
المحتويات
مقدمة
زاد استخدام تقنية التعرُّف على الوجه بقوة خلال الفترة الماضية من قبل الكثير من الدول في مجالات عديدة ، فأصبحت هذه التقنية الأداة الأكثر أماناً على مستوى الدول أو المؤسسات أو على المستوى الشخصي حيث تُعتبر هذه التقنية من الأنظمة الحديثة لتحديد هوية الأشخاص في الصور الرقمية أو إطار الفيديو وهناك طرق متعددة لعمل هذه الأنظمة ، ولكنها تتمثل بشكل عام بالخوارزمية التالية :
- إلقاء نظرة على الصورة وتحديد مواقع الأشخاص بداخلها .
- التركيز على كل وجه والقدرة على التعرُّف عليه مع اختلاف درجة دورانه أو درجة الإضاءة .
- اكتشاف السمات الخاصة بكل وجه مثلاً أن يحتوي الوجه على عيون صغيرة أو كبيرة، أنف كبير أو صغير وذلك لكي يتم تفريقه عن الآخرين.
- مقارنة السمات الخاصة بكل وجه مع مجموعة من الصور المخزّنة تعرف بقاعدة البيانات وذلك لكي يتم التعرُّف على اسم الشخص .
نلاحظ أن خطوات هذه الخوارزمية تشبه الى حدٍ ما الخطوات التي يستخدمها الإنسان في التعرُّف على شخص معين ولكن الإنسان يستطيع القيام بذلك بكل سهولة لأنه معتاد على رؤية الأشخاص يومياً مقارنةً مع الحاسوب لذلك يجب تعليمه خطوة بخطوة بشكل منفصل ليقوم بهذه المهمة .
استخدامات تقنية التعرُّف على الوجوه
- الحماية الأمنية : تستخدم الكثير من الدول أنظمة التعرُّف على الوجه لأغراض أمنية أهمها الكشف عن المجرمين ، فمثلاً تستخدم الولايات المتحدة نظام “US- VISIT ” لمنع دخول الأشخاص غير المرغوب بهم في أراضيها عن طريق مسح بصمات الأصابع ومطابقة الصورة الشخصية للزائر بقاعدة بيانات تحتوي على عدد كبير من صور المجرمين. تم وضع هذا النظام في 2004 وفي ذلك الوقت تمت معالجة أكثر من 16 مليون زائر للولايات المتحدة، وحينها اعتُقِل 370 شخصاً بتهمة ارتكاب جرائم من خلال هذا النظام .
- الحماية الشخصية : أغلب شركات الهواتف النقالة أصبحت تستخدم نظام التعرُّف على الوجه في حماية الهاتف ، ومن أشهرهم شركة Apple Face ID ،فبدلاً من استخدام كلمة مرور أو بصمة الإصبع لفتح قفل الشاشة أصبح بمجرد أن توجّه وجهك لكاميرا الهاتف الخاص بك تتم عملية المقارنة مع الصورة المحفوظة مسبقاً على الهاتف ، و بالاعتماد على نتيجة المصادقة يتم فتح القفل أو عدم فتحه.
- الإعلانات الموجهة : تعتمد أغلب الشركات على تقنية التعرُّف على الوجه في توجيه اعلانات مناسبة لمستخدميها ،فمثلا فيسبوك تستخدم هذه التقنية من أجل القيام بعملية دراسة كاملة لمستخدميها من حيث شكل الجسم و تسريحة الشعر والملابس التي يرتدونها وعلى أساس هذه الدراسة يتم اقتراح اعلانات للمستخدمين المحتمَلين لشراء منتج معين .
- التسوق الإلكتروني : تستخدم العديد من المواقع مثل ebay التسوق من خلال التقاط صورة للمنتج الذي ترغب في الحصول عليه ومن خلال التقنية السابقة يتم عرض لائحة من المنتجات المشابهة للصورة الملتقطة سواء هذه الصورة تم التقاطها حديثاً او كانت مخزنة مسبقاً على ذاكرة الموبايل الخاص بك .
- معرفة الحضور : يمكن استخدام تطبيق التعرُّف على الوجه لمعرفة عدد مرات الحضور والغياب لطلاب كلية معينة وذلك من خلال التقاط صورة جماعية للأشخاص الموجودين في القاعة ومن خلال تطبيق هذه التقنية على هذه الصورة تُمكّن الدكتور من الحصول على دراسة شاملة لوضع الطالب خلال الفصل بشكل كامل بدون اي تدخل أو جهد شخصي .
المبدأ العام لعمل خوارزمية التعرُّف على الوجوه :
1- تحديد أماكن الوجوه
تم الإهتمام بعملية اكتشاف الوجوه في عام 2000 و ظهرت العديد من الخوارزميات و الطرق للقيام بذلك ومن أشهرها خوارزمية مخطط التدرج الموجَه Histogram Of Oriented Gradient) HOG) التي تم اختراعها في عام 2005 ومازالت تحقق المرونة العالية في عملية اكتشاف الوجوه .
تتمثل خوارزمية مخطط التَدرج الموجه بالخطوات التالية :
- ليكن لدينا صورة الممثل الأمريكي ويل فيريل كصورة دخل .

- تحويل الصورة الملونة الى صورة رمادية. لأن الصورة الملونة تتكون من ثلاث مركبات لونية (RGB) بالتالي عملية اكتشاف الوجه في صورة ملونة تصبح أكثر تعقيداً وتأخذ زمناً أكبر مقارنة مع الصورة الرمادية التي تتكون من مركبة لونية واحدة لذلك تتطلب الخوارزمية تحويل الصور الى صور رمادية .

- المرور على كل بكسل من بكسلات الصورة بالإضافة الى البكسلات المجاورة له ( اي البكسلات التي تقع في الأعلى – الأسفل – يسار – يمين – أعلى اليمين – أعلى اليسار – وأسفل اليمين – وأسفل اليسار ).

الشكل 3 : معرفة البكسلات المجاورة لكل بكسل
- تحديد ما هو البكسل الغامق المجاور مباشرةً لبكسل فاتح وبعدها نرسم سهم باتجاه التغيّر من البكسل الفاتح الى البكسل الغامق .

نكرر الخطوة السابقة من أجل كل بكسل من بكسلات الصورة بالتالي تكون النتيجة النهائية استبدال كل قيمة بكسل في الصورة بسهم يعبر عن اتجاه التَغيّر من اللون الفاتح الى اللون الغامق ،والغاية من ذلك، أنه بفرض لدينا صورة تم التقاطها في الصباح لشخص ما وصورة أخرى تم التقاطها في المساء لنفس الشخص بالتالي نلاحظ أن قيم البكسلات للصورة الأولى هي عالية أي تقترب من 255 (لأن الإضاءة عالية) وقيم البكسلات في الصورة الثانية هي منخفضة وتكاد تقترب من الصفر (لأن الإضاءة منخفضة ) بالتالي سوف يعتبر الحاسوب أن الشخص الموجود في الصورة الأولى هو شخص مختلف عن الموجود في الصورة الثانية وهذا خاطئ منطقياً ،أما في حالة استخدام الأسهم، عندها فإن الصورتين سيكون لديهما اتجاهات التغيّر ذاتها أي أن ملامح الشخص الموجود في الصورة الأولى هي نفسها في الصورة الثانية .

- يتم تقسيم الصورة الى مربعات بحجم n * n حيث قيمة n تتعلق بالكائن المُراد اكتشافه ( الهيكل الرئيسي للوجه أو الهيكل الرئيسي للجسم ) بالتالي إذا كان المطلوب اكتشاف الوجه فقط عندها القيمة المثالية ل n تساوي 8 أو 16 ,أما إذا كان المطلوب اكتشاف الجسم عندها القيمة المثالية ل n هي 80 بعد ذلك يتم استبدال جميع الأسهم في كل مربع بسهم واحد فقط يشير الى أكبر عدد من الأسهم في نفس الإتجاه . هذه العملية تسمح لنا بتخزين البيانات المهمة التي تعبر عن الحواف المهمة مثل العين – الأنف – الفم التي تساعدنا في عملية اكتشاف الوجه بسرعة أكبر والاستغناء عن البيانات غير المهمة أي الكائنات الإضافية الموجودة في خلفية الصورة مثل سيارة – شجرة – اشارة مرور.
لنقُم بعملية توضيح بسيطة بمثال عملي لهذه الخطوة :
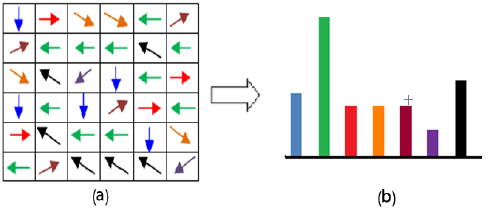
بفرض لدينا صورة وتم تقسيمها الى مربعات بحجم 7 * 7 وكان لدينا أحد المربعات هو المربع a ،إذا قُمنا بعملية تحليل لهذا المربع نجد أن النسبة الأكبر من الأسهم تتجه من اليمين الى اليسار أي الأسهم التي باللون الأخضر( وهذا مايوضحه المدرج التكراري b )بالتالي يوجد لدينا بيانات مهمة تم اكتشافها في الوجه ربما انف – عين – حاجب بالتالي يتم استبدال جميع الأسهم في المربع a بسهم واحد فقط يتجه من اليمين إلى اليسار .
- في النهاية قُمنا بتحويل الصورة المدخلة الى صورة ممثلة بطريقة مخطط التَدرج الموجه

- من أجل تحديد أماكن الوجه في الصورة الناتجة من الخطوة السابقة يتم تدريب الحاسوب على صور ممثلة بخوارزمية مخطط التَدرج الموجه بحيث تحتوي فقط معالم الوجه الرئيسية مثل العين – الحاجب – الفم – الأنف. بعد تكرار عملية التدريب على آلاف الصور يصبح الحاسوب قادراً على تحديد أماكن الوجه في الصور المُتمثلة بخوارزمية مخطط التَدرج الموجه .
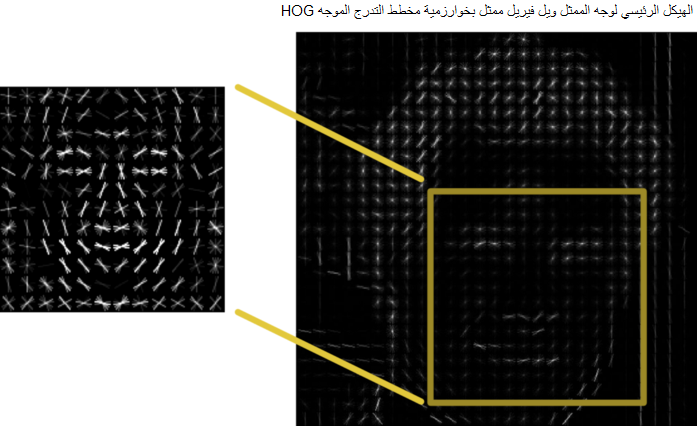
- في هذه الطريقة قُمنا بتحويل الصورة المدخلة الى شكل يمكننا من خلاله تحديد أماكن الوجه بشكل سريع ومبسط .

2- أوضاع الوجوه
تُعتبر عملية التعرُّف على الوجوه في حالة دورانها بزاوية معينة عملية بسيطة وسهلة بالنسبة للإنسان مقارنةً بالحاسوب فمثلاً اذا كان لدينا صورة تحتوي على وجه شخص ما وكانت وضعية الوجه ملتفة بزاوية 45 فعند تطبيق خوارزمية التعرُّف على الوجوه علىهذه الصورة تكون نتيجتها “غير معروف” مع العلم أن صورة الشخص موجودة في قاعدة البيانات. تم اقتراح خوارزمية لحل هذه المشكلة في عام 2014 من قبل فهد كاظمي “Vahid Kazemi ” و جوسفين “Joesphine ” تسمى خوارزمية تقدير معالم الوجه Face Landmarks Estimation.


مبدأ عمل خوارزمية تقدير معالم الوجه :
- تعمل هذه الخوارزمية على إيجاد 68 نقطة مهمة في الوجه،تسمى هذه النقاط بالنقاط الفاصلة Landmarks وتتواجد أعلى الدقن – الحافة الخارجية للعين – الحافة الداخلية للعين – الحاجب – حول الفم – حول الأنف . يتم إيجاد هذه النقاط من خلال تدريب خوارزمية تعلّم آلة .

- تطبيق خوارزمية تقدير معالم الوجه على الصورة الناتجة من الخطوة 1 (قبل حل مشكلة دوران الوجه ) :

- تطبيق عملية الدوران على ناتج الخطوة السابقة حتى نجعل كلاً من العيون الفم موجودين في وسط الصورة .
- الناتج النهائي بعد تنفيذ الخطوة السابقة :
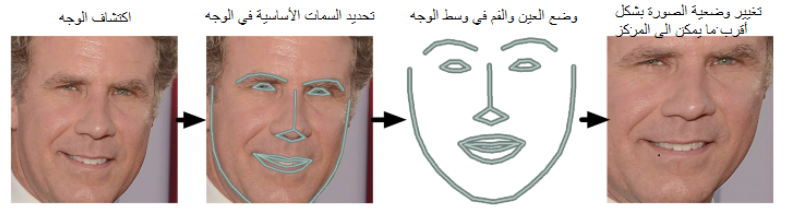
- نلاحظ انه مهما كان وضعية الوجه في الصورة يمكننا ازاحة الفم والعيون الى الوسط وهذه العملية تساعدنا في الحصول على نتائج دقيقة في التعرُّف على الشخص .
3-التعرُّف على الوجوه
الطريقة الأبسط للقيام بهذه العملية هي مقارنة الصورة التي تم الحصول عليها في الخطوة 2 مع جميع الصور الموجودة في قاعدة البيانات ولكن من الممكن أن تحتوي قاعدة البيانات على آلاف الصور بالتالي ستأخذ عملية المقارنة زمناً كبيراً. تم اقتراح حل لهذه المشكلة في عام 2015 من قبل باحثي غوغل تتمثل بالخطوات التالية :
- تحضير عينات التدريب بحيث تتضمن كل عينة تدريب مايلي :
- صورة لشخص معروف ( ولتكن صورة الممثل ويل فيريل ).
- صورة أخرى لنفس الشخص (صورة أخرى للممثل ويل فيريل ).
- صورة أخرى لشخص مختلف ( ولتكن صورة الممثل جاد سميث ) .
- بناء وتدريب شبكة الطّي العصبونية على الكثير من صور الوجوه مهمتها استخراج شعاع مكون من 128 بُعد لكل وجه ويسمى بشعاع التضمين Embedding،الفائدة منه اختزال الصورة ببياناتها الكبيرة الى بعض الأرقام القليلة بالتالي بدلاً من مقارنة الصورة بشكل كامل مع الصور الموجودة في قاعدة البيانات ،يتم مقارنة شعاع التضمين لصورة الوجه المُدخلة مع أشعة التضمين الخاصة بكل صورة من صُور الوجوه الموجودة في قاعدة البيانات .

- تبدأ الخوارزمية عملها في التعرُّف على أفضل الأبعاد والتي من خلالها يمكن التعرُّف على تلك الصور بحيث تقوم الشبكة بضبط أوزانها تلقائياً حتى تتعرف على أفضل الأبعادالتي تجعل صورتي نفس الشخص متشابهتين بدرجة كبيرة مع وجود اختلاف كبير بينهما وبين الصورة الثالثة .
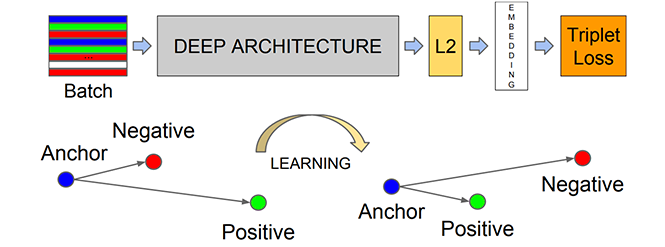
- بتكرار الخطوة الأخيرة ملايين المرات على آلاف الصور المختلفة تتعلمالشبكة تلقائياً أفضل 128 بُعد لكل صورة وجه .
ملاحظة : عملية تدريب شبكة عصبونية لإستخراج أشعة التضمين قد يستغرق وقتاً طويلاً قد يصل إلى 24 ساعة للحصول على نتائج دقيقة ولكن بمجرد تدريب الشبكة ستُنتج الأبعاد لأي وجه وإن لم تراه مسبقا في بيانات التدريب بسرعة عالية.في مشروعنا سوف نعتمد على نموذج /شبكة عصبونية تم تدريبه مسبقاً للقيام بهذه المهمة.
ملاحظة : قبل البدء بتنفيذ المشروع يتم ايجاد أشعة التضمين لجميع صور الأشخاص الموجودة في قاعدة البيانات ويتم وضعها في ملف خاص يتم تحميله أثناء تنفيذ المشروع .
4- الحصول على اسم الشخص
يتم معرفة اسم الشخص من خلال تدريب مصنف آلة متّجه الدعم Support Vector Machine مهمته التعرُّف على الشخص من خلال إيجاد شعاع التضمين الأقرب للصورة المُدخلة من بين أشعة التضمين الخاصة بصور الوجوه الموجودة في قاعدة البيانات ،تحدث هذه العملية بسرعة كبيرة بأقل من 1 ثانية .

التطبيق العملي
تتوضح خطوات بناء نموذج التعرُّف على الوجوه كالتالي :
- الخطوة الأولى : استخراج شعاع التضمين من أجل كل وجه موجود في مجموعة البيانات.
- الخطوة الثانية : تدريب نموذج تعلّم الآلة للتعرف على الوجه.
- الخطوة الثالثة : تطبيق نموذج التعرُّف على الوجه باستخدام المكتبة المفتوحة للرؤية الحاسوبية OpenCV.
في البداية سوف نستعرض هيكل مشروعنا :
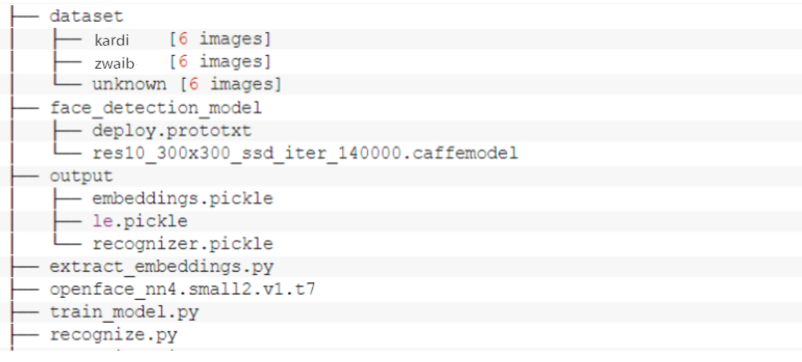
مشروعنا هذا كما نرى يتضمن 3 مجلدات و 4 ملفات
أولا – لنتحدث عن مجلدات المشروع :
- مجموعة البيانات dataset : من أجل بناء نموذج يقوم بالتعرُّف على الأشخاص لابد من تضمين هذا النموذج بصور تحتوي على وجوه هؤلاء الاشخاص بالاضافة الى أسمائهم ، بالتالي يحتوي مجلد مجموعة البيانات على عدة مجلدات فرعية بحيث كل مجلد يُسمى باسم شخص معين ويحتوي بداخله على صور لوجه هذا الشخص.
- نموذج اكتشاف الوجه face_detection_model: يحتوي على نموذج كافيه Caffe المدرّب مسبقاً على اكتشاف الوجوه ،هذا النموذج يكتشف ويحدد موضع الوجه في الصورة.
- مجلد الخرج output : يحتوي هذا المجلد بداخله على مجموعة ملفات الخرج الخاصة بمشروعنا هذا ،وهي :
- تضمينات الوجوه embeddings.pickle : يتم استخراج شعاع التضمين من أجل كل وجه في مجموعة البيانات ويتم حفظ هذه التضمينات ضمن هذا الملف.
- مشفّر التسمية le.pickle : وهو ملف مشفّر التسمية label encoder ، فمن أجل كل اسم موجود ضمن مجموعة البيانات يتم إجراء تشفير لهذا الاسم وفي النهاية يتم الاحتفاظ بجميع الأسماء المشفّرة ضمن هذا الملف.
- نموذج التعرُّف على الوجه recognizer.pickle :نموج آلة متجه الدعم الخطي Linear Support Vector Machine الذي قمنا بتدريبه من أجل مجموعة البيانات الخاصة بنا، و يعتبر نموذج من نماذج تعلم الآلة وهو المسؤول فعلياً عن التعرُّف على الوجه.
ثانياً – ملفات المشروع :
- استخراج التضمينات extract_embeddings.py :هذا الملف يتضمن الخطوة الاولى من بناء نموذج التعرُّف على الوجوه ،وهو المسؤول عن استخراج متجهات 128-D التي تصف الوجوه الموجودة في مجموعة البيانات الخاصة بنا حيث يتم تمرير الوجه عبر شبكة عصبونية تقوم بتوليد متجه التضمين لهذا الوجه.
- نموذج التضمين openface_nn4.small2.v1.t7 : نموذج تورش Torch المسؤول عن إنتاج متجه تضمين 128-D يصف الوجه ،وهو نموذج تعلم عميق.
- تدريب النموذج train_model.py : يتضمن الخطوة الثانية من بناء نموذج التعرُّف على الوجه وفي هذه الخطوة سيتم تدريب نموذج آلة متجه الدعم الخطي على مجموعة البيانات الخاصة بنا.
- التعرُّف على الوجه recognize.py : وهو يمثل الخطوة الاخيرة ففي هذه الخطوة سنقوم بمعالجة الإطارات المتدفقة من الكاميرا واكتشاف جميع الوجوه الموجودة في الإطار ومن ثم استخراج متجهات التضمين للوجوه المكتشفة وبعد ذلك نقوم بالاستعلام عن هذه الوجوه باستخدام نموذج آلة متجه الدعم الخطي الخاص بنا لتحديد أسماء الأشخاص الموجودين في الإطار.
الآن بعد أن ألقينا نظرة عامة على هيكلية المشروع وتحدثنا بشكل مختصر عن خطوات تنفيذ المشروع سنقوم بتنفيذ هذه الخطوات باستخدام لغة البرمجة بايثون.
الخطوة الأولى – استخراج شعاع التضمين من أجل كل وجه موجود في مجموعة البيانات.
نفتح ملف extract_embeddings.py ونقوم بتنفيذ الشيفرة البرمجية.
في البداية نقوم باستدعاء المكتبات والتوابع التي سنتعامل معها
from imutils import paths
import numpy as np
import imutils
import pickle
import cv2
import os
إنّ المكتبةُ المفتوحةُ للرُّؤيةِ الحاسُوبيَّةِ cv2 هي مكتبة مفتوحة المصدر تضم مجموعة من التوابع البرمجية التي تهدف بشكل رئيسي إلى التعامل مع تطبيقات الرؤية الحاسوبية في الزمن الحقيقي .
نستخدم مكتبة imutils لتغير حجم الإطار.
أما المكتبة Pickle فنستخدمها من أجل إجراء تسلسل و إلغاء تسلسل لبنية كائن بايثون وسنتحدث عنها لاحقاً.
توفر لنا المكتبة os العديد من التوابع الضرورية للتفاعل مع نظام التشغيل.
وتوفر مكتبة numpy العديد من التوابع للتعامل مع المصفوفات.
نستخدم الوحدة الفرعية مسار paths من أجل الحصول على مسارات الصورة الموجودة ضمن مجموعة البيانات الخاصة بنا.
والآن دعونا نقوم بتهيئة المتحولات
dataset ='./dataset'
embeddings = './output/embeddings.pickle'
detector_path = './face_detection_model'
embedding_model ='./openface_nn4.small2.v1.t7'
Confidence = 0.5
- مُعامل مجموعة البيانات : يتضمن مسار مجموعة البيانات.
- مُعامل التضمينات : يتضمن مسار ملف تضمينات الوجه (ملف الخرج الذي تحدثنا عنه سابقاً).
- مسار الكاشف detector_path : يتضمن مسار نموذج كافيه.
- نموذج التضمين : يتضمن مسار نموذج تورش المستخدم في استخراج متجه تضمين الوجه.
- العتبة الاحتمالية Confidence :يتم ضبطها بشكل اختياري و بالاعتماد على هذه القيمة يتم التخلص من اكتشافات الوجوه الضعيفة أي التي تقل عن هذا الحد.
الآن بعد أن قمنا باستدعاء المكتبات الضرورية وهيّأنا نا المتحولات نقوم بتحميل نموذجي كافيه و تورش.
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([detector_path, "deploy.prototxt"])
modelPath = os.path.sep.join([detector_path,"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(embedding_model)
يمثل السطر15 تحميل نموذج كافيه
ويمثل السطر17 تحميل نموذج تورش
دعنا الآن نحصل على مسارات الصور الموجودة في مجموعة البيانات ونهيئ قائمتين الأولى هي قائمة التضمينات المعروفة knownEmbeddings والثانية هي قائمة الاسماء المعروفةKnownNames
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(dataset))
knownEmbeddings = []
knownNames = []
total = 0
في السطر 19 نحصل على جميع مسارات الصور الموجودة في مجموعة البيانات حيث أن مُعامل مسارات الصور imagePaths هو عبارة عن قائمة list تضم مسارات الصور (لاحظ مسارات الصور وليس الصور).
في السطر 20 نهيئ قائمة التضمينات المعروفة وهي قائمة خاصة بتضمينات الوجوه الموجودة في مجموعة البيانات.
في السطر21 نهيئ قائمة الاسماء المعروفة وهي قائمة خاصة بأسماء الأشخاص الموجودة في مجموعة البيانات.
في السطر 22 نهيئ المُعامل الإجمالي total وهو يمثل إجمالي عدد الوجوه التي تمت معالجتها (طبعا الوجوه الموجودة في مجموعة البيانات).
لنبدأ الآن بالحلقة التكرارية المستخدمة من أجل المرور على جميع مسارات الصور أي المرور على جميع القيم الموجودة في قائمة مسارات الصور ، ستقوم هذه الحلقة بالمرور على جميع الصور(الوجوه) الموجودة في مجموعة البيانات من أجل استخراج متجهات التضمينات لها.
for (i, imagePath) in enumerate(imagePaths):
print("[INFO] processing image {}/{}".format(i + 1,len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
في السطر 25 نستخرج اسم الشخص من المسار ، لشرح كيفية عمل ذلك تابع المثال التالي :

حيث so.path.sep تُرجِع محرف فاصل المسار المستخدم في نظام التشغيل فعلى سبيل المثال فاصل المسار في نظام التشغيل windows هو ‘\’ أما بالنسبة لنظام التشغيل Unix هو ‘ / ‘.
بالتالي باستخدام تابع التقسيم split نقسم المسار حسب محرف فاصل المسار ونحصل على قائمة بأسماء المجلدات/الملفات الموجودة في المسار ، وباستخدام التعليمة الاخيرة نحصل على اسم الشخص والذي هو في هذه الحالة ‘Mohammad’.
أخيراً نختم كتلة الكود أعلاه بتحميل الصورة وتغيير حجمها مع الاحتفاظ بأبعاد الصورة في المتحولين h و w ، كما في الأسطر 26-28.
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
detector.setInput(imageBlob)
detections = detector.forward()
نمرر الصورة الى التابع blobFromImage ومن خلال هذا التابع نستطيع تحديد عملية المعالجة المسبقة التي نريد تطبيقها على هذه الصورة قبل إدخالها إلى الشبكة العصبونية أي نموذج كافيه .
سنقوم بتوضيح المعاملين الثاني والرابع لهذا التابع اللذان يحددان المعالجة المسبقة :
بالنسبة للمعامل الثاني هو معامل التَّقييسُ scale factor وظيفة هذا المعامل تحجيم قيم بكسلات الإطار إلى نطاق معين ، أما بالنسبة للمعامل الرابع فهو متوسط الطرح Mean Subtraction.
نبدأ بشرح معامل متوسط الطرح : يستخدم هذا المعامل للمساعدة في معالجة تغيرات الإضاءة في الصور المدخلة , لذلك يمكن اعتباره تقنية تستخدم لمساعدة شبكات الطّي العصبونية ، ولاستخدام هذا المفهوم نقوم قبل البدء في تدريب الشبكة العصبونية بحساب متوسط كثافة البيكسل لكل طبقة (الحمراء والخضراء والزرقاء) لجميع الصور الموجودة في مجموعة البيانات dataset
هذا يعني أنه نحصل على ثلاثة قيم:
µR , µG , µB
عندما نمرر صورة عبر شبكة (سواء للتدريب أو الاختبار) ، فإننا نطرح المتوسط من كل قيم البيكسلات في الصورة المدخلة بالشكل التالي :
R = R – µR
G = G – µG
B = B – µB
مع تابع blobFromImage افترضنا أن متوسط قيم البيكسلات للطبقات الثلاثة هي (123.0 , 177.0 , 104.0) وذلك لأن نموذج كافيه هو نموذج مدرب مسبقاً على مجموعة بيانات تدريب ImageNet والقيم المتوسطة لهذه البيانات هي µR=104.0 و µG=177.0 و µB=123.0 بالتالي سوف نعتمد هذه القيم.
أما بالنسبة للمعامل Scale factor يتم استخدامه عندما نريد تطبيق عملية التَّقييسُ على قيم بيكسلات صورة لجعلها تنحصر ضمن مجال معين وفق المعادلات التالية :
R = (R – µR) / σ
G = (G – µG) / σ
B = (B – µB) / σ
كذلك افترضنا أن قيمة معامل التَّقييسُ في التابع blobFromImage هي 1.0 أي أننا لم نقم بعمل تقييسُ لقيم بكسلات الصورة وإنما اكتفينا بتطبيق متوسط الطرح فقط.
التابع setInput لتنفيذ المعالجة المسبقة على الصورة.
التابع forward للقيام بعملية تمرير للأمام للصورة عبر الشبكة العصبونية من أجل اكتشاف جميع الوجوه الموجودة فيها.
دعنا الآن نعالج الوجوه المُكتشفة في الشفرة البرمجية التالية:
# ensure at least one face was found
if len(detections) > 0:
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
if confidence > Confidence:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
if fW < 20 or fH < 20:
continue
التعليمة الشرطية في البداية للتأكد من وجود وجه واحد مكتشف على الأقل.
تحتوي قائمة الاكتشافات detections على الاحتمالات والاحداثيات لتحديد مواقع الوجوه على الصورة.
نحن نعلم أن كل صورة من مجموعة البيانات يجب أن تحتوي على وجه واحد فقط لذلك نستخرج مربع الاحاطة Bounding Box ذو قيمة الاحتمالية الاعلى أي الأكبر احتمالاً ، الأسطر37-38.
سنقوم بالتأكد من خلال تعليمة شرطية أن الاحتمال الأكبر هو أكبر من العتبة الاحتمالية التي يتم استخدامها لفلترة الاكتشافات الضعيفة ،بافتراض أن الاكتشاف استوفى الشرط السابق، بالتالي فإننا سوف نقتطع الوجه من الصورة (أي منطقة الأهتمام region of interest) ،ولا ننسى قبل الاقتطاع أن نضرب قيم إحداثيات مربع الإحاطة في طول وعرض الصورة الأصلية للحصول على الإحداثيات الصحيحة لمربع الإحاطة على الصورة وذلك لأن قيم إحداثيات مربع الإحاطة مطبق عليها تقييس Normalization أي مجال قيمها هو [0,1] ،ثم باستخدام تابع القصر astype نقصر قيم الإحداثيات الى نوع البيانات الصحيحة Integer وذلك من أجل التخلص من الفواصل العشرية ، الأسطر39-43.
في الأسطر تم التحقق من أن منطقة الأهتمام كبيرة بما يكفي أي أن أبعادها أكبر من 20×20 ، الأسطر44-45.
الآن من أجل استخراج تضمين الوجه سنقوم باستخدام نموذج التضمين تورش
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
knownNames.append(name)
knownEmbeddings.append(vec.flatten())
total += 1
بالنسبة للتابع blobFromImage فقط تحدثنا عنه سابقاً حيث نمرر له الوجه المقتطع من الصورة أي منطقة الاهتمام وبعد ذلك يتم تمرير الوجه المقتطع عبر أداة التضمين أي عبر شبكة طّي عصبونية لتوليد متجه التضمين D-128 الذي يصف الوجه ، الأسطر49-52.
ثم بعد ذلك نضيف تضمين الوجه إلى قائمة التضمينات المعروفة وكذلك الاسم المقابل للوجه إلى قائمة الأسماء المعروفة ، الأسطر53-54.
في النهاية نقوم بزيادة قيمة المُعامل الإجمالي بمقدار واحد ، السطر55.
وهكذا نواصل عملية استخراج تضمينات الوجوه من أجل كل صورة (وجه) موجودة في مجموعة البيانات الخاصة بنا .
الآن بعد أن ننتهي من استخراج التضمينات يجب أن نقوم بتخزينها حتى نستفيد منها لاحقاً
print("[INFO] serializing {} encodings...".format(total))
data = {"embeddings": knownEmbeddings, "names": knownNames}
f = open(embeddings, "wb")
f.write(pickle.dumps(data))
f.close()
حيث نقوم بإنشاء قاموس البيانات data وإضافة متجهات التضمين والأسماء إليه ،ثم نقوم بتخزين هذا القاموس في ملف خرج التضمينات بامتداد pickle.
ملاحظة : نستخدم مكتبة pickle لإجراء تسلسل أو إلغاء تسلسل لبنية كائن بايثون (قاموس ، قائمة ….) أي أنّ ما تفعله هذه المكتبة هوتحويل الكائن إلى سلسلة محارف قبل تخزينه على القرص ،الفكرة أن هذا التسلسل من المحارف يحتوي على جميع المعلومات اللازمة لإعادة بنائه في برنامج بايثون آخر.
الخطوة الثانية – تدريب نموذج تعلّم الآلة للتعرف على الوجه
في المرحلة السابقة قمنا باستخراج شعاع التضمين D-128 من أجل كل صورة (وجه) في مجموعة البيانات ولكن كيف يمكننا التعرُّف على شخص باستخدام هذه الاشعة ؟؟ الإجابة هي أن نقوم بتدريب نموذج تعلّم الآلة على مجموعة البيانات الخاصة بنا بحيث تكون مهمة هذا النموذج هي التعرُّف على الأشخاص. سنتحدث عن آلية التعرُّف بالخطوة الثالثة.
الآن افتح ملف train_model.py وتابع الشيفرة البرمجية التالية :
نقوم في البداية باستيراد المكتبات وتهيئة بعض المُعاملات
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import pickle
embeddings ='./output/embeddings.pickle'
recognizer_path = './output/recognizer.pickle'
le_path = './output/le.pickle'
سنحتاج إلى مكتبة التعلّم الآلي scikit learn التي توفر لنا تحقيق لنموذج آلة متجه الدعم ،أما بالنسبة للمعاملات فإنه لدينا :
- مُعامل التضمينات : يتضمن مسار ملف تضمينات الوجه (ملف الخرج الذي تحدثنا عنه سابقاً).
- مسار المعرّف recognizer : يتضمن المسار الذي سيتم فيه تخزين نموذج تعلم الآلة بعد تدريبه وهذا النموذج سيكون هو المسؤول عن التعرُّف على الأشخاص.
- مسار مشفّر التسمية le : وهو اختصار لـ label encoder أي ما سنفعله هو أننا سنقوم بتشفير التسميات (أي الأسماء) ثم إجراء تسلسل لمشفّر التسمية وتخزينه على القرص حتى نتمكن من استخدامه هو ونموذج تعلم الآلة في الخطوة الثالثة.
الآن دعنا نحمل ملف تضمينات الوجه ونقوم بعملية تشفير للتسميات
print("[INFO] loading face embeddings...")
data = pickle.loads(open(embeddings, "rb").read())
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
في السطر 9 قمنا بتحميل ملف تضمينات الوجه .
في الأسطر11-12 قمنا بتشفير التسميات باستخدام مكتبة تعلم الآلة.
الآن نقوم بتدريب نموذج آلة متجه الدعم
print("[INFO] training model...")
recognizer = SVC(C=1.0, kernel="linear", probability=True)
recognizer.fit(data["embeddings"], labels)
في السطر 14 نقوم بتهيئة نموذج آلة متجه الدعم SVM بالمعاملات المناسبة له.
في السطر 15 نقوم بتغذية النموذج بالدخل والخرج لكي يقوم بإجراء ملاءمة مناسبة على هذه البيانات والتدرب عليها.
لاحظ هنا أننا نستخدم نموذج آلة متجه الدعم ولكن بإمكانك تجريب نماذج تعلم آلة أخرى مثل خوارزمية أقرب جار KNN أو الغابة العشوائية Random Forest.
بعد القيام بعملية تدريب للنموذج نقوم بحفظه وكذلك أيضاً نقوم بحفظ مشفر التسمية
f = open(recognizer_path, "wb")
f.write(pickle.dumps(recognizer))
f.close()
f = open(le_path, "wb")
f.write(pickle.dumps(le))
f.close()
في الأسطر 16-18 قمنا بتخزين نموذج التعرُّف على الوجوه .
في الأسطر 19-21 قمنا بتخزين مشفّر التسمية.
الخطوة الثالثة – تطبيق نموذج التعرُّف على الوجوه باستخدام المكتبة المفتوحة للرؤية الحاسوبية OpenCV.
بعد أن قمنا بتدريب نموذج آلة متجه الدعم SVM أصبحنا قادرين على التعرُّف على الوجه باستخدام المكتبة المفتوحة للرؤية الحاسوبية.
ملخص ماذا سيحدث في هذه الخطوة :
- في البداية تتم قراءة الإطارات المتدفقة من الكاميرا.
- القيام بعملية معالجة لكل إطار واكتشاف جميع الوجوه الموجودة فيه باستخدام نموذج كافيه.
- استخراج متجه التضمين للوجه المكتشف باستخدام نموذج تورش.
- التعرُّف على الوجه ومعرفة تسميته (اسم الشخص) وذلك من خلال إيجاد شعاع التضمين الأقرب إلى شعاع تضمين الوجه المكتشف من بين أشعة التضمين الخاصة بصور الوجوه في قاعدة البيانات.
الآن نفتح ملف recognize.py وننفذ الشيفرة البرمجية الخاصة به
في البداية نقوم باستيراد المكتبات التي سنتعامل معها وتهيئة بعض المُعاملات
from imutils.video import VideoStream
import numpy as np
import imutils
import pickle
import time
import cv2
import os
detector_path = './face_detection_model'
embedding_model = './openface_nn4.small2.v1.t7'
recognizer_path = './output/recognizer.pickle'
le_path = './output/le.pickle'
Confidence = 0.5
تُستخدم مكتبة time من أجل إحداث تأخير زمني .
وتستخدم VideoStream من أجل الوصول الى الكاميرا .
بالنسبة للمُعاملات لدينا :
- مسار الكاشف: يتضمن مسار نموذج كافيه.
- نموذج التضمين : يتضمن مسار نموذج تورش المستخدم في استخراج متجه تضمين الوجه.
- مسار المعرّف : يتضمن مسار نموذج آلة متجه الدعم.
- مسار مشفّر التسمية : يتضمن مسار ملف مشفّر التسمية.
- العتبة الاحتمالية Confidence :يتم ضبطها بشكل اختياري ويتم استخدامها من أجل التخلص من اكتشافات الوجوه الضعيفة.
الآن نقوم بتحميل النماذج الثلاثة ومشفّر التسمية
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([detector_path, "deploy.prototxt"])
modelPath = os.path.sep.join([detector_path,
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(embedding_model)
recognizer = pickle.loads(open(recognizer_path, "rb").read())
le = pickle.loads(open(le_path, "rb").read())
في السطر 18 نقوم بتحميل نموذج كافيه.
في السطر 20 نقوم بتحميل نموذج تورش.
في السطر 21 نقوم بتحميل نموذج آلة متجه الدعم.
في السطر 22 نقوم بتحميل مشفّر التسمية.
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
نقوم بتشغيل تدفق الفيديو VideoStream وبدء عمل حساس الكاميرا , لكن نقوم بعمل تأخير زمني بمقدار 2 ثانية الى أن تجهز الكاميرا .
while True:
frame = vs.read()
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
detector.setInput(imageBlob)
detections = detector.forward()
تُستخدم الحلقة التكرارية while من أجل الوصول إلى إطارات الكاميرا والقيام بعملية المعالجة عليها بالزمن الحقيقي .
توضح الأسطر 27-29 قراءة إطار من الكاميرا ثم القيام بتغير حجم هذا الإطار إلى عرض ثابت مع الحفاظ على نسبة العرض إلى الطول aspect ratio و الاحتفاظ بطول وعرض الإطار في المتحولين h و w .
نمرر الإطار الملتقط من الكاميرا عبر نموذج كافيه لاكتشاف جميع الوجوه الموجودة في الإطار كما في الأسطر30-34.
# loop over the detections
for i in range(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > Confidence:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
if fW < 20 or fH < 20:
continue
يتم المرور على جميع تنبؤات نموذج كافيه المطبق على الإطار ، حيث يتم التخلص من التنبؤات الضعيفة التي تقل عن حد العتبة ، يتم ضرب قيم إحداثيات مربع الإحاطة في طول وعرض الإطار للحصول على الإحداثيات الصحيحة لمربع الإحاطة على الإطار ،ثم بعد ذلك يتم تحويل قيم الإحداثيات الى نوع البيانات الصحيحة Integer وذلك من أجل التخلص من الفواصل العشرية ، كما في الأسطر36-40.
يتم في الأسطر41-42 اقتطاع الوجه المكتشف من الإطار مع الاحتفاظ بطول وعرض الوجه في المتحولين fh و fw .
ثم يتم التأكد من أن طول وعرض الوجه كبيران بما يكفي كما في الأسطر43-44.
والآن إجراء عملية التعرُّف على الوجه المكتشف في الإطار
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
تبين الأسطر48-51 تمرير الوجه المكتشف عبر نموذج تورش من أجل استخراج شعاع التضمين لهذا الوجه
ثم توضح الأسطر52-55 التعرُّف على الوجه ومعرفة الاسم الأكثر احتمالاً للوجه
الآن سنقوم برسم مربع إحاطة حول الوجه ووضع التسمية عليه
# draw the bounding box of the face along with the
# associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
حيث يتم رسم مربع الإحاطة باستخدام تابع رسم المستطيل rectangle ووضع التسمية مع الاحتمال باستخدام تابع كتابة النص putText.
سنتحدث عن مُعاملات هذين التابعين :
أولاً – بالنسبة لتابع رسم المستطيل يستخدم هذا التابع لرسم مربع على الصورة حيث يقبل هذا التابع المُعاملات التالية :
- المُعامل الأول : الصورة المراد رسم مربع الإحاطة عليها.
- المُعامل الثاني والثالث : إحداثيات مربع الإحاطة ممثلة بالزاويتين العليا اليسارية والسفلى اليمنية .
- المُعامل الرابع : لون الخط المستخدم ,حيث تتعامل المكتبةُ المفتوحةُ للرُّؤيةِ الحاسُوبيَّةِ مع صور ملونة بترتيب الألوان BGR فعلى سبيل المثال نمرر القيمة (255,0,0) بالنسبة للّون الأزرق.
- المُعامل الأخير : سماكة الخط .
ثانياً – تابع كتابة النص يستخدم هذا التابع لكتابة نص على صورة وهنا نستخدم هذا التابع من أجل كتابة الاسم مع الاحتمال حيث يقبل هذا التابع المُعاملات التالية :
- المُعامل الأول : الصورة المراد الكتابة عليها .
- المُعامل الثاني : السلسلة النصية المراد كتابتها على الصورة.
- المُعامل الثالث :موضع النص بالنسبة للصورة (إحداثيات الزاوية السفلية اليسارية للنص).
- المُعامل الرابع : نوع الخط المستخدم.
- المُعامل الخامس : عامل مقياس الخط الذي يتم ضربه في حجم الخط الأساسي.
- المُعامل السادس : لون الخط .
- المُعامل السابع : سماكة الخط .
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
يوضح السطر 65 إظهار الإطار بعد إجراء عملية المعالجة عليه
بالنسبة للتابع waiyKey سنتحدث عنه قليلاً :
يعيد هذا التابع قيمة عددية 32 بت حيث البتات الثمانية أقصى اليسار تمثل القيمة العددية لرمز المفتاح المضغوط عليه بترميز ASCII لذلك نحن نهتم فقط بهذه البتات الثمانية ونريد أن تكون جميع البتات الاخرى صفر بالتالي للقيام بذلك نقوم بتطبيق عملية AND بين القيمة المعادة لتابع waitKey و العدد 0xFF .
العدد 0xFF هو بالنظام الست عشري Hexadecimal وبالتالي العدد المقابل له في النظام الثنائي هو 11111111 أي 8 بت فقط لذلك يتم استخدامه للحصول على أخر 8 بت .
القيمة المعادة من ( ord( char تمثل قيمة الترميز ASCII المقابلة للمحرف المرر char وبالتالي بالمقارنة مع هذا العدد يمكننا التحقق من وجود مفتاح مضغوط وكسر الحلقة.
ملاحظة : التابع waitKey يعمل فقط في حال إنشاء نافذة HighGUI واحدة على الأقل وإذا كانت نشطة .
وبالتالي التعليمة الشرطية في حال تم الضغط على مفتاح q على لوحة المفاتيح يتم الخروج من الحلقة while وإنهاء التنفيذ ،كما في الأسطر67-68.
cv2.destroyAllWindows()
vs.stop()
التابع destroyAllWindows لإغلاق جميع النوافذ التي تم إنشاؤها (حيث يتم إنشاء نافذة لعرض إطار الخرج الناتج عند استخدام التابع imshow).
التابع v.stop من أجل إيقاف عمل حساس الكاميرا.
عزيزي القارئ يمكنك الاطلاع على كامل الشيفرة البرمجية في مستودع الجيت هب الخاص بموقع الذكاء الاصطناعي باللغة العربية.
فيديو يظهر خرج التطبيق العملي
الخاتمة
تعرفنا في هذا المقال على مبدأ عمل خوارزمية التعرُّف على الوجوه والتي تعتبر الوحدة الأساسية في التطبيقات المُستخدمة في الحماية الأمنية وخصوصاً في كشف المجرمين ، تحدثنا عن آلية عمل هذه الخوارزمية بشكل تفصيلي ثم بعد ذلك قُمنا بتطبيق هذه الخوارزمية ، وطبقنا مثال عملي للتعرف على الوجوه ، وأخيراً رأينا سوياً فيديو يوضح نتيجة خرج التطبيق العملي.





6 تعليقات
كيف لي ان انشاء برنامج لهذا الغرض هل يوجد احد يساعدني ويعلمني
لماذا لم يشتغل معي
عاوز مساعدة
عندي مشروع تسجيل حضور بالتعرف علي الوجه
طيب لمن افتح الكاميرا وتلقط الموظف داير اسجل لي زمن الحضور في برنامج اكسل
مع العلم المناقشة قربت
هل من جديد حول مشروعك؟
هل يمكن تساعدني عندي مشروع التعرف ع الوجه
ممكن استخدام برمجة ماتلاب بدل البايثون