
ازداد استخدام شبكات الطّي العصبونية في الرؤية الحاسوبية، وقد قام الباحثون بتطوير هذه الشبكات لجعلها أكثر عمقًا وتعقيدًا لتعطي دقة أعلى. لكن هذه التطورات لجعل الشبكات أكثر دقة لا تعني بالضرورة جعلها أكثر كفاءة فيما يتعلق بالحجم والسرعة. ففي العديد من التطبيقات كالروبوتات والسيارات ذاتية القيادة يجب تنفيذ المهام في الوقت المناسب. لذلك تم تقديم الحل من قبل باحثين في جوجل عام 2017 ضمن الورقة المسماة شبكات الطيّ العصبونية الفعّالة لتطبيقات الرؤية في الأجهزة المحمولة. حيث قاموا بإيجاد بنية شبكة فعّالة لبناء نماذج صغيرة جدًا وذات أداء سريع لتتناسب مع متطلبات تصميم الأجهزة المحمولة والمضمّنة. هذه البنية هي موبايل-نت MobileNet.
المحتويات
الطّي بالعمق المنفصل depthwise separable convolutions
الفكرة الأساسية من شبكات موبايل-نت هو استخدام الطيّ بالعمق المنفصل لبناء شبكات عميقة خفيفة الوزن light-weight. وتعود تسمية هذه العملية بالطّي بالعمق المنفصل لسببين:
1- لا يدخل في حسابه أبعاد الصورة فقط (العرض والارتفاع) وإنما العمق ايضًا أو ما يعبر عن عدد القنوات في الصورة.
على فرض لدينا صورة آر جي بي RBG أي لها ثلاث قنوات وبأبعاد 12×12 ونريد تطبيق عملية الطيّ بمصفوفة (5×5)وبخطوة تحريك 1. في حال أخذنا فقط الطول والعرض بالحسبان عندها ستخضع مصفوفة الطيّ إلى جداء عددي مع كل 25 بيكسل لتعطي رقم واحد في كل مرة لتكون النتيجة صورة بـ 8×8 بيكسل. لكن باعتبار الصورة تحوي ثلاث قنوات لذلك يجب أن تحوي مصفوفة الطيّ ثلاث قنوات أيضًا لذلك ستتم عملية الجداء بمصفوفة الطيّ 5x5x3=75 في كل مرة يتم فيها تحريك المصفوفة بنفس الطريقة يتم ضرب المصفوفة بكل 25 بيكسل ويكون الخرج بيكسل واحد وبعد المرور بهذه المصفوفة على كل الصورة ستكون النتيجة صورة بأبعاد 8x8x1. أي تم تجميع قنوات الدخل في صورة الخرج لتكون قناة واحدة لكل بكسل. بالتالي لكل بيكسل مدخل بغض النظر عن عدد القنوات عملية الطيّ تنتج بيكسل خرج جديد بقناة وحيدة.
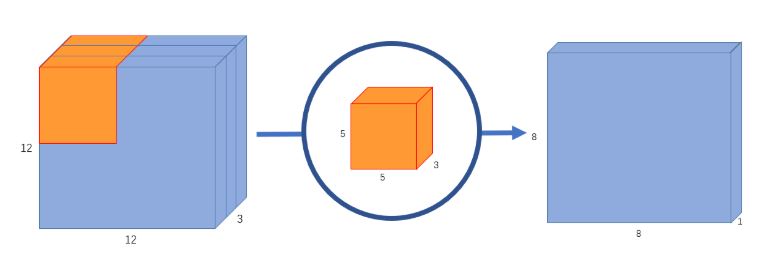
جيد حتى الآن! لكن ماذا لو أردنا زيادة عدد القنوات في صورة الخرج لتكون 8x8x256؟ عندها يجب بناء 256 مصفوفة طيّ لبناء 256 صورة ذات أبعاد (8x8x1) ومن ثم جمعهم معًا لإنشاء مصفوفة الخرج المطلوبة.هذا تمامًا ما كان سيقوم به جداء الطّي الاعتيادي! لذلك تم إيجاد الطّي المنفصل بالعمق ليقسم هذه العملية (عملية الطّي وعملية إرجاع عدد القنوات) الى مرحلتين.
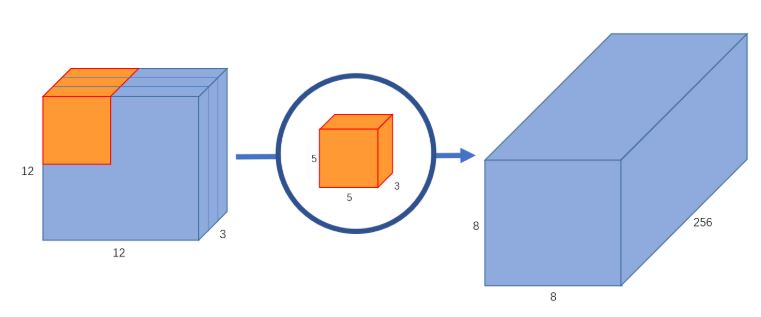
2- تتم عملية الطّي على مرحلتين الأولى تسمى الطّي بالعمق والثانية الطّي النقطي:
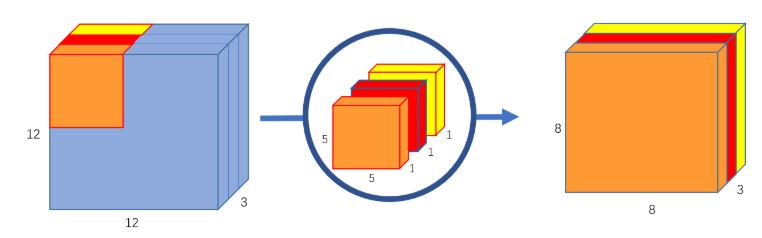
– الطّي بالعمق: على عكس الطّي الاعتيادي لا يتم تجميع قنوات الدخل وإنما تتم عملية الطّي على كل قناة بشكل منفصل. ففي حال مرّرنا صورة الدخل(12x12x3) المطلوب تحويلها إلى (8x8x3) بدون تغيير العمق سيتم استخدام ثلاث مصفوفات طيّ (مصفوفة لكل قناة) من الشكل (5x5x1) ونتيجة مرور كل مصفوفة من مصفوفات الطّي هي 8x8x1 ومن خلال دمجهم معًا سنحصل على المطلوب.
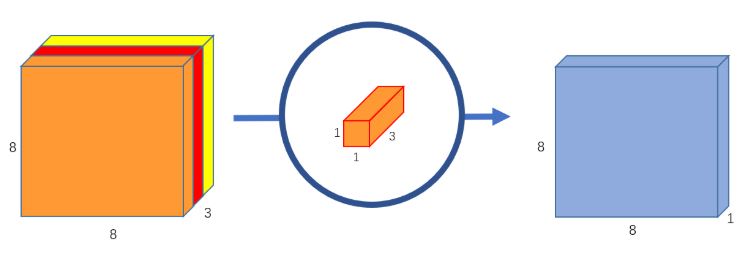
– الطّي النقطي: في هذه المرحلة يتم تجميع قنوات الخرج للحصول على مزايا جديدة.
تدعى هذه المرحلة بالطّي النقطي لأنها تستخدم مصفوفة طي 1×1 بمعنى آخر المصفوفة التي تمرر عبر كل نقطة على حدا. أما عمق هذه المصفوفة فسيكون بنفس عمق صورة الدخل في حالتنا هو 3. الآن سنمرر مصفوفة الطّي 1x1x3 على كامل صورتنا 8x8x3 للحصول على 8x8x1.
وللحصول على صورة 8x8x256 يمكن بناء 256 مصفوفة طيّ من الشكل 1x1x3 لتعطي كل منها 8x8x1 لنحصل بتجميعها معًا على النتيجة المطلوبة.
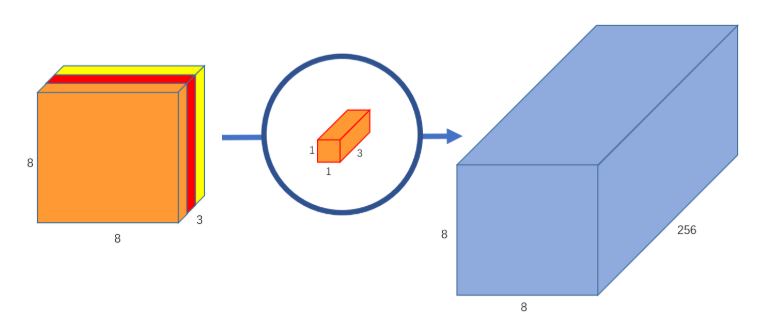
بهذا تكون قد قامت الشبكة بعمل نفس الحسابات لكن بسرعة أكبر. كيف ذلك:
1- سنقوم بحساب عدد الجداءات التي تم تنفيذها في عملية الطّي الاعتيادية:
كان هناك 256 مصفوفة طيّ من الشكل(5x5x3) التي مٌررت عدد مرات مساوي 8×8 بالتالي لدينا 256x3x5x5x8x8=1,228,800 عملية جداء.
2- وحساب عدد الجداءات التي تم تنفيذها في عملية الطّي المنفصل بالعمق:
في المرحلة الأولى كان لدينا 3 مصفوفات طيّ من الشكل (5x5x1) التي مررت عدد مرات مساوي 8×8 بالتالي لدينا 3x5x5x8x8=4,800 عملية جداء.
وفي المرحلة الثانية كان لدينا 256 مصفوفة طيّ من الشكل (256x1x1x3x8x8) وبالتالي 49,152 عملية جداء و بالمحصلة 53,952 عملية جداء.
الفرق واضح، أليس كذلك. فالرقم 52,952 أقل بكثير من الرقم 1,228,800. بالتالي زمن أقل في إنجاز المهمة وأصبح بإمكان الشبكة معالجة المزيد في فترة زمنية أقصر.
بنية شبكة موبايل-نت
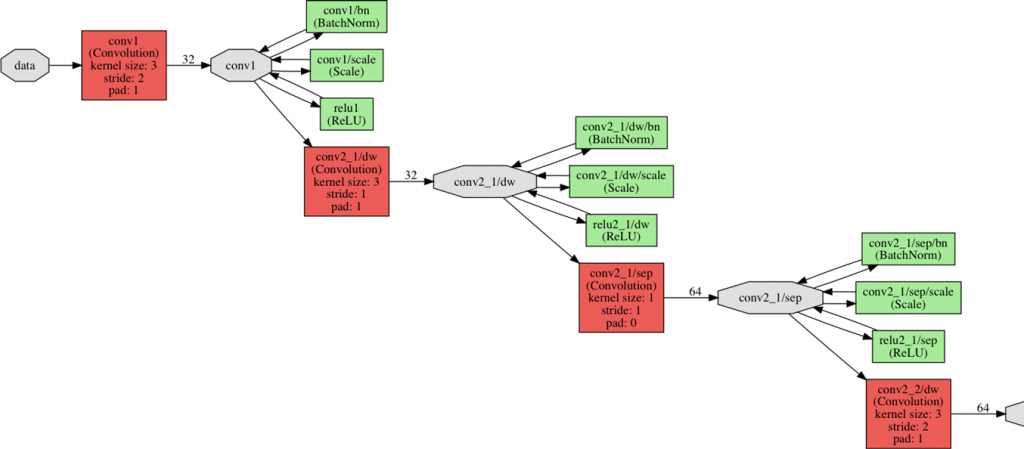
شبكة الموبايل-نت الكاملة تتضمن 30 طبقة على الشكل التالي:
1- طبقة الطّي الاعتيادية بخطوة تحريك 2.
2- طبقة الطّي بالعمق.
3- طبقة الطّي النقطي التي تضاعف عدد القنوات.
4- طبقة العمق بخطوة تحريك 2
5- طبقة الطّي النقطي التي تضاعف عدد القنوات
6- طبقة الطّي بالعمق
7- طبقة الطّي النقطي
8-طبقة الطّي بالعمق بخطوة تحريك 2
9- طبقة الطّي النقطي التي تضاعف عدد القنوات
وهكذا….كما في الشكل (7)
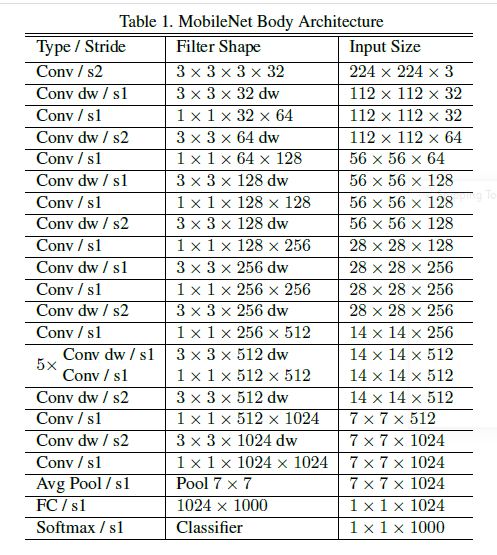
بعد قيام الطبقة الأولى بعملية الطّي الاعتيادية تتناوب طبقات الطّي بالعمق والنقطي. أحيانًأ طبقة الطّي بالعمق تكون بخطوة تحريك 2 لتقليل عرض وارتفاع البيانات أثناء تدفقها عبر الشبكة. وأحيانًأ أخرى طبقة الطّي النقطي تضاعف عدد قنوات البيانات. كل طبقات الطّي يتبعها تقييس الدفعة (لتحسين سرعة وأداء واستقرار الشبكة) Batch Normalization و تابع التفعيل الخطي المصحح ريلو ReLU.
يستمر ذلك لفترة حتى يتم تقليص الصورة ذات الأبعاد 224×224 إلى صورة بأبعاد 7×7 بيكسل لكن بـ 1024 قناة. بعد ذلك، هناك طبقة متوسطة للتجميع التي تعمل على كامل الصورة لينتهي الأمر بصورة ذات أبعاد 1x1x1024 والتي هي في الحقيقة عبارة عن مجرد شعاع مكون من 1024 عنصر.
ملاحظة: في حال كنا نستخدم شبكة موبايل-نت كمصنف على سبيل المثال في الإيمج نت ImageNet التي تحتوي ألف صنف محتمل ستكون الطبقة الأخيرة كاملة الاتصال مع تابع التفعيل سوفت ماكس وخرج 1000.
على الرغم من أن شبكة موبايل-نت صممت لتكون سريعة، من الممكن استخدام إصدار مخفض من بنية هذه الشبكة. هناك ثلاث معاملات أساسية يمكن ضبطها لتحديد حجم الشبكة:
1- آلفا alpha (كما تم تسميته في الورقة)- مضاعف العرض (Width multiplier ): يغير هذا المعامل عدد القنوات في كل طبقة يأخذ القيم بين الـ 0 والـ 1. فمثلًا عند ضبطه على القيمة 0.5 سيتم إنقاص عدد القنوات المستخدمة في كل طبقة إلى النصف بينما عند جعل قيمته مساوية للـ 1 عندها ستبدأ الشبكة بـ 32 قناة وتنتهي بـ 1024.
2- رو rho (كما تم تسميته في الورقة)- مضاعف الدقة (Resolution multiplier): يستخدم للتحكم بأبعاد الصورة المدخلة. يأخذ القيم بين الـ 0 والـ 1. الأبعاد الافتراضية لصورة الدخل هي 224×224.
3- مقدار العمق: الشبكة بشكلها الكامل لديها مجموعة من 5 طبقات في الوسط والتي من الممكن الاستغناء عنها.
بتغيير هذه المعاملات الثلاثة يمكن جعل حجم الشبكة أصغر وبالتالي أسرع. ولكن على حساب دقة التنبؤ (لمعرفة مدى تأثير تغيير هذه المعاملات على الدقة يمكن الرجوع إلى الورقة).
يبلغ العدد الإجمالي لمعاملات الشبكة بشكلها الكامل 4,221,032 (بعد طيّ طبقات التسوية). وهذه المعاملات بالتأكيد أقل بكثير من معاملات شبكات الهندسة البصرية VGGNet والتي تصل إلى أكثر من 130 مليون.
التنفيذ العملي
التطبيق العملي الأول:
فيما يلي التطبيق العملي لتصنيف الصور باستخدام نموذج موبايل-نت المدرب مسبقًأ، سنقوم أولًأ بتحميل المكتبات اللازمة.
import numpy as np
import pandas as pd
import glob
import matplotlib.pyplot as plt
%matplotlib inline
import cv2
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from tensorflow.keras.applications.mobilenet import MobileNet
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
img_size = 128 # image height and width
train_size = None # number of samples for training
test_size = None # number of samples for testing
ثم تحميل الصور والتصنيفات
files_paths = glob.glob('data/train/*.jpg')
files_labels = [[1, 0] if 'dog' in f else [0, 1] for f in files_paths] # labels
print(len(files_paths), len(files_labels))
أخذ قائمة ملفات الصور والقيام ببعض عمليات المعالجة الأولية على الصور ومن ثم تحويلها إلى مصفوفة من الصور ليتم استخدامها في التدريب. تم اختيار 10000 صورة عشوائياً لسهولة وسرعة التدريب.
import random
random.Random(4).shuffle(files_paths)
random.Random(4).shuffle(files_labels)
def files_2_img_array(files_list):
imgs = []
for i in files_list:
img = cv2.imread(i)
img = cv2.resize(img, (img_size, img_size))
img = img / 255.
imgs.append(img)
return np.array(imgs)
x = files_2_img_array(files_paths[10000])
y = np.array(files_labels[10000])
print(x.shape, y.shape)
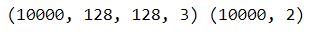
- رسم بعض النماذج من مجموعة البيانات التي تم تحميلها.
n = 4
fig, axs = plt.subplots(nrows=n, ncols=n, sharex=True, sharey=True, figsize=(10, 10))
for i in range(n**2):
ax = axs[i // n, i % n]
ax.imshow(x[i])
ax.set_title('label: %s, idx: %s' % (str(y[i]), str(i)))
ax.axis('off')
plt.show()

بعدها تطبيق تقنية تعزيز البيانات data augmentation لزيادة حجم بيانات التدريب من خلال إنشاء إصدارات مختلفة من الصور وذلك من أجل تحسين أداء وقدرة النموذج على التعميم.
x_flipped = np.array([np.fliplr(img) for img in x]) # performing flipping
x = np.concatenate([x, x_flipped])
y = np.concatenate([y, y])
del x_flipped
plt.imshow(x[100])
plt.axis('off')
plt.show()
plt.imshow(x[25100])
plt.axis('off')
plt.show()

تقسيم مجموعة البيانات إلى مجموعتي تدريب واختبار
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
if train_size:
x_train = x_train[:train_size]
y_train = y_train[:train_size]
if test_size:
x_test = x_test[:test_size]
y_test = y_test[:test_size]
print(x_train.shape, x_test.shape)
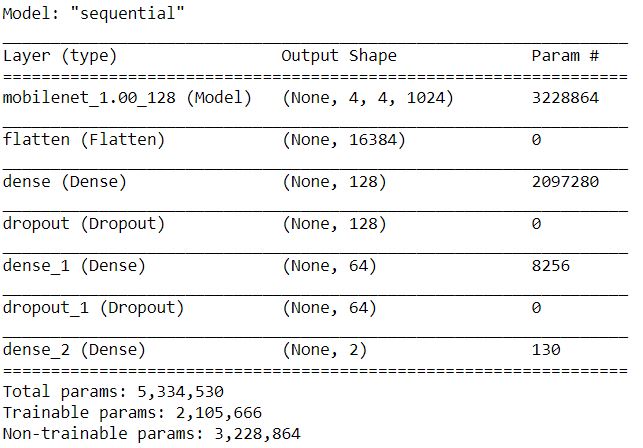
بناء نموذج موبايل-نت
mobile_net_model= MobileNet(weights='imagenet', include_top=False, input_shape=(img_size, img_size, 3))
mobile_net_model.trainable = False
model = Sequential()
model.add(mobile_net_model)
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(2, activation='softmax'))
model.summary()
تدريب النموذج
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['acc'])
history = model.fit(
x_train,
y_train,
epochs=15,
batch_size=100,
validation_data=(x_test, y_test),
verbose=1)

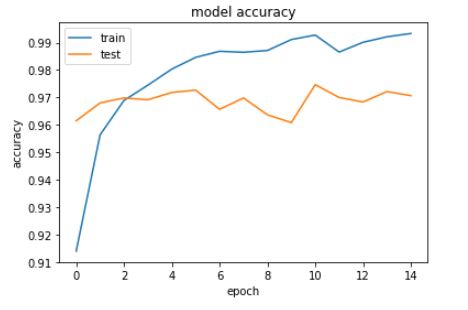
رسم نتائج تدريب النموذج – التمثيل البياني للدقة
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
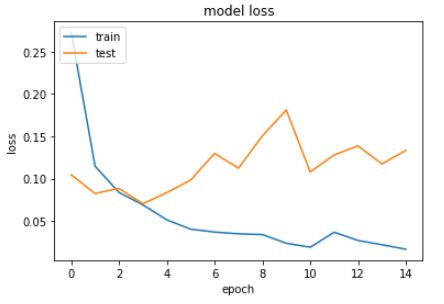
التمثيل البياني للخسارة
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
يمكنك عزيزي القارئ الاطلاع على الشيفرة البرمجية كاملةً على مستودع الجيت هب الخاص بنا.
التطبيق العملي الثاني:
- تم تنفيذ شبكة موبايل-نت باستخدام MPSCNN والتي تستخدم لغة الميتل Metal Shading Language لتحسين أداء شبكات الطّي العصبونية (وهي لغة غرضية التوجه تم تطويرها من قبل آبل Apple للأجهزة التي لها نظام التشغيل IOS ويتم استدعاؤها باستخدام لغات البرمجة سويفت Swift و سي غرضية التوجّه Objective-C وهي تسمح بالتكامل المحكم بين البرامج الرسومية و الحوسبة).
وقد تم تدريب هذه الشبكة بواسطة الكافيه Caffe، و لكن لغة الميتل لا تدعم عملية الطّي بالعمق المنفصل لذلك كان التحدي الأساسي هو كتابة نواة الطّي Kernal لعملية الطّي بالعمق باعتبار لغة الميتل لا تتضمن نواة جاهزة.
kernel void depthwiseConv3x3_array(
texture2d_array inTexture [[texture(0)]],
texture2d_array outTexture [[texture(1)]],
constant KernelParams& params [[buffer(0)]],
const device half4* weights [[buffer(1)]],
const device half4* biasTerms [[buffer(2)]],
ushort3 gid [[thread_position_in_grid]])
{
if (gid.x >= outTexture.get_width() ||
gid.y >= outTexture.get_height() ||
gid.z >= outTexture.get_array_size()) return;
constexpr sampler s(coord::pixel, filter::nearest, address::clamp_to_zero);
const ushort2 pos = gid.xy * stride;
const ushort slices = outTexture.get_array_size();
const ushort slice = gid.z;
half4 in[9];
in[0] = inTexture.sample(s, float2(pos.x - 1, pos.y - 1), slice);
in[1] = inTexture.sample(s, float2(pos.x , pos.y - 1), slice);
in[2] = inTexture.sample(s, float2(pos.x + 1, pos.y - 1), slice);
in[3] = inTexture.sample(s, float2(pos.x - 1, pos.y ), slice);
in[4] = inTexture.sample(s, float2(pos.x , pos.y ), slice);
in[5] = inTexture.sample(s, float2(pos.x + 1, pos.y ), slice);
in[6] = inTexture.sample(s, float2(pos.x - 1, pos.y + 1), slice);
in[7] = inTexture.sample(s, float2(pos.x , pos.y + 1), slice);
in[8] = inTexture.sample(s, float2(pos.x + 1, pos.y + 1), slice);
float4 out = float4(0.0f);
for (ushort t = 0; t < 9; ++t) {
out += float4(in[t]) * float4(weights[t*slices + slice]);
}
out += float4(biasTerms[slice]);
out = applyNeuron(out, params.neuronA, params.neuronB);
outTexture.write(half4(out), gid.xy, gid.z);
}
كما هو معروف عن نماذج الكافيه يجب إجراء بعض المعالجة المسبقة على صورة الدخل قبل تمريرها إلى الشبكة وذلك ضمن عدة خطوات:
- قراءة البيكسل المدخل (4 قنوات في المرة الواحدة)
- الضرب بالقيمة 255.0f (لأن الميتل يعطي اللون ضمن المجال من 0 لـ 1).
- طرح القيم المتوسطة لقنوات الألوان الأحمر والأخضر والأزرق من البيكسل.
- ومن ثم القيام بعملية التقييس بالقيمة 0.017f.بهذه الطريقة تم تدريب الشبكة!
- وأخيرًأ قلب لقنوات الألون الأحمر والأزرق لأن نماذج الكافيه تاخذ وحدات البيكسلات بالترتيب BGR.
kernel void adjust_mean_rgb(
texture2d inTexture [[texture(0)]],
texture2d outTexture [[texture(1)]],
uint2 gid [[thread_position_in_grid]])
{
const auto means = float4(123.68f, 116.78f, 103.94f, 0.0f);
const auto inColor = (float4(inTexture.read(gid)) * 255.0f - means) * 0.017f;
outTexture.write(half4(inColor.z, inColor.y, inColor.x, 0.0f), gid);
}
الشيفرة البرمجية الكاملة موجودة في مخزن الجيت هوب لتنفيذ هذه الشيفرة يجب توفر نظام تشغيل+ iOS10.0 ومن ثم تحميل الـ xcode 8.0 من متجر Apple.
(أمّا بالنسبة لمن لا يملك نظام تشغيل+ iOS10.0 فلن يستطيع تنصيب xcode كونه لا تتوفر نسخة منه تعمل على ويندوز وعوضًأ عن ذلك يمكن تنصيب vmware ومن ثم تحميل نظام mac من خلال تتبع الخطوات الموجودة في هذه المقالة ومن ثم تحميل xcode من متجر Apple بعد إنشاء حساب على AppDeveloper).
ملاحظة: لا يمكن تشغيل هذا المشروع على المحاكي Simulator كون أنه لم يكن يدعم لغة الميتل قبل نسخة iOS11 و xcode 11 أي يجب توفر جهاز iPhone حقيقي.

استخدام CoreMl
في نسخة نظام التشغيل المحدثة iOS11 تم إصدار بيئة عمل جديدة لتعلم الآلة تدعى Core ML. وهي توفر أدوات تحويل لـ CoreML لتشغيل شبكة موبايل-نت MobileNet عليها. ويوجد على الجيت هوب أيضًا نص التحويل والتي هي عبارة عن بضعة أسطر من الشيفرة البرمجية. وبأخذ مثال كامل من الجيت هوب لتطبيق لشبكة موبايل-نت MobileNet باستخدام الكورل إم إل سنحصل على النتيجة التالية:
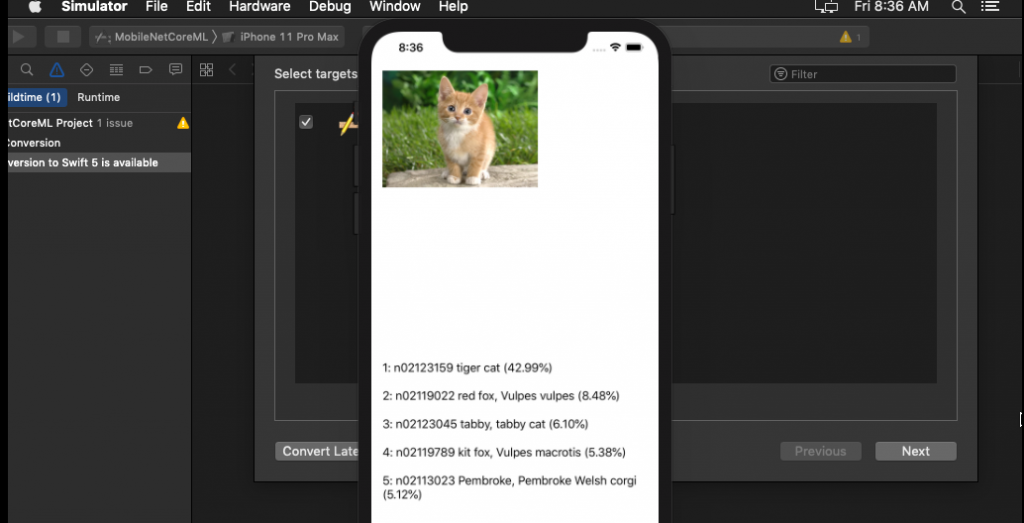
قياس أداء شبكات الموبايل-نت
لم يكن ناشر هذه الورقة يكذب عندما قال أن شبكات الموبايل سريعة
حتى عند تطبيق عملية الطّي بالعمق التي تمت كتابتها بشكل غير محسّن عملت بنية هذه الشبكة الكاملة بسرعة 0.05 ثانية لكل صورة على iPhone6s. عند السماح بتدفق الفيديو في الوقت الفعلي، وكان معدل استهلاك الطاقة الذي تم قياسه لبرنامج xcode من متوسط لمرتفع. أي ما يعادل 20 إطار في الثانية بتكلفة طاقة مقبولة. وهذا بالنسبة لشبكة عصبية عميقة ليس سيء..
وكيف تتم مقارنتها مع الشبكات الأخرى؟
تحسب عالشكل التالي: سرعة انسبشن Inception مضروبًة بـ3 و سرعة VGGNet-16 مضروبة بـ10.
وهي تستخدم طاقة بطارية أقل من كلاهما ويعود ذلك إلى العدد الأقل من المعاملات (4 ملايين مقابل 24 مليون في انسبشن النسخة الثالثة و138 مليون لشبكات الهندسة البصرية) حيث يعد الوصول إلى الذاكرة أكبر استنزاف لطاقة البطارية لذلك وجود عدد أقل من المعاملات يعد ميزة مهمة.
السرعة ليست كل شيء، لن تكون شبكات الموبايل-نت مفيدة إلا عندما تكون دقيقة أيضًا. إذاً ما مدى دقة هذه الشبكات؟
نماذج الكافيه التي دُربت على مجموعة بيانات الايمج نت. وبالعودة إلى الورقة كانت دقة التحقق الأولى لهذه الشبكات على الايمج نت 70.6% مقابل 71.5% لشبكات مجموعة الهندسة البصرية 16.
مؤلف نموذج كافيه يدّعي أن الإصدار الذي درّبه يحقق معدلات دقة أفضل قليلًا من الإصدار الأصلي المذكور في الورقة. ودقة أعلى بنسبة 70.81% في التحقق الأول ويصل إلى 89.85% في التحقق الخامس لذا فهي قريبة جدًأ من شبكات الهندية البصرية في الواقع.
هذا رائع لأن شبكات الهندسة البصرية 16 غالبًأ تستخدم لاستخراج المزايا لشبكات عصبية أخرى لذلك يمكن استبدالها الآن بشبكات الموبايل-نت والحصول على زيادة فورية في السرعة بمقدار عشر مرات.
الخاتمة
تعرفنا في هذه المقالة على البنية الأساسية لشبكة موبايل-نت وتعرفنا أيضًأ على السبب الذي جعلها أسرع وأدق لتتوافق مع إمكانيات الأجهزة المحمولة ألا وهو استخدام الطّي المنفصل بالعمق الذي حقق تطبيقه فيها نتائج رائعة بمقارنتها مع شبكات الانسبشن والهندسة البصرية. هذه الشبكات ليست هي الوحيدة ذات البنية الصغيرة التي تم تحسينها لأجهزة المحمول فهناك بنية أخرى شائعة تدعى SqueezeNet التي تم إصدارها عام 2016 من قبل الباحثين في DeepScale والتي تحوي عدد معاملات أقل لكن بدقة أقل ( 57.5% في التحقق الأول) أيضًأ من شبكة موبايل-نت. تتوفر الشيفرة البرمجية لشبكة موبايل-نت على موقع الجيت هوب بالتالي يمكن استخدامها في العديد من تطبيقات الرؤية وقد قمنا بعرض مثالين في مقالتنا.
إذا كنت مهتمًا باستكشاف المزيد حول أحدث التقنيات وتبحث أيضًا عن بعض المرح والترفيه ، ففكر في تجربة لعبة Let it ride Poker – https://slotogate.com/table-games/let-it-ride-poker/ . تقدم هذه اللعبة طريقة رائعة للاسترخاء والاستمتاع ببعض أعمال لعب الورق الافتراضية. اختبر مهاراتك في البوكر ، وخطط لتحركاتك ، واكتشف ما إذا كان بإمكانك الفوز بيدك. انغمس في عالم ألعاب الفيديو بوكر المجانية مع البقاء على اطلاع بأحدث التطورات في التكنولوجيا.





تعليق واحد