إعداد: م. محمّد سرميني، م. ماريا حمادة
التّدقيق العلمي: د.م. حسن قزّاز، م. رامي عقاد
المَحتويَات
المقدّمة:
كانت ومازالت البيانات بأنواعها محطّ أنظار واهتمام جميع المتخصّصين بها، من أجل معالجتها واستخراج المعلومات والأنماط (petterns) المهمّة غير المرئيّة منها; وغدت الآن بنوعها غير المهيكل (unstructured data) غزوًا احتلّ جميع المصادر بما فيها: المستندات النّصّيّة، رسائل البريد الإلكترونيّ، نتائج الاستطلاعات، منشورات وسائل التّواصل الاجتماعيّ، الصّور، ملفات الفيديو والصّوت وما إلى ذلك…
لذلك كان لابدّ من استغلال هذا التّواجد الهائل، من أجل خلق نموذجٍ_ أحدث فيما بعد ثورةً ونقطة تحوّلٍ كبيرٍ في مجال النّماذج الأساسيّة (Foundation Models) _ قادرٍ على تصنيف وتحليل وفهم المستندات المرئيّة (visual documents); ألا وهو مُحوّل فهم المستندات “دونات” (Document Understanding Transformer=Donut).
نتمنّى لكم أعزّاءنا القرّاء، قراءةً ممتعةً بين ثنايا مفرداتنا…
وفائدةً خيّرةً بين أسطر مقالتنا الاستثنائيّة اليوم..!
المُتطلّبات المُسبقة:
يَفترضُ مقالنا هذا إلمام القارئ بمفاهيم ومصطلحات تقنيّةٍ تُعتبر أساسيّةً تُبنَى عليها فكرة مُحوّل فهم المستندات “دونات” (Donut). من أهمّ هذه التّقنيّات على سبيل الذّكر وليس الحصر ما يلي:
- المُحوّل (Transformer) مرجع [1].
- المُشفّر (Encoder) مرجع [1].
- فاكُّ التّشفير (Decoder) مرجع [1].
- الاهتمام والاهتمام الذّاتيّ (Attention/Self Attention) مرجع [2].
لذلك قبل الخوض في عمق تفاصيل المعماريّة الخاصّة بنموذجنا، أوصيك عزيزي القارئ بالاطّلاع على المرجعين [2،1] الّذين يشرحان المفاهيم السّابقة بشكلٍ مُبسّطٍ وشيّقٍ.
ماهو نموذج دونات (Donut) وأين تكمن أهمّيته:
يعتبر دونات (Donut) نموذج مُحوّل لفهم المستندات (Document Understanding Transformer Model) بأنواعها المختلفة مثل: الفواتير التّجاريّة (commercial invoices)، الإيصالات (receipts) وبطاقات العمل (business cards) وغيرها الكثير…
وتكمن أهميّة هذا العمل الفريد في تحقيقه أداءً متطوّرًا (state-of-the-art performance) في العديد من المهام المتعلّقة بفهم المستندات المرئيّة (VDU) كمثل: تصنيف المستندات المرئيّة (visual document classification) أو استخراج معلوماتٍ مفيدةٍ من خلال تحليل المستندات (document parsing) بالإضافة إلى مهمّة الإجابة عن الأسئلة (question answering)، حيث أنّ دونات (Donut) يعتمد على استخدام طريقةٍ جديدةٍ لتمثيل البيانات تسمح بالتقاط العلاقات بين العناصر المختلفة في المستند بطريقةٍ أكثر دقة وفاعليّة [3].
ومن الجدير ذكره، أنّ هذا النّموذج قد تمّ اقتراحه من قبل فريقٍ من الباحثين في مجال تعلّم الآلة (ML) ضمن شركة نافر كلوفا (Naver Clova) والّتي تعتبر من الشّركات الرّائدة في مجال تقديم الخدمات السّحابيّة والبرمجيّة (software & cloud services)، حيث تمّ نشر الورقة البحثيّة الخاصّة به بعنوان: (OCR-free Document Understanding Transformer) والّتي يمكن الاطّلاع عليها من هنا [4].
المكوّنات الأساسيّة الخاصّة بنموذج دونات (Donut):
كما أشرنا سابقًا، يُستخدم نموذج دونات (Donut) من أجل الفهم العام لصور المستندات (document image) وفق بنيةٍ بسيطةٍ إلى حدٍّ ما مؤلّفةٍ من محوّلٍ (Transformer) معتمدٍ على وحدات تشفيرٍ مرئيّةٍ (visual encoder) مسؤولةٍ عن استخراج الميّزات (features) من أيّ مستندٍ مرئيٍّ معطى وأخرى خاصّةٍ بفكّ تّشفيرٍ نصّيّةٍ (textual decoder) مسؤولةٍ عن القيام بعمليّة الرّبط بين الميّزات الّتي تمّ الحصول عليها سابقًا والوحدات اللّفظيّة للكلمات الفرعيّة رغبةً بإنشاء التّنسيق المنظّم المرغوب كتنسيق (JSON) الّذي يعتبر طريقةً شائعةً في تمثيل وتنظيم البيانات [3].
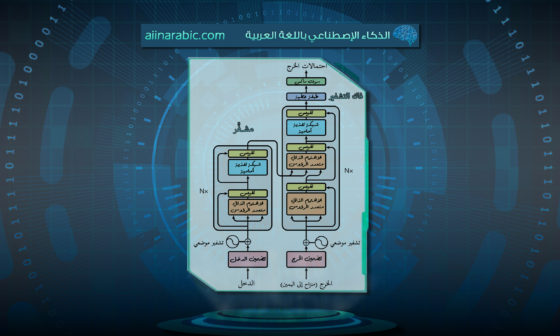
يمكن توضيح كامل البنية لنموذج دونات (Donut) من خلال الشّكل (1) التّالي:

وتأكيدّا على أهميّة الإلمام بالتّقنيّات آنفة الذّكر السّابقة باعتبارها انطلاقةً لفهم دونات (Donut)، وحرصًا على تكوين صورةٍ ذهنيّةٍ واضحةٍ عن آليّة عمل المحوّل، أُذكر عزيزي القارئ بالاطّلاع على المقال الخاصّ به من هنا.
إنّ المكوّنات الرّئيسيّة لبنية دونات (Donut) هي كالتّالي: المشفّر (encoder) المسؤول عن معالجة البيانات المرئيّة (visual data)، بالإضافة إلى فاكّ التّشفير (decoder) المسؤول عن معالجة البيانات النّصّيّة (textual data)، وبالتّالي يعمل النّموذج وفق مرحلتين أساسيّتين:
- مرحلة التّشفير (Encoding): يقوم المُشفّر في هذه المرحلة بمعالجة صورة الدّخل وتحويلها إلى مجموعةٍ من التّضمينات (embeddings)، والّتي هي عبارةٌ عن قيمٍ رقميّةٍ تمثّل أنواعًا مرئيّةً أو نصّيةً أو أيّ نوعٍ آخر من البيانات، حيث أنّ الغاية من هذه المرحلة تكمن في تحويل المعلومات المرئيّة للمستند إلى تنسيقٍ قابلٍ للقراءة بواسطة الآلة [5]. وعلى الرّغم من أنّه يمكن استخدام النّماذج المستندة إلى شبكات الطّيّ العصبونيّة (CNN) أو النّماذج المستندة إلى المحوّل (transformer) كشبكة تشفيرٍ ضمن هذه المرحلة، إلّا أنّ محوّل سوين (Swin transformer) قد تمّ استخدامه هنا لأنّه أظهر أفضل أداء في تحليل المستندات (document parsing). في بداية الأمر نلاحظ أنّ محوّل سوين (Swin) يقوم بتقسيم صورة الدّخل (x) إلى دفعاتٍ (patches) غير متداخلةٍ تُطبّق عليها الكتل والمجموعات الخاصّة بالنّموذج والّتي يمكن تلخيصها بوحدة الاهتمام الذّاتي متعدّد الرّؤوس (multi-head self attention) المستند إلى نافذةٍ منزلقةٍ (sliding window)، ثمّ بعد ذلك يتمّ تطبيق طبقات التّجميع على دفعات الصّورة هذه في كلّ مرحلةٍ، وفي النّهاية يتمّ تغذية خرج كتلة (Swin) إلى فاكّ التّشفير النّصّيّ التّالي (textual decoder) [3].
- مرحلة فكّ التّشفير (Decoding): يقوم فاكّ التّشفير في هذه المرحلة بأخذ التّضمينات (embeddings) الّتي تمّ إنشاؤها من قبل المشفّر من أجل توليد نصٍ بناءً على مخرجاته، ويعتمد هنا في عمليّة التّوليد على الكلمات الّتي تمّ إنشاؤها مسبقًا وكأنّها بمثابة سياقٍ (context) في سبيل إنشاء الكلمة التّالية [5]. أي بما معناه يقوم فاكّ التّشفير النّصّيّ بإنشاء تسلسلٍ خاصٍّ بالوحدة اللّفظيّة (token sequence) يمكن التّعبير عنه بواسطة شعاع ون هوت (one hot vector)، حيث يُستخدم هنا نموذج بارت (BART) ضمن معماريّة فكّ التّشفير تُؤخذ أوزان التّهيئة الخاصّة به من نموذج بارت (BART) متعدّد اللّغات والمدرّب مسبقًا والمتاح للعامّة [3].
مرحلة التّدريب المسبق (pre-training) ومولّد المستندات الاصطناعيّة (Synthetic Document Generator):
1-4- مرحلة التّدريب المسبق (pre-training):
يتمّ تدريب نموذج اللّغة المرئيّ دونات (Donut) على قراءة النّصوص في صورة المستند المرئيّ وفق ترتيب القراءة (من أعلى اليسار إلى أسفل اليمين)، والهدف هو بشكلٍ أساسيٍّ من أجل تقليل تابع خسارة الانتروبيا المتقاطعة (cross-entropy loss function) للتّنبؤ بالوحدة اللّفظيّة التّالية من خلال أخذ السّياقات السّابقة بعين الإعتبار [3].
لقد اعتُمد في عمليّة التّدريب على مجموعةٍ مرئيّةٍ (visual corpora) مثل مجموعة البيانات (IIT-CDIP) والّتي تعتبر مجموعةً مؤلّفةً من 11 مليون صورةٍ لمستنداتٍ خاصّةٍ باللّغة الإنكليزيّة ممسوحةٍ ضوئيًّا، ولكنّ هذا النّوع من مجموعة البيانات لا يتوفر بالنّسبة للّغات الأخرى المغايرة للإنكليزيّة; لذلك تمّ بناء منشئ مستنداتٍ اصطناعيّةٍ (Synthetic Document Generator=SynthDoG) قابلٍ للتّطوير للغات اليابانيّة، الصّينيّة والكوريّة [3]. وقبل الانتقال للحديث عنه نودّ التّنويه على تقنيّة التّعلّم بالفرض (teacher-forcing)_تُستخدم لتحسين عمليّة التّدريب_ والّتي تعتبر استراتيجيّةً لتدريب النّموذج، حيث تعتمد على تغذية فاكّ التّشفير (Decoder) بالإجابات الصّحيحة في أثناء تعلّمه وتدريبه، بدلًا من إعطائه مساحةً خاصّةً به ليخمّن الخرج بناءً على محاولاته السّابقة، وبالتّالي إجبار النّموذج على البقاء على مقربةٍ من العنوان الحقيقيّ الأساس (ground truth label)، فعلى سبيل المثال، من أجل مهمّة تصنيف المستندات يمكن التّعبير عن العنوان الحقيقيّ الأساس (ground truth label) كالتّالي:

كما ويوجد أيضًا نموذجان مدرّبان مسبقًا يشكّلان الأساس والعمود الفقريّ (backbones) لدونات كان ولابدّ من التّطرّق إليهما وهما:
- نموذج دونات الأساسي (Donut-base): تمّ تدريبه بواسطة 64 معالج رسوميّات (GPU) من نوع A100 ولمدّةٍ تقارب اليومين والنّصف، وكان عدد الطّبقات المستخدم ضمن مراحل التّشفير الأربع (2,2,14,2)، في حين استُخدم ضمن شبكة فكّ التّشفير 4 طبقاتٍ، حجم صورة الدّخل كان حوالي (1920*2560)، حجم النّافذة الخاصّة بنموذج سوين (Swin) كان 10، مجموعة البيانات (IIT-CDIP) كان حجمها حوالي 11 مليون، وأمّا مولّد المستندات الاصطناعيّة (SynthDoG) المتضمّن على اللّغة الإنكليزيّة, الصّينيّة، اليابانيّة والكوريّة كان حجمه حوالي (0.5M*4) [6].
- نموذج دونات بروتو (Donut-proto): تمّ تدريبه بواسطة ثمان معالجات رسوميّات (GPU) من نوع V100 ولمدّةٍ تقارب الخمسة أيّامٍ، وكان عدد الطّبقات المستخدم ضمن مراحل التّشفير الأربع (2,2,18,2)، في حين استُخدم ضمن شبكة فكّ التّشفير 4 طبقاتٍ، حجم صورة الدّخل كان حوالي (1536*2048)، حجم النّافذة الخاصّة بنموذج سوين (Swin) كان 8، وأمّا مولّد المستندات الاصطناعيّة (SynthDoG) المتضمّن على اللّغة الإنكليزيّة، اليابانيّة والكوريّة كان حجمه حوالي (0.4M*3) [6].
2-4- مولّد المستندات الاصطناعيّة (Synthetic Document Generator):
إنّ كلّ عيّنةٍ يتمّ إنشاؤها هنا تكون مكوّنةً من عدّة مكوّناتٍ وهي: الخلفيّة (background)، المستند (document)، النّصّ (text) والتّخطيط (layout)، وتُؤخذ جميعها وفق التّالي:
- عيّنات الخلفيّة (background): يتمّ تجميعها من مجموعة البيانات ايمج نت (ImegNet).
- عيّنات نسيج المستند (document texture): يتمّ أخذها من الصّور الورقيّة المجمعة.
- عيّنات الكلمات والعبارات (words and phrases): يتمّ تجميعها من ويكيبيديا (wikipedia).
- عيّنات التّخطيط (layout): يتمّ توليدها باستخدام خوارزميّةٍ مستندةٍ إلى القواعد، والّتي تقوم بتكديس الشّبكات (grids) بشكلٍ عشوائيٍّ [3].
ويعرض الشّكل (3) التّالي الأمثلة الّتي تمّ إنشاؤها وفق (SynthDoG):

المهام المتعلّقة بنموذج دونات (Donut):
تمّ اقتراح نموذج دونات (Donut) من أجل تنفيذ عددٍ من المهام المتعلّقة بفهم المستندات (Document Understanding) والّتي هي: مهمّة تصنيف المستندات, مهمّة استخراج المعلومات بالإضافة إلى مهمّة الإجابة عن الأسئلة. ونظرًا لقابليّة وقدرة دونات على تنفيذ هذه المهام المختلفة، قد يتبادر إلى أذهاننا السّؤال التّالي وهو: كيف بمقدور فاكّ التّشفير (Decoder) معرفة المهمّة أو مسار التّنفيذ الواجب اتّباعه من أجل الحصول على نتائج أفضل وتوليد المخرجات المطلوبة؟!
وهنا تكمن الإجابة من خلال الشّكل (1) المذكور سابقًا والّذي يوضّح لنا اعتماد نموذج دونات على استخدام فكرة الموجه (prompt) حيث يستخدم وحداتٍ لفظيّةٍ خاصّةٍ (special tokens) لتمثيل ووصف المهمّة المحدّدة المطلوب تنفيذها، فمثلًا في حالة مهمّة الإجابة عن الأسئلة يتمّ إدخال نصّ السّؤال مع صورة المستند المرئيّ إلى النّموذج لتوجيهه بشكلٍ أفضل.
1-5- مهمّة تصنيف المستندات (document classification):
تتلخّص هذه المهمّة في قدرة النّموذج على التّمييز بين أنواعٍ مختلفةٍ من المستندات، حيث أنّ دونات (Donut) يقوم (بعكس النّماذج الأخرى) بتوليد تنسيق (json) يحتوي على معلومات الصّنف (class information).
وهنا يتمّ تدريب النّموذج على مجموعة البيانات (RVL-CDIP) الّتي تتألّف من 400 ألف صورةٍ موزّعةٍ في 16 صنفٍ وفق 25 ألف صورةٍ للصّنف الواحد، حيث كانت هذه الأصناف: رسالة، مذكرة وبريدٍ إلكترونيٍّ وما إلى ذلك [3].
كما وتمّ تقسيم مجموعة البيانات هذه وفق التّالي: 320 ألف صورة تدريبٍ، و 40 ألف صورة تحقّقٍ و 40 ألف صورة اختبارٍ.
2-5- مهمّة تحليل المستندات/استخراج المعلومات (document parsing/information extraction):
تتلخّص هذه المهمّة في قدرة النّموذج على فهم التّخطيطات (layouts) والسّياقات (contexts) المعقّدة في المستندات، حيث يتمّ اختباره على العديد من صور المستندات الحقيقيّة بما فيها مجموعات البيانات الصّناعيّة الحقيقيّة [3].
وليست الغاية من هذه المهمّة فقط أن يقرأ النّموذج الأحرف بشكلٍ جيّدٍ، وإنّما يجب عليه أن يفهم التّخطيطات والدّلالات (semantics) من أجل استنتاج المجموعات والتّسلسلات الهرميّة المتداخلة بين النّصوص [3].
تمّ استخدام مجموعتي بياناتٍ معياريّةٍ عامّةٍ بالإضافة إلى مجموعتي بياناتٍ صناعيّةٍ مأخوذةٍ من منتجاتٍ خدميّةٍ في العالم الحقيقيّ (real world)، وهي وفق التّالي:
- مجموعة البيانات (CORD): تعدّ مجموعة بيانات الفواتير الموحّدة (Consolidated Receipt Dataset=CORD) بمثابة معيارٍ عام يتكوّن من (0.8k=800) صورة تدريبٍ و (0.1k=100) صورة تحقّقٍ و (0.1k=100) صورة اختبارٍ، كما وأنّ الحروف ضمن هذه الفواتير مكتوبةٌ بالأبجديّة اللّاتينيّة، وعدد الحقول الفريدة هو 30 حقل يحتوي على: اسم القائمة (menu name)، العدد (count) والسّعر الإجماليّ (total price) وما إلى ذلك [3].
- مجموعة البيانات (Ticket): تعدّ هذه المجموعة من مجموعات البيانات المعياريّة العامّة والّتي تتكوّن من (1.5k=1500) صورة تدريبٍ و (0.4k=400) صورة اختبارٍ لتذكرة قطارٍ صينيّةٍ، كما وتمّ اعتبار 10% من إجمالي الصّور كمجموعة تحقّقٍ أي مايعادل 150 صورةٍ، ويوجد هنا 8 حقولٍ تحتوي على: رقم التّذكرة (ticket number)، محطة البداية (starting station) ورقم القطار (train number) وما إلى ذلك [3].
- مجموعة البيانات (Business card): وهي بياناتٌ خدميّةٌ مأخوذةٌ من المنتجات الّتي تمّ نشرها، بحيث تتألّف من 120 ألف صورة تدريبٍ و (0.3k=300) صورة تحقّقٍ و (0.3k=300) صورة اختبارٍ لبطاقات عملٍ يابانيّةٍ، وبلغ إجمالي عدد الحقول فيها حوالي 11 حقل بما في ذلك: الاسم (name)، الشّركة (company) والعنوان (address) وما إلى ذلك [3].
- مجموعة البيانات (Receipt): وهي بياناتٌ خدميّةٌ أيضًا مأخوذةٌ من منتجات حقيقيّةٍ، تتكوّن من 40 ألف صورة تدريبٍ و 1000 صورة تحقّقٍ و 1000 صورة اختبارٍ لصور إيصالاتٍ كوريّةٍ، وبالنّسبة لعدد الحقول الفريدة فيها فكان حوالي 81 حقلٍ موزّعٍ وفق التّالي: معلومات المتجر (store inforamtion) ومعلومات الدفع (payment information) ومعلومات الأسعار (price information) وما إلى ذلك [3].
3-5- مهمّة الإجابة عن الأسئلة (document visual question anserwing=docVQA):
في هذه المهمّة، يتمّ تقديم أزواجٍ من صورة المستند والسّؤال حيث يتنبّأ النّموذج بإجابة السّؤال من خلال التقاط المعلومات المرئيّة والنّصّيّة في الصّورة، وهنا يتمّ جعل وحدة فكّ التّشفير (decoder) تولّد الإجابة عن طريق تحديد السّؤال (question) كموجّه بدايةٍ (starting prompt).
وأمّا مجموعة البيانات المستخدمة في هذا النّوع من المهمّات فكانت من مسابقة (Document Visual Question Answering)، وتتألّف من 50 ألف سؤالٍ محدّدٍ من أكثر من 12 ألف مستندٍ، كما ويوجد 40 ألف سؤال تدريبٍ و 5000 سؤال تحقّقٍ و 5000 سؤال اختبارٍ [3].
التّطبيق العمليّ:
تعرّفنا في الفقرات السّابقة على المُكوّنات الأساسيّة لبنية نموذج دونات (Donut) وعلى المهام الّتي يمكن تنفيذها بواسطته. والآن دعنا -عزيزي القارئ- نرى ما يُمكن فعله مع هذا النّموذج. في هذه الفقرة سنستعرض شيفرةً برمجيّةً بسيطةً تقوم بما يلي:
- تحميل نموذج دونات (Donut) المُدرّب مسبقًا إلى الذّاكرة.
- إعداد مُوجّه المهمّة (Task Prompt) ليقوم نموذج دونات (Donut) بتنفيذ المهمّة المطلوبة منه.
- تشغيل واجهة المُستعرض (Demo).
نحتاج لمكتبات البايثون التّالية لتشغيل المُستعرض:
- مكتبة المُحوّلات (transformers): الإصدار المُجرَّب (4.25.1)، وهي مكتبةٌ تضمُّ آلاف نماذج التّعلُّم العميق لتنفيذ عددٍ كبيرٍ من المهام ضمن العديد من المجالات. مكتبة المُحوّلات تدعم كلًّا من بايتورش (Pytorch) وتنسرفلو (TensorFlow) وجاكس (JAX).
- مكتبة بايتورش الخفيفة (pytorch-lightning): الإصدار المُجرَّب (1.6.4)، وهي الإصدار الخفيف من مكتبة بايتورش.
- مكتبة نماذج بايتورش-تيم (timm): الإصدار المُجرَّب (0.5.4)، وهي مكتبة بايتورش تضمُّ العديد من نماذج وأوزان مدرّبة بشكلٍ مُسبقٍ وشبكاتٍ عصبونيّةٍ عميقةٍ ومُحوّلاتٍ وشيفراتٍ برمجيّةٍ.
- مكتبة غراديو (gradio).
- مكتبة محوّل فهم المستندات دونات (donut-python).
أوّلًا: تمَّ استدعاء المكتبات اللّازمة كما هو مُبيّنٌ في الشّيفرة البرمجيّة التّالية:
- مكتبة غراديو (gradio): تُمكّن من عرض مشاريع تعلُّم الآلة في المُتصفّح.
- مكتبة تورش (torch): منصّة تورش الغنيّة عن التّعريف.
- مكتبة بيل (pil): مكتبة “بيل” مفتوحة المصدر للتّعامُل مع الصّور.
- مكتبة دونات (donut): تُمكّن من العمل مع نماذج “دونات” المدرّبة مُسبقًا.
import gradio as gr
import torch
from PIL import Image
from donut import DonutModel
ثانيًا: تمّ تحضير تابعين من أجل تنفيذ عمليّة الاستدلال باستخدام نموذج دونات المُدرّب مُسبقًا وإرجاع النّتيجة على شكل نصٍّ كما هو مُبيّنٌ في الشّيفرة البرمجيّة التّالية:
def process_vqa(input_img, question):
global pretrained_model, task_prompt
input_img = Image.fromarray(input_img)
user_prompt = task_prompt.replace("{user_input}", question)
output = pretrained_model.inference(input_img,
prompt=user_prompt)["predictions"][0]
return output
def process(input_img):
global pretrained_model, task_prompt
input_img = Image.fromarray(input_img)
output = pretrained_model.inference(image=input_img, prompt=task_prompt)["predictions"][0]
return output
كما هو واضحٌ أعلاه، إنَّ الفرق الوحيد بين التّابعين السّابقين يكمن في إعداد مُوجّه المهمّة (Task Prompt) وبالتّالي في نوع المهمّة الّتي سيقوم نموذج دونات (Donut) بتنفيذها. ففي التّابع الأوّل “process_vqa”، تمَّ تعديل مُوجّه المهمّة لتنفيذ مهمّة الإجابة عن الأسئلة (vqa) عن طريق إضافة سؤال المستخدم بينما يقوم التّابع الثّاني “process” بتنفيذ المهام الأخرى (تصنيف، تحليل المستندات، استخراج المعلومات).
ثالثًا: تمّ تهيئةُ مُعالج دونات (Donut Processor) ونموذج دونات (Donut) المُدرّب بشكلٍ مُسبقٍ كما هو موضّحٌ في السّطر البرمجيّ التّالي:
pretrained_model = DonutModel.from_pretrained(pretrained_path)
رابعًا: تمَّ فحصُ وجود منصّة البرمجة التّفرّعيّة كودا (CUDA) وفي هذه الحالة يتمُّ تنفيذ النّموذج على وحدة المُعالجة الرّسوميّة (GPU) وإلّا فإنّ التّنفيذ سيكون على المُعالج الرّئيسيّ (CPU)، كما هو موضّحٌ في الشّيفرة البرمجيّة التّالية:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrained_model.to(device)
pretrained_model.eval()
ملاحظة: تقوم ()model.eval بتهيئة النّموذج لمرحلة التّقييم أو الفحص عن طريق إطفاء بعض طبقات وأجزاء النّموذج المُستخدمة في مرحلة التّدريب مثل: طبقات تعطيل عمل العصبونات (Dropouts) وطبقات تقييس الدّفعة (BatchNorm) إلخ.
خامسًا: تمّ إعداد مُوجّه المهمّة (Prompt) لتنفيذ إحدى المهمّتين، الأولى هي مهمّة الإجابة عن الأسئلة (vqa) عن طريق إضافة سؤال المستخدم إلى المُوجّه، والثّانية هي تنفيذ المهام الأخرى (تصنيف، تحليل المستندات، استخراج المعلومات) عن طريق إضافة اسم المهمّة إلى المُوجّه كما هو مُبيّنٌ في الشّيفرة البرمجيّة التّالية:
if "docvqa" == task_name:
task_prompt = "{user_input} "
else: # rvlcdip, cord, ...
task_prompt = f""
وأخيرًا، تمَّ تشغيل واجهة المُستعرض كما هو موضّحٌ في الشّيفرة البرمجيّة التّالية:
demo = gr.Interface(
fn=demo_process_vqa if task_name == "docvqa" else demo_process,
inputs=["image", "text"] if task_name == "docvqa" else "image",
outputs="json",
title=f"Donut 🍩 demonstration for `{task_name}` task",
)
demo.launch()
والآن، بعدما انتهينا من شرح الشّيفرة البرمجيّة الخاصّة بواجهة المُستعرض، دعنا – عزيزي القارئ – نختبرُ نموذج دونات (Donut) ببعض الصّور. لنقم أوّلًا بتجريب مهمّة الإجابة عن الأسئلة، وللقيام بذلك يكفي أن نقوم بإسناد القيمة النّصّيّة التّالية “docvqa” لمُعامل اسم المهمّة (task_name) إضافةً إلى تمرير مسار (pretrained_path) نموذج دونات الخاصّ بمهمّة الإجابة عن الأسئلة. يُبيّن الشّكل (4) واجهة المُستعرض لنموذج دونات (Donut) من أجل تنفيذ مهمّة الإجابة عن الأسئلة:

يُبيّن الشّكل (5) صورةً لفاتورة كهرباءٍ نريد استخراج بعض المعلومات منها عن طريق تمرير بعض الأسئلة لنموذج دونات (Donut):

لنقم الآن بتمرير الأسئلة التّالية للنّموذج:
| 1. What is the issue date? |
| 2. What is the bill amount? |
| 3. What is the account number? |
يُبيّن الشّكل (6) إجابات النّموذج الصّحيحة للأسئلة السّابقة وهي على التّرتيب:
|
1. November 15, 2021 |
| 2. 3000 |
| 3. 12345678910 |

في المرحلة التّالية لنختبر نموذج دونات (Donut) في مهمّة تصنيف المستندات، وللقيام بذلك يكفي إسناد أيّ قيمةٍ نصّيّةٍ غير مساويةٍ للقيمة “docvqa” إلى مُعامل اسم المهمّة (task_name) ولتكن مثلًا “rvlcdip” إضافةً إلى تمرير مسار (pretrained_path) نموذج دونات الخاصّ بمهمّة تصنيف المستندات.
عند تمرير صورة فاتورة الكهرباء السّابقة إلى النّموذج، قام بتصنيفها كفاتورةٍ كما هو مُبيّنٌ في الشّكل (7):

أخيرًا، لنختبر نموذج دونات (Donut) في مهمّة تحليل المستندات واستخراج المعلومات. سنستخدم لهذه المهمّة نموذج دونات المُعادُ ضبطه (fine-tuned) على الإصدار الثّاني من قاعدة البيانات كورد CORD-v2 [7]. تمَّ إسناد القيمة النّصّيّة “cord-v2″ إلى مُعامل اسم المهمّة (task_name) إضافةً إلى تمرير مسار (pretrained_path) نموذج دونات الخاصّ بمهمّة تحليل المستندات. يُبيّن الشّكل (8) خرج النّموذج عند تمرير صورة إيصال مطعم:

ملاحظة: يمكنكم الاطّلاع وتحميل نماذج دونات المُختلفة من مستودع الشّيفرة البرمجيّة الرّسميّ لمشروع دونات [6].
الخاتمة:
وختامًا لمقالتنا الّتي لم تكن_ بكلّ مافيها من جوانب، انطلاقًا بتسليط الضوء على نموذج دونات (Donut) والتّعريف به كأسلوبٍ جديدٍ متّبعٍ في معالجة صور المستندات وفق كفاءةٍ حسابيّةٍ جيّدةٍ، مرورًا بسردٍ لأهمّ المكوّنات المبنيّ عليها، وانتهاءً بتوضيح إمكانيّاته المتمثّلة بتنفيذ مهمّة تصنيف المستندات (document classification)، ومهمّة تحليل المستندات/استخراج المعلومات (document parsing/information extraction)، ومهمّة الإجابة عن الأسئلة (doc VQA)، والّتي تمّ إسقاطها ونمذجتها جميعًا من خلال تطبيقٍ عمليٍّ بسيطٍ يعرض نتائج كلّ مهمّةٍ وفق واجهة المستعرض (Demo) _إلّا البداية لمعرفة كيفيّة تدريب نموذج دونات (Donut) وإعادة ضبطه (fine–tuning) في مقالتنا القادمة، فانتظرونا أعزّاءنا القرّاء…