إعداد: م. نور شوشرة
التّدقيق العلميّ: م. رامي عقّاد، م. ماريّا حماده
المَحتويَات
- المقدّمة
- المحوّلات ذوات المشفّر التلقائي Autoencoder Transformers
- لماذا يُعدّ Bert بيرت مهمًّا؟
- كيف يعمل بيرت؟
- تهيئة ومعالجة النّصوص قبل إدخالها إلى بيرت
- المحوّلات التّنبؤيّة Autoregressive Transformers
- كيف يعمل شات جي بي تي؟
- محوّلات سلسلة إلى سلسلة Sequence-to-Sequence Transformers
- الخاتمة
- المراجع
- المقدّمة
- المحوّلات ذوات المشفّر التلقائي Autoencoder Transformers
- لماذا يُعدّ Bert بيرت مهمًّا؟
- كيف يعمل بيرت؟
- تهيئة ومعالجة النّصوص قبل إدخالها إلى بيرت
- المحوّلات التّنبؤيّة Autoregressive Transformers
- كيف يعمل شات جي بي تي؟
- محوّلات سلسلة إلى سلسلة Sequence-to-Sequence Transformers
- الخاتمة
- المراجع
المقدّمة
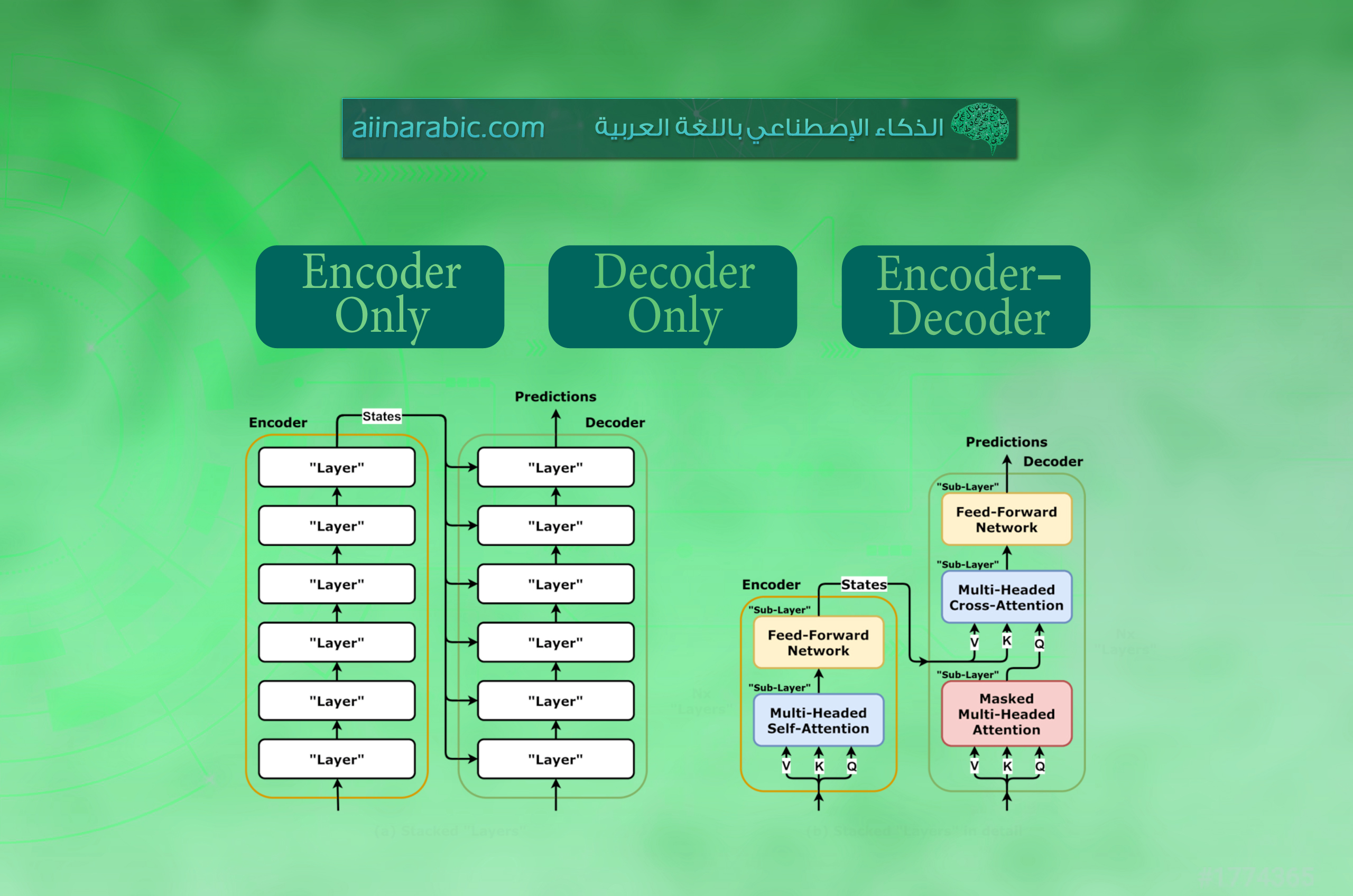
في عالم الذّكاء الإصطناعيّ وتعلّم الآلة، برز نموذج المحوّل Transformer كمعماريّةٍ رائدةٍ غيّرت قواعد اللّعبة؛ فقد عزّزت بشكلٍ كبيرٍ من أداء وكفاءة النّماذج في مجالاتٍ مختلفةٍ، بما في ذلك معالجة اللّغة الطّبيعيّة ورؤية الحاسوب، والّذي تمّ تقديمه لأوّل مرّةٍ من قبل فاسواني وآخرون vaswani et al في الورقة البحثيّة عام 2017 بعنوان “الاهتمام هو كلّ ما تحتاجه” Attention Is All You Need [1] [4].
يمكنكم الاطّلاع على هذه المقالة للفهم الأعمق لنموذج المحوّل، ويوضّح الشّكل 1 بنية نموذج المحوّل:
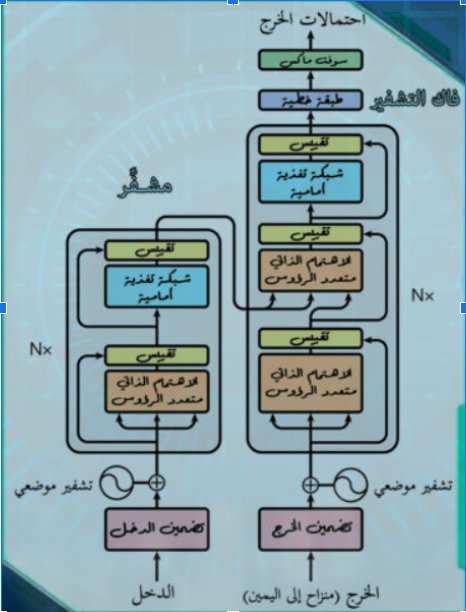
ومنذ ذلك الحين، تمّ تطوير العديد من المحوّلات المتخصّصة، كلٌّ منها مصمّمٌ للتّعامل مع مهام وتحدّياتٍ محدّدةٍ. سنستعرض في هذه المقالة الأنواع المختلفة من المحوّلات، وهي المحوّلات ذوات المشفّر التلقائي Autoencoder Transformers، المحوّلات التّنبؤيّة Autoregressive Transformers ومحوّلات سلسلة إلى سلسلة Sequence-to-Sequence Transformers، مع تقديم رؤيةٍ مفصّلةٍ لكلّ نوعٍ وتسليط الضّوء على النّماذج الموجودة في كلّ فئةٍ.
المحوّلات ذوات المشفّر التلقائي Autoencoder Transformers
تتفوّق المحوّلات ذوات المشفّر التلقائي في تقليل الأبعاد وتعلّم الميّزات، حيث تقوم بترميز البيانات المدخلة إلى تمثيلاتٍ ذات حجمٍ ثابتٍ في أبعاد مخفّضةٍ، ثمّ تقوم بإعادة بناء المخرجات من هذا التّمثيل مع الاحتفاظ بالمعلومات الأساسيّة من البيانات المدخلة.
النّموذج الموجود: نموذجٌ يُعرف باسم بيرت، وهو اختصارٌ لـ “التّمثيلات المشفّرة ثنائيّة الاتّجاه من المحوّلات” Bidirectional Encoder Representations from Transformers، ويطلق عليه أيضًا Encoder Only؛ لأنّه يستخدم جزء ال مُشفَّرٌ Encoder من المحوّل. [1][5]
لماذا يُعدّ Bert بيرت مهمًّا؟
تخيّل جملةً مثل: “هي تعزف الكمان بشكل رائع.”
النّماذج التّقليديّة، مثل RNN الشَّبَكَاتُ العُصبُونِيَّةُ الإرجاعِيَّةُ أو الشَّبَكَةُ العُصبُونِيَّةُ ذاتُ الذَّاكِرةِ الطَّويلةِ قصيرةِ المَدى LSTM كانت تعتمد على قراءة النّصّ إمّا من اليمين إلى اليسار أو العكس؛ ممّا قد يفوّت عليها الحقيقة الحاسمة وهي أنّ هويّة الآلة الموسيقيّة (الكمان) تؤثّر على فهم الجملة بأكملها.
أمّا بيرت، فيفهم أنّ العلاقة السّياقيّة بين الكلمات تلعب دورًا محوريًّا في استنباط المعنى. فهو يعتمد على ثنائيّة الاتّجاه؛ ممّا يُمكّنه من أخذ السّياق الكامل المحيط بكلّ كلمةٍ في الاعتبار، وهذا ما أحدث ثورةً في دقة وعمق فهم اللّغة.[5]
كيف يعمل بيرت؟
يعتمد بيرت في جوهره على بنية شبكاتٍ عصبيّةٍ قويّةٍ تُعرف باسم المحوّلات Transformers. هذه البنية تتضمّن آليّةً تُسمّى الاهتمام الذّاتي Self-Attention، والّتي تسمح لـ بيرت بتحديد أهميّة كلّ كلمةٍ بناءً على السّياق المحيط بها سواء كان السّياق السّابق أو اللاّحق. هذا الفهم العميق للسّياق يُمكّن بيرت من توليد تمثيلاتٍ سياقيّةٍ للكلمات؛ أي تمثيلاتٍ تُعبّر عن معنى الكلمة بناءً على موقعها في الجملة.
يمكن تشبيه عمل بيرت بقراءة الجملة وإعادة قراءتها ليفهم بعمقٍ دور كلّ كلمةٍ.
لنأخذ جملةً، مثل: (ذهب إلى السوق ليشتري ذهبًا.)
قد تواجه النّماذج التّقليديّة صعوبةً في التّعامل مع غموض الكلمة “ذهب” (الّتي يمكن أن تكون اسمًا أو فعلًا)، لكنّ بيرت يميّز بسهولةٍ أنّ ذهب هي فعل في حين أنّ الثّانية اسم ممّا يُبرز قدرته الفائقة على حلّ الغموض اللّغويّ.[5]
تهيئة ومعالجة النّصوص قبل إدخالها إلى بيرت
قبل أن يتمكّن بيرت من العمل بجدارةٍ على النّصوص، يحتاج إلى تحضير النّصوص وتنسيقها بطريقةٍ يفهمها.
سنستعرض الخطوات الأساسيّة لمعالجة النّصوص قبل إدخالها إلى بيرت، بما في ذلك:
- التَّقسيمُ إلى وحداتٍ لُغويَّةٍ Tokenization.
- تنسيق المدخلات Input Formatting.
- النّموذج اللّغويّ المُقنّع Masked Language Model – MLM.
التَّقسيمُ إلى وحداتٍ لُغويَّةٍ
أي تقسيم النّص إلى أجزاء ذات معنى.
تخيّل أنّك تقوم بتعليم كيفيّة قراءة كتابٍ. لن تسلّمه الكتاب بأكمله دفعةً واحدةً، بل ستقوم بتقسيمه إلى جملٍ وفقراتٍ. وبالمثل، يحتاج إلى تقسيم النّصّ إلى وحداتٍ أصغر تُعرف باسم وحداتٍ لفظيَّةٍ tokens ، ولكن هنا توجد لمسةٌ خاصّة حيث يستخدم طريقةً تسمّى جزء من كلمة WordPiece لتجزئة الكلمات. يقوم بتقسيم الكلمات إلى أجزاء أصغر، مثل في اللّغة الإنكليزيّة تحويل كلمة “running” إلى “run” و”ning”. هذا يساعد في التّعامل مع الكلمات الصّعبة ويضمن أنّ بيرت لا يضيع في الكلمات غير المألوفة. في اللّغة العربيّة استخدام جزء من كلمة WordPiece يختلف عن المثال الإنجليزيّ بسبب طبيعة اللّغة الاشتقاقيّة والمعقدة، حيث أنّ تقسيم الكلمات في اللّغة العربيّة يحتاج إلى التّعامل مع اللّواحق Suffixes والسّوابق Prefixes بشكلٍ دقيقٍ.
باستخدام جزء من كلمة WordPiece يمكن لبيرت أن يقسّم الكلمة إلى:
الكلمة : كتابكم
- “كتاب ” (الجذر).
- “##كم” (لاحقة ملكيّة).
بمعنى أنّ بيرت يتعرّف على الجذر “كتاب” ككلمةٍ معروفةٍ، ويعامل “كم” كلاحقة ملكيّةٍ يتمّ إضافتها. هذا يساعد بيرت في التّعامل مع الكلمات الجديدة والمشتقة في اللّغة العربيّة بطريقةٍ فعاّلةٍ.
في هذا السّياق، بيرت لا يقوم بتقسيم الكلمة إلى أجزاءٍ غير مفهومةٍ، مثل “كت” و “اب”، بل يفهم الجذر الرّئيسيّ للكلمة ويضيف اللّواحق المناسبة؛ ممّا يجعله قادرًا على معالجة الكلمات بشكلٍ أفضل في اللّغة العربيّة.
وبهذه الطّريقة، يمكن لبيرت التّعامل مع البادئات، مثل “الـ” في “الكتاب” واللّواحق، مثل “كم” في “كتابكم” وهي سمةٌ مهمّةٌ لمعالجة النّصوص باللّغة العربيّة.
مثال:
النّصّ الأصلي: “سيذهبون إلى منازلكم غدًا.”
التّقسيم باستخدام جزء من كلمة WordPiece:
“سي”
“##ذهب”
“##ون”
“إلى”
“منازل”
“##كم”
“غدًا”
التّوضيح:
“سيذهبون” تمّ تقسيمها إلى ثلاثة أجزاءٍ: “سي” (بادئة تشير إلى المستقبل)، “ذهب” (الجذر الرئيسيّ للفعل)، و”##ون” (لاحقة تدلّ على الجمع).
“منازلكم” تمّ تقسيمها إلى “منازل” (الجذر)، و”##كم” (لاحقة ملكيّة تشير إلى “أنتم”).
الكلمات “إلى” و”غدًا” بقيت كما هي لأنّها بسيطةٌ ومفهومةٌ.
في هذا المثال، نرى كيف تتعامل جزء من كلمة WordPiece مع السّوابق، مثل “سي” الّتي تدلّ على المستقبل واللّواحق، مثل “ون” للجمع و”كم” للملكيّة؛ ممّا يساعد النّموذج على فهم السّياق والتّراكيب المعقدة في اللّغة العربيّة بشكلٍ أكثر فعاليّة.
تنسيق المدخلات
أي تقديم السّياق لـبيرت BERT .
إنّ بيرت يفهم السّياق؛ ويجب علينا أن نقدّمه له بطريقةٍ واضحةٍ. وللقيام بذلك، نقوم بتنسيق الوحدات اللّفظيّة tokens بطريقةٍ يفهمها بيرت. نضيف رموزًا خاصّةً مثل [CLS] (والّتي ترمز إلى التّصنيف) في بداية النّصّ و [SEP] (والّتي ترمز إلى الفصل) بين الجمل، بالإضافة إلى ذلك، نضيف تضمينات الفقرات (segment embeddings) لإخبار بيرت أي ال وحداتٌ لفظيَّةٌ تنتمي إلى أيّ جملةٍ.
التّقسيم باستخدام WordPiece جزء من كلمة :
[“[CLS]”, “ال”, “##ذكاء”, “ال”, “##اصطناعي”, “مثير”, “ل”, “##لاهتمام”, “.”, “[SEP]”]
التوضيح:
“[CLS]” و “[SEP]” هما رمزان خاصّان مثلما هو الحال في المثال الإنجليزي.
“الذكاء” تمّ تقسيمه إلى جزأين: “ال” (السّابقة) و”##ذكاء” (الجذر).
“الاصطناعي” تمّ تقسيمه إلى ثلاثة أجزاءٍ: “ال” (السّابقة)، “##اصطناع” (الجذر) و “ي” لاحقة.
“مثير” بقيت كما هي لأنّها كلمةٌ بسيطةٌ.
“للاهتمام” تمّ تقسيمها إلى جزأين: “ل” (سابقة) و التي هي حرف جر و”##لاهتمام” (الجذر).
“.” بقيت كما هي لأنّها رمزٌ بسيطٌ.
بهذا الشّكل، يقوم بيرت بتقسيم الكلمات إلى سوابق وجذور ولواحق بطريقةٍ تجعل النّموذج يفهم السّياق اللّغويّ بشكلٍ أفضل.
النّموذج اللّغوي المُقنّع Masked Language Model (MLM)
أي تعليم بيرت السّياق.
إنّ السّرّ في قوّة بيرت يكمن في قدرته على فهم السّياق في كلا الإتّجاهين. خلال مرحلة التّدريب، يتمّ إخفاء بعض الكلمات (واستبدالها بـ [MASK قناع ]) داخل الجمل، ويتعلّم بيرت التّنبؤ بهذه الكلمات بناءً على السّياق المحيط بها. هذا يساعد بيرت على فهم كيفيّة ارتباط الكلمات ببعضها البعض سواء قبل الكلمة أو بعدها،
مثال:
الجملة الأصليّة: “يحب الأطفال اللّعب في الحديقة.”
الجملة المُقنّعة: “يحب [ قناع ] اللّعب في الحديقة.”
في الجملة الأصليّة، الكلمة “الأطفال” توضّح من هم الّذين يحبّون اللّعب.
في الجملة المُقنّعة، تمّ استبدال كلمة “الأطفال” بـ “[قناع ]”.
خلال التّدريب، يتعلّم بيرت كيف يمكن للكلمات الأخرى في الجملة، مثل “يحب” و”اللعب في الحديقة” أن تساعده في التّنبؤ بالكلمة المفقودة.
في هذه الحالة، الاحتماليّة الأقوى ستكون “الأطفال”، ولكن قد تكون هناك كلماتٌ أخرى محتملةٌ، مثل “الطّلاب” أو “الأخوة”؛ ممّا يظهر قدرة بيرت على استخدام السّياق لفهم العلاقات اللّغويّة.
وبهذا المثال يمكننا أن نرى كيف يتعامل بيرت مع الكلمات في السّياق ويستخدم الفهم الشّامل للتّنبّؤ بالكلمة المفقودة بشكلٍ أكثر دقة.
المحوّلات التّنبؤيّة Autoregressive Transformers
تعتمد المحوّلات التّنبؤيّة على التّنبؤ بالرّمز التّالي في التّسلسل من خلال الاعتماد على الرّموز السّابقة. يتمّ استخدامها بشكلٍ واسعٍ في نمذجة اللّغة والمهام التّوليديّة الأخرى.
النّموذج الموجود: الإصدار الثّالث من الجي بي تي GPT-3 (المحوّلات التّوليديّة المدرّبة مسبقًا Generative Pre-trained Transformer ) ويطلق عليه أيضًا Decoder Only؛ لأنّه يستخدم جزء ال فاكُّ الشِّيفرةِ Decoder من المحوّل.
مايعنيه حرف الـ G، هو أنّه “توليدي”، ممّا يعني أنّه تمّ تدريبه على نموذج توليد اللّغة الّذي ناقشنا عنه سابقًا. لكن ماذا عن حرفي الـ P و T؟
سنمرّ سريعًا على حرف الـ T، ويعني “المحوّل Transformer” الّذي عرضناه سابقًا. والآن لننتقل إلى حرف الـ P، الّذي يعني “التّدريب المسبق”. [1] [2] [6] [7]
كيف يعمل شات جي بي تي؟
يعمل نموذج شات جي بي تي Chat GPT من خلال المراحل التّالية:
- التّدريب المسبق.
المرحلة الأولى هي التّدريب المسبق، وهي بالضّبط ما مررنا به للتّو. تتطلّب هذه المرحلة كمّياتًا هائلةً من البيانات لتعلّم التّنبؤ بالكلمة التّالية. في تلك المرحلة يتعلّم النّموذج ليس فقط إتقان قواعد اللّغة وتركيب الجمل، بل أيضًا يكتسب قدرًا كبيرًا من المعرفة.
تتمثّل مهمّة التّدريب المسبق النّموذجيّة في التّنبؤ بالكلمة التّالية في تسلسل. مع وجود مجموعة البيانات التّدريبيّة الكاملة كخلفيّةٍ، يمكن للنّموذج تطبيق الأنماط الّتي تعلّمها في هذه المهمّة.
على سبيل المثال، قد يتعلّم أنّ الكلمة “going” غالبًا ما تتبعها “to”، أو أنّ “thank” تتبعها عادةً “you”.
تسجّل الشّبكة هذه الأنماط وتخزّنها كمعاملاتٍ parameters، ثمّ يمكنها الإشارة إليها لإجراء مزيدٍ من التّوقعات أو التّنبؤات .
في نهاية عمليّة التّدريب المسبق، قالت شركة أوبن أيه آي OpenAI: إنّ شات جي بي تي قد طوّر 175 مليار معاملٍ parameters. وهذه الكمّيّة الهائلة من البيانات تعني خيارات أكثر للنّظام للاستفادة منها من أجل الحصول على استجابةٍ دقيقةٍ. [6] [7]
- الضَبطٌ الدقيقٌ Fine Tuning
نأخذ النّموذج اللّغوي الكبير المدرّب مسبقًا بقدراته الحالية، ونقوم بشكلٍ أساسيٍّ بما قمنا به سابقًا —أي تعلّم التّنبؤ بكلمةٍ واحدةٍ في كلّ مرّةٍ— لكنّنا الآن نفعل ذلك باستخدام أزواجٍ من التّعليمات والاستجابات عالية الجودة كبيانات تدريبنا (نخصّصه على بيانات التّدريب الخاصّة بنا).
- التّعلّم المعزّز من التّغذية الرّاجعة البشريّة [7] reinforcement learning from human feedback (RLHF).
توجد أيضًا مرحلةٌ ثالثةٌ تمرّ بها بعض النّماذج اللّغوية الكبيرة، مثل شات جي بي تي ChatGPT وهي التّعلّم المعزّز من ملاحظات البشر (reinforcement learning from human feedback (RLHF.
قام البشر بتقييم استجابة نموذج لغويٌ كبير من حيث الفعاليّة، وأعادوا إدخال هذه التّقييمات إلى النّموذج حتّى يفهم أدائه.
لقد أدّى ضبط التّعلّم المعزّز من التّغذية الرّاجعة البشريّة الدّقيق إلى جعل شات جي بي تي أكثر فعاليّة في توليد استجاباتٍ ذات صلة ومفيدةٍ في كلّ مرّة.
يمكنكم قراءة المقال التّالي الّذي يشرح إمكانيّة توليد النّصوص باستخدام شات جي بي تي توليدُ النّصوصِ العربيّةِ مع نموذجِ GPT
محوّلات سلسلة إلى سلسلة Sequence-to-Sequence Transformers
تُستخدم محوّلات سلسلة إلى سلسلة في المهام الّتي تتطلّب تحويل تسلسلات المدخلات إلى تسلسلات مخرجاتٍ، وهي مفيدةٌ في التّرجمة الآليّة، التّلخيص، والإجابة على الأسئلة.
النّموذج الموجود: T5 (المحوّلات المحوّلة من نصٍّ إلى نصٍّ Text-to-Text Transfer Transformer ).
الغرض: تحويل جميع مهام معالجة اللّغة الطّبيعيّة إلى تنسيق النّصّ إلى النّصّ.
التطبيقات: التّرجمة، التّلخيص، الإجابة على الأسئلة وغيرها.
مثالٌ مع الشّرح:
المهمّة: التّرجمة الآليّة.
العمليّة: يقوم الإصدار الخامس من المحول T5 بأخذ جملةٍ بلغةٍ معيّنةٍ كمدخلاتٍ وينتج ترجمتها بلغةٍ أخرى كمخرجاتٍ. يتعلّم النّموذج التّمثيلات السّياقيّة والرّوابط بين اللّغات المختلفة خلال عمليّة التّدريب؛ ممّا يسمح له بالتّرجمة بفعاليّةٍ بين اللّغات.
الفائدة: ترجمةٌ فعّالةٌ ودقيقةٌ، ممّا يساعد على كسر الحواجز اللّغويّة في التّواصل العالميّ.
يمكنكم الاستفادة من المقالة التّالية الّتي تشرح التّرجمة الآليّة باستخدام محوّلات سلسلة إلى سلسلة نموذج ترجمة آليّة عصبونيّة (نماذج سلسلة إلى سلسلة Seq2Seq مع آليّة الاهتمام Attention) [1]
الخاتمة
يتطلّب تشغيل بيرت إعداد النّصّ بطريقةٍ دقيقةٍ. تتضمّن هذه العمليّة تجزئة الكلمات إلى أجزاء صغيرة باستخدام WordPiece، إضافة رموزٍ خاصّةٍ لتنسيق المدخلات بشكلٍ صحيحٍ وتعليم بيرت كيفيّة التّنبؤ بالكلمات المخفيّة في الجمل؛ لتعزيز فهمه للسّياق اللّغويّ.
يعتمد ChatGpt على التّوليد التّنبؤي Predictive Text Generation أي يمكنه توليد نصٍّ بناءً على المدخلات الّتي يتلقاها. عند تقديم سؤالٍ أو جملةٍ، يقوم النّموذج بتحليل الكلمات الأولى، ثمّ يبدأ في توليد الجملة التّالية بطريقةٍ منطقيّةٍ بناءً على المعلومات الّتي تعلّمها أثناء التّدريب المسبق، ويستخدم التّدريب باستخدام ردودٍ بشريّةٍ Fine-tuning with Human Feedback. بعد مرحلة التّعلم المسبق، يتمّ تحسين ChatGPT باستخدام ردودٍ بشريّةٍ عبر تقنيّة RLHF. يقوم المدرّبون البشر بتقديم أمثلةٍ عن الإجابات الصّحيحة أو يقيّمون الإجابات الّتي ينتجها النّموذج؛ وهذا يساعده في تحسين أدائه وجعله أكثر توافقًا مع التّوقعات البشريّة.
تستمر مجموعةٌ متنوّعةٌ من نماذج المحوّلات _بما في ذلك بيرت للمهام المعتمدة على المحوّلات ذوات المشفّر التلقائي و GPT-3 للمهام التّنبؤيّة و T5 لمهام سلسلة إلى سلسلة_ في تحقيق تقدّمٍ كبيرٍ في مجالات الذّكاء الإصطناعيّ وتعلّم الآلة. إنّ المعماريّات والقدرات الفريدة لهذه النّماذج تجعلها مناسبةً لمجموعةٍ واسعةٍ من المهام، ممّا يضمن استمرار تطوّرها وتكيّفها في المستقبل. توضّح الأمثلة العمليّة الفوائد والتّطبيقات الواقعيّة لهذه النّماذج، ممّا يبرز تأثيرها وأهمّيتها في تطوير التّكنولوجيا وحلّ المشكلات المعقّدة. [1][5][6][7]
المراجع
- أنواع المحولات
- توليدُ النّصوصِ العربيّةِ مع نموذج جي بي تي
- نموذج ترجمة آليّة عصبونيّة (نماذج سلسلة إلى سلسلة Seq2Seq مع آليّة الاهتمام Attention)
- المحوّل
- إتقان بيرت : دليل شامل من المستوى المبتدئ إلى المستوى المتقدم في معالجة اللغة الطبيعية (NLP)
- كيف تعمل نماذج اللغة الكبيرة
- كيف يعمل تشات جي بي تي (شرح بسيط وتقني)
- المحوّل
- قاموس المُصطلحات العلميّة


تعليقان