0 حتى 9، تحتوي مجموعة البيانات MNIST على 70000 صورة، يمكننا تقسيمها بالطريقة التي نراها مناسبة إلى مجموعتين الأولى مجموعة التدريب Training Set والثانية مجموعة الاختبار Test Set. التقسيم الأكثر شيوعاً هو 60000 صورة للتدريب و 10000 صورة للاختبار أي 75%/25%، لكننا في هذا المقال سندرب شبكتنا على ثلثي البيانات وسنختبرها بالثلث المتبقي.
يتم تمثيل كل رقم كصورة بتدرج الرمادي بحجم 28× 28 بكسل (يمكن رؤية الأمثلة من مجموعة بيانات MNIST في الشكل (1).
إن شدة البكسل الرمادية عبارة عن أرقام صحيحة غير سالبة ضمن المجال [0-255]، يتم وضع جميع الأرقام على خلفية سوداء بينما الرقم نفسه بلون أبيض ولون رمادي مختلف.
تجدر الإشارة إلى أن العديد من المكتبات مثل (scikit-learn) لديها طرق مساعدة مضمّنة لتنزيل مجموعة البيانات MNIST ، وتخزينها مؤقتًا على القرص ، ثم تحميلها. عادةً ما يتم تمثيل الصور في مكتبات بايثون بشعاع ذو 784 قيمة.
من أين أتى الرقم 784؟
ببساطة، إنّها الصورة المسطّحة فقط من 28 × 28 = 748.
لاستعادة صورتنا الأصلية من الشعاع ذي 784 قيمة ، نقوم ببساطة بإعادة تشكيل المصفوفة إلى صورة بحجم 28 × 28.
في سياق منشور المدونة هذا ، يتمثل هدفنا في تدريب LeNet بحيث نزيد الدقة على مجموعة الاختبارات الخاصة بنا.
بنية LeNet
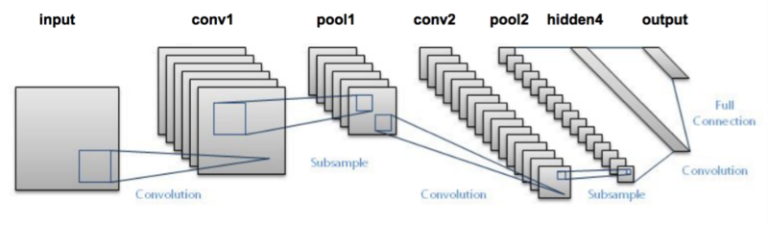
تُعد بنية LeNet ممتازة كبنية أولية لشبكات الطّي العصبونية (خاصة عند تدريبها على مجموعة البيانات MNIST وهي مجموعة بيانات صور من أجل التعرف على الأرقام المكتوبة بخط اليد)
LeNet صغيرة وسهلة الفهم – لكنها كبيرة بما يكفي لتوفير نتائج مثيرة للاهتمام. علاوة على ذلك، فإن مجموعة LeNet + MNIST يمكن العمل بها على وحدة المعالجة المركزية CPU، مما يجعل من السهل على المبتدئين الحصول على الخطوة الأولى في التعلم العميق وشبكات الطّي العصبونية. بشكل عام يمكن اعتبار تعلم LeNet + MNIST بمثابة الخطوة الأولى “Hello World” في التعلم العميق من أجل تصنيف الصور.
تتألف بنية LeNet من الطبقات التالية:
INPUT => CONV => RELU => POOL => CONV => RELU => POOL => FC => RELU => FCالدخل => الطي => التفعيل Relu => التجميع => الطي => التفعيل Relu => التجميع => كاملة الاتصال => التفعيل Relu => كاملة الاتصال
ملاحظة: استخدمت البنية الأصلية لـ LeNet توابع التفعيل TANH بدلاً من RELU. نحن نستخدم RELU هنا لأنه يميل لإعطاء دقة تصنيف أفضل نظراً لعدد من الخصائص الدقيقة والمرغوبة فيه. إذا صادفت أية نقاشات أخرى عن LeNet ، قد ترى أنّها تستخدم TANH بدلاً من RELU- مرة ثانية، هذا مجرد شيء يجب أخذه بعين الاعتبار.
تنفيذ LeNet باستخدام بايثون و Keras
للبدء سأفترض أن لديك Keras ،scikit-Learn و OpenCV مثبتة على نظامك.
(اختيارياً يمكنك استخدام GPU). افتح ملف lenet.jpynb وأدخل الكود البرمجي التالي:
# import the necessary packages
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras import backend as K
class LeNet:
@staticmethod
def build(numChannels, imgRows, imgCols,
numClasses,activation="relu"):
# initialize the model
model = Sequential()
inputShape = (imgRows, imgCols, numChannels)
# if we are using "channels first", update the input shape
if K.image_data_format() == "channels_first":
inputShape = (numChannels, imgRows, imgCols)
الأسطر من 2-8 تعالج استيراد الأصناف Classes والتوابع المطلوبة من مكتبة Keras.
عُرّف الصنف LeNet في السطر العاشر متبوعاً بالطريقة Build. عند تعريف بنية شبكة جديدة أضعها دائماً في صنفها class الخاص (لغاية التنظيم) متبوعة بإنشاء تابع ستاتيكي Build.
تأخذ طريقة Build كما يبين الاسم معاملات مزودة على الشكل التالي:
- عمق الصور المدخلة أو ما يسمى بعدد القنوات فمثلا لدينا 3 قنوات في الصور الملونة RGB
- ارتفاع الصور المدخلة
- عرض الصور المدخلة
- عدد الأصناف (يوجد لكل صنف رقم فريد) في مجموعة البيانات المدروسة.
وبأخذ هذه المعاملات فإن تابع Build يكون جاهز لبناء بنية الشبكة.
عند بناء شبكة LeNet ننشئ مثال instance من الصنف Sequential الذي يُستَخدم لبناء الشبكة.
علينا أيضاً ضبط إعدادات TensorFlow لتحديد كيفية قراءة الصورة، حيث يوجد نمطين النمط الأول يقرأ Tensorflow عدد قنوات الصورة من أول معامل “القنوات أولاً” أما في النمط الثاني فتؤخذ عدد قنوات الصورة من آخر معامل دخل “القنوات آخراً” وهو النمط الافتراضي.
الآن، بعد أن أصبح النموذج مهيأَ بإمكاننا إضافة الطبقات عليه.
# define the first set of CONV => ACTIVATION => POOL layers
model.add(Conv2D(20, 5, padding="same", input_shape=inputShape))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
في الأسطر من 23-25 ننشئ أول مجموعة من طبقات
CONV => RELU => POOL
الطّي => RELU => التجميع
طبقة الطّي الخاصة بمثالنا ستتعلم أوزان 20 فلتر طي، حيث كل فلتر بحجم 5×5.
إن بعد الدخل لهذه الطبقة هو بعد الصور المدخلة (العرض، الارتفاع، العمق)- في حالتنا، حيث نستخدم مجموعة البيانات MNIST فإنّه لدينا 28×28 دخل وقناة وحيدة للعمق (تدرج الرمادي).
سنطبق بعد ذلك تابع التفعيل RELU المتبوع بـتجميع-القيمة الأكبر max-pooling بحجم 2×2 على المحور x و المحور y مع خطوة stride 2. (تخيل نافذة انزلاقية بحجم 2×2 تنزلق عبر القيم المفعلة وتأخذ أكبر قيمة من كل منطقة، وبأخذ خطوة على البكسلات بحجم 2 في الاتجاهين الأفقي والعمودي).
ملاحظة: هذا الدرس التعليمي موجّه بشكل أساسي للكود البرمجي ويراد منه أن تنفذ أول شبكة طي عصبونية. لذلك حاول ببساطة اتباع الكود البرمجي.
والآن نحن جاهزون لتطبيق المجموعة الثانية من الطبقات
CONV => RELU => POOL
الطّي => RELU => التجميع
# define the second set of CONV => ACTIVATION => POOL layers
model.add(Conv2D(50, 5, padding="same"))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
هذه المرة ستتعلم الشبكة أوزان 50 فلتر طي بدلاً من 20 فلتر كما في مجموعة الطبقات السابقة.
من الشائع أن نرى زيادة في عدد فلاتر الطّي في الطبقات الأعمق من الشبكة.
بعد ذلك، وصلنا إلى الطبقات كاملة الاتصال (غالبًا ما تسمى الطبقات “الكثيفة” “dense”) في بنية LeNet.
# define the first FC => ACTIVATION layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation(activation))
# define the second FC layer
model.add(Dense(numClasses))
# lastly, define the soft-max classifier
model.add(Activation("softmax"))
في السطر 33 نأخذ خرجMaxPooling2D السابقة ونسطحه إلى شعاع واحد. مما يسمح لنا بتطبيق الطبقات الكثيفة كاملة الاتصال. وكما تعلم، فأن الشبكات الكثيفة هي من الشبكات الأساسية والتي تستخدم كأحدى طبقات الشبكات العصبونية العميقة، حيث يتصل كل عصبون في الطبقة السابقة مع جميع عصبونات الطبقة التالية (ومن هنا جاءت التسمية “كاملة الاتصال” أو “كثيفة”)
ستحتوي الطبقة كاملة الاتصال على 500 عصبون كما هو موضح في السطر 34 وسنمررها إلى تابع التفعيل غير الخطي RELU.
إن السطر 38 مهم جداً، يعرّف هذا السطر صنف آخر من Dense حيث يقبل الحجم كمتغير variable. هذا الحجم هو عدد الأصناف الممثلة بالمتغير classes. في حالتنا حيث نستخدم مجموعة البيانات MNIST فإنه لدينا 10 أصناف (واحد لكل واحد من الأرقام العشرة التي نحاول أن نتعلم التعرف عليها).
أخيراً نطبق المصنف softmax (الانحدار اللوجستي متعدد الحدود- multinomial logistic regression) الذي يعيد قائمة من الاحتمالات، احتمال لكل واحد من الأصناف العشرة (السطر 41)
يتم اختيار الصنف ذو قيمة الاحتمال الأكبر كتصنيف نهائي للرقم من الشبكة.
إنشاء برنامج تشغيل LeNet
بعد أن قمنا بتصميم بنية شبكة الطّي العصبونية باستخدام بايثون وكيراس Keras، يمكننا القيام بما يلي:
- تحميل مجموعة البيانات MNIST.
- تقسيم مجموعة البيانات MNIST إلى مجموعة تدريب ومجموعة اختبار.
- تحميل وتجميع بنية LeNet.
- تدريب الشبكة.
- (خياري) يمكن حفظ النموذج الناتج إلى القرص الصلب لإعادة استخدامه (بدون الحاجة إلى إعادة تدريب الشبكة).
- عرض أمثلة مرئية لخرج الشبكة لإثبات أن تطبيقنا يعمل بشكل صحيح بالفعل.
تتمثل هذه الخطوات بالكود البرمجي التالي:
# import the necessary packages
from sklearn.model_selection import train_test_split
from keras.datasets import mnist
from keras.optimizers import SGD
from keras.utils import np_utils
from keras import backend as K
import numpy as np
import cv2
في الأسطر السابقة تم استيراد حزم بايثون المطلوبة.
والآن نحن جاهزون لتحميل مجموعة البيانات MNIST وتقسيمها إلى مجموعات تدريب واختبار:
# grab the MNIST dataset (if this is your first time running this
# script,-- the 55MB MNIST dataset will be downloaded)
print(" MNIST downloading...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# if we are using "channels first" ordering, then reshape the
# design matrix such that the matrix is:
# num_samples x depth x rows x columns
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# otherwise, we are using "channels last" ordering, so the design
# matrix shape should be: num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# scale data to the range of [0, 1]
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
يحُمّل السطر 13 مجموعة البيانات MNIST من القرص، إذا كانت هذه المرة الأولى التي تستدعي بها تابع fetch_mldata من أجل سلسلة MNIST الأصلية, فستحتاج أن تحمّل مجموعة البيانات MNIST. إن حجم مجموعة بيانات MNIST هو 55 ميغا بايت.
تعُالج أسطر الكود 18-26 إعادة تشكيل البيانات آخذة بعين الاعتبار تنفيذ “القنوات أولاً” أو “القنوات آخراً” وكما ذكرنا فإن TensorFlow يدعم ترتيب “القنوات آخراً”.
أخيراً فإن الأسطر 29-30 تنجز تقسيم البيانات إلى تدريب واختبار مستخدمة 2/3 من البيانات كبيانات تدريب و1/3 من البيانات المتبقية للاختبار. نقوم أيضًا بتحويل صورنا من النطاق [0 ، 255] إلى [0 ، 1.0] ، وهي تقنية تقييس scaling شائعة.
تعالج الخطوة التالية تشفير الأصناف labels لذلك يمكن استخدام categorical cross-entropy كتابع خسارة Loss function.
# transform the training and testing labels into vectors in the
# range [0, classes] -- this generates a vector for each label,
# where the index of the label is set to `1` and all other entries
# to `0`; in the case of MNIST, there are 10 class labels
trainLabels = np_utils.to_categorical(trainLabels, 10)
testLabels = np_utils.to_categorical(testLabels, 10)
# initialize the optimizer and model
print("....compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(numChannels=1, imgRows=28, imgCols=28,numClasses=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,metrics=["accuracy"])
تعالج الأسطر 36-37 تشفير الأصناف المرغوبة labels لعينات التدريب والاختبار (مثلاً أصناف “الحقائق المرجعية” لكل صورة في مجموعة البيانات MNIST. المقصود بمصطلح الحقائق المرجعية إن لم تكن الأصناف المرغوبة بالواقع صحيحة فنتائج الشبكة لن تكون صحيحة.
سنحتاج إلى تطبيق التابع to_categorical لأننا نستخدم تابع الخسارة The categorical cross-entropy، وهو تابع يحول الأصناف labels من أرقام صحيحة إلى شعاع. حيث كل شعاع يكون طوله من ]0- عدد الأصناف[. هذا التابع يولد شعاع لكل صنف label حيث أن فهرس index الصنف الصحيح يوضع 1 وباقي قيم الشعاع تكون أصفاراً.
لدينا 10 أصناف مرغوبة labels في حالة مجموعة البيانات MNIST، لذلك كل صنف label يُمثَّل كشعاع من 10 قيم، على سبيل المثال افترض أن لدينا الصنف المرغوب label لعينة تدريب “3”، بعد تطبيق تابع to_categorical سيبدو الشعاع بالشكل التالي:
[0 0 0 1 0 0 0 0 0 0 0]
لاحظ كيف تكون جميع مدخلات الشعاع صفراً 0 باستثناء الفهرس الثالث الذي تم وضع قيمته واحد 1.
سندرب شبكتنا الآن باستخدام تناقص المشتق الإحصائي Stochastic Gradient Descent (SGD) مع معدل تعلم 0.01 (السطر 41). وسيُستخدم Categorical cross-entropy كتابع خسارة. وهو اختيار قياسي إلى حد ما عند العمل مع مجموعات بيانات تحتوي أكثر من صنفين labels، ثم يتم تفسير نموذجنا وتحميله على الذاكرة في الأسطر 42-43.
والآن نحن جاهزون لتدريب شبكة LeNet الخاصة بنا أو بشكل اختياري تحميل نموذج مدرب سابقاً.
# only train and evaluate the model if we *are not* loading a
# pre-existing model
model.fit(trainData, trainLabels, batch_size=128, epochs=20,verbose=1)
يُنجَز تدريب الشبكة باستدعاء الطريقة fit من النموذج المثال-instance (السطر السابق). سنسمح للشبكة أن تتدرب 20 دورة epochs (مع الإشارة إلى أن شبكتنا ستشاهد كل مثال من أمثلة التدريب 20 مرة لتعلم الفلاتر المميزة لكل صنف رقم).
ثم سنقيّم شبكتنا على بيانات الاختبار ونعرض النتائج على الشاشة.
# show the accuracy on the testing set
(loss, accuracy) = model.evaluate(testData, testLabels,batch_size=128, verbose=1)
print("[INFO] accuracy: {:.2f}%".format(accuracy * 100))
إذا أردنا حفظ النموذج إلى ملف، مما يتيح لنا اختبار الشبكة دون الحاجة إلى إعادة تدريبها من نقطة الصفر، حينها نكتب الكود التالي:
# saved the model to file
LeNetModel=model.save('LeNetModel.h5')
يعالج آخر قسم من الكود البرمجي اختيار بضعة أرقام بشكل عشوائي من مجموعة الاختبار ثم اختبارهم خلال الشبكة المدربة LeNet من أجل التصنيف.
# randomly select a few testing digits
for i in np.random.choice(np.arange(0, len(testLabels)), size=(10,)):
# classify the digit
probs = model.predict(testData[np.newaxis, i])
prediction = probs.argmax(axis=1)
# extract the image from the testData if using "channels_first"
# ordering
if K.image_data_format() == "channels_first":
image = (testData[i][0] * 255).astype("uint8")
# otherwise we are using "channels_last" ordering
else:
image = (testData[i] * 255).astype("uint8")
# merge the channels into one image
image = cv2.merge([image] * 3)
# resize the image from a 28 x 28 image to a 128 x 128 image so we
# can better see it
image = cv2.resize(image, (128, 128), interpolation=cv2.INTER_LINEAR)
# show the image and prediction
cv2.putText(image, str(prediction[0]), (5, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
print("Predicted:{},Actual:{}".format(prediction[0],
np.argmax(testLabels[i])))
cv2.imshow("Digit", image)
cv2.waitKey(2)
نحن نصنف الصور باستخدام نموذجنا LeNet من أجل كل رقم من الأرقام المختارة عشوائياً (السطر 60).
نحصل على التنبؤ الفعلي لشبكتنا بإيجاد فهرس index لكل صنف label يحمل أكبر احتمال largest probability. تذكر أن شبكتنا ستعيد مجموعة من الاحتمالات بواسطة تابع Softmax، احتمال واحد لكل صنف – و بالتالي فإنّ “التنبؤ” الفعلي للشبكة هو الصنف label ذو الاحتمال الأكبر.
تعالج الأسطر 65-81 إعادة تحجيم الصورة 28×28 إلى 96×96 بكسل لذلك نستطيع عرض الصورة، وإظهار التنبؤ عليها.
أخيراً، تُعرض النتيجة على الشاشة من خلال الأسطر 82-85.
تدريب LeNet باستخدام بايثون وكيراس Keras
لتدريب LeNet على مجموعة البيانات MNIST، تأكد من قيامك بكتابة الكود البرمجي المصدر الموجود في هذه المقالة.
يحتوي الملف LeNet.jpynb على الكود البرمجي الذي قمت بتفصيله في هذا الدرس التعليمي.
يمكنك استخدام LeNet المدربة سابقاً LeNet.h5 من خلال الأوامر التالية:
from keras.models import load_model
model=load_model(‘LeNet.h5’)
ثم اختبارها على بيانات الاختبار.
لقد ضمّنت الخرج من جهازي كما هو واضح أدناه:
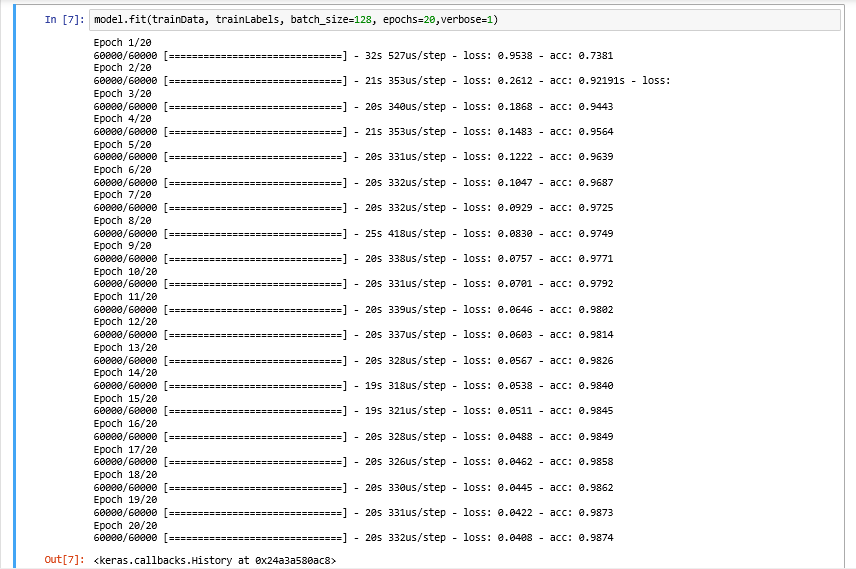
في وحدة GPU ، يستغرق الأمر حوالي 20 ثانية لكل دورة ، مما يسمح بإنهاء عملية التدريب بأكملها في 6 دقائق ونصف.
بعد 20 دورة فقط ، وصلت LeNet إلى دقة تصنيف 98.52٪ على مجموعة البيانات MNIST وهي دقة ليست سيئة على الإطلاق لمدة 6 دقائق ونصف فقط من وقت الحساب!
ملاحظة: إذا قمت بتدريب الشبكة على وحدة المعالجة المركزية CPU بدلاً من وحدة المعالجة الرسومية GPU ، فتوقع أن يزيد الوقت لكل دورة إلى 70-90 ثانية. إذاً لا يزال من الممكن تدريب LeNet على وحدة المعالجة المركزية CPU الخاصة بك ، وسوف يستغرق الأمر بعض الوقت لفترة أطول.
تقييم LeNet باستخدام بايثون و كيراس Keras
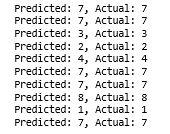
أدرجت أعلاه أمثلة قليلة من تقييم LeNet على بعض العينات المختارة عشوائياً من عينات الاختبار.
في هذه الصورة ، تتعرف LeNet بشكل صحيح على الرقم “7”

وهذه صورة أخرى أيضاً ، تستطيع أيضاً شبكة LeNet تصنيف الرقم “1”.

لقد ضمنّت في الأسفل رسماً متحركاً GIF من LeNet المستخدمة لتصنيف الأرقام المكتوبة بخط اليد بشكل صحيح

الخلاصة
في منشور المدونة اليوم ، أوضحنا كيفية تنفيذ بنية LeNet باستخدام لغة برمجة بايثون Python ومكتبة Keras للتعلم العميق.
إنّ بنية LeNet تشبه أمثلة “Hello World” لتساعدك في تعلم أساسيات التعلم العميق وشبكات الطّي العصبونية. الشبكة نفسها بسيطة وتتطلب مساحة صغيرة من الذاكرة ، وعند تطبيقها على مجموعة البيانات MNIST، يمكن تشغيلها إما على وحدة المعالجة المركزية CPU أو وحدة المعالجة الرسومية GPU، مما يجعلها مثالية للتجربة والتعلم ، خاصة إذا كنت جديداً في مواضيع التعلم العميق.
كان هذا الدرس التعليمي في الأساس يركز على الكود البرمجي ، ولهذا السبب ، تخطينا التفاصيل حول مفاهيم شبكات الطّي العصبونية مثل طبقات التفعيل ، طبقات التجميع ، والطبقات الكثيفة / كاملة الاتصال (وإلا فإن هذا المنشور كان من الممكن أن يكون أطول بخمسة أضعاف).
تعرّف على الكود البرمجي وحاول تنفيذه بنفسك. وإذا كنت تمتلك الجرأة الحقيقية ، فحاول تغيير عدد الفلاتر وأحجام الفلاتر لكل طبقة طي ومعرفة ما يحدث!
على أي حال ، آمل أن تكون قد استمتعت بقراءة المنشور هذا – بالتأكيد سنقوم بنشر المزيد من منشورات التعلم العميق وتصنيف الصور في المستقبل.
المراجع
- https://www.pyimagesearch.com/2016/08/01/lenet-convolutional-neural-network-in-python/, Last Access Date 9/10/2019.
- Adrian Rosebrock, Deep Learning for Computer Vision with Python, PyImageSearch, 2018.





تعليقان
السلام عليكم
يرجى كتابة المقال كترجمة الدكتورة وليست بقلم الدكتورة ….مقالة للدكتور العالمي ادروين