إعداد: م. ماريّا حماده
التّدقيق العلميّ: د.م. حسن قزّاز، م. محمّد سرميني
المَحتويَات
المقدّمة.
كثرَ الحديث في الآونة الأخيرة عن المعماريّات المعتمدة على تقنيّة الاهتمام الذّاتيّ (self attention-based architectures) ومنها على وجه الخصوص المحوّلات (transformers)، حيث تُعتبر هذه التّقنيّة مكوّنًا أساسيًّا لها وعصب ولادة وأوج دقة أدائها.
وبالفعل، تُرجم هذا الحديث إلى اهتمامٍ حثيثٍ تناقله مجتمع معالجة اللّغات الطّبيعيّة (NLP) عبر طرح ونشر أوراقٍ ومقالاتٍ بحثيّةٍ علميّةٍ متخصّصةٍ توضّح قدرة المحوّلات التّمثيليّة العالية في إنتاج دقةٍ وأداءٍ عاليين بالمجمل من أجل الارتقاء بحلّ مختلف مشاكل ومهام وتطبيقات العالم الحقيقيّ (real world applications).
إذًا، هيّا بنا لنكتشف سويّةً بحر معرفتنا اليوم (محوّل الرّؤية ViT) ونجوب في آفاقه; لنسقصيَ الحقيقة وراء إمكانيّة محاكاة أسلوب المحوّل المتّبع في معالجة البيانات النّصّية ضمن نماذج سلسلة إلى سلسلة (seq2seq models)، وإسقاطه بشكلٍ نظيرٍ وحديثٍ على مختلف مهام الرّؤية الحاسوبيّة (Computer Vision).
تاريخ تطوّر المحوّلات.
إنّ مختلف أنظمة الذّكاء الاصطناعيّ _كما هو متعارفٌ عند الكثير منّا_ تعتمد على الشّبكات العصبونيّة العميقة (Deep Neural Networks=DNNs) والّتي تُعكسُ كبنيةٍ تحتيّةٍ أساسيّةٍ لها، بالإضافة إلى كون كلّ نوعٍ مختلفٍ من المهام يُرفق بمتطلّباتٍ وشبكات معالجةٍ مختلفةٍ ومعيّنةٍ [1]. فقد وُجدت شبكات الطّيّ العصبونيّة (CNNs) من أجل تقديم معالجةٍ لبياناتٍ ثابتةٍ (invariant data) مثل الصّور (images)، في حين ظهرت الشّبكات العصبونيّة الإرجاعيّة (RNNs) من أجل معالجة البيانات المتسلسلة (sequential data) أو بيانات السّلاسل الزّمنيّة (Time Series data)، ولاحقًا لظهورٍ سابقٍ، اعتُمدت المحوّلات (transformers) كنوعٍ جديدٍ من الشّبكات العصبونيّة (Neural Network) المرتكزة على تقنيّة الاهتمام الذّاتيّ (self-attention) لاستخراج كافة الميّزات الجوهريّة من بيانات المعالجة [1].
سنعرض لكم أعزّاءنا القرّاء فيما يلي، خطًّا زمنيًّا تتابعيًّا يوضّح تاريخ تطوّر هذه المحوّلات بدءًا من اقتحامها لعالم معالجة اللّغات الطّبيعيّة إلى حين هيمنتها على غالبيّة مهام الرّؤية من خلال الشّكل (1) التّالي:

في بادئ الأمر، ظهرت المحوّلات عام (2017) وطُبّقت لأوّل مرّةٍ على مهامّ معالجة اللّغات الطّبيعيّة مثل التّرجمة الآليّة (machine translation) وغيرها الكثير، وبالطّبع عزيزي القارئ، يمكنك الاطّلاع على كامل التّفاصيل المتعلّقةِ بالمحوّلات وآليّة ومبدأ عملها من خلال مقالٍ سابقٍ لنا بعنوان “المُحوّل” المُدرج في المرجع [2]. ونظرًا للتّطوّرات القائمةِ في هذا المجال، تمّ تقديم نموذجٍ جديدٍ لتمثيل اللّغة عام (2018) يدعى بيرت (BERT) اختصارًا لتمثيلات التّشفير ثنائيّة الاتّجاه من المحوّلات (Bidirectional Encoder Representations from Transformers) وهو نموذجٌ مدرّبٌ مسبقًا يأخذ بعين الاعتبار سياق كلّ كلمةٍ في أثناء المعالجة [1].
توالت التّطوّرات والتّحسينات للنّماذج المعتمدة على المحوّلات (Transformer-based models)، إلى أن أبصر نموذج جبت-3 (GPT-3) النّور عام (2020) ويُعدّ اختصارًا للمحوّل التّوليديّ المدرّب مسبقًا (Generative Pre-trained Transformer-3) حيث دُرّب بشكلٍ أسبقيٍّ على (45) تيرابايت من بياناتٍ نصّيّةٍ مضغوطةٍ وباستخدام (175) مليار معاملٍ [1].
ونتيجة الإقبال الشّديد على استخدام المحوّلات ونجاح معماريّتها الملحوظ في العديد من تطبيقات معالجة اللّغات الطّبيعيّة (NLP); تمّ الإتيانُ بفكرة تطبيقها أيضًا في مجال الرّؤية من خلال ذلك، حيث كانت شبكات الطّيّ العصبونيّة تحتلّ الصّدارة في تطبيقات الرّؤية في حين أصبحت الآن هذه المحوّلات بديلًا مثاليًّا عنها بفضل أدائها الاستثنائيّ. ففي عام (2020)، ظهر نموذج ديتر (DETR) وهو محوّلٌ تسلسليٌّ للتّنبؤ بقيم البكسلات بشكلٍ رجعيٍّ (auto-regressively)، حقّق تشابهًا من حيث النّتائج مع (CNN) في مهامّ تصنيف الصّور (image classification)، كما وأنّه استُخدم في المهامّ المتعلّقة بالرّؤية عالية المستوى (high level vision) [1].
لم يتوقف سير التّطوّر عند محوّل الرّؤية هذا فحسب، بل تبعه في ذات العام (2020) إصدار محوّل الرّؤية النّقيّ المعروف بــ (ViT=Vision Transformer) الذّي يعطي تصنيفًا كلّيًّا للصّورة من خلال معالجتها كسلاسل من الدّفعات (sequences of image patches) ممّا جعله يحقّق أداءً متطوّرًا (state-of-the-art performance) في الكثير من مهامّ التّعرّف على الصّور (image recognition) وغيرها من مثل: مهام الكشف عن الأغراض (object detection)، التّجزئة الدّلاليّة (semantic segmentation)، ومعالجة الصّورة (image processing) [1].
في نهاية عام (2020)، ظهرت عدّة تطبيقاتٍ لنموذج المحوّل من مثل: محوّل معالجة الصّورة (Image Processing Transformer=IPT)، الذّي دُرّب على مجموعة البيانات إمج-نت (ImageNet) وحقّق أداءً متطوّرًا في العديد من مهام الرّؤية منخفضة المستوى (low level vision)، بما فيها الدّقة الفائقة (super-resolution)، إزالة التّشويش (denoising) والتّفريغ (draining) [1]. تلاه بعد ذلك نموذج سيتر (SETR) وهو شبكة تجزئةٍ دلاليّةٍ (semantic segmentation) قائمةٌ على المحوّلات وتستخدم مُشفّرًا مشابهًا لمحوّل الرّؤية (ViT) من أجل استخراج الميّزات من صورة الدّخل. وأمّا آخر تطوّرٍ شهده ذات العام كان من نصيب نموذج التّدريب المسبق المقارن بين الصّورة واللّغة (كليب) (Contrastive Language -Image pre_processing=CLIP)، دُرّب على مجموعة بياناتٍ تحتوي على (400) مليونٍ من زوج (نص، صورة) ويأخذ اللّغة الطّبيعيّة كإشرافٍ من أجل أن يتعلّم تمثيلًا أكثر كفاءةً للصّورة [1].
تمّ اقتراح مجموعةٍ متنوّعةٍ من البدائل والأشكال المختلفة من محوّل الرّؤية (ViT variants) عام (2021); من أجل تحسين الأداء في مهام الرّؤية مثل تعزيز الموقع (enhancing locality)، تحسين الاهتمام الذّاتيّ (self-attention improvement) والتّصميم المعماريّ (architecture design). من ضمن هذه البدائل كان محوّل الصّورة الفعّال للبيانات (Data Efficient Image Transformer=DeiT) دُرّب فقط على مجموعة بيانات إمج-نت (ImageNet). تلاه أيضًا محوّل بفت (PVT)، ثمّ نموذج محوّل داخل محوّل (Transformer In Transformer=TNT) الّذي يستخدم كتلة محوّلٍ داخليّةٍ من أجل نمذجة العلاقة بين الدّفعات الجزئيّة (sub patches)، وكتلة محوّلٍ خارجيّةٍ لتبادل المعلومات على مستوى الدّفعة. وآخرها كان محوّل سوين (Swin) الذّي قمنا باستخدامه كمشفّرٍ مرئيٍّ (visual encoder) في مقالٍ سابقٍ لنا بعنوان “محوّل فهم المستندات المرئيّة دونات (Donut)” والمدرج في المرجع [3].
في عام (2022)، تمّ العمل على دفع مجال توليد الصّورة (image generation) قِدمًا إلى الأمام من خلال تقديم صيحةٍ جديدةٍ وهي نماذج الانتشار (Diffusion Models) مثل نموذج الانتشار المستقر (StableDiffusion model) ونموذج دالي2 (DALLE2) الّذي يعدّ محوّلًا لتحويل النّصّ إلى صورةٍ أي توليد صورٍ ذات جودةٍ عاليةٍ من أوصاف اللّغة الطّبيعيّة (natural language descriptions) كمثل شرحٍ أو تعليقٍ للصّورة (image caption) [1].
وبدلًا من الاعتماد على نموذج ذكاءٍ اصطناعيٍّ واحدٍ، تمّ العمل في عام (2023) على تشكيل نظام (AI) أكثرَ تكاملًا وتماسكًا من خلال خلق تعاونٍ بين عدّة نماذجَ قادرةٍ على دمج أنواعٍ مختلفةٍ من البيانات ومعالجتها وفهمها; لتوليد مخرجاتٍ وقراراتٍ أكثر دقة. وهذا ما يُعرف بالنّموذج متعدّد الوسائط والمهام (multi-modal model) مثل نموذج جبت-4 (GPT-4) المستخدم لكلا المهام المتعلّقة باللّغة والرّؤية (language and vision tasks) [1].
وبالطّبع، لن يتوقف تطوّر المحوّلات عند هذا الحدّ فحسب، بل سيكون هنالك الكثير من النّماذج والأعمال التّحسينيّة الأخرى في المستقبل. وسنكون لها خير مُرتقبٍ!.
ما هو محوّل الرّؤية (Vision Transformer).
محوّل الرّؤية النّقيّ (Vision Transformer) هو شبكةٌ عصبونيّةٌ رائدةٌ في معالجة وفهم الصّور، ويعمل على إضفاء طابعٍ تحليليٍّ جديدٍ لها من خلال تقسيمها إلى سلسلةٍ من عدّة دفعاتٍ صغيرةٍ (image patches) يتمّ فيها الاستفادة من استخدام تقنيّة الاهتمام الذّاتيّ (self-attention); من أجل التقاط العلاقات المحلّية (local relationships) والشّاملة (global relationships) بداخلها معطيةً بالمجمل أداءً فائقًا في العديد من مهام الرّؤية الحاسوبيّة (CV) [4].
تمّ عرض العمل الخاصّ بمحوّل الرّؤية هذا للمرّة الأولى من خلال الورقة البحثيّة المُشار إليها بالمرجع [5]، والّتي قُدّمت في مؤتمر تعلّم الآلة الدّوليّ (ICLR) عام (2021) تحت عنوان: (An image is worth 16*16 Words: Transformers for Image Recognition at Scale). حيث تمّت الإشارة إلى مدى فاعليّة وكفاءة استخدامه تبعًا للنّتائج الممتازة الّتي حقّقها مقارنةً مع شبكات (CNN)، بالإضافة إلى متطلّباته القليلة (أقل بــ 4 مرّاتٍ) من الموارد الحسابيّة (computational resources) لعمليّة التّدريب (training) [5].
التّعريف ببنية النّموذج.
كما أسلفنا سابقًا بشأن نموذج محوّل الرّؤية (ViT) في تحليله لصورة الدّخل، حيث ينظر إليها بذات عين المعالجة للبيانات النّصّيّة ضمن المحوّلات في إطار مهام اللّغات الطّبيعيّة; أي أنّ دفعات الصّورة المعبّرة عن كامل المشهد تُعتبر كمثل سلسلةٍ من الوحدات اللّفظيّة (tokens sequences) تمامًا كالكلمات.
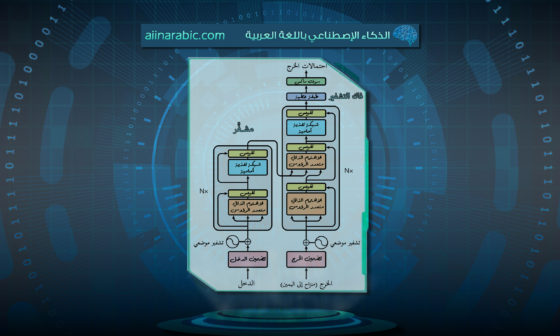
وأمّا فيما يخصّ كتلة التّشفير (encoder block)، فهي نسخةٌ مطابقةٌ ومماثلةٌ لبنية المحوّل الأصليّ المُقترح من قبل فاسواني وآخرون (Vaswani et al) والمُدرج في المرجع [6] من العمل البحثيّ الشّهير عام (2017) بعنوان: (Attention Is All You Need) [7]. يوجد العديد من الكتل في مشفّر (ViT)، وكلّ واحدةٍ منها تتألّف من ثلاثة عناصر أساسيّةٍ للمعالجة، هي:
- تسوية الطّبقة (Layer Norm).
- شبكة الاهتمام متعدّد الرّؤوس (Multi- head Attention Network=MSP).
- شبكة بيرسيبترون متعدّدة الطّبقات (Multi-Layer Perceptrons=MLP).
في هذه البنية، تمّ اللّجوء لتسوية الطّبقة (layer Norm) من أجل تتبّع مسار وسير عمليّة التّدريب وجعل النّموذج قادرًا على التّكيّف مع الاختلافات بين صور التّدريب (training images). في حين أنّ شبكة الاهتمام متعدّد الرّؤوس (MSP)، كانت المسؤولة عن توليد خرائط الانتباه (attention maps) من الوحدات اللّفظيّة المرئيّة المضمّنة المعطاة (embedded visuals tokens)، بالإضافة إلى كونها يدَ إرشادٍ مساعدٍ للشّبكة للتّركيز على المناطق الأكثر أهميّة داخل إطار الصّورة مثل الكائنات والأشياء الأخرى. وأمّا بالنّسبة لشبكة بيرسيبترون متعدّدة الطّبقات (MLP)_عنصر المعالجة الأخير_ فهي عبارةٌ عن شبكة تصنيفٍ بطبقتين مع تابع التّفعيل جيلو (Gaussian Error Linear Unit=GELU) في النّهاية، حيث أنّ الكتلة الأخيرة من الشّبكة _عادةً تسمّى رأس الشّبكة MLP head_ تُستخدم كمثل خرجٍ للمحوّل لحين تطبيق سوفت ماكس (softmax) على هذا الخرج وتشكيل عناوين التّصنيف (classification labels) في حال كان التّطبيق لتصنيف الصّور [7]. وكلّ هذه المكوّنات المعبّرة عن كتلة مشفّر المحوّل يمكن إيضاحها من خلال الشّكل (2) التّالي:

ماهي آليّة عمل النّموذج.
سنتطرّق أعزّاءنا القرّاء بدايةً لعرضٍ-الشّكل (3)-يعكس المسار الكلّيّ والخطوات العديدة المتّبعة في عمل محوّل الرّؤية (ViT) هذا، لنعرج سويّةً فيما بعد إلى شرحٍ تفصيليٍّ عنها الواحدة تلوَ الأخرى:

لدينا خطوات العمل كالتّالي:
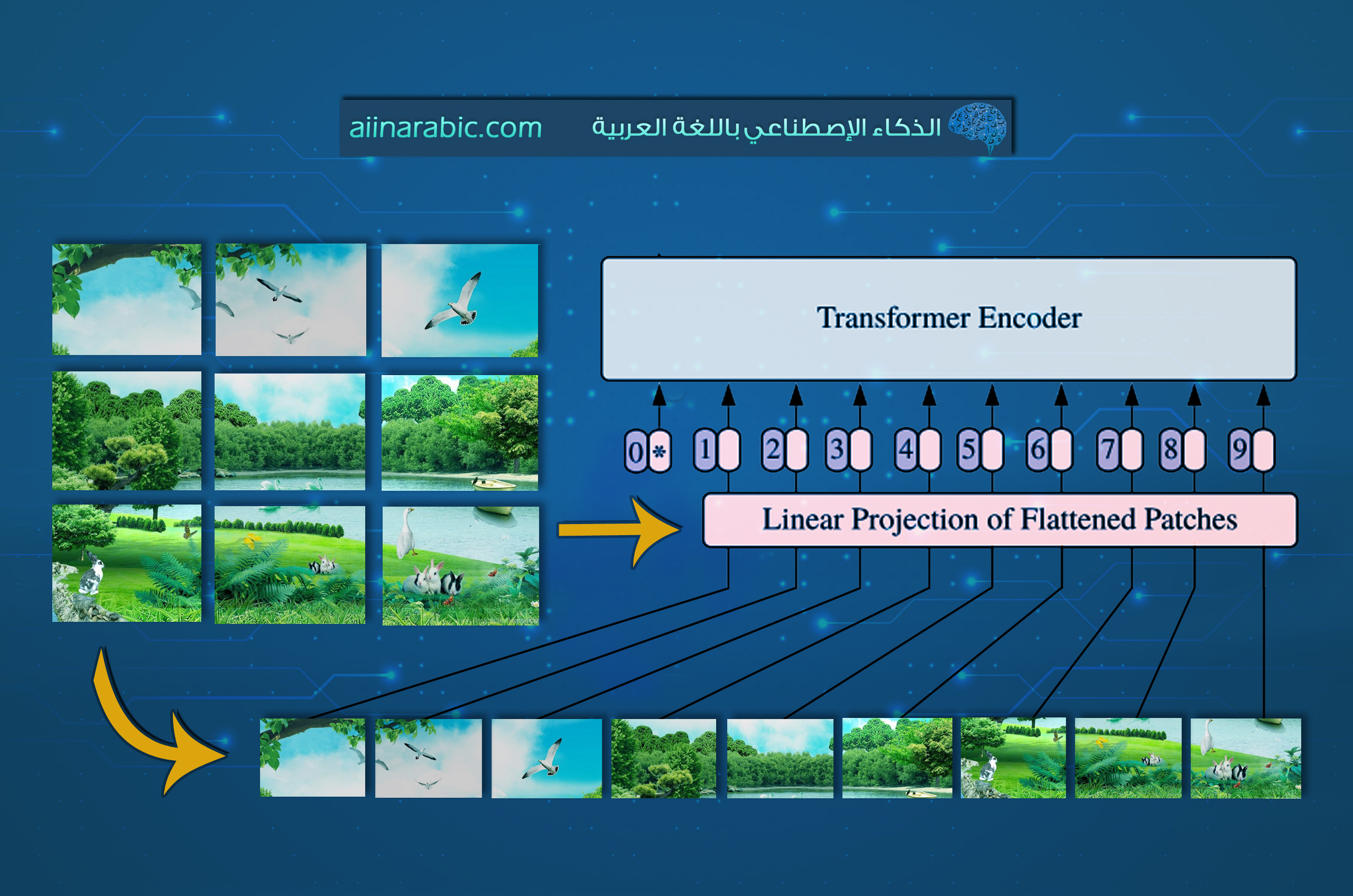
- تضمين الدّفعة (Patch Embedding): يتمّ تقسيم صورة الدّخل إلى دفعاتٍ مربّعةٍ ذات حجمٍ ثابتٍ (من خلال تقسيم الدّقة الإجماليّة للصّورة على الدّقة الإجماليّة لكلّ دفعةٍ منها أي N =HW/P2)، كلّ واحدةٍ منها تُحوَّل خطيًّا بشكلٍ منفصلٍ إلى متجهٍ (vector) وذلك باستخدام إسقاطٍ خطّيٍّ قابلٍ للتّعلّم (learnable linear projection) [4]. أي أنّ هذه الدّفعات تُسقط خطّيًّا لفضاءٍ منخفض الأبعاد (lower-dimensional space) [5]. تتشكل لدينا في النّهاية سلسلة من تضمينات الدّفعة (patch embeddings) والّتي تُقدّم كوحداتٍ لفظيّةٍ للدّخل للطّبقات اللّاحقة. والشّكل (4) التّالي يُظهر بعض مرشحات التّضمين:

- التّضمين الموضعيّ (Positional Embedding): لافتقار محوّل الرّؤية إلى أيّ فهمٍ واستيعابٍ للعلاقات المكانيّة (spatial relationships); من الضّروريّ أن يتمّ التّصريح والإفصاح عن المعلومات الموضعيّة (positional information) بشكلٍ دقيقٍ وواضحٍ، وهذا من خلال تعلّم وإضافة التّشفيرات الموضعيّة (positional encoding) إلى تمثيلات الدّفعة (patch representations) عادةً في مرحلة الإدخال. وبالطّبع تعطي هذه التّضمينات النّموذجَ القدرة على التّمييز بين المواضعِ المختلفة في الصّورة المُعالجة وبالتّالي التقاط العلاقات المكانيّة بين كائناتها [4]. يوضّح لنا الشّكل (5) كيف يتعلّم النّموذج تشفير المسافة داخل الصّورة من خلال تشابه تضمينات الموضع، حيث أنّ الدّفعات الأقرب لبعضها البعض (إضافةً لتلك الموجودة في ذات السّطر أو العمود) تميل إلى امتلاك تضمينات موضعٍ أكثر تشابهًا [5].

- طبقات التّشفير (Encoder Layers): تذكيرًا لما طُرح سابقًا، يتألّف محوّل الرّؤية (ViT) من عدّة طبقات تشفيرٍ، وكلٌّ منها مكوّنٌ من طبقتين فرعيّتين أساسيّتين هما: الاهتمام الذّاتيّ متعدّد الرّؤوس (multi-head self-attention) والشّبكات العصبونيّة ذات التّغذية الأماميّة (feedforward neural networks) [4].
- الاهتمام الذّاتي متعدّد الرّؤوس (Multi-Head Self-Attention):
- تساعد آليّة الاهتمام الذّاتيّ (self-attention mechanism) النّموذج بالتقاط العلاقات بين الدّفعات المختلفة من سلسلة الإدخال [4].
- تقوم تقنيّة الاهتمام الذّاتيّ بحساب المجموع الموزون (weighted sum) وهذا يتمّ من أجل كلّ تضمينٍ من تضمينات الدّفعة الممثّلة لصورة الدّخل، حيث تُحدّد الأوزان تبعًا لمدى صلة كلّ دفعةٍ بالدّفعة الحاليّة المدروسة [4].
- وبالمجمل تسمح هذه التّقنيّة للنّموذج بتوجيه انتباهه وصبّ جلّ تركيزه على الدّفعات الأكثر أهميّة في الصّورة مع أخذ السّياقات المحلّية والشّاملة بالحسبان [4]. كما هو مشارٌ إليه في الشّكل (6).
- التقاط الأنواع المختلفة من العلاقات يُعتبر من الميّزات الفعّالة لهذه التّقنيّة ويقع على عاتقها; من خلال استخدام مجموعاتٍ متنوّعةٍ من المعاملات القابلة للتّعلّم (رؤوس الاهتمام) (attention heads)، وهذا ما يُعرف بالاهتمام الذّاتيّ متعدّد الرّؤوس (multi-head self-attention) [4].

- الشّبكات العصبونيّة ذات التّغذية الأماميّة (Feeforward Neural Networks):
- بعد الحصول على المخرجات من تقنيّة الاهتمام الذّاتيّ لكلّ دفعةٍ من دفعات الصّورة، يتمّ تمريرها باتجاه عنصر المعالجة الآخر وهو الشّبكة العصبونيّة ذات التّغذية الأماميّة (feedforward neural networks). تتكوّن هذه الشّبكة عادةً من الطّبقة ذات الاتّصال الكامل (fully connected layer) يليها تابع التّفعيل المعروف باسم (ReLU) وهو وحدة التّصحيح الخطيّ (Rectified Linear Unit) [4].
- الغرض الأساسيّ من هذه الشّبكة هو السّماح للنّموذج بتعلّم العلاقات المعقدة بين الدّفعات وتقديم اللّاخطيّة (non-linearity).
- تسوية الطّبقة والوصلات المختصرة (Layer Normalization and Residual Connections):
- تقصّيًا لبنية مشفّر محوّل الرّؤية (ViT)، نلاحظ أنّ مخرجات آليّة الاهتمام الذّاتيّ وشبكة التّغذية الأماميّة يتلوهما تسوية الطّبقة (layer normalization) والوصلات المختصرة (residual connections).
- مهمّة تسوية الطّبقة تلخّص كجانبٍ مهمٍّ هو: المساعدة باستقرار وتسريع التّدريب من خلال تسوية المدخلات لكلّ طبقةٍ فرعيّةٍ [4].
- في حين تقوم الوصلات المختصرة والمعروفة باسم “وصلات التّخطّي” (skip connections) بإضافة تضمينات الإدخال الأصليّة إلى مخرجات كلّ طبقةٍ فرعيّةٍ; وهذا من شأنه أن يساعد في إنتاج المشتقات (gradients) أثناء مرحلة التّدريب بالإضافة إلى كونها مانعةً لمشكلة تلاشي المشتقّ (vanishing gradient problem) [4].
استخدامات النّموذج في مجال الرّؤية الحاسوبيّة (computer vision).
لقد اكتسب محوّل الرّؤية (ViT) أهميّةً ومكانةً بارزةً في الاهتمامات البحثيّة بسبب قابليّته للتّطبيق على نطاقٍ واسعٍ, ويشمل هذا مايلي:
- تصنيف الصّورة (Image Classification): يعدّ من إحدى مشاكل الرّؤية الأكثر شيوعًا والّتي كانت تُعتبر فيها شبكات (CNN) في بادئ الأمر الحلّ الأمثليَّ وأحدث ما توصّلت إليه البحوث لحلّها. وبمجرّد انقشاع الضّوء عن (ViTs)، أصبحت هذه الأخيرة الخيارَ البديل عنها حيث تفوّقت على شبكات (CNN) في مجموعات البيانات الكبيرة جدًّا (large datasets)، ولكنّها لم تُنتج أداءً قابلًا للمقارنة معها في مجموعات البيانات الصّغيرة والمتوسطة (small and medium datasets) [7].
- توليد وصفٍ للصّورة (Image Captioning): أصبح بالإمكان تحقيق شكلٍ أكثرَ تقدّمًا لتصنيف الصّور من خلال توليد تعليقٍ توضيحيٍّ يصف محتوى الصّورة بدلًا من مجرّد كلمةٍ واحدةٍ (label); وذلك بالاستعانة بــ (ViT) [7].
وبتدريب (ViT) على مجموعة البيانات كوكو (COCO dataset)، تمّ الحصول على عيّنةٍ من النّتائج توضّح التّعليقات التّوضيحيّة الوصفيّة عليها كما في الشّكل (7) الآتي:

- تجزئة الصّورة (Image Segmentation): تُعتبر محوّلات التّنبؤ الكثيف (Dense Prediction Transformers=DPT) كنموذج تجزئةٍ (segmentation model) تمّ إطلاقه من قبل شركة إنتل (Intel) في شهر مارس (March) من عام (2021)، والّذي يطبّق محوّلات الرّؤية على الصّور [7].
يستطيع هذا النّموذج إجراءَ تجزئةٍ دلاليّةٍ للصّورة بنسبة (%49.02) وفق المقياس الذّهبيّ: متوسط التّقاطع على الاتّحاد (Mean Intersection Over Union=mIOU) لمجموعة البيانات (ADE20k)، كما أنّه يُستخدم لتقدير العمق الأحاديّ (monocular depth estimation) مع تحسين الأداء النّسبيّ لحوالي (%28) مقارنةً بالشّبكة ذات الطّيّ الكامل (fully–convolutional network) [7]. تُظهرالصّور في الشّكل (8) التّالي نتائج التّجزئة باستخدام (ViT):

- كشف الحالات الشّاذة (Anomaly Detection): إنّ استخدام شبكات المحوّلات هنا في هذه المهمّة من شأنه أن يساعد في الحفاظ على المعلومات المكانيّة (spatial information) للدّفعات المضمّنة، والّتي لاحقًا تتمّ معالجتها بواسطة شبكة كثافة الخليط الغوسي (Gaussian Mixture Density network); لتحديد وتكوين مربّعات إحاطةٍ (bounding boxes) حول المناطق الشّاذة (anomalous areas) [7]. وهذا ما يظهره الشّكل (9) التّالي:

وإغناءً لتلك التّطبيقات آنفة الذّكر، نذكر أخرى منها من مثل: توليد الصّورة (Image Generation)، كشف التّزييف العميق للفيديو (Video DeepFake Detection)، التّعرّف على النّشاط (Action Recognition)، القيادة الذّاتيّة (Autonomous Driving) وتطول القائمة…
مقارنة النّموذج مع شبكات الطّيّ العصبونيّة (CNNs).
سنتطرّق في هذه الفقرة، لذكر أهمّ أفكار المقارنة بين شبكات (CNNs) ومحوّلات (ViTs) والّتي تمّت تغطيتها من خلال الورقة البحثيّة الّتي تحمل عنوان “هل ترى محوّلات الرّؤية مثل شبكات الطّيّ العصبونيّة؟” (?Do Vision Transformers See Like Convolutional Neural Networks)، حيث تمّ نشرها من عام (2021) من قبل (Google Research) وفريق (Google Brain):
- يتمتّع محوّل الرّؤية (ViT) بتشابهٍ أكثر بين التّمثيلات (representations) الّتي تمّ الحصول عليها من الطّبقات السّطحيّة (shallow) والعميقة (deep) مقارنةً بشبكات (CNN) [7].
- إنّ (ViT) لديه نشرٌ قويٌّ أكبر بكثيرٍبالنّسبة للتّمثيلات بين الطّبقات السّفليّة والعليا [11].
- على عكس شبكات (CNNs)، يحصل (ViT) على تمثيلٍ شاملٍ (global representation) من الطّبقات السّطحيّة، كما أنّ التّمثيل المحليّ الّذي يتمّ الحصول عليه من الطّبقات السّطحيّة مهمٌّ أيضًا [7].
- إنّ (ViT) يتعلّم تمثيلاتٍ مختلفةٍ عن ريس-نت (ResNet) في الطّبقات السّفليّة; بسبب الوصول إلى كمّياتٍ كبيرةٍ من المعلومات الشّاملة وهذا ما يؤدي إلى ميّزاتٍ مختلفةٍ كمّيًا [11].
- إنّ وصلات التّخطّي (skip connections) في (ViT) أكثر تأثيرًا من شبكات (CNNs) مثل شبكة ريس-نت (ResNet)، كما أنّ لها تأثيرًا كبيرًا على أداء التّمثيلات وتشابهها [7].
- إنّ (ViT) يحتفظ بمعلوماتٍ مكانيّةٍ (spatial informations) أكثر من شبكة ريس-نت (ResNet) [7].
- إنّ (ViT) يستطيع تعلّم تمثيلاتٍ متوسطةٍ عالية الجودة من كميّاتٍ كبيرةٍ من البيانات [7].
- تمتلك الطّبقات العليا لــ (ViT) تمثيلاتٍ مختلفةٍ عن ريس-نت (ResNet) [11].
- إنّ نموذج شبكة بيرسيبترون متعدّدة الطّبقات ذي مزيج الشّبكات (MLP-Mixer) أقرب إلى (ViT) من شبكة ريس-نت (ResNet) [7].
- إنّ ما يميّز (ViT) هو استخدامه لتقنيّة الاهتمام الذّاتيّ (self-attention) الّتي تتيح التّجميع المُبكر للمعلومات الشّاملة، كما وأنّ طبقات الاهتمام هذه الموجودة فيه لديها مزيجًا من الرّؤوس المحلّيّة (local heads) خاصّةٍ بالمسافات الصّغيرة (small distances) ورؤوسٍ شاملةٍ (global heads) خاصّةٍ بالمسافات الكبيرة (large distances)، بالإضافة إلى وجود وصلات التّخطّي (skip connections) فيه بعد كلّ طبقة اهتمامٍ ذاتيٍّ وكلّ طبقة (MLP)، والّتي تقوم بنشر الميّزات بقوّةٍ أكبر من الطّبقات السّفليّة إلى الطّبقات العليا حيث لُوحظ أنّ لها تأثيرًا قويًّا على الأداء أكثر من تلك الموجودة في ريس-نت (ResNet) [11].
- في غالب الوقت تتطلّب شبكات (CNNs) كمّياتٍ كبيرةٍ من البيانات المصنّفة (labeled data) للتّدريب، في حين يستطيع (ViT) الاستفادة من التّدريب المسبق على مجموعات البيانات الكبيرة ومن ثمّ الضّبط الدّقيق (fine-tuning) من أجل تحقيق مهامٍ محدّدةٍ [4].
- لدى شبكات (CNNs) أسلوب معالجةٍ مختلفٍ للصّورة عن (ViT)، حيث تقوم بمعالجة قيم البكسلات الأوّليّة مباشرةً، بينما يقوم الأخير بتقسيم صورة الدّخل إلى مجموعةٍ من الدّفعات المربعة ومن ثمّ تحويلها لوحداتٍ لفظيّةٍ مرئيّةٍ (visual tokens) [4].
- إنّ طبقات الطّيّ (convolutional layers) والتّجميع (pooling layers) في شبكات (CNNs) مسؤولةٌ عن التقاط الميّزات بشكلٍ هرميٍّ على نطاقاتٍ مكانيّةٍ مختلفةٍ، بينما يستخدم (ViT) آليّة الاهتمام الذّاتيّ من أجل النّظر في العلاقات بين مختلف دفعات الصّورة حتّى وإن كانت على مسافاتٍ متباعدةٍ من بعضها البعض [4].
- إنّ شبكات (CNNs) تميل إلى الانحياز الاستقرائيّ (inductive bias) وهو الافتراض الّذي يقوم به النّموذج عند إجراء التّنبؤات ممّا يحدّ من فشله في عمليّة التّعميم (generalization)، بينما في الجهة المناظرة نجد أنّ محوّل الرّؤية (ViT) لا يمتلك أي من هذه الانحيازات وما يجعله يعمل بشكلٍ جيّدٍ هو نهج أسلوب التّدريب الخاصّ به [12].
- تكون شبكات (CNNs) متسلسلةً في معالجة البيانات، بينما تعمل المحوّلات (transformers) بشكلٍ غير متسلسلٍ [12].
الخاتمة.
في نهاية المطاف، لا يسعنا أعزّاءنا القرّاء إلّا أن نصقلَ سيوف علمكم بما طاب من المعلومات وما بلغ تقدّمًا وتطوّرًا من أساليب معالجة وفهم الصّور مثل محوّل الرّؤية (ViT) في جعبتنا اليوم، الّذي كان خير محسّنٍ لمهام الرّؤية الحاسوبيّة (CV); من خلال نقاط قوّته البارزة بدءًا بإضفاء نهج معالجةٍ مستوحًى من عمل المحوّل الأصليّ في معالجة البيانات المتسلسلة (sequential data)، وصولًا لاستخدامه تقنيّة الاهتمام الذّاتيّ (self-attention)، وقدرته على الاحتفاظ بالمعلومات المكانيّة (spatial information)، والتقاطه السّياق المحلّيّ والشّامل بفضل مزيج رؤوس الاهتمام (attention heads) واعتماده لوصلات التّخطي (skip connections); الّتي كانت عنصرًا مساعدًا في منع مشكلة تلاشي المشتقّ (vanishing gradient problem).
وهكذا لن يكون (ViT) إلّا نقطة البداية لولادة بنًى هجينةٍ وتعاونٍ قويٍّ بينه وبين شبكات (CNNs) من أجل الحصول على نتائجَ ممتازةٍ وفائقةٍ واستثنائيّةٍ.
المراجع.
- A Survey on Vision Transformer.
- المُحوّل Transformer.
- محوّل فهم المستندات المرئيّة (Donut).
- Unveiling Vision Transformers: Revolutionizing Computer Vision Beyond Convolution.
- An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.
- Attention Is All You Need.
- Vision Transformer: What It Is & How It Works [2023 Guide].
- Transformers for Image Recognition at Scale – Google Research Blog.
- Vision Transformers for Dense Prediction.
- VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization.
- Do Vision Transformers See Like Convolutional Neural Networks?
- Introduction to Vision Transformers (ViT).