
أصبحت تطبيقات الحاسب التي تعتمد على الرؤية الحاسوبية Computer Vision أكثر شيوعاً في حياتنا اليومية حيث أن الأنظمة المساعدة في القيادة Advanced Driver Assistance Systems – ADAS أصبحت تُستخدم تقريباً في كل السيارات مما جعل تحقيق حلم السيارات ذاتية القيادة قريب المنال. إضافة إلى ذلك لا تعد صناعة السيارات الهدف الوحيد لتقنيات الرؤية الحاسوبية فهي مفيدة أيضاً في التطبيقات التي تساعد المكفوفين في السير داخل وخارج المنازل كما تساعد أيضاً في تطوير رجال آلية Robots تساعد المصابين في أماكن لا يستطيع الإنسان الوصول إليها مثل أماكن الحروب و الكوارث الطبيعية. نظراً لكثرة وأهمية هذه التطبيقات يزداد عدد الأبحاث في هذه المواضيع بشكل ملحوظ و مع أن الطرق التقليدية التي تستخدم تقنيات كشف وتوصيف المزايا HOG histogram of oriented gradients و SIFT scale-invariant feature transform استطاعت تسريع وتطوير الأداء بشكل ملحوظ إلا أنها تحتاج إلى جهد بشري كبير. من جهة أخرى أحدث التعلم العميق Deep Learning تطوراً ملحوظاً في دقة نتائج تطبيقات الرؤية الحاسوبية ولكنه يحتاج من أجل عملية التدريب إلى كمية كبيرة جداً من الصور المشروحة على مستوى البكسل pixel-level annotated images، نقصد بالصور المشروحة على مستوى البكسل إسناد كل بكسل في الصورة إلى صنف معين وهو ما يدعى بالتجزئة الدلالية Semantic Segmentation. على الرغم من صعوبة هذه العملية و كلفتها الكبيرة في الجهد والمال هناك تزايد في عدد قواعد البيانات التي تم إيجادها لهذا الهدف. في هذا المقال سوف نشرح بداية حل إبداعي لهذه المشكلة يستخدم قاعدة بيانات صناعية سينزيا SYNTHIA تحوي على صور مأخوذة من مدينة إفتراضية تم إنشاؤها باستخدام منصة يونيتي Unity، ثم نعرض حل لمشكلة تغيير المجال من خلال تقديم ملائم Adapter خاص للانتقال بين العالمين الحقيقي والافتراضي يستخدم صور مأخوذة من الّلعبة الإلكترونية الشهيرة جي-تي-اي GTA. أخيراً سوف نشرح كيف حلت شبكات الملائمة كاملة الطّيّ Fully Convolutional Adaptation Network – FCAN مشكلة الانحياز الذي يسببها تغيير المجال.
المحتويات
مقدمة

يزداد الاستثمار في مجال الرؤية الحاسوبية بشكل ملحوظ خصوصاً في الدول الصناعية التي تقوم بتطوير أنظمة القيادة الذاتية autonomous driving – AD وذلك بفضل النجاح الذي حققته الأنظمة المساعدة في القيادة advanced driver assistance systems – ADAS حيث أصبحت القيادة أسهل وأكثر أماناً. لا تفيد الرؤية الحاسوبية فقط في مجال المركبات بل تساعد أيضاً المكفوفين من خلال برمجيات تعمل كدليل لهم أثناء الحركة والسير داخل أو خارج الأماكن المغلقة، إضافة إلى المساعدة في تطوير رجال آلية تساعد المصابين في الحروب أو الكوارث الطبيعية حين يصعب أو يستحيل على البشر الوصول لهذه الأماكن.
تعد التجزئة الدلالية Semantic Segmentation واحدة من أهم أدوات الرؤية الحاسوبية التي تسهل على الحاسوب فهم الصور من خلال إعطاء تصنيف لكل بكسل من بكسلات الصورة، يوضح الشكل (1) مثالين لتطبيقات التجزئة الدلالية.
ولدت العديد من تقنيات الرؤية الحاسوبية من أجل التعرف على الأشياء في الأماكن العامة مثل إشارات المرور، الطرق، الناس والمركبات. يمكن تقسيم كل هذه التقنيات إلى مجموعتين، الأولى تقنيات كشف وتوصيف المزايا HOG و SIFT والثانية تعتمد على تعلم الآلة (machine learning) والتي تستخدم طرق مثل Support Vector Machine-SVM , Adaptive Boosting-AdaBoost. مؤخراً وبفضل التطور في أداء الحاسب وإختراع وحدات معالجة الرسوميات Graphics Processing Unit-GPUs أصبح استخدام شبكات الطي العصبونية العميقة deep convolutional neural networks-DCNNs أكثر فعالية حيث زادت من دقة نتائج تطبيقات الرؤية الحاسوبية بشكل كبير ولكن يبقى نجاح استخدام هذه الشبكات مرهوناً بوجود كمية هائلة من الصور المشروحة على مستوى البكسل من أجل عملية التدريب Training وهو عملية صعبة جداً لأن كل بكسل يجب أن يسند لصنف معين.
من أجل إيجاد هذه الكمية الهائلة من الصور المشروحة على مستوى البكسل تم إنجاز العديد من قواعد البيانات مثل سيتي-سكيب Cityscape التي تبقى محدودة الحجم وذلك بسبب التكلفة العالية للصور حيث يجب أخذها من مدن كثيرة و بظروف بيئية مختلفة. سنتعرف على تفاصيل أكثر عن هذه القواعد في الفقرة رقم (2). لتجنب هذه المحدودية ظهرت فكرة أخذ صور من العالم الافتراضي وخصوصاً بعد تطويره وجعله أقرب للواقع.
تعد قاعدة البيانات “سينزيا SYNTHIA ” الخاصة بالصور المشروحة على مستوى البكسل SYNTHetic collection of Imagery and Annotations of urban scenarios [1] واحدة من القواعد التي طبقت فكرة الاستفادة من صور العالم الافتراضي حيث تم استخدام طريقتين للتصوير لإنشاء 13400 صورة و 200000 إطار Frame لمزيد من التفاصيل عن هذه القاعدة يمكن الاطلاع على الفقرة رقم (3).
من ناحية أخرى قد يؤدي تدريب شبكات الطّيّ العصبيونيّة العميقة على صور اصطناعية من العالم الافتراضي واختبارها على الصور الحقيقية في عالمنا الواقعي إلى مشكلة انحياز تدعى مشكلة تغيير المجال Domain Shift بسبب الاختلاف بين معاملات الكاميرات في العالمين الواقعي والافتراضي مما يؤدي في النتيجة إلى إضعاف الأداء وانخفاض في دقة النتائج.
لمعالجة مشكلة تغيير المجال سنحاول جعل الصور الافتراضية تبدو وكأنها مأخوذة من كاميرات حقيقية من وجهة نظر شبكات الطّيّ العصبيونيّة العميقة حيث نقدم في الفقرة رقم 4 طريقتين للملائمة Adaptation: الأولى بسيطة وهي إضافة بعض الصور الحقيقية لقاعدة التدريب. والطريقة الثانية تتمثل باستخدام شبكات الملائمة كاملة الطّيّ [2] والتي تعمل على ملائمة الصور في مستويي التمثيل representation والمظهر appearance.
بعد تحليل نتائج التجارب التي قمنا بها سنجد في الفقرة رقم (5) أن التعلّم من قاعدة بيانات مختلطة حقيقيّة واصطناعية يحسن الأداء وأنّ الملائمة بواسطة شبكات كاملة الطّيّ تستخدم صور من عالم لعبة جي-تي-اي يقلّل تأثير تغيير الدومين. في الفقرة رقم (6) نقدّم ملخصاً لأهم النقاط التي عرضناها في هذا المقال.
الأعمال المشابهة
أدى التحسّن الأخير في نتائج تطبيقات التجزئة الدلالية باستخدام شبكات الطّيّ العصبونيّة إلى إعطاء المزيد من الاهتمام في إنشاء قواعد بيانات مشروحة على مستوى البكسل وذلك بسبب الحاجة لمزيد من البيانات الخام من أجل تدريب هذه الشبكات. يمكننا تقسيم هذه الأعمال إلى ثلاث مجموعات رئيسية. الشكل (2) يظهر صور ومعلومات أساسية عن أهم قواعد البيانات المتعلّقة بالتجزئة الدلالية.
- قواعد بيانات الأماكن المغلقة: تفيد هذه القواعد في المهام التي تعتمد على الأغراض العامة في الأماكن المغلقة وبالتالي لا تتناسب مع مهام السيارات ذاتية القيادة التي يجب أن تتعرف على الأغراض الموجودة في الشوارع مثل إشارات المرور، الدراجات الهوائية وغيرها. تعتبر قواعد بيانات نواي-ديبث NYUDepth dataset [3] ، باسكال PASCAL [4] ومايكروسوفت-كوكو MSCOCO [5] أمثلة جيدة لهذا النوع.
- قواعد بيانات الأماكن المفتوحة محدودة الحجم: تعتبر قاعدتي البيانات كام-فيد CamVid [6] و كيتي KITTI [7] فعالتين جداً في تطبيقات التجزئة الدلالية خارج الأماكن المغلقة ولكنهما محدودتين من حيث التنوع في الصور وذلك بسبب اعتمادهما على أخذ الصور في مدينة واحدة فقط. في 2015، تم إلتقاط 5000 صورة في مدن حول العالم ثم شرحهم بثلاثين صنفاً لتشكيل أكبر قاعدة بيانات للتجزئة الدلالية سيتي-سكيب Cityscapes [8] ولكن التكلفة العالية جداً لالتقاط المزيد من الصور في مدن أخرى وبشروط بيئية مختلفة أدى إلى توقف التوسع في هذه القاعدة.
- قواعد بيانات صناعية تحوي صور مأخوذة من العالم الافتراضي: تغلبت قاعدة البيانات الصناعية سينزيا SYNTHIA على مشكلة التكلفة العالية في الجهد والمال والوقت لأخذ الصور من العالم الحقيقي عن طريق أخذ الصور من العالم الافتراضي محققة نتائج ممتازة عن طريق استخدام ملائم خاص لجعل هذه الصور تظهر كما وكأنها التقطت من عالمنا الحقيقي.

قاعدة البيانات الصناعية سينزيا SYNTHIA
تحتوي قاعدة البيانات الصناعية سينزيا SYNTHIA على 13400 صورة SYNTHIA-Rand و 200000 إطار SYNTHIA-Seqs و دقة الصور في كليهما 960 * 720 بكسل. تم شرح هذه الصور عن طريق إسناد كل بكسل إلى صنف من الثلاثة عشرة صنف المعرفين في سينزيا (انظر الشكل 3).
تم إلتقاط صور المجموعة الأولى SYNTHIAS-Rand من كاميرات موضوعة في أماكن عشوائية في المدينة الافتراضية، ارتفاع هذه الكاميرات من 1 إلى 1.5 متر والمسافة بين الكاميرتين ليست أقل من عشرة أمتار وذلك لتجنب التشابه similarity. في حين تم الحصول على الإطارات SYNTHIA-Seqs من خلال مجموعتين من الكاميرات كل مجموعة تحتوي على أربع كاميرات موضوعة فوق سيارة افتراضية تسير في المدينة وتغير سرعتها بحسب بعدها عن الأغراض الأخرى الموجودة قربها. حيث تقلل أو تزيد سرعتها من أجل تجنب الاصطدام مع سيارات أو أشخاص آخرين، يلعب هذا التغير في السرعة دوراً هاماً جداً في زيادة التنوع في البيانات. في نهاية رحلة المسير هذه يتم توليد 50000 إطار، بعد ذلك تقوم السيارة بنفس الرحلة في المدينة ولكن بعد تغيير الفصل (صيف، خريف، شتاء، ربيع) الشكل (4) يظهر المنصة الافتراضية لالتقاط الصور مع أربعة صور لنفس الموضع ولكن أثناء فصول مختلفة.

تم إنشاء المدينة الافتراضية باستخدام منصة يونيتي Unity بطريقة تجميع عدة مكونات بمعنى أنه عند إضافة المكونات أو تعديل معاملاتها يتغير المشهد scene وبالتالي يزداد التنوع في الصور (الشكل 5 يوضح ذلك)

ملائمات المجال Domain Adaptation
رغم التحسن الكبير في واقعية العوالم الافتراضية يبقى هناك اختلاف بين صورهم وصور عالمنا الحقيقي بسبب الكاميرات، مما يقود إلى مشكلة انحياز تسمى مشكلة تغيير المجال domain shift problem التي تتطلب ملائم خاص من أجل حلها. أحد الحلول المشروحة في هذه الورقة البحثية [1] هي ملائم بسيط فكرته دمج الصور الحقيقية مع الصور الافتراضية.
الطريقة الثانية المقدمة في البحث [2] تقترح استخدام شبكة كاملة الطّيّ fully convolutional network FCAN من أجل الملائمة حيث تحتوي على جزئين رئيسيين (الشكل 6) شبكة ملائمة المظهر appearance adaptations network (AAN) وشبكة ملائمة التمثيل representation adaptation network (RAN).
تقوم الشبكة الأولى بملائمة الصور المأخوذة من أحد المجالات لتظهر وكأنها مأخوذة من المجال الآخر من حيث المظهر. بينما تقوم الثانية بنفس العمل ولكن من حيث التمثيل. الشبكتان تكملان بعضهما و تقللان معاً من تأثير مشكلة تغيير المجال.
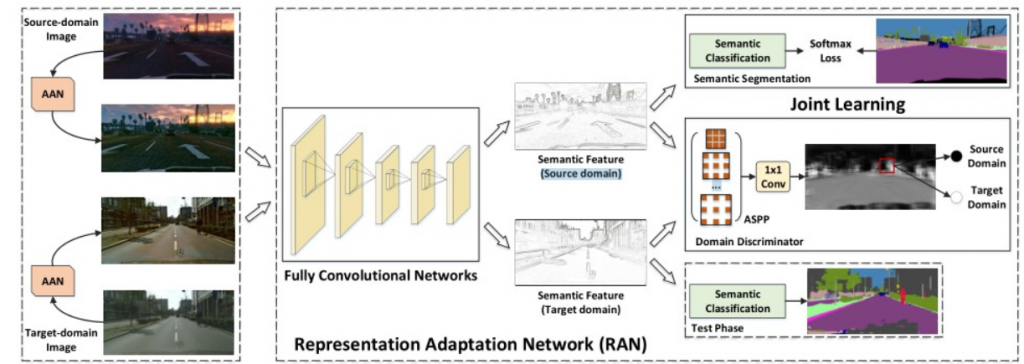
الشكل (7) يظهر بينة شبكة ملائمة المظهر والتي تتكون من عدد من طبقات الطّيّ. الطبقات الأولى تستخرج مزايا منخفضة المستوى التي تكوّن شكل المجال الهدف والطبقات الأعمق تستخرج المزايا عالية المستوى والتي هي محتويات صورة المصدر. دخل شبكة ملائمة المظهر هو صور تم إنشاؤها من صورة ضجيج أبيض white noise image و ناتج دمج محتوى Content صورة المصدر Xs مع شكل Style صور الهدف Xt والخرج هو الصورة التي تمت ملاءمتها Xo
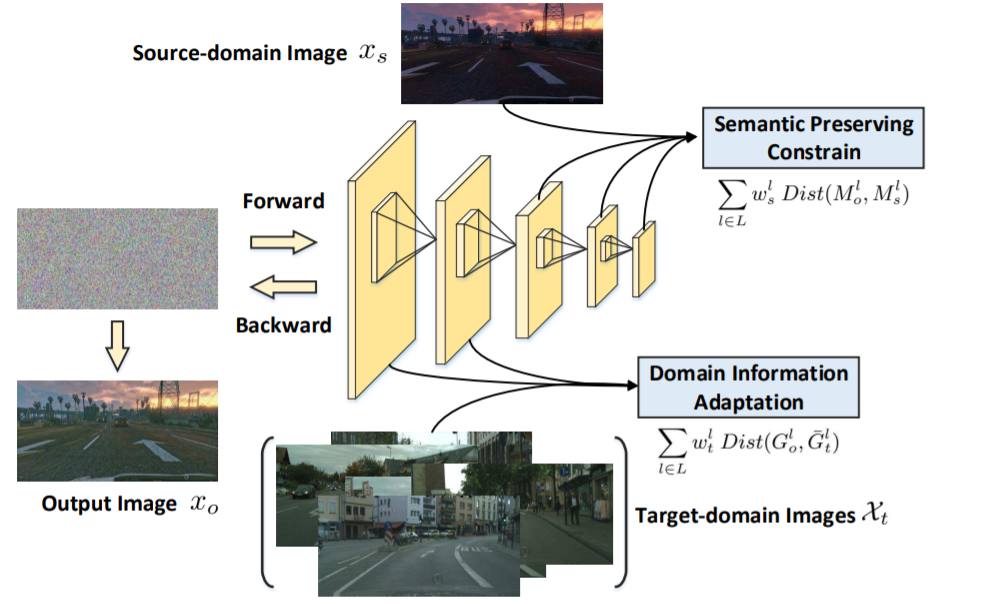
تابع الخسارة في شبكة ملائمة المظهر هو جمع خطي للمسافة بين خارطة مزايا الخرج Mo وصور المصدر Ms مع المسافة بين الشكل الوسطي لصور الخرج (Gt) و شكل صورة الخرج Go
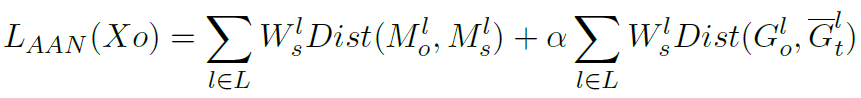
تطبق شبكة ملائمة التمثيل RAN من جهة أخرى استراتيجية التعلم العدائي adversarial learning strategy الموضحة في هذه الورقة البحثية [9]. بينما تتعلّم شبكة الملائمة كاملة الطّيّ كيفية أن لا تكون قادرة على معرفة المجال الذي تنتمي له صورة الدخل، يتعلم مميز المجال domain discriminator كيفية التمييز بين صور الدخل والخرج. يحتوي مميز المجال على 4 شبكات تأخير Atrous Spatial Pyramid Pooling (ASPP) من أجل حل مشكلة القياسات المختلفة لصور الدخل. الطبقة الأخيرة من مميز المجال تستخدم تابع سيغمويد Sigmoid لأنه لدينا فقط صنفين إما مجال المصدر أو مجال الهدف. التجزئة الدلالية تستخدم الانتروبيا المتقاطعة cross entropy كتابع للخسارة و سوفت-ماكس softmax من أجل تقييس النتائج.
تقييم النتائج
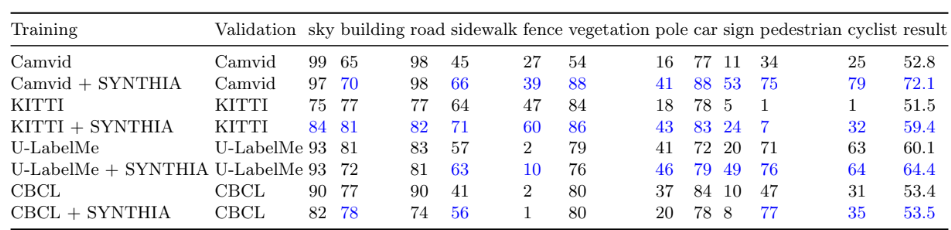
التجربة الأولى: تهدف تجربتنا الأولى إلى إظهار تأثير إضافة قاعدة بيانات صناعية سينزيا إلى قواعد بيانات التدريب حيث تم تدريب شبكة كاملة الطّيّ بقواعد البيانات الخاصة بالتدريب التالية كام-فيد CamVid [6],كيتي KITTI [7],يو-ليبل-مي U-LabelMe [11] و سي-بي-سي-إل CBCL [12] ثم تم توسيعها باستخدام صور من قاعدة سينزيا في كل الحالات تم استخدام نفس قواعد بيانات التحقق Validation set.
تظهر الأرقام الموضوعة بالنسب المئوية في الجدول (1) أن التوسيع بقاعدة بيانات صناعية يزيد من الدقة من أجل كل قواعد البيانات التي تم الاختبار عليها، الفائدة الأعظم كانت مع الأجسام المتحركة مثل الدراجات الهوائية. الشكل (8) يظهر النتائج النوعية بجيث ومع أنه أمكن رؤية الأغراض المشروحة في صورة الخرج للشبكة كاملة الطّيّ التي تم تدريبها بصور من العالم الافتراضي بوضوح وسهولة كانت صور الخرج في حال الدمج بين صور من العالمين الافتراضي والحقيقي أكثر دقة و نعومة.
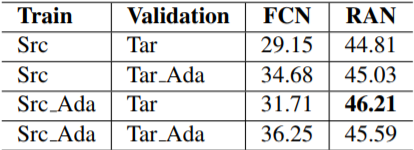
التجربة الثانية تثبت كيف أن الملائم المكون من شبكتي ملائمة المظهر والتمثيل يحسن الأداء حيث تم استخدام صور من الإصدار الخامس للعبة جي-تي-اي GTA5 [13] كقاعدة بيانات افتراضية و صور من قاعدة بيانات سيتي-سكيب Cityscape [8] كقاعدة بيانات حقيقية. الجدول (2) يوضح أربع حالات بحسب الصور المستخدمة في مرحلتي التدريب Training و التحقق Validation لملائمة صور قاعدة بيانات المصدر جي-تي-اي مع صور قاعدة بيانات الهدف سيتي-سكيب حيث أن الغاية تكمن في الاستفادة من صور اللعبة عن طريق إظهارها كما لو أنها أخذت من قاعدة بيانات صور عالمنا الحقيقي سيتي-سكيب.
- الحالة الأولى: التدريب على قاعدة بيانات المصدر والتحقق على قاعدة بيانات الهدف.
- لحالة الثانية: التدريب على قاعدة بيانات المصدر والتحقق على خرج شبكة ملائمة المظهر التي تخلق صور جديدة من خلال دمج محتوى صور المصدر مع شكل صور الهدف Rendering.
- الحالة الثالثة : التدريب على خرج شبكة ملائمة المظهر وهي صور جديدة تدمج محتوى صور الهدف مع شكل مجال المصدر والتحقق على قاعدة بيانات الهدف.
- الحالة الرابعة: التدريب على خرج شبكة ملائمة المظهر التي تخلق صور جديدة بدمج محتوى صور الهدف مع شكل مجال المصدر والتحقق على خرج شبكة ملائمة المظهر التي تخلق صورها من خلال دمج محتويات صور المصدر بشكل المجال الهدف.
حتى نستطيع تحليل النتائج ومقارنة الحالات السابقة نستخدم مقياس التقييم الأشهر متوسط التداخل عبر الوحدات the mean of Intersection over Union (mIoU) الذي يقوم بحساب الفرق بين الوحدات الحقيقية والوحدات الناتجة عن الموديل الذي نريد اختباره، في حالتنا هنا شبكات كاملة الطَيَ، ملائمة المظهر وملائمة التمثيل. تعبر الأرقام في العمود الثالث من الجدول رقم (2) عن متوسط التداخل عبر الوحدات بدون استخدام شبكة ملائمة التمثيل. بينما تمثل الأعداد في العمود الرابع المتوسط نفسه ولكن مع استخدام شبكة ملائمة التمثيل.
يظهر تحليل النتائج أن استخدام شبكة ملائمة التمثيل يحسن الدقة (الأرقام في العمود الرابع أكبر من مثيلاتها في العمود الثالث) كما يظهر أنّ استخدام شبكة ملائمة المظهر يزيد من قيمة متوسط التداخل عبر الوحدات (الأعداد في السطر الاول أصغر من مثيلاتها في باقي الأسطر).
وبالتالي فإن شبكتي ملائمة المظهر وملائمة التمثيل تكملان بعضهما البعض و تعملان معاً على إعطاء نتائج أفضل كما يمكن ملاحظة أن استخدام شبكة ملائمة المظهر في مرحلة التدريب أعطى أعظم قيمة لمتوسط التداخل 46.21

يوضح الشكل (9) النتائج النوعية لاستخدام شبكة ملائمة المظهر حيث أنّ إشباع الألوان saturation أصبح أقل عندما وضعنا الصور من لعبة جي-تي-اي GTA هي مجال المصدر و صور سيتي-سكيب Cityscape هي مجال الهدف. ويصبح أعلى في الحالة المعاكسة ولكن في الحالتين المظهر صار أفضل وأوضح.

خاتمة
تكلمنا في هذا المقال عن أهمية التجزئة الدلالية (إسناد كل بكسل في الصورة إلى صنف معين) في مجال الرؤية الحاسوبية وكيف قمنا بتصنيف قواعد البيانات الخاصة بها بحسب الهدف من إنشاءها إلى قواعد بيانات صور لأشياء خارج وداخل الأماكن المغلقة. ناقشنا بعد ذلك مشكلة محدودية هذه القواعد التي تسببها الكلفة العالية في الوقت والجهد للحصول على الصور المشروحة على مستوى البكسل وتوصلنا إلى حلها عن طريق استخدام صور من الواقع الافتراضي حيث قمنا بشرح قاعدة البيانات الصناعية سينزيا والتي تحوي على صور مأخوذة من مدينة افتراضية تم إنشاءها باستخدام منصة يونيتي. ثم وجدنا أن استخدام صور من الواقع الافتراضي يسبب لنا مشكلة انحياز هي مشكلة تغيير المجال والتي تغلبنا عليها عن طريق استخدام شبكات ملائمة كاملة الطّيّ والاستفادة من صور عالم ألعاب الحاسب. أخيراً قمنا بعمل تجارب عديدة وعرضنا نتائجها الكمية والنوعية حيث تم إثبات أن استخدام صور من العالم الافتراضي أدى إلى تحسين الأداء وأن استخدام شبكات الملائمة كاملة الطَيّ أدت إلى حل مشكلة تغيير المجال.
المراجع
- Ros, G., Sellart, L., Materzynska, J., Vazquez, D., Lopez, A.: The SYNTHIA Dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2016)
- Zhang, Y., Qiu, Z., Yao, T., Liu, D., Mei, T.: Fully convolutional adaptation networks for semantic segmen-tation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (June 2018)
- P. K. Nathan Silberman, D.H., Fergus, R.: Indoor segmentation and support inference from rgbd images, Eur. Conf. on Computer Vision (ECCV) (2012)
- R. Mottaghi, X. Chen, X.L.N.G.C.S.W.L.S.F.R.U., Yuille, A.: The role of context for object detection and semantic segmentation in the wild., In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2014)
- T.-Y. Lin, M. Maire, S.B.J.H.P.P.D.R.P.D., Zitnick, C.L.: Microsoft coco: Common objects in context., In Eur. Conf. on Computer Vision (ECCV) (2014)
- G. J. Brostow, J.F., Cipolla, R.: Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters. (2009)
- A. Geiger, P. Lenz, C.S., Urtasun, R.: Vision meets Robotics: The KITTI Dataset, Intl. J. of Robotics Research (2013)
- M. Cordts, M. Omran, S.R.T.S.M.E.R.B.U.F.S.R., Schiele., B.: The cityscapes dataset, In CVPR, Workshop (2015)
- I. J. Goodfellow, J. Pouget-Abadie, M.M.B.X.D.W.F.S.O.A.C., Bengio, Y.: Generative adversarial nets, NIPS (2014)
- J. Long, E.S., Darrell, T.: Fully convolutional adaptation networks for semantic segmentation, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2015)
- B. C. Russell, A. Torralba, K.P.M., Freeman, W.T.: LabelMe: a database and web-based tool for image annotation, Intl. J. of Computer Vision (2008)
- Bileschi, S.: CBCL StreetScenes challenge framework. (2007)
- S. R. Richter, V. Vineet, S.R., Koltun, V.: Playing for data: Ground truth from computer games, ECCV (2016)




