إعداد: م. حمادة حمادة
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. ماريّا حماده
المَحتويَات
المقدّمة
يعدّ تراكم التّدرّجات (Gradient Accumulation) تقنيّةً حيويّة في تدريب نماذج التّعلّم العميق، خاصّة في عصر النّماذج الضّخمة ذات المليارات من المعاملات. أصبحت تقنيّات التّعلّم العميق تتطلّب موارد حاسوبيّة هائلة، حيث تتجاوز النّماذج الحديثة، مثل: الإصدار الثّالث من الجي بي تي (GPT-3) ونموذج المسارات اللّغويّة (PaLM) تريليونات المعاملات. في هذا السّياق، يبرز تراكم التّدرّجات كحلٍّ عمليٍّ للتّغلّب على قيود الذّاكرة في وحدات معالجة الرّسومات (GPUs). هذه التّقنيّة لا تمثّل مجرّد أسلوبٍ برمجيٍّ، بل هي مدخلٌ لفهمٍ أعمق لديناميكيّات تحسين النّماذج في ظلّ قيود الأجهزة.
تقدّم هذه المقالة تحليلًا شاملًا لهذه التّقنية، حيث تبدأ بشرحٍ مفصّلٍ لآليّات عملها الرّياضيّة والخوارزميّة، ثمّ تستعرض المزايا العمليّة بعمقٍ أكبر متضمّنةً دراسة حالةٍ من تطبيقات حقيقيّة. نناقش كذلك التّحدّيات التّقنيّة والقيود العمليّة مع تقديم تحليلٍ مقارنٍ بين تراكم التّدرّجات والبدائل الأخرى مثل التّدريب الموزّع. تشمل أيضًا قسمًا متقدّمًا حول التّطبيقات الحديثة في نماذج المحوّلات (Transformers) والبرمجة العمليّة باستخدام أطر العمل الشّائعة. كما وتتناول في النّهاية تقديم بعض التّوصيات للممارسين بناءً على محتوى المقالة.
الأسس الرّياضيّة والخوارزميّة
الصّيغة الرّياضيّة
لنفترض أنّه لدينا دالّة خسارة (ℒ) تعتمد على (أوزان الّنموذج) (θ) في التّدريب التّقليديّ. يتمّ حساب التّدرّج grad ∇ℒ(θ) لكلّ دفعةٍ (batch) وتحديث الأوزان مباشرةً باستخدام:
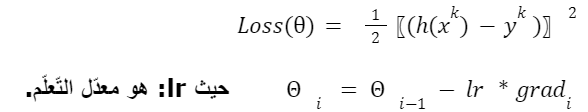
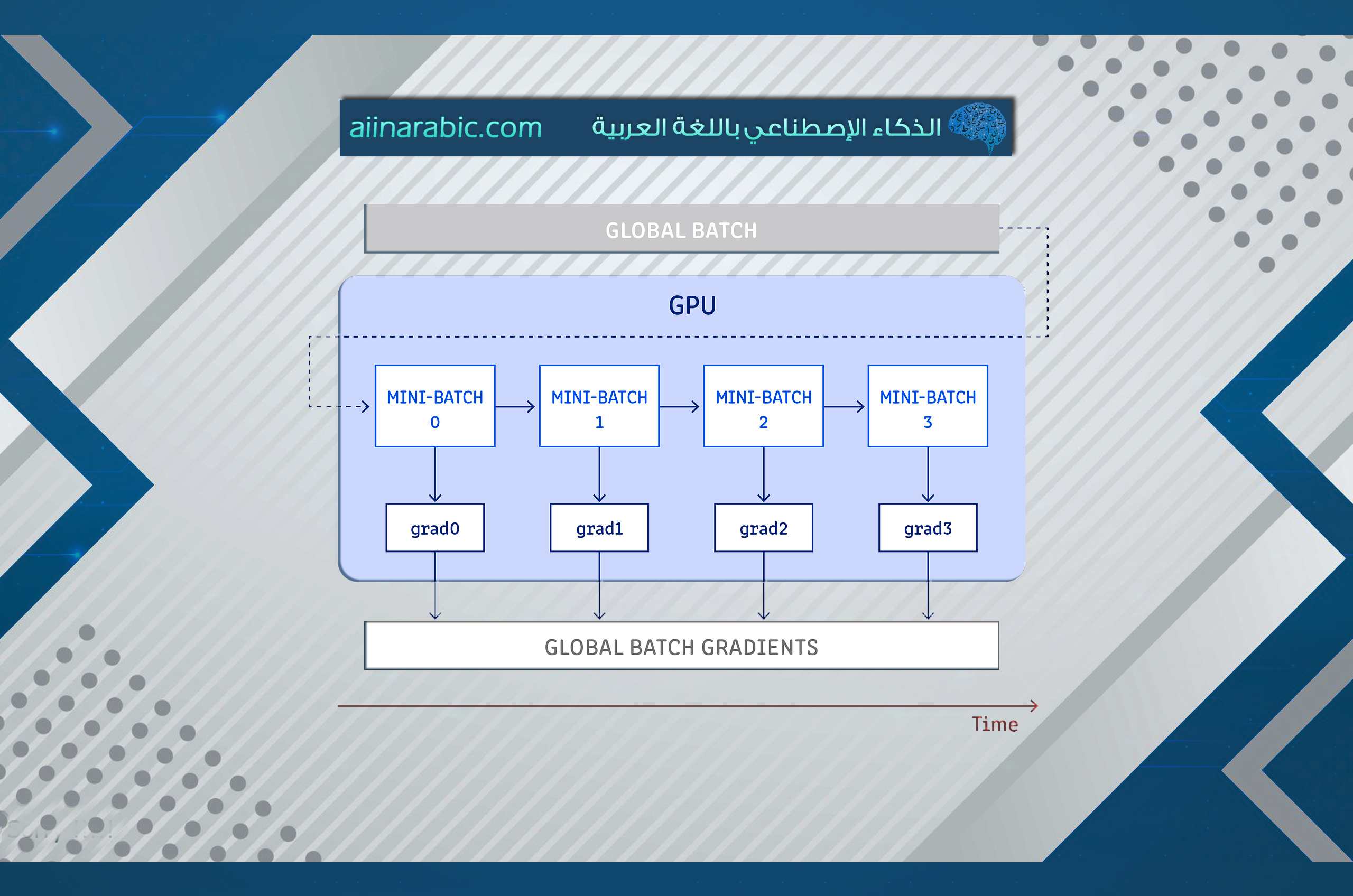
في التّجميع التّدرّجي، نجمع التّدرجات عبر (k) دفعةٍ صغيرةٍ قبل التّحديث أي:
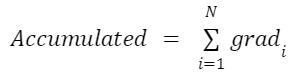
هذه الصّيغة تكافئ رياضيًّا التّدريب بدفعةٍ كبيرةٍ بحجم k×b، حيث b هو حجم الدّفعة الصّغيرة.
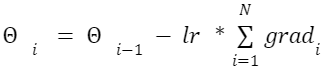
الخوارزميّة المتّبعة
يمكن تلخيص خوارزميّة عمل تقنية تراكم التدرجات بالخطوات الآتية:
- التّهيئة اللّازمة وتتمّ من خلال:
- تحديد حجم الدّفعة الكلّيّ (L) وحجم الدّفعة الفعليّة (s).
- حساب خطوات التّجميع k = L/s
- تهيئة متغيّرٍ يمثّل عدّاد التّدرّجات (للدّفعات الفعليّة) G = 0.
- نحسب التّدرّجات لكلّ قطعةٍ صغيرةٍ ونجمعها في الذّاكرة ونزيد العدّاد (G += 1).
- عند تحقّق الشّرط G % k == 0 يتمّ:
- تحديث الأوزان.
- مسح التّدرّجات للبدء مجدّدًا.[1]
بفرض لدينا تدرّجات الدّفعات الفعليّة الآتية: g0, g1, g2, g3، فإنّ التّحديث سيكون بعد التّراكم بالشّكل الآتي :
θ_new = θ_old – η*(g0+g1 + g2 + g3 ) / 4

مثالٌ رياضيٌّ
نفترض أنّ:
- حجم الدّفعة (batch size) الّذي نريده هو 64 (لكنّ ذاكرتنا لا تتّسع سوى لـ 16 في المرّة).
- نستخدم تراكم تدرّجات بعامل 4 أي (accumulation_steps=4).
كيف يتمّ التّدريب؟
- نمرّر 16 عيّنة (بدل 64)، نحسب الخسارة (loss) والتّدرّجات (gradients) ونخزّنها من دون تحديث الأوزان.
- نكرّر الخطوة لـ 3 دفعاتٍ أخرى (16 × 4 = 64).
- بعد 4 خطواتٍ، نجمّع التّدرّجات من جميع الدّفعات الصّغيرة.
- نقوم بتحديث أوزان النّموذج بناءً على التّدرّجات المجمّعة.
- نكرّر العمليّة.
تأثير الاستقرار العدديّ
يلعب الاستقرار العدديّ (Numerical Stability) دورًا مهمًّا في جودة الخوارزميّات وبالأخصّ في النّماذج الضّخمة، وهنا نرى بعض تأثيراته على أداء تقنيّة تراكم التّدرّج:
الجدول (1): أثر الاستقرار العدديّ على تراكم التّدرّجات.[2]
| تجميع التّدرّجات | – تراكم أخطاء الفاصلة العائمة – فقدان الدّقة في التّدرّجات الصّغيرة |
| تحديث الأوزان | – أخطاء التّقريب في عمليّة التّحديث – تفاعل مع معدّل التّعلّم |
| إعادة تعيين التّدرّجات | ضرورة تنظيف المتغيّرات المؤقتة بدقّة |
تطبيقٌ عمليٌّ لآليّة عمل تراكم التّدرّج
for i, (inputs, targets) in enumerate(dataloader):
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward pass
loss.backward()
# تجميع التدرجات
G += 1
# شرط التحديث
if G % k == 0:
optimizer.step()
optimizer.zero_grad()
شرح الكود
for i, (inputs, targets) in enumerate(dataloader):
هذه حلقةٌ تدريبيّةٌ تقليديّةٌ في مكتبة بايتورش (PyTorch) تقوم بـ:
- dataloader: يحمّل الدّفعات (batches) من البيانات.
- enumerate: يعطي رقمًا تسلسليًّا (i) لكلّ دفعةٍ.
- (inputs, targets): تفكيك الدّفعة إلى بيانات الإدخال (مثلًا صور) والعناوين (labels).
outputs = model(inputs)
loss = criterion(outputs, targets)
ويمثّل عمليّة الانتشار الأماميّ:
- تمرير البيانات عبر النّموذج (model) للحصول على المخرجات.
- حساب الخسارة (loss) بين المخرجات والقيم الحقيقيّة باستخدام دالّة الخسارة (criterion).
loss.backward()
ويمثّل عمليّة الانتشار الخلفيّ، حيث تقوم بالخطوات التّالية:
- حساب التّدرّجات لكلّ معاملٍ (parameter) في النّموذج.
- تخزين هذه التّدرّجات في خاصيّة grad لكلّ معاملٍ
G += 1
هذا العدّاد (G) يقوم بـما يلي:
- تتبّع عدد الدّفعات الصّغيرة الّتي تمّت معالجتها.
- كلّ تكرارٍ للحلقة يمثّل دفعةً صغيرةً واحدةً.
- عندما يصل G إلى مضاعفات k، يتمّ تطبيق التّحديث
if G % k == 0:
optimizer.step()
optimizer.zero_grad()وهذا الجزء يمثّل جوهر عمليّة تراكم التّدرّج:
- G % k == 0: يتحقّق فيما إذا كان العدّاد G من مضاعفات k.
- optimizer.step(): يقوم بتحديث أوزان النّموذج باستخدام التّدرّجات المجمّعة.
- optimizer.zero_grad(): البدء بمسح التّدرّجات مجدّدًا.


الشّكل (2): مقارنةٌ بين عمل الخليّة العصبيّة مع تراكم التّدرّجات وبدونه[3]
مزايا تراكم التّدرّجات وبعض التّطبيقات العمليّة
يقلّل تراكم التّدرّج متطلّبات الذّاكرة بعدّة طرقٍ:
- ذاكرة التّدرّجات: تخزين تدرّجات دفعةٍ صغيرةٍ بدلًا من الكبيرة.
- ذاكرة التّنشيطات: تقليل متطلّبات الذّاكرة أثناء المرور الأماميّ.
- ذاكرة المؤقتات: إمكانيّة إعادة حساب بعض القيم بدلًا من تخزينها. [4]
بعض التّطبيقات العمليّة
النّموذج الأوّل: نموذج بيرت الكبير (BERT-Large)
- الحجم: 340 مليون معامل.
- بدون تجميع: يتطلّب 32GB ذاكرة لوحدة معالجة الرّسوميّات.
- مع تجميع (k=8): يعمل على وحدة معالجة الرّسوميّات بسعة 16GB(تقليل) [5]
النّموذج الثّاني: الإصدار الثّالث من الجي بي تي
- استخدمت شركة أوبن أيه آي (OpenAI) نسخةً معدّلةً من التّجميع التّدرّجي.
- مكّنت من تدريب النّموذج على 1024 GPU بدلًا من 2048. [6]
سلبيّات وتحديّات تراكم التّدرّجات
على الرّغم من كفاءة تراكم التّدرّج في استثمار موارد الذّاكرة ، إلّا أنّ هناك تبعات غير مرغوبةٍ منها:
- زيادة زمن التّدريب: يتطلّب خطواتٍ أكثر لنفس الأداء ويطيل مدّة كلّ تكرارٍ بسبب تجميع التّدرّجات.
- مشاكل التّقارب: تحديثات الأوزان الأقلّ تكرارًا تسبّب تقلّباتٍ أكبر في الخسارة وتأخّرًا في التّقارب.
- تعقيد ضبط المعايير: يصبح اختيار معدّل التّعلّم المناسب أصعب ويحتاج إعادة معايرة مع حجم الدّفعة الفعّال.
- عدم الاستقرار: يزيد خطر انفجار التّدرّجات عند التّراكم على خطواتٍ كثيرةٍ، خاصّةً في النّماذج الكبيرة.
- قيود التّوازي: لا يحلّ مشكلة الذّاكرة للنّماذج الضّخمة مع عدم الاستفادة الكاملة من توازي وحدة معالجة الرّسوميّات.
- غير مجدٍ مع النّماذج من نوع النّماذج ذات السّياق (Stateful Models): لحاجتها تحديث الأوزان بعد كلّ دفعةٍ للحفاظ على تدفّق الحالة. [7]
تعديلاتٌ تحسينيّةٌ
loss = loss / accumulation_steps
يكتب هذا السّطر إضافةً إلى سطر عمليّة حساب الخسارة.
الهدف: ليعادل متوسّط التّدرّجات بعد التّجميع، ممّا يحافظ على استقرار التّدريب.
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
الهدف: قطع التّدرّجات إذا تجاوزت حدًّا معيّنًا، فيمنع انفجارها (تضخّمها المفاجئ) الّذي قد يعطّل النّموذج.
optimizer.zero_grad(set_to_none=True)
الهدف: يحسّن أداء الذّاكرة وذلك بمسح التّدرّجات بكفاءةٍ أعلى (بدل تعبئتها بأصفار) PyTorch 1.7+ .
الخاتمة
وهكذا وبناءً على ما سبق، يُعد تراكم التّدرّجات تقنيّةً ذكيّةً توفّر المواردَ الحسابيّة وتُحسّن استقرارَ التّدريب، ممّا يفتح البابَ أمام تدريب النّماذج الكبيرة بفعّالية حتّى على الأجهزة المحدودة. بتوازنٍ دقيقٍ بين حجم الدّفعات وتكرار التّجميع، يمكن تحقيق أداءٍ عالٍ دون التّضحية بدقة النّموذج، ليكون بذلك أداةً أساسيّةً في صندوق أدوات كلّ مهتمٍّ بتطوير الذّكاء الإصطناعيّ. وفيما يلي بعض التّوصيات:
- مراقبة الاستقرار: خاصّةً في الطّبقات الحسّاسة، مثل: التّطبيع (Normalization).
- التّكامل مع تقنيّات مقاربةٍ، مثل: (Gradient Clipping تقييد التدرج), (Gradient Checkpointing نقاط تحقق التدرج).
- الجدولة الدّيناميكيّة: تعديل k أثناء التّدريب.
- تحسينات المعدّات: استخدام (وحدات معالجة مصفوفات متعددة الأبعاد Tensor Cores) في وحدات معالجة الرّسوميّات الحديثة.
اتّجاهاتٌ بحثيٌّة
- تحسينات الخوارزميّة لتقليل أثر التّأخير.
- تكاملٌ أفضل مع التّدريب الموزّع الضّخم.
المراجع والمصادر
- Gradient Accumulation
- fixing-faulty-gradient-accumulation-understanding-the-issue-and-its-resolution
- gradient-accumulation-vs-batch-size-in-deep-learning
- gradıent accumılatıon and checkpointıng
- https://huggingface.co/docs/transformers/v4.17.0/performance
- https://training-api.cerebras.ai/en/2.1.1/wsc/general/grad_accumulation.html
- What are the benefits and drawbacks of using gradient accumulation in large language model training




