
المحتويات
هل ترغب ببناء شبكة طّيّ عصبونية Convolution Neural Network CNN خاصة بك على جهازك؟
هل ترغب باستخدام مكتبة كيراس في بايثون في بناء شبكة طّيّ عصبونية؟
هل ترغب بمعرفة بنى معمارية مختلفة مستخدمة في تصميم شبكة الطّيّ العصبونية ؟
كن معنا في هذا البرنامج التعليمي.
يوجد عناصر معمارية متمايزة من نماذج معروفة يمكنك استخدامها في تصميم شبكات الطّيّ العصبونية الخاصة بك، ونخص منها تلك النماذج التي حققت نتائج هامة في مهام تصنيف الصور مثل كتلة مجموعة الهندسة المرئية VGG block في نماذج مجموعة الهندسة المرئية ووحدة انسبشن inception module المستخدمة في شبكة جوجل انسبشن GoogLeNet بالإضافة إلى وحدة الرواسب residual module المستخدمة في شبكة الرواسب ResNet. بمجرد أنك قمت بتنفيذ هذه العناصر المعمارية ذات المعاملات يمكنك استخدامها في تصميم نماذج الرؤية الحاسوبية وغيرها من التطبيقات.
الآن سنبدأ برنامجنا التعليمي في اكتشاف كيفية تنفيذ العناصر المعمارية المختلفة من نماذج شبكة الطّيّ العصبونية من البداية، وبعد الانتهاء سنكون قادرين على:
- تنفيذ وحدة مجموعة الهندسة المرئية المستخدمة في نماذج شبكة الطّي العصبونية VGG-16 و VGG-19.
- تنفيذ وحدة انسبشن البسيطة والأمثلية المستخدمة في نموذج شبكة جوجل انسبشن GoogLeNet.
- تنفيذ الوحدة الراسبة الفريدة المستخدمة في نموذج شبكة الرواسب ResNET.
كما سنكتشف كيفية إنشاء نماذج لتصنيف الصور واكتشاف الأغراض والتعرف على الوجوه.
هل أنت مستعد ومتشوق الآن …؟ إذاً دعنا نبدأ ..
تنفيذ كتل مجموعة الهندسة المرئية VGG
تعتبر كتل مجموعة الهندسة المرئية علامة مرجعية هامة جداً في استخدام خوارزميات التعلّم العميق في مجال الرؤية الحاسوبية، وتسمى بالأحرف الأولى من اسم مجموعة الهندسة المرئية Visual Geometry Group في أكسفورد.
تمّ شرح بنية هذه الشبكة في ورقة بحثية بعنوان “شبكة الطّيّ العصبونية العميقة جداً للتعرف على الصور على نطاق واسع” “Very Deep Convolutional Networks for Large-Scale Image Recognition” من قبل الباحثة كارين سيمونيان والباحث أندريه زيسرمان[1]، وقد حققت هذه الشبكة أعلى نتائج في مسابقة تحدي التعرف البصري واسع النطاق للرؤية الحاسوبية LSVRC-2014 Large Scale Visual Recognition Challenge .
الفكرة الجديدة في هذه البنية هي تعريف وتكرار ما سنشير إليه بـ “كتل مجموعة الهندسة المرئية VGG-blocks ” وهي مجموعة من طبقات الطّي التي تستخدم مرشحات طّي صغيرة 3×3 بكسل (عنصر صورة) تليها طبقة تجميع وفق القيمة الأكبر max pooling layer .
إنّ شبكة الطّي العصبونية بكتل مجموعة الهندسة المرئية هي نقطة انطلاق مناسبة عند تطوير نموذج جديد من البداية لأنها سهلة الفهم والتنفيذ وفعالة جداً في استخلاص المزايا من الصور.
يمكن تعميم مواصفات كتلة مجموعة الهندسة المرئية كطبقة واحدة أو عدة طبقات طّي بنفس عدد مرشحات الطّي وبعد مرشح الطّي 3×3 وبخطوة تحريك للمرشح stride 1×1 وحشو صفري padding من نوع “same” حيث يتم حساب مقدار الحشو المطلوب وإضافته ليكون حجم الخرج مساوياً لحجم الدخل من أجل كل مرشح طّي، بالإضافة لاستخدام تابع التفعيل الخطي المصحح relu. ثمّ يلي هذه الطبقات طبقة التجميع وفق القيمة الأكبر بحجم 2×2 وبخطوة تحريك stride ذات نفس الأبعاد 2×2.
# function for creating a vgg block
def vgg_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in=Conv2D(n_filters, (3,3), padding='same', activation='relu')(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
في السطر الثاني: يتم التصريح عن تابع تعريف كتلة مجموعة الهندسة المرئية وله ثلاث معاملات دخل تتمثل في الطبقة layer_in التي تسبق كتلة مجموعة الهندسة المرئية وقد تكون الطبقة الأولى (طبقة الدخل) في النموذج. وعدد مرشحات الطّي n_filters لكل طبقة طّيّ في الكتلة بالإضافة لعدد طبقات الطّيّ المتكررة n_conv التي ستتشكل منها هذه الكتلة.
في السطر الرابع والخامس: يتم استخدام التابع Conv2D لإضافة طبقة طّيّ ذات عدد مرشحات الطّيّ محدد كمعامل دخل للتابع، وبُعد مرشح الطّيّ 3×3 وطريقة الحشو same وتابع التفعيل relu. وتتكرر العملية بنفس العدد المحدد كمعامل دخل للتابع n_conv لإضافة طبقة طّيّ جديدة بنفس المواصفات في كل مرة.
في السطر السابع: إضافة طبقة التجميع وفق القيمة الأكبر بحجم 2×2 وبخطوة تحريك stride ببعد 2×2.
السطر الثامن: الحصول على طبقة في نهاية كتلة مجموعة الهندسة المرئية من أجل استخدامها في نموذج التنبؤ بالتصنيف عن طريق وصلها مع طبقة مسطحة flatten layer وطبقات كاملة الاتصال Dense layers اللاحقة.
يوضح المثال التالي استخدام التابع في تعريف نموذج شبكة طّيّ عصبونية بسيط باستخدام كتلة مجموعة الهندسة المرئية لتوقع صورة مربع ملون، حيث يتم إضافة كتلة واحدة بطبقتي طّيّ وكل طبقة طّيّ ب 64 مرشح طّيّ.
# Example of creating a CNN model with a VGG block
from keras.models import Model
from keras.layers import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.utils import plot_model
# function for creating a vgg block
def vgg_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in = Conv2D(n_filters, (3,3), padding='same', 12-activation='relu')(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
# define model input
visible = Input(shape=(256, 256, 3))
# add vgg module
layer = vgg_block(visible, 64, 2)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
# plot model architecture
plot_model(model, show_shapes=True, to_file='vgg_block.png')
الأسطر من 2- 6: يتم استدعاء التوابع من مكتبات كيراس في لغة البرمجة بايثون مثل تابع بناء طبقة الدخل Input وتابع بناء طبقة الطّيّ Conv2D وتابع بناء طبقة التجميع MaxPooling2D من مكتبة layers والتابع plot_model من مكتبة utils بالإضافة إلى التابع Model من مكتبة models.
الأسطر من 8-15: يتم تعريف كتلة مجموعة الهندسة المرئية المشروحة في الكود السابق.
السطر 17: يتم استخدام التابع Input لبناء طبقة الدخل visible من مصفوفة ثلاثية الأبعاد 3×256×256 تدل على صورة ملونة بأبعاد 256×256 وبثلاثة مركبات لونية.
السطر 19: يتم استخدام كتلة مجموعة الهندسة المرئية من طبقتي طّيّ وفي كل طبقة 64 مرشح طّيّ، ودخلها هو الطبقة visible وخرجها هو الطبقة layer.
السطر 21: يتم بناء النموذج بحيث دخله هو الطبقة visible وخرجه هو الطبقة الناتجة عن استخدام كتلة مجموعة الهندسة المرئية.
السطر 23: يظهر ملخص عن النموذج الذي تم بناؤه.
بتنفيذ المثال وإظهار ملخص بنية الشبكة نلاحظ بنية النموذج كما يلي:
الملخص:

كما أن طباعة النموذج تجعل بنية النموذج أكثر وضوحاً.
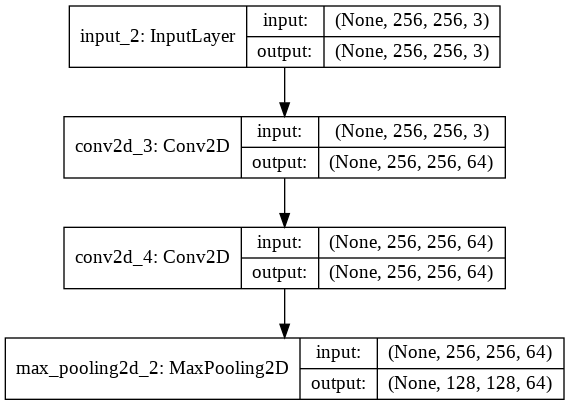
يُعدّ استخدام كتل مجموعة الهندسة المرئية في بناء النماذج أمرا شائعاً لأنها بسيطة وفعالة. ويجب أن يكون قد أصبح أمراً مألوفا لك الآن لتستخدمه في بناء نماذجك الخاصة، أليس كذلك؟
الآن..
يمكننا توسيع المثال وبناء نموذج شبكة طّيّ عصبونية يحتوي على ثلاثة كتل مجموعة هندسة مرئية سيكون عدد المرشحات في طبقات الطّيّ في الكتلة الأولى 64 مرشح طّيّ وعددها في طبقات الطّيّ في الكتلة الثانية 128 مرشح طّيّ، أما في الكتلة الثالثة فسيكون عدد مرشحات الطّيّ 256 لكل طبقة طّيّ.
وتذكر أنّ هذا هو الاستخدام الشائع لكتل مجموعة الهندسة المرئية في بناء النماذج حيث يتم زيادة عدد مرشحات الطّيّ طرداً مع ازدياد عمق النموذج.
# Example of creating a CNN model with many VGG blocks
from keras.models import Model
from keras.layers import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.utils import plot_model
# function for creating a vgg block
def vgg_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in = Conv2D(n_filters, (3,3), padding='same',
activation='relu')(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
# define model input
visible = Input(shape=(256, 256, 3))
# add vgg module
layer = vgg_block(visible, 64, 2)
# add vgg module
layer = vgg_block(layer, 128, 2)
# add vgg module
layer = vgg_block(layer, 256, 4)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
# plot model architecture
plot_model(model, show_shapes=True, to_file='multiple_vgg_blocks.png')
يتم استخدام الكتل الثلاث من كتل مجموعة الهندسة المرئية في بناء النموذج في الأسطر 19، 21، 23 على التوالي. وبتنفيذ المثال، فيكون ملخص بنية النموذج كما يلي:
الملخص:

ويكون مخطط بنية النموذج كما يلي:
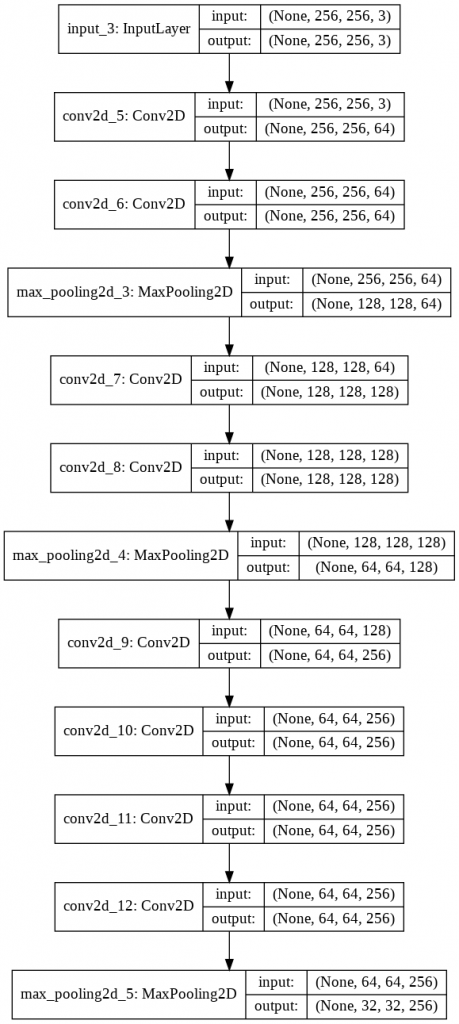
تنفيذ وحدة انسبشن Inception Module
تمّ وصف واستخدام وحدة بناء جوجل انسبشن Inception في نموذج شبكة جوجل GoogLeNet عام 2015 من قبل الباحثة كريستين زيجدي ورفاقها في ورقة بحثية [2] بعنوان” الاتجاه نحو العمق مع عمليات الطّيّ”
“Going Deeper with Convolutions“.
حقق نموذج GoogLeNet أعلى النتائج في تحدي التعرف البصري واسع النطاق للرؤية الحاسوبية للعام 2014 ILSVRC-2014 أيضاً مثل نموذج مجموعة الهندسة المرئية، الابتكار الأساسي في نموذج شبكة جوجل انسبشن يسمى “وحدة انسبشن ” “inception module”.
وحدة بناء انسبشن هي كتلة من طبقات طّيّ متوازية ذات أحجام مرشحات طّيّ مختلفة (مثلا 1×1 ، 3×3 ، 5×5) وطبقة تجميع وفق القيمة الأكبر ببعد 3×3 . ثم يتم جمع نتائج جميع الطبقات.
تُعتبَر هذه البنية وحدة بناء بسيطة وفعالة جداً تسمح للنموذج بتعلم مرشحات طّيّ متوازية وبأحجام مختلفة بالإضافة لتعلم مرشحات الطّيّ المتوازية ذات الأحجام المتساوية مما يسمح بالتعلّم على مستويات متعددة.
يمكن تنفيذ وحدة انسبشن باستخدام توابع المكتبة كيراس في لغة البرمجة بايثون. حيث سيتم إنشاء وحدة بناء وحيدة بعدد ثابت من مرشحات الطّيّ لكل طبقة طّيّ متوازية. لا يظهر أنه تم استخدام تحجيم منتظم لمرشحات الطّيّ في طبقات الطّيّ المتوازية في بنية نموذج شبكة جوجل المشروحة في البحث[2] ، لأن النموذج تم تحسينه بشكل كبير. على هذا النحو يمكن تحديد تعريف وحدة البناء وبالتالي يمكن تحديد عدد مرشحات الطّيّ المستخدمة بالأحجام 1×1و 3×3 و 5×5 مرشح طّيّ، كما هو موضح في المقطع البرمجي التالي.
# function for creating a naive inception block
def inception_module(layer_in, f1, f2, f3):
# 1x1 conv
conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in)
# 3x3 conv
conv3 = Conv2D(f2, (3,3), padding='same', activation='relu')(layer_in)
# 5x5 conv
conv5 = Conv2D(f3, (5,5), padding='same', activation='relu')(layer_in)
# 3x3 max pooling
pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in)
# concatenate filters, assumes filters/channels last
layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1)
return layer_out
السطر الثاني: يتم التصريح عن التابع تعريف وحدة انسبشن وله أربع معاملات دخل يمثل المعامل الأول مؤشر لطبقة الدخل layer_in ويمثل المعامل الثاني والثالث والرابع عدد المرشحات المستخدمة في كل طبقة طّيّ على التوالي f1,f2,f3 ، كما يعيد التابع مؤشر لطبقة تجميع الطبقات المتوازية المستخدمة في وحدة البناء.
السطر الرابع والسادس والثامن: يتم استخدام التابع Conv2D لإضافة طبقات الطّيّ ذات عدد مرشحات الطّيّ المحددة كمعامل دخل f1,f2,f3 إلى تابع بناء وحدة انسبشن وبأبعاد مرشحات طّيّ 1× 1، 3×3، 5×5 على التوالي وطريقة الحشو الصفري same وتابع التفعيل relu.
السطر العاشر: إضافة طبقة التجميع وفق القيمة الأكبر بحجم 2×2 وبخطوة تحريك 1×1.
السطر الثاني عشر: الحصول على مؤشر للطبقة في نهاية كتلة انسبشن layer_out من أجل استخدامها في بناء النماذج التي تستخدم وحدة انسبشن.
يمكن استخدام هذا التابع في بناء نموذج يستخدم وحدة انسبشن واحدة وعدد المرشحات يعتمد على شكل انسبشن (3a) في الجدول [1] الموجود في الورقة البحثية [2] والذي يوضح أشكال بنية انسبشن في نموذج شبكة جوجل:
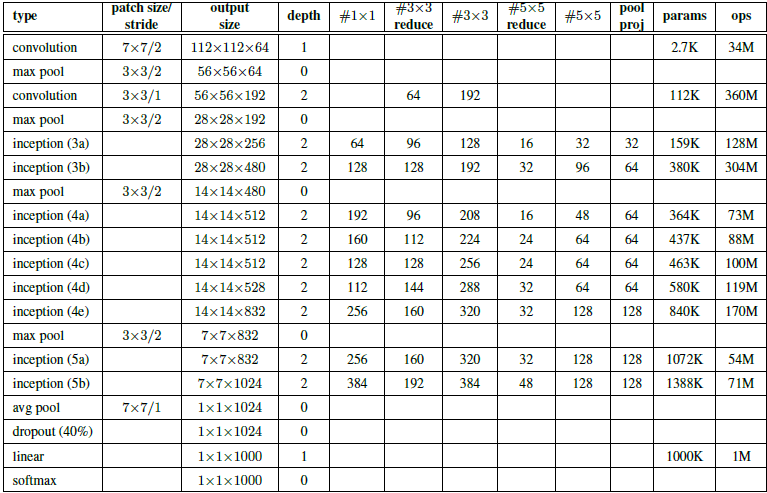
نعرض فيما يلي مثال لبناء النموذج الذي يستخدم وحدة انسبشن واحدة ذات المواصفات الموضحة في شكل انسبشن (3a) الموصوف في الجدول [1] باستخدام مكتبة كيراس في لغة البرمجة بايثون.
# example of creating a CNN with an inception module
from keras.models import Model
from keras.layers import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers.merge import concatenate
from keras.utils import plot_model
# function for creating a naive inception block
def naive_inception_module(layer_in, f1, f2, f3):
# 1x1 conv
conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in)
# 3x3 conv
conv3 = Conv2D(f2, (3,3), padding='same', activation='relu')(layer_in)
# 5x5 conv
conv5 = Conv2D(f3, (5,5), padding='same', activation='relu')(layer_in)
# 3x3 max pooling
pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in)
# concatenate filters, assumes filters/channels last
layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1)
return layer_out
# define model input
visible = Input(shape=(256, 256, 3))
# add inception module
layer = naive_inception_module(visible, 64, 128, 32)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
# plot model architecture
plot_model(model, show_shapes=True, to_file='naive_inception_module.png')
الأسطر من 2- 7: يتم استدعاء التوابع من مكتبات كيراس في بايثون مثل تابع بناء طبقة الدخل Input وتابع بناء طبقة الطّيّConv2D وتابع بناء طبقة التجميع MaxPooling2D من مكتبة layers والتابع plot_model من مكتبة utils بالإضافة إلى التابع Model من مكتبة models والتابع concatenate لدمج الطبقات الناتجة.
الأسطر من 10-21: يتم تعريف وحدة انسبشن المشروحة في المقطع البرمجي السابق.
السطر 24: يتم استخدام التابع Input لبناء طبقة الدخل visible من مصفوفة ثلاثية الأبعاد 3×256×256 تدل على صورة ملونة بأبعاد 256×256 وبثلاثة مركبات لونية.
السطر 26: يتم استخدام وحدة انسبشن من ثلاث طبقات طّيّ متوازية وعدد مرشحات الطّيّ في الطبقات هي
64، 128، 32 على التوالي من أجل أبعاد المرشحات 1×1، 3×3، 5×5 على التوالي، ودخلها هو الطبقة visible وخرجها هو الطبقة layer.
السطر 28: يتم بناء النموذج بحيث دخله هو الطبقة visible وخرجه هو الطبقة الناتجة عن استخدام وحدة انسبشن layer.
السطر 30: يظهر ملخص عن النموذج الذي تم بناؤه.
السطر 32: طباعة النموذج.
بتنفيذ المثال وإظهار ملخص بنية الشبكة نلاحظ بنية النموذج كما يلي:
:الملخص
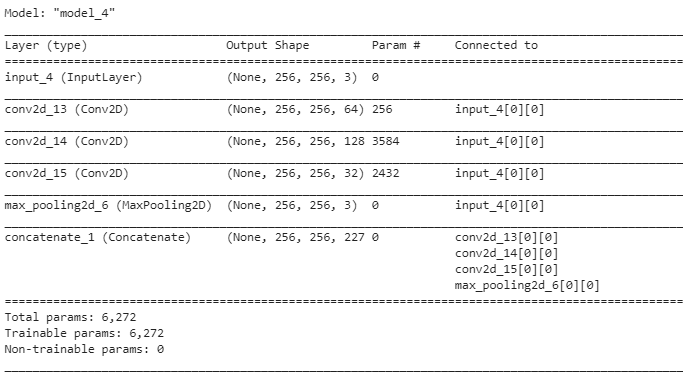
إن الملخص لا يظهر البنية المتوازية للنموذج فتتم طباعة النموذج لتظهر بنية النموذج المتوازية كما يلي:

سميت النسخة المنفذة من وحدة انسبشن باسم وحدة انسبشن البسيطة naive inception module، وقد تم تعديل هذه النسخة لتقليل كمية العمليات الحسابية المطلوبة، وذلك بإضافة طبقات طّيّ بحجم 1×1 لتقليل عدد مرشحات الطّيّ قبل طبقات الطّيّ ذات الأحجام 3×3 و 5×5 ولزيادة عدد مرشحات الطّيّ بعد طبقة التجميع. تحتاج هذا التعديل الحسابي المعتمد على الأداء إذا كنت تنوي استخدام عدد من وحدات انسبشن في بناء النموذج الخاص بك.
توضح القطعة البرمجية التالية تابع تنفيذ التحسين على وحدة انسبشن البسيطة بوجود معاملات للتحكم بكمية تقليل عدد مرشحات الطّيّ التي تسبق طبقات الطّيّ ذات الحجم 3×3 و5×5 والتحكم بزيادة عدد مرشحات الطّيّ بعد طبقة التجميع وفق القيمة الأكبر.
# function for creating a projected inception module
def inception_module(layer_in, f1, f2_in, f2_out, f3_in, f3_out, f4_out):
# 1x1 conv
conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in)
# 3x3 conv
conv3 = Conv2D(f2_in, (1,1), padding='same', activation='relu')(layer_in)
conv3 = Conv2D(f2_out, (3,3), padding='same', activation='relu')(conv3)
# 5x5 conv
conv5 = Conv2D(f3_in, (1,1), padding='same', activation='relu')(layer_in)
conv5 = Conv2D(f3_out, (5,5), padding='same', activation='relu')(conv5)
# 3x3 max pooling
pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in)
pool = Conv2D(f4_out, (1,1), padding='same', activation='relu')(pool)
# concatenate filters, assumes filters/channels last
layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1)
return layer_out
حيث يتم التعديل على تابع تعريف وحدة انسبشن البسيطة بالأسطر التالية:
السطر الثاني: يتم التصريح عن تابع تعريف وحدة انسبشن المحسنة ولها سبع معاملات دخل حيث يمثل المعامل الأول مؤشر لطبقة الدخل layer_in، ويمثل المعامل الثاني f1 عدد مرشحات الطّيّ في طبقة الطّيّ 1×1 أما المعامل الثالث f2_in فيمثل عدد مرشحات الطّيّ في طبقة الطّيّ 1×1 التي ستضاف قبل طبقة الطّيّ 3× 3 ويمثل المعامل الرابع f2_out عدد مرشحات الطّيّ في طبقة الطّيّ 3×3، كما يمثل المعامل الخامس f3_in عدد مرشحات الطّيّ في طبقة الطّيّ 1×1 التي ستضاف قبل طبقة الطّيّ 5× 5 أما المعامل السادس f3_out فيدل على عدد مرشحات الطّيّ في طبقة الطّيّ 5×5، وأخيرا يدل المعامل السابع f4_out على عدد مرشحات الطّيّ في طبقة الطّيّ 1×1التي ستضاف بعد طبقة التجميع وفق القيمة الأكبر، ويعيد التابع مؤشر لطبقة دمج الطبقات المتوازية المستخدمة في وحدة البناء.
السطر السادس والتاسع والثالث عشر: يتم استخدام التابع Conv2D لإضافة طبقات طّيّ بحجم 1×1 وبعدد مرشحات طّيّ محدد بمعاملات الدخل قبل طبقتي الطّيّ 1×1 , 5×5 وبعد طبقة التجميع.
الآن ..
يمكننا إنشاء نموذج يحتوي على وحدتي انسبشن محسنة للحصول على فكرة واقعية عن بنية النموذج من الناحية العملية، وفي هذه الحالة فإن تكوين عدد مرشحات الطّيّ سيكون كما في انسبشن(3a) و انسبشن(3b) الموضحة في الجدول [1].
1- # example of creating a CNN with an efficient inception module
2- from keras.models import Model
3- from keras.layers import Input
4- from keras.layers import Conv2D
5- from keras.layers import MaxPooling2D
6- from keras.layers.merge import concatenate
7- from keras.utils import plot_model
8-
9- # function for creating a projected inception module
10- def inception_module(layer_in, f1, f2_in, f2_out, f3_in, f3_out, f4_out):
11- # 1x1 conv
12- conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in)
13- # 3x3 conv
14- conv3 = Conv2D(f2_in, (1,1), padding='same', activation='relu')(layer_in)
15- conv3 = Conv2D(f2_out, (3,3), padding='same', activation='relu')(conv3)
16- # 5x5 conv
17- conv5 = Conv2D(f3_in, (1,1), padding='same', activation='relu')(layer_in)
18- conv5 = Conv2D(f3_out, (5,5), padding='same', activation='relu')(conv5)
19- # 3x3 max pooling
20- pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in)
21- pool = Conv2D(f4_out, (1,1), padding='same', activation='relu')(pool)
22- # concatenate filters, assumes filters/channels last
23- layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1)
24- return layer_out
25- # define model input
26- visible = Input(shape=(256, 256, 3))
27- # add inception block 1
28- layer = inception_module(visible, 64, 96, 128, 16, 32, 32)
29- # add inception block 1
30- layer = inception_module(layer, 128, 128, 192, 32, 96, 64)
31- # create model
32- model = Model(inputs=visible, outputs=layer)
33- # summarize model
34- model.summary()
35- # plot model architecture
36- plot_model(model, show_shapes=True, to_file='inception_module.png')
عند تنفيذ المثال نحصل على ملخص خطي للطبقات كما يلي:
الملخص:
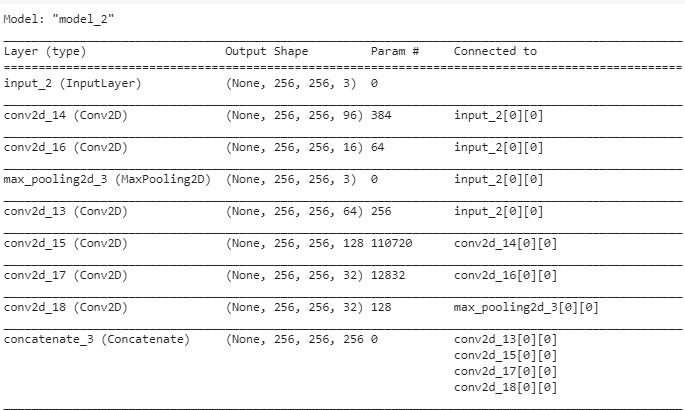
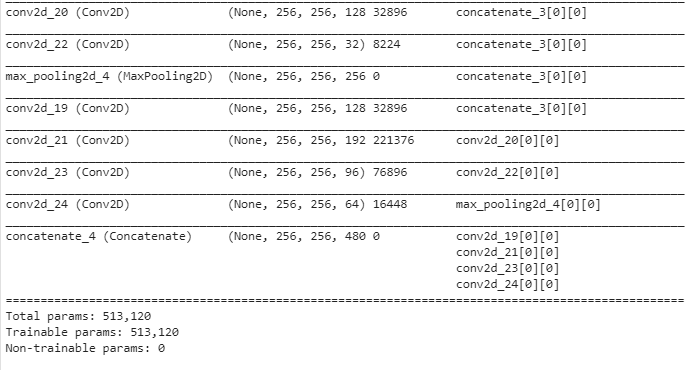
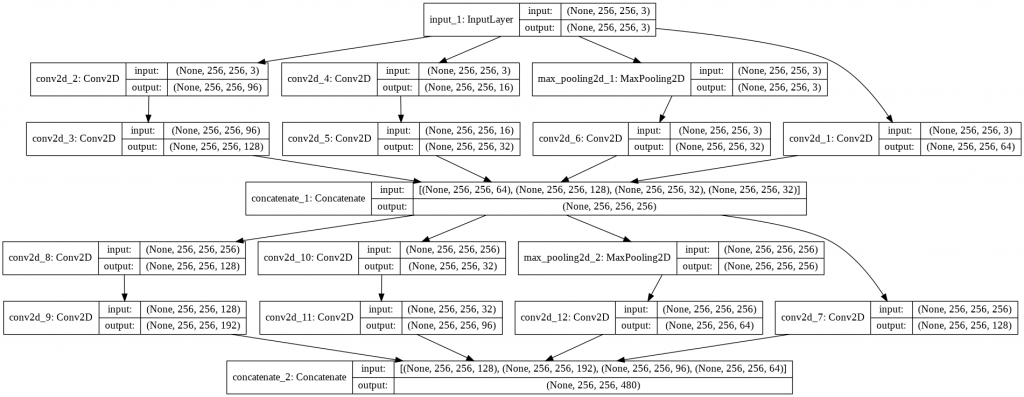
إنّ طباعة بنية النموذج تظهر تخطيط النموذج بشكل أوضح وتوضح كيف تمر المعلومات من وحدة الانسبشن الأولى إلى الوحدة الثانية مع ملاحظة أن طبقة الطّيّ ذات الحجم 1×1 في كل وحدة انسبشن تكون على اليمين بسبب توفير المساحة إلا أن باقي الطبقات تكون منتظمة على يسار كل وحدة انسبشن.
تنفيذ الوحدة الراسبة Residual Module
اقترحت شبكة الرواسب Residual Network ResNet لبناء شبكة الطّيّ العصبونية CNN من قبل كيمنغهي ورفاقه في الورقة البحثية [3] بعنوان “تعليم الراسب العميق للتعرف على الصور” “Deep Residual Learning for Image Recognition,” الذي حقق نجاح كبير في تحدي التعرف البصري واسع النطاق للرؤية الحاسوبية للعام 2015 ILSVRC-2015 .
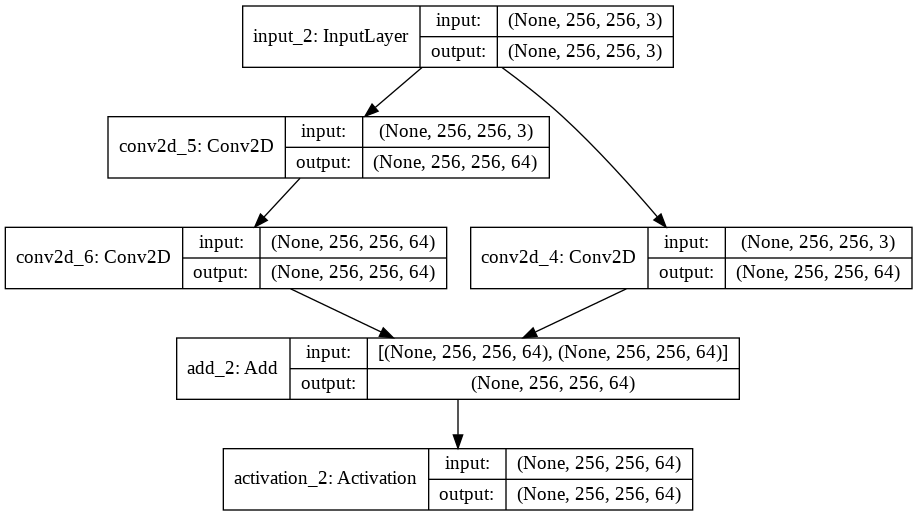
الفكرة الأساسية في شبكة الرواسب هي وحدة الراسب residual module. وحدة الراسب وبشكل أكثر خصوصية، نموذج الراسب المعرّّف identity residual mode هو كتلة من طبقتي طّيّ لهما نفس عدد مرشحات الطّيّ وبعد مرشح صغير حيث يضاف خرج الطبقة الثانية مع دخل الطبقة الأولى وبالرسم البياني فإن دخل وحدة الراسب يٌجمَع مع خرجها ويسمى “وصلة الاختصار” “a shortcut connection”.
يمكن تنفيذ وحدة الراسب باستخدام توابع مكتبة كيراس في بايثون واستدعاء تابع الدمج ()add كما يلي:
# function for creating an identity residual module
def residual_module(layer_in, n_filters):
# conv1
conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in)
# conv2
conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1)
# add filters, assumes filters/channels last
layer_out = add([conv2, layer_in])
# activation function
layer_out = Activation('relu')(layer_out)
return layer_out
السطر الثاني: معاملات الدخل لتابع بناء وحدة الراسب وهي طبقة الدخل layer_in وعدد مرشحات الطّيّ n_filters .
السطر الرابع: بناء شبكة طّيّ بتابع تفعيل relu وعدد مرشحات طّيّ مطابق لمعامل الدخل وتهيئة بدائية للأوزان
he-normal وبحجم 3×3 وحشو صفري same.
السطر السادس: بناء شبكة طّيّ خطية بتابع التفعيل الخطي linear وعدد مرشحات طّيّ مطابق لمعامل الدخل وتهيئة بدائية للأوزان he-normal وبحجم 3×3 وحشو صفري same.
السطر الثامن: استدعاء التابع add لإضافة خرج طبقة الطّيّ الثانية مع دخل طبقة الطّيّ الأولى.
السطر العاشر: تطبيق تابع التفعيل relu على الطبقة الناتجة.
إنّ محدودية تنفيذ هذا التابع هي وجود خطأ عندما لا يتطابق عدد المرشحات في طبقة الدخل مع عددها في طبقة الطّيّ الأخيرة في وحدة الراسب والمحددة بمعامل الدخل n_filters .
وكان الحل هو إضافة طبقة طّيّ بحجم 1×1 يشار إليها بطبقة تحوير”a projection layer” بهدف زيادة عدد مرشحات طبقة الدخل أو لتقليل عدد مرشحات الطّيّ في طبقة الطّيّ الأخيرة. الحل منطقي وهو التطبيق المقترَح في البحث [3] ويشار إليه بالاختصار المحوَّر a projection shortcut.
توضح القطعة البرمجية التالية النسخة المطوَّرة من تابع تعريف وحدة الراسب Residual Module حيث يتم استخدام المعرًَف إن أمكن أو استخدام التحوير لعدد مرشحات الطّيّ في طبقة الدخل التي لا تتطابق مع معامل عدد المرشحات n_filters.
# function for creating an identity or projection residual module
def residual_module(layer_in, n_filters):
merge_input = layer_in
# check if the number of filters needs to be increased, assumes channels last format
if layer_in.shape[-1] != n_filters:
merge_input = Conv2D(n_filters, (1,1), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in)
# conv1
conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in)
# conv2
conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1)
# add filters, assumes filters/channels last
layer_out = add([conv2, merge_input])
# activation function
layer_out = Activation('relu')(layer_out)
return layer_out
بشكل مماثل لبنية نموذج الراسب المعرّّف مع اختلاف في السطرين التاليين:
السطر الخامس: يفحص فيما إذا كان عدد المرشحات في طبقة الدخل يحتاج إلى زيادة مع الأخذ بعين الاعتبار أن تنسيق قنوات الصورة هو الأخير.
السطر السادس: يتم إضافة طبقة تحوير وهي طبقة طّيّ ببعد 1×1 وبتابع تفعيل relu وحشو صفري من نوع same وتهيئة بدائية للأوزان he_normal.
ويمكن وصف استخدام وحدة الراسب في بناء نموذج بسيط كما يلي:
# example of a CNN model with an identity or projection residual module
from keras.models import Model
from keras.layers import Input
from keras.layers import Activation
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import add
from keras.utils import plot_model
# function for creating an identity or projection residual module
def residual_module(layer_in, n_filters):
merge_input = layer_in
# check if the number of filters needs to be increased, assumes channels last format
if layer_in.shape[-1] != n_filters:
merge_input = Conv2D(n_filters, (1,1), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in)
# conv1
conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in)
# conv2
conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1)
# add filters, assumes filters/channels last
layer_out = add([conv2, merge_input])
# activation function
layer_out = Activation('relu')(layer_out)
return layer_out
# define model input
visible = Input(shape=(256, 256, 3))
# add vgg module
layer = residual_module(visible, 64)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
# plot model architecture
plot_model(model, show_shapes=True, to_file='residual_module.png')
نلاحظ من المثال السابق أن معامل عدد المرشحات يساوي 64 وبالتالي عند استدعاء تابع تعريف وحدة الراسب يتم استخدام وحدة الراسب مع طبقة التحوير لزيادة عدد مرشحات الدخل من 3 إلى 64 من أجل استدعاء التابع add لجمع دخل طبقة الطّيّ الأولى بعدد المرشحات 64 مع خرج طبقة الطّيّ الثانية بعدد مرشحات طّيّ 64 ويظهر ذلك بشكل واضح في الشكل(5).
بتنفيذ المثال وإظهار ملخص عن النموذج الذي سيكون مفيد لأن وحدة الراسب خطية.
الملخص:
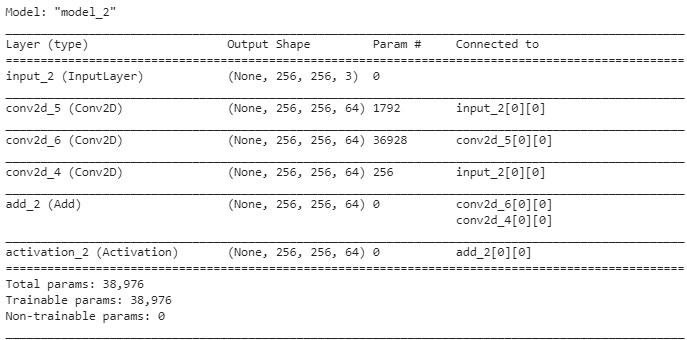
و بطباعة النموذج نلاحظ تضخم عدد مرشحات الطّيّ في الدخل بالإضافة لوجود عنصرين في نهاية وحدة الراسب.
يمكنك عزيزي القارئ الوصول إلى الشيفرة البرمجية (ورقة جوبيتر) من هنـــا.
الخاتمة
الآن أصبحت ملماً بكيفية تنفيذ عناصر بناء أساسية ومختلفة مستخدمة في بناء شبكة الطّيّ العصبونية .
كما أصبحت ملماً بتطوير وحدات مجموعة الهندسة المرئية و وحدات انسبشن ووحدات الرواسب باستخدام مكتبة كيراس في لغة البرمجة بايثون.
هل كان هذا البرنامج التعليمي مفيداً لك؟
هل كان البرنامج التعليمي ممتعاً؟
أرجو ذلك.. يمكنك طرح الأسئلة عن الموضوع وسأبذل جهدي للإجابة عنها.
المراجع
[1] SIMONYAN, Karen; ZISSERMAN, Andrew. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[2] SZEGEDY, Christian, et al. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. P. 1-9.
[3] HE, Kaiming, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770-778.
[4] KRIZHEVSKY, Alex; SUTSKEVER, Ilya; HINTON, Geoffrey E. Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems. 2012. p. 1097-1105.




