التدّقيق العلمي: د.م. حسن قزّاز، م. محمّد سرميني
التدّقيق اللّغوي: هبة الله فلّاحةِ
المَحتويَات
المقدّمة:
خلال العقود القليلة الماضية، ومع ظهور يوتيوب youtube، أمازون Amazon و نيتفليكس Netflix وخدمات الشّبكة العنكبوتيّة الأخرى، ظهرت أنظمة التّوصية recommendation systems واحتلّت مكانًا كبيرًا في حياتنا، ابتداءً من التّجارة الإلكترونيّة (اقتراح توصيات على الزّبائن بالبضائع التي قد تهمّهم) إلى الإعلان عبر الشّبكة العنكبوتيّة (اقتراح توصيات على المستخدمين بالمحتويات التي تطابق تفضيلاتهم)، وهكذا لم يعد هناك مفرًّا من أنظمة التّوصية في رحلاتنا اليوميّة عبر الشّبكة. في هذه المقالة، سنتطرّق إلى نماذج مختلفة لأنظمة التّوصية؛ سوف نشرح كيفيّة عمل كلّ نموذج، و أساسه النّظريّ ومناقشة نقاط القوّة والضّعف لديه.
1- ما المقصود بأنظمة التّوصية؟
بصورة عامّة أنظمة التّوصية هي عبارة عن خوارزميّات تهدف إلى اقتراح عنصر ذي صلة بالمستخدم (مثل أفلام أو مقالات أو بضائع حسب الخدمة المستخدمة).
وتعدّ أنظمة التّوصية أمرًا بالغ الأهمّيّة في بعض الصّناعات، لأنّها تستطيع تحصيل مقدار كبير من الدّخل عندما تكون فعّالة وتحقّق التّميز عن المنافسين وكمثال على أهمّيتها؛ ما حدث قبل بضع سنوات حيث قامت نيتفلكس Netflix بتنظيم تحدّي تصميم نظام توصية يتفوّق على نظامهم الخاصّ بها مع جائزة مليون دولار للفائز.
2- أنواع أنظمة التّوصية:
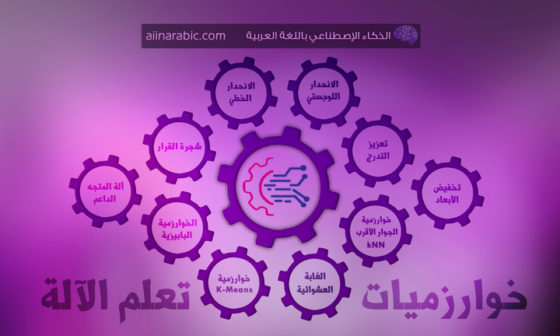
هناك طريقتان أساسيّتان في أنظمة التّوصية وهما طرق التّصفية التّعاونيّة collaborative filtering methods والطّرق القائمة على المحتوى content based methods، سنتعرّف عليهما قبل الغوص في أعماق كلّ منهما على حدة.
1-2- طرق التّصفية التّعاونيّة Collaborative Filtering Methods:
تعتمد هذه الطّرق على التّفاعلات السّابقة المسجّلة بين المستخدمين والعناصر بهدف اقتراح توصيات جديدة للمستخدمين، ويتمّ تخزين هذه التّفاعلات فيما يسمّى (مصفوفة تفاعلات مستخدم-عنصر) (user-item interactions matrix) والموضّحة في الشّكل (1).

إنّ الفكرة الرّئيسيّة التي تحكم هذه الطّريقة؛ أنّ تلك التّفاعلات كافية لاكتشاف المستخدمين المتشابهين والعناصر المتشابهة بناءً على هذه التّقريبات المقدّرة.
تنقسم خوارزميّات التّصفية التّعاونيّة إلى فئتين فرعيّتين؛ هما طريقة قائمة على الذّاكرة memory-based approach و طريقة قائمة على النّموذج model-based approach.
أقسام الطّرق التّعاونيّة:
أوّلًا: طريقة قائمة على الذّاكرة:
تتعامل بشكل مباشر مع التّفاعلات المُسجّلة _تفترض عدم وجود نموذج_ وتعتمد على البحث عن أقرب جوار Nearest Neighbor (مثلًا تبحث عن أقرب جوار لمستخدم ذي اهتمامات معيّنة وتقترح العناصر الأكثر شيوعًا بين هؤلاء الجيران).
ثانيًا: طريقة قائمة على النّموذج:
تفترض وجود نموذج “توليديّ” له حقّ الأوّلية؛ حيث أنّه يفسّر تفاعلات مستخدم-عنصر ويحاول اكتشافها بهدف تنبّؤ التّفاعلات الجديدة ويوضّح الشّكل (2) أقسام طرق التّصفية التّعاونيّة.
ونلاحظ أنّه في الطّريقة القائمة على الذّاكرة سيتمّ البحث عن الجوار الأقرب عبر متّجهات متناثرة ضخمة من خلال مصفوفة التّفاعلات، بينما في الطّريقة القائمة على النّموذج سيتمّ ذلك على متّجهات صغيرة كثيفة كما سنرى لاحقًا من خلال تفكيك المصفوفة .

مميّزات وعيوب الطّرق التّعاونيّة:
لميزة الأساسيّة للطّرق التّعاونيّة أنّها لا تتطلّب معلومات حول المستخدمين أو العناصر، وبالتّالي يمكن استخدامها في العديد من الحالات.
بالإضافة إلى أنّه كلّما ازداد تفاعل المستخدمين مع العناصر كلّما ازدادت دقّة التّوصيات المقترحة، لذلك بالنّسبة إلى مجموعة ثابتة من المستخدمين والعناصر تجلب التّفاعلات المُسجّلة عبر الزّمن معلومات جديدة ممّا يجعل نظام التّوصية أكثر فعاليّة.
ومع ذلك، فإنّ الطّرق التّعاونيّة لا تخلو من العيوب لأنّها لا تأخذ في عين الاعتبار سوى التّفاعلات السّابقة لذلك فهي تعاني من “مشكلة البداية الباردة”؛ تتمحور هذه المشكلة حول المستخدمين الجدد والعناصر الجديدة و حتّى المستخدمين أو العناصر الذين لديهم تفاعلات قليلة جدًّا، إذًا كيف لهذه الطّريقة أن تتنبّأ بتوصيات مناسبة لهؤلاء من دون أن يكون لديها تفاعلات مسبقة عنهم؟!
يمكن التّعامل مع هذا العيب بطرق مختلفة منها:
1- الاستراتيجيّة العشوائيّة: التّوصية بعناصر عشوائيّة للمستخدمين الجدد أو عناصر جديدة لمستخدمين عشوائيّين.
2-استراتيجيّة التّوقّع الأقصى: التّوصية بالعناصر الشّائعة للمستخدمين الجدد أو العناصر الجديدة للمستخدمين الأكثر نشاطًا.
3-الاستراتيجيّة الاستكشافيّة: التّوصية بمجموعة من العناصر المتنوّعة للمستخدمين الجدد أو عنصر جديد لمجموعة من المستخدمين المختلفين.
4-استخدام طريقة غير تعاونيّة لبداية نشاط المستخدم والعنصر الجديدين.
والآن سننتقل للحديث عن الطّريقة الثّانية في أنظمة التّوصية وهي:
2-2- الطّرق القائمة على المحتوى content based methods:
على عكس الطّرق التّعاونيّة التي تعتمد فقط على تفاعلات عنصر-مستخدم، تستخدم الطّرق القائمة على المحتوى معلومات إضافيّة حول المستخدمين و/ أو العناصر.
ومن أوضح الأمثلة على هذه الطّرق نظام التّوصية بالأفلام، فيمكن أن تكون هذه المعلومات الإضافيّة مثلًا العمر أو الجنس أو الوظيفة أو أيّ معلومات شخصيّة أخرى (للمستخدمين)، بالإضافة إلى الفئة أو الممثّلين الرئيسيّين أو المدّة أو الخصائص الأخرى للأفلام (العناصر).
إنّ الفكرة الرّئيسيّة التي تحكم هذه الطّريقة هي محاولة بناء نموذج قائم على “الميزات features” المتاحة التي تفسّر التّفاعلات التي تمّ تسجيلها بين المستخدم والعنصر.
لنرجع إلى مثال الأفلام السّابق، كلّنا يعلم أنّ الشّابات لهنّ تفضيل في الأفلام مختلف عن تفضيل الشّباب مثلًا، وهكذا إذا استطعنا بناء نموذج نعرف فيه تفضيلات المستخدمين حسب (العمر،الجنس،…) سيصبح التنبّؤ بالتّوصيات سهلًا للغاية؛ بحيث أنّنا نحتاج فقط إلى إلقاء نظرة على الملفّ الشّخصيّ لهذا المستخدم لنعرف تفضيلاته، وبناءً عليها نقترح عليه التّوصيات المناسبة له والشّكل (3) يوضّح الطّرق القائمة على المحتوى.

إذا عقدنا مقارنة بين الطّرق التّعاونيّة والطّرق القائمة على المحتوى، فإنّ الأخيرة تعاني بدرجة أقلّ بكثير من مشكلة البداية الباردة، لأنّها تقترح توصيات للمستخدمين الجدد من خلال معلومات المحتوى، لكن سوف تقتصر المشكلة على المستخدمين والعناصر الجدد ذوي الميزات غير المرئيّة، لكن بمجرّد أن يصبح النّظام قديمًا بما يكفي ستكون هذه المشكلة نادرة الحدوث.
النّماذج، الانحياز والتّباين:
الانحياز والتّباين أحد أهمّ المصطلحات في النّمذجة الإحصائيّة، كذلك في تعلّم الآلة.
ليست كُلّ العيّنات بنفس الصّفات؛ لذلك عندما يكون لدينا عيّنتان مُختلفتان فإنّنا سنبني نماذج مُختلفة قليلًا عن بعضها وهذا هو مفهوم التّباين.
أما الانحياز فهو مدى اختلاف القيمة المتوقّعة لكلّ التنبّؤات عن القيم الحقيقيّة.
لنلقِ نظرة على الاختلافات الرّئيسية بين الطّرق السّابقة وبشكل خاصّ تأثير مستوى نمذجتها الضّمنيّة على الانحياز والتّباين.
- في الطّرق التّعاونيّة ذات النّهج القائم على الذّاكرة لا يتمّ افتراض أيّ نموذج ضمنيّ، بحيث تتعامل الخوارزميّات مع تفاعلات مستخدم-عنصر بشكل مباشر، وكمثال على ذلك يتمّ تمثيل المستخدمين عبر تفاعلاتهم مع العناصر ويتمّ البحث عن أقرب جوار لهذا التّمثيل من أجل اقتراح التّوصيات.
وبما أنّه لا يوجد أيّ نموذج ضمنيّ فهذه الطّرق نظريًّا لها انحياز منخفض وتباين كبير.
- في الطّرق التّعاونيّة ذات النّهج القائم على النّموذج يتمّ افتراض بعض النّماذج الضّمنيّة، بحيث يتمّ تدريب النّموذج على إعادة بناء قيم تفاعلات مستخدم-عنصر من تمثيله الخاصّ للمستخدمين والعناصر، ومن ثمّ يتمّ اقتراح توصيات جديدة اعتمادًا على النّموذج.
إنّ هذه التّمثيلات الضّمنيّة للمستخدمين والعناصر لها معنى رياضيّ يصعب تفسيره للإنسان؛ لأنّه يفترض نموذجًا (مجانيًّا) للتّفاعلات بين المستخدمين والعناصر، لذا هذه الطّرق لها نظريًّا تحيّز أعلى وتباين أقلّ من الطّرق التي تفترض عدم وجود نموذج ضمنيّ.
- في الطّرق القائمة على المحتوى يتمّ أيضًا افتراض بعض النّماذج الضّمنيّة، لكنّ الفرق هنا أنّه يتمّ تزويد هذه النّماذج بمحتوًى يحدّد تمثيل المستخدمين و/ أو العناصر.
على سبيل المثال، يتمّ تمثيل المستخدمين بناءً على ميزات معيّنة، ويتمّ محاولة نمذجة لكلّ عنصر ونوع الملفّ الشّخصيّ للمستخدمين الذين يفضّلون هذا العنصر أم لا.
ويجدر بنا ملاحظة أنّ النّماذج هنا أكثر تقييدًا من الطّرق التّعاونيّة القائمة على النّموذج (بسبب تقديم تمثيل للمستخدمين و/ أو العناصر)؛ وبالتّالي فإنّ الانحياز هنا أعلى والتّباين أقلّ.
3-2- الطّرق الهجينة Hybrid methods:
في هذه الطّرق يتمّ الدّمج بين طرق التّصفية التّعاونية والطّرق القائمة على المحتوى، والشّكل (4) يوضّح خوارزميّات أنظمة التّوصية.

3- نظرةٌ أعمق عن أنواع أنظمة التّوصيّة:
الآن وبعد أن أخذنا فكرة عامّة عن خوارزميّات أنظمة التّوصية وأنواعها وكيفيّة عملها سنغوص في أعماق كلّ نوع منها على حدة، أدعوك عزيزي القارئ أن تشاركنا في هذه الرّحلة الممتعة.
1-3- الطرق التّعاونيّة القائمة على الذّاكرة:
الخصائص الرّئيسيّة لطرق مستخدم-مستخدم user-user و عنصر-عنصر item-item؛ أنّها تستخدم فقط مصفوفة تفاعلات مستخدم-عنصر ولا تفترض أيّ نموذج لاقتراح توصيات جديدة.
طريقة مستخدم-مستخدم:
من أجل اقتراح توصيات جديدة لمستخدم ما، تحاول طريقة مستخدم-مستخدم تحديد مستخدمين لديهم (ملفّ التّفاعلات) الأكثر تشابهًا (أقرب الجوار) بهدف اقتراح العناصر الأكثر شيوعًا بين هؤلاء الجيران (وهذه العناصر جديدة للمستخدم).
تتمحور هذه الطّريقة حول المستخدم “user-centred مركزيّة المستخدم” لأنّها تمثّل المستخدمين بناءً على تفاعلاتهم مع العناصر وتقييم المسافات بين المستخدمين.
لنفترض أنّنا نريد اقتراح توصيات لمستخدم (س)؛ أوّلًا يمكن تمثيل كلّ مستخدم بمتّجه تفاعلاته مع العناصر المختلفة (الصّفّ الخاصّ بالمستخدم في مصفوفة التّفاعلات)، ومن ثمّ نستطيع حساب نوع من “التّشابه” بين المستخدم (س) وبقيّة المستخدمين.
مقياس التّشابه هنا هو أنّ اثنين من المستخدمين ذوي تفاعلات متشابهة على نفس العناصر، يجب اعتبارهما قريبين من بعضهما.
بمجرّد الانتهاء من حساب التّشابه بين كلّ المستخدمين، نستطيع الاحتفاظ بأقرب جوار للمستخدم (س) واقتراح العناصر الأكثر شيوعًا بينهم (وهنا نقصد فقط العناصر التي لم يتفاعل معها هذا المستخدم بعد).
نلاحظ أنّه عند حساب التّشابه بين المستخدمين يجب أن نراعي بعناية عدد التّفاعلات المشتركة (كم من العناصر تمّ التّفاعل معها من نفس المستخدمين).
في الواقع، أنّنا في معظم الأوقات نريد أن نتجنّب أن يكون مستخدم ما لديه تفاعل واحد مشترك مع المستخدم المدروس وأن يعتبر مطابق 100%؛ بل ويعتبر “أقرب” من مستخدم لديه 100 تفاعل مشترك (ويوافق على 98% فقط منهم).
لذلك نحن نعتبر أنّ المستخدمين متشابهون إذا تفاعلوا مع الكثير من العناصر المشتركة بنفس الطّريقة (تقييم مشابه، تصفّح في الوقت نفسه،…) والشّكل (5) يوضّح طريقة مستخدم-مستخدم.

طريقة عنصر-عنصر:
من أجل اقتراح توصيات جديدة لمستخدم ما، تحاول طريقة عنصر-عنصر إيجاد عناصر مشابهة لتلك التي تفاعل معها المستخدم “بطريقة إيجابيّة”، يعتبر العنصران متشابهَين إذا تفاعل معهما المستخدمون بطريقة مماثلة.
تتمحور هذه الطّريقة حول العنصر “item-centred مركزيّة العنصر” لأنّها تمثّل العناصر بناء على تفاعلات المستخدمين معهم وتقييم المسافات بين هذه العناصر.
لنفترض أنّنا نريد اقتراح توصيات لمستخدم (س)؛ أوّلًا يمكن تمثيل العنصر الأكثر تفضيلًا من قبل المستخدم _مثل كلّ العناصر_بمتّجه التّفاعلات معه من قبل كلّ المستخدمين (العمود الخاصّ بالمستخدم في مصفوفة التّفاعلات) ومن ثمّ نستطيع حساب نوع من “التّشابه” بين أفضل عنصر وبقيّة العناصر.
بمجرّد الانتهاء من حساب التّشابه نستطيع الاحتفاظ بأقرب جوار لأفضل عنصر؛ بحيث أنّ هذه العناصر جديدة على المستخدم (س) ومن ثمّ التّوصية له بهذه العناصر.
نلاحظ أنّه من أجل الحصول على توصيات مُفضّلة، نستطيع النّظر إلى n العناصر المفضّلة للمستخدم بدلًا من عنصر مفضّل واحد فقط، وفي هذه الحالة يمكننا التّوصية بالعناصر الأقرب من العديد من العناصر المفضّلة والشّكل (6) يوضّح طريقة عنصر-عنصر.

مقارنة بين (مستخدم-مستخدم) و (عنصر-عنصر):
تعتمد طريقة مستخدم-مستخدم على البحث عن المستخدمين المتشابهين من حيث التّفاعلات مع العناصر، ولأنّ كلّ مستخدم تفاعل مع عدد قليل من العناصر فإنّ الطريقة حسّاسة جدًّا لأيّ تفاعلات مسجّلة (تباين كبير)، ومن ناحية أخرى فإنّ التّوصيات النّهائيّة للمستخدم المدروس تعتمد فقط على التّفاعلات المسجّلة للمستخدمين المشابهين له ممّا يؤدّي إلى نتائج أكثر تخصيصًا (انحياز منخفض) كما هو مُبيّن في الجدول (1).
على العكس من ذلك، تعتمد طريقة عنصر-عنصر على البحث عن العناصر المتشابهة من حيث تفاعلات المستخدمين، ولأنّ الكثير من المستخدمين تفاعلوا مع عنصر ما، فإنّ البحث عن الجوار سيكون أقلّ حساسيّة من التّفاعلات الفرديّة (تباين أقلّ).
وبالنّسبة للتّوصيات النّهائيّة فإنّها تأخذ بعين الاعتبار تفاعلات كافّة أنواع المستخدمين _حتى المختلفين عن المستخدم المدروس_ لذلك تعتبر هذه الطّريقة أقلّ تخصيصًا (انحياز أعلى) كما هو مُبيّن في الجدول (1)؛ وبالتّالي فإنّ طريقة عنصر-عنصر أقلّ تخصيصًا من طريقة مستخدم-مستخدم ولكنّ الأخيرة أكثر قوّة.
الجدول (1) مقارنة بين طريقتي مستخدم-مستخدم و عنصر-عنصر من حيث الانحياز والتّباين
| طريقة عنصر -عنصر | طريقة مستخدم_مستخدم | |
| كبير | منخفض | الانحياز |
| منخفض | كبير | التباين |
والشّكل (7) يوضّح الفرق بين طريقة مستخدم-مستخدم وطريقة عنصر-عنصر.

التّعقيد والآثار الجانبيّة:
أحد أكبرعيوب خوارزميّة التّصفية التّعاونيّة القائمة على الذّاكرة؛ هي أنّها غير قادرة على التّوسّع بسرعة، بحيث أنّها تحتاج وقتًا طويلًا لتوليد توصيات لنظام ضخم.
في الواقع، لأنظمة بملايين المستخدمين وملايين العناصر ستكون خطوة البحث عن أقرب جوار صعبة الحلّ إذا لم يتمّ تصميمها بعناية (خوارزميّة الجوار الأقرب KNN لها تعقيد (O(ndk مع n عدد المستخدمين، وd عدد العناصر وk عدد الجيران المعتبرين).
ولكي نجعل العمليّات الحسابيّة أكثر قابليّة للتّتبّع للأنظمة الضّخمة، يمكننا الاستفادة من تباين مصفوفة التّفاعلات عند تصميم الخوارزميّة أو استخدام طرق الجيران التّقريبيّة Approximate Nearest Neighbours (ANN).
علينا أن نتوخّى الحذر في معظم خوارزميّات التّوصيات من تأثير “الثّريّ يصبح أكثر ثراءً” للعناصر الشّائعة والحذر من أن يعلق المستخدمون في ما يسمّى “منطقة حجز المعلومات”.
بعبارة أخرى، لا نريد من النّظام أن يستمر باقتراح توصيات فقط بالعناصر الشّائعة، أو أن يتلقّى المستخدمون توصيات بعناصر شديدة القرب من العناصر التي فضّلوها من غير أن تتاح لهم الفرصة أن يتعرّفوا على عناصر قد يفضّلونها أيضًا؛ لأنّها قد تكون ليست بهذا القرب ليتمّ التّوصية بها.
يمكن أن تظهر هذه المشكلات في معظم خوارزميّات التّوصية، لكنّها تظهر بشكل خاصّ في خوارزميّة التّصفية التّعاونيّة القائمة على الذّاكرة وبشكل متكرّر؛ والسّبب يعود إلى عدم وجود نموذج للتّنظيم.
2-3- الطّرق التّعاونيّة القائمة على النّموذج:
تعتمد هذه الطّريقة على معلومات تفاعلات مستخدم-عنصر وتفترض نموذجًا ضمنيًّا ليشرح هذه التّفاعلات،
على سبيل المثال تتكوّن خوارزميّات تفكيك المصفوفة من تحليل مصفوفة تفاعلات مستخدم-عنصر الضّخمة والمتناثرة إلى منتج من مصفوفتين صغيرتين وكثيفتين وهو:
مصفوفة مستخدم-عامل user-factor (التي تتكوّن من تمثيلات المستخدمين) التي تضرب بمصفوفة عامل-عنصر factor-item (التي تتكوّن من تمثيلات العناصر).
تفكيك المصفوفة matrix factorisation :
الافتراض الرّئيسيّ وراء تفكيك المصفوفة هو أنّنا نستطيع من خلالها تمثيل المستخدمين والعناصر على حدٍّ سواء، بحيث أنّه يمكن الحصول على التّفاعل بين المستخدم والعنصر عن طريق حساب الجداء السّلميّ للمتّجهات الكثيفة؛ مصفوفة مستخدم-عامل (تمثيلات المستخدمين) بمصفوفة عامل-عنصر(تمثيلات العناصر).
على سبيل المثال، لنفترض أنّ لدينا مصفوفة تقييم مستخدم-فيلم ومن أجل نمذجة التّفاعلات بين المستخدمين والافلام سنفترض ما يلي:
يوجد ميزات تصف بوضوح الأفلام الجيّدة، وهذه الميزات يمكن أن تُستخدم أيضًا في وصف تفضيلات المستخدم (قيم عالية للميزات التي أحبّها المستخدم وقيم منخفضة بخلاف ذلك).
ولكنّنا لا نريد إعطاء هذه الميزات إلى النّموذج بشكل مباشر، بل نفضّل أن يكتشفها بنفسه وأن يصنع تمثيلاته الخاصّة للمستخدمين والعناصر.
وبما أنّ هذه الميزات يتعلّمها النّموذج لوحده فيصعب علينا فهمها بشكل فرديّ بل يكاد يستحيل ذلك؛ لأنّ معناها رياضيّ أكثر من أن يكون معنويًّا، لكنّ النّتائج ستكون قريبة من المعنى المعنويّ الذي يمكننا أن نفكر فيه.
وستكون النّتائج أنّ المستخدمين القريبين والعناصر المتشابهة من حيث الخصائص ستكون تمثيلاتهم متقاربة أيضًا، والشّكل (8) يوضّح طريقة تفكيك المصفوفة.

الأساسُ الرّياضيّ لتفكيك المصفوفة:
في هذه الفقرة سنقدّم لمحة رياضيّة بسيطة عن تفكيك المصفوفة، بشكل خاصّ سوف نقوم بوصف نهج تكراريّ كلاسيكيّ يعتمد على الانحدار التّدريجيّ؛ الذي يمكّننا من الحصول على عوامل لمصفوفات ضخمة دون تحميل جميع البيانات في نفس الوقت في ذاكرة الحاسوب.
لنفترض أنّه لدينا مصفوفة تفاعلات (M(nxm وهي عبارة عن تقييمات، ولكنّ هذه التّقييمات قليلة حيث أنّه تمَّ تقييم بعض العناصر فقط مِن قِبل جميع المستخدمين.
نريد تحليل هذه المصفوفة إلى عوامل كما يلي :

حيث X هي “مصفوفة المستخدم (nxl)” تمثّل صفوفها المستخدمين n وحيث Y هي “مصفوفة العنصر (mxl)” تمثّل صفوفها العناصر m:

يعبّر الرّمز I هنا عن بُعد المساحة الضّمنيّة التي سيتمّ فيها تمثيل المستخدمين والعناصر.
وبناءً عليه نريد الحصول على أفضل التّمثيلات للتّفاعلات من خلال البحث عن أفضل مصفوفتين X,Y واللّتين تحقّقان أفضل جداء سلميّ لهما والذي بدوره يقلّل خطأ إعادة التّشكيل قدر الإمكان، حيث أنَّ E هي عيّنات الأزواج (i,j) مثل M_ij وهي ذات قيمة محدّدة وليست “لا شيء None”.
هدفنا هو إيجاد المصفوفتين X و Y بحيث تحدّدان “خطأ إعادة بناء التّقييم” بأقلّ ما يمكن.

بإضافة عامل التّنظيم regularization factor λ وبالقسمة على 2 نحصل على:

يمكن بعد ذلك الحصول على المصفوفتين X و Y بعد إجراء خوارزميّة التّحسين (الانحدار التّدريجيّ gradient descent) ونلاحظ:
- أوّلًا أنّه لا يلزم حساب الانحدار التّدريجيّ على جميع الأزواج الموجودة في E في كلّ خطوة، حيث يمكننا فقط النّظر إلى مجموعة فرعيّة من هذه الأزواج ونقوم بعمليّة التّحسين “عن طريق الدُّفعة by batch”.
- ثانيًا لا يلزم تحديث القيم في X و Y تزامنيًّا ويمكن إجراء الانحدار التّدريجيّ بدلًا من ذلك على X و Y في كلّ خطوة (عند القيام بذلك، تُعتبر المصفوفة ثابتة بينما تُحسّن الأخرى قبل القيام بالعكس في دورة التّكرار التّالية).
بمجرّد تحليل المصفوفة إلى عوامل، يصبح لدينا معلومات أقلّ يجب معالجتها، حيث يمكننا ببساطة ضرب متّجه المستخدم في أيّ متّجه عنصر بهدف اقتراح توصية جديدة.
لاحظ أنّه يمكننا أيضًا استخدام طرق مستخدم-مستخدم و عنصر-عنصر مع هذه التّمثيلات الجديدة للمستخدمين والعناصر،
(تقريبيًّا) لن يتمّ إجراء عمليّات البحث عن الجوار الأقرب عبر متّجهات متناثرة ضخمة بل على متّجهات صغيرة كثيفة ممّا يجعل بعض تقنيّات التّقريب أكثر قابليّة للمراقبة.
امتدادات تفكيك المصفوفة:
إنّ المفهوم الأساسيّ عن تفكيك المصفوفة يمكنه أن يمتدّ لنماذج أعقد.
مثلاً، لنتحدّث عن شبكة عصبونيّة تقوم بعمليّة “التّحليل” decomposition .
تستخدم معظم أنظمة التّوصية قيم تقييم صحيحة لتمثيل رأي المستخدمين على العناصر، ومن أجل ضبط مجال التنبّؤ إلى المجال [0, 1] يتمّ استبدال الجداء الدّاخليّ الخطّيّ البسيط وذلك من خلال تمرير هذا الجداء عبر تابع غير خطّيّ أو تابع لوجستيّ logistic function.

مع استخدام التّابع اللّوجستيّ (.)f من الممكن استخدام نماذج شبكات عصبونيّة عميقة من أجل تحقيق أداء أنظمة توصية معقّدة، والشّكل (9) يوضّح مفهوم تفكيك المصفوفة.

3-3- الطّرق القائمة على المحتوى:
في ما سبق ناقشنا بشكل أساسيّ طرق مستخدم-مستخدم، عنصر-عنصر وتفكيك المصفوفة، ووجدنا أنّ هذه الطّرق تعتمد على مصفوفة التّفاعلات أي أنّها تنتمي إلى طرق التّصفية التّعاونيّة، أمّا الآن لنناقش الطّرق القائمة على المحتوى.
في الطّرق القائمة على المحتوى، يتمّ طرح مشكلة التّوصية على أنّها مشكلة تصنيف (تنبّؤ هل المستخدم يفضّل عنصرًا ما أم لا)، أو مشكلة توقّع (التنبّؤ بالتقييم المُعطى من المستخدم على العنصر) وفي الحالتين سوف نقوم بوضع نموذج يعتمد على ميزات المستخدم أو/ و العنصر.
طريقة مركزيّة العنصر:
إذا كان التّصنيف أو التّوقّع معتمدًا على ميزات المستخدمين نقول أنّ الطريقة مركزيّة العنصر، وحينها تتمّ عمليّات النّمذجة والتّحسين والحسابات من خلال العنصر.
في هذه الحالة، نقوم ببناء نموذج للعناصر ونعلّمه ميزات المستخدمين في محاولة للجواب على السّؤال التّالي : “ما هي احتماليّة أن يفضّل كلّ مستخدم هذا العنصر؟” أو “ما هو التّقييم المقدّم من كلّ مستخدم على هذا العنصر؟ (من أجل التّوقع Regression)”
إنّ النّموذج المرتبط بكلّ عنصر يتدرّب بشكل طبيعيّ على البيانات المرتبطة بهذا العنصر، وهكذا نصل إلى نموذج قويّ عندما يتفاعل الكثير من المستخدمين مع العنصر.
ومع ذلك فإنّ التّفاعلات التي يتعلّم منها النّموذج تأتي من كلّ مستخدم، وحتى إن كانوا بشخصيّات (ميزات) متشابهة إلّا أنّ تفضيلاتهم قد تختلف.
وهذا يعني أنّه حتّى وإن كانت هذه الطّريقة أكثر قوّة فيمكن اعتبارها على أنّها أقلّ تخصيصًا (أكثر انحيازًا) من طريقة مركزيّة المستخدم.
طريقة مركزيّة المستخدم:
وبالمقابل إذا كان التّصنيف أو التّوقّع معتمدًا على ميزات العناصر، نقول إنّ الطّريقة مركزيّة المستخدم، وحينها تتمّ عمليّات النّمذجة والتّحسين والحسابات من خلال المستخدم،
في هذه الحالة نقوم ببناء نموذج للمستخدمين ونعلّمه ميزات العناصر في محاولة للجواب على السّؤال التّالي : “ما هي احتماليّة أن يفضّل هذا المستخدم كلّ عنصر؟” أو “ما هو التّقييم المقدّم من هذا المستخدم على كلّ عنصر؟ (من أجل التوقع Regression)”.
وهكذا نحصل على نموذج لكلّ مستخدم متدرّب على بياناته، و يكون أكثر تخصيصًا من طريقة مركزيّة العنصر؛ لأنّه يأخذ بعين الاعتبار فقط المستخدم المدروس.
ولكن بأغلب الأوقات يتفاعل المستخدم مع عدد قليل من العناصر، وبهذا يكون النّموذج بهذه الطّريقة أقلّ قوّة من طريقة مركزيّة العنصر، والشّكل (10) يوضّح الفرق بين طريقة مركزيّة العنصر وطريقة مركزيّة المستخدم.

من وجهة نظر عمليّة، علينا الإشارة إلى أنّ طرح الأسئلة على المستخدمين الجدد _لا يرغب المستخدمون بالإجابة على الكثير من الأسئلة_ أكثر صعوبة من طرح الاسئلة حول العناصر الجدد؛ حيث يرغب النّاس بإضافة معلومات حول العناصر التي يضيفونها و ذلك للتّوصية بها للمستخدمين المهتمّين بشأنها.
ونلاحظ أنّ النّموذج قد يكون أكثر أو أقلّ تعقيدًا بناءً على النّموذج الأساسيّ الذي يتمّ البناء وفقه، فهو إمّا توقّع خطّيّ/لوجستيّ من أجل (التّوقع أو التّصنيف) أو شبكات العصبونيّة.
أخيرًا الطّرق القائمة على المحتوى يمكنها أن تكون مركزيّة العنصر أو مركزيّة المستخدم للنّماذج، ويمكن استخدام معلومات المستخدم والعنصر للنّماذج مثلًا عن طريق تكديس متّجه الميزات للطّريقة الأولى مع متّجه الميزات للطّريقة الثّانية، ومن ثمّ تمرير المتّجهات عبر بنية الشّبكات العصبونيّة.
المُصنّف الافتراضيّ/البايزي Bayesian مركزيّ العنصر:
أوّلاً لنفكّر في حالة التّصنيف مركزيّ العنصر، نريد أن ندرّب مصنّفًا افتراضيًّا/بايزي Bayesian لكلّ عنصر والذي يأخذ ميزات المستخدم كمدخلات وتكون المخرجات “يفضّل” أو “لا يفضّل”.
ولإتمام مهمّة التّصنيف علينا حساب:

النّسبة بين احتمال تفضيل مستخدم ميزات معيّنة بالعنصر المدروس واحتماليّة عدم تفضيله.
يمكن التّعبير عن هذه النّسبة من الاحتمالات الشّرطيّة التي تحدّد قاعدة التّصنيف (مع عتبة بسيطة) بصيغة بايز Bayes التّالية:




هي احتمالات أولية محسوبة من البيانات بينما

هي احتمالات يفترض بها أن تتبع التّوزيع الغاوسيّ Gaussian distribution مع العوامل ليتمّ تحديدها من البيانات.
يمكن عمل فرضيّات مختلفة حول مصفوفات التّباين لهذين التّوزيعين المحتملين (بدون افتراض، تَساوي المصفوفات، التّساوي في المصفوفات مع استقلاليّة السّمات) ممّا يؤدّي إلى نماذج مختلفة معروفة (تحليل تمييزيّ تربيعيّ، تحليل تمييزيّ خطّيّ، مصنّف naive Bayes).
يمكننا التّأكيد على أنّه يجب تقدير العوامل الاحتماليّة فقط، بناء على البيانات (التّفاعلات) المتعلّقة بالعنصر المدروس والشكل (11) يوضّح المصنّف البايزي القائم على المحتوى مركزيّ العنصر.

توقّع خطّيّ مركزيّ المستخدم:
لنفكّر في حالة التّوقّع مركزيّ المستخدم، نريد تدريب نموذج توقّع خطّيّ صغير لكلّ مستخدم، بحيث يأخذ ميزات العنصر على أنّها مدخلات ويخرج تقييم هذا العنصر.
مازلنا نشير إلى M مصفوفة تفاعلات مستخدم-عنصر، حيث تمثّل صفوفُ المصفوفة X عواملَ المستخدمين ليُتعلّم منها، وتمثّل صفوفُ المصفوفة Y ميزاتِ العناصر المعطاة.
وبهذا فإنّه لمستخدم i يتمّ تعلّم العوامل في X-i من خلال حلّ مشكلة التّحسين التّالية:

حيث i ثابتة وعمليّة الجمع الأولى تتعلّق فقط بزوج (مستخدم،عنصر) المتعلّقة بالمستخدم i.
يمكننا ملاحظة أنّه إذا تمّ حلّ هذه المشكلة لكلّ المستخدمين في نفس الوقت، فإنّ مشكلة التّحسين هي بالضّبط نفس المشكلة التي قمنا بحلّها في “تفكيك المصفوفة المتناوب” عندما نبقي العناصر ثابتة.
هذه الملاحظة تؤكّد الرّابط الذي ذكرناه في القسم الأوّل؛ نموذج قائم على طرق التّصفية التّعاونيّة (مثل تفكيك المصفوفة) ونموذج الطّرق القائمة على المحتوى، كلاهما يفترض نموذجًا ضمنيًّا لتفاعلات مستخدم-عنصر، ولكنّ النّموذج القائم على التّصفية التّعاونيّة يجب أن يتعلّم التّمثيلات الضّمنية لكلا المستخدمين والعناصر، أمّا الطّرق القائمة على المحتوى فإنّها تبني النّموذج بناءً على الميزات المحدّدة من قبل الإنسان للمستخدمين و / أو العناصر، والشّكل (12) يوضّح التّوقّع القائم على المحتوى مركزيّ المستخدم.

4- تقييم نظام التّوصية:
من أساسيّات مجال تعلّم الآلة وجود قدرة على تقييم الخوارزميّات لنستطيع تحديد الخوارزميّة المناسبة للحالة المدروسة.
لتقييم أداء أنظمة التّوصية لدينا مجموعتان من طرق التّقييم:
- تقييم قائم على مقاييس محدّدة.
- تقييم قائم على الحكم البشريّ ومدى الرّضى.
التّقييم القائم على المقاييس:
إذا كان نظام التّوصية قائمًا على نموذج يُخرج قيمًا رقميّة مثل التنبّؤ بالتّقييم أو احتمالات المطابقة، يمكننا تقييم جودة هذه المخرجات بطريقة كلاسيكيّة للغاية باستخدام مقياس قياس الخطأ على سبيل المثال، متوسّط الخطأ التّربيعيّ (MSE). في هذه الحالة يتمّ تدريب النّموذج فقط على جزء من التّفاعلات المتاحة ويتمّ اختباره على التّفاعلات المتبقيّة.
ومع ذلك، إذا كان نظام التّوصية الخاصّ بنا يعتمد على نموذج يتنبّأ بالقيم الرّقميّة، فيمكننا أيضًا ترميز هذه القيم باستخدام الطّريقة الكلاسيكيّة المعتمدة على عتبة _القيم فوق العتبة تُعتبر موجبة والتي تحتها تُعتبر سالبة_ وتقييم النّموذج بطريقة أكثر تصنيفيّة.
في الواقع بما أنّ بيانات تفاعلات مستخدم-عنصر الماضية هي أيضًا ثنائيّة (أو يمكن أن نجعلها ثنائيّة من خلال عتبة) ويمكن بعد ذلك تقييم الدّقة (إضافة إلى حساسيّة التنبّؤ recall وقيمة التنبّؤ الإيجابيّ precision) للمخرجات الثّنائيّة للنّموذج على بيانات اختبار من التّفاعلات التي لم تستخدم ضمن بيانات التّدريب.
أخيرًا، إذا اعتبرنا أنّ نظام التّوصية لا يعتمد على القيم الرّقميّة ويخرج فقط قائمة من التّوصيات _مثل مستخدم-مستخدم أو عنصر-عنصر يعتمد على خوارزميّة الجوار الأقرب_ فلا يزال بإمكاننا تحديد الدّقة من خلال مثلًا تقدير نسبة العناصر المُوصى بها والتي تناسب المستخدم المدروس حقًا.
لتقدير هذه الدّقة لا يمكننا أن نأخذ في عين الاعتبار العناصر المُوصى بها والتي لم يتفاعل معها المستخدم المدروس، بل فقط يجب النّظر في العناصر من مجموعة بيانات الاختبار التي لدينا تفاعلات المستخدم معها.
التّقييم القائم على الحكم البشريّ:
عند تصميم نظام توصية ليس علينا الاهتمام فقط بأن يكون النّموذج قادرًا على اقتراح توصيات واثقين من أنّها مناسبة، ولكن أيضًا علينا الاهتمام بأن يملك خصائص جيّدة أخرى مثل التّنوّع وإمكانيّة شرح هذه التّوصيات.
كما ذكرنا سابقًا في فقرة طرق التّصفية التّعاونيّة، نريد بالتّأكيد الابتعاد عن منطقة حجز المعلومات.
غالبًا يتمّ استخدام مفهوم “الصّدفة” للتّعبير عن مدى ميل النّموذج إلى إنشاء مثل هذه المنطقة (مدى تنوّع التّوصيات).
هذه الصّدفة التي يتمّ حسابها من خلال المسافة بين العناصر الموصى بها، لا يجب أن تكون صغيرة جدًّا لكي لا نعلق ضمن منطقة حجز المعلومات، ولا كبيرة جدًّا لكي لا نبتعد عن اهتمامات المستخدم وتفضيلاته عندما نقترح التّوصيات (الاستكشاف مقابل الاستثمار).
وبالتّالي من أجل تحقيق التنوّع في التّوصيات المقترحة، يجب أن نوصي بالعناصر التي تناسب المستخدم ولا تتشابه كثيرًا مع بعضها البعض.
قابليّة التّفسير هي نقطة النّجاح لخوارزميّة التّوصية، في الواقع تبيّن أنّ المستخدمين إذا لم يعرفوا لماذا تمّ اقتراح عنصر معيّن عليهم، سوف يفقدون الثّقة بنظام التّوصية؛ لذلك إذا صمّمنا نظام توصية قابلًا للتّفسير يمكننا _عند اقتراح توصية بعنصر ما_ إضافة جملة توضّح سبب اقتراح هذا العنصر (قام الأشخاص الذين تُتابعهم بالإعجاب بهذا العنصر، لقد أُعجبتَ بعنصرٍ مشابهٍ قبل ذلك …)
أخيرًا علاوة على حقيقة أنّ التنوّع وقابليّة التّفسير يمكن أن يصعب تقييمهما جوهريًّا، يمكننا أن نلاحظ أنّه من الصّعب أيضًا تقييم جودة التّوصية التي لا تنتمي إلى مجموعة بيانات الاختبار، كيفيّة معرفة ما إذا كانت التّوصية الجديدة ذات صلة قبل اقتراحها للمستخدم المدروس؟ لكلّ هذه الأسباب، قد يكون من المغري أحيانًا اختبار النّموذج في “ظروف حقيقيّة”.
ونظرًا لأنّ الهدف من نظام التّوصية هو إنشاء إجراء (مشاهدة فيلم، شراء منتج، قراءة مقال، إلخ …)، يمكننا بالفعل تقييم قدرته على إنشاء الإجراء المتوقّع، على سبيل المثال يمكن وضع النّظام كمنتج باتّباع طريقة اختبارA / B 2] ] (الهدف الرّئيسيّ لهذا الاختبار هو قياس التّغيير النّاتج عن تعديل متغيّر A وتحويله إلى متغيّر B)، أو يمكن اختباره فقط على عيّنة من المستخدمين ومع ذلك تتطلّب مثل هذه العمليّات وجود مستوًى معيّن من الثّقة في النّموذج.
5- تلخيص لأهمّ الأفكار السّابقة:
- يمكن تقسيم خوارزميّات التّوصية إلى طريقتين:
- الطّرق التّعاونيّة (مثل المستخدم-المستخدم، والعنصر، وتفكيك المصفوفة) التي تعتمد فقط على مصفوفة تفاعلات مستخدم-عنصر.
- الطّرق القائمة على المحتوى (مثل نماذج التّوقّع أو التّصنيف) التي تستخدم معلومات مسبقة عن المستخدمين و / أو العناصر.
- لا تفترض الطّرق التّعاونيّة القائمة على الذّاكرة أيّ نموذج ضمنيّ لذلك لها انحياز منخفض ولكن بتباين كبير.
- تفترض المناهج التّعاونيّة القائمة على النّموذج نموذجًا ضمنيًّا للتّفاعلات يحتاج إلى تعلّم تمثيلات المستخدمين والعناصر من نقطة الصّفر، لذلك لديها انحياز أعلى ولكن بتباين أقلّ.
- تفترض الطّرق القائمة على المحتوى أنّ نموذجًا ضمنيًّا يتمّ إنشاؤه حول المستخدمين و / أو ميزات العناصر المدروسة، وبالتّالي يكون لها انحياز أعلى وبتباين أقل.
- تزداد أنظمة التّوصية أهمّيّة أكثر فأكثر في العديد من الصّناعات الكبيرة، ويجب أن تؤخذ بعض اعتبارات المقاييس في الحسبان عند تصميم النّظام (استخدام أفضل للتّناثر والطّرق التّكرارية للعوامل أو عمليّة التّحسين، والتّقنيات التّقريبيّة للبحث عن الجوار الأقرب …)
- يصعب تقييم أنظمة التّوصية: إذا كان من الممكن استخدام بعض المقاييس الكلاسيكيّة مثل MSE أو الدّقّة accuracy أو حساسيّة التنبّؤ recall أو قيمة التنبّؤ الإيجابيّة precision، فيجب على المرء أن يضع في اعتباره أنّ بعض الخصائص المرغوبة مثل التّنوع (الصّدفة) وقابليّة التّفسير لا يمكن تقييمها بهذه الطّريقة؛ بل إنّ تقييم الظّروف الحقيقيّة (مثل اختبار A/B أو اختبار العيّنة) هو أخيرًا الطّريقة الحقيقيّة الوحيدة لتقييم نظام التّوصية الجديد، ولكنّه يتطلّب ثقة لا بأس بها في النّموذج.
يجب أن نشير إلى أنّنا لم نناقش الأساليب المختلطة في هذا المقال التّمهيديّ؛
نقصد الطّرق التي تجمع بين التّصفية التّعاونيّة والطّرق القائمة على المحتوى، والتب تحقّق نتائج متطوّرة في كثير من الحالات، لذلك تستخدم في العديد من أنظمة التّوصية على نطاق واسع في الوقت الحاضر.
يمكن أن يتّخذ المزيج الذي تمّ إجراؤه في الطّرق الهجينة شكلين أساسيّين:
حيث أنّه يمكننا إمّا تدريب نموذجين بشكل مستقلّ (نموذج تصفية تعاونيّ واحد ونموذج قائم على المحتوى) ودمج اقتراحاتهم، أو إنشاء نموذج واحد مباشرة _غالبًا شبكة عصبونية_ يوحّد كلا الطّريقتين باستخدام معلومات مسبقة كمدخلات حول المستخدم و / أو العنصر، بالإضافة إلى معلومات التّفاعلات “التّعاونيّة”.
6- قضايا أخلاقية متعلّقة بأنظمة التّوصية:
في الواقع هناك تأثير كبير من قبل أنظمة التّوصية على قراراتنا واختياراتنا، فمثلًا يوتيوب Youtube، فيسبوك Facebook، انستغرام instagram وغيرها الكثير من الخدمات التي قد يؤخذ عليها العديد من المعضلات الأخلاقيّة ومنها:
1- الإدمان: لقد تمّ إنشاؤها لتكون مسبّبة للإدمان، والغرض منها هو جذب اهتمام المستخدم والحفاظ عليه لفترات طويلة من الزّمن ليرى أكبر قدر ممكن من الإعلانات لتحقيق الرّبح.
2- التطرّف: حيث أنّ هذه الخدمات تقدم للمستخدم محتوى مخصّصًا بشكل متزايد ليستمرّ المستخدم بالمشاهدة، ولا توصي له باقتراحات من الأفكار المقابلة ممّا قد يزيد بتطرّف المستخدمين .
3- جمع البيانات الشخصيّة: تتطلّب التّوصيات المخصّصة عادةً جمع البيانات الشخصية لتحليلها، ممّا قد يجعل المستخدمين عرضة لمشاكل انتهاك الخصوصيّة.
مع تزايد سيطرة وسائل التّواصل الاجتماعيّ، تلعب خوارزميّات أنظمة التّوصية دورًا هائلًا في ما يشاهده النّاس، ولذلك يتوجّب على منشئي هذه الأنظمة فهم ومعالجة المشكلات الأخلاقيّة التي تهدّد المستخدمين.
7- الخاتمة:
أصبحت أنظمة التّوصية ضروريّة في العديد من المجالات، وبالتّالي حظيت دائمًا بمزيد من الاهتمام في السّنوات الأخيرة.
في هذه المقالة قدّمنا مفاهيم أساسيّة مطلوبة لفهم الأسئلة المتعلّقة بهذه الأنظمة بشكل أفضل، لكنّنا نشجّع القرّاء المهتمّين بشدّة على استكشاف هذا المجال بشكل أكبر …