إعداد: م. عمّار وضّاح
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. ماريّا حماده
المَحتويَات
المقدّمة
شهد مجال التّعلّم العميق (Deep Learning) في السّنوات الأخيرة طفرةً غير مسبوقةٍ أحدثت تغييرات جذريّة في مجالاتٍ متنوّعةٍ، بدءًا من معالجة اللّغات الطّبيعيّة (Natural Language Processing=NLP) وصولًا إلى الرّؤية الحاسوبيّة (Computer Vision=CV). لم يقتصر تأثير هذه التّكنولوجيا التّحويليّة على تحقيق تقدّماتٍ علميّةٍ ملموسةٍ فحسب، بل فتح أيضًا آفاقًا جديدةً أمام مختلف التّخصّصات. بفضل قدرتها على تمكين الآلات من التّعلّم من البيانات؛ أصبحت هذه النّماذج قادرةً على فهم المعلومات المعقّدة، التّنبّؤ بها، واتّخاذ قراراتٍ دقيقةٍ بدرجةٍ غير مسبوقةٍ [1].
إلّا أنّ تطبيق هذه النّماذج في الواقع العملي يواجه تحدّياتٍ كبيرة، لا سيّما فيما يتعلّق بالقيود المتعلّقة بالذّاكرة وكفاءة التّدريب، وعلى وجه الخصوص عند التعامل مع نماذج ضخمة أو تدريب مجموعات بيانات كبيرة [2]. في هذا السّياق، نعرض في هذا المقال أبرز هذه المشاكل، مع تسليط الضّوء على طريقتين شائعتين لمعالجتها: نقاط تحقّق التّدرّج (Gradient Checkpointing) وتراكم التدرّج (Gradient Accumulation). ومقارنة أساسية فيما بينهم، مع بيان كيف يمكن لكل منهما المساهمة في التغلّب على محدوديّات الموارد وتحقيق كفاءة أعلى في التّدريب.
تحدّي الذّاكرة في التّعلّم العميق
رغم التّقدّم المتسارع، برزت تحدّيات كبيرة أبرزها استهلاك الذّاكرة المفرط أثناء تدريب الشّبكات العصبونيّة العميقة (Deep Neural Networks) [2]، حيث تُعدّ خوارزميّة الانتشار الخلفيّ (Backpropagation) (المسؤولة عن حساب تدرّجات الأوزان وتحديثها) من أكثر العمليّات استهلاكًا للذّاكرة، خاصّةً في الشّبكات العصبونيّة العميقة جدًّا (Deep Neural Networks). ومع ازدياد حجم النّماذج وازدياد تعقيدها، تزداد الحاجة إلى سعة ذاكرةٍ أكبر، ممّا قد يُصبح عقبةً رئيسيّةً تعوق تدريب نماذج أكبر وأكثر تطوّرًا على الأجهزة الحاليّة [1].
فمع اتّساع نطاق هذه النّماذج وتعقّدها، أصبحت تضمّ ملايين المعاملات القابلة للتّدريب بالإضافة لطبقاتٍ متعدّدةٍ، ممّا يفرض ضغطًا هائلًا على موارد الذّاكرة خلال مرحلتي الانتشار الأماميّ والخلفيّ [1].
في الشّبكات العصبونيّة العميقة، تتطلّب عمليّة الانتشار الخلفيّ موارد حسابيّة هائلة لمعالجة جميع التّفعيلات الوسيطيّة (Intermediate activations). وكلّما زاد عدد المعاملات في النّموذج، ازدادت العمليّات الحسابيّة المطلوبة، ممّا يؤدّي بدوره إلى استهلاكٍ متزايدٍ للذّاكرة العشوائيّة [2]. وكلّما كبر حجم النّموذج، زادت حدَّة المشكلة حتّى أصبحت الأخطاء، مثل: “نفاد الذّاكرة” شائعةً عند استخدام وحدات معالجة الرّسومات (GPUs)، ممّا يعيق عمليّة التّدريب ويحدّ من تطوير نماذج أكثر تطوّرًا [2].
فهم تقنيّة نقاط تحقّق التّدرّج
تُعدّ تقنيّة نقاط تحقّق التّدرّج (Gradient Checkpointing) وما تتضمّنه من الحفظ المرحليّ (Checkpointing) للنّموذج إحدى طرق التّحسين المستخدمة في التّعلّم العميق؛ لخفض استهلاك الذّاكرة خلال مرحلة الانتشار الخلفيّ. تعتمد هذه التّقنيّة على تحديد نقاط تحقّقٍ محدّدةٍ في الشّبكة العصبونيّة (Neural Network)، حيث يتمّ حفظ التّفعيلات الوسيطيّة الأكثر أهمّيّة فقط في هذه النّقاط، بدلًا من تخزينها جميعًا. وبذلك تقلّ الحاجة إلى الذّاكرة بشكلٍ كبيرٍ من دون التّضحية بكفاءة النّموذج [1].
تعمل هذه التّقنيّة على إيجاد توازنٍ بين استخدام ذاكرة الوصول العشوائيّ (RAM) والوقت الحسابيّ المطلوب أثناء عمليّة الانتشار الخلفيّ لتحديث الأوزان [2].
آليّة عمل تقنيّة نقاط تحقّق التّدرّج
تقدّم تقنيّة نقاط تحقّق التّدرّج حلًّا ذكيًّا لمشكلة استهلاك الذّاكرة عبر إعادة حساب جزءٍ مختارٍ من التّنشيطات الوسيطيّة أثناء الانتشار الخلفيّ، بدلًا من تخزينها جميعًا. تعتمد الفكرة على تخزين نقاط الحفظ المرحليّ للنّموذج فقط في الذّاكرة، بينما تتمّ إعادة حساب باقي القيم عند الحاجة باستخدام أقرب نقطةٍ محفوظةٍ [2].
ميّزة هذه الطّريقة أنّها تتيح تدريب نماذج أعمق باستخدام نفس الموارد العتاديّة، ممّا يفتح المجال لتجارب أكثر تقدّمًا في مجال التّعلّم العميق [2].
أثناء المرور الأماميّ (Forward Pass):
- يتمّ حفظ التّفعيلات الوسيطيّة فقط عند نقاط الحفظ المرحليّ المحدّدة مسبقًا في الشّبكة [1].
- يتمّ تجاهل التّفعيلات (Activations) في الطّبقات الأخرى بعد استخدامها مباشرةً، ممّا يقلّل بشكلٍ كبيرٍ من استهلاك الذّاكرة [1].
أثناء المرور الخلفيّ (Backward Pass):
- تُعاد حساب التّفعيلات الوسيطيّة المفقودة بدءًا من أقرب نقطة حفظٍ مرحليٍّ [1].
- تُحسب التّدرّجات (Gradients) فقط للطّبقات الّتي تمّ تحديدها كنقاط حفظٍ مرحليٍّ، مع إعادة بناء القيم الوسيطيّة المطلوبة للطّبقات (Layers) الأخرى عند الحاجة [1].
وبهذه الطّريقة، تقلّل التّقنيّة بشكلٍ كبيرٍ من متطلّبات الذّاكرة، حيث لا يتمّ تخزين سوى مجموعةٍ محدودةٍ من القيم الوسيطيّة. لكنّ هذا التّوفير في الذّاكرة يأتي على حساب زيادةٍ في الوقت الحسابيّ، إذ تتطلّب العمليّة إعادة حساب بعض القيم أثناء الانتشار الخلفيّ [1].
يعتمد اختيار نقاط التّخزين المثاليّ على عاملين رئيسيّين هما [1]:
- سعة الذّاكرة المتاحة.
- التّوازن المطلوب بين سرعة التّنفيذ واستهلاك الموارد.
التّمثيل الرّياضيّ
إنّ الفكرة الأساسيّة لتقنيّة نقاط تحقّق التّدرّج تعتمد على تقسيم عمليّة حساب التّدرّجات إلى مراحل أصغر. تخيّل أنّه لدينا شبكةٌ عصبونيّةٌ عميقةٌ مكوّنةٌ من N طبقة، مع تحديد نقاط حفظٍ مرحليٍّ عند طبقاتٍ معيّنةٍ، يمكن حساب التّدرّجات كالتّالي [1]:
- يتمّ تقسيم الشّبكة إلى مقاطع (segments) بناءً على نقاط الحفظ المرحليّ.
- يحسب كل قطاع تدرّجات الجزء الخاص به فقط.
- يتمّ جمع التّدرّجات الجزئيّة للحصول على التّدرّج الكلّيّ.
رياضيًّا، يمكن التّعبير عنها بالمعادلة التّالية:
المعادلة (1): [1]
∇L/∇θ = ∇L/∇θ₁ + ∇L/∇θ₂ + ... + ∇L/∇θₖ
حيث:
- L/∇θ∇ تمثّل التّدرّج لدالّة الخسارة بالنسبة لجميع بارامترات النّموذج.
- θ₁, θ₂, …, θₖ هي مجموعة البارامترات المرتبطة بنقاط الحفظ المرحليّ.
إنّ كلّ L/∇θᵢ∇ يحسب تدرّجات الجزء الخاصّ به من الشّبكة.
فوائد وإيجابيّات استخدام تقنيّة نقاط تحقّق التّدرّج
تقدّم تقنيّة نقاط تحقّق التّدرّج فوائد استثنائيّة تجعلها أداةً لا غنى عنها في تدريب النّماذج العميقة. تمثّل التّقنيّة نقلةً نوعيّةً في كفاءة تدريب النّماذج العميقة، حيث تجمع بين ثلاث مزايا رئيسيّة هي:
- كفاءة ذاكرةٍ غير مسبوقةٍ.
تقلّل التّقنيّة بشكلٍ جذريٍّ من استهلاك الذّاكرة أثناء الانتشار الخلفيّ، حيث تقوم بتخزين التّفعيلات الوسيطيّة فقط في طبقات نقاط الحفظ المرحليّ المحدّدة. هذا الأسلوب الذّكيّ يتيح تدريب نماذج أعمق بكثير من دون مواجهة مشاكل نفاد الذّاكرة (Out Of Memory=OOM)، خاصّةً عند العمل مع النّماذج الضّخمة ذات الملايين من المعاملات [1] [2]. - تمكين النّماذج فائقة العمق (Increased Model Depth).
بفضل هذه التّقنيّة، أصبح بالإمكان تدريب شبكاتٍ عصبونيّةٍ أعمق تتفوّق في أدائها والّتي كانت تعتبر غير عمليّة سابقًا بسبب قيود الذّاكرة. هذا يفتح آفاقًا جديدةً لاستكشاف معماريّاتٍ أكثر تعقيدًا في مجالات، مثل: نماذج المحوّلات (Transformers) وشبكات الطّيّ العصبونيّة (Convolutional Neural Networks) المتطوّرة [1] [2]. - مرونةٌ تصميميّةٌ فائقةٌ (Flexibility).
تمنح التّقنيّة الباحثين حرّيّةً استراتيجيّةً في:
- تحديد مواقع نقاط الحفظ المرحليّ المثلى.
- الموازنة بين استهلاك الذّاكرة والوقت الحسابيّ.
- التّكيّف مع مواصفات العتاد المتاح.
إنّ هذه المرونة تجعل التّقنيّة قابلةً للتّطبيق في مختلف السّيناريوهات، من الأجهزة محدودة الموارد إلى أنظمة الحوسبة الفائقة [1] [2]. ويوضّح الشّكل (1) التّالي، تقنيّة نقاط تحقّق التّدرّج
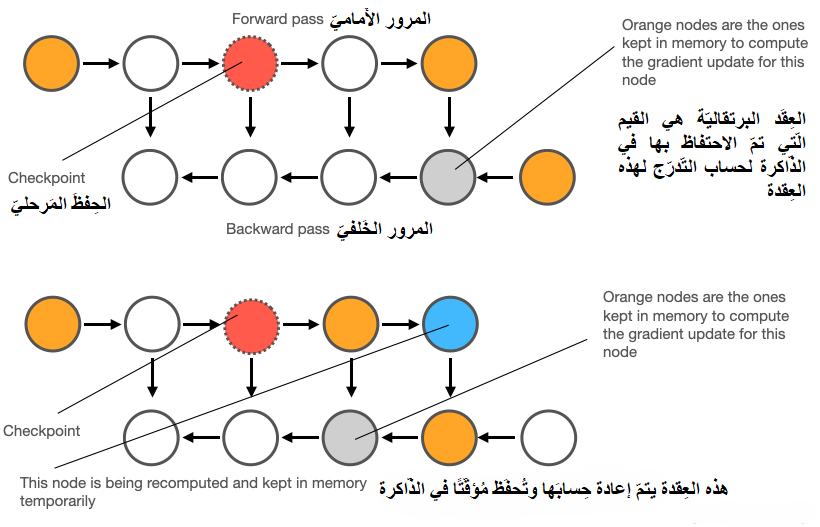
يُشير الجزء العُلويّ من الشَّكل (1) (عمليّتَيِ المُرور الأَماميّ والخَلفيّ):
Forward pass (المرور الأَماميّ): هُنا تَتِمّ عمليّة حِساب مُخرَجات النّموذَج من خلال التّمرير من المُدخلات وحتّى المُخرَجات.
Backward pass (المرور الخَلفيّ): يتمّ حِساب التّدرّجات لِتَحديث الأوزان من المُخرَجاتِ وحتّى المُدخلات.
Checkpoint (الحِفظُ المَرحليّ): هي نُقطَة يتمّ فيها حفظ بعض القيم مُؤقّتًا لاستخدامها لاحقًا، بدَلًا من حفظ كلّ القيم في الذّاكرة، مِمّا يُقلّل من استهلاك الذّاكرة.
العقَد البرتقاليّة: هي القيم الّتي تمّ الاحتفاظ بها في الذّاكرة لحساب التّدرّجاتِ لاحقًا.
العقَد البَيضاء: لَم يتمّ الاحتِفاظ بِها في الذّاكرة.
كَمَا يُشير الجزء السّفليّ من الشّكل (1) (إِعادة الحساب):
العقَد غَير المخَزّنَة (البَيضاء) يتمّ إعادة حِسابِها مُؤقّتًا (العقَد الزّرقاء) أثناء المُرور الخلفيّ عِند الحاجة إِلى تِلكَ العقَد، وبالتّالي تَوفير الذّاكرة عَن طريق إعادة الحِساب بَدَل تَخزين كُلّ شَيءٍ.
وهكذا نرى أنّ تقنيّة نقاط تحقّق التّدرّج تسعى للتّخفيف من مشكلة “عنق الزّجاجة” (Bottleneck) في الذّاكرة من خلال تخزين جزءٍ محدّدٍ فقط من تفعيلات الطّبقات، بدلًا من من حفظها جميعًا. وتعيد حساب التّفعيلات المفقودة عند الحاجة أثناء المرور الخلفيّ، وبالتّالي هذا التّوازن بين الذّاكرة والحساب يتيح تدريب نماذج أكبر بكثير (حتّى 4 إلى 10 أضعافٍ) مقارنةً بما تسمح به ذاكرة وحدة معالجة الرّسوميّات عادةً [1] [2].
ومع ذلك، هناك مقايضةٌ (Trade-off): فكلّما قلَّ عدد النّقاط المرحليّة المحفوظة، زادت الحاجة إلى إعادة الحساب، ممّا يزيد الحمل الحسابيّ ويبطئ التّدريب؛ لذلك، تُحدّد النّقاط المثلى (مثل حفظ كلّ n√ طبقة) لتحقيق توازنٍ بين استهلاك الذّاكرة والسرعة. ونتيجةً لذلك، تصبح النّماذج _الّتي كان من المستحيل تشغيلها سابقًا بسبب قيود الذّاكرة_ قابلةً للتّدريب بكفاءةٍ [1] [2].
المقارنة مع التّقنيّات المرتبطة
لمحةٌٌ عن تراكم التّدرّج (Gradient Accumulation)
هو أسلوبٌ يُستخدم لتجاوز قيود الذّاكرة عند تدريب النّماذج الكبيرة أو معالجة كمّياتٍ كبيرةٍ من البيانات. في التّدريب التّقليديّ، يتمّ حساب تدرّجات معاملات النّموذج (Parameters) وتحديثها بعد كلّ دفعةٍ من البيانات. لكن في هذه التّقنيّة، بدلًا من تحديث المعاملات بعد كلّ دفعةٍ، يتمّ تجميع التّدرّجات عبر عدّة دفعاتٍ قبل إجراء التّحديث النّهائيّ. وهذا يُقلّل من استهلاك الذّاكرة، ممّا يُسهّل تدريب نماذج أكبر أو التّعامل مع أحجام بياناتٍ أعلى [2].
على سبيل المثال، إذا تمّ ضبط تراكم التّدرج ليعمل على 4 دفعاتٍ (Batches)، فسيتمّ جمع تدرّجات معاملات النّموذج عبر هذه الدّفعات الأربع، ثمّ يتمّ تحديث الأوزان مرّةً واحدةً فقط بعد اكتمال التّراكم. هذا الأسلوب يُخفّض العبء على الذّاكرة عبر تقليل عدد عمليّات التّحديث، ممّا يُمكّن من تدريب النّماذج بدُفعاتٍ أكبر أو التّعامل مع نماذج أكثر تعقيدًا [2].
وبشكلٍ عام، تُعدّ تقنيّة تراكم التّدرّج (Gradient Accumulation) إحدى طرق التّعلّم العميق؛ لتحسين كفاءة حجم الدّفعات أثناء التّدريب. ففي التّدريب العادي، يتمّ تعديل أوزان الشّبكة العصبونيّة بناءً على تدرّجات دفعةٍ واحدةٍ (Batch) من البيانات. لكن في النّماذج الضّخمة، يكون حجم الدّفعة محدودًا بسعة ذاكرة وحدة معالجة الرّسوميّات، ممّا قد يُطيل زمن التّدريب ويُبطئ عمليّة التّقارب بسبب قيود الحساب الشّعاعيّ [2].
ويُعتمد عليها عادةً لمحاكاة تأثير التّدريب بدُفعاتٍ ضخمةٍ، مع الحفاظ على استهلاك الذّاكرة عند المستوى ذاته الّذي كان سيكون عليه بدون استخدام التّقنيّة [1].
ويُوضِّح الشّكل (2) تَوضيحًا لِتِقنيّة تَراكُم التَّدرُّج.

يُشير مُحتوَى الشّكل (2) إِلى:
الدّفعَة العامّة (GLOBAL BATCH): هي الدّفعَة ذات الحَجم الكَبير الّتي نُريد استِخدامَها فِعليّا في التّحديث، ولَكن لا يُمكِن تَحميلها على شكل دفعَة واحِدة بِسَبَب قُيود الذّاكرة.
الدّفعَة المُصَغّرة (MINI-BATCH): يتمّ تَقسيم الدّفعَة الكامِلَة إِلى دفعات صغيرة (0، 1، 2، 3) تُمرّر بِشَكل مُتَتال عَبر وحدة معالجَة الرّسومات (GPU).
grad0، grad1، grad2، grad3: هي التّدرّجات الّتي يتَمّ حِسابها من كُلّ دفعَة مُصَغَّرَة.
تَدرّجات الدّفعَة العامّة (GLOBAL BATCH GRADIENTS): يتمّ تَجميع هذه التّدرّجاتِ على مَدى الزّمَن، ثمّ يتمّ استِخدامها لِتَحديث أوزان النّموذَج كَأنّها ناتِجَة عن الدّفعَة الكاملَة.
الزّمَن (Time): يُشير إِلى أنّ التّجميع يتمّ على مَراحِل، عبر مُرور الزّمن.
المقارنة بين كلٍّ من تقنيّة نقاط تحقّق التّدرّج وتراكم التّدرّج في التّعلّم العميق
على الرّغم من أنّ كلًّا من نقاط تحقّق التّدرّج وتراكم التّدرّج تُستخدمان للتّغلّب على قيود الذّاكرة في التّدريب، إلّا أنّهما تختلفان جوهريًّا في الآليّة والغرض [1]:
نقاط تحقّق التّدرّج.
- التّركيز: تحسين استخدام الذّاكرة أثناء المرور الخلفيّ.
- الآليّة:
- تخزينٌ انتقائيٌّ لعمليّات التّفعيل في طبقات محدّدة لنقاط الحفظ المرحليّ.
- إعادة حساب التّفعيلات غير المخزّنة عند الحاجة أثناء الانتشار الخلفيّ.
تراكم التّدرج.
- التّركيز: تمكين استخدام دفعاتٍ فعّالةٍ كبيرةٍ خلال المرور الأماميّ.
- الآليّة:
- تجميع التّدرّجات عبر عدّة دفعاتٍ صغيرةٍ.
- تأجيل تحديث الأوزان حتّى اكتمال التّراكم.
| Gradient Accumulation | Gradient Checkpointing | المعيار |
| التّمرير الأماميّ والخلفيّ | الانتشار الخلفيّ | مرحلة التّأثير |
| ذاكرة التّدرّجات | ذاكرة التّفعيلات | الكفاءة |
| زيادة وقت التّدريب | زيادة وقت الحساب | التّكلفة |
تطبيقاتٌ حقيقيّةٌ في تقنيّة نقاط تحقّق التّدرّج
وجدت تقنيّة نقاط تحقّق التّدرّج آثارًا إيجابيّةً في تطبيقات العالم الحقيقيّ، حيث تلعب الذّاكرة دورًا مهمًّا وحيويًّا فيها. هنا سوف نستعرض بعضًا من تطبيقاتها في العالم الحقيقيّ الّتي شغلت خلالها دورًا مهمًّا [1]:
الشّبكات العصبونيّة العميقة
تتميّز الشّبكات العصبونيّة العميقة بعمقها وتعقيدها، حيث أصبحت حجر الأساس في مجال التّعلّم الآليّ (Machine Learning) الحديث. وقد حقّقت تقدّمًا ملحوظًا في معالجة مهام متنوّعة تتراوح بين معالجة الصّور (Image Processing) وفهم اللّغة الطّبيعيّة (Natural Language Understanding). ولكنّ ذلك جاء مصحوبًا باستهلاكٍ كبيرٍ للذّاكرة أثناء عمليّة التّدريب [1].
وهنا تبرز أهمّيّة هذه التّقنيّة كحلٍّ لهذه المشكلة، حيث يمكنها تحسين تدريب الشّبكات العصبونيّة العميقة والمعقّدة، مثل:شَبَكَةُ الرَّواسِبِ (ResNets) بشكلٍ كبيرٍ. تعمل هذه التّقنيّة من خلال تحديد طبقاتٍ معيّنةٍ كـنقاط حفظٍ مرحليٍّ، ممّا يقلّل من استخدام الذّاكرة ويُمكّن من تدريب شبكاتٍ كبيرةٍ كانت مقيّدةً سابقًا بسبب محدوديّة الموارد [1].
نماذج المحوّلات
أحدثت نماذج المحوّلات ثورةً في مجال معالجة اللّغة الطّبيعيّة والمهام التّسلسليّة (Sequences)، حيث حقّقت نماذج، مثل: بيرت (BERT) والإصدار الثّالث من الجي بي تي (GPT-3) نتائج رائدة لأحدث ما توصّلت إليه التّقنيّة (state-of-the-art). ومع ذلك، واجهت هذه النّماذج تحدّيات تتعلّق بالطّلب الكبير على الذّاكرة، ممّا أثّر على انتشارها [1].
لحلّ هذه المشكلة، ظهرت تقنيّة نقاط تحقّق التّدرّج كأداةٍ فعّالةٍ للتّعامل مع قيود الذّاكرة. ومن خلال التّوزيع الاستراتيجيّ لنقاط حفظٍ مرحليٍّ داخل بنية النّموذج، يمكن للباحثين تحقيق توازنٍ بين استهلاك الذّاكرة والأداء الحسابيّ، ممّا يتيح تدريب نماذج محوّلاتٍ ضخمةٍ بكفاءةٍ أعلى [1].
الانتشار الخلفيّ المجزّئ
في العديد من التّطبيقات وخاصّةً تلك الّتي تتضمّن تعلّمًا معزّزًا (Reinforcement Learning) بمساراتٍ (Trajectories) طويلةٍ أو سلاسل زمنيّةٍ ممتدّةٍ، أثبتت تقنيّة الحفظ المرحليّ قيمتها الكبيرة في إدارة الذّاكرة بشكلٍ فعّالٍ. تواجه هذه التّطبيقات تحدّيًا رئيسيًّا يتمثّل في تمدّد السّلسلة الزّمنيّة، ممّا قد يؤدّي إلى استنزاف موارد الذّاكرة بشكلٍ كبيرٍ [1].
وتبرز هنا أهمّيّة تقنيّة نقاط تحقّق التّدرّج في تقديم حلٍّ عمليٍّ للانتشار الخلفيّ المجزّأ. فمن خلال تحديد نقاط حفظٍ مرحليٍّ استراتيجيّة عبر التّسلسل الزّمنيّ، يتمّ الحفاظ على استهلاك الذّاكرة تحت السّيطرة أثناء عمليّة التّدريب، ممّا يضمن قدرة النّموذج على التّعلّم بكفاءةٍ من السّلاسل الطّويلة دون الاصطدام بقيود الذّاكرة [1].
وتظهر التّطبيقات العمليّة في مجالاتٍ متنوّعةٍ، من معالجة الصّور إلى فهم اللّغة الطّبيعيّة. تكمن الأهمّية الحيويّة لهذه التّقنيّة في التّغلّب على تحدّيات الذّاكرة، ممّا يجعلها أداةً لا غنى عنها في تدريب النّماذج المعقّدة على البيانات الكبيرة [1].
التّطبيق العمليّ
تختلف كيفيّة تطبيق تقنيّة نقاط تحقّق التّدرّج باختلاف أطر عمل التّعلّم العميق المستخدمة، حيث توفّر معظم المكتبات الشّهيرة، مثل: بايتورش (PyTorch) ومكتبةُ تنسور فلو للتَّعلُّمِ العميقِ من جوجل (TensorFlow) واجهات برمجة التّطبيقات (APIs) جاهزة لدمج هذه التّقنيّة مع النّماذج المخصّصة [1].
أمثلةٌ توضيحيّةٌ باستخدام بايتورش:
<code>import torch
from torch.utils.checkpoint import checkpoint
# Define a custom model with checkpointed layers
class CustomModel(torch.nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.layer1 = torch.nn.Linear(512, 256)
self.layer2 = torch.nn.Linear(256, 128)
def forward(self, x):
# Checkpoint the computation in layer1
x = checkpoint(self.layer1, x)
x = torch.relu(x)
x = self.layer2(x)
return x
# Instantiate and train the model
model = CustomModel()
# ...</code>
نبدأ باستيراد المكتبات المطلوبة، بما في ذلك مكتبة بايتورش ودالّة (checkpoint) من:
torch.utils.checkpoint
ثمّ نُعرّف نموذجًا مخصّصًا باسم CustomModel، والّذي يعمل كمثالٍ توضيحيٍّ ويحتوي على طبقتين خطّيّتين [1].
في مرحلة المرور الأماميّ للنّموذج، استخدمنا دالّة (checkpoint) لتطبيق تقنيّة نقاط تحقّق التّدرّج. وتحديدًا، اخترنا تطبيق هذه التّقنيّة على الحسابات الّتي تتمّ في self.layer1.
يعني هذا القرار أنّه أثناء المرور الأماميّ، سيتمّ حفظ التّفعيلات الوسيطة للطّبقة الأولى فقط عند نقطة الحفظ المرحليّ المحدّدة [1].
كما يبيّن الكود الموضّح في المرجع [3]، أنّ استخدام نقاط الحفظ المرحليّ التّدرجيّة وتجميع التّدرّجات يُقلّل من استهلاك الذّاكرة، ولكنّه يُطيل من مدة التّدريب. وفقًا لـهاكينغ فيس [3] HuggingFace، فإنّ تطبيق نقاط الحفظ المرحليّ التّدرّجيّة يؤدّي عادًة إلى إبطاء سرعة التّدريب بنسبةٍ تقارب 20% [2].
<code>training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)</code>
وبالتّالي نتيجة تنفيذ هذه التّعليمات تتبع الشّكل التّالي:
<code>> BEFORE
Time: 66.03
Samples/second: 7.75
GPU memory: 8681 MB
> AFTER
Time: 85.47
Samples/second: 5.99
GPU memory occupied: 6775 MB.</code>
يوضّح هذا المثال طريقة تنفيذ تقنيّة نقاط تحقّق التّدرّج في نماذج بايتورش، حيث يمكن تكييف نفس المفاهيم مع أطر عمل التّعلّم العميق الأخرى، مثل: مكتبةُ تنسور فلو للتَّعلُّمِ العميقِ من جوجل. باتّباع هذه التّقنيّة، يصبح من الممكن تحسين كفاءة استخدام الذّاكرة، ممّا يتيح تدريب نماذج أعمق دون التّعرّض لقيود السّعة التّخزينيّة [2].
المخاطر المحتملة
على الرّغم من المزايا الكبيرة الّتي تقدّمها تقنيّة نقاط تحقّق التّدرّج، إلّا أنّها لا تخلو من بعض التّحدّيات المحتملة، ومن أبرزها:
- زيادة التّكلفة الحسابيّة:
تتطلّب هذه التقنيّة عمليّات حسابيّة إضافيّة بسبب تخزين واسترجاع التّفعيلات الوسيطة في طبقات الحفظ المرحليّ (Checkpoints Layers)، ممّا قد يؤدّي إلى إبطاء سرعة التّدريب، خاصّةً على الأنظمة ذات قدرة التّوازي (Parallel) المحدودة [1].
- عدم الحاجة إليها دائمًا:
لا تُعدّ هذه التّقنيّة ضروريّةً في جميع الحالات. إذا لم تكن الذّاكرة عائقًا رئيسيًّا، فقد يكون تدريب النّماذج العميقة أكثر كفاءة دون إدخال التّعقيدات الحسابيّة الإضافيّة المصاحبة لتقنيّة نقاط تحقّق التّدرّج [1].
- صعوبات التوزيع الأمثل:
يحتاج التّخطيط الدّقيق لتوزيع طبقات الحفظ المرحليّ عبر الشّبكة إلى دراسةٍ متأنّيةٍ، إذ قد يؤدّي التّوزيع غير المدروس إلى توفيرٍ غير كافٍ للذّاكرة أو حتّى إلى استهلاك ذاكرةٍ أكبر من المتوقّع [1].
الخاتمة
بالملخّص، تبرز تقنيّة نقاط تحقّق التّدرّج كأداةٍ فعّالةٍ لا غنى عنها في التّعلّم العميق. فهي تُقدّم حلًّاً فعّالًا لتحدّيات الذّاكرة الّتي غالبًا ما تُصاحب تدريب الشّبكات العصبونيّة العميقة. ومن خلال إدارتها الاستراتيجيّة لموارد الذّاكرة، تفتح تقنيّة نقاط تحقّق التّدرّج آفاقًا جديدةً في تطوير النّماذج المُعقّدة، كما وتُعزّز التّقدّم في مختلف مجالات تعلّم الآلة.
تشمل أهمّ النّتائج المُستفادة من تطبيق تقنيّة نقاط تحقّق التّدرّج ما يلي:
- تمكين نماذج أكثر عمقًا: من أهمّ مزايا تقنيّة نقاط تحقّق التّدرّج قدرتها على تمكين تدريب الشّبكات العصبونيّة الأكثر عمقًا. ونظرًا لكون عمق النّماذج عاملًا حاسمًا في تحقيق أداءٍ مُتطوّرٍ، تُوفّر هذه التّقنيّة وسيلةً لاستكشاف بنًى أكثر تعقيدًا [1].
- كفاءة الذّاكرة: تتميّز تقنيّة نقاط تحقّق التّدرّج بكفاءةٍ عاليةٍ في استخدام الذّاكرة. فهي تسمح بتخصيص موارد الذّاكرة بدقّةٍ حيث تكون الحاجة إليها مُلحّةً، ممّا يُقلّل الاستهلاك غير الضّروري ويُخفّف من خطر استنفاد الذّاكرة [1].
- تطبيقاتٌ متعدّدة الاستخدامات: من الشّبكات العصبونيّة العميقة إلى نماذج المحوّلات والانتشار الخلفيّ المجزّأ، تُثبت تقنيّة نقاط تحقّق التّدرّج تعدّد استخداماتها في مجموعةٍ واسعةٍ من السّيناريوهات الواقعيّة. فهي تتكيّف مع قيود الذّاكرة الفريدة لكلّ تطبيقٍ، ممّا يضمن الأداء الأمثل [1].
ومع ذلك، من المهمّ توخّي الحذر عند تطبيقها. تُسبّب نقاط تحقّق التّدرّج عبئًا حسابيًّا إضافيًّا، ويعتمد استخدامها الحكيم على المتطلّبات والقيود الخاصّة بالمشكلة المطروحة. لا يتطلّب كلّ نموذجٍ أو سيناريو استخدام نقاط تحقّق التّدرّج وينبغي اتّباعها بعنايةٍ [1].
المراجع
- Gradient / Activation checkpointing
- Aman’s AI Journal • Gradient Accumulation and Checkpointing
- Performance and Scalability
- T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training Deep Nets with Sublinear Memory Cost.” arXiv preprint arXiv:1604.06174, 2016. Available: https://arxiv.org/abs/1604.06174




