
المحتويات
لقد كان لشبكة جوجل انسبشن أثر واضح في تطوير المصنفات ضمن شبكات الطي العصبونية Convolutional Neural Network تعتمد هذه الشبكة على تكديس طبقات الطي واحدة تلو الأخرى، بغية تحسين الأداء.
أحبُ أن أقوم بالتعريف قليلاً عن شبكات جوجل انسبشن من حيث منشأ الكلمة Inception؛ فهي اصطلاحياً تعني بداية لشيء ما.

إن شبكة جوجل انسبشن معقدة أكثر من شبكات الطّي السابقة لها (أي مبرمجة بشكل أدق)، استخدم فيها الكثير من الطرق والحيل لتحسين الأداء من حيث السرعة والدقة, وأصدر لها عدة إصدارات لتحسينها وتطويرها (والإصدارات حسب ورودها في الورقات البحثية:
- الإصدار الأول للشبكة جوجل انسبشن (Inception v1) .
- الإصدار الثاني والثالث للشبكة جوجل انسبشن (Inception v2 and Inception v3).
- الإصدار الرابع للشبكة جوجل انسبشن و شبكة الرواسب ResNet ( Inception v4 and Inception-ResNet).
يتعلق كل إصدار بالنسخة السابقة له، حيث يتم تكرار بعض الخصائص وإضافة بعض التحسينات التي تسهل على المبرمج بناء مصنف خاص به وتحسن السرعة والدقة معاً. ليس بالضرورة أن يتم اعتماد النسخة الأحدث، ولكن تُحدد كمية ونوعية البيانات الموجودة الأصدار الذي يجب استخدامه. أحياناً يقدم الإصدار الأقدم أداءً أفضل.
في هذه مدونة سنستكشف معاً كيف تطورت شبكة جوجل انسبشن من خلال شرح بسيط لكل إصدار.
الإصدار الأول لشبكة جوجل انسبشن Inception v1
هنا بدأت فكرة شبكة جوجل انسبشن، سنقوم أولا بتحليل المشكلة التي قد تم طرحها للحل، وكيف تم حلها.
الفرضية: وأهم نقاطها:
- تشغل الأجزاء المهمة حيزاً مختلفاَ من صورة لأخرى، فمثلاَ في الصور التالية يشغل الكلب حيزاً مختلفاَ في كل صورة.

( مصدر الصور unsplash)
- يصعب اختيار حجم مصفوفة الطي kernel size المناسبة من أجل عملية الطّي بسبب الاختلافات الكبيرة لموقع المعلومات في الصورة، إذ سيتم استخدام مصفوفة ذات حجم أكبر من أجل المعلومات الموزعة بشكل كبير، ومصفوفة طي ذات حجم أقل من أجل المعلومات الموزعة بشكل أقل.
- الشبكات ذات الطبقات الكثيرة جداً مهددة بـ طفحان الملائمة overfitting، التي تجعل عملية إدخال حزم التحديثات إلى الشبكة الكليّة أصعب .
- زيادة الكلفة الحسابية بسبب تكديس عمليات الطّي بشكل مبدئي وساذج.
الحل:
تم اقتراح استخدام عدة مصفوفات طيّ تعمل في مستوى واحد، فبدلاً من تمدد الشبكة طولياً سيتم تمدده عرضياً، صمم مطورو هذا الإصدار ما يسمى بـ وحدة جوجل انسبشن Inception Module ليقوم بهذا المفهوم الجديد.
يُظهر المخطط التالي وحدة جوجل انسبشن “الأولي البسيط”. تُنفذ عملية الطّي على الدخل باستخدام ثلاث أنواع من مصفوفات الطي بأحجام مختلفة: (1×1) (3×3) (5×5) بالإضافة إلى التجميع وفق القيمة الأكبر max polling. يتم تجميع كل ما سبق في الخرج وإرساله إلى وحدة جوجل انسبشن التالية.
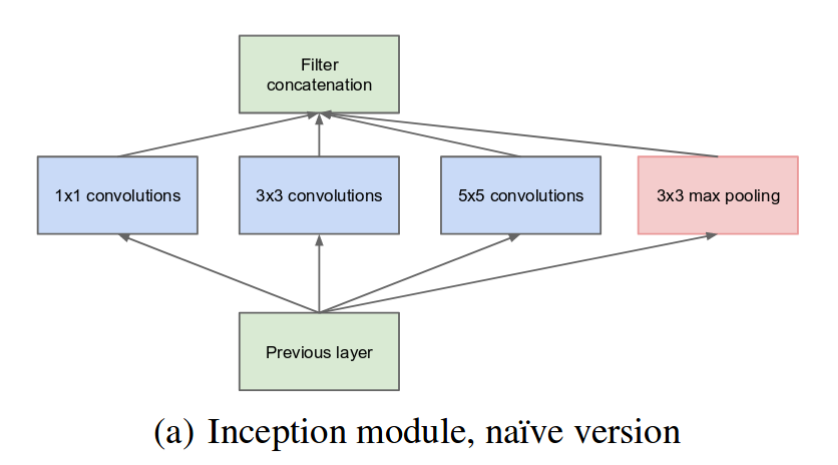
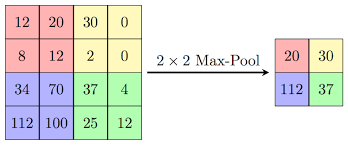
كما ذكرنا سابقاً، فإن الشبكات العصبونية العميقة (ذات الطبقات الكثيرة) مكلفة جداً حسابياً. لجعلها أقل تكلفة، فقد قام المؤلفون بتحديد عدد قنوات الدخل وإضافة عملية تكميلية ذات بُعد (1×1) قبل العمليات التكميلية (3×3) و (5×5). قد يتم اعتبار أن إإضافة عملية طّي إضافية لن يستطيع تخفيض التكلفة الحسابية ولكن في الحقيقة إن عمليات الطّي (1×1) أقل تكلفة بكثير من عمليات الطّي (5×5)، فساعد تخفيض عدد القنوات الدخل إلى تقليل التكلفة. يجب التنويه أن عملية الطّي (1×1) تضاف بعد عملية التجميع وفق القيمة الأكبر.
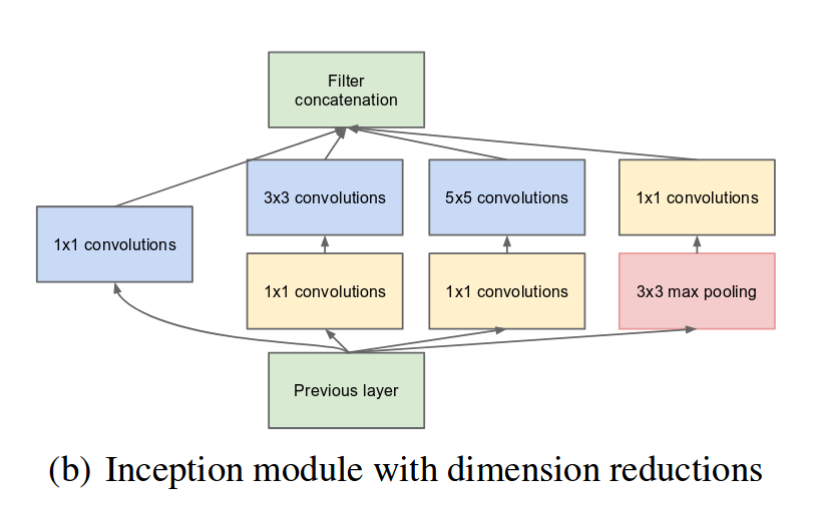
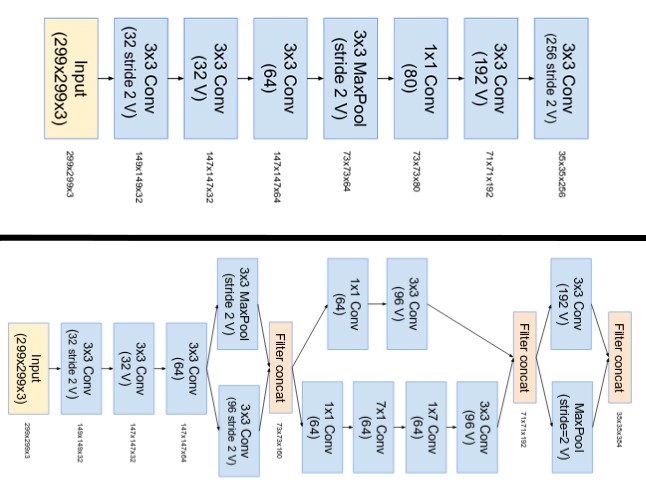
تم بناء بنية شبكة عصبية جديدة باستخدام وحدة جوجل انسبشن ذو الأبعاد المُخفضة. وأطلق عليها اسم GoogLeNet أو (Inception v1). إن بنية هذه الشبكة موضحة بالشكل التالي:
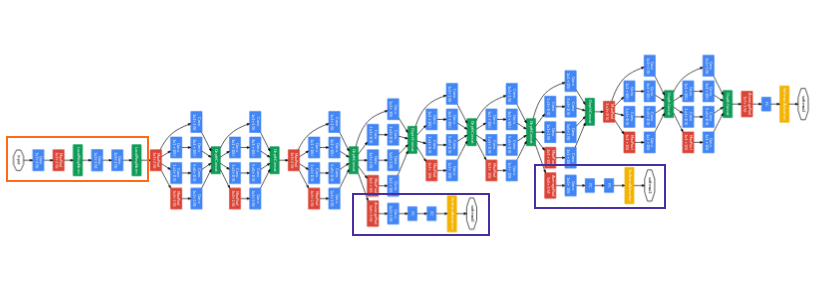
أما الأجزاء الواسعة تمثل نماذج جوجل انسبشن.
( المصدر: الورقة البحثية Inception v1 )
تمتلك (GoogLeNet) شبكة جوجل نت 9 نماذج جوجل انسبشن مكدسة بشكل خطيّ الشكل(4). تتألف من 22 طبقة عمقيّة (27 طبقة مع طبقات التجميع polling). التي تستخدم التجميع “تجميع موسع متوسط” بعد آخر عملية استخدم فيها وحدة جوجل انسبشن.
إن هذا الإصدار يمكن اعتباره مصنف عميق جداً، وكما في أي شبكة عمقية، فهي مهددة دوماً باختفاء عامل إدخال حزم التحديثات إلى بنية الشبكة.
لحل مشكلة توقف المنطقة الوسطية في الشبكة عن أداء عملها، قدمتْ نوعين من المصنفات المساعدة (الصناديق ذات اللون البنفسجي في الشكل (4)). تعمل هذه المصنفات بشكل أساسي على إضافة تابع التفعيل softmax إلى خرج اثنين من نماذج جوجل انسبشن، نجم عن ذلك تابع أطلق عليه تابع الخسارة المساعدة auxiliary loss.
إن تابع الخسارة الكلي يساوي إلى (مجموع أوزان تابع الخسارة المساعدة) مضافاً إليه (الخسارة الحقيقية real loss). تم أخذ عامل الأوزان من أجل كل تابع خسارة مساعد مساوياً إلى 0.3.
total_loss = real_loss + ( 0.3 * aux_loss_1 ) + ( 0.3 * aux_loss_2)
يمكن استنتاج مما سبق بأن تابع الخسارة المساعد يتم استخدامه في عملية التدريب training، ومن ثم يتم تجاهلها أثناء استخراج النتائج.
تم تقديم الإصدار الثاني والثالث في ذات الورقة البحثية Inception v2 ، ولكن سنقوم بتفصيل كل إصدار على حدا.
الإصدار الثاني لشبكة جوجل انسبشن Inception v2
قٌدمت عدد من التحديثات التي لها أثر فعّال في زيادة الدقة، وتخفيض التعقيدات الحسابية. إن الإصدار الثاني يبحث فيما يلي:
الفرضية: وأهم نقاطها:
- تخفيض حالة “عنق الزجاجة” representational bottleneck (فمعالجة طبقات الدخل الكثيرة التي تحتوي على الكثير من المعلومات تم تشبيهها بتدفق الماء من خلال عنق الزجاجة أثناء تفريغها)
من البديهي، أن تقوم الشبكات العصبونية بأداء أفضل عندما لا تؤثر عمليات الطّي على أبعاد الصورة الأصلية بشكل جذري. فإن تقليل الأبعاد بشكل جذري يسبب نقص في معلومات الصورة وهذا ما يسمى حالة “عنق الزجاجة”.
- باستخدام طرق ذكية لتحليل الصورة إلى عدة عوامل، يمكن إجراء عمليات جداء الطّي بشكل أكثر فعالية فيما يتعلق بالتعقيد الحسابي.
الحل:
تم تحليل مصفوفة الطّي (5×5) إلى مصفوفتين (3×3)، لتحسن سرعة العملية الحسابية. عند الوهلة الأولى قد يعتقد البعض أن هذه الطريقة غير مجدية، ولكن في حقيقة الأمر، فإن استخدام مصفوفة طّي (5×5) مكلفة أكثر بـ 2.78 مرة من استخدام مصفوفة طّي (3×3)، وبالتالي عند أخذ مصفوفتين متكاملتين ذات بُعد (3×3) سيؤدي إلى تعزيز الأداء وزيادته، يوضح الشكل التالي التغيرات التي قام بها المؤلفون في الإصدار الثاني:
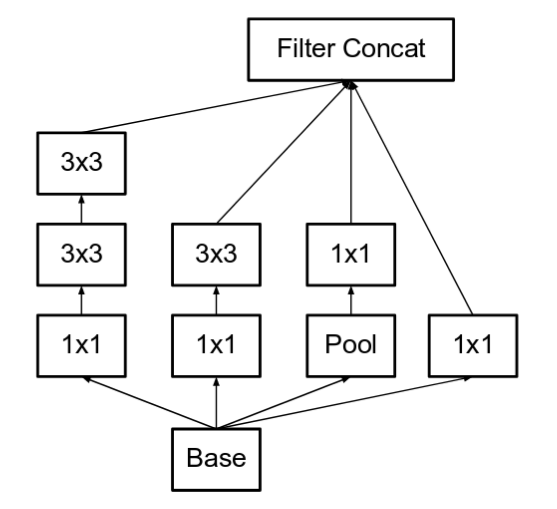
وقد أدى ذلك إلى اعتماد حجم المرشح filter size المؤلفة من (n × n) إلى تحليلها إلى عوامل مركبة مؤلفة من مصفوفتين متكاملتين، الأولى (1xn) والثانية (nx1). فعلى سبيل المثال، عملية طّي (3×3) تكافئ، إلى تنفيذ مصفوفتين متكاملتين، الأولى (1 × 3) والثانية (3 × 1) على خرج الأولى. خفضت هذه الطريقة التكلفة في الأداء بنسبة أكثر بـ 33% من استخدام مصفوفة طّي (3×3). وهي موضحة بالشكل التالي:
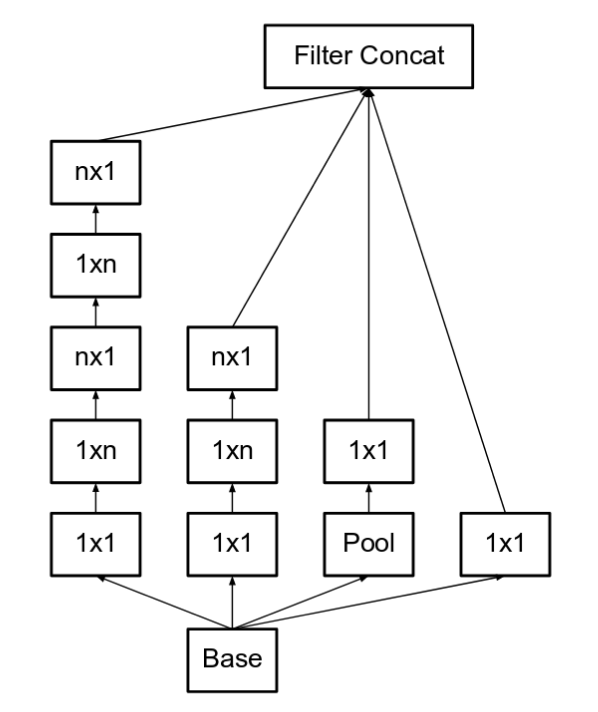
[ ضع n=3 حتى يكون الرسم مساوياً إلى الرسم السابق، مصفوفة 5×5 يمكن أن تُمثل بمصفوفتين من 3×3 حيث أن بالمقابل سيتم تبديل كل واحدة منها إلى 1×3 و 3×1 بالتسلسل. ]
تم توسيع مصفوفات المُرشحات Filter banks ( حيث أصبحت “أعرض” بدلاً من “أعمق”) للتخلص من حالة عنق الزجاجة. فيما لو بقيت الوحدة تتوسع بشكل أعمق، كانت لتسبب انخفاضاً مفرطاً في الأبعاد وبالتالي نقص كبير في المعلومات، وهي موضحة بالشكل التالي:
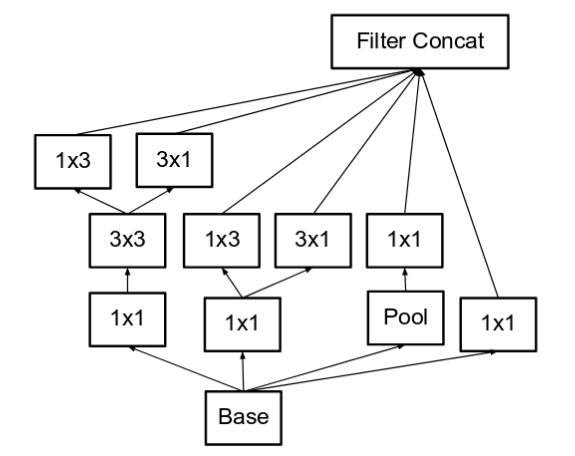
هذا الشكل يكافئ الرسم السابق
اُستخدمت المبادئ الثلاث السابقة في بناء ثلاثة أنواع مختلفة من نماذج جوجل انسبشن (سنطلق عليهم الأسماء التالية: وحدة A، وحدة B، وحدة C ، تسلسلياً حسبما أوردتها لكم في هذه المقالة. هذه الأسماء تم تقديمها من أجل التوضيح فقط وليست أسمائهم الرسمية المصرحة) أصبحت البنية النهائية لتسلسل العمليات في الإصدار الثاني بالشكل التالي:
الإصدار الثالث لشبكة جوجل انسبشن Inception v3
الفرضية: وأهم نقاطها:
- لاحظ المطورون أن المصنفات المساعدة لا تقدم تلك المساهمة القيّمة إلا عند الاقتراب من إيجاد الخرج (في المراحل الأخيرة من احتساب الخرج حيث أن الدقة تصبح ). ناقشوا أن المصنفات المساعدة كانت تعمل كــمُنظمات regularizes، وبشكلٍ خاص، في حال كانت مترافقة مع عمليات تقييس الدفعة BatchNorm وتعطيل عمل العصبونات Dropout.
- إجراء عدة محاولات تهدف إلى تحسين الإصدار الثاني Inception v2 دون التطرق إلى تغيير النماذج بشكل جذري.
الحل:
دمج الإصدار الثالث جميع التحديثات المعلنة عنها بعد طرح الإصدار الثاني بالإضافة إلى ما يلي:
- RMSProp Optimizer
- عمليات طّي 7×7 محللة إلى عواملها. Factorized 7×7 convolutions
- استخدام BatchNorm في المصنفات المساعدة.
- التنعيم المعنون Label Smoothing (وهو نوع من المركبات المنظمة التي تضاف إلى المكونات الضائعة أو غير الكاملة، التي تمنع الشبكة من الوثوقية العالية تجاه المصنفات، بمعنى آخر، فهي تمنع حالة طفحان الملائمة)
قد تم التصريح عن الإصدار الرابع Inception v4 والإصدار الذي يليه، الذي أًطلق عليه اسم Inception ResNet ضمن ورقة بحثية واحدة. Inception v4 and Inception ResNet سنتحدث، كما سبق، كل منهما على حدا.
الإصدار الرابع لشبكة جوجل انسبشن Inception v4
الفرضية:
- السعي إلى توحيد النماذج، فقد لوحظ أن بعض النماذج كانت معقدة أكثر من اللازم. فإن تبسيط النماذج وزيادتها سيدعم عمل الشبكة ويحسنها.
الحل:
- تم تغير الوحدة الأساسية للإصدار الرابع، ونقصد بالوحدة الأساسية المجموعة الأولية من العمليات المنفذة قبل بدء عمل كتل جوجل انسبشن Inception Blocks.
الجزء الأيمن يمثل الوحدة الأساسية لـ Inception v4 و Inception-ResNet v2.
- يمتلك الإصدار الرابع ثلاث نماذج جوجل انسبشن، قاموا بتسميتها بـ A,B,C (بشكل مغاير للإصدار الثاني، فإن هذه القوالب فعلاً تم ذكرها هكذا) يتشابهون في مكوناتهم بمثيلاتهم في الإصدار الثاني.
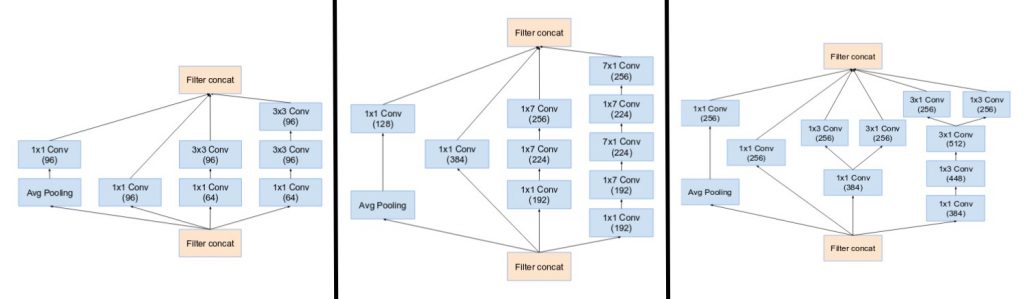
(لاحظ كيف هي متشابهة مع قوالب الإصدارات الثانية والثالث)
طرح الإصدار الرابع وحدات خاصة سُميت بـ الكتل المُخفضة Reduction Blocks مهمتها تغيير أبعاد الطول والعرض في خطوط الشبكية. الإصدارات السابقة لم تكن تمتلك فعلياً هذه الكتل المُخفضة وإنما كانت هذه الميزة تتم بشكل ضمني.
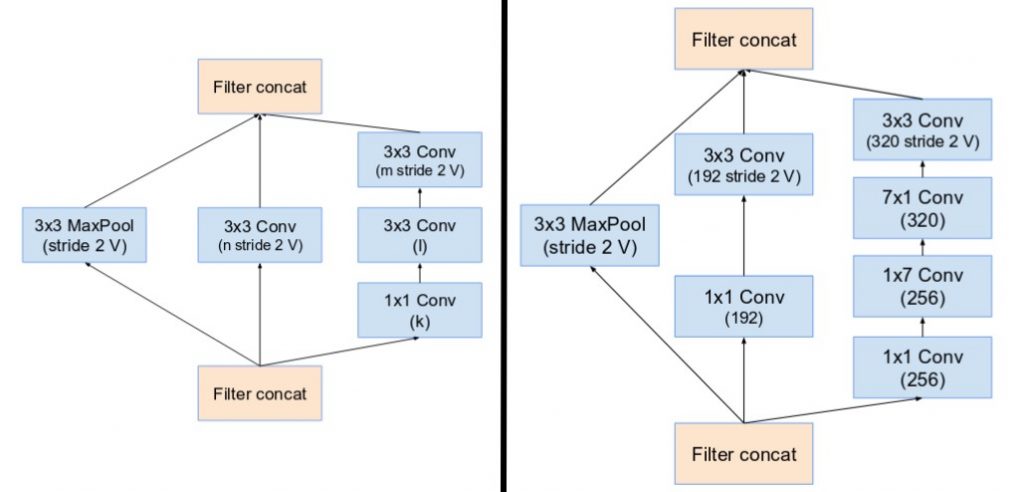
وإلى جانبه وحدة المُخفض ذو الكتلة B ( مُخفضة من 17×17 إلى 8×8 )
الإصداران الجزئيتان لشبكة جوجل انسبشن Inception ResNet v1 and v2
بعد الأداء العالي لشبكة جوجل انسبشن ResNet، تم تقديم وحدة جوجل انسبشن هجين. تم طرح إصداران جزئيتان للشبكة Inception ResNet، قبل أن ننتقل إلى المميزات الأساسية لهما، سنطلع معاً على أهم الفروقات الواضحة بين هاتين الإصدارين:
- الإصدار الأول لها تكلفة حسابية مشابهة للإصدار الثالث.
- الإصدار الثاني لها تكلفة حسابية مشابهة للإصدار الرابع.
- كل واحدة منهما تمتلك وحدة أساسية خاصة بها. ( قمنا بتوضيح ذلك ضمن فقرة الإصدار الرابع)
- كلا الإصدارين السابقين لهما نفس البينة في قوالب A,B,C والكتل المُخفضة. الفرق الوحيد بينهما هو في ضبط المعاملات الأساسية. في هذه الفقرة، سنقوم فقط بالتركيز على بنية الإصدارات المبدئية. ( إذا كنت تود معرفة المزيد عن إعدادات سرعة البارامترات فقم بمراجعة الورقة الأساسية)
الفرضية:
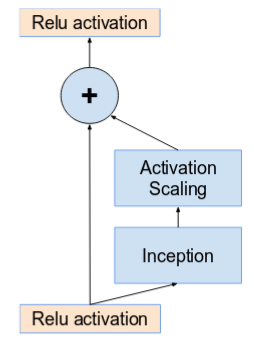
- تقديم الوصلات الراسبة residual connections التي تقوم بإضافة الخرج الناتج عن عمليات الطّي من قوالب جوجل انسبشن، إلى الدخل.
الحل:
- حتى تعمل الاتصالات المكملة، يجب أن يكون الدخل والخرج، بعد عمليات الطّي، لهما نفس الأبعاد. لذلك نستخدم عملية طّي 1×1 بعد إجراء عمليات الطّي الأساسية، لموازنة أحجام العمق. ( يزداد حجم العمق بعد كل عملية طّي).
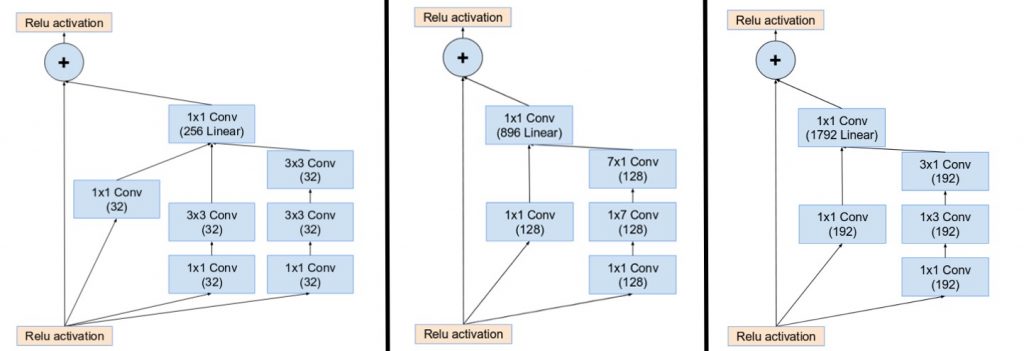
لاحظ كيف أن طبقة التجميع تم استبدالها بالاتصالات المكملة، وكيف تم إضافة عملية طّي 1×1 قبل الإضافة.
- تم استبدال عمليات التجميع داخل نماذج جوجل انسبشن الأساسية بالوصلات الراسبة. لكن يمكن إيجاد تلك العمليات في الكتل المُخفضة. وحدة المُخفض ذو الكتلة A هو نفسه وحدة A في الإصدار الرابع.
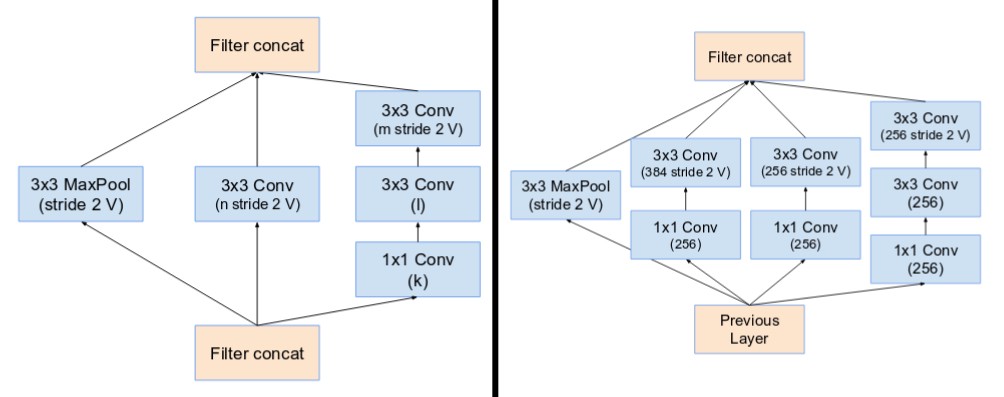
وإلى جانبه وحدة المُخفض ذو الكتلة B ( مُخفضة من 17×17 إلى 8×8 )
وجود وحدات أعمق في بنية الشبكة يسبب “موت” الشبكة بشرط تجاوز عدد مصفوفات الطي أكثر من العدد 1000. وبذلك، لزيادة استقرار الشبكة، تم تحجيم نشاط الوصلات الراسبة بقيمة ( ما بين 0.1 و 0.3).
- الورقة الأساسية لم تستخدم تقييس الدفعة بعد انتهاء تدريب الوحدة على جهاز معالجة الرسومات GPU. (أي توسيع وحدة جوجل انسبشن على جهاز عرض واحد).
- تم ملاحظة أن قوالب شبكات جوجل انسبشن من نوع ResNet ( شبكة الرواسب) حققت أداء عالٍ في زمن أقل.
- تصميم الشبكة النهائي من أجل شبكات جوجل انسبشن للإصدار الرابع ومن نوع ResNet هي بالشكل التالي:
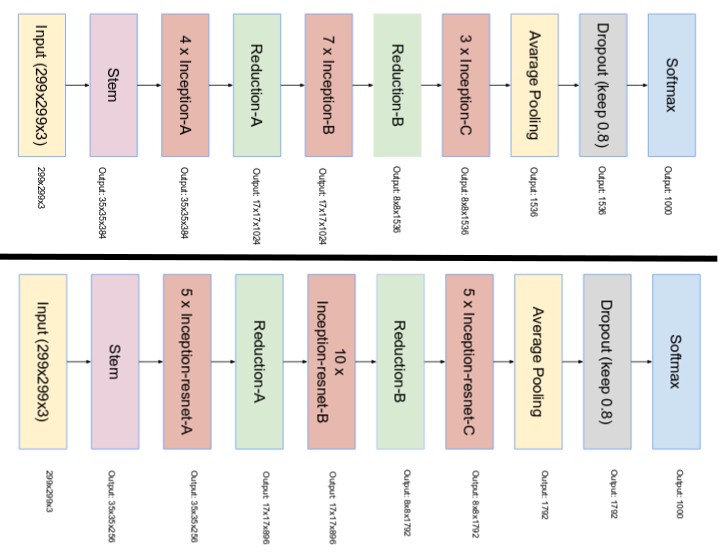
نتمنى أن نكون قد قدمنا لكم شرحاً كافياً وملهماً لمختلف إصدارات شبكة جوجل انسبشن.




