
المَحتويَات
مقدّمة
إنَّ نماذج سلسلة إلى سلسلة Seq2Seq هي نماذج تَعلُّم عميق حقَّقت الكثير من النجاح في عدد من المهام مثل الترجمة الآليّة، تلخيص النصّ، شرح الصور وغيرها، وبدأت خدمة الترجمة من جوجل Google translate باستخدام هذه النماذج في أواخر 2016.
تمَّ تقديم و شرح هذه النماذج بشكل جيد في الورقتين البحثيَّتين التاليتين [2][3]، ولكن إن كنت تبحث – عزيزي القارئ – عن أسلوب مُبسَّط وممتع لفهم هذا النموذج، يمكنك أن تكمل قراءة هذا المقال حيث تمّ فيه الاعتماد على أسلوب الشرح البصريّ لضمان إيصال الفكرة بشكل أسهل. بدايةً، دعونا نقوم بشرح سلسلة من المفاهيم المَبنيّة على بعضها البعض، من أجل فهم نموذج سلسلة إلى سلسلة بشكل كافٍ يُمَكِّنكَ من تطبيقه بشكل عمليّ.
ملاحظة: يجب أن يكون لديك فهم مُسبق للتعلُّم العميق، وإلمام بسيط لبعض مفاهيم آليّة الاهتمام Attention من أجل فهم هذا المقال بشكل جيد.
نماذج سلسلة إلى سلسلة في الترجمة الآليّة
هو نموذج يأخذ سلسلة من العناصر (كلمات، حروف، مزايا صور، … إلخ) و يقوم بإخراج سلسلة أخرى منها. مثلًا لو كان لدينا نموذج سلسلة إلى سلسلة مُدَرَّب، فإنه سيعمل كما هو مُبيَّن في المثال التوضيحيّ التالي.
أما في حالة الترجمة الآليّة العصبونيّة فإنّ السلسلة هي عبارة عن تسلسل من الكلمات تتمُّ مُعالجتُها الواحدة تلوَ الأخرى، ويكون الخرج عبارة عن سلسلة من الكلمات كما هو واضح في المثال التالي.
رأينا في المثالين السابقين كيف أنّ نموذج سلسلة إلى سلسلة يستقبل سلسلة من العناصر ويقوم بإخراج سلسلة أخرى. و لكن ما الذي يحدث داخل هذا النموذج!؟ كيف تتمُّ مُعالجة سلسلة الدّخل و التَّنبُّؤ بسلسلة الخرج؟ دعنا عزيزي القارئ نشرح ذلك في الفقرات التالية.
يتكوَّن نموذج سلسلة إلى سلسلة من مُشفّر Encoder و فاكّ الشيفرَة Decoder.
يُعالج المُشفّر كلّ عنصر من عناصر سلسلة الدّخل، حيث يقوم بتجميع المعلومات التي يُحَصّلها (يلتقطها) ويُحوّلها إلى مُتَّجه vector (يُدعى السياق context). يقوم المُشفّر بعد معالجة سلسلة الدّخل بإرسال السياق إلى فاكّ الشيفرة الذي يبدأ بدوره بإنتاج سلسلة الخرج عنصر بعد عنصر. يُبيّن المثال التوضيحيّ التالي آليّة عمل المُشفّر- فاكّ الشيفرة.
ينطبق نفس المبدأ على حالة الترجمة الآليّة كما هو مُبيّن في المثال التوضيحيّ التالي.
ما هو السياق Context؟
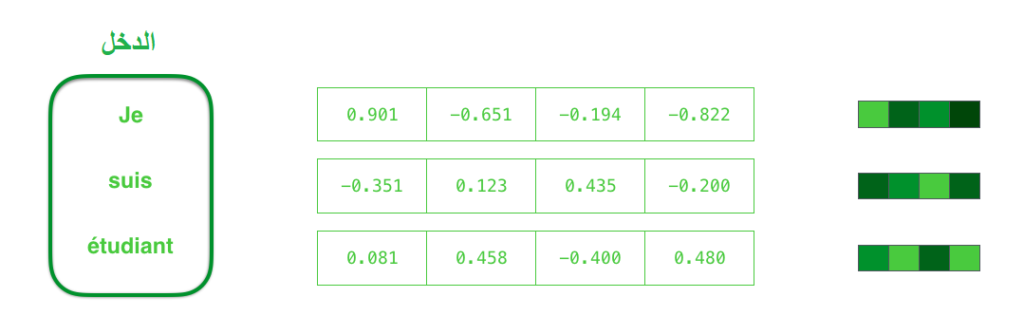
في حالة الترجمة الآليّة، السياق هو عبارة عن مُتَّجه (مصفوفة من الأرقام)، بينما يميل كلّ من المُشفّر و فاكّ الشيفرة ليكونا شبكتين عصبونيّتين إرجاعيّتين RNN. يبين الشكل (1) أنّ السياق هو متجه من الأرقام الحقيقية ذات الفاصلة العائمة floats.

يُمكنك -عزيزي القارئ- ضبط حجم مُتّجه السياق عند إعداد نموذج سلسلة إلى سلسلة. في الحقيقة، حجم المُتّجه هو عدد الوحدات المخفيّة hidden units في مُشفّر الشبكة العصبونيّة الإرجاعيّة RNN. جرت العادة أن يكون حجم مُتّجه السياق في تطبيقات العالم الحقيقيّ 256 أو 512 أو 1024، وذلك حسب نوع المسألة المُراد حلها.
تأخذ الشبكات العصبونيّة الإرجاعيّة RNN دخلين في كلّ خطوة زمنيّة:
- دخل (في حالة المُشفّر، كلمة واحدة من جملة الدّخل يتمُّ تمثيلها بواسطة مُتّجه)
- حالة مخفيّة hidden state
من أجل تحويل الكلمة إلى مُتّجه يتمُّ استخدام طريقة تُسمّى خوارزميّات “تضمين الكلمة” word embedding، حيث تقوم بتحويل الكلمات إلى فضاءات المُتجهات التي تمتلك الكثير من المعلومات الدّلاليّة لتلك الكلمات (مثال: ملك – رجل + امرأة = ملكة). يمكنك الاطلاع أكثر على هذه الخوارزميّة عن طريق قراءة هذا المقال على مدونة الذّكاء الاصطناعيّ باللغة العربيّة. يبين الشكل (2) عمليّة تحويل كلمات الدّخل (على اليسار) إلى مُتّجهات عن طريق استخدام خوارزميّة تضمين الكلمة. يُمكننا استخدام نماذج تضمين مُدرّبة بشكل مُسبق، أو تدريب نموذجنا الخاصّ باستخدام مجموعة بيانات خاصة بنا. جرت العادة على استخدام أشعة تضمين بحجم 200، 300 أو 500.
الآن وبعد أن تكلّمنا عن المُتَّجهات، دعونا نستعرض بشكل سريع آليّة عمل الشبكات العصبونيّة الإرجاعيّة RNN. كما هو مُبيّن في المثال التوضيحيّ التالي، تأخذ الشبكات العصبونيّة الإرجاعيّة شعاعَي دخل (شعاع الدّخل الحالي و الحالة المخفيّة السابقة)، تقوم بمُعالجتهِما وأخيرًا تُعطي شعاعي خرج (شعاع الخرج و الحالة المخفيّة للخطوة الزمنيّة الحاليّة t).
نموذج الترجمة الآليّة العصبونيّة Neural Machine Translation Model
في المثال التوضيحيّ التالي، تُعبِّر كلّ نبضة للمُشفّر أو فاكّ الشيفرة عن معالجة شبكة RNN للمُدخلات وتوليد الخرج لتلك الخطوة الزّمنيّة. بما أنّ المُشفّر و فاكّ الشيفرة هما شبكتان عصبونيّتان إرجاعيّتان RNN، فإنه في كلّ خطوة زمنيّة تقوم شبكة واحدة من شبكات RNN ببعض المعالجة، حيث تقوم بتحديث حالتها المخفيّة اعتمادًا على دخلها الحاليّ وعلى دخلها السابق. إذا نظرنا إلى الحالات المخفيّة للمشفّر، نلاحظ أنّ الحالة المخفيّة الأخيرة ما هي إلا السياق الذي سيمُرّ إلى فاكّ الشيفرة.
فاكّ الشيفرة لديه أيضًا حالة مخفيّة تنتقل من خطوة زمنيّة إلى أخرى ولكن لم يتمّ عرضها في المثال السابق.
يبيّن المثال التوضيحيّ التالي طريقة أخرى أسهل لفهم نموذج سلسلة إلى سلسلة. سنستخدم في المثال التالي طريقة عرض تُسمّى “مَبسُوطة أو منشورَة”، فبدلًا من إظهار وحدة فاكّ شيفرة واحدة سنقوم بعرض نسخة منها لكلّ خطوة زمنيّة. وهكذا يمكننا النظر للمُدخلات و المُخرجات عند كلّ خطوة زمنيّة.
والآن دعونا نركز فيما سيأتي
تبيَّن مما سبق أنّ مُتّجه السياق أصبح عنق الزّجاجة في مثل هذا النوع من النماذج (سلسلة إلى سلسة)، حيث أصبح تعامُل هذه النماذج مع الجمل الطويلة يمثّل تحديا حقيقيّا. تمّ اقتراح حلّ لهذه المشكلة في الورقتين البحثيّتين التاليّتين [4][5]. قدّمت هاتان الورقتان ونقّحتا آليّة الاهتمام Attention وذلك أدّى إلى تحسين جودة أنظمة الترجمة الآليّة بشكل كبير. تسمح آليّة الاهتمام للنموذج بالتركيز على الأجزاء المناسبة من سلسلة الدّخل حسب الحاجة.
يُبيّن المثال التوضيحيّ التالي (الشكل 3)، أنه في الخطوة الزّمنية السابعة، تُمكّن آليّة الاهتمام فاكّ الشيفرة من التركيز على كلمة “طالب” (“étudiant” في اللغة الفرنسية) قبل أن تقوم بتوليد الترجمة الإنجليزيّة لها. إنَّ هذه القدرة على تضخيم الإشارة من الأجزاء المناسبة من سلسلة الدخل، تجعل النماذج التي تعتمد على آليّة الاهتمام تُعطي نتائج أفضل من النماذج الأخرى التي لا تعتمد على هذه التقنيّة.

دعونا نواصل النظر على نماذج الاهتمام Attention Models وفق مستوى عالٍ من التجرّد. يختلف نموذج الاهتمام عن نموذج سلسلة إلى سلسلة التقليديّ بشيئين رئيسيّين:
أولاً: يمرّر المُشفّر كمية أكثر من البيانات لفاكّ الشيفرة. فعوضًا عن تمرير الحالة المخفيّة الأخيرة لمرحلة التشفير، يمرّر المُشفّر جميع الحالات المخفيّة لفاكّ الشيفرة كما هو واضح في المثال التوضيحيّ التالي.
ثانياً: يقوم فاكّ الشيفرة في النماذج التي تعتمد على آليّة الاهتمام بخطوة إضافيّة قبل توليد خرجه، فمن أجل التركيز على أجزاء سلسلة الدّخل المناسبة للخطوة الزّمنيّة الحاليّة لعمليّة فكّ التشفير، يقوم فاكّ الشيفرة بالخطوات التالية:
- يقوم بالنظر على مجموعة الحالات المخفيّة التي يستقبلها من المُشفّر، حيث ترتبط كلّ حالة مخفيّة للمُشفّر بكلمة معيّنة من جملة الدّخل.
- يقوم بإعطاء كلّ حالة مخفيّة درجة score (دعونا نتجاهل كيف تتمّ عملية حساب الدرجات)
- يتمّ تطبيق تابع سوفت ماكس softmax على كلّ حالة مخفيّة، ومن ثم يُضرب الناتج بالدرجة الخاصة بها. يؤدّي ذلك إلى تضخيم الحالات المخفيّة ذات الدّرجات العالية وتقليص الحالات المخفيّة ذات الدّرجات المنخفضة.
تتمُّ عمليّة حساب الدّرجات في كلّ خطوة زمنيّة في فاكّ الشيفرة. يبين المثال التوضيحيّ التالي الخطوات التي يقوم بها فاكّ الشيفرة في النماذج التي تعتمد على آليّة الاهتمام.
والآن دعونا نجمع كلّ ما تكلّمنا عنه أعلاه عن فاكّ الشيفرة في الرّسم التوضيحيّ التالي لنرى كيفيّة عمل آليّة الاهتمام:
- يأخذ فاكّ الشيفرة في الشبكات العصبونيّة الإرجاعيّة RNN -التي تعتمد على آليّة الاهتمام- مُتّجه التضمين embedding vector لوحدة <END> و الحالة المخفيّة الأوّليّة لفاكّ الشيفرة.
- تُعالج الشبكة العصبونيّة الإرجاعيّة RNN دخلها و تقوم بتوليد الخرج و متّجه حالة مخفيّة جديد (h4).
- يتمُّ تنفيذ خطوة الاهتمام: يتمُّ استخدام الحالات المخفيّة للمُشفّر و مُتّجه الحالة المخفيّة h4 من أجل حساب مُتّجه السياق (C4) للخطوة الزّمنيّة الحالية.
- يتمُّ سَلْسَلة (concatenate) المتّجهين h4 و C4 في مُتّجه واحد.
- يتمُّ تمرير هذا المتّجه الجديد عبر شبكة عصبونيّة ذات تغذية أماميّة feedforward neural network (تمَّ تدريبها مع نموذج سلسلة إلى سلسة).
- يُعبّر خرج الشبكة العصبونيّة ذات التغذية الأماميّة عن كلمة الخرج لهذه الخطوة الزّمنيّة.
- يتمُّ تكرار الخطوات السابقة من أجل كلّ خطوة زمنيّة تالية.
يُبيّن المثال التوضيحيّ التالي طريقة أخرى لمعرفة أيّ جزء من جملة الدخل يتمُّ التركيز عليه عند كلّ خطوة من خطوات فكّ التشفير.
لاحظ عزيزي القارئ أنّ النموذج قد تعلّم – في مرحلة التدريب – كيفيّة محاذاة الكلمات في الزّوج اللغويّ (فرنسي – إنكليزي في حالتنا). أي أنه قام بربط كلمات الخرج مع كلمات الدّخل بشكل صحيح. بمعنى آخر، تَعلّم النموذج كيف يُركّز على الكلمة الصحيحة من جملة الدّخل، ليولّد الترجمة الصحيحة والمقابلة لها في جملة الخرج). يُعطي الشكل (4) مثالًا عن مدى دقّة هذه الآليّة.

يمكننا رؤية كيف أنّ النموذج أعطى اهتمامًا بشكل صحيح عند توليد “European Economic Area”. ففي اللغة الفرنسيّة ترتيب هذه الكلمات معكوس (“européenne économique zone”) مقارنةً مع اللغة الإنجليزيّة. نلاحظ أيضًا أنّ كلّ كلمات الجملة – في اللغتين – لها نفس الترتيب.
عزيزي القارئ، إنّ التطبيق العمليّ للترجمة الآليّة المُعتمدة على الشبكات العصبونيّة سلسلة إلى سلسلة seq2seq خارج سياق هذا المقال، ولكن لو كان لديك الشغف لتطبيق هذه الآليّة عمليًّا، يمكنك الاطلاع على مستودع الشيفرة البرمجيّة التالي هنـــا.
المراجع
- Visualizing A Neural Machine Translation Model
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Visualizing A Neural Machine Translation Model



3 تعليقات
موضوع شيق وتم عرضه باسلوب رااائع رغم صعوبته
ممكن ايميل حضرتك ؟ للإستفسار عن شئ مهم
شكرا لك على كلماتك المُشجعة. يمكنك إرسال أي استفسار إلى بريد المدونة وهو hello@aiinarabic.com