
المقدمة Introduction
شهدت الرؤية الحاسوبيّة الكثير من التطوّرات في الآونة الأخيرة، وما زالت مشكلة اكتشاف الكائن object detection وتجزئة الصّورة Image Segmentation موضع تحدٍّ حتى الآن.
قد تحتاج في رحلة معالجتك للصّور الحصول على موقع كائن في صورة ما، ثمّ قد ترغب بتحديد حدوده وحجمه بدقّة أو تعيين نوعه وصنفه. للحقيقة، في الصّور الفعليّة قد يختلف حجم الكائن بشكل كبير، كما قد تختلف زاوية الجسم ووضعيّته من صورة إلى صورة، قد يكون هناك تداخل بين الأشياء والأجسام أيضاً، وهذا سيجعل عمليّة اكتشاف الهدف وتجزئته صعبة للغاية.
سوف نركّز اليوم على موضوع تجزئة الصّورة التي تتمثل بتصنيف كلّ بكسل إلى الصنف الخاصّ به.
المحتويات
- المقدمة Introduction
- أنواع تجزئة الصّورة Image Segmentation types
- استخدام شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN في تجزئة الصّور
- استخدام خوارزميّة غرابكت Grabcut في تجزئة الصّور
- تطبيقات عمليّة على دمج الشبكة العصبونية المناطقية ذات القناع Mask R-CNN و خوارزميّة غرابكت GrabCut معاً
- ما هي قاعِدُةُ بياناتِ مايكروسوفت كوكو MS-COCO
- خطوات التطبيق العملي Implementation
- مناقشة النّتائج Performance results
- الخاتمة Conclusion
- المراجع References
أنواع تجزئة الصّورة Image Segmentation types
على الرّغم من وجود أنواع عديدة لتجزئة الصّور، إلّا أنّ نوعي التجزئة السّائدين عندما يتعلق الأمر بمجال التعلّم العميق هما التجزئة الدّلالية Semantic Segmentation، وتجزئة المثيل Instance Segmentation سوف أوضّح الفرق بين النّوعين في مثالنا التالي:
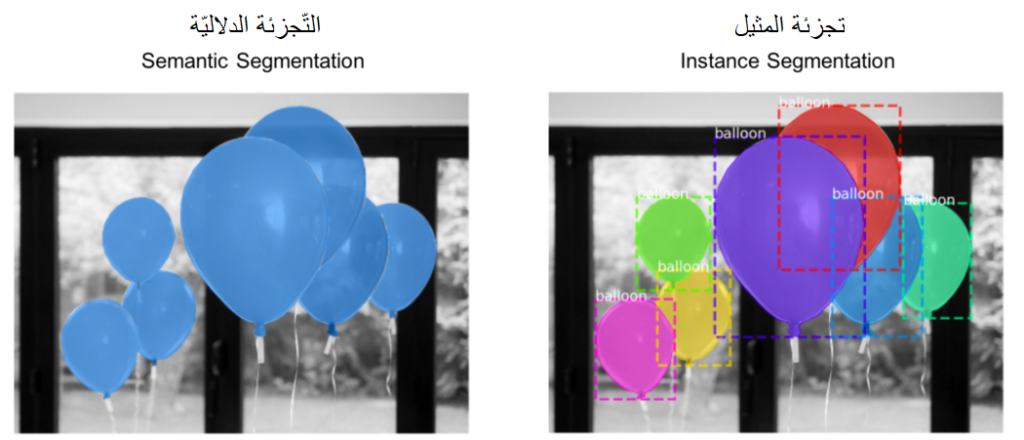
في التجزئة الدّلالية يتمّ تمثيل جميع وحدات البكسل التي تنتمي إلى فئة معيّنة بنفس اللّون، لاحظ أنّ جميع البالون لها اللّون ذاته بينما للخلفيّة لون آخر.
في تجزئة المثيل يتمّ تعيين فئة معيّنة لكلّ بكسل في الصّورة؛ أي يصبح لكلّ كائن لون خاصّ به وإن كانت الكائنات من نفس الفئة، لاحظ أنّ لكلّ بالون لوناً خاصاً به.
التّجزئة الدّلاليّة وتجزئة المثيل مجالان صغيران في التّجزئة المستهدفة، حيث يتمّ استخدامهما لتجزئة صورة الدّخل.
تشير التّجزئة المستهدفة في الحالات العامّة إلى التّجزئة الدّلالية التي لها تاريخ طويل في تجزئة الصّور وحققت تقدّمًا جيدًا، بينما مجال تجزئة المثيل تمّ تطويره فقط في السّنوات الأخيرة، و بمقارنته مع النّوع الأوّل فإنه أكثر تعقيدًا والباحثون الحاليّون قليلون في هذا الميدان [4].
يوجد العديد من خوارزميّات تجزئة الصّور المختلفة مثل خوارزميّة التّجزئة حسب المنطقة Region-based Segmentation، و خوارزميّة التّجزئة المعتمدة على كشف الحوافّ Edge Detection Segmentation، و خوارزميّة التجزئة المعتمدة على التّجمُّعات Image Segmentation based on Clustering وشَبكة الطَّيِّ العُصبونِيَّة المناطِقيَّة ذات القناع Mask R-CNN وGrabcut غرابكت وغيرها.
استخدام شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN في تجزئة الصّور
شبكة الطي العصبونية ذات القناع المناطقية Mask R-CNN هي شبكة تستخدم لتجزئة المثيل، يمكن استخدامها لإنجاز مجموعة متنوّعة من المهام، بما في ذلك التّصنيف، كشف الهدف، التجزئة الدّلالية، وتجزئة المثيل، والتّعرف على الأشياء، وما إلى ذلك. تتمتّع هذه الشبكة بقابليّة جيّدة للتوسّع وسهولة في الاستخدام كما تعتبر من أحدث ما توصلّت إليه تكنولوجيا تجزئة الصّور اليوم.
إنّ فكرة شَبَكَةُ الطَّيِّ العُصبُونِيَّةِ المناطِقيَّةِ ذاتُ القناع بسيطة، إذ أنّها نتجت عن إضافة خوارزمية التجزئة الدلالية الكلاسيكية (الشبكة العصبونيَّة كاملة الطَّيِّ FCN) إلى شَبَكَةُ الطَّيِّ العُصبُونِيَّةِ المناطِقيَّةِ الأسرع Faster-RCNN الأصليّة، لإنشاء فرع إضافيّ MASK يعطينا ميّزات و معلومات إضافيّة عن القناع المقترح.
تتألف شبكة Mask R-CNN من 3 أجزاء:
Faster R-CNN الشبكة العُصبُونِيَّةِ المناطِقيَّة الأسرع ومنطقة الاهتمام ROIAlign و الشبكة العصبونيَّة كاملة الطَّيِّ FCN، كما أنّها تعطي ثلاثة مخرجات لكلّ كائن موجود في الصّورة: فئته، إحداثيّات الصّندوق المحيط به، وقناع هذا الكائن. يمكننا توضيح تفاصيل هذه الشّبكة في مقالات لاحقة، تابع مدوّنتنا.
استخدام خوارزميّة غرابكت Grabcut في تجزئة الصّور
استُخدِمت خوارزميّة غرابكت GrabCut في عمليّات تجزئة المقدّمة في الكثير من التّطبيقات، وقد أعطت نتائج عالية الجودة مقارنةً مع طرق التجزئة التقليديّة السابقة [3]، نقترح الاستفادة من ميّزات هذه الخوارزميّة لتحسين التّجزئة وذلك باستخدام طريقة GrabCut with Mask (يمكنك مراجعة مقالنا على المدونة بعنوان خوارزمية استخراج وتجزئة المقدمة غرابكات GrabCut لمعرفة تفاصيل أكثر عن هذه الخوارزميّة).
سوف نستخدم طريقة تهيئة صورة الدّخل مع القناع المُقترح mask approximations.
تطبيقات عمليّة على دمج الشبكة العصبونية المناطقية ذات القناع Mask R-CNN و خوارزميّة غرابكت GrabCut معاً
سوف نستخدم شبكة Mask R-CNN المدرّبة مسبقاً للتنبّؤ بالكائنات الموجودة في الصورة، ثمّ سنقوم بتطبيق Grabcut لتحسين النتائج، و ذلك من خلال تحميل نموذج Mask R-CNN TensorFlow المدرّب مسبقًا على مجموعة بيانات MS-COCO، وتحميل أسماء الفئات والأوزان النّاتجة.
ما هي قاعِدُةُ بياناتِ مايكروسوفت كوكو MS-COCO
COCO عبارة عن مجموعة بيانات واسعة تستخدم لاكتشاف الكائنات و تقسيمها وتصنيفها، تحتوي على 328 ألف صورة وعدّة حالات لكلّ كائن في كلّ صورة، من هذه الكائنات (شخص، درّاجة، قطار، قارب، إشارة المرور، عصفور، قطّة، كلب، حصان، قبّعة، حقيبة ظهر، مظلّة، حذاء، نظارة طبيّة، طائرة ورقيّة، زجاجة، لوحة، كوب، سكّين، صحن، كرسيّ، باب، تلفاز، حاسوب محمول، لوحة المفاتيح، الهاتف الخلويّ، الكتاب، مقصّ، فرشاة الأسنان.. الخ).
خطوات التطبيق العملي Implementation
سوف نستخدم شبكة Mask R-CNN المدرّبة مسبقاً للتنبّؤ بكلّ الصّناديق المقترحة وكلّ أقنعة التجزئة المقترحة للكائنات في الصّورة، ثمّ سنقوم بتطبيق Grabcut على الأقنعة النّاتجة عن المرحلة السّابقة بغرض تحسينها.
- استيراد المكتبات اللازمة
import numpy as np
import cv2
import io
from google.colab import files
from matplotlib import pyplot as plt
- قراءة الملفّ الخاص بالشبكة المدرّبة مسبقاً mask_rcnn_inception_v2_coco_2018
mask_rcnn = "/content/mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"
file1 = open(mask_rcnn, "r")
- تحميل أسماء الأصناف لربطها مع لون خاصّ بها (من النموذج المدرّب مسبقاً) ثمّ عرضها.
classes_coco = "/content/object_detection_classes_coco.txt"
file1 = open(classes_coco, "r")
LABELS = open(classes_coco).read().strip().split("\n")
LABELS
- إنشاء مجموعة ألوان عشوائيّة لتمثيل كلّ فئة، ثمّ عرض القيم اللّونية.
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
COLORS
- تحميل نموذج Mask R-CNN المدرّب مسبقاً والمبنيّ بالاعتماد على مكتبة تنسورفلو للتَّعلُّمِ العميقِ من جوجل.
configPath = "/content/mask_rcnn_inception_v2_coco_2018_01_28.pbtxt"
config = open(configPath).read()
weightsPath = "/content/frozen_inference_graph.pb"
with open(weightsPath, 'rb') as w:
weights = w.read()
net = cv2.dnn.readNetFromTensorflow(weightsPath, configPath)
- تحميل الصّورة المراد تجزئتها وتعديل حجمها ثمّ عرضها.
image = cv2.imread("/content/exx.jpg")
dim = (600,375)
image = cv2.resize(image,dim,interpolation = cv2.INTER_AREA)
image.shape
plt.imshow(image)
plt.show()
- معالجة المدخلات عن طريق استدعاء الدالة blobFromImage من حزمة الشبكات العصبونية في المكتبةُ المفتوحةُ للرُّؤيةِ الحاسُوبيَّةِ opencv حيث نمرّر له الصّورة المدخلة ثمّ نقوم بعمليّات معالجة عليها مثل التوسع scaling وغيرها.
blob = cv2.dnn.blobFromImage(image, swapRB=True, crop=False)
- نقوم بتمرير ناتج الدالة السابقة إلى شبكتنا، للحصول على كلّ الصّناديق المحيطة بالكائنات وأقنعة التجزئة الخاصّة بها.
net.setInput(blob)
(boxes, masks) = net.forward(["detection_out_final",
"detection_masks"])
boxes.shape
- مرحلة إنشاء وتوليد أربع صور لتوضيح ناتج تجزئة Mask R-CNN وناتج الدّمج عبر تهيئة (Bounding box+Mask) و تكرار عمليّة الاكتشاف.
for i in range(0, boxes.shape[2]):
classID = int(boxes[0, 0, i, 1])
confidence = boxes[0, 0, i, 2]
if confidence > 0.5:
print("[INFO] showing output for '{}'...".format(
LABELS[classID]))
(H, W) = image.shape[:2]
box = boxes[0, 0, i, 3:7] * np.array([W, H, W, H])
(startX, startY, endX, endY) = box.astype("int")
boxW = endX - startX
boxH = endY - startY
mask = masks[i, classID]
mask = cv2.resize(mask, (boxW, boxH),interpolation=cv2.INTER_CUBIC)
mask = (mask > 0.3).astype("uint8") * 255
plt.imshow(mask)
plt.show()
rcnnMask = np.zeros(image.shape[:2], dtype="uint8")
rcnnMask[startY:endY, startX:endX] = mask
rcnnOutput = cv2.bitwise_and(image, image, mask=rcnnMask)
plt.imshow(rcnnMask)
plt.show()
plt.imshow(rcnnOutput)
plt.show()
gcMask = rcnnMask.copy()
gcMask[gcMask > 0] = cv2.GC_PR_FGD
gcMask[gcMask == 0] = cv2.GC_BGD
print("[INFO] applying GrabCut to '{}' ROI...".format(LABELS[classID]))
fgModel = np.zeros((1, 65), dtype="float")
bgModel = np.zeros((1, 65), dtype="float")
(gcMask, bgModel, fgModel) = cv2.grabCut(image, gcMask,
None, bgModel, fgModel, iterCount=10,
mode=cv2.GC_INIT_WITH_MASK)
outputMask = np.where((gcMask == cv2.GC_BGD) | (gcMask == cv2.GC_PR_BGD), 0, 1)
outputMask = (outputMask * 255).astype("uint8")
output = cv2.bitwise_and(image, image, mask=outputMask)
plt.imshow(outputMask)
plt.show()
plt.imshow(output)
plt.show()
ملاحظة:
الثقة confidence : قيمة احتماليّة تُستخدم لتصفية اكتشافات الأجسام الضّعيفة (هنا افتراضيّا يتمّ تعيين هذه القيمة إلى 50٪).
العتبة Threshold : يمكنك ضبط هذه القيمة للتحكّم في الحدّ الأدنى لتجزئة قناع البكسل.
الدورة iter : عدد مرات تكرار GrabCut المطلوب تنفيذها، يؤدّي المزيد من التّكرارات إلى وقت تشغيل أطول.
مناقشة النّتائج Performance results
تطبيق 1:
لدينا الصّورة المُدخلة التالية

ينتج عن تطبيق الطّريقة السّابقة تقسيم الكائنات في الصّورة [1]، وعرض أربع صور لكلّ كائن تتمثل بـ:
| rcnnMask | القناع النّاتج عن تطبيق Mask R-CNN |
| rcnnOutput | الخرج (الصورة) النّاتجة عن تطبيق القناع السّابق. |
| outputMask | تطبيق GrabCut على قناع Mask R-CNN والحصول على القناع المُحسّن. |
| output | الخرج النّاتج عن تطبيق القناع المُحسّن (القناع الناتج عن تطبيق الخوارزميتين). |
سوف نقوم بمناقشة كلّ كائن والتمييز بين حالات التجزئة باستخدام شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN فقط و باستخدام شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN و غرابكت GrabCut معاً.
- الحصان:

تظهر لدينا أربع صور (قناع Mask R-CNN – الخرج بعد تطبيق القناع السّابق – قناع GrabCut المحسّن مع Mask R-CNN – الخرج بعد تطبيق القناع المحسّن على الحصان)
نلاحظ أنّ النّتائج غير مثالية عند تطبيق Mask R-CNN فقط حيث تسرّبت الخلفيّة مع الحصان، و لكنها تبقى أفضل من النّتائج التي حصلنا عليها عند تطبيقها مع Grabcut حيث تمّ استبعاد أجزاء كبيرة من جسم الحصان وبالتالي النّتائج أصبحت أسوأ.
- الشخص القريب (فوق الحصان)

نلاحظ أنّ النّتائج غير مثاليّة عند تطبيق Mask R-CNN حيث تسرّب جزء من الخلفيّة مع الشخص، بينما عند الدّمج مع Grabcut تمت عمليّة التجزئة بنجاح ومع ذلك فإنّ شعر الرّأس (تطابق لونه مع الخلفيّة مما أدّى إلى عزله)؛ أي توجد نسبة خطأ ولكنّها صغيرة وأفضل من القناع السّابق.
- السّيارة

نلاحظ أنّ نتائج Mask R-CNN وحدها أفضل حيث أننا خسرنا جزءاً كبيراً من السّيارة عند استخدام Grabcut معها، وبالتالي من أجل هذا الكائن قناع Mask R-CNN أفضل.
- الشّخص البعيد
نلاحظ أنّ النّتائج غير مثاليّة عند تطبيق Mask R-CNN حيث تسرّب جزء من الخلفيّة مع الشخص، بينما عند تطبيق Grabcut تمّت عملية التجزئة بنجاح.

- الكلب:

نلاحظ هنا أنّ الطّريقتين غير جيّدتين، عند استخدام Mask R-CNN تسرّب الكثير من الخلفيّة مع الكائن، وعند استخدام غرابكت GrabCut فقدنا الكثير من جسم الكائن.
تطبيق 2:
لدينا الصّورة المدخلة التالية

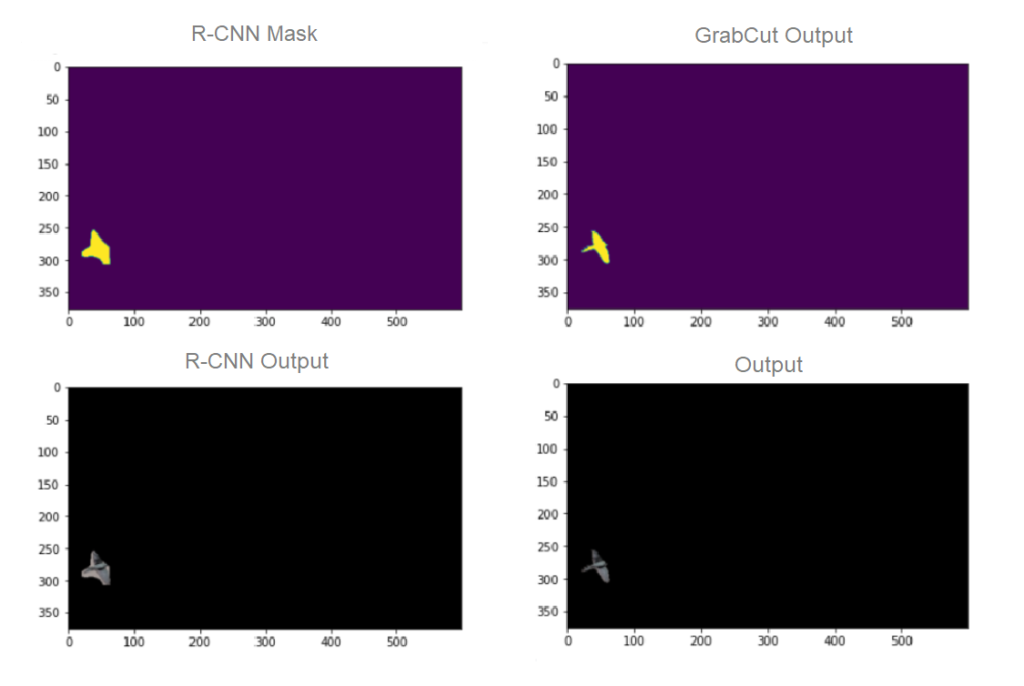
تحتوي هذه الصّورة على مجموعة من الطيور (كائنات من نفس النوع)، عند تطبيق الطّريقة السّابقة عليها تظهر لنا أربع صور:
- قناع Mask R-CNN
- الخرج بعد تطبيق القناع السّابق
- قناع غرابكت GrabCut المحسّن عن Mask R-CNN
- الخرج بعد تطبيق القناع المحسّن على الطير
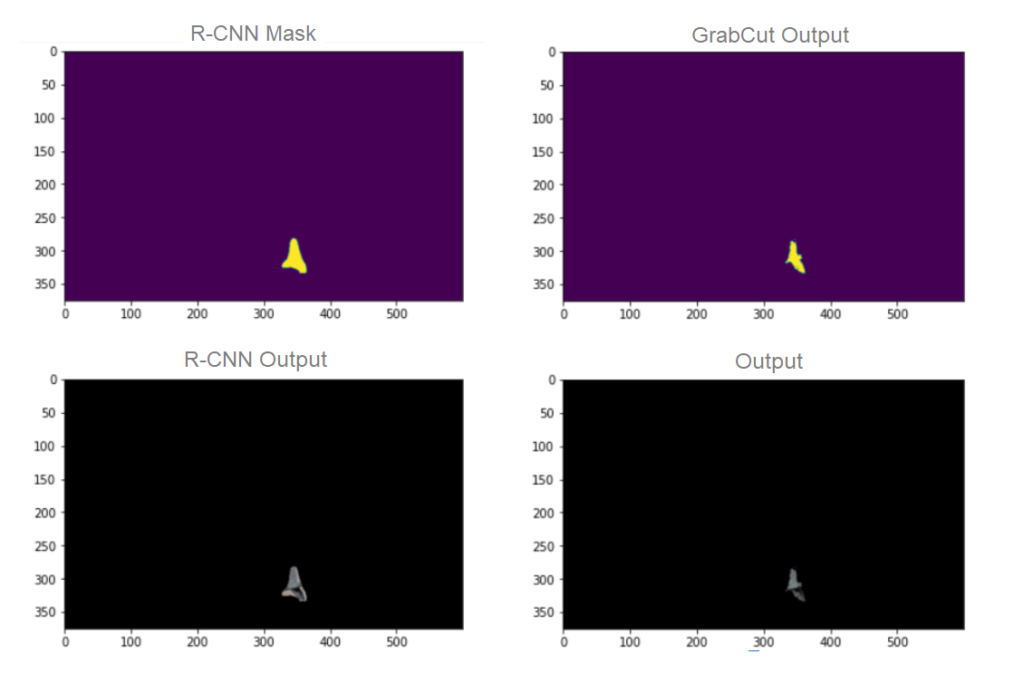
نلاحظ أنّ النتائج غير مثاليّة عند تطبيق Mask R-CNN حيث تسرّب جزء من الخلفيّة مع الطائر، بينما عند تطبيق الشبكة مع غرابكت Grabcut تمّت عمليّة التجزئة بنجاح.
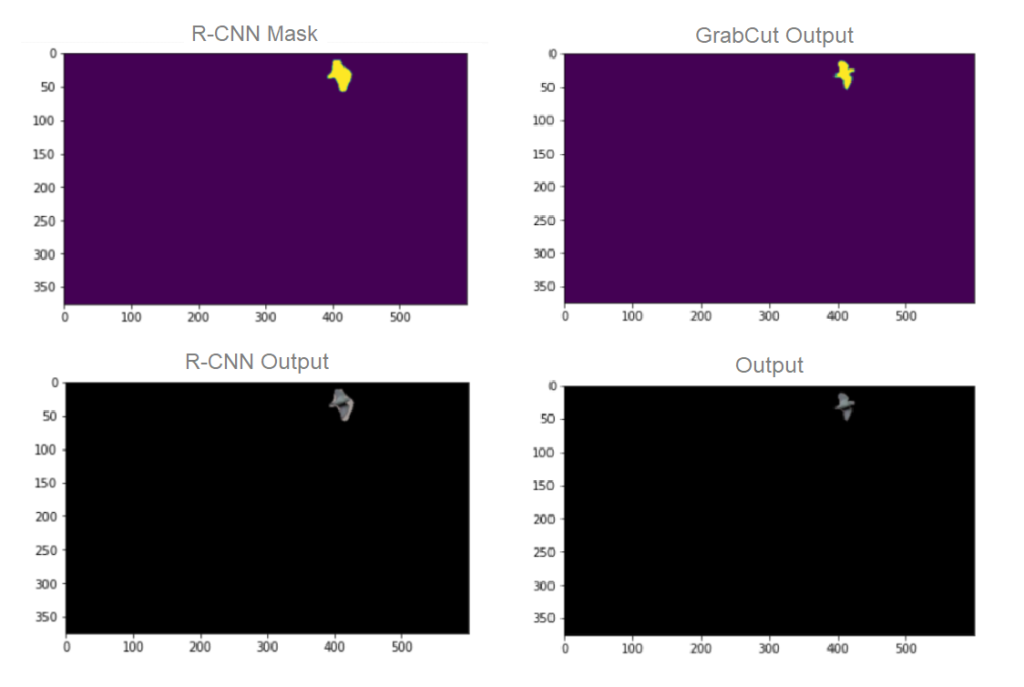
نلاحظ أنّه تمّ تقسيم العناصر ذات الصّنف الواحد بدقّة وأعطت نتائج أفضل عند دمج الطّريقتين.
عزيزي القارئ بإمكانك متابعة كامل الشفرة البرمجيةCode في مستودع المدونة على الغيت هب
الخاتمة Conclusion
قبل استخدام التعلّم العميق deep learning وشبكات التجزئة الدّلالية مثل Mask R-CNN و U-Net وغيرها، كانت خوارزميّة GrabCut هي الطّريقة المستخدمة لتجزئة مقدّمة الصّورة بدقّة عن الخلفيّة، ولكن في الواقع على الرّغم من أنّ شبكات التجزئة الدّلالية تعتبر طرقاً قوية للغاية، إلا أنّه يمكن أن ينتج عنها أقنعة فوضويّة بعض الشيء.
يمكننا استخدام GrabCut لتحسين و تنظيف هذه الأقنعة والاستفادة من دمج الطّرق السابقة معاً للحصول على نتائج أفضل. سيكون هناك بالتّأكيد نتائج مختلطة عند تطبيق المُقترح على مشاريع من نوع آخر، قد تكون هذه النّتائج إيجابيّة وقد تكون سلبيّة ولكن ليس لدينا إلا إجراء المزيد من التّجارب للتّحقق من ذلك.
نلاحظ من الدّراسة السّابقة أنّ تطبيق غرابكت Grabcut مع Mask R-CNN قد يجعل النّتائج أسوأ في أغلب الأحيان، وعلى الرّغم من أنّ هذا صحيح إلا أنّ بعض الحالات حصلت على نتائج أفضل بشكل فعّال.
لقد استخدمنا في البداية صورة معقّدة لتوضيح قيود هذه الطّريقة، قد نحصل على نتائج أفضل عند استخدام صور أقلّ تعقيداً كما في صورة الطيور.
من الأمثلة الرّائعة على الطّريقة المقترحة تجزئة الملابس (في محرّكات البحث الخاصّة بالموضة)، عندها تستطيع Mask R-CNN التنبّؤ بموقع وقناع كلّ قطعة من الملابس ثمّ نستطيع تحسين القناع باستخدام Grabcut وإجراء تجربة لعرض الملابس بطريقة أروع [1].
في هذا المقال تعرّفنا على نتائج دمج Mask R-CNN و GrabCut لتحسين تجزئة الكائنات في صورة معقّدة وأخرى بسيطة، تحدَثنا عن آليّة العمل و استعرضنا النّتائج الخاصّة بالطّريقة المقترحة وتوصلنا إلى أن محتوى الصورة وطبيعتها يعتبران عاملان أساسيان في تحديد طريقة التجزئة الأفضل لها.





تعليق واحد