المَحتويَات
- المقدمــة Introduction
- تمثيل الكلمات باستخدام ترميز ون هوت One Hot Encoding
- مساوئ تمثيل الكلمات باستخدام ترميز ون هوت One Hot Encoding
- تضمين الكلمات word embedding
- نماذج الكلمة إلى متّجه Word2Vec
- نموذجا تخطّي الكلمات Skip-Gram و حقيبة الكلمات المستمرّة CBOW
- تفاصيل نموذج تخطّي الكلمات Skip-Gram
- الطبقة الخفيّة لنموذج تخطّي الكلمات skip-Gram
- طبقة الخرج لنموذج تخطّي الكلمات skip-Gram
- نموذج حقيبة الكلمات المستمرّة CBOW
- مساوئ نموذجي تخطّي الكلمات Skip-Gram وحقيبة الكلمات المستمرّة CBOW
- الخاتمة
المقدمــة Introduction
عند القيام ببناء نماذج تعلم الآلة مهمّتها فهم وتفسير اللغات الطبيعيّة المتدفّقة مثل لغات البشر من غير الممكن لهذه النّماذج التّعامل مع البيانات النصيّة بشكل مباشر، فهي ليست ذكيّة بما فيه الكفاية لبدء معالجة النّص في شكلها الأصليّ، نماذج تعلّم الآلة تعتمد بشكل رئيسيّ على مبادئ الإحصاء والرّياضيات والتّحسين، ولا تفهم سوى لغة الأرقام الأمر الذي يستدعي إجراء معالجة مسبقة للبيانات النصيّة وتحويلها إلى تمثيل عدديّ مقابل لها، إنّ تحويل البيانات النصيّة إلى بيانات عدديّة مقابلة لها سيمكّن حتماً خوارزميّة التعلم الآليّ من فهمها والتعامل معها؛ حيث تعمل خوارزميّات التضمين Embedding على إيجاد تمثيل عدديّ مقابل للكلمات النصيّة بشكل فعّال.
تمثيل الكلمات باستخدام ترميز ون هوت One Hot Encoding
يتمّ تمثيل الكلمة بواسطة شعاع من الأعداد الصّحيحة {0,1}، وتتطلّب هذه الطّريقة أن تكون جميع المفردات محدّدة مسبقاً قبل إجراء عمليّة التّمثيل.
تتمثّل خطوات تمثيل الكلمة باستخدام ترميز ون هوت كالتالي:
- تحديد جميع المفردات الموجودة في مجموعة البيانات dataset.
- إجراء ترتيب أبجديّ لهذه المفردات.
- إنشاء قاموس للمفردات وإضافة جميع المفردات إليه بعد ترتيبها أبجديّاً.
- إسناد رقم فريد إلى كلّ كلمة موجودة في قاموس المفردات.
- تمثيل كلّ كلمة بشعاع طوله يساوي عدد المفردات، حيث تكون جميع عناصر هذا الشعاع أصفاراً ماعدا عنصر واحد يحمل القيمة واحد، وتمثل القيمة واحد في الشعاع موضع الكلمة في قاموس المفردات.
مثال:
بفرض لدينا قاموس يحتوي على المفردات التّالية:
{قطة , سيارة, طائرة, قطار, كلب}
يكون تمثيل هذه المفردات باستخدام ترميز ون هوت كالتّالي:

عند ترميز الكلمة “قطار” نلاحظ أنّ الرّقم 1 أخذ الموضع الثّاني في الشّعاع والقيمة 2 تمثّل موضع الكلمة في قاموس المفردات.
مساوئ تمثيل الكلمات باستخدام ترميز ون هوت One Hot Encoding
تتمثّل مساوئ تّرميز ون هوت في التكلفة الحسابيّة و الزّمنية اللازمة لمعالجة الأشعة الناتجة عن هذا التّرميز، فعلى سبيل المثال في حال كان لدينا قاموس يحتوي 10000 مفردة بالتالي نحن بحاجة إلى شعاع بحجم 1×10000 لتمثيل الكلمة الواحدة، وهذا رقم كبير بالنسبة لكلمة واحدة فلو أردنا على سبيل المثال تمثيل جملة تحتوي 100 كلمة، بالتالي سنحتاج إلى مليون قيمة من أجل إجراء تمثيل للجملة، من المساوئ الأخرى أيضاً أنّ الشعاع المعبّر عن الكلمة ليس له علاقة بمعناها، بمعنًى آخر إنّ كلمتين متشابهتين بالمعنى قد يتمّ تمثيلهم بأشعة بعيدة عن بعضهما، وبالنّظر إلى المثال التالي يتّضح الأمر:
بفرض لدينا مجموعة من المفردات تمّ ترتيبها أبجديّاً بغرض إيجاد تمثيل لها باستخدام ترميز ون هوت، سنأخذ من مجموعة المفردات عيّنة منها وهي كالتالي:

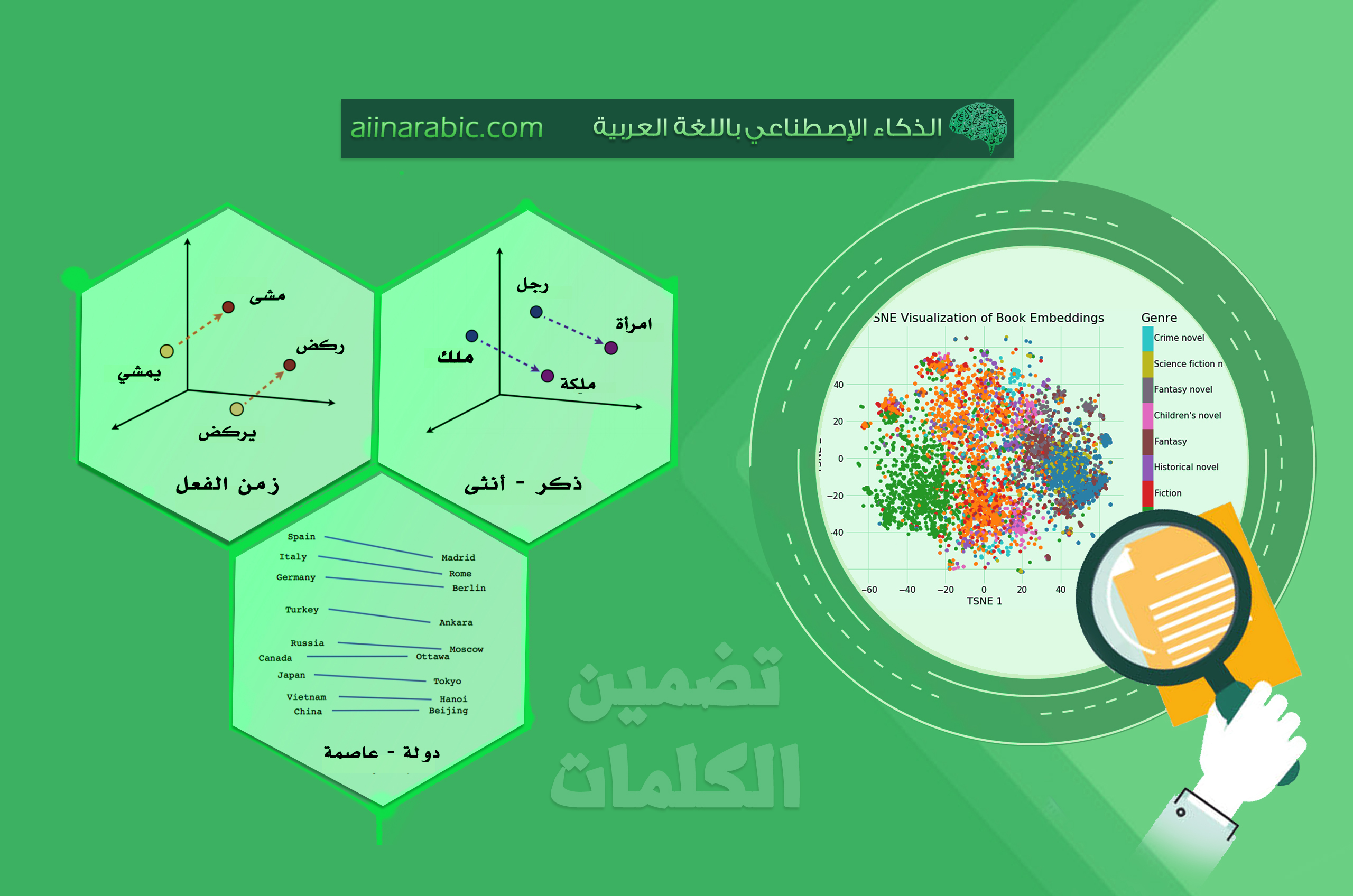
نلاحظ أنّ الكلمتين “ملك” و “ملكة” متشابهتان في المعنى ولكنّ أشعتهما بعيدة عن بعضهما جدّاً، ونلاحظ أيضاً أنّ الفرق بالأرقام بين الكلمتين “برتقال” و “ملكة” أقلّ من الفرق بين الكلمتين “برتقال” و “تفاحة” أي أنّ التشابه في المعنى بين الكلمتين “برتقال” و “ملكة” أكبر بكثير من الكلمتين “برتقال” و “تفاحة” وهذا خاطئ حتماً.
المشكلتان السّابقتان دفعت الباحثين إلى إيجاد أساليب أخرى لترميز الكلمات بشكل أكثر فعاليّة من الطريقة السّابقة، بحيث تقلّل من التكلفة الحسابيّة وأيضاً تمثّل الكلمات اعتماداً على سياقها؛ أي يتمّ تمثيل كلّ كلمتين متشابهتين بالمعنى بشعاعين قريبين من بعضهما (تكون المسافة الإقليديّة بينهما صغيرة) وبالمقابل أيضا الكلمات البعيدة تكون المسافة بينها بعيدة، وهذا ما يدعى بأسلوب التّضمين word embedding.
تضمين الكلمات word embedding
في هذه الطّريقة يتمّ أوّلاً تجميع الكلمات التي نرغب في إيجاد ترميز لها، ومن ثمّ اختيار بُعد الشعاع للكلمة، هنا البُعد يرمز إلى عدد الميّزات features، هذه الميّزات ستصف الكلمة (سنوضح هذا لاحقاً)، في هذه الحالة نستطيع التحكّم ببُعد شعاع الكلمة (عدد الميّزات) ونستطيع جعله أقلّ بكثير من العدد الإجماليّ للمفردات، قيمة كلّ ميّزة في الشعاع تكون عدداً حقيقيّاً ضمن المجال [1,-1]، وكلّما كانت القيمة قريبة من الواحد كلّما كانت الميّزة تعبر عن الكلمة والعكس في حال اقتربت من الصّفر. على سبيل المثال بإمكاننا اختيار 300 ميّزة في حال كان لدينا قاموس يحتوي على 10000 مفردة، وهذا ما يؤدّي إلى تخفيض التكلفة الحسابيّة والزمنيّة بشكل كبير مقارنة مع ترميز ون هوت.
مثال توضيحيّ:
بفرض لدينا المفردات التالية
{ولد , أميرة , ملكة , ملك}
والميّزات المستخدمة لهذه المفردات هي
(العمر, أنثى, ذكر, ملكي)
لدينا الجدول التالي يعبّر عن شعاع كلّ كلمة.

نلاحظ من الجدول السّابق أنّ الميّزة “ذكر” تخصّ الكلمتين “ملك” و “ولد” فقط لذلك تكون قيمتها عند هاتين الكلمتين قريبة من الواحد بينما هذه الميّزة لا تخصّ الكلمتين “ملكة” و “أميرة” لذلك تكون قيمتها عند هاتين الكلمتين قريبة من الصفر. باستخدام هذه الطّريقة استطعنا تمثيل الكلمات التي تتشابه في المعنى بأشعة قريبة جدّاً من بعضها؛ أي أنّ المسافة الإقليديّة بينهما تكون صغيرة وهذا مفيد جدّاً في حالات كثيرة منها حالة تعميم الشبكة العصبونيّة. فعلى سبيل المثال في حال أردنا إجراء تحليل مشاعر للجمل النصيّة وتصنيفها إلى ثلاثة أصناف هي إيجابيّ Positive و سلبيّ Negative وحياديّ Neutral. في حال كان لدينا الجملتين التاليتين:
- بعد استخدام الجهاز لمدة شهر أدركت أنه جهاز جميل.
- بعد استخدام الجهاز لمدة شهر أدركت أنه جهاز رائع.
نذكر أنّ الكلمتين “رائع” و “جميل” متشابهتان جدّاً بالمعنى ويتمّ استخدامهما في سياق متشابه، أثناء تدريب الشبكة العصبونيّة كانت الجملة الأولى موجودة في مجموعة بيانات التّدريب،
Training Dataset وتمّ تدريب الشبكة العصبونيّة على أن يكون خرج هذه الجملة إيجابيّاً. الجملة الثانية موجودة في مجموعة بيانات الاختبار ،Test dataset ولم تتدرّب عليه الشبكة أثناء عمليّة التّدريب، في حال أدخلنا الجملة الثانية إلى الشبكة العصبونيّة لمعرفة خرج هذه الجملة مع العلم أنّ كلمة “رائع” غير موجودة أبداً في بيانات التّدريب. وباستخدام أسلوب التّضمين سيتمّ تمثيل كلمة “رائع” بشعاع قريب جداً من “جميل” وبالتالي ستتمكن الشبكة العصبونيّة من إعطاء خرج إيجابي ، فنستنتج ميّزة كبرى لـدى تضمين الكلمات word embedding وهي أنّها قادرة على إجراء تعميم بشكل كبير جداً للشبكة العصبونيّة.
هو بالضّبط ما يسعى نموذج الكلمة إلى متّجه Word2Vec إلى القيام به، إنّه يحاول تحديد معنى الكلمة من خلال تحليل الكلمات المجاورة لها (سياق الكلام).
توضيح: يقصد بمفهوم تعميم الشبكة العصبونية هو قدرة الشبكة العصبونية على التكيف واتخاذ القرارات الصحيحة من أجل البيانات الجديدة غير المرئية سابقًا والمستمدة من نفس التوزيع المستخدم في تدريب الشبكة العصبونية.
نماذج الكلمة إلى متّجه Word2Vec
هي مجموعة من النّماذج تعمل على تمثيل الكلمة اعتماداً على سياقها في متّجه أبعاده N، تمّ تطوير هذا الأسلوب من قبل توماس ميكولوف Tomas Mikolov في العام 2013 لجعل التّدريب في الشبكات العصبونيّة مبنيّ على التّضمين، والذي يحقق أكثر كفاءة ومنذ ذلك الحين أصبح المعيار الواقعيّ لتطوير تضمين الكلمة.
نماذج الكلمة إلى متّجه تجيبنا على السؤال التالي:
العلاقة بين الكلمتين “رجل” و “أمرأة” هي بمثابة العلاقة بين الكلمتين “ملك” و ؟؟ وماذا ؟؟

إنّ طرح شعاع الكلمة “رجل” من شعاع الكلمة “ملك” ثمّ إضافة شعاع الكلمة “أمرة” ينتج عنه شعاع الكلمة “ملكة” ، وهو أقرب ما يكون إلى شعاع الكلمة “ملك” وبالتالي هي إجابة صحيحة منطقيّاً. كما هو موضّح في الشكل 2.

نجد أنّ هذه التمثيلات جيدة بشكل مدهش في التقاط التراكيب النحويّة والدلاليّة في اللّغة. سوف نستعرض في هذا المقال نموذجين مختلفين للتدريب يندرجان تحت فكرة نماذج الكلمة إلى متّجه لتعلّم تضمين الكلمات وهما :
_ نموذج تخطّي الكلمة ( Skip-Gram Model)
_ نموذج حقيبة الكلمات المستمرّة (CBOW (Continuous Bag of Words
نموذجا تخطّي الكلمات Skip-Gram و حقيبة الكلمات المستمرّة CBOW
نماذج الكلمة إلى متّجه تتضمّن بشكل أساسيّ النموذجين تخطّي الكلمة و حقيبة الكلمات المستمرّة، حيث يتنبّأ نموذج تخطّي الكلمة بالسّياق استنادًا إلى كلمة الدّخل، بينما يعمل نموذج حقيبة الكلمات المستمرّة بشكل مغاير؛ حيث يتنبّأ بالكلمة استناداً على السّياق. الشكل 3 يوضّح الاختلاف بين نموذجي تخطّي الكلمة وحقيبة الكلمات المستمرّة.

تتشابه عمليّة النّمذجة في نماذج “الكلمة إلى متّجه” مع فكرة المشفّر التلقائيّ autoencoder، فالهدف هو الحصول على مصفوفة أوزان الطبقة المخفية التي تحقق متجهات الكلمة word vectors وللحصول على ذلك نقوم بإنشاء مهمة مزيقة fake task لتدريب الشبكة العصبونية حيث لا نهتم بالدخل والخرج للشبكة وإنما يهمنا مصفوفة أوزان الطبقة الخفية فقط [1].
لنلقِ نظرة على كيفيّة تدريب الشّبكة العصبونيّة. بفرض لدينا الجملة التالية:
“الثعلب البني السريع يقفز فوق الكلب الكسول”
- أوّلاً نختار كلمة الدّخل من منتصف الجملة، على سبيل المثال نختار الكلمة “البني”.
- مع كلمة الدّخل نحدّد معامل يسمى نافذة التخطي skip_window يمثّل حجم النّافذة التي تعرّف المجال الذي يمكن اختيار كلمات الخرج منه (البعد عن كلمة الدخل)، بفرض وضعنا القيمة skip_window = 2 يكون حجم النافذة كلمتين على اليسار وأيضاً كلمتين على اليمين.
- هناك معامل آخر يدعى num_skips، والذي يمثّل عدد الكلمات المختلفة التي نختارها بشكل عشوائيّ من النّافذة بأكملها (تكون هذه الكلمات هي المخرجات).
- عندما يكون skip_window = 2 ، num_skips = 2، فإننا سنحصل على مجموعتين من بيانات التّدريب بالصيغة التالية (context ، target).
- على سبيل المثال تكون المجموعتان : (“بني” ، “ثعلب”) (“بني” ، “سريع”)
- ستقوم الشبكة العصبونيّة بإخراج الاحتمالات استنادًا إلى بيانات التّدريب.
يُظهرالشكل 4 بعض الأمثلة من عينات التّدريب، نختار الجملة
“الثعلب البني السريع يقفز فوق الكلب الكسول”
يمثّل اللون الأزرق كلمة الدّخل، ويمثّل المربع الكلمات في نّافذة عينات التّدريب (المدخلات والمخرجات)

تفاصيل نموذج تخطّي الكلمات Skip-Gram
نموذج تخطّي الكلمات ما هو إلا شبكة عصبونيّة نرغب في تدريبها من أجل الحصول على مصفوفة أوزان الطبقة المخفيّة، والتي تمثل أشعة التّضمين (كما سنوضح لاحقاً)، لكن قبل تدريب هذه الشّبكة نحتاج إلى تمثيل الكلمات النصيّة بشكل عدديّ فكما ذكرنا أنّ الشّبكة العصبونيّة لا تقبل سوى المدخلات العدديّة، وأبسط طريقة لترميز الكلمات هي طريقة ون هوت لذلك سوف نختارها.
ملاحظة: في نموذج تخطّي الكلمة استخدمنا ترميز ون هوت كطريقة فقط لنصل إلى ترميز التّضمين.
بفرض تمّ استخراج 10000 كلمة فريدة من نوعها من بيانات التّدريب لتشكيل قاموس المفردات، نقوم بإجراء ترميز ون هوت على هذه الكلمات البالغ عددها 10000، وكلّ كلمة تمّ الحصول عليها هي متّجه بعشرة آلاف، بالتالي سيكون بُعد طبقة الدّخل في نموذج تخطّي الكلمة هو 10 آلاف وأيضاً طبقة الخرج بنفس البُعد.
الشكل التالي يوضح معماريّة الشبكة العصبونيّة في نموذج تخطّي الكلمة:

تستخدم الطبقة الخفيّة التابع الخطّي Linear كـ تابع تنشيط، لكنّ طبقة الإخراج تستخدم تابع سوفت ماكس softmax .
نقوم بتدريب الشبكة العصبونيّة على أساس أزواج من الكلمات، وعيّنات التدريب هي أزواج من الكلمات مثل (كلمة الإدخال ، كلمة الإخراج) وكلّ من مدخلات الشبكة ومخرجاتها هي متّجهات مرمّزة باستخدام طريقة ون هوت.
الطبقة الخفيّة لنموذج تخطّي الكلمات skip-Gram
بعد الحديث عن ترميز الكلمات واختيار عينات التّدريب، نلقي نظرة على الطبقة الخفيّة . إذا أردنا الآن تمثيل كلمة بها 300 ميزة، بالتالي يجب أن تحتوي الطبقة الخفيّة على 300 عصبون (أي البُعد هو 300)، تصبح مصفوفة أوزان الطبقة الخفيّة هي 10000×300 (أي 10000 صف و 300 عمود) كما يوضّح الشكل 6.

بالنّظر إلى الشكل 7 تمثل الصورتان اليمنى واليسرى على التّوالي مصفوفة أوزان الطّبقة الخفيّة (المصفوفة Wax)، يمثل كلّ عمود في الصورة اليسرى متّجهًا يتكوّن من 10000 قيمة متصلة بخليّة عصبونيّة واحدة في الطبقة الخفيّة . في الشكل الموجود على اليمين، كلّ سطر في المصفوفة يمثل متّجه كلمة التّضمين.

لذلك هدفنا النهائيّ هو استخراج مصفوفة الأوزان للطبقة الخفيّة، وبعد ذلك يتمّ الحصول على أشعة التّضمين بإجراء عمليّة الضرب للمتّجه 1 × 10000 مع المصفوفة 10000 × 300، هذا الأمر سوف يسبّب استهلاكاً كبيراً للموارد الحاسوبيّة، ولكي يتمّ استخراج شعاع التّضمين بكفاءة دون الحاجة لعمليّة الضرب، فإنه سيتمّ تحديد صفّ الفهرس فقط بقيمة البعد 1 في المتّجه المقابل في المصفوفة كما توضّح الصّورة التالية.

كما ذكرنا أعلاه أنّ كلمة الدّخل ستكون مرمّزة بأسلوب ون هوت ومعظم قيم الشعاع تأخذ القيمة 0، موضع واحد فقط يكون 1.
يمكننا أن نرى أنّ نتيجة الضرب للمصفوفة هي في الحقيقة مؤشّر القيمة 1 في المتّجه المقابل للمصفوفة.
في المثال أعلاه البعد المقابل للقيمة 1 في المتّجه الأيسر هو 3 ثمّ تكون نتيجة الحساب هي الصفّ الثالث من المصفوفة، لذلك عند استخراج شعاع التّضمين يتمّ البحث مباشرة عن قيم الوزن المقابلة للقيمة 1 في متّجه الدّخل. العلاقة الرّياضيّة التالية توضّح خرج الطبقة الخفيّة لكلّ كلمة دخل.
ex = Wax X
حيث أنّ :
ex : شعاع الكلمة المضمّن
Wax: مصفوفة أوزان الطبقة الخفيّة
X : شعاع كلمة الدّخل المرمز بترميز ون هوت.
طبقة الخرج لنموذج تخطّي الكلمات skip-Gram
بعد حساب الطبقة الخفيّة للشبكة العصبونيّة ستتغيّر الكلمة من متّجه 1 × 10000 إلى متّجه 1 × 300 ثمّ يتمّ إدخالها في طبقة المخرجات، طبقة الخرج عبارة عن طبقة تصنيف بتابع تنشيط سوفت ماكس، حيث ستنتج كلّ عقدة منها قيمة احتماليّة ضمن المجال [0,1].

تدريب نموذج تخطّي الكلمات Skip-Gram
تقوم الشّبكة في البداية بتهيئة أوزانها بشكل عشوائيّ، ثمّ تقوم بضبط أوزانها بشكل متكرّر أثناء التّدريب لتقليل الخطأ الذي تحدثه عند التنبّؤ بكلمات السياق. ولتوضيح فكرة التّدريب نأخذ المثال التالي :
بفرض لدينا الجملة
يوم سعيد يا صديقي!
ففي حال كان لدينا العيّنة على سبيل المثال (“يوم” ، “سعيد”) وقمنا بإدخال الكلمة “سعيد” إلى الشبكة العصبونيّة، وكان خرج شعاع ون هوت يمثل الكلمة “جحيم” وهذا معناه أنّ الكلمة “جحيم” تظهر بكثرة في سياق كلمة “سعيد” وهذا غير صحيح، وبمقارنته مع الخرج الحقيقيّ يظهر خطأ كبير، بالتالي سوف يتمّ استخدام هذا الخطأ في استراتيجية التسلسل الخلفي back propagation لتعديل الأوزان من أجل تقليل احتماليّة الكلمة “جحيم” وتزويد احتماليّة للكلمة “يوم” ستكون الكلمات ذات المعنى المماثل قريبة من بعضها البعض، وهذا يحدث بمفرده لأنّ الكلمات المتشابهة ستكون محاطة أيضًا بسياق مشابه، وهذا يؤدّي إلى تعديل مشابه للأوزان. بعد الانتهاء من عمليّة التّدريب يتمّ وضع مصفوفة الأوزان الخفيّة Waxفي الواجهة الأماميّة للشّبكة العصبونيّة الارتجاعيّة Recurrent Neural Network.
نموذج حقيبة الكلمات المستمرّة CBOW
يعمل نموذج حقيبة الكلمات المستمرّة بشكل مغاير لنموذج تخطّي الكلمة، حيث يستخدم للتنبّؤ بالكلمة الهدف الحالية (الكلمة المركزية) بناءً على كلمات السياق (الكلمات المحيطة)؛ أي تشكيل أزواج (context, target). كما يوضّح الشكل 9.

يوضّح الشكل التالي بنية الشبكة لنموذج حقيبة الكلمات المستمرّة.

x1 ، x2 ، …. Xc في الشكل 10 تمثّل كلمات السّياق بالنسبة لطبقة الخرج والطبقة الخفيّة وآليّة تدريب نموذج حقيبة الكلمات المستمرّة، فهي مشابهة تماماً لنموذج تخطّي الكلمة.
مقارنة سريعة بين نموذجي تخطّي الكلمات وحقيبة الكلمات المستمرّة:
نموذج تخطّي الكلمة: يعمل بشكل جيّد مع بيانات التّدريب التي حجمها صغير ويمثّل بشكل جيّد حتى الكلمات أو العبارات النّادرة.
نموذج حقيبة الكلمات المستمرّة: أسرع بعدّة مرّات من ناحية التّدريب مقارنة مع تخطّي الكلمة.
مساوئ نموذجي تخطّي الكلمات Skip-Gram وحقيبة الكلمات المستمرّة CBOW
على سبيل المثال في حال كان لدينا مجموعة بيانات مكونة من 10,000 كلمة، و أردنا إجراء تضمين لكلمات التّدريب بحيث تحتوي الطبقة الخفيّة على 300 عصبون، فسنحصل على مصفوفة أوزان بالنسبة للطبقة الخفيّة 10000 × 300 أي 3 ملايين معامل (بمعنى 3 ملايين علاقة رياضيّة)، التّصنيف في مثل هذه الشبكة العصبونيّة الضّخمة بطيء للغاية، ونحتاج إلى الكثير من بيانات التّدريب لضبط أوزان هذه الشبكة بشكل مثالي. الملايين من القيم في مصفوفات الأوزان والآلاف من عيّنات التّدريب تعني أنّ تدريب هذا النموذج سيكون صعباً جداً.
الخاتمة
تعرّفنا في هذا المقال على مفهوم تضمين الكلمة، ورأينا كيف يتمّ ترميز الكلمة النّصيّة باستخدام ثلاث طرق هي: ترميز ون هوت ونموذج تخطّي الكلمة ونموذج حقيبة الكلمات المستمرّة. تعرّفنا أيضاً على طبقة الدّخل والخرج في معماريّة الشبكة العصبونيّة المستخدمة في نموذج تخطّي الكلمة، بالإضافة إلى الطبقة الخفيّة. رأينا بشكل تفصيليّ كيف يتمّ ترميز الكلمة باستخدام نموذج تخطّي الكلمة، أمّا بالنسبة لآليّة التّرميز باستخدام نموذج حقيبة الكلمات المستمرّة، فهي مشابهة تماماً لآليّة التّرميز في نموذج تخطّي الكلمة مع بعض الاختلافات البسيطة، وأخيراً قمنا باستعراض مساوئ كلٍّ من نموذجي تخطّي الكلمة وحقيبة الكلمات المستمرّة.
المراجــــع
[1]- Word2Vec Tutorial – The Skip-Gram Model.
[2]- Skip-Gram: NLP context words prediction algorithm.
[3]- A non-NLP application of Word2Vec.
[4]- Using Word2Vec to spot anomalies while Threat Hunting using ee-outliers.




تعليقان
شرح جميل جدا