- المقدّمة
- التكميم
- التمثيلات العددية
- تقنيات التكميم وتطبيقاتها على نماذج كوين
- 1.4.تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل
- 2.4. التكميم الدقيق بعد التدريب
- 3.4. تطبيق طريقتي التكميم جي بي تي كيو GPTQ و إي دبليو كيوAWQ على نماذج كوين
- 4.4. التكميم بواسطة مكتبة بت وبايت
- 5.4. تنسيق موحّد موّلد بواسطة جي بي تي
- الخاتمة
- المراجع
1. المقدّمة
أدّى التطوّر السريع لنماذج كوين Qwen، خاصة الإصدارين الثاني والثالث، وتزايد أحجامها، إلى الحاجة لاعتماد التكميمِ Quantization لتقليل الحجمِ مع الحفاظ قدر الإمكان على الجودةِ والأداءِ. وتتنوع أساليب التكميمِ بحسب نوع النموذجِ والبيئةِ الحاسوبيةِ؛ لذا تقدّم هذه المقالة مقارنةً لأبرز الطرقِ المعتمدةِ على العتادِ، تكميم الأوزان مع مراعاة حساسيّة توابع التفعيلِ Activation-Aware Weight Quantization – AWQ ولتكميم الدقيق بعد التدريبِ Accurate Post-Training Quantization – GPTQ، إضافةً إلى تنسيق موحّد موّلد بواسطة جي بي تي GPT-Generated Unified Format – GGUF المعتمد على وحدة المعالجة المركزيّة CPU، مع استعراض تطبيقاتها على نماذج كوين وبيان مزايا كل طريقةٍ وحدودها.
لنتعرّف على مفهوم التكميمِ.
2. التكميم
تشهد النّماذج اللغويّة الكبيرة Large Language Models- LLMs ونماذج اللّغة–الرّؤية Vision Language Models – VLMs تطوّرًا متسارعًا مكّنها من تنفيذ مهامٍ متقدمةٍ تتطلب فهمًا عميقًا للغةِ والسياقِ وربطهما بالمحتوى البصريِّ ومعالجة المدخلات متعددة الوسائطِ. غير أنّ تحقيق ذلك يستلزم نماذج ضخمةً ذات طبقاتٍ وأوزانٍ كثيرةٍ ومعاملاتٍ هائلةٍ، ما يرفع استهلاك الذاكرةِ والقدرةِ الحاسوبيةِ وزمنَ التدريبِ إلى مستوياتٍ قد تمتد لساعاتٍ أو أيامٍ.
وكما تُضغط الصور لتقليل حجمها مع الحفاظ على جودتها، ظهر في مجال النّماذج الذكيّة مفهوم التكميمِ لتحسين كفاءة التنفيذ دون إضرارٍ يُذكر بالأداءِ.
التكميم لغويًا مشتقٌّ من الكمِّ، ويعني تحويل القيم المتّصلة إلى قيمٍ منفصلةٍ.
أمّا علميًا في سياق التعلّم العميق ومعالجة اللّغات الطبيعيّة فهو عملية تقليل دقّة التمثيل العددي للبيانات أو معاملات النموذج عبر خفض عدد البِتّات المستخدمة في التمثيل الثنائي Bit-Width، مثل الانتقال من 32 بِتًّا إلى 8 بِتّاتٍ أو أقلَّ، مع الحرص على الحفاظ قدر الإمكان على المعلومات الجوهريّة التي تمكّن النموذج من استخلاص المعرفةِ وفهم المعنى الدلاليِّ، وهو ما ينعكس في تقليل مساحة التخزينِ والذاكرةِ المطلوبةِ، وخفض العمليات الحسابية أثناء التنفيذِ، وتسريع الاستدلال Inference، وتقليل استهلاك الطاقةِ، مع السعي لتحقيق توازنٍ أمثلَ بين الدقّة العدديّة وكفاءة الأداء الحاسوبيِّ.
النماذج تتعامل مع المدخلات في النهاية كأرقامٍ ثنائيةٍ؛ فالصور تُحوَّل إلى مصفوفاتٍ متعددة الأبعاد Tensors تمثل قيم البكسلات وقنوات الألوانِ، والنص يُحوَّل إلى معرّفات وحدات لفظية Token IDs وتضمينات Embeddings على شكل متجهاتٍ رقميةٍ، والصوت يُعالج كإشاراتٍ رقميةٍ عبر قيم عيناتٍ تمثل الخصائص الصوتية اللازمة لتفسيرهِ.
دعونا نتعرّف على أنواع التمثيلات العدديّةِ.
3. التمثيلات العدديّة:
1- التمثيل العائم بدقّة 32 بِتًّا – FP32: تُعدّ هذه الصيغة هي المعيار السائد في تدريب الشبكات العصبيّة لسنواتٍ طويلة، وذلك لما توفّره من دقّة عدديّة عالية ونطاقٍ تمثيليٍّ واسعٍ يُسهم في تجنّب المشكلات العدديّة أثناء عمليّات التدريب.
مجال النّطاق الديناميكيّ الذي تدّعمه هذه الصيغة هي: [1e-38 إلى 1e+38]، مع دقّة عدديّة تُقدَّر بحوالي 7 أرقام عشرية.
إلّا أنّها تتسبّب في استهلاكٍ مرتفعٍ للعتاد، ممّا ينعكس سلبًا على سرعة التدريب والاستدلال. [1]
2- التمثيل العائم بدقّة 16 بِتًّا – FP16: تكمنُ أهميّةُ هذه الصيغة في قدرتها على تقليل استهلاك الذاكرة إلى النصف مقارنةً بالصيغة السابقة، إلى جانب تحسين كفاءة الاداء الحسابيّ وتسريع عمليّات التدريب والاستدّلال. [1]
مجال النّطاق الديناميكيّ الذي تدّعمه هذه الصيغة هي: [6e-8 إلى 6e+4]، مع دقّة عدديّة تُقدَّر بحوالي 4 أرقام عشرية.
3- عدد صحيح 8 بِتّات – INT8:يكون التمثيل العدديّ باستخدام الأعداد الصحيحة 8 بِتّات أقل حجمًا أربع مرات تقريبًا مقارنةً بالتمثيل العددي باستخدام الأعداد العائمة بدقّة 32 بِتًّا. مجال النّطاق الديناميكيّ الذي تدّعمه هذه الصيغة هي: [-128 إلى +127]. [1]
4- عدد صحيح 4 بِتّات – INT4.
يقوم التكميم في جوهره على تقريب القيم العددية وتمثيلها بعدد أقل من البِتّات باستخدام صيغ منخفضة الدقة، إلا أنّ هذا التقريب يؤدي حتمًا إلى ظهور أخطاء عدديّة ناتجة عن فقدان جزء من الدقة الأصلية. وفي النماذج العميقة لا تظل هذه الأخطاء محصورة في طبقة واحدة، بل قد تتراكم عبر الطبقات المتعاقبة، ما قد يسبب تضخّمها ويؤدي إلى تراجع ملحوظ في دقة النموذج وأدائه، وهو ما يُعرف بأخطاء التكميم Quantization Errors. لذلك ينبغي تطبيق التكميم وفق منهجية مدروسة و بحذر، من خلال اختيار الاستراتيجية الأنسب التي تحقق توازنًا فعّالًا بين تقليل الدقة العددية والحفاظ على جودة التعلّم وكفاءة أداء النموذج.
4. تقنيات التكميم وتطبيقاتها على نماذج كوين:
يُسمّى تطبيق التكميم على نموذج مُدرَّب مسبقًا التكميم بعد التدريب Post-Training Quantization
-PTQ، أمّا إدخال تأثيرات التكميم ضمن مرحلة التدريب كي يتعلّم النموذج التكيّف معها فيُعرف بـ التدريب المُراعي للتكميم Quantization-Aware Training -QAT.
فيمّا يلي تقنيتين متقدّمتين من التكميم بعد التدريب صُمّمتا لمعالجة حساسية النماذج اللغويّة الكبيرة لأخطاء التكميم لتقليل فقدان الدقّة دون الحاجة إلى إعادة تدريب النموذج.
1.4. تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل Activation-Aware Weight Quantization – AWQ:
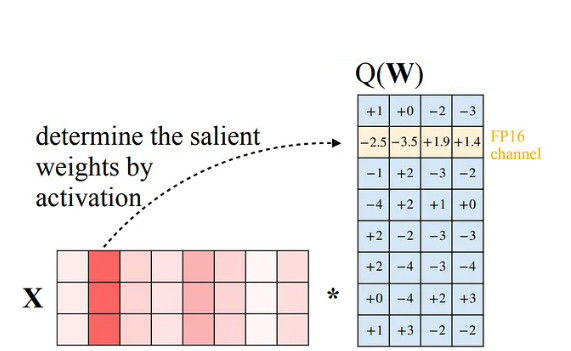
أولًا: تقوم الطريقة على مبدأٍ محوريٍّ أنّ أوزان النموذج ليست متساويةٌ في تأثيرها على دقّة الأداء، إذ إنّ جزءًا محدودًا منها يكون حاسمًا في الحفاظ على الاستقرار العدديّ [2] والمعنى الدلاليّ للمخرجات، بينما تكون بقية الأوزان أقل حساسيةً.
ثانيًا: تعتمد آلية العمل على مسارين رئيسيين؛ إذ تُحدَّد مجموعةً صغيرةً من الأوزان البارزة Salient weights قرابة 1٪ لتُحفظ بدقّةٍ أعلى مثل تمثيل عائم عشريّ FP16 لضمان الدقّة، بينما تُكمَّم بقية الأوزان بدقّات أقل.
تمتاز هذه الطريقة بأنّها لا تقيس الأهمية اعتمادًا على القيمة المطّلقة للوزن فقط، بل تستخدم تقديرًا مراعيًا لتوابع التفعيل يقيّم أثر الوزن وفق تفاعله مع التفعيلات ودوره الفعليّ في استقرار النموذج وأدائه.
ثالثًا: لتقليل أخطاء التكميم وموازنتها بين الأوزان المهمة وغيرها، تُطبَّق خطوة التحجيم التلقائي Auto Scaling عبر تعيين معامل تحجيم مستقلٌ لكل قناة إدخال بالاستناد إلى حجم تفعيلات الإدخال، بهدف الحد من تشبّع القيم أو اقترابها من الصفر. ثم تُستخرج قيمة التحجيم المثلى باستخدام بحث شبكي Grid Search ضمن مجموعة محدودة من القيم المحتملة، بما يخفّض أخطاء التكميم ويحافظ على دقّة النموذج. [2]
2.4. التكميم الدقيق بعد التدريب Accurate Post-Training Quantization- GPTQ:
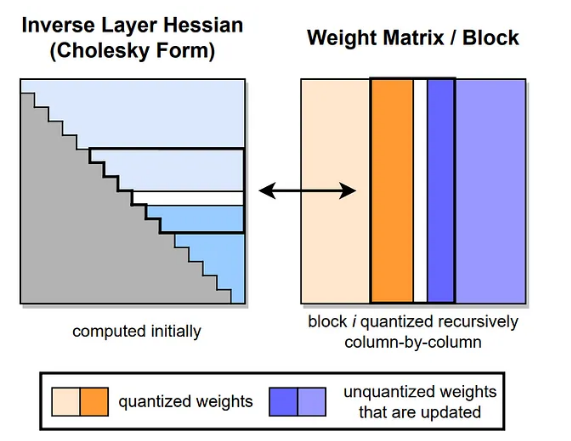
أوّلًا: الفكرة الأساسيّة: ترتكز على تكميم طبقةٍ واحدةٍ في كل مرة إلى تمثيلٍ صحيحٍ منخفض الدقّة (عادةً 4 بتّات)، ثم إجراء تحديثٍ تعويضي لبقية الأوزان ذات التمثيل العائم، بحيث تصبح مخرجات الطبقة بعد التكميم أقرب ما يمكن إلى مخرجاتها الأصلية قبل التكميم. [3]
ثانيًا: آليّة العمل الداخليّة: تبدأ العملية بتمرير مجموعةٍ محدودةٍ من بيانات المعايرة عبر الطبقة المستهدفة لتسجيل المدخلات وتقدير أثر التكميم، ثم تُستخدم المعايرة لاشتقاق نطاقات القيم ومعاملات التكميم للأوزان (وأحيانًا للتفعيلات) اعتمادًا على بيانات تمثيلية قريبة من توزيع بيانات الاستدلال، بعد ذلك تُقدَّر حساسية الطبقة عبر المصفوفة الهيسيانية العكسية Inverse Hessian التي تعبّر عن مدى تأثر الخسارة بتغيّرات الأوزان؛ وتُعد الأوزان المرتبطة بقيم أصغر فيها أكثر أهمية، يُنفَّذ التكميم بصورة متسلسلة وزنًا بعد وزن: يُكمَّم الوزن ثم يُلغى تكميمه للعودة إلى المجال العائم، ويُحسب خطأ التكميم الناتج ويُوزن بقيمة الهيسياني العكسي، ثم يُعاد توزيع الخطأ Error Compensation على بقية الأوزان في الصف نفسه لتعويض الانحراف وتقليل تراكمه. تتكرر هذه الخطوات عبر أوزان الصف ثم بقية الصفوف والطبقات حتى يكتمل تكميم النموذج.
ثالثًا: تنجح هذه الآلية لأن أوزان الطبقة الواحدة مترابطة رياضيًا؛ فعندما يُحدث تكميم أحد الأوزان خطأً، يمكن تعويض أثره على المخرجات عبر تعديل الأوزان المرتبطة به بطريقة موجّهة بحساسية الخسارة (الهيسياني العكسي)، مما يحدّ من تراكم الأخطاء ويحافظ على استقرار النموذج ودقّة مخرجاته.[3]
إليكم جدول (1) مقارنة واضح ومختصر يوضّح الفرق بين الطريقتين السابقتين من حيث المبدأ وآليّة العمل:
|
الطريقة / الخوارزمية |
تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ |
التكميم الدقيق بعد التدريب GPTQ |
|
الفكرة الأساسية |
إعطاء أولوية للأوزان الأكثر تأثيرًا على تابع التفعيلات. |
تقليل خطأ المخرجات عبر تحسين تكميم كل طبقة. |
|
معيار الأهمية |
تأثير الوزن على حجم التفعيلات. |
المصفوفة الهيسيانيّة. |
|
آلية التكميم |
الإبقاء على الأوزان البارزة بدقّة أعلى. |
تكميم متسلسل مع تعويض الخطأ. |
|
تقليل الخطأ |
غير مباشر عبر التحجيم التلقائي. |
مباشر عبر إعادة توزيع الخطأ. |
|
نوع التكميم |
مختلط عدد صحيح وعدد عشري (FP16 + INT3/INT4) |
عدد صحيح ذو 4 بتّات INT4 |
|
سرعة التكميم |
عالية |
أبطىء نسبياً |
|
العتاد المستخدم |
وحدة المعالجة الرسومية GPU |
وحدة المعالجة الرسومية GPU |
الجدول (1): مقارنة بين طريقتيّ تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل و التكميم الدقيق بعد التدريب
دعونا ننظر إلى الطريقتين السابقتين ونحلّل تأثيرهما الإيجابي على نموذج Qwen بنسختيه الثانية والثالثة.
3.4. تطبيق طريقتي التكميم جي بي تي كيو GPTQ و إي دبليو كيوAWQ على نماذج كوين:
لنتعرّف في البداية على نماذج كوين بإصدارتهم الثانية والثالثة.
1.3.4. تطبيق عملي على نموذج كوين بنسخته الثانية :
أهم المميزات الجوهريّة لنّموذج كوين وما يميزه عن البقية: [4]
- فهم متقدّم للصور بمختلف الدقّات ونِسَب الأبعاد:
يحقّق نموذج اللّغة-الرّؤية كوين بإصداره الثاني أداءً رائدًا على أحدث معايير تقييم الفهم البصريّ، ما يدلّ على قدرته العالية على تحليل الصور بمستويات دقّة وأبعاد مختلفة. - فهم مقاطع فيديو تتجاوز مدّتها 20 دقيقة:
بفضل قدراته على المعالجة المتدفّقة عبر الإنترنت Online Streaming، يستطيع فهم مقاطع الفيديو التي تزيد مدّتها عن 20 دقيقة، وتقديم إجابات عالية الجودة على الأسئلة المعتمّدة على الفيديو، بالإضافة إلى إجراء الحوارات وتوليد المحتوى استنادًا إلى الفيديو. - وكيل ذكي قادر على تشغيل الهواتف المحمولة والروبوتات وغيرها:
اعتمادًا على إمكانته في الاستدلال المعقّد واتخاذ القرار، يمكن دمج نموذج كوين مع الأجهزة المختلفة مثل الهواتف الذكية والروبوتات، لتنفيذ عمليات تلقائية اعتمادًا على البيئة البصريّة المحيطة والتعليمات النصّية. - دعم متعدّد اللغات:
لا يقتصر على دعم اللغتين الإنجليزية والصينية فقط، بل أصبح قادرًا على فهم النصوص داخل الصور بعدّة لغات أخرى، تشمل معظم اللغات الأوروبية، واليابانية، والكوريّة، والعربية، والفيتناميّة، وغيرها.
لِمَزيدٍ من المعلومات حول آليّة عمل نموذج اللغة–الرؤية كوين بنسخته الثانية، وما يتمتّع به من مميّزات وتقنيات مُستخدَمة، تُقدِّم المقالةُ المُشارُ إليها في المرجع [5] شرحًا معمّقًا ومفصّلًا لهذا النموذج.
[4] تطبيق عملي لطريقتي التكميم – تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل و التكميم الدقيق بعد التدريب – على نموذج اللغة-الرؤية كوين بنسخته الثانية ذو 7 مليارات بارامتر Qwen2-VL-7B.
|
طول الإدخال |
طريقة التكميم | السرعة | استهلاك الذاكرة – GPU |
|
1 |
التكميم الدقيق بعد التدريب – عدد صحيح ذو 8 بتّات (GPTQ-Int8) | 31.60 | 10.11 |
| التكميم الدقيق بعد التدريب – عدد صحيح ذو 4 بتّات (GPTQ-Int4) | 42.76 | 7.20 | |
| تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ | 32.08 | 7.07 | |
|
6144 |
التكميم الدقيق بعد التدريب – عدد صحيح ذو 8 بتّات (GPTQ-Int8) | 31.31 | 15.61 |
| التكميم الدقيق بعد التدريب – عدد صحيح ذو 4 بتّات (GPTQ-Int4) | 39.75 | 12.69 | |
| تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ | 32.66 | 12.56 | |
|
14336 |
التكميم الدقيق بعد التدريب – عدد صحيح ذو 8 بتّات (GPTQ-Int8) | 27.96 | 23.11 |
| التكميم الدقيق بعد التدريب – عدد صحيح ذو 4 بتّات (GPTQ-Int4) | 29.72 | 20.20 | |
| تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ | 31.42 | 20.07 | |
|
30720 |
التكميم الدقيق بعد التدريب – عدد صحيح ذو 8 بتّات (GPTQ-Int8) | 18.37 | 38.13 |
| التكميم الدقيق بعد التدريب – عدد صحيح ذو 4 بتّات (GPTQ-Int4) | 19.15 | 35.22 | |
| تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ | 19.95 | 35.08 |
الجدول (2): نتائج تنفيذ طرائق التكميم على نموذج اللغة-الرؤية كوين بنسخته الثانية ذو 7 مليارات بارامتر. [4]
نلاحظُ وفقاً للجدول (2) أنّه عند طول إدخالٍ قصيرٍ يساوي1 كان جي بي تي كيو بتكميمٍ عدديٍّ صحيحٍ ذو 4 بِتّات هو الأسرع والأقلّ استهلاكًا للذاكرة. كما يتبيّن أنّه عند طول إدخالٍ يساوي 6144 حافظ جي بي تي كيو بتكميمٍ عدديٍّ صحيحٍ ذو 4 بِتّات أيضًا على تفوّقه من حيث السرعة وكفاءة الذاكرة.ومع زيادة طول الإدخال تزداد كمية المعالجة الحسابيّة المطلوبة، الأمر الذي يؤدّي إلى انخفاض السرعة وارتفاع استهلاك الذاكرة.
أمّا عند أطوال إدخالٍ كبيرة، تتراوح بين 14336 و 30720، فيتفوّق تكميم الأوزان المراعي لحساسيّة توابع التفعيل، حيث يُظهر أداءً أفضل في الحفاظ على الدقّة مع كفاءةٍ أعلى في هذا النطاق من الأحجام.
2.3.4. تطبيق عملي على نموذج كوين بنسخته الثالثة :
من سلسلة النّماذج والنسخ التي طرأت على نماذج كوين نموذج كوين بنسخته الثالثة Qwen-v3 التي طوّرته شركة كلاود علي بابا ، وقد برز كأحد النماذج اللغويّة التوليديّة ذاتيّة الانحدار Autoregressive LLMs مفتوحة المصدر، حيث يتوفّر بتكويناتٍ متعدّدةٍ تبدأ من 0.6 مليار وتصل إلى 235 مليار بارامتر. ونظرًا لمتطلّباته الحاسوبيّة المرتفعة، فإنّ نشر نموذج كوين 3 بكفاءة يُعَدّ تحدّيًا غير بسيط، ممّا يجعل التكميم تقنيّةً أساسيّةً ولا غنى عنها لتحقيق تشغيل عملي وفعّال. [6]
[7] المميزات الجوهريّة لنموذج كوين بنسخته الثالثة:
- أنماط التفكير الهجينة: يعتمدُ نموذجُ كوين بنسختِهِ الثالثةِ على آليةِ تدريبٍ هجينةٍ تمكّنُهُ من دعمِ أنماطٍ متعددةٍ للإجابةِ تبعًا لطبيعةِ الأوامرِ والسياقِ المقدَّمِ؛ إذ يوفّرُ نمطَ التفكيرِ الاستدلاليِّ لمعالجةِ المشكلاتِ المعقَّدةِ التي تتطلبُ تحليلًا منطقيًا وخطواتٍ متعددةٍ، ونمطَ الاستجابةِ السريعةِ للإجابةِ عن الاستدلالاتِ البسيطةِ.
- الدعم متعدّد اللغات: يدعمُ النموذجُ 119 لغةً ولهجةً، ما يعزّزُ قابليتَهُ للاستخدامِ عالميًّا ويُمكّنهُ من فهمِ النصوصِ والتفاعلِ معها ضمنَ سياقاتٍ لغويّةٍ وثقافيّةٍ متنوّعةٍ.
- تحسين القدرات الوكيليّة: خضعَ النموذجُ لتحسيناتٍ متخصّصةٍ لتعزيزِ قدراتِهِ في البرمجةِ والسلوكِ الوكيليِّ، مع دعمٍ متقدّمٍ لمعالجةِ القدراتِ المتعدّدةِ، بما يُتيحُ لهُ التخطيطَ واتّخاذَ القرارِ وتنفيذَ المهامِّ المركّبةِ بفاعليّةٍ أعلى.
- تدريب مُحسَّن ومُعزَّز:مرَّ النموذجُ بمرحلةِ ما قبلِ التدريبِ المُحسَّنةِ باستخدامِ بياناتٍ متنوّعةٍ وعاليةِ الجودةِ، مع زيادةِ الوحداتِ اللفظيةِ التدريبيةِ Training Tokens لتعزيزِ التعميمِ والفهمِ الدلاليِّ العميقِ. في مرحلةِ ما بعدِ التدريبِ تمَّ اعتمادُ مراحلَ شملت دعمَ سلاسلِ التفكيرِ الطويلةِ لترسيخِ الاستدلالِ المعقَّدِ، وتطبيقَ نظامِ مكافآتٍ قائمٍ على القواعدِ لتعزيزِ القدراتِ التفسيريةِ والاستكشافيةِ، ودمجَ أنماطِ التفكيرِ لتحقيقِ توازنٍ بين العمقِ والكفاءةِ، والتدريبَ على طيفٍ واسعٍ من المهامِّ العامةِ لتحسينِ القدراتِ الشاملةِ وضبطِ السلوكياتِ غيرِ المتوافقةِ مع السياقِ.
[6] تطبيق عملي لطريقتي التكميم الدقيق بعد التدريب و تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل على نموذج كوين بنسخته الثالثة من خلال استخدام مجموعة بيانات إدخال C4 على النموذج.
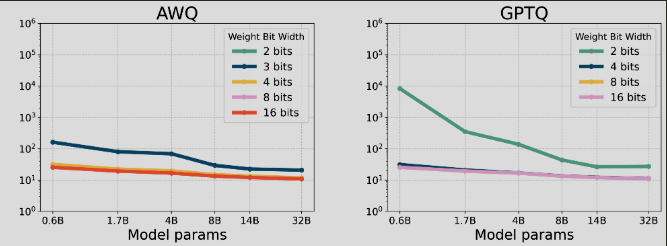
- يُستخدم مقياس الحيرة Perplexity – PPL لتقييم جودة نماذج اللّغة، حيث تشير القيم المنخفضة إلى قدرة أعلى على التنبؤ بالكلمات.
- يعتبر العدد العشري ذو 16 بتّات هو المرجع الأساسي لدقة النّموذج الذي نقارن بها بقية التمثيلات لطرائق التكميم.
- المحور الأفقي: حجم النموذج (عدد المعاملات) ( 0.6B → 1.7B → 4B → 8B → 14B → 32B)
- المحور العمودي : قيمة مقياس الحيرة (كلما كانت أقل → الأداء أفضل)
أولاً: التكميم الدقيق بعد التدريب GPTQ : (وفقاً للشكّل (4))،
- يُحافظ INT8 على أداء شبه ثابت عبر جميع الأحجام. أمّا INT4 فيُحدث تراجعًا طفيفًا عند 0.6B و1.7B ثم يستقر من 4B فأعلى قريبًا من الأساسي، وبزيادة حيرة أقل من AWQ بينما يُضعف INT2 الأداء بوضوح، لكن أثره يتراجع مع كِبر حجم النموذج بفضل آليات التعويض والمصفوفة الهيسيانية.
ثانياً: تكميم الأوزان مع مراعاة حساسيّة توابع التفعيل AWQ: (وفقاً للشكّل (4))،
يُظهر تكميم INT8 استقرارًا شبه كامل في الأداء عبر جميع أحجام النموذج. أمّا INT4 فيسبّب تراجعًا طفيفًا عند 0.6B و1.7B ثم يستقر من 4B فأعلى قريبًا جدًا من الأداء الأساسي. بينما يؤدي INT3 إلى انخفاض ملحوظ، لكنه يتراجع تدريجيًا مع زيادة حجم المعاملات حتى يقترب من الأداء الأساسي عند أحجام تقارب 8B إلى 32B.
4.4. التكميم بواسطة مكتبة بت وبايت BitsAndBytes:
بعضُ نماذج كوين في إصدارتها الثانية، مثل Qwen2.5-3B و Qwen2.5-7B، تعتمد على مكتبة بت وبايت BitsAndBytes – bnb التي تُمكّن من تكميم الأوزان باستخدام تمثيلات عدديّة صحيحة بدقّة 8 بتّات و 4 بتّات، وذلك بهدف تقليل استهلاك الذاكرة وتحسين كفاءة التشغيل دون تأثير ملحوظ على الأداء. [8]
فيما يلي مقارنة استهلاك ذاكرة وحدة المعالجة الرسومية GPU عند استخدام عدة طرائق تكميم:[8]
|
النموذج |
استهلاك الذاكرة GB |
| نموذج اللّغة-الرؤيّة كوين 2.5 ذو حجم معاملات 3B – Qwen2.5-VL-3B | 7.8 |
| نموذج اللّغة-الرؤيّة كوين 2.5 ذو حجم معاملات 3B المُكمّم بمكتبة بت وبايت ذو 8 بتّات | 4.4 |
| نموذج اللّغة-الرؤيّة كوين 2.5 ذو حجم معاملات 3B المُكمّم بطريقة GPTQ ذو 4 بتّات | 3.8 |
| نموذج اللّغة-الرؤيّة كوين 2.5 ذو حجم معاملات 3B المُكمّم بمكتبة بت وبايت ذو 4 بتّات | 3.4 |
الجدول (3): نتائج استهلاك ذاكرة وحدة المعالجة الرسومية عند استخدام طرائق التكميم. [8]
نستنّتج وفقاً للجدول (3) كلما انخفض عدد البِتّات زاد توفير الذاكرة. بت وبايت ذو 4 بتّات هو الأكثر كفاءة من حيث الذاكرة والأسرع من ناحية التنفيذ لنماذج اللغة -الرؤية، بينما تقدّم طريقة جي بي تي كيو ذو تمثيل صحيح 4 بتّات GPTQ-INT4 توازنًا أفضل بين تقليل الذاكرة والحفاظ على الأداء بسبب تعويض الخطأ.
5.4. تنسيق موحّد موّلد بواسطة جي بي تي GPT-Generated Unified Format – GGUF:
عند عدم توفّر سعةٍ كافيةٍ لذاكرة المعالجة الرسوميّة VRAM، بحيث لا يكون تنفيذ النموذج أو تطبيق طرق التكميم على وحدة المعالجة الرسوميّة ممكنًا بالكامل، يمكن في هذه الحالة استخدام تنسيق موحّد موّلد بواسطة جي بي تي لإسناد أيّ طبقة من طبقات النموذج إلى وحدة المعالجة المركزيّة CPU، مما يتيح الاستفادة المشتركة من موارد الـ جي بي يو والـ سي بي يو وتشغيل النموذج ضمن القيود المتاحة.
من الطرق التقليدية لهذا التنسيق: [9]
1- التكميم المتماثل Symmetric Quantization: يُرمَز إلى هذا الأسلوب بالصيغة المختصرة Qm-0، حيث يشير m إلى عدد البتّات المستخدمة في التمثيل العددي الصحيح للوزن (تكميم بتمثيل صحيح ذو m بتّات).
تُكمَّم جميع القيم وفق آلية موحَّدة باستخدام معامل تحجيم واحد Scale Factor، مع افتراض أنّ مجال القيم متماثل حول الصفر ولا يتضمّن نقطة إزاحة Zero-Point
S = (β – α) / (max_int – min_int)
المعادلة (1): معامل التحجيم
quant(r) = round(r/ S)
المعادلة (2): مقياس التكميم
حيث قيم [α, β] = [-1, +1]
2- التمثيل غير المتماثل Asymmetric Quantization: يُرمَز إلى هذا الأسلوب بالصيغة المختصرة Qm-1، يتم حساب نقطة إزاحة بسبب ان البيانات اغلبها غير متماثلة حول الصفر.
| Z = round(-α / S) + min_int | quant(r) = Z + round(r / S) |
| المعادلة (3): معامل التحجيم | المعادلة (4): مقياس التكميم |
كِلا الأسلوبين يعتمدان على التكميم الكُتَلي Block Quantization، حيث تُشارَك ثوابت التكميم بين مجموعات من الأوزان.وينتج عن ذلك مفاضلة واضحة: كلّما كان حجم الكتلة أكبر، قلّ عدد الثوابت المخزَّنة لكن تنخفض الدقّة، بينما تؤدّي الكتل الأصغر إلى دقّة أعلى على حساب زيادة الحمل التخزيني. [9]
من الطرق المتقدّمة لهذا التنسيق:
3- التكميم بالمجموعات Group-wise Quantization – K-Quants: يُرمَزُ إلى هذا الأسلوب بالصيغة المختصرة Qm-k. تعتمد هذه الطريقة على تكميمٍ ثنائيّ المستوى، إذ تُكمَّم كلُّ مجموعة باستخدام معامل تحجيم مستقلّ يُحدَّد وفق مجال القيم داخل كل بلوك، ممّا يُسهم في تقليل أخطاء التكميم والحفاظ على الدقّة العدديّة.
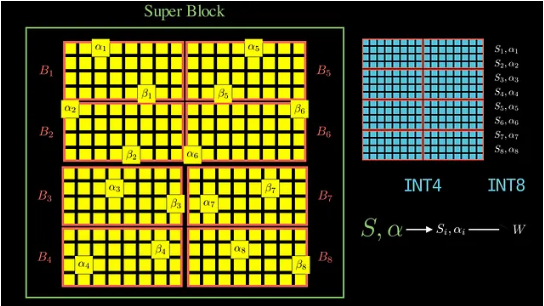
آلية العمل وفقاً للشكّل (5):
تُقسَّم مصفوفة الأوزان Super Block إلى بلوكات فرعية تضم عادةً 32 أو 64 وزنًا، وغالبًا ما يكون عددها 8 (B1–B8) ويُحسَب لكل بلوك حدّان هما (الأدنى) و (الأعلى) لاشتقاق معامل التحجيم الخاص به. تُكمَّم الأوزان داخل كل بلوك بتمثيل صحيح 4 بت، بينما تُكمَّم قيمتا و بتمثيل صحيح 8 بت للحفاظ على دقة فك التكميم. كما تعتمد الطريقة دقّةً مختلطة؛ إذ تُحفظ المكوّنات الجوهرية مثل طبقات التَّطبيع Layer Norms وآليّات الاهتمام Attention Mechanisms بتمثيل عائم، وتُكمَّم بقية الأوزان، ويُشار إلى هذا الأسلوب بالصيغة Qm_K_M.
4- التكميم المتجهيّ Vector Quantization- I-Quants: يعتبر أحدث ابتكار من بين جميع الطرق ، إذ تُعامَل مجموعاتٌ من 8 أوزان كوحداتٍ متجهيّة عالية الأبعاد بدلًا من تكميم كل وزنٍ على حدة. يُرمَزُ إلى هذا الأسلوب بالصيغة المختصرة IQm.
آلية عمل الطريقة: تبدأُ بإنشاءِ قاموسِ متجهاتٍ Codebook يضمُّ 256 متجهًا مرجعيًّا، طولُ كلِّ متجهٍ 8 أبعادٍ، وهو ما يعادلُ عمليًّا 8 بتّاتٍ لكلِّ وزنٍ؛ وعند اعتمادِ تمثيلٍ صحيحٍ بثمانيةِ بتّاتٍ يُشارُ إليهِ بالرمزِ IQ8، ثمَّ تُجمعُ كلُّ ثمانيةِ أوزانٍ متجاورةٍ منَ النموذجِ في متجهٍ واحدٍ.
وبما أنَّ متجهاتِ القاموسِ موجبةُ القيمِ، بينما قد تكونُ الأوزانُ موجبةً أو سالبةً، تُحفَظُ إشاراتُ الأوزانِ في بايتٍ مستقلٍّ Sign Bits بدلًا من توسيعِ القاموسِ.
ثمَّ يُحسَبُ معاملُ التحجيمِ عبر إيجادِ المتجهِ المرجعيِّ الأقربِ إلى متجهِ الأوزانِ وفقَ المعادلةِ (5). [9]
||S = ||w|| / ||r
المعادلة (5): معامل التحجيم
يُستخدمُ معاملُ التحجيمِ لضبطِ المتجهِ المرجعيِّ المُكمَّمِ ليصبحَ أقربَ ما يمكنُ إلى التمثيلِ الحقيقيِّ لمتجهِ الأوزانِ. وخلالَ عمليةِ التكميمِ تُخزَّنُ ثلاثةُ عناصرَ: مؤشّرُ المتجهِ المرجعيِّ، ومعاملُ التحجيمِ، وبايتُ الإشارةِ.
فيما يلي جدول (4) إرشاديّ يُوضّح آليّة اختيار طريقة التكميم الأنسب.
| الطريقة | الاستخدام الأمثل |
|
Q6_K, Q8_0 |
|
|
Q4_K_M, Q5_K_M |
|
|
IQ2_XS, IQ2_S |
|
الجدول (4): مقارنة طرق GGUF من حيث الاستخدام الأمثل. [9]
تطبيق عملي لطرق تكميم تنسيق موحّد موّلد بواسطة جي بي تي GGUF على نموذج كوين بنسّخته الثانية ذو أحجام مختلفة بالاعتماد على تقييم مقياس الحيرة. [10]
|
حجم النموذج |
fp16 |
q8-0 |
q6-k |
q5-k-m |
q5-0 |
q4-k-m |
q4-0 |
q3-k-m |
q2-k |
|
0.5B |
15.11 |
15.13 |
15.14 |
15.24 |
15.40 |
15.36 |
16.28 |
15.70 |
16.74 |
|
1.5B |
10.43 |
10.43 |
10.45 |
10.50 |
10.56 |
10.61 |
10.79 |
11.08 |
13.04 |
|
7B |
7.93 |
7.94 |
7.96 |
7.97 |
7.98 |
8.02 |
8.19 |
8.20 |
10.58 |
|
72B |
5.58 |
5.58 |
5.59 |
5.59 |
5.60 |
5.61 |
5.66 |
5.68 |
5.91 |
الجدول (5): نتائج مقياس الحيرة لطرق GGUF على نموذج كوين بنسخته الثانية.[10]
من خلال الجدول (5)، نلاحظ أنّه كلّما ازداد حجم النموذج انخفضت قيمة مقياس الحيرة ، ويعود ذلك إلى تحسّن الدقّة اللغوية للنموذج، إذ إنّ زيادة عدد المعاملات المكوّنة له تؤدي إلى قدرة أكبر على التعلّم والمعالجة، وبالتالي تحسّن الأداء.
- تُظهرُ صيغُ FP16 وQ8_0 وQ6_K أداءً قريبًا جدًّا من عدمِ التكميمِ وبجودةٍ شبهِ متطابقةٍ، لكن مع استهلاكٍ أعلى للذاكرةِ. في المقابلِ، تُحقِّقُ Q5_K_M وQ5_0 وQ4_K_M انخفاضًا محدودًا في الجودةِ يظهرُ كارتفاعٍ طفيفٍ في مقياسِ الحيرةِ، مقابلَ توفيرٍ ملحوظٍ في الذاكرةِ عبرَ خفضِ عددِ البِتّاتِ. ويعتمدُ هذا التوازنُ على مصفوفةِ الأهميّةِ التي تمنحُ المعاملاتِ الأكثرَ تأثيرًا دقّةً أعلى أو تكميمًا أخفَّ، بينما تُكمَّمُ الأقلُّ أهميّةً بدرجةٍ أكبرَ. أمّا Q3_K_M وQ2_K فتتسبّبانِ في ارتفاعٍ واضحٍ في مقياسِ الحيرةِ وانخفاضٍ ملحوظٍ في الجودةِ، لكنّهما يوفّرانِ ضغطًا شديدًا للنموذجِ يجعلهما ملائمَيْنِ للبيئاتِ محدودةِ المواردِ.
5. الخاتمة
يُعَدُّ التكميمُ خطوةً محوريةً عند تطبيقِ النماذجِ اللغويةِ الكبيرةِ، نظرًا لما تتطلبهُ من ذاكرةٍ وحوسبةٍ كثيفتينِ في التدريبِ والاستدلالِ، وقد قدَّمَ حلًا فعّالًا لتخفيفِ عبءِ المعالجةِ وتقليلِ استهلاكِ الذاكرةِ، ما يجعلُهُ مناسبًا للبيئاتِ محدودةِ المواردِ.
يقومُ التكميمُ على خفضِ دقّةِ معاملاتِ النموذجِ عبر استخدامِ تمثيلاتٍ عدديةٍ أقلَّ بعرضِ بِتّاتٍ أصغرَ، إلّا أنَّ الانتقالَ من الدقّةِ العاليةِ إلى المنخفضةِ وتراكمَهُ عبر طبقاتِ النموذجِ يسبّبُ أخطاءَ تكميمٍ قد تؤثّرُ في الجودةِ والأداءِ؛ لذلك ظهرتْ طرائقُ متعدّدةٌ تسعى لموازنةِ ضغطِ النموذجِ مع الحفاظِ على دقّتِهِ.
من أبرزِ هذهِ الطرائقِ AWQ التي تمنحُ أولويةً للأوزانِ الأكثرِ تأثيرًا استنادًا إلى حساسيةِ التفعيلاتِ، وGPTQ الذي يعتمدُ على المصفوفةِ الهيسيانيةِ لتقديرِ أهميةِ الأوزانِ وتكميمِها تراكميًا مع تعويضِ الخطأِ للحدِّ من أثرِهِ على الأداءِ. وقد جرى اختبارُ هاتينِ الطريقتينِ على نماذجِ كوين بإصداريها الثاني والثالثِ، وغالبًا ما تُنفَّذانِ على وحدة المعالجة الحاسوبيّة لما توفّرُهُ من قدرةٍ حسابيةٍ عاليةٍ. وعند تشغيلِ النماذجِ الضخمةِ ضمن قيودِ مواردٍ صارمةٍ، برزَ تنسيقُ GGUF بوصفِهِ خيارًا أكثرَ كفاءةً في إدارةِ الذاكرةِ والحساباتِ، مع آلياتٍ تدعمُ التمثيلَ المتماثلَ وغيرَ المتماثلِ، والتكميمَ بالمجموعاتِ (تقسيمُ الأوزانِ إلى مجموعاتٍ وتكميمُ كلِّ مجموعةٍ مستقلًّا)، إضافةً إلى التكميمِ المتجهيِّ الذي يستخدمُ متجهاتٍ مرجعيةً مكمّمةً تُطبَّقُ على مجموعاتٍ من الأوزانِ، ويُضبطُ توازنُهُ عبر معاملاتِ التحجيمِ.
6. المراجع:
- Unlocking Efficiency: A Deep Dive into Model Quantization in Deep Learning| medium
- Speeding Up Large Language Models: A Deep Dive into GPTQ and AWQ Quantization | medium
- A visual guide to Quantization | medium
- Qwen2-VL | github
- نموذج الرّؤية-اللّغة كوين بإصداره Qwen-2.5-VL | aiinarabic
- arXiv:2505.02214v1 [cs.LG] 04 May 2025
- Understanding Qwen-V3: My A Personal Take | medium
- Quantizing Qwen VL Models Using BitsAndBytes (bnb) for Efficient Inference with Small GPU | medium
- GGUF Quantization: Making Large Language Models Accessible to Everyone | medium
- Qwen2-7B-Instruct-GGUF | huggingface