المقدّمة
يعرّف استرجاع المعلومات على أنّه عمليّة استرجاع المعلومات ذاتِ العلاقة، بناءً على استعلامٍ معيّن من قِبل مستخدمٍ ما، و إنّ ذلك يتطلّب استخلاص هذه المعلومات ذاتِ الصّلة من بياناتٍ غيرِ مُهيكلة قد تكون نصوصاً أو صوتاً أو صوراً.
وفي هذا السّياق فإنّ من أهمّ المشاكل التي تواجهها استرجاع المعلومات وبصورة خاصّة _النصّيّة_ منها، هو أنّ الملفّاتِ المُسترجعة تعتمد صيغةَ التّطابق الفعليّ للكلمة أو الكلمات الموجودة في الاستعلام، والبحث عن نفس الكلمات في الملفّات المعيّنة، وذلك يؤدّي في أغلب الحالات إلى فقدان تلك الملفّات التي تحتوي على مصطلحاتٍ مرادفة لتلك الموجودة في الاستعلام المعيّن، والتي قد تكون أكثر فائدةً للمستخدم، ومن المُلاحظ أنّ هذه المُعضلة تظهر في أغلب أنظمة استرجاع البيانات بأغلب اللّغات وخاصّة اللّغة العربيّة.
وفي هذا السّياق سوف نشرح فيما يلي واحدةً من أهمّ خوارزميّات التّعامل مع النّصوص تردّد الكلمة-تردّد المستند العكسيّ .
المحتويات
- مكتبة صندوق الأدوات الطبيعيّة (NLTK)
- ما هي خوارزميّة تردّد الكلمة-تردّد المستند العكسيّ (Term Frequency-Inverse Document Frequency)؟
- تطبيق عمليّ باستخدام بايثون
- ماهي مكتبة اس كي للتعلّم (sklearn)؟
- تطبيق عمليّ على مكتبة اس-كي-للتعلّم
- الخاتمة
- المراجع
مكتبة صندوق الأدوات الطبيعيّة NLTK
أوّلاً سوف نتعرّف على مكتبة صندوق الأدوات، هي عبارة عن مكتبةٍ مفتوحةِ المصدر موجودة في بايثون لمعالجة اللّغات الطبيعيّة (NLP)، وتحتوي هذه المكتبة على العديدِ من الدوال (Functions) والأصناف (Classes) المختلفة، والتي تساعد الباحثين في علم اللّغات ومحلّلي البيانات على معالجة النّصوص (Text Analysis) والتنقيب في النّصوص (Text Mining) بصورةٍ تمکّنهم من مساعدة أصحاب الشّركات الكبيرة من اتخاذ عددٍ من القرارات الهامّة.
ماهي خوارزميّة تردّد الكلمة-تردّد المستند العكسيّ
تُستخدم خوارزميّة تردّد الكلمة-تردّد المستند العكسيّ بتحديد أهميّة كلمة (مصطلح) معينة في مستندٍ معيّن من ضمن ديوانٍ نصّيٍّ معيّن، وإنّ زيادة أهميّة تلك الكلمة متكافئ مع عدد مرّات ظهورها في المستند المعيّن، و کما أنّها لابدّ أن تتناسب مع عدد مرّات ظهور الكلمة في كامل الدّيوان النّصيّ(corpus) المحدّد.
إنّ تردّد الكلمة هو عبارة عن عدد مرّات ظهور الكلمة في المستند، بينما تردّد المستند العكسيّ يحدّد عدد ظهور الكلمة في كامل الدّيوان النّصيّ.
ونلاحظ من التّعريف السّابق أنّ درجة أهميّة الكلمة تتحدّد تِبعاً له، فإذا كان ظهور كلمة معيّنة نادراً في المستند المعيّن فذلك دلالة على أنّ الكلمة مهمّة وذات أثرٍ علی المستند، وبناءً على ذلك يتمّ إعطاء الكلمة درجةً عالية (high score)، وعلى النّقيض من ذلك إذا ظهرت الكلمة عدّة مرّات في المستند فهذا دلالة على عدم أهميّة تلك الكلمة، وعندها يتمّ تحديد درجةٍ منخفضة (low score) للكلمة، ومن خلال هذا التّقييم فإنّ الكلمات الأكثر استخداماً أو ما يُعرف بكلمات الرّبط مثل (“إلى”،”من”،”عن”…الخ) والتي تظهر دائماً في كلّ المستندات، لا تعني فقط أنّها كلمات غير مهمّة بل تعني أيضاً أنّها لا تميّز المستند المعيّن.
وسوف نقوم بشرحٍ مبسّط لكيفيّة استخدام هذا المقياس مع النّصوص العربيّة.
التّطبيق العمليّ
الآن بعد أن قمنا بتعريف وشرح الخوارزميّة وطريقة عملها بصورةٍ مفصّلة، سنتدرّب على تطبيق الخوارزميّة في خطواتٍ بسيطة، مستعينين بديوانٍ نصّيّ بسيط باللّغة العربيّة يتكوّن من مستندَين فقط مستخدمين البرمجة بلغة بايثون.
وفيما يلي خطوات العمل :
1.في هذة الخطوة نعرّف المستندات المستخدمة في التّطبيق كما في الشّيفرة البرمجيّة (code) التّالية:
import nltk
from nltk import word_tokenize
DA='التنقيب في البيانات باللغة العربية'
DB='علم التنقيب في البيانات هو علم حديث'
2. إنّ خوارزميّات تعلّم الآلة الموجودة في مكتبة صندوق أدوات اللّغات الطبيعيّة (nltk)، لاتستطيع التّعامل مع النّصوص مباشرةً، لذلك يَلزم علينا تحويل هذه النّصوص إلى متّجهاتٍ رقميّة، وفي هذا السّياق إنّ مكتبة صندوق أدوات اللغات الطبيعيّة تحتوي على طريقةٍ لاستخراج النّصوص الموجودة ووضعها في شكل حزمٍ من الكلمات (Bag of words)، ويمكنك عزيزي القارئ الاطّلاع على كيفيّة بناء حقيبة الكلمات من خلال الموقع الخاصّ بالذّكاء الاصطناعيّ باللّغة العربيّة هنا، ويمكن القيام بذلك أوّلاً مستخدمين خاصيّة التّقسيم إلى وحداتٍ لغوّية (Tokenization) كما هو موضّح في المثال التّالي:
BofwA=nltk.word_tokenize(DA)
BofwB=nltk.word_tokenize(DB)
print(BofwA)
print(BofwB)
['التّنقيب', 'في', 'البيانات', 'باللّغة', 'العربيّة']
['علم', 'التّنقيب', 'في', 'البيانات', 'هو', 'علم', 'حديث']
الشّكل (1) حزمة الكلمات لكلٍّ من المستند الأوّل والمستند الثّاني بعد عملية التّقسيم إلى وحداتٍ لغوّية.
3.اتّحاد المجموعات(union) سوف نستخدم عمليّة اتّحاد المجموعات(union) بين مجموعتين(مستندَين) من الكلمات، وذلك كي نتأّکّد من عدم تكرار الكلمة في المجموعة الجديدة.يوضح الشّكل (2) حزمة الكلمات بعد حذف الكلمات المكرّرة.
UniqSet=set(BofwA).union(set(BofwB))
print(UniqSet)
{'علم', 'هو', 'العربية', 'التنقيب', 'باللغة', 'في', 'البيانات', 'حديث'}
الشّكل (2) حزمة الكلمات بعد تطبيق عمليّة اتّحاد المجموعات
4. إزالة كلمات الوقف(Stop words)
وكما ذكرنا سابقاً إنّ الكلمات مثل (“من”،”في”) هي كلمات لاتعبّر عن أهميّة المستند المعيّن ولذلك يجب إزالتها، ولكي نتعلّم تفاصيل إزالة كلمات الوقف يمكن الرّجوع إلى موقع الذّكاء الاصطناعيّ باللّغة العربية من هنا.
يوضح الشّكل(3) النّتيجة النّهائية لحزمة الكلمات من غير تكرار ومن غير كلمات الوقف.
وقد تمّت إزالة كلمات الوقف مستخدمين الشّيفرة البرمجيّة التّالية :
nltk.download('stopwords')
from nltk.corpus import stopwords
stopWD = set(stopwords.words("arabic"))
for word1 in UniqSet:
if word1 not in stopWD:
print(word1)
علم
العربية
التنقيب
باللغة
البيانات
حديث
الشّكل(3)حزمة البيانات بعد حذف كلمات الوقف
5.تردّد الكلمة (Term Frequency)
هو عدد مرّات ظهور الكلمة في المستند المعيّن نسبةً إلى عدد الكلمات فيه، وكلّ مستندٍ لديه نسبةُ ظهور مختلفة.
وتكون العلاقة الرّياضيّة كما في المعادلة (1) لحساب تردّد الكلمة بالشّكل التّالي:
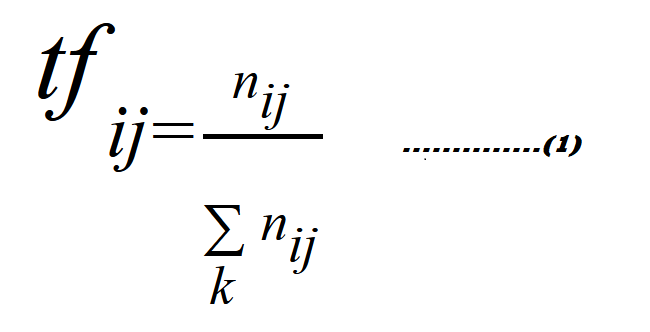
حيث tfij عدد مرات ظهور الكلمة tj في المستند Di
توضح الشيفرة البرمجية لبناء الدالّة (calctf)، كيفيّة حساب وزن كلّ كلمةٍ مقارنةً بالعدد الكلّيّ لكلمات المستند، ويتمّ ذلك بالخطوات التّالية:
أوّلاً يوضع المستند في شكلِ مجموعة كلماتٍ منفصلة.
ثانياً يتمّ حساب طول المستند، وذلك بحساب عددِ الكلمات الموجودة في المستند المعيّن ووضعها في حزمةٍ من الكلمات.
ثالثاً يتمّ حساب تردّد كلّ كلمةٍ بحساب عدد مرّات ظهور تلك الكلمة في المتغيّر(count)، ومن ثَمّ تُقسم على عدد الكلمات الكلّ لذلك المستند والمتمثّل في المتغيّر(bagofwordcount).
وأخيراً بذلك نكون عزيزي القارئ قد حسبنا تردّد كلّ الكلمات الموجودة في كامل المستند المعيّن.
ولحساب هذا المقياس (tf) قمنا ببناء الشّيفرة البرمجيّة التّالية :
def calctf(worddict,bagofword):
tfdict={}
bagofwordcount=len(bagofword)
for word ,count in worddict.items():
tfdict[word]=count/ float(bagofwordcount)
return tfdict
وفي السّطور التالية حسبنا (tf) لكلا المستندَين باستخدام الشّيفرة البرمجيّة التّالية :
tfA=calctf(NofwinA,BofwA)
tfB=calctf(NofwinB,BofwB)
print(tfA)
print(tfB)
يوضّح الشّكل(4) نتيجةَ حساب تردّد الكلمة لجميع الكلمات.
{'علم': 0.0, 'هو': 0.0, 'العربية': 0.2, 'التنقيب': 0.2, 'باللغة': 0.2, 'في': 0.2, 'البيانات': 0.2, 'حديث': 0.0}
{'علم': 0.2857142857142857, 'هو': 0.14285714285714285, 'العربية': 0.0, 'التنقيب': 0.14285714285714285, 'باللغة': 0.0, 'في': 0.14285714285714285, 'البيانات': 0.14285714285714285, 'حديث': 0.14285714285714285
الشّكل(4)حساب تردّد الكلمة (TF) لكلّ الكلمات
6.العلاقة الرّياضيّة لحساب تردّد المستند العكسيّ
تكون العلاقة الرّياضيّة كما في المعادلة(2) لحساب تردّد المستند العكسيّ بالشّكل التّالي:
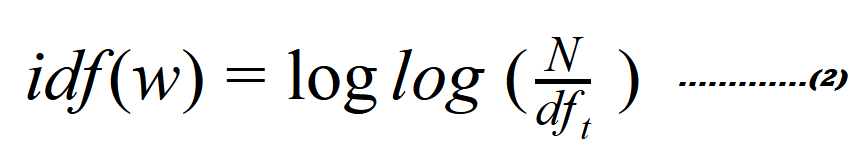
حيث N هي عدد المستندات الكلّيّ و w هي وزن كلّ كلمة
في الجزء التّالي تمّ بناء الدالّة (calcidf) لحساب تردّد المستند العكسيّ من خلال الخطوات التّالية:
أوّلاً: حساب عدد المستندات في كامل الدّيوان النّصيّ ووضعها في المتغيّر(N).
ثانياً: عمل قاموس لكلّ الكلمات الموجودة في كامل الدّيوان النّصيّ.
ثالثاً: حساب اللوغاريثم (log) لكلّ الكلمات، وبذلك نكون قد حصلنا على تردّد المستند العكسيّ لكلّ الكلمات الموجودة في الدّيوان النّصيّ.
ولحساب idf تمّ بناء الشّيفرة البرمجيّة التّالية :
import math
def calcidf(documents):
N=len(documents)
idfDict=dict.fromkeys(documents[0].keys(),0)
for document in documents:
for word,val in document.items():
if val>0:
idfDict[word] +=1
for word,val in idfDict.items():
idfDict[word]=math.log(N/float(val))
return idfDict
7. وتكون العلاقة الرّياضيّة كما في المعادلة (3) لحساب تردّد الكلمة-تردّد المستند العكسيّ بالشّكل التّالي:
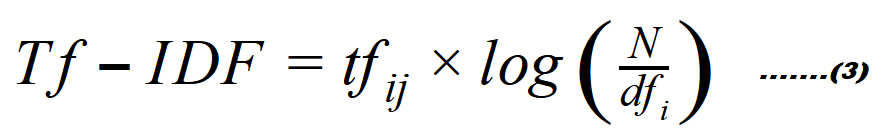
ولحساب هذه العلاقة تمّ بناء الشّيفرة البرمجيّة التّالية :
def calcTFIDF(tfbagofword,idfs):
tfidf={}
for word,val in tfbagofword.items():
tfidf[word]=val *idfs[word]
return tfidf
وبذلك نكون قادرين على حساب تردّد الكلمة-تردّد المستند العكسيّ لكلّ الكلمات الموجودة في الدّيوان النّصّيّ كما هو واضح في الشّكل(5)، عن طريق استخدام مكتبة الطّباعة (pprint) لنتمکّن من عرض البيانات بصورةٍ واضحة كالتّالي:
import pprint
tfidf_A=calcTFIDF(tfA,idfss)
tfidf_B=calcTFIDF(tfB,idfss)
pprint.pprint(tfidf_A)
pprint.pprint(tfidf_B)
{'البيانات': 0.0,
'التنقيب': 0.0,
'العربية': 0.08664339756999316,
'باللغة': 0.08664339756999316,
'حديث': 0.08664339756999316,
'علم': 0.17328679513998632,
'في': 0.0,
'هو': 0.08664339756999316
الشّكل(5) حساب تردّد الكلمة-تردّد المستند العكسيّ لكامل الدّيوان النّصيّ
مكتبة اس-كي-للتعلم (sklearn)
هذه المكتبة هي مكتبة مفتوحةُ المصدر ومجانيّة، وتستخدم في تحليل البيانات بصورةٍ بسيطة وفعّالة، تعتمد في بنائها على عدد من المكتبات مثل مكتبة بايثون العدديّة Numpy ومكتبة الحوسبة العلميّة ،Scipy بالإضافة إلى احتوائها على العديد من الخوارزميّات واستخدامها في عمليّات تجهيز البيانات وتقييم النّماذج، وسوف نتعرّف معاً على الصف (class) والذي يمكّن من حساب تردّد الكلمة-تردّد المستند العكسيّ داخليّاً في مكتبة (اس-كي-للتعلم) و يسمّی (TfidfVectorizer).
في هذا الجزء عزيزي القارئ سوف نقوم باستخدام الصّفّ (TfidfVectorizer)، وهو الصّ المستخدم لحساب الخوارزمية تردّد الكلمة-تردّد المستند العكسيّ والموجودة داخل المكتبة (اس-كي-للتعلم)، وذلك يتطلّب أولاً إنشاء كائن(object) في المتغير(vectorizer)، ثانياً تحويل كامل الدّيوان النّصيّ إلی متّجهاتٍ رقميّة باستخدام الدالّة (fit_transform) كما هو واضح في الشّكل(6)، ثالثاً استخراج الكلمات ووضعها في شكل قائمة من مزايا (features)، أخيراً حساب تردّد الكلمة-تردّد المستند العكسيّ لكامل الدّيوان النّصيّ.
تطبيق عمليّ:
import sklearn
from sklearn.feature_extraction.text import
TfidfVectorizer
vectorizer = TfidfVectorizer()
vectors = vectorizer.fit_transform([DA,DB])
feature_names = vectorizer.get_feature_names()
(0, 2) 0.5330978245262535
(0, 3) 0.5330978245262535
(0, 0) 0.3793034928087496
(0, 6) 0.3793034928087496
(0, 1) 0.3793034928087496
(1, 4) 0.36469322896147516
(1, 7) 0.36469322896147516
(1, 5) 0.7293864579229503
(1, 0) 0.2594822360637418
(1, 6) 0.2594822360637418
(1, 1) 0.2594822360637418
الشّكل(6) متّجهات البيانات لكامل الدّيوان النّصيّ
وتكون الشّيفرة البرمجيّة لحساب تردّد الكلمة-تردّد المستند العكسي لكلّ الكلمات كالتّالي :
TfidfForAll= vectors.todense()
pprint.pprint(TfidfForAll)
يبيّن الشّكل(7)القيم المختلفة لحساب تردّد الكلمة-تردّد المستند العكسيّ.
matrix([[0.37930349, 0.37930349, 0.53309782, 0.53309782, 0. ,
0. , 0.37930349, 0. ],
[0.25948224, 0.25948224, 0. , 0. , 0.36469323,
0.72938646, 0.25948224, 0.36469323]])
الشّكل(7) تردّد الكلمة-تردّد المستند العكسيّ لجميع كلمات الدّيوان
عزيزي القارئ يمكنك الاطلاع على كامل الشيفرة البرمجية في مستودع الجت هب الخاص بموقع الذكاء الاصطناعي باللغة العربية
الخاتمة
تعرّفنا في هذا المقال على طريقة استخدام خوارزميّة تردّد الكلمة-تردّد المستند العكسيّ وتطبيقها على النّصوص العربيّة، والتي تعتمد على تحديد أهميّة الكلمات في كلّ النّصوص، هذا وإنّ نسبةَ ظهور تلك الكلمة هو ما يحدّد أهميّة الكلمة في النّص المعيّن، بالإضافة إلى أهميّة هذه الخوارزميّة في برامج تعلّم الآلة وذلک في عمليّات تحليل البيانات واتّخاذ القرارات، ومن السّهل تطبيقها على الدّيوان النّصيّ العربيّ مهما كبرت حجم البيانات.
والخَيار متروك لمحلّل البيانات في استخدام إحدى الطّريقتين، إمّا بناء الشّيفرة البرمجيّة الخاصّة به واستخدامها أو استخدام الخوارزميّات المبنيّة مُسبقاً والتّعامل معها مع مراعاة بعض الاختلافات في النّتائج عند استخدام الطّريقة المعيّنة.
المراجع
- https://towardsdatascience.com/natural-language-processing-feature-engineering-using-tf-idf-e8b9d00e7e76
- Grossman, D.A. and Frieder, O., 2012. Information retrieval: Algorithms and heuristics (Vol. 15). Springer Science & Business Media.
- Ramos, J., 2003, December. Using tf-idf to determine word relevance in document queries. In Proceedings of the first instructional conference on machine learning.
- Ahmed, R.O.M., Supervised, A.A.M.A. and Ali, S.A.A.M., 2015. Design of Arabic Dialects Information Retrieval Model for Solving Regional Variation Problem (Doctoral dissertation, Sudan University of Science and Technology).
- https://aiinarabic.com/glossary/