سنتعرَّف في هذا المقال على المُحوّل Transformer الذي يُعتبر نموذجًا يستخدم تقنيّة الاهتمام Attention – التي قمت بشرحها في المقال السابق [3]- لزيادة سرعة التّدريب. لقد تفوَّق المُحوّل في مهامّ محدّدة على نموذج التّرجمة الآليّة العصبونيّة المُقترَح من جوجل Google، ومن ناحية أخرى فإنّ أكبر فائدة لنماذج المُحوّلات هي القدرة على التّفرعيّة، ولذلك تُوصي خدمة جوجل السّحابيّة Google Cloud باستخدام المُحوّل كنموذج مرجعيّ، في حال استخدام وحدة المُعالجة تينسور TPU المُقدّمة من جوجل للتّدريب سحابيًّا. والآن دعونا نحاول تفكيك نموذج المُحوّل إلى أجزاء لمعرفة كيفيّة عمله.
تمّ اقتراح فكرة المُحوّل في الورقة البحثيّة [1]، كما أنَّ تطبيق مكتبة تنسور فلو للتّعلُّم العميق TensorFlow للمُحوّل مُتاح كجزء من حزمة تنسور إلى تنسور Tensor2Tensor. قامت أيضًا مجموعة معالجة اللّغات الطّبيعيّة NLP في جامعة هارفرد بإنشاء دليل [4] يشرح الورقة البحثيّة السّابق ذكرها باستخدام مكتبة بايتورش PyTorch. سنحاول في هذا المقال شرح المفاهيم الأساسيّة الواحد تلوَ الآخر بشكل مُبسّط، على أمل تسهيل فهم المُحوّل للقارئ دون الحاجة لامتلاكه معرفة عميقة مُسبقة عن هذا الموضوع.
التدقيق العلمي: د. دانيا صغير، م. هديل عبد الرحمن
التدقيق اللغوي: هبة الله فلّاحة
المَحتويَات
نظرة عامّة على المُحوّل Transformer
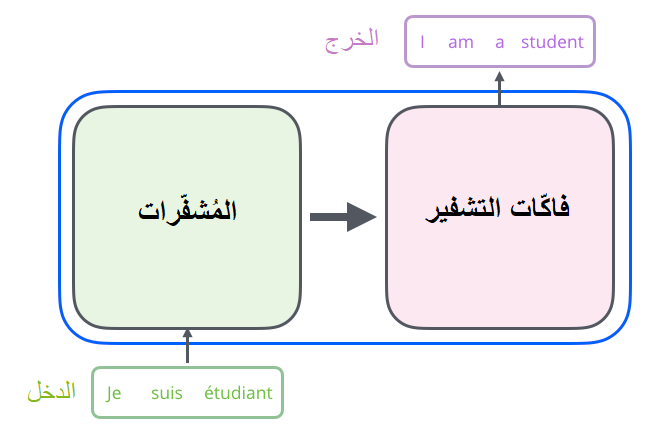
لنبدأ أوّلًا بالنّظر إلى النّموذج على أنّه صندوق أسود، يقبل هذا الصّندوق -في تطبيق التّرجمة الآليّة على سبيل المثال- دخلًا واحدًا وهو جملة مكتوبة بإحدى اللّغات، و له خرج واحد أيضًا هو ترجمة هذه الجملة إلى لغة أخرى كما هو واضح في الشّكل (1).

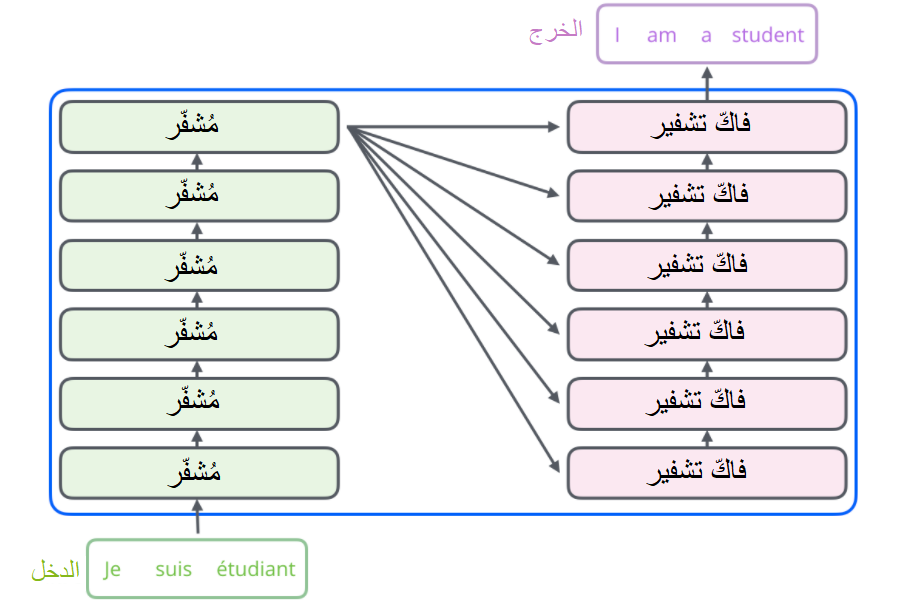
والآن في حال قمنا بفتح هذا الصّندوق، فإننا سنرى كُلًّا من المُشفّر وفاكّ الشّيفرة و الاتّصال بينهما كما هو واضح في الشّكل (2).
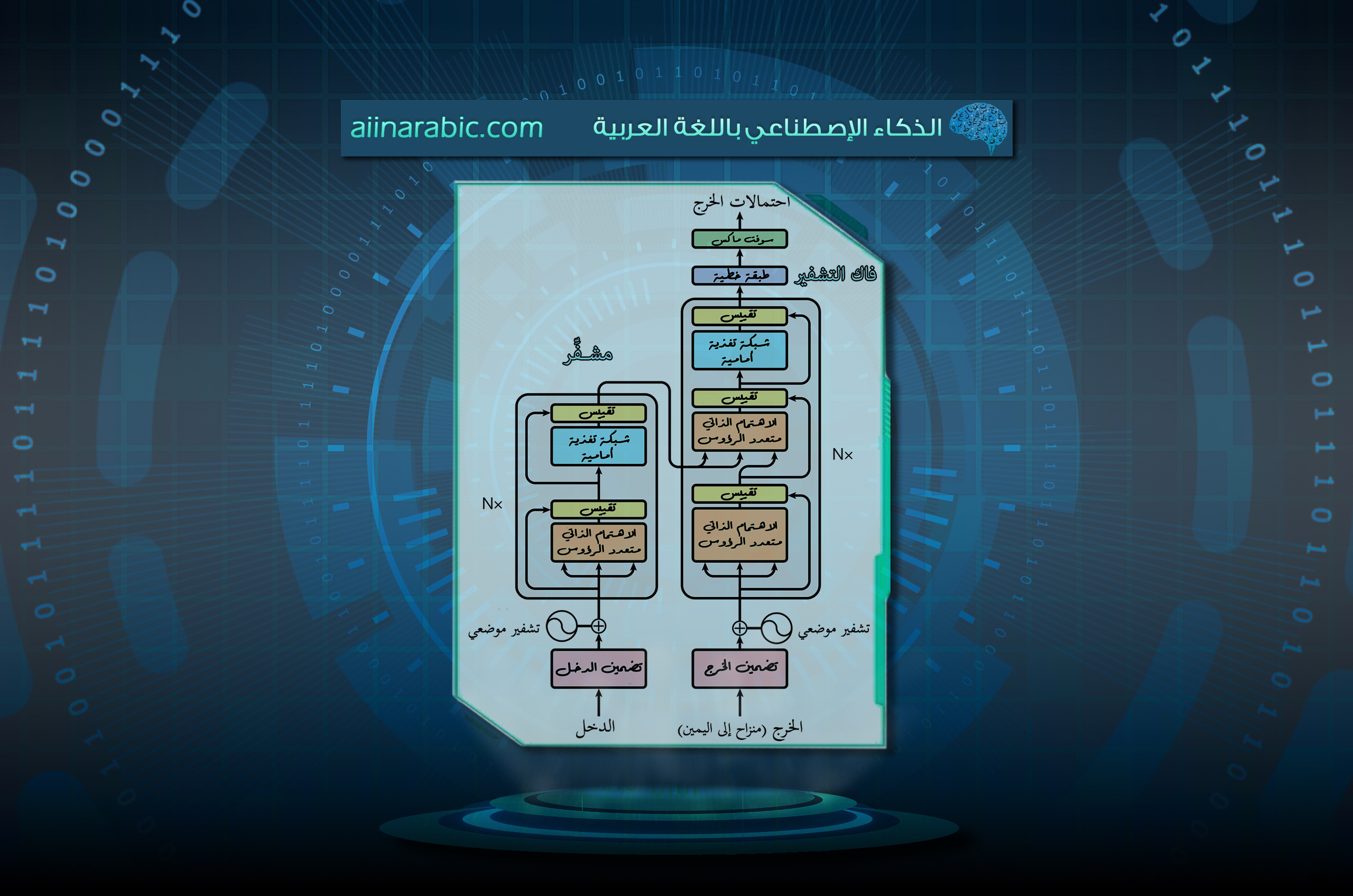
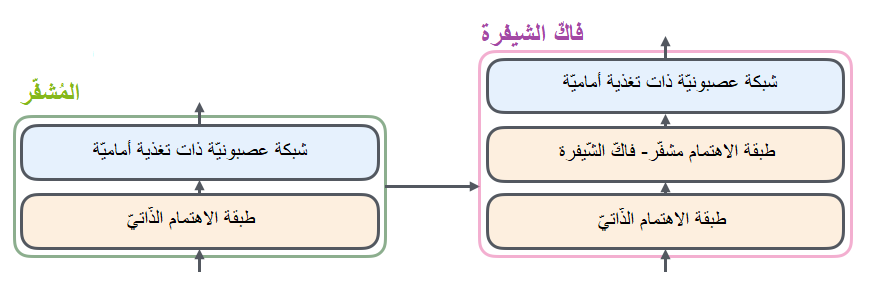
يتألف مُكوّن المُشفّر في الحقيقة من مجموعة من المُشفّرات المُكدّسة (في الورقة البحثيّة المذكورة أعلاه، تمّ تكديس ستة مُـشفّرات فوق بعضها البعض لا يوجد أيّ شيء مميز حول اختيار الرقم 6، يمكنك أن تقوم بتجربة أرقام أخرى إن أحببت). ينطبق نفس الأمر على مُكوّن فاكّ الشّيفرة، فهو عبارة عن مجموعة من نفس العدد من فاكّات الشّيفرة المُكدّسة. يبيّن الشّكل (3) بنية مُكوّني المُشفّر وفاكّ الشّيفرة المُوضّحين في الشّكل (2).
على الرّغم من أنّ جميع المُشفّرات تمتلك نفس البنية إلا أنّها لا تتشارك نفس الأوزان، ينقسم كلّ مُشفّر منها إلى طبقتين جُزئيَّتين كما هو واضح في الشّكل (4).
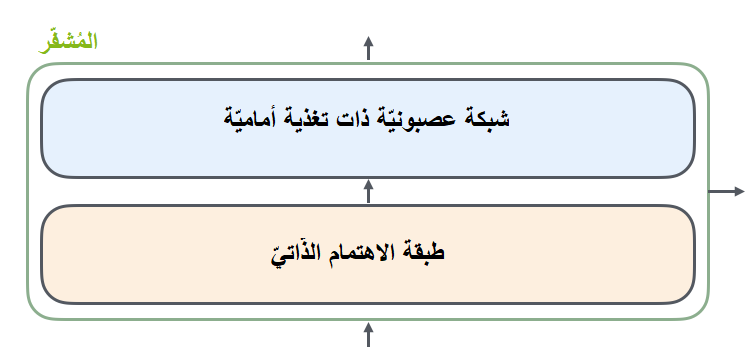
يتدفَّق أوّلًا دخل المشفّر عبر طبقة الاهتمام الذّاتيّ Self-Attention؛ وهي طبقة تساعد المُشفّر على النّظر إلى كلمات أخرى في جملة الدّخل أثناء تشفيره لكلمة محدّدة. (سنتكلّم لاحقًا على طبقة الاهتمام الذّاتيّ في هذا المقال). بعد ذلك، يتمُّ تمرير خرج طبقة الاهتمام الذّاتيّ إلى شبكة عصبونيّة ذات تغذية أماميّة Feed Forward، حيث يتمّ تطبيق نفس الشّبكة ذات التّغذية الأماميّة بشكل مستقلّ في كلّ موقع.
يحتوي فاكّ الشّيفرة على كِلا الطبقتيّن السّابقتين، ولكن تفصل بينهما طبقة اهتمام تساعد فاكّ الشّيفرة على التّركيز على الأجزاء من جملة الدّخل ذات الصّلة (عمل هذه الطّبقة مشابه لما قمت بشرحه في مقال الاهتمام في نماذج السلسلة للسلسلة seq2seq). يبيّن الشّكل (5) البنية الداخليّة لكلٍّ من المُشفّر وفاكّ الشّيفرة.
بعد أن تكلّمنا عن المكوّنات الرّئيسيّة لنموذج المُحوّل، دعونا نلقي نظرة على المُتَّجهات/ المصفوفات متعدّدة الأبعاد Tensors لنرى كيف تتدفَّق البيانات عبرها وعبر المُكوّنات سابقة الذّكر من أجل تحويل دخل النّموذج المُدرَّب إلى خرج.
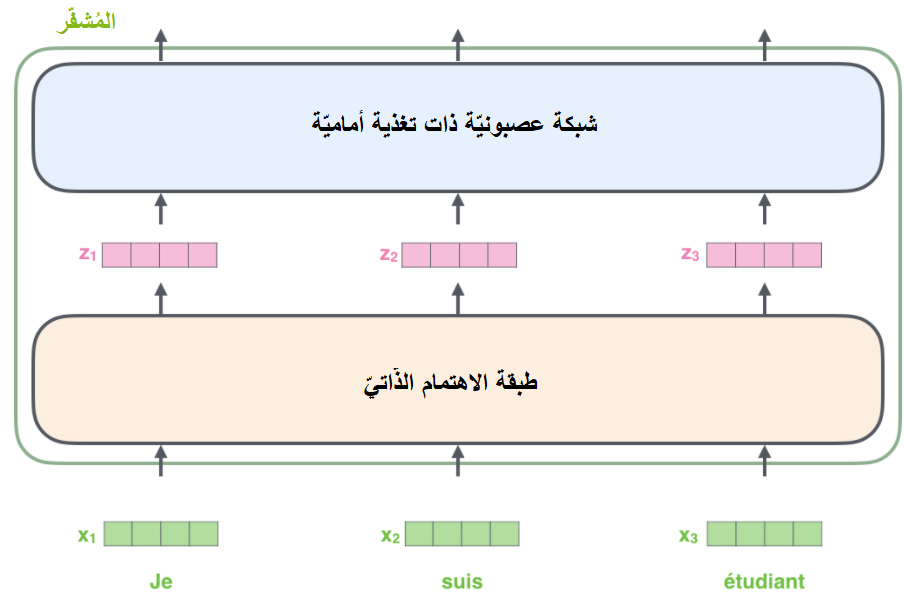
نبدأ أوّلًا بتحويل كلّ كلمة دخل إلى مُتّجه باستخدام خوارزميّة التّضمين Embedding Algorithm كما هو الحال بشكل عام في تطبيقات معالجة اللّغات الطّبيعيّة NLP. يُبيّن الشّكل (6) تضمين الكلمات على شكل مُتّجهات ذات حجم 512 مثلًا.

تحدث عمليّة التّضمين في المُشفّر السّفليّ فقط. تستقبل كلّ المُشفّرات (الموجودة في الشكل 3) قائمة من المُتّجهات حجم كلٍّ منها 512، حيث يكون دخل المُشفّر السّفليّ مُتّجهات التّضمين أمّا المُشفّرات الأخرى فدخلها هو خرج المُشفّر السّابق مباشرةً. يُعتبر حجم هذه القائمة مُعاملًا أساسيًّا hyperparameter يُمْكننا ضبطه لاحقًا. (يمكن أن يكون مثلًا طول أطول جملة في مجموعة بيانات التدرّيب).
بعد القيام بتضمين الكلمات في جملة الدّخل، تتدفّق عبر كلٍّ من طبقتي المُشفّر طبقة الاهتمام الذّاتيّ و الشّبكة العصبونيّة ذات التّغذية الأماميّة) كما هو واضح في الشّكل (7).
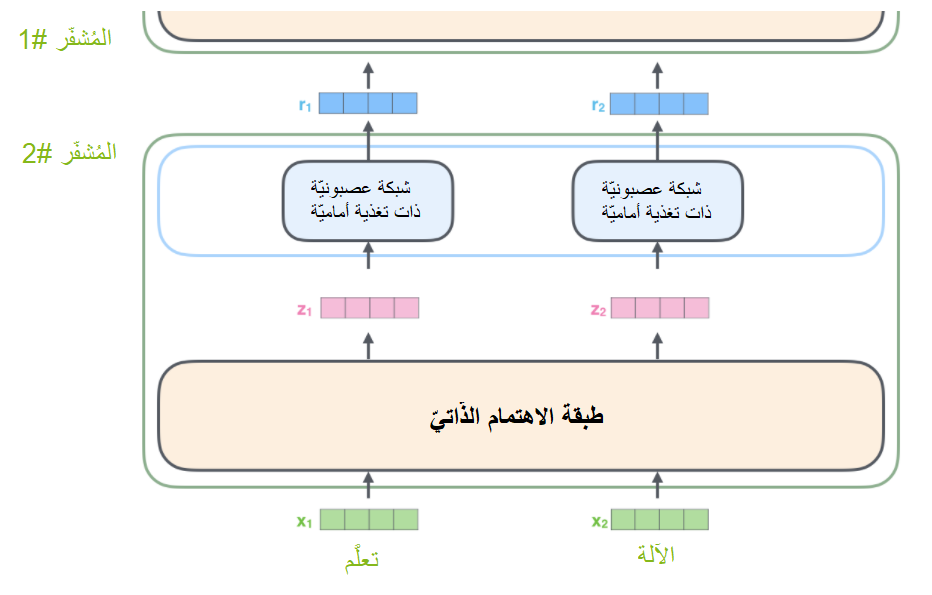
يُعتبر ما سبق أحد أهمّ ميّزات المُحوّل حيث تمرُّ الكلمة في كلّ موقع عبر مسار خاصّ في المُشفّر، يوجد هناك علاقات اعتماديّة بين تلك المسارات في طبقة الاهتمام، بينما لا تمتلك طبقة التّغذية الأماميّة هذه العلاقات، وبالتّالي يمكن تنفيذ عدّة مسارات على التّفرُّع في طبقة التّغذية الأماميّة.
سنقوم فيما يلي باستخدام جملة قصيرة كما هو واضح في الشّكل (8)، كمثال عمليّ من أجل أن نُلقي نظرة على ما يحدث في كلّ طبقة فرعيّة من طبقات المُشفّر.
بدايةُ التّشفير
كما أشرنا سابقًا، يستقبل المُشفّر قائمة من المُتّجهات كدخل له، ثمّ يقوم بمعالجة هذه القائمة عن طريق تمرير المُتّجهات إلى طبقة الاهتمام الذّاتيّ ثمّ إلى الشّبكة العصبونيّة ذات التّغذية الأماميّة، وأخيرًا يتمُّ إرسال الخرج إلى مُشفّر آخر.
الاهتمام الذّاتيّ Self-Attention
لنفترض أنّ الجملة التّالية هي جملة دخل نريد ترجمتها:
“The animal didn’t cross the street because it was too tired“
لنسأل أنفسنا، إلى ماذا تشير كلمة “it” في الجملة السّابقة؟ هل تُشير إلى الشّارع أم إلى الحيوان؟ في الحقيقة، يبدو هذا السّؤال بديهيًّا وبسيطًا بالنّسبة للإنسان، ولكنّه ليس كذلك بالنسبة للخوارزميّة. وهنا يأتي دور طبقة الاهتمام، فعندما يقوم النّموذج بمُعالجة كلمة “it”، فإنّ طبقة الاهتمام الذّاتيّ تسمح له بربطها مع الكلمة “animal”.
يسمح الاهتمام الذّاتيّ للنّموذج عندما يقوم بمعالجة كلّ كلمة (كلّ موقع في سلسلة الدّخل) بالنّظر إلى المواقع الأخرى في سلسلة الدّخل، للبحث عن أدلّة تساعده في الوصول إلى تشفير أفضل لجملة الدّخل.
عزيزي القارئ، إذا كانت الشبكات العصبونيّة الإرجاعيّة RNNs مألوفةً بالنّسبة لك، فتذكّر كيف أن الحفاظ على الحالة المخفيّة وتمريرها عبر وحدات الشّبكة العصبونيّة الإرجاعيّة، يسمحُ بدمج مُتَّجهات الكلمات السّابقة التي تمّت مُعالجتُها مع مُتّجه الكلمة الحاليّة الذي تتمّ مُعالجته الآن. و بشكل مُشابه، يستخدم المُحوّل الاهتمام الذّاتيّ كطريقة تُمكّنه من فهم الكلمات المُتعلّقة بالكلمة الحاليّة التي تتمّ مُعالجتها (أي تسمح له بفهم السّياق).
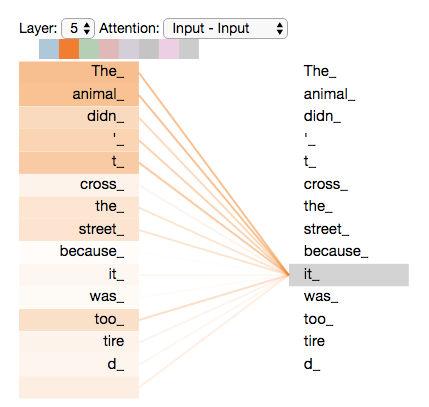
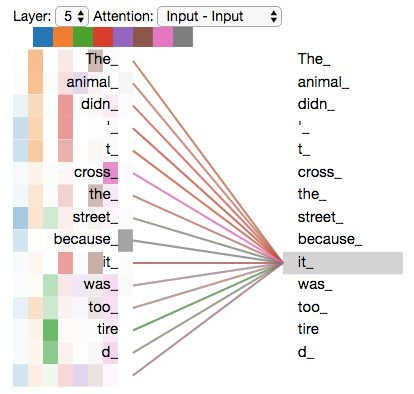
يُبيّن الشّكل (9) أنّه عند تشفير الكلمة “it” في المشفّر رقم 5، يقوم جزء من آليّة الاهتمام بالتّركيز على كلمة “Animal”، حيث يقوم بتضمين جزء من تمثيلها في تشفير الكلمة “it”. يدلُّ تدرّج اللّون على قوة العلاقة بين الكلمة الحاليّة و الكلمات الأخرى في جملة الدّخل.
والآن دعونا نتعمَّق أكثر في فهم آليّة الاهتمام الذّاتيّ
تفاصيل الاهتمام الذّاتيّ
يتمُّ حساب الاهتمام الذّاتيّ باستخدام المُتّجهات عن طريق تطبيق ست خطوات:
الخطوة الأولى هي إنشاء ثلاث مُتَّجهات من أجل كلّ مُتّجه من مُتّجهات دخل المُشفّر (يُقصد بمُتّجهات الدّخل تضمين الكلمات). فمن أجل كلّ كلمة من كلمات الدّخل نقوم بإنشاء ثلاثة مُتّجهات هي مُتّجه الاستعلام أو السّؤال Query vector، مُتّجه المفتاح Key vector و مُتّجه القيمة Value vector. يتمُّ إنشاء هذه المُتّجهات عن طريق ضرب مُتّجه التّضمين بثلاث مصفوفات قابلة للتّدريب (يتمُّ ضبط أوزانها أثناء عمليّة التّدريب) كما هو واضح في الشّكل (10). لاحظ مثلًا أنّه لإنشاء مُتّجه السّؤال q1، يتمُّ ضرب مُتّجه تضمين كلمة الدّخل x1 بمصفوفة الأوزان WQ.
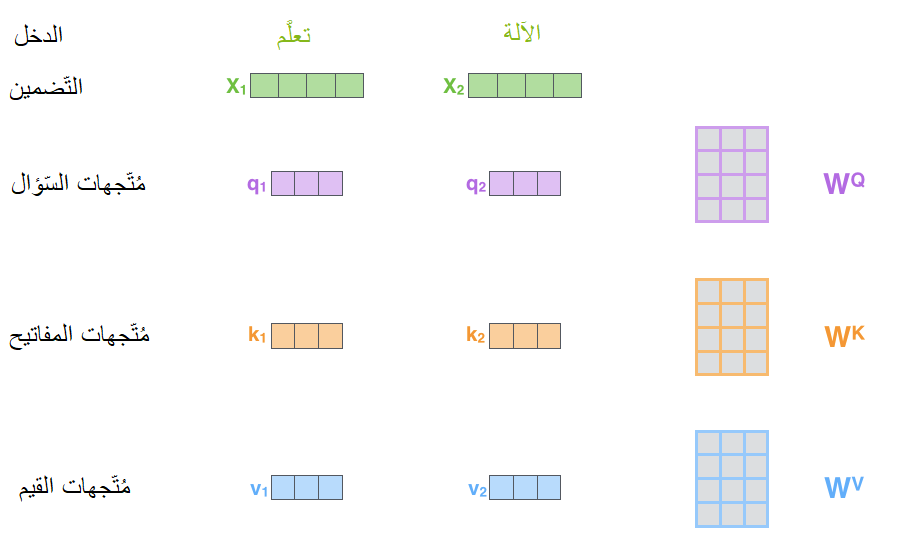
لاحظ أيضًا عزيزي القارئ أنّ أبعاد هذه المُتّجهات المُوَّلَّدة أصغر من أبعاد مُتّجه التّضّمين. إنَّ حجم هذه المُتّجهات هو قرار تصميميّ حيث يتمُّ ضبطه أثناء تصميم النّموذج، فليس ضروريًّا أن يكون حجمها أصغر ولكنّها تميل بالعادة لأن تمتلك أبعادًا أصغر لأسباب تتعلّق بكفاءة عمليّة حساب الاهتمام.
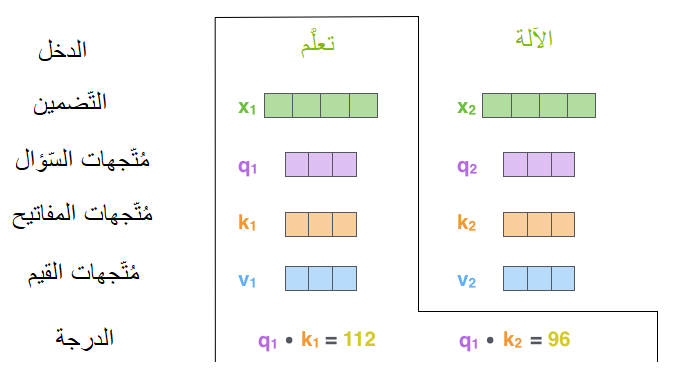
الخطوة الثّانية هي حساب الدّرجة/النّتيجة score بين كل كلمة وباقي كلمات الجملة. لنفرض أنّنا نقوم بحساب الاهتمام الذّاتيّ للكلمة الأولى وهي “تعلُّم” في المثال الذي نستخدمه، سيتمُّ في هذه الخطوة حساب درجة كلّ كلمة في جملة الدّخل مقابل الكلمة الحاليّة، تُحدّد هذه الدّرجة مقدار التّركيز الذي سيكون على الأجزاء الأخرى من جملة الدّخل أثناء عمليّة تشفير كلمة ما. يتمّ حساب الدّرجة عن طريق تطبيق الجداء النُّقَطيّ dot product بين مُتّجهي السّؤال والمفتاح للكلمة التي نقوم بحساب الدّرجة لها. فعلى سبيل المثال، في حال حساب الاهتمام الذّاتيّ للكلمة في الموقع #1 من جملة الدّخل كما هو واضح في الشّكل (11)، ستكون قيمة الدّرجة الأولى هي الجداء النُّقطيّ للمُتّجهين q1 و k1، وتكون قيمة الدّرجة الثّانية عبارة عن الجداء النُّقطيّ للمُتّجهين q1 و k2.
يتمُّ في الخطوتين الثّالثة والرّابعة تقسيم قيمة الدّرجة المحسوبة على 8 (الجذر التّربيعيّ لأبعاد مُتّجهات المفتاح -64- المُستخدمة في الورقة البحثيّة [1]، تُؤدّي هذه العمليّة إلى جعل المُشتقّات gradients أكثر ثباتًا. من الممكن استخدام قيم أخرى ولكن هذه القيمة هي الافتراضيّة). يتمُّ بعد ذلك تمرير النّتيجة إلى عمليّة سوفت ماكس softmax التي تقوم بتقييس الدّرجات، بحيث تكون جميعها قيمًا إيجابيّة ويكون مجموعها مُساوياً 1 كما هو واضح في الشّكل (12).
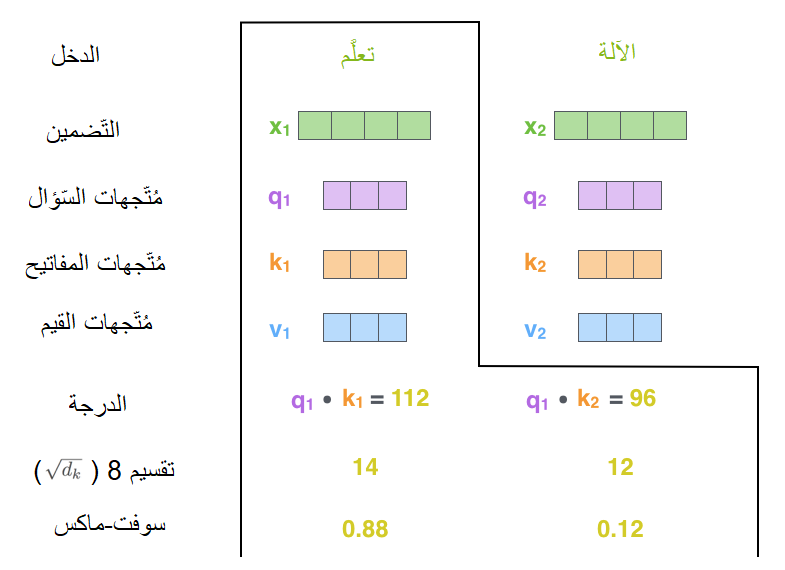
تُحدِّد قيمة الدّرجة بعد تطبيق عمليّة سوفت ماكس مدى تعبير أو مشاركة كلّ كلمة في هذا الموقع. من الواضح أنّ كلّ كلمة ستمتلك في موقعها أعلى درجة سوفت ماكس، ولكن من المفيد الاعتماد على كلمة أخرى متعلّقة بالكلمة الحاليّة.
يتمُّ في الخطوة الخامسة ضرب كلّ مُتّجه قيمة، بدرجة السّوفت ماكس (تحضيرًا لجمعهم معًا فيما بعد). إنّ السّبب وراء هذه العمليّة هو الحفاظ على قيَم الكلمة/الكلمات التي نريد التّركيز عليها، وإهمال الكلمات عديمة الصّلة (عن طريق ضربهم بأرقام صغيرة مثل 0.001).
في الخطوة السّادسة يتمُّ جمع مُتّجهات القيم المَوزُونِة، يَنتُج عن هذا خرج طبقة الاهتمام الذّاتيّ عند هذا الموقع (الكلمة الأولى). يبيّن الشّكل (13) الخطوتين 5&6.
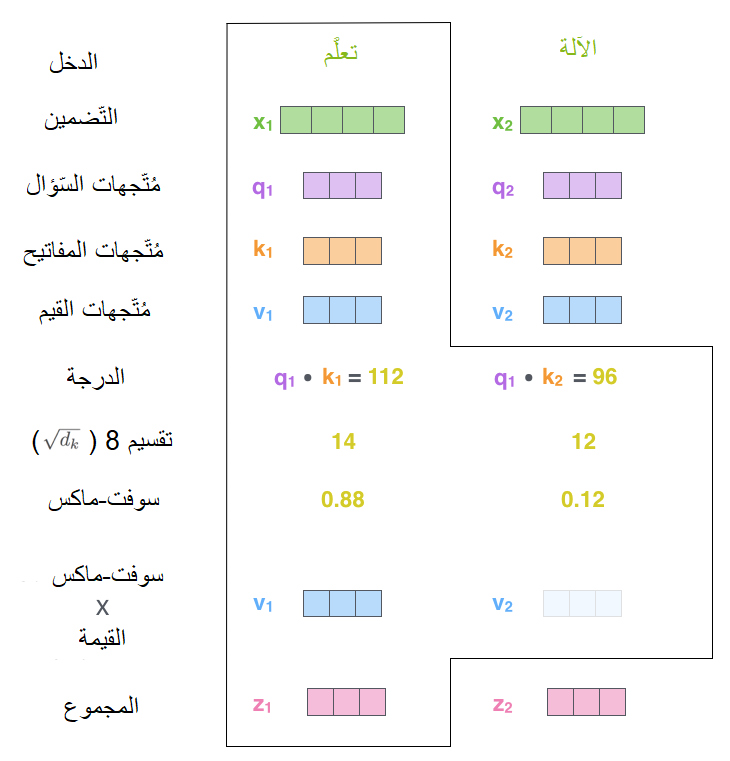
إنّ مُتّجهات الخرج النّاتجة هي قيم الاهتمام الذّاتيّ والتي سيتمُّ إرسالها إلى الشّبكات العصبونيّة ذات التّغذية الأماميّة.
عزيزي القارئ، يتمُّ في التّطبيق العمليّ لحساب الاهتمام استخدام المصفوفات من أجل الحصول على كفاءة تنفيذ وسرعة أعلى (شرح ذلك خارج إطار هذا المقال).
الاهتمام الذّاتيّ مُتعدّد الرّؤوس
تمّ في الورقة البحثيّة [1] تحسين طبقة الاهتمام الذّاتيّ عن طريق إضافة آليّة تُدعى الاهتمام مُتعدّد الرّؤوس multi-headed attention. أدّى ذلك إلى تحسين أداء طبقة الاهتمام على صعيدين:
- توسيع قدرة النّموذج على التّركيز على عدّة مواقع مختلفة.
- إعطاء طبقة الاهتمام عدّة فضاءات تمثيل فرعيّة. كما سنرى، باستخدام الاهتمام مُتعدّد الرّؤوس لن يكون لدينا مجموعة واحدة فقط من مصفوفات الوزن (السّؤال/المفتاح/القيمة Q/K/V) وإنما سيكون هناك مجموعات مُتعدّدة منها (واحدة لكلّ رأس).
يتمُّ عند استخدام الاهتمام مُتعدّد الرّؤوس الحفاظ على مصفوفات الوزن Q/K/V منفصلة لكلّ رأس كما هو واضح في الشّكل (14).
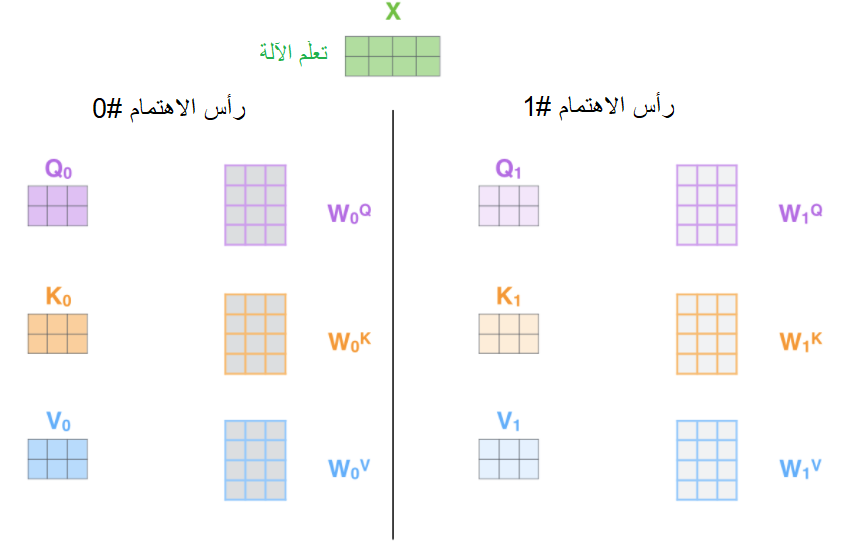
لو افترضنا أنّنا سنستخدم طبقة اهتمام ذاتيّ لها /8/ رؤوس (الرّقم الافتراضيّ في المُحوّلات)، وبالتالي سينتُج لدينا ثماني مصفوفات وزن Z مختلفة كما هو واضح في الشّكل (15).
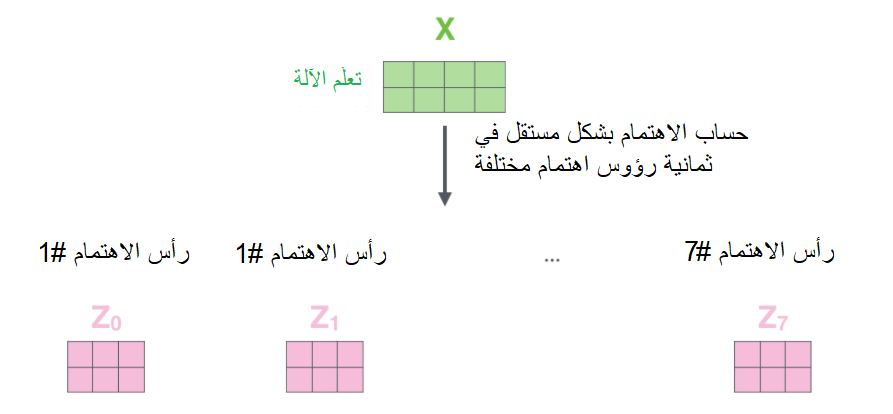
ولكنَّ ذلك سيتركنا مع تحدٍّ لأنّ طبقة التّغذية الأماميّة لا تتوقّع ثماني مصفوفات كدخل لها، وإنّما تتوقّع مصفوفة واحدة فقط (مُتّجه لكلّ كلمة)، لذلك نحتاج إلى طريقة لتقليص المصفوفات الثّمانية هذه إلى مصفوفة واحدة.
فكيف سنقوم بذلك؟ حسنًا، سنقوم بضمّ المصفوفات الثّمانية في مصفوفة واحدة، وبعد ذلك سنقوم بضرب المصفوفة النّاتجة بمصفوفة أوزان إضافيّة W0 كما هو مُبيّن في الشّكل (16).

يُبيّن الشّكل (17) مراحل الحساب في الاهتمام الذّاتيّ مُتعدّد الرّؤوس
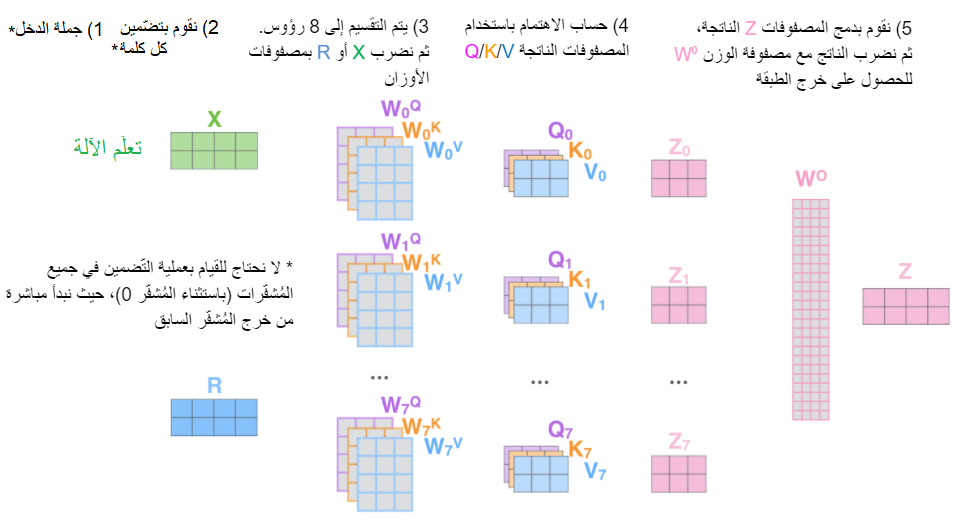
والآن بعد أن تطرّقنا للاهتمام مُتعدّد الرّؤوس، دعونا نرجع إلى مثالنا البسيط السّابق لمعرفة مكان تركيز رؤوس الاهتمام المختلفة أثناء عمليّة تشفير الكلمة “it”. يُوضّح الشّكل (18) أنّه أثناء عمليّة تشفير الكلمة “it” يقوم أحد رؤوس الاهتمام بالتّركيز بشكل أكبر على “the animal”، بينما يُرَكّز رأس آخر على كلمة “tired”، بمعنى أنّ تمثيل النموذج للكلمة “it” يضمُّ جزءاً من تمثيلات كلٍّ من الكلمتين ” tired” و “animal”.

يُبيّن الشّكل التّالي (19) أنّه لو قمنا بإضافة كلّ رؤوس الاهتمام إلى الشّكل السّابق، سيكون من الصّعب علينا تفسير الخرج النّاتج.
تمثيل ترتيب سلسلة الدّخل باستخدام التّشفير الموضعيّ Positional Encoding
يفتقدُ النّموذج الذي قمنا بشرحه حتى الآن إلى شيء واحد وهو وجود طريقة لحساب ترتيب الكلمات في سلسلة الدّخل. من أجل حلّ هذه المسألة، يقوم المُحوّل بإضافة مُتّجه جديد إلى كلّ مُتّجه تضمين دخل، تقوم هذه المُتّجهات الجديدة باتّباع نمط مُحدّد يَتعلَّمُه النّموذج ليساعده على تحديد موقع كلّ كلمة أو المسافة بين الكلمات المختلفة في الجملة. تكمُنُ الفكرة وراء هذا الحلّ في أنَّ إضافة هذه القيم إلى مُتّجهات التّضمين، تُؤمِّن مسافات ذات معنى بين مُتّجهات التّضمين عند حساب مُتَّجهات Q/K/V و خلال عمليّة الجداء النُّقطيّ في الاهتمام. يُبيّن الشّكل (20) طريقة التّشفير الموضعيّ.
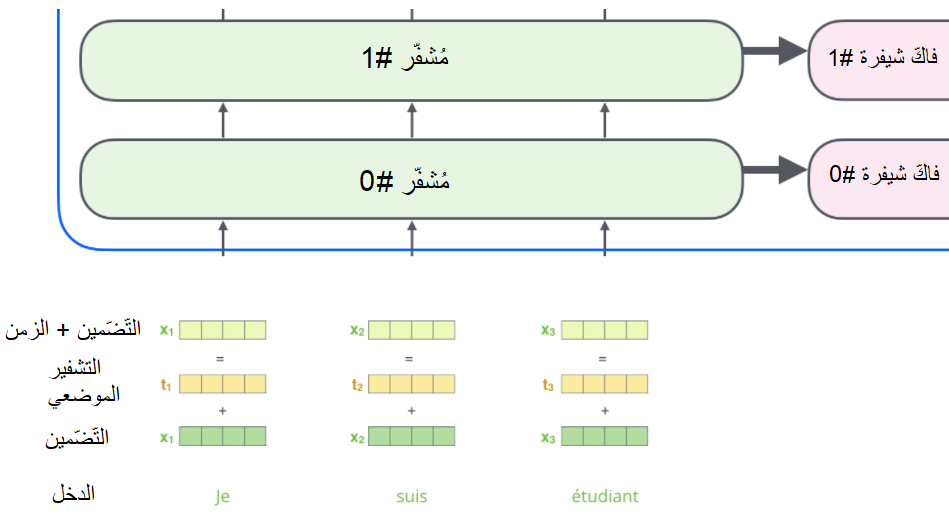
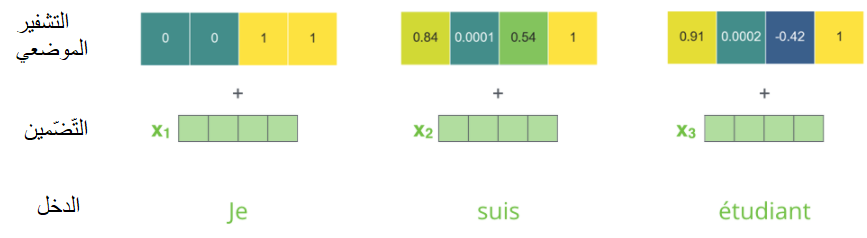
لو افترضنا أنّ أبعاد مُتّجه التّضمين /4/، فإنّ التّشفيرات الموضعيّة الفعليّة ستبدو كما هو واضح في الشّكل (21).
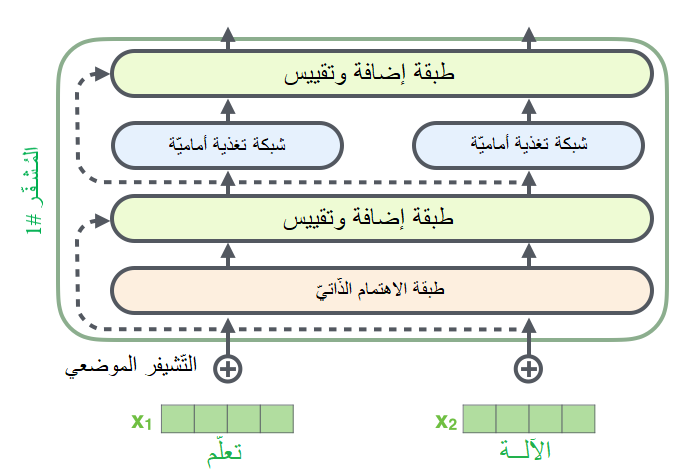
الرَّواسب Residuals
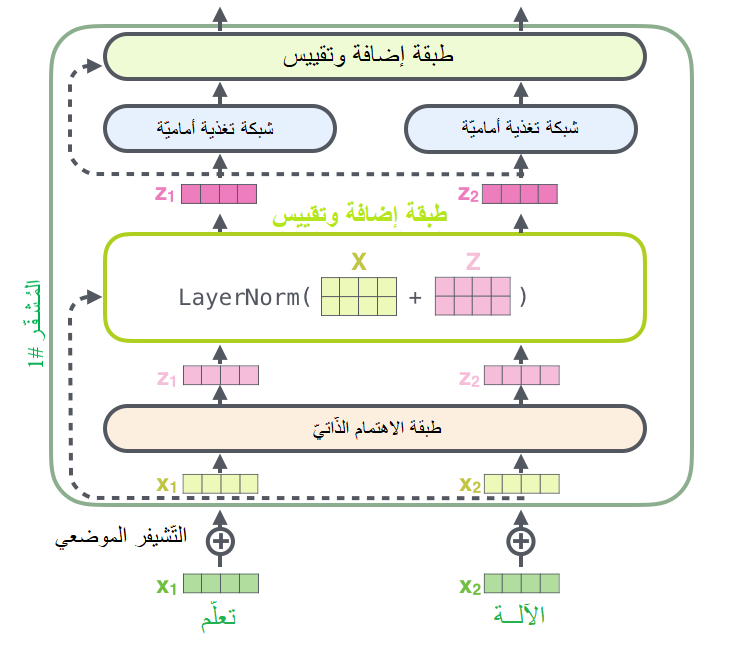
هناك تفصيلٌ لا بُدَّ من ذكره في بنية المُشفّر، وهو أنّه في كلّ مُشفّر تمتلك كلَّ طبقة فرعيّة (الاهتمام الذّاتيّ مثلًا) وصلة مُختصرة residual connection حولها تليها خطوة تقييس (طبقة تقييس normalization layer)، كما هو واضح في الشّكل (22).
يُبيّن الشّكل (23) خرج طبقة الاهتمام الذّاتيّ وتفاصيل طبقة التّقييس في المُشفّر.
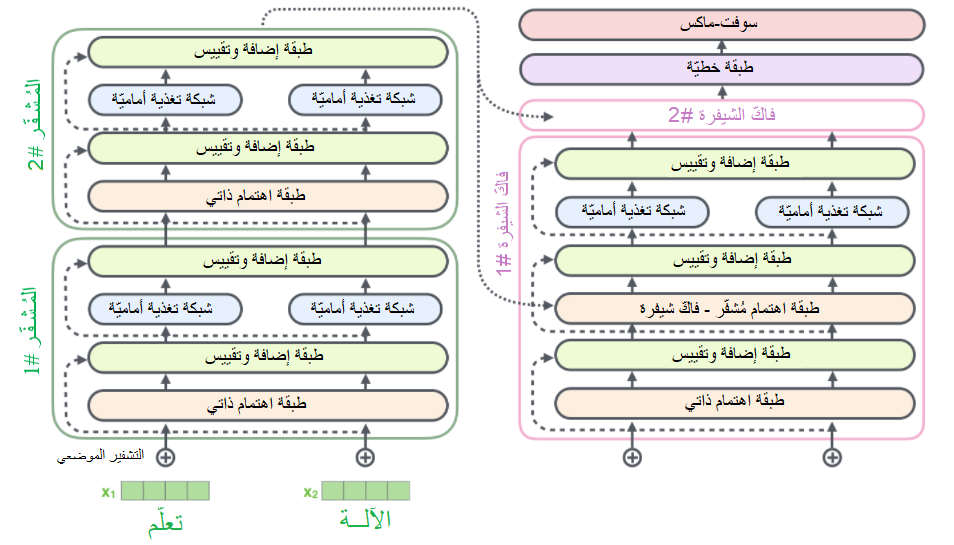
يتمُّ تمرير خرج المُشفّرات إلى الطّبقات الفرعيّة لفاكّ الشّيفرة، فلو افترضنا أنّه لدينا مُحوّل مُكوّن من مُشفّرين وفاكّي شيفرة، ستبدو بنيتهما كما هو واضح في الشّكل (24).
فاكّ الشيفرة
تعملُ أغلب مُكوّنات فاكّ الشيفرة بنفس طريقة عمل مُكوّنات المُشفّر، وسنقوم فيما سيأتي بإلقاء نظرة على كيفيّة عملهما معًا.
أولًا يبدأ المُشفّر بمعالجة سلسلة الدّخل، ثمّ يتمُّ تحويل خرج المُشفّر العلويّ (آخر مُشفّر) إلى مجموعة من مُتّجهات الاهتمام المفتاح K و القيمة V. تُستخدمُ هذه المُتّجهات في كلّ فاكّ شيفرة عن طريق طبقة “الاهتمام مشفّر- فاكّ الشّيفرة encoder-decoder attention”؛ التي تُساعد فاكّ الشيفرة على التّركيز على الأماكن المناسبة في سلسلة الدّخل كما هو مُبيّن في الشّكل (25).
نلاحظ أنّه بعد انتهاء مرحلة التّشفير تبدأ مرحلة فكّ التّشفير، حيث تقوم كلّ خطوة فكّ تشفير بإخراج عنصر من سلسلة الخرج.
يتمُّ تكرار الخطوات السّابقة حتى الوصول إلى رمز خاصّ يُشيرُ إلى أنّ فاكّ الشيفرة في المحوّل قد أنهى عمله (اكتمل الخرج). يتمُّ تمرير خرج كلّ خطوة إلى فاكّ الشّيفرة السّفليّ (الأوّل) في الخطوة الزّمنيّة التّالية، وتقومُ فاكّات الشّيفرة المُكدّسة برفع خرجها إلى الأعلى الواحد تلوَ الآخر كما رأينا في المُشفّر تمامًا. يتمُّ هنا أيضًا تطبيق التّضمين و التّشفير الموضعيّ لمُدخلات فاكّ الشّيفرة تمامًا كما فعلنا مع مُدخلات المُشفّر للدّلالة على موقع كلّ كلمة. يوضّح الشّكل (26) خطوات عمل فاكّ الشّيفرة في كلّ خطوة زمنيّة.
تعمل طبقات الاهتمام الذّاتيّ في فاكّ الشّيفرة بطريقة مختلفة قليلًا عن تلك الموجودة في المُشفّر.
- ففي فاكّ التّشفير، تُوجد طبقة الاهتمام الذّاتيّ فقط في المواقع الأولى في سلسلة الخرج. يتمُّ ذلك عن طريق حجب masking المواقع اللّاحقة (المُستقبليّة) بضبطهم بالقيمة -inf قبل خطوة السّوفت ماكس عند حساب الاهتمام الذّاتيّ.
- تعمل طبقة “الاهتمام مشفّر- فاكّ الشّيفرة” تمامًا كطبقة الاهتمام الذّاتيّ مُتعدّد الرّؤوس، عدا أنّها تقوم بإنشاء مصفوفة الأسئلة Q الخاصّة بها من الطّبقات الموجودة أسفل منها، وتقوم بأخذ مصفوفتي المفاتيح K والقيَم V من خرج مُكدّس المشفّر.
طبقة السّوفت ماكس والطّبقة الخطّيّة الأخيرتان
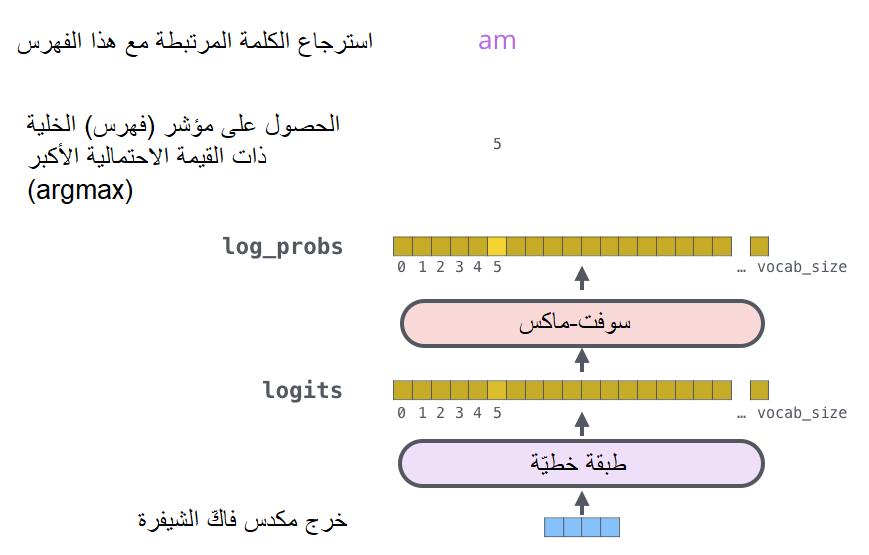
إنَّ خرج مكدّس فاكّ الشيفرة هو مُتّجه من الأعداد ذات الفاصلة العائمة floats. والسّؤال هنا، كيف سنحوّل هذه الأعداد إلى كلمة؟
حسنًا، الجواب هو عن طريق الطّبقة الخطّيّة الأخيرة المتْبوعة بطبقة سوفت ماكس.
إنّ الطّبقة الخطّيّة هي عبارة عن شبكة عصبونيّة بسيطة ذات اتّصال كامل fully ،connected layer تقوم بإسقاط المُتّجه النّاتج عن مكدّس فاكّات الشّيفرة على مُتّجه أكبر بكثير يُدعى المُتّجه اللّوغاريتميّ logits.
لنفترض أنّ النّموذج يعرف 10000 كلمة إنجليزيّة فريدة (“مفردات الخرج” الخاصّة بالنّموذج) قام بتَعلُّمها من مجموعة بيانات التّدريب، وبالتّالي سيكون حجم المُتّجه اللّوغاريتميّ 10000 بحيث تُمثّلُ كلّ قيمة في هذا المُتّجه درجة كلمة فريدة. بعد ذلك، تقومُ طبقة سوفت ماكس بتحويل تلك الدّرجات إلى احتمالات (جميعها موجبة ومجموعها 1). أخيرًا، يتمُّ اختيار القيمة ذات الاحتماليّة الأكبر ويتمُّ اعتبار الكلمة المرتبطة بها كخرج لهذه الخطوة الزّمنيّة. يوضّح الشّكل (27) آليّة تطبيق الطّبقة الخطيّة وطبقة سوفت ماكس.
الخاتمة
تكلّمنا في هذا المقال عن المُحوّل وعن مكوّناته الرّئيسيّة، وتعرّفنا على طريقة عمل كلّ من المُشفّر وفاكّ الشّيفرة. كما قمنا بشرح بعض الطّبقات المُهمّة في هذا النّموذج كطبقة الاهتمام الذّاتيّ. أرجو – عزيزي القارئ – أن تكون استفدت من هذا المقال الذي يهدف إلى شرح المفاهيم الأساسيّة لنموذج المُحوّل. في حال كنت تريد التعمُّق أكثر، أنصحك بأن تطّلع على ما يلي:
- قراءة الورقة البحثيّة التي قدّمت نموذج المُحوّل [1].
- مشاهدة فيديو للباحث لدى جوجل لوكاسز كايسير الذي شرح فيه تفاصيل النّموذج
الاطّلاع على ملفّ جوبيتر المُقدّم من جوجل كجزء من مستودع الشّيفرة البرمجيّة تينسور-إلى-تينسور.
المراجع
- Attention Is All You Need
- The Illustrated Transformer
- نموذج ترجمة آليّة عصبونيّة (نماذج سلسلة إلى سلسلة Seq2Seq مع آليّة الاهتمام Attention)
- The Annotated Transformer
- Transformer: A Novel Neural Network Architecture for Language Understanding
- Accelerating Deep Learning Research with the Tensor2Tensor Library


تعليقان
بارك الله فيكم على هذا الشرح المميز
اريد بعص التفاصيل في استخدام المحول في معالجة الصور وتحليل الصور وكيفية التعرف على الوجه واستخراج تحاليل الصورة باستخدام المحول ان امكن ذلك ولو حتى شرح بعض المقالات المتخصصة في مثل هذه المجال بارك الله فيكم ماجورين مشكورين باذن الله
مشكور دكتور على شرح.
هل يمكن شرح كيفية استعمال transformese في مجال رؤية الصور ومعالجتها و تصنيفها مثل CNN