
إعداد: م. نور شوشرة
التّدقيق العلميّ: د.م. حسن قزّاز، م. محمّد سرميني
المَحتويَات
مقدمة إلى أباتشي سبارك
أباتشي سبارك (بالإنجليزية: Apache Spark) هو نظام معالجةٍ موزّعةٍ يستخدم لأداء مهام البيانات الضّخمة وتّعلّم الآلة على مجموعات البيانات الضخمة.
في حالة محدودية التخزين المحلي على جهاز الحاسب و معالجة البيانات باستخدام بايثون أو أر R و عدم إمكان التّعامل مع مجموعات البيانات الضخمة للغاية،هنا يأتي نظام المعالجة الموزّعة مثل أباتشي سبارك.
المعالجة الموزّعة هي نظامٌ يتم فيه استخدام معالجات متعددةٍ لتشغيلِ التّطبيق. بدلاً من محاولة معالجة مجموعاتِ بياناتٍ ضخمةٍ على جهازِ حاسبٍ واحدٍ، يمكن تقسيم المهمّة بين أجهزةٍ متعددةٍ متصلةٍ فيما بينها.
باستخدام أباتشي سبارك، يمكن للمستخدمين تشغيل الاستعلامات ومهامِّ سير عمل تّعلّم الآلة على بيتابايت petabytes من البيانات، وهو أمرٌ يستحيل القيام به على جهازك المحليّ.
هذا الإطار أسرع حتّى من محركات معالجة البيانات السابقة مثل هادوب Hadoop، وازدادت شعبيته في السنوات الثماني الماضية. وتستخدم شركات مثل آي بي إم IBM، وأمازون Amazon، وياهو Yahoo أباتشي سبارك كإطارٍ لها.
إن القدرة على تحليل البيانات وتدريب نماذج التّعلّم الآليّ على مجموعاتِ بياناتٍ و امتلاك الخبرة اللازمة للعمل مع أطر البيانات الضّخمة مثل أباتشي سبارك أصبح الأن مهماً نظراً لضخامة البيانات فيما
ماهو “بيسبارك” Pyspark ؟ [1]
بيسبارك هو واجهةٌ لأباتشي سبارك في بايثون.
مع بيسبارك، يمكنك كتابة أوامر بايثون و SQL لمعالجة وتحليل البيانات في بيئةِ معالجةٍ موزعةٍ. هذه المقالة للمبتدئين ستأخذكم عبر: معالجة البيانات، بناء خط أنابيب تعلم الآلة، وضبط النماذج مع بيسبارك.
فيمَ تستخدم “بيسبارك” Pyspark ؟ [1]
معظم علماء البيانات والمحللين يستخدمون لغة البرمجة بايثون لتنفيذ نماذج التعلم الآلي. تسمح بيسبارك لهم بالعمل بلغة مألوفة على مجموعات البيانات الموزعة على نطاق واسع.
أباتشي سبارك يمكن أيضاً أن تستخدم مع غيرها من لغات برمجة علوم البيانات مثل R أو جافا java.
لماذا “بيسبارك” Pyspark ؟ [1]
مع زيادة ضخامة البيانات حولنا،فالشّركات التي تجمع تيرابايت terabytes من البيانات ستضطرّ لاستخدام إطارٍ للبيانات الضخمة مثل أباتشي سبارك للعمل مع مجموعات البيانات الضخمة هذه، نحتاج لاستخدام إطارِ عمل مع لغة البرمجة المستخدمة بايثون أو أر R يسمح لك بمعالجة مجموعات البيانات على رأس نظام المعالجة الموزعة.
ذاً پيسبارك مهمةٌ للتعامل مع أباتشي سبارك باستخدام بايثون و لأنّ تركيبته اللّغوية بسيطةٌ ويمكن تعلُّمها بسهولة إذا كنتم على دراية بلغة البرمجة بايثون .
والسبب وراء اختيار الشّركات لاستخدام إطارٍ مثل بيسبارك هو مدى سرعتها في معالجة البيانات الضخمة. وهي أسرع من مكتباتٍ مثل بانداس pandas، ويمكنها التعامل مع كمّياتٍ أكبر من البيانات من هذه الأطر. إذا كان لديك أكثر من بيتابايت من البيانات للمعالجة، على سبيل المثال، البانداس ستفشل ولكن بيسبارك ستكون قادرة على التعامل معها بسهولةٍ.
بالإضافة إلى أنّها أسرع ويمكنها التعامل مع البيانات في الوقت الحقيقي.
كيفية تثبيت باي سبارك [1][3][2]
قبل تثبيت أباتشي سبارك Apache Spark و PySpark، تحتاج إلى إعداد البرامج التالية على جهازك
بايثون Python
إذا لم تكن لغة بايثون مثبتةً لديك بالفعل، تحتاج إلى تثبيتها على جهازك،اتبع هذا البرنامج التّعليمي لتثبيت بايثون على جهازكتثبيت بايثون
جافا JAVA
بعد ذلك، اتبع هذا البرنامج التّعليمي لتثبيت لغة الجافا Java على جهاز الحاسوب الخاصّ بك إذا كنت تستخدم نظام التشغيل Windowsتثبيت جافا
أباتشي سبارك Apache Spark
لإعداد أباتشي سبارك، انتقل إلى صفحة التّنزيل وقم بتنزيل ملفّ .tgz المعروض على الصّفحة:
والشكل (1) يوضح واجهة تحميل أباتشي سبارك
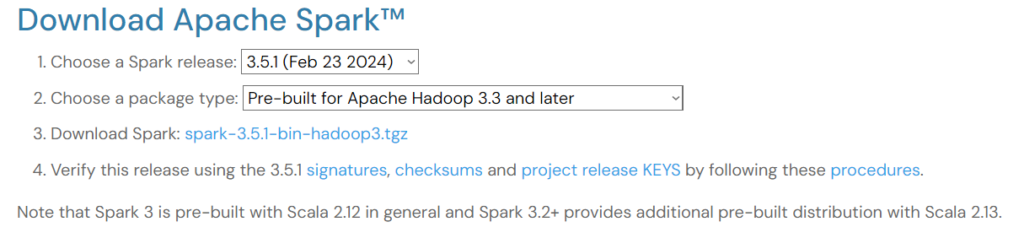
ثمّ، إذا كنت تستخدم نظام التّشغيل Windows، فقم بإنشاء مجلدٍ في دليل C الخاص بك يسمى “spark”.
بعد ذلك، قم باستخراج الملفّ الذي قمت بتنزيله للتّوّ ولصق محتوياته في مجلد “spark” هذا. هذا هو الشكل الذي يجب أن يبدو عليه مسار المجلد:
C:\spark\spark-2.4.0-bin-hadoop2.6
الآن، تحتاج إلى تعيين متغيّرات البيئة الخاصّة بك يدوياً.
الخطوة 1: انتقل إلى ابدأ -> النّظام -> الإعدادات -> الإعدادات المتقدّمة
Start -> System -> Settings -> Advanced Settings
الخطوة 2: انقر على متغيّرات البيئة
Environment Variables
والشكل(2) يوضح متغيرات البيئة
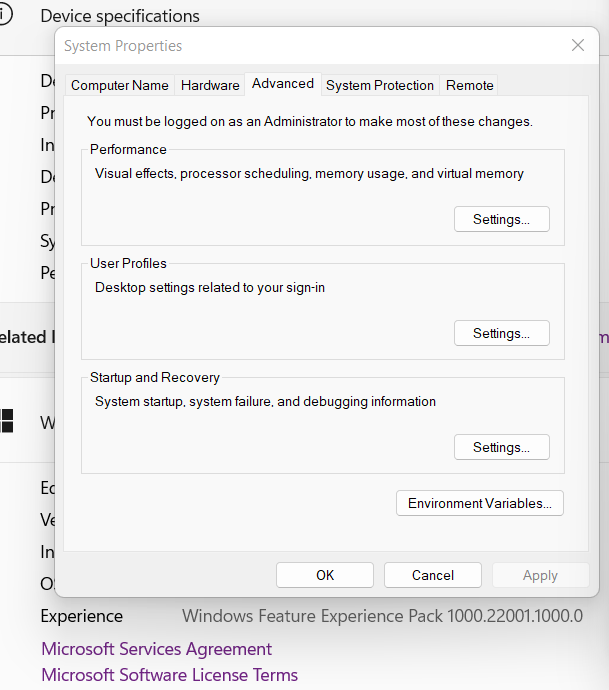
الخطوة 3: في متغيّرات البيئة، انقر فوق جديد.
الخطوة 4: أدخل القيم التالية في اسم المتغيّر وقيمة المتغيّر. لاحظ أن الإصدار الذي قمت بتثبيته قد يكون مختلفًا عن الإصدار الموضح أدناه، لذا انسخ المسار والصقه في دليل Spark الخاص بك.
والشكل(3) يوضح إضافة متيغر بيئة

الخطوة 5: بعد ذلك، في علامة التّبويب متغيرات البيئة، انقر فوق المسار وحدّد تحرير.
الخطوة 6: انقر على جديد والصقه في المسار إلى دليل Spark bin الخاصّ بك. فيما يلي مثالٌ لما يبدو عليه دليل bin:
C:\spark\spark-3.3.0-bin-hadoop3\bin
مجموعة البيانات :
سنستخدم مجموعةَ بياناتِ التّجارة الإلكترونيّة الخاصّة بـ Datacamp لإجراء جميع التّحليلات في هذا البرنامج التعليمي، لذا تأكد من تنزيلها. مجموعة البيانات
تثبيت باي سبارك PySpark :
الآن بعد أن قمت بتثبيت أباتشي سبارك Apache Spark وجميع المتطلّبات الأساسيّة الأخرى بنجاح، افتح ملفّ بايثون في صفحة جوبتر Jupyter Notebook وقم بتشغيل سطور التعليمات البرمجية التالية في الخلية الأولى:
!pip install pyspark
البرنامج التعليمي الشامل لتعلم الآلة بيسبارك:[1]
الآن بعد أن تمّ تشغيل بيسبارك، سنوضّح لك كيفيّة تنفيذ مشروعِ تجزئة العملاء الشامل باستخدام المكتبة بي سبارك pysparkتجزئة العملاء هي تقنية تسويقية تستخدمها الشركات لتحديد وتجميع المستخدمين الذين يظهرون خصائص مماثلة. على سبيل المثال: إذا قمت بزيارة ستاربكس خلال فصل الصّيف فقط لشراء المشروبات الباردة، فيمكن تصنيفك على أنّك “متسوقٌ موسميٌ” وإغرائُك بعروضٍ ترويجيةٍ خاصةٍ مصممةٍ لموسمِ الصيف.عادةً ما يقوم علماء البيانات ببناء خوارزميات تعلّم آليٍّ غير خاضعةٍ للرقابة مثل خوارزمية التجميع K-Means أو التّجميع الهرمي لتنفيذ تجزئة العملاء. تعتبر هذه النماذج رائعةً في تحديد الأنماط المتشابهة بين مجموعات المستخدمين .
في هذا المقال ، سوف نستخدم خوارزمية التجميع K-Means لإجراء تجزئة العملاء على مجموعة بيانات التّجارة الإلكترونيّة التي قمنا بتنزيلها سابقًا.في نهاية هذا المقال ، سوف تكون على دراية بالمفاهيم التالية:
- قراءة ملفات CSV مع PySpark
- تحليل البيانات الاستكشافية باستخدام PySpark
- تجميع وفرز البيانات
- إجراء العمليات الحسابية
- تجميع مجموعات البيانات Aggregating
- المعالجة المسبقة للبيانات باستخدام PySpark
- العمل مع قيم التاريخ والوقت
- الانضمام إلى إطارين للبيانات Joining
- التّعلّم الآليّ PySpark
- إنشاء شعاع الميزات feature vector
- توحيد البيانات Standardizing
- بناء نموذج التّجميع K-Means
- تفسير النّموذج
الخطوة 1: إنشاء جلسة SparkSession
تعدّ جلسة سبارك نقطة دخولٍ إلى جميع الوظائف في Spark، وهي مطلوبةٌ إذا كنت تريد إنشاء إطار بياناتٍ في بي سبارك PySpark. قم بتشغيل الأسطر التالية من التعليمات البرمجية لتهيئة SparkSession:
spark = SparkSession.builder.appName("Pyspark Tutorial").getOrCreate()
إنشاء كائنٍ SparkSession يسمى “spark”
يقوم المُعامل appName بتعيين اسم التطبيق إلى “Pyspark Tutorial”.
الخطوة 2 : إنشاء إطار البيانات DataFrame
يمكننا الآن قراءة مجموعة البيانات التي قمنا بتنزيلها سابقاً :
df = spark.read.csv('datacamp_ecommerce.csv',header=True)
استخدمنا معامل header لنأخذ أسماء الاعمدة كما وردت في الملف
دعونا نلقي نظرة على رأس إطار البيانات باستخدام الدّالة show():
والشكل (4) يوضخ تاتج عملية إظهار رأس البيانات
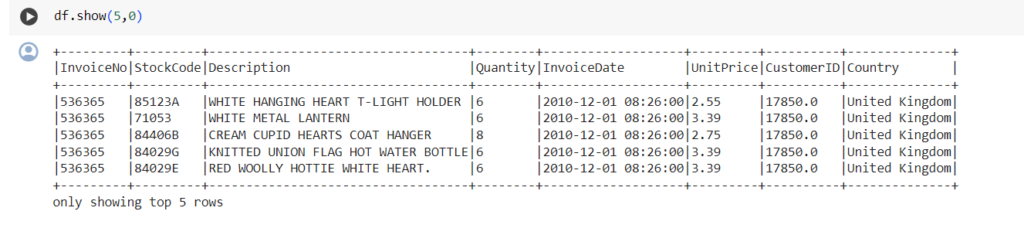
لعرض الصفوف الخمسة الأولى من إطار البيانات DataFrame df.
عن طريق تعيين الوسيطة الثانية إلى 0، سيتم عرض كافّة الأعمدة دون اقتطاع
يكون هذا مفيدًا عند العمل مع مجموعات البيانات الضخمة حيث نأخذ نظرةً على مجموعة البيانات بدل من عرضها جميعها .
يتكون إطار البيانات من 8 متغيرات:
- InvoiceNo: المعرّف الفريد لكلّ فاتورة عميل.
- StockCode: المعرّف الفريد لكلّ عنصر في المخزن.
- الوصف Description : السلعة التي اشتراها العميل.
- الكمية Quantity: عدد كلّ صنفٍ اشتراه العميل في الفاتورة الواحدة.
- تاريخ الفاتورة InvoiceDate : تاريخ الشّراء.
- سعر الوحدة UnitPrice: سعر وحدةٍ واحدةٍ من كلّ منتجٍ.
- معرف العميل CustomerID: معرّفٌ فريدٌ مخصصٌ لكلِّ مستخدمٍ.
- البلد Country: البلد الذي تمَّ الشّراء منه
الخطوة 3: تحليل البيانات الاستكشافية
الآن بعد أن رأينا المتغيّرات الموجودة في مجموعة البيانات هذه، دعونا نجري بعض التحليل للبيانات الاستكشافية لفهم نقاط البيانات بشكل أكبر:
لنبدأ بحساب عدد الصفوف في إطار البيانات:
df.count()
يتم استخدام الدّالة df.count() لحساب عدد القيم غير الخالية في كل عمودٍ من إطار البيانات df و لدينا 541909سطر
كم عدد العملاء الفريدين الموجودين في إطار البيانات؟
df.select('CustomerID').distinct().count()
- يقوم الكود بتحديد العمود “معرف العميل ‘CustomerID'” من PySpark إطار البيانات المسمى “df”.
- بعد ذلك، يتم تطبيق التاّبع “distinct” للحصول على القيم الفريدة لـ “CustomerID” فقط.
- وأخيرًا، يتم استخدام طريقة “count” لحساب عدد القيم الفريدة.
- و لدينا 4373 عميل فريد
من أي بلد تأتي معظم المشتريات؟
للعثور على البلد الذي تتمُ منه معظم عمليات الشّراء، نحتاج إلى استخدام جملة groupBy() في PySpark:
from pyspark.sql.functions import *<br>from pyspark.sql.types import *<br>df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()<br>
- يستخدم السطر الثاني من التعليمات البرمجية أسلوب groupBy() لتجميع البيانات في إطار البيانات df حسب عمود البلد.
- يتم بعد ذلك استخدام طريقة agg() لتطبيق دالّة التّجميع على كل مجموعة.
- في هذه الحالة، يتم استخدام الدالة countDistinct() لحساب عدد قيم معرف العميل المميزة في كلّ مجموعةٍ.
- يتم استخدام الأسلوب alias() لإعادة تسمية العمود الناتج إلى Country_count.
- وأخيرًا، يتم استخدام طريقة show() لعرض إطار البيانات الناتج بتنسيقٍ جدولي.
- سيُظهر هذا عدد العملاء المتميزين لكل بلد في عمود “البلد” في إطار البيانات الأصلي.
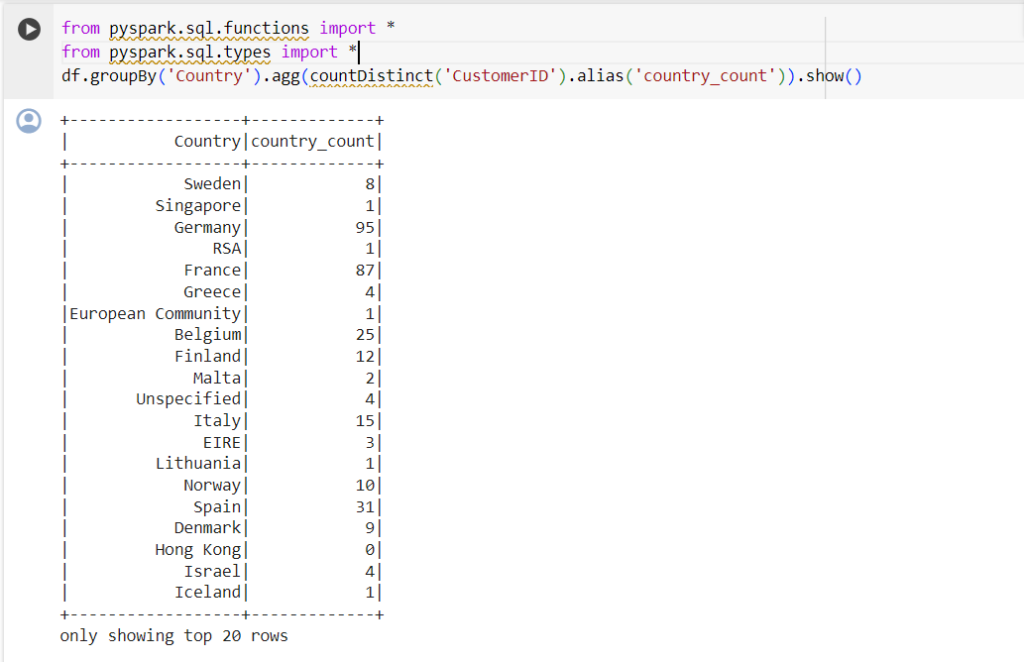
لاحظ أن البيانات في الجدول أعلاه غير معروضةٍ حسب ترتيب المشتريات. لفرز هذا الجدول، يمكننا تضمين جملة orderBy():
يتم الآن فرز الإخراج المعروض بترتيب تنازلي:
والشكل (6) يوضح ترتيب البلدان بشكل تنازلي

بناء على ذلك أغلب عمليات الشراء تتم في المملكة المتحدة United Kingdom.
متى كانت آخر عملية شراء قام بها العميل على منصّة التجارة الإلكترونية؟
لمعرفة متى تمّ إجراء آخر عملية شراءٍ على المنصّة، نحتاج إلى تحويل عمود “InvoiceDate” إلى تنسيق طابع زمني واستخدام دالّة max() في Pyspark
df = df.withColumn('date',to_timestamp("InvoiceDate"))<br>df.select(max("date")).show()
يقوم السّطر الأول بإنشاء عمودٍ جديدٍ يسمى التاريخ في إطار البيانات df
تمّ إنشاء القيم الموجودة في هذا العمود من خلال تطبيق الدّالّة to_timestamp على العمود InvoiceDate في df. أي تحويلها لطريقة يمكن فهمها من خلال البيسبارك على أنها datetime
السّطر الثاني يقوم باختيار Max القيمة الأعلى في عمود التاريخ ويعرضها باستخدام طريقة العرض.show()
و بناء عليه أخر تاريخ شراءٍ |2011-12-09 12:50:00|
متى كانت أوّل عملية شراء قام بها العميل على منصة التّجارة الإلكترونية؟
مثلما فعلنا أعلاه، يمكن استخدام الدّالّة min() للعثور على أقل تاريخٍ ووقتٍ للشراء
df.select(min("date")).show()<br> <br>
وبناء عليه أولّ عملية شراء |2010-12-01 08:26:00|
الخطوة 4: المعالجة المسبقة للبيانات
الآن بعد أن قمنا بتحليل مجموعة البيانات ولدينا فهم أفضل لكلّ نقطة بياناتٍ، نحتاج إلى إعداد البيانات لإدخالها في خوارزميّة تعلّم الآلة.
من مجموعة البيانات أعلاه، نحتاج إلى إنشاء شرائح عملاءٍ متعددةٍ بناءً على سلوك الشّراء لكلّ مستخدمٍ.
المتغيّرات في مجموعة البيانات هذه موجودةٌ بتنسيقٍ لا يمكن استيعابه بسهولةٍ في نموذج تجزئة العملاء. لا تخبرنا هذه الميزات بشكلٍ فرديٍ كثيرًا عن سلوك الشراء لدى العميل.
ونتيجةً لذلك، سوف نستخدم المتغيرات الحالية لاستخلاص ثلاث ميزاتٍ جديدة – الحداثة والتكرار والقيمة النقدية (RFM).
يُستخدم نظام RFM بشكلٍ شائعٍ في التّسويق لتقييم قيمة العميل بناءً على:
- الحداثة Recency: ما مدى قيام كلّ عميلٍ بعملية شراءٍ مؤخرًا؟
- التكرار Frequency: كم مرةً قاموا بشراء شيءٍ ما؟
- القيمة النقدية Monetary Value: ما هو مقدار الأموال التي ينفقونها في المتوسط عند إجراء عمليات الشراء؟
سنقوم الآن بمعالجة إطار البيانات مسبقًا لإنشاء المتغيّرات المذكورة أعلاه.
الحداثة Recency:
دعونا نحسب قيمة الحداثة – آخر تاريخ ووقت تم فيه إجراء عملية شراء على المنصة.
ويمكن تحقيق ذلك في خطوتين:
- تعيين درجة حداثةٍ لكلّ عميلٍ
سنقوم بطرح كلّ تاريخٍ في إطار البيانات من التّاريخ الأقدم. سيخبرنا هذا بمدى ظهور العميل في إطار البيانات. تشير القيمة 0 إلى أقل حداثة، حيث سيتم تخصيصها للشخص الذي تمت رؤيته وهو يقوم بعملية شراء في أقلّ تاريخٍ
df = df.withColumn("from_date", lit("2010-12-01 08:26:00"))<br>df = df.withColumn('from_date',to_timestamp("from_date")) <br>df2=df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))<br>
يقوم السطر الأول بإنشاء عمودٍ جديدٍ يسمى “from_date” في PySpark DataFrame “df” ويقوم بتعيين كافة القيم في هذا العمود إلى السلسلة “12/1/10 08:26”. • يقوم السّطر الثاني بتحويل عمود “from_date” من سلسلة إلى تنسيق طابع زمني باستخدام دالة “to_timestamp”. • يقوم السّطر الثالث بإنشاء DataFrame جديد يسمى “df2” عن طريق تطبيق تحويلين على DataFrame الأصليّ “df”. • يقوم التحويل الأول بتحويل عمود “from_date” إلى تنسيق طابع زمني باستخدام دالة “to_timestamp” بدون وسائط. • يقوم التحويل الثاني بإنشاء عمودٍ جديدٍ يسمى “الحداثة” عن طريق طرح الطابع الزمني لنظام Unix الخاصّ بعمود “from_date” من الطابع الزمني لنظام Unix الخاصّ بعمود “date”. • يتم استخدام الدالة “col” للإشارة إلى الأعمدة في DataFrame.
- تحديد آخر عملية شراء
يمكن لعميلٍ واحد إجراء عمليّات شراءٍ متعدّدةٍ في أوقاتٍ مختلفةٌ. نحتاج فقط إلى تحديد وقت آخر عملية شراء:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')
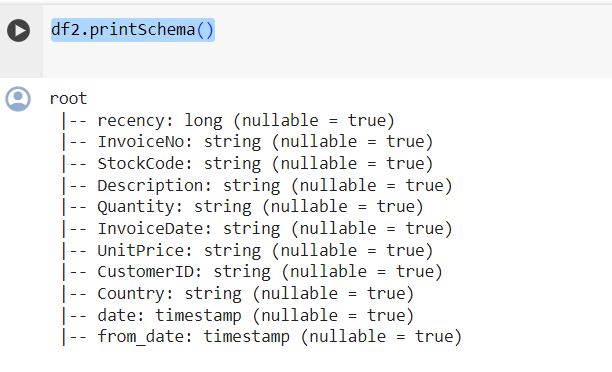
أسهل طريقةٍ لعرض جميع المتغيّرات الموجودة في إطار بيانات PySpark هي استخدام دالة printSchema() الخاصة بها. هذا يعادل دالة info() في Pandas:
والشكل (7) يوضح إظهار وعرض جميع المتغيرات الموجودة في إطار البيانات
التّكرارFrequency
لنحسب الآن قيمة التّكرار – عدد المرات التي اشترى فيها العميل شيئًا ما على المنصة- للقيام بذلك، نحتاج فقط إلى التجميع group by حسب معرّف كلّ عميلٍ وحساب عدد العناصر التي اشتراها:
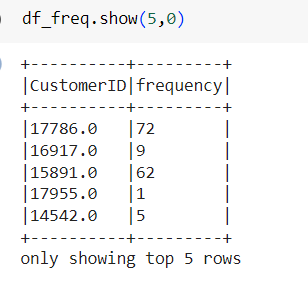
توجد قيمة تردّد تكرار خاصة لكل عميلٍ في إطار البيانات. يحتوي إطار البيانات الجديد هذا على عمودين فقط، ونحن بحاجة إلى ربطه بإطار البيانات السابقة:
والشكل (8) يوضج رأس إطار البيانات في df_freq
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))
ربطه بإطار البيانات السابقة
df3 = df2.join(df_freq,on='CustomerID',how='inner')
لنطبع مخطط إطار البيانات هذا: و الشكل (9) يوضح جميع المتغيرات الموجودة في df3

القيمة النقدية Monetary Value
أخيرًا، دعونا نحسب القيمة النقدية – المبلغ الإجمالي الذي أنفقه كلّ عميلٍ في إطار البيانات. هناك خطوتان لتحقيق ذلك:
- ابحث عن المبلغ الإجمالي الذي تم إنفاقه في كلّ عملية شراء:
يأتي كلّ معرف عميل مع متغيرات تسمى “الكميّة” و”سعر الوحدة” لعملية شراءٍ واحدةٍ:
للحصول على المبلغ الإجماليّ الذي أنفقه كلّ عميلٍ في عملية شراءٍ واحدة، نحتاج إلى ضرب “الكميّة” في “سعر الوحدة”:
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))
- ابحث عن المبلغ الإجمالي الذي أنفقه كل عميل:
للعثور على إجمالي المبلغ الذي أنفقه كلّ عميلٍ بشكلٍ عامٍ، نحتاج فقط إلى التجميع حسب عمود معرّف العميل وجمع إجمالي المبلغ الذي تمّ إنفاقه:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))
دمج إطار البيانات هذا مع جميع المتغيرات الأخرى:
finaldf = m_val.join(df3,on='CustomerID',how='inner')
الآن بعد أن أنشأنا جميع المتغيرات اللّازمة لبناء النموذج، قم بتشغيل سطور التّعليمات البرمجية التالية لتحديد الأعمدة المطلوبة فقط حذف الصفوف المكرّرة من إطار البيانات
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()
التوحيد القياسي standraization
قبل بناء نموذج تجزئة العملاء، دعونا نوحّد إطار البيانات للتأكّد من أن جميع المتغيرات على نفس النطاق:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)
قم بتشغيل الأسطر التالية من التّعليمات البرمجية لترى كيف يبدو ناقل الميزات القياسي:
data_scale_output.select('standardized').show(2,truncate=False)
الخطوة 5: بناء نموذج تعلّم الآلة
الآن بعد أن أكملنا جميع تحليل البيانات وإعدادها، فلنبني نموذج التجميع K-Means
- إيجاد العدد المناسب لعدد العناقيد
عند إنشاء نموذج تجميع K-Means، نحتاج أولاً إلى تحديد عدد المجموعات أو العناقيد التي نريد أن تعدّها الخوارزمية. إذا قررنا اختيار ثلاث مجموعات، على سبيل المثال، فسيكون لدينا ثلاث شرائحٍ من العملاء.
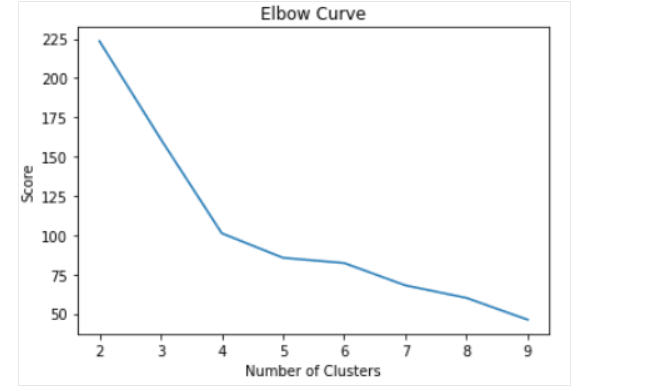
التقنية الأكثر شيوعًا المستخدمة لتحديد عدد المجموعات التي سيتم استخدامها في K-Means تسمى “طريقة الكوع Elbow Method”.
يتم ذلك ببساطة عن طريق تشغيل خوارزمية K-Means لمجموعةٍ واسعةٍ من المجموعات وتصور نتائج النموذج لكل مجموعة. سيكون للمخطّط نقطة انعطافٍ تشبه المرفق، ونحن فقط نختار عدد العناقيد عند هذه النقطة.
لنقم بتشغيل الأسطر التّالية من التعليمات البرمجية لإنشاء خوارزمية تجميع K-Means من 2 إلى 10 مجموعات
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCost
باستخدام التّعليمات البرمجيّة المذكورة أعلاه، نجحنا في بناء وتقييم نموذج تجميع K-Means الذي يتكون من 2 إلى 10 مجموعات. تم وضع النتائج في مصفوفة، ويمكن الآن تصورها في مخطّطٍ خطّيٍ:
والشكل (10) يوضح تطبيق نموذج تجميع K-Means من 2 إلى 10 مجموعات
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()
- بناء نموذج التجميع K-Means
من المخطّط أعلاه، يمكننا أن نرى أن هناك نقطة انعطافٍ تشبه المرفق عند النقطة الرابعة. ونتيجة لهذا، سنشرع في بناء خوارزمية K-Means بأربع مجموعات:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)
- عمل التنبؤات
دعونا نستخدم النموذج الذي أنشأناه لتعيين مجموعاتٍ لكل عميل في مجموعة البيانات:
preds=KMeans_fit.transform(data_scale_output)<br><br>preds.show(5,0)<br>
هناك عمودَ “تنبؤ” في إطار البيانات هذا يخبرنا عن المجموعة التي ينتمي إليها كل معرفِ عميلٍ
الخطوة 6: تحليل العناقيد
الخطوة الأخيرة في هذا المثال العملي هي تحليل شرائح العملاء التي بنيناها للتّوّ.
قم بتشغيل سطور التعليمات البرمجية التالية لتصور الحداثة والتكرار والقيمة النقدية لكلّ معرفِ عميلٍ في إطار البيانات:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()
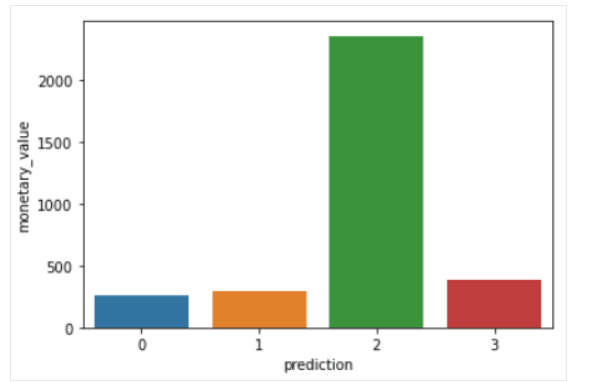
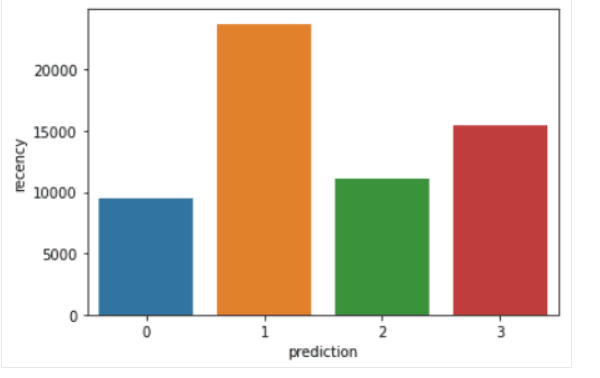
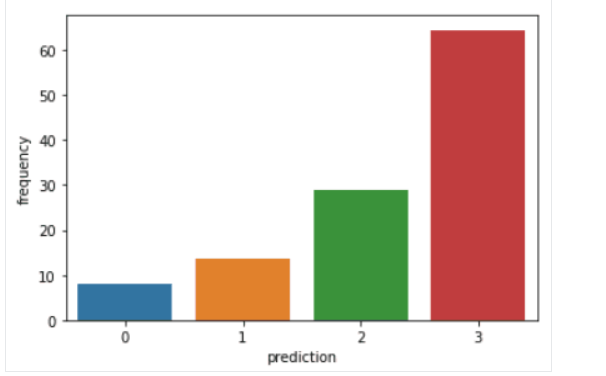
فيما يلي نظرةٌ عامةٌ على الخصائص التي يعرضها العملاء في كلّ مجموعةٍ:
- المجموعة 0: يُظهر العملاء في هذه الشريحة حداثةً وتكرارًا وقيمةً نقديةً منخفضة. نادرًا ما يتسوقون على المنصة وهم عملاء محتملون منخفضون ومن المرجح أن يتوقفوا عن التّعامل مع شركة التّجارة الإلكترونيّة.
- المجموعة 1: يُظهر المستخدمون في هذه المجموعة حداثةً عالية ولكن لم يتمّ رؤيتهم ينفقون الكثير على النظام الأساسي. كما أنهم لا يزورون الموقع كثيرًا. يشير هذا إلى أنهم قد يكونون عملاء جدد بدأوا للتّوّ التعامل مع الشركة.
- المجموعة 2: يظهر العملاء في هذه الشريحة حداثةً وتكرارًا متوسطين وينفقون الكثير من المال على المنصّة. ويشير هذا إلى أنهم يميلون إلى شراء سلعٍ ذات قيمةٍ عاليةٍ أو إجراء عمليات شراءٍ بالجملة.
- المجموعة 3: الجزء الأخير يضم المستخدمين الذين يظهرون حداثةً عاليةً ويقومون بعمليات شراءٍ متكررةٍ على المنصّة. ومع ذلك، فإنهم لا ينفقون الكثير على المنصة، مما قد يعني أنهم يميلون إلى اختيار عناصر أرخص في كلّ عمليّة شراءٍ.
والشكل (11) يوضح تقسيم العملاء حسب ال monetary value
أما الشكل (12) يوضح تقسيم العملاء حسب recency
والشكل (13) يوضح تقسيم العملاء حسب frequency
الخاتمة
تعرفنا في المقالة على أهميّة أباتشي سبارك في معالجة البيانات الضّخمة و أهميّة و سلاسة بيسبارك في التّعامل مع البيانات الضّخمة
باختصار، pyspark يوفر حلاً فعالًا وقويًا لتحليل ومعالجة البيانات الكبيرة، مما يساهم في تحسين أداء الشركات واتخاذ قرارات استراتيجية مستنيرة استنادًا إلى تحليل بيانات دقيق ,تعرفنا على خوارزميّة تقسيم العملاء RMF التي يمكن استخدامها في تقسيم العملاء عن طريق kmeans باستخدام pyspark من خلال تطبيق هذه الخوارزمية، يمكن للشركات تحسين استراتيجياتها التسويقية وتحسين خدماتها للعملاء. بالاعتماد على تحليل البيانات والتعلم الآلي، يمكن للشركات تحسين تجربة العملاء وزيادة رضاهم، مما يؤدي في النهاية إلى زيادة الإيرادات وتحسين الأداء العام للشركة.
المراجع
- pyspark-tutorial-getting-started-with-pyspark
- apache-spark-tutorial
- https://spark.apache.org/downloads.html




