
المحتويات
- كيف تستطيع الحواسيب فهم لغة الإنسان؟؟؟
- هل بإمكان الحواسيب أن تفهم اللغة؟
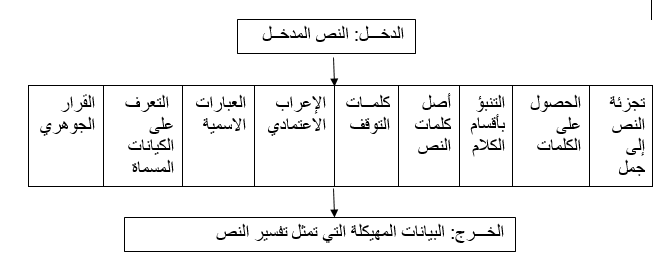
- بناء تسلسل معالجة اللّغات الطّبيعية خطوة بخطوة
- المرحلة الأولى: تجزئة الجمل Sentence Segmentation
- المرحلة الثانية: الحصول على الوحدات اللغوية Tokenization
- المرحلة الثالثة: التنبؤ بأقسام الكلام Part of Speech لكل وحدة لغوية
- المرحلة الرابعة: أصل كلمات النص Lematization
- المرحلة الخامسة: تحديد كلمات التوقف
- المرحلة السادسة:
- أ. الإعراب الاعتمادي Dependency Parsing
- ب: إيجاد العبارات الاسمية
- المرحلة السابعة: التعرف على الكيانات المسماة Named-Entity Recognition NER
- المرحلة الثامنـــة: القرار الجوهري Coreference Resolution
- برمجة تسلسل مراحل معالجة اللغات الطبيعية باستخدام بايثون
- الخلاصــة
- المراجـــع
كيف تستطيع الحواسيب فهم لغة الإنسان؟؟؟
تبدو الحواسيب رائعة في معالجة البيانات المهيكلة مثل الجداول الإلكترونية وقواعد البيانات، لكننا نحن كبشر نتواصل مع بعضنا من خلال الكلمات لا الجداول. وهذا غير مألوف للحاسوب الذي لا يفقه إلا أرقاما وبيانات منظمة فالكثير من المعلومات في الواقع هي غير مهيكلة، مثلاً النصوص المكتوبة باللغة الإنجليزية أو العربية أو غيرها من اللغات الطبيعية. لنفكر معاً كيف سنجعل الحاسوب يفهم هذه النصوص غير المهيكلة ويستخرج منها البيانات المناسبة.
لنفكر معاً كيف سنجعل الحاسوب يفهم هذه النصوص غير المهيكلة ويستخرج منها البيانات المناسبة.
|
مدينة دمشق هي عاصمةُ الجمهورية العربية السورية و أكبر المدن السورية من حيث الكثافة السكانية؛ تعتبر مدينة دمشق من أقدم العواصم المأهولة في العالم، وقد رجِّح المؤرِّخون أن تاريخ المدينة يعود إلى ما قبل الألف السابع قبل الميلاد، حيث تم العثور على بعض الحفريات في منطقة تل الرماد، ودلّت هذه الحفريات أن تاريخ المدينة يعود إلى تسع آلاف سنة قبل الميلاد. يعود اسم (دمشق) إلى أصولٍ آشوريّةٍ قديمةٍ و يعني الأرض العامرة والزّاهِرة، دَلالةً على جمال طبيعتها وتضاريسها الخلّابة، ويُقال بأنها سُميت (شام) نسبةً إلى سام بن نوح عليه السلام. تقع مدينة دمشق في الجزء الجنوبي الغربي من الجمهورية السوريّة، يحدّ المدينة سهول حوران وجبال القلمون والبادية السورية و تحيط بالمدينة بساتين الغوطة، وربوة دمشق، وجبل قاسيون، كما تطل المدينة على ضفاف نهر بردى. |
دمشق -عاصمةُ الجمهورية العربية السورية -أكبر المدن السورية من حيث الكثافة السكانية -من أقدم العواصم المأهولة في العالم -ذات أصولٍ آشوريّةٍ قديمةٍ
|
تعتبر معالجة اللغات الطبيعية من تطبيقات الذكاء الصنعي التي تركز على تمكين الحاسوب من فهم ومعالجة اللغات البشرية.
دعونا نرى كيف تعمل معالجة اللغات الطبيعية ونتعلم كيفية كتابة برامج استخلاص المعلومات من النصوص الخام باستخدام لغة البرمجة بايثون Python.
ملاحظة: عزيزي القارئ إذا لم تكن مهتماً بمعرفة آلية عمل معالجة اللغات الطبيعية، وتريد فقط أخذ الكود البرمجي، فأنصحك أن تتجاوز هذه الفقرات وتنتقل إلى قسم تسلسل برمجة معالجة اللغات الطبيعية باستخدام بايثون.
هل بإمكان الحواسيب أن تفهم اللغة؟
تستمر محاولات المبرمجين في كتابة برمجيات تفهم اللغات البشرية طالما يستمر استخدام الحواسيب في حياتنا. والسبب وراء ذلك واضح، فالبشر يكتبون ما يريدونه منذ آلاف السنين وسيكون من المفيد حقاً إذا أصبحت أجهزة الحواسيب تقرأ وتفهم تلك البيانات المكتوبة.
ما زالت الحواسيب لا تستطيع فهم اللغة البشرية بشكل صحيح تماماً مثل الطريقة التي يفهم بها الإنسان. لكن يمكنها أن تقدم الكثير من المساعدة للإنسان. ستشعر أن معالجة اللغات الطبيعية في بعض المجالات تشبه أعمال السحر.فأنصحك أن تطبق تقنيات معالجة اللغات الطبيعية على مشاريعك الخاصة، وأن تستخدم مكتبات بايثون مفتوحة المصدر الخاصة بمعالجة اللغات الطبيعية لتتابع أحدث التطورات في معالجة اللغات الطبيعية مثل SpaCy ،Textacy و neuralcoref فبأسطر قليلة ستحقق عملاً رائعاً.
بناء تسلسل معالجة اللّغات الطّبيعية خطوة بخطوة
دعونا نأخذ هذا الجزء من النص:
“مدينة دمشق هي عاصمةُ الجمهورية العربية السورية و أكبر المدن السورية من حيث الكثافة السكانية؛ تعتبر مدينة دمشق من أقدم العواصم المأهولة في العالم، وقد رجِّح المؤرِّخون أن تاريخ المدينة يعود إلى ما قبل الألف السابع قبل الميلاد، حيث تم العثور على بعض الحفريات في منطقة تل الرماد، ودلّت هذه الحفريات أن تاريخ المدينة يعود إلى تسع آلاف سنة قبل الميلاد. يعود اسم (دمشق) إلى أصولٍ آشوريّةٍ قديمةٍ و يعني الأرض العامرة والزّاهِرة، دَلالةً على جمال طبيعتها وتضاريسها الخلّابة، ويُقال بأنها سُميت (شام) نسبةً إلى سام بن نوح عليه السلام. تقع مدينة دمشق في الجزء الجنوبي الغربي من الجمهورية السوريّة، يحدّ المدينة سهول حوران وجبال القلمون والبادية السورية و تحيط بالمدينة بساتين الغوطة، وربوة دمشق، وجبل قاسيون، كما تطل المدينة على ضفاف نهر بردى”.
تتألف هذه الفقرة النصية من عدة حقائق مفيدة. وسيكون شيئاً عظيماً إذا استطاع الحاسوب أن يفهم من قراءته للنص أن دمشق هي عاصمةُ الجمهورية العربية السورية و هي من أكبر المدن السورية من حيث الكثافة السكانية، وكذلك تعدّ من أقدم العواصم المأهولة في العالم، وذات أصولٍ آشوريّةٍ قديمةٍ.
لنحقق ذلك، علينا أن نعلّم الحاسوب أولاً المفاهيم الأساسية للغة المكتوبة، ثم ننتقل إلى المراحل الأخرى للوصول إلى فهم النص.
المرحلة الأولى: تجزئة الجمل Sentence Segmentation
إن المرحلة الأولى في مراحل معالجة اللغات الطبيعية هي تقطيع النص إلى الجمل المكون منها، فمن النص السابق المدروس تكون الجمل:
| مدينة دمشق هي عاصمةُ الجمهورية العربية السورية و أكبر المدن السورية من حيث الكثافة السكانية |
| تعتبر مدينة دمشق من أقدم العواصم المأهولة في العالم |
| وقد رجِّح المؤرِّخون أن تاريخ المدينة يعود إلى ما قبل الألف السابع قبل الميلاد…. |
إنّ كل جملة من جمل النص تعبر عن فكرة معينة كما هو الأمر بالنسبة لأي نص في اللغة الطّبيعية، لذلك يكون من الأسهل أن نجعل الحاسوب يفهم فكرة جملة إلى أن يصل إلى فهم كامل النص المؤلّف من هذه الجمل. ومن الشّائع في تقطيع النصوص الاعتماد على علامات التنقيط، حيث تشكّل علامات التنقيط الفاصل بين جمل النص، وفي حال لم يكن النص منسّقاً باستخدام علامات التنقيط فيمكن اعتماد طرق أكثر تعقيداً لتقطيع النص والحصول على جمله.
المرحلة الثانية: الحصول على الوحدات اللغوية Tokenization
في المرحلة الثانية سنقوم بتقطيع الجمل التي حصلنا عليها إلى الوحدات اللغوية Tokens ، في حالتنا تتمثل token بالكلمة word ، ويمكن أن تتم هذه المرحلة من المعالجة على التسلسل أي معالجة جملة تلو الجملة الأخرى.
لنأخذ الجملة الأولى من النص المدروس على سبيل المثال
“مدينة دمشق هي عاصمةُ الجمهورية العربية السورية و أكبر المدن السورية من حيث الكثافة السكانية”
تتمثل هذه المرحلة التي تدعى Tokenization (الحصول على الوحدات اللغوية) بتقطيع الجمل إلى كلماتها، فإذا طبقنا عملية الحصول على الوحدات اللغوية على الجملة المدروسة سنحصل على الكلمات التالية:
“مدينة”، “دمشق”، “هي”، “عاصمةُ”، “الجمهورية”، ” العربية”، “السورية”، “و”، “أكبر”، “المدن”، “السورية”، “من”، “حيث”، “الكثافة”، “السكانية”، “.”.
إن عملية الحصول على الكلمات في اللغة الإنجليزية بسيط لأنه يمكن أن يكون الفراغ هو الفاصل بين كلمات الجمل أما بالنسبة إلى اللغة العربية فالأمر أكثر تعقيداً، لوجود ضمائر متصلة بالكلمة وكل ضمير يحمل معنىً مختلفاً.
تُفصل علامات التنقيط كوحدة لغوية Token مستقلة، وذلك لأننا نعرف أن كل علامة تنقيط لها معنى مختلف عن الأخرى.
المرحلة الثالثة: التنبؤ بأقسام الكلام Part of Speech لكل وحدة لغوية
سنقوم في هذه المرحلة بإسناد كل وحدة لغوية إلى قسم الكلام المناسب لها سواء كان اسماً، أو فعلاً أو صفة.
إن معرفة الدور الذي تؤديه كل كلمة في الجملة سوف يساعد الحاسوب على فهم ما تعنيه هذه الجملة. سنحصل على أقسام الكلام من خلال تمرير الكلمة والسياق المجاور لها إلى نموذج تصنيف أقسام الكلام المدرب مسبقاً.
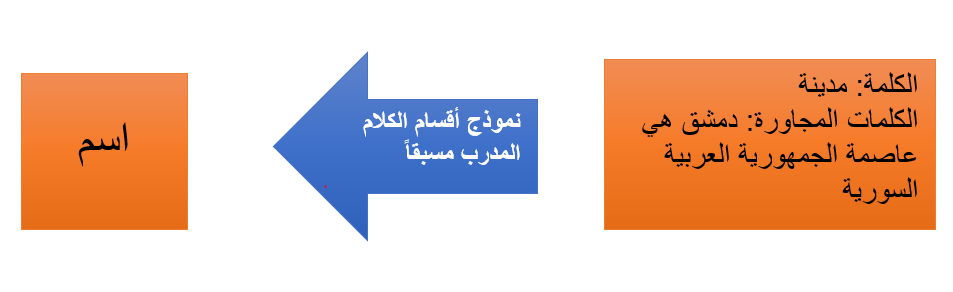
يتم تدريب نماذج أقسام الكلام على مجموعة كبيرة من الجمل بحيث تكون كل جملة موسومة tagged بأقسام الكلام المناسب لها.
لنأخذ باعتبارنا أن النموذج يعتمد بشكل كلي على الإحصاءات ومهما كانت نتائجهم صحيحة لكنه بالتأكيد لن يفهم ماذا تعني الكلمات في الحقيقة كما نفهمها نحن كبشر.
إن النموذج يعرف فقط كيف يتنبأ بأقسام الكلام بناء على الجمل والكلمات التي مررت له سابقاً.
بعد معالجة الجملة التالية “تعتبر مدينة دمشق من أقدم العواصم المأهولة في العالم” يمكن أن نحصل على النتيجة التالية:
| تعتبر | دمشق | من | أقدم |
| “فعل” | “اسم علم” | “حرف جر” | “اسم” |
| العواصم | المأهولة | في | العالم |
| “اسم” | “اسم” | “حرف جر” | “اسم” |
عند حصولنا على هذه المعلومات ، سنستطيع البدء بجمع المعاني الأساسية، على سبيل المثال بعد معرفتنا أن الأسماء تضم “دمشق” و “العواصم” فإن الجملة ربما تتحدث عن دمشق.
المرحلة الرابعة: أصل كلمات النص Lematization
تظهر الكلمة في اللغات الطبيعية بأشكال مختلفة ، مثلاً في اللغة الإنجليزية يضاف حرف s إلى آخر بعض الكلمات لتعبر عن الجمع، أما في اللغة العربية فتضاف بعض الحروف وتحذف بعضها لتعبر عن حالات مختلفة في علم الصرف للغة العربية، وأصل الكلمة هو الشكل الأساسي لها على سبيل المثال فإن الشكل الأساسي لكلمة “يحتاجون” في اللغة العربية هي “احتاج” وكذلك الشكل الأساسي لكلمة “studied” في اللغة الإنكليزية “study”.
ومن المفيد أن يعرف الحاسوب أصل الكلمات أي شكلها الأساسي كي يعرف أن الجمل التي تحتوي هذه الكلمات تدل على مفهوم واحد. فكما تعلم عزيزي القارئ أن الحاسوب يفهم الكلمات كلها كمحارف فإذا اختلفت هذه المحارف ولو اختلافاً بسيطاً اعتبرها الحاسوب كلمة مختلفة تماماً.
سنسمي هذه المرحلة في معالجة اللغات الطبيعية إيجاد “أصل الكلمة” أي اكتشاف الشكل الأساسي “Lemma” لكل كلمة في الجملة.
تطبق عملية إيجاد أصل الكلمة على الأفعال والأسماء. فنحن نعلم أن الأفعال تتغير أشكالها بتغير الزمن الذي تدل عليه أو حسب الضمائر المتصلة بها.
عادة يتم الاعتماد على جدول مفهرس لأشكال الكلمات وأصلها بناء على قسمها الكلامي من أجل عملية إيجاد أصل الكلمة، ويمكن أن يكون هناك قواعد مخصصة للكلمات التي لا ترد كثيراً، وتعتبر خوارزميات إيجاد أصل الكلمة مجالاً مفتوحاً للبحث العلمي.
مثال يوضح عملية الحصول على أصل الكلمة:
| تعتبر | دمشق | من | أقدم |
| “اعتبر” | “دمشق” | “من” | “أقدم” |
| العواصم | المأهولة | في | العالم |
| “عاصمة” | “مأهول” | “في” | “عالم” |
المرحلة الخامسة: تحديد كلمات التوقف
نريد الآن أن نفكر بأهمية كل كلمة في الجملة، ففي أغلب اللغات تتكررحروف العطف والتعريف كثيراً خلال الجمل النصية. وعند بناء نماذج إحصائية للغة ستعطي هذه الكلمات تشويشاً للنتيجة حيث أنها تظهر أكثر من باقي الكلمات في الجمل. يمكن تسمية هذه الكلمات بكلمات التوقف Stop Words وهي الكلمات التي يجب حذفها من النص قبل البدء بأي عملية إحصائية. تصبح الجملة المدروسة بالشكل التالي بعد إزالة حروف التوقف “تعتبر مدينة دمشق أقدم العواصم المأهولة العالم”.
يمكن تحديد حروف التوقف بإضافة سلسلة من كلمات التوقف المعروفة، لكن لا يوجد سلسلة قياسية لحروف التوقف مناسبة لكل التطبيقات وذلك لأن كلمات التوقف تختلف من تطبيق لآخر.
على سبيل المثال في اللغة الإنجليزية ، إذا كنت تقوم بإنشاء محرك بحث لموسيقى الروك ، فأنت تريد التأكد من أنك لا تتجاهل كلمة “The”. وذلك لأنه لا تظهر كلمة “The” في أسماء مجالات الموسيقى فقط ، فهناك أيضًا فرقة روك شهيرة من ثمانينيات القرن العشرين تسمى The The.
المرحلة السادسة:
أ. الإعراب الاعتمادي Dependency Parsing
عزيزي القارئ لعلك مللت من كثرة الخطوات، إنها لغة طبيعية ومعالجتها ليست بالأمر السهل فنحن نحاول أن نجعل الحاسوب -الآلة الجامدة -تقرأ لغتنا وتفهم معانيها.
في هذه المرحلة سنكتشف علاقات كلمات الجملة مع بعضها البعض وهذا ما يسمّى الإعراب الاعتمادي.
تتميز اللغة العربية بنظام إعرابي خاص بها، كونها لغة غنية بالمكونات النحوية، فمثلاً لتكن لدينا الجملة التالية: “صديقي وُلِد في دمشق” يمكن أن تكون الهيئات التركيبية للجملة – أي ترتيب المكونات النحوية التي تتألف منها الجملة- كما يلي:
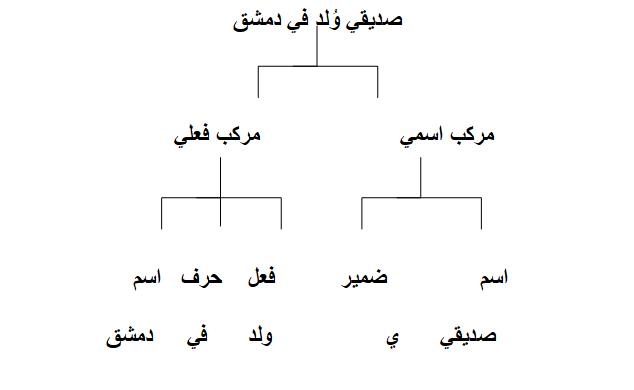
إذا أحببت أن تدرس مرحلة معالجة الإعراب في اللغة العربية بالتفصيل انظر إلى المراجع [1] [2].
سنأخذ الجملة التالية “تُعتبر دمشق من أقدم العواصم المأهولة في العالم، وهي عاصمة سورية”
الهدف من مرحلة الإعراب الاعتمادي هو بناء شجرة تعيّن كلمة أصل واحدة لكل كلمة في الجملة. وسيكون جذر الشجرة هو الفعل الرئيسي في الجملة.
ستبدو شجرة التحليل كما يلي:
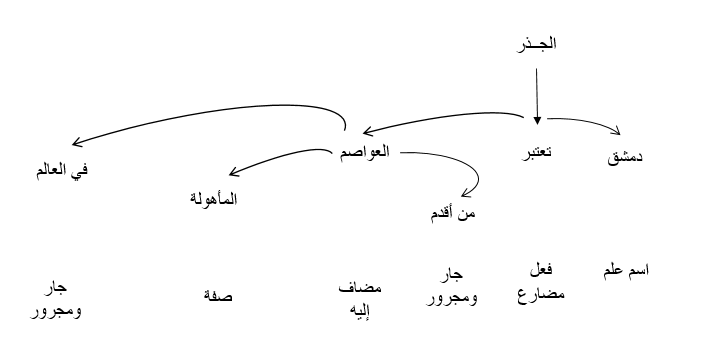
بالإضافة إلى تحديد الكلمة الأب لكل كلمة، نستطيع أيضاً التنبؤ بنمط العلاقة الموجودة بين هذه الكلمات.
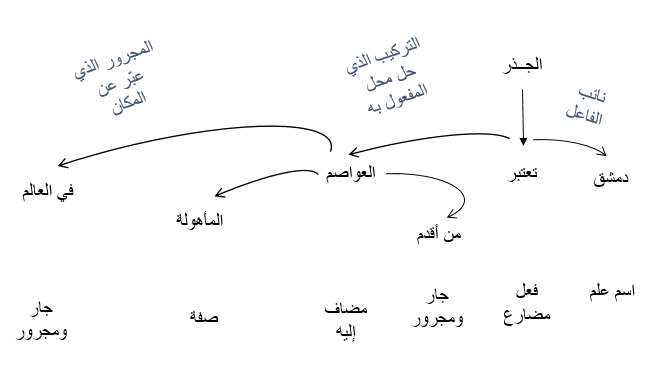
توضح لنا هذه الشجرة التحليلية أن نائب الفاعل في الجملة هو الاسم “دمشق” وله علاقة “تُعتبر” مع “العواصم”، ونحن نعلم سابقاً من مرحلة إيجاد أصل الكلمة أن أصل العواصم “عاصمة”، وبالتالي علمنا شيئاً مفيداً وهو أن دمشق عاصمة وإذا تابعنا شجرة التحليل الكاملة لهذه الجملة، فسنكتشف أن دمشق هي عاصمة سورية.
يعمل الإعراب الاعتمادي أيضًا على تمرير الكلمات إلى نموذج التعلم الآلي وإخراج النتيجة، تمامًا مثل الطريقة التي تنبأنا بها عن أقسام الكلام في المرحلة السابقة باستخدام نموذج التعلم الآلي. ولكن الإعراب الاعتمادي مهمة معقدة بشكل خاص وتتطلب مقالات أخرى لشرحها بالتفصيل.
يمكن اعتبار هذا الأسلوب في الإعراب الاعتمادي هو طريقة قياسية لكن قد يجد البعض أنه أصبح قديماً، حيث أصدرت Google في عام 2016 محللًا جديدًا للاعراب يُدعى Parsey McParseface والذي تفوق على المعايير السابقة باستخدام منهج جديد للتعلم العميق انتشر سريعًا في جميع الأنحاء. بعد ذلك بعام ، أطلقوا نموذجًا أحدث أطلق عليه اسم ParseySaurus مما زاد من تحسين الأمور. وبذلك يمكننا القول، أن تقنيات الإعراب لا تزال مجالًا للبحث العلمي.
من المهم أن نتذكر أن اللغة العربية غنية بالمكونات النحوية وتحتاج إلى دراسة تحليلية تخصصية لمعرفة إعرابها الصحيح، وكذلك هناك عدة جمل إنجليزية غامضة ويصعب تحليلها، وفي هذه الحالات ، سيقدم النموذج تخمينًا اعتماداً على ما يبدو إعراب الجملة ، لكنه ليس مثالياً وأحيانًا سيكون النموذج خاطئًا بشكل كبير. لذلك مع مرور الوقت، ستستمر نماذج معالجة اللغات الطبيعية في تحسين إعراب النص بطريقة مقبولة، على مستوى جميع اللغات، ولا سيّما اللغة العربية التي هي قيد البحث والتطوير.
ب: إيجاد العبارات الاسمية
حتى الآن، تعاملنا مع كل كلمة في الجملة ككيان منفصل. لكن في بعض الأحيان يكون من المنطقي تجميع الكلمات التي تمثل فكرة أو شيء واحد معًا. يمكننا استخدام المعلومات من شجرة الإعراب الاعتمادي لتجميع الكلمات التي تتحدث عن نفس الشيء تلقائيًا.
على سبيل المثل بدلاً من هذا الشكل:
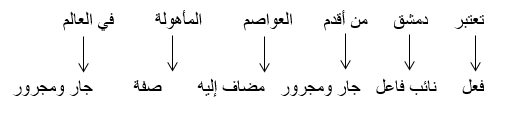
يمكننا تجميع الكلمات التي وقعت في محل جرّ وعبرت عن فكرة واحدة، لتوليد ذلك الشكل:
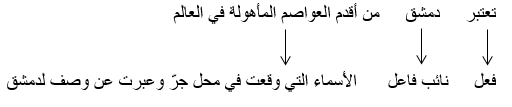
إن هذه المرحلة اختيارية وذلك بناء على الهدف المطلوب. وغالبًا تكون هذه المرحلة طريقة سريعة وسهلة لتبسيط الجملة إذا لم نكن بحاجة إلى المزيد من التفاصيل.
المرحلة السابعة: التعرف على الكيانات المسماة Named-Entity Recognition NER
بعد أن أنهينا القسم الصعب، الذي كان يهتم بالقواعد، ننتقل إلى استخراج الأفكار من الجمل.
في جملتنا المدروسة لدينا الأسماء التالية:
“تعتبر دمشق من أقدم العواصم المأهولة في العالم، وهي عاصمة سورية”
| دمشق | أقدم | العواصم | المأهولة |
| العالم | عاصمة | سورية |
تشير بعض هذه الأسماء على أشياء من الواقع مثلا دمشق ، سورية لها مواقع جغرافية على الخريطة يمكنك تحديدها. وبذلك سنقوم بالاستخراج الآلي للائحة من الأماكن الحقيقية المذكورة في المستند النصي باستخدام معالجة اللغات الطبيعية.
الهدف من التعرف على الكيانات المسماة هو تحديد وتسمية label هذه الأسماء Nouns بمفاهيم حقيقية تمثلّها.
تصبح جملتنا بعد تمريرها على نموذج تحديد الكيانات المسماة بالشكل التالي:
| دمشق | أقدم | العواصم | المأهولة |
| موقع جغرافي | |||
| العالم | عاصمة | سورية | |
| موقع جغرافي |
لكن أنظمة التعرف على الكيانات المسماة لا تقتصر مهمتها على إنجاز قاموس بسيط فحسب، إنما تستخدم سياق الكلام لتعرف كيفية ظهور الكلمة و النموذج الإحصائي للتنبؤ بنوع الاسم الذي تمثله الكلمة.
فنظام التعرف على الكيانات المسماة الجيد يستطيع تمييز “شام” (اسم لفتاة) أنّها شخص و “شام” مكان ذو موقع جغرافي وذلك من السياق.
سنورد لكم بعض الأشياء التي تستطيع أنظمة التعرف على الكيانات المسماة تسميتها.
- أسماء الأشخاص
- أسماء الشركات.
- المواقع الجغرافية(الفيزيائية والسياسية)
- أسماء المنتجات
- التاريخ والوقت
- كميات النقود
- أسماء الأحداث.
إن التعرف على الكيانات المسماة له الكثير من الاستخدامات لأنه يسّهل كثيراً عملية الحصول على البيانات المنظمة من النص، والوصول إلى فهمه [3].
المرحلة الثامنـــة: القرار الجوهري Coreference Resolution
عند هذه المرحلة نكون قد أوجدنا التمثيل المفيد للجمل، من أجل كل جملة نعرف أقسام الكلام لكل كلمة، كيفية ارتباط الكلمات مع بعضها والكلمات التي تمثل كيانات مسماة.
لكننا ما زلنا نعاني من مشكلة أخرى، فأغلب اللغات الطبيعية مليئة بالضمائر لأنها تستخدم لتختصر تكرار بعض الكلمات. وتستطيع البشر أن تتبع سياق النص لتعرف على ماذا يدل كل ضمير في الجمل. لكن نماذج معالجة اللغات الطبيعية التي تتعامل مع كل جملة على حدا لن تستطيع أن تعرف دلالة الضمائر.
فإذا نظرنا إلى الجملة التالية:
“مدينة دمشق هي عاصمة الجمهورية العربية السورية وهي من أقدم العواصم المأهولة في العالم، وقد أسسها الآشوريون”
إذا عالجنا هذه الجملة بالخطوات المتسلسلة لمعالجة اللغات الطبيعية سنعرف أن “هي” من أقدم العواصم لكن من المفيد والمهم أن نعرف أن “دمشق” من أقدم العواصم.
يستطيع البشر ببساطة اكتشاف أن “هي” تعني “دمشق”. إن الهدف من هذه المرحلة هو تمكين الحاسوب من إنجاز هذا التتبع، تتبع الضمائر عبر الجمل، ومعرفة كل الكلمات التي تشير إلى نفس الكيان.
نلاحظ نتيجة تنفيذ المقطع النصي على مرحلة القرار الجوهري.
“مدينة دمشق هي عاصمة الجمهورية العربية السورية وهي من أقدم العواصم المأهولة في العالم، وقد أسسها الآشوريون”
والآن سنكون قادرين على استخراج الكثير من المعلومات من النص نتيجة دمج المعلومات الجوهرية مع شجرة الإعراب ومعلومات الكيانات المسماة.
إن القرار الجوهري هو أحد الخطوات الصعبة في تسلسل خطوات تطبيق معالجة اللغات الطبيعية، حتى أنها أكثر صعوبة من الإعراب الاعتمادي للجمل. ولقد أدت التطورات الحديثة في التعلم العميق إلى مناهج جديدة أكثر دقة، لكنّها ما زالت قيد الدراسات والأبحاث العلمية.
برمجة تسلسل مراحل معالجة اللغات الطبيعية باستخدام بايثون
ملاحظة: قبل المتابعة ، تجدر الإشارة إلى أن هذه هي الخطوات في تسلسل معالجة اللغات الطبيعية نموذجية ، فقد نتخطى بعض الخطوات أو نعيد ترتيب الخطوات اعتمادًا على ما نريد القيام به وكيفية تنفيذ مكتبات معالجة اللغات الطبيعية. على سبيل المثال ، تقوم بعض المكتبات مثل Spacy بتنفيذ تجزئة الجمل بالاعتماد على نتيجة مرحلة الإعراب الاعتمادي.
والآن لنفكر معاً كيف يمكننا تنفيذ كل هذه الخطوات، خطوات معالجة اللغات الطبيعية.
إذا كنا نعمل على معالجة اللغة الإنجليزية فهناك عدة مكتبات بلغة البايثون ستساعدنا في تنفيذ هذه الخطوات، أما إذا أردنا معالجة اللغة العربية فالأمر مختلف، لأن اللغة العربية ما زالت بحاجة إلى دعمكم أيها القراء والباحثون في هذا المجال، فأغلب المكتبات لم تدعم اللغة العربية بعدُ.
لذا لنتعرف على أداء مكتبات بايثون في معالجة اللغات الطبيعية [4]، سنأخذ نصاً مكتوباً باللغة الإنجليزية.
في البداية سنقوم بتنصيب مكتبتي معالجة النصوص Spacy وtextacy على اعتبار أن بايثون 3 موجود على الجهاز بشكل مسبق.
# Install spaCy
pip3 install -U spacy
# Install textacy which will also be useful
pip3 install -U textacy
python -m spacy download en
يكون كود تشغيل سلسلة معالجة اللغات الطبيعية على مقطع نصي كما يلي:
import spacy
nlp=spacy.load("en_core_web_sm")
text ="""Damascus is the capital of the Syrian Arab Republic and the most densely
populated Syrian city; Damascus is one of the oldest inhabited capitals in the world,
and historians have suggested that the city's history dates back to before the seventh
millennium B.C,Some of the excavations were found in the area of Tall Arramad, and these
excavations indicate that the history of the city dates back to nine thousand years BC.
The name (Damascus) dates back to ancient Assyrian origins and means the land full of bright and flower, indicating the beauty of nature and scenic terrain, It is said that it was named (Sham) relative to Sam bin Noah, peace be upon him.The city of Damascus is located in the southwestern part of the Syrian Republic, bordering the plains of Horan and the mountains of Qalamoun. The city is surrounded by orchards of Ghouta, Rabwat Damascus, and Mount Qassioun. The city also overlooks the banks of the Barada River"""
doc = nlp(text)
for entity in doc.ents:
print(f"{entity.text} ({entity.label_})")
يكون الخرج على الشكل التالي:
- the Syrian Arab Republic (GPE)
- Syrian (NORP)
- Damascus (GPE)
- seventh (ORDINAL)
- Arramad (PERSON)
- nine thousand years (DATE)
- Damascus (GPE)
- Assyrian (NORP)
- Sham (PERSON)
- Sam bin Noah (PERSON)
- Damascus (GPE)
- the Syrian Republic (GPE)
- Horan (GPE)
- Qalamoun (GPE)
- Ghouta (GPE)
- Rabwat Damascus (PERSON)
- Mount Qassioun (PERSON)
- the Barada River (LOC)
تعبر GPE عن الكيان الموقع الجغرافي، LOC المكان، Ordinal العدد. نلاحظ أن إسناد بعض الكلمات إلى تسمياتها كان خاطئاً، مثل إسناد ربوة دمشق إلى Person شخص وجبل قاسيون إلى Person شخص.
إذا كان النص يحتوي على كلمات فريدة أو مصطلحات مخصصة فلن يكون نموذج التعرف على الكيانات المسماة المبني في مكتبة بايثون SpaCy مدرباً على هذه الكلمات ولذلك لا بدّ لك من معايرة النموذج ليناسب كلماتك.
إذا تغيرت القوانين وأردنا أن نزيل أسماء الأشخاص فالأمر سيكلف الكثير من الوقت إذا تم عمله يدوياً، لذلك نقوم بإزالة هذه الأسماء من خلال معالجة اللغات الطبيعية من خلال الكود البرمجي التالي:
#Replace a token with "REDACTED" if it is a name
def replace_name_with_placeholder(token):
if token.ent_iob != 0 and token.ent_type_ == "PERSON":
return "[REDACTED] "
else:
return token.string
نفحص في السطر 3 وجود الكيان المسمى “Person””شخص” لاستبداله بما يشير إليه “REDACTED”
#Loop through all the entities in a document and check if they are names
def scrub(text):
doc = nlp(text)
for ent in doc.ents:
ent.merge()
tokens = map(replace_name_with_placeholder, doc)
return "".join(tokens)
s = """
In 1950, Alan Turing published his famous article "Computing Machinery and Intelligence". In 1957, Noam Chomsky's
Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
"""
print(scrub(s))
وعند تنفيذ هذا الكود ستكون النتيجة:
In 1950, [REDACTED] published his famous article "Computing Machinery and Intelligence" in 1957 [REDACTED]
Syntactic Structures revolutionized Linguistics with 'universal grammar' rule based system of syntactic structures.
استخلاص الحقائق
يمكننا استخدام الخرج الناتج من Spacy كدخل لخوارزميات استخلاص البيانات الأكثر تعقيداً، فمثلاً لدينا مكتبة textacy التي تنفذ عدة خوارزميات استخلاص البيانات، منها خوارزمية استخراج العبارات النصف مهيكلة Semi-Structured Statement Extraction يمكننا استخدامها للبحث في شجرة الإعراب الاعتمادي عن عبارات بسيطة موضوعها “دمشق”.
ويجب أن يساعدنا ذلك في العثور على حقائق حول دمشق.
سنطبق الكود البرمجي التالي لتحقيق ذلك:
import textacy.extract
nlp = spacy.load('en_core_web_sm')
# The text we want to examine
text = """Damascus is the capital of the Syrian Arab Republic and the most densely populated Syrian city; Damascus is one of the oldest inhabited capitals in the world, and historians have suggested that the city's history dates back to before the seventh millennium B.C,Some of the excavations were found in the area of Tall Arramad, and these excavations indicate that the history of the city dates back to nine thousand years BC. The name (Damascus) dates back to ancient Assyrian origins and means the land full of bright and flower, indicating the beauty of nature and scenic terrain, It is said that it was named (Sham) relative to Sam bin Noah, peace be upon him.The city of Damascus is located in the southwestern part of the Syrian Republic, bordering the plains of Horan and the mountains of Qalamoun. The city is surrounded by orchards of Ghouta, Rabwat Damascus, and Mount Qassioun. The city also overlooks the banks of the Barada River"""
# Parse the document with spaCy
doc = nlp(text)
# Extract semi-structured statements
statements = textacy.extract.semistructured_statements(doc, "Damascus")
# Print the results
print("Here are the things I know about Damascus:")
for statement in statements:
subject, verb, fact = statement
print(f" - {fact}")
سيكون الخرج كما يلي:
:Here are the things I know about Damascus
the capital of the Syrian Arab Republic and the most densely populated Syrian city-
وإذا قمنا بتنفيذ نفس الكود على جزء من نص مقالة ويكيبيديا عن دمشق [5] “Damascus”.
فسنحصل على النتيجة التالية:
:Here are the things I know about Damascus
a major cultural center of the Levant and the Arab world-
the center of a large metropolitan area of 2.7 million people (2004)-
وللحصول على معلومات أكثر دقة، جرّب تشغيل neuralcoref بشكل إضافي حيث أنها تعتمد في عملها على الشبكات العصبونية، ثم تنفيذ مرحلة القرار الجوهري ضمن تسلسل المعالجة فستحصل على معلومات موجودة في الجمل التي تحتوي على الضمير العائد إلى “دمشق”، وليس فقط المعلومات الموجودة في الجمل التي تحتوي “دمشق” بشكل مباشر.
ماذا يمكن أن نفعل أيضاً؟
من خلال الاطلاع على مستندات spacy ومحررات النصوص ، سترى الكثير من الأمثلة على الطرق التي يمكنك من خلالها التعامل مع النصوص التي تم تحليلها. ما رأيناه حتى الآن هو مجرد عينة صغيرة.
إليك مثال عملي آخر: تخيل أنك تقوم بإنشاء موقع ويب يتيح للمستخدم عرض المعلومات لكل مدينة في العالم باستخدام المعلومات التي استخرجناها في المثال السابق.
إذا كانت لديك ميزة بحث على موقع الويب ، فقد يكون من الجيد الإكمال التلقائي لطلبات البحث الشائعة مثل Google:
ولكن للقيام بذلك ، نحتاج إلى قائمة بالإكمالات الممكنة لاقتراحها على المستخدم. يمكننا استخدام معالجة اللغات الطبيعية لتوليد هذه البيانات بسرعة.
في ما يلي طريقة لاستخراج أجزاء الأسماء التي يتم ذكرها بشكل متكرر من مستند:
import spacy
import textacy.extract
# Load the large English NLP model
nlp = spacy.load('en_core_web_sm')
# The text we want to examine
text ="""Damascus is the capital of the Syrian Arab Republic and the most densely populated Syrian city; Damascus is one of the oldest inhabited capitals in the world, and historians have suggested that the city's history dates back to before the seventh millennium B.C,
Some of the excavations were found in the area of Tall Arramad, and these excavations indicate that the history of the city dates back to nine thousand years BC.
The name (Damascus) dates back to ancient Assyrian origins and means the land full of bright and flower, indicating the beauty of nature and scenic terrain,
It is said that it was named (Sham) relative to Sam bin Noah, peace be upon him.The city of Damascus is located in the southwestern part of the Syrian Republic, bordering the plains of Horan and the mountains of Qalamoun. The city is surrounded by orchards of Ghouta, Rabwat Damascus, and Mount Qassioun. The city also overlooks the banks of the Barada River"""
# Parse the document with spaCy
doc = nlp(text)
# Extract noun chunks that appear
noun_chunks = textacy.extract.noun_chunks(doc, min_freq=3)
# Convert noun chunks to lowercase strings
noun_chunks = map(str, noun_chunks)
noun_chunks = map(str.lower, noun_chunks)
# Print out any nouns that are at least 2 words long
for noun_chunk in set(noun_chunks):
if len(noun_chunk.split(" ")) > 1:
print(noun_chunk)
إذا طبقنا هذا الكود البرمجي على المقطع النصي المستخدم فلن نحصل على نتيجة لأنه مقطع نصي قصير، إذا أخذنا نصاً أطول من مقالة ويكيبيديا سيكون الخرج:
barada river-
عزيزي القارئ إذا كنت مهتماً بالأكواد البرمجية ستجدها في ملف NLPCode.Jpynb.
نظرة أعمق
هذه لمحة عن الأفكار الأساسية في معالجة اللغات الطبيعية. لكن في الواقع هناك تطبيقات أخرى لـمعالجة اللغات الطبيعية مثل تصنيف النصوص [6] وتحليل الأسئلة والتلخيص [7] وغيرها.
الخلاصــة
تعتبر معالجة اللغات الطبيعية من المواضيع المثيرة للاهتمام في عصر أصبحت به التكنولوجيا شريكة البشر في كل المجالات. تتم معالجة اللغات الطبيعية من خلال مراحل متكاملة مع بعضها للوصول إلى الهدف المطلوب.
إن كل مرحلة من مراحل معالجة اللغات الطبيعية هي قيد البحث العلمي والتطوير. قدّمت مكتبات بايثون كما لاحظنا معاً نتائج جيدة في الوصول إلى فهم بسيط للنص المكتوب باللغة الإنكليزية لكن مازالت بحاجة إلى تطوير ولا نعرف هل ستصل هذه الأدوات إلى تحليل النصوص بما يماثل تحليل وفهم الإنسان.
وأما عن لغتنا العربية فما زالت بانتظار جهودنا وأبحاثنا لنحلل اللغة العربية وخصائصها ونعالج تحدياتها في كل مرحلة من مراحل معالجة اللغات الطبيعية.
المراجـــع
- فاضل سكر, حازم عيسى, محمد سرميني، نظام هجين لتمخيص النص العربي باستخدام قواعد التعلّم الترجيحية والعنقدة المركزية، مجلة بحوث جامعة حلب، 2014.2.
- محمد سرميني، منظومة لتلخيص النص العربي، رسالة أعدّت لنيل لدرجة الماجستير في هندسة الحواسيب، 2015.
- Dania Sagheer, Fadel Sukkar, Text Template Mining using Named Entity Recognition, International Journal of Computer Applications, 2019.
- Adam Geitgey, Natural Language Processing is Fun!, Medium, 2018.
- Dania Sagheer, Fadel Sukkar, Arabic Sentences Classification via Deep Learning, International Journal of Computer Applications, July, 2018.
- Dania Sagheer, Fadel Sukkar, A Hybrid Intelligent System for Abstractive Summarization, International Journal of Computer Applications, June, 2017.



7 تعليقات
شكرا جزيلا ، احب ان اتعلم بايثون لاجل هذا الغرض تحديدا وذلك لان اللغة وعاء الفكر ، لا يستطيع الانسان التفكير بدون لغة ولو كانت لغة اشارة فقط لابد من اللغة ، واذا استطعنا معالجة اللغة وعمل الخوارزميات المطلوبة لجعل الكمبيوتر يحللها بالشكل الصحيح فقد استطعنا جعله يفكر بمعنى ما …
قال الله تعالى في كتابه الكريم : وعلم آدم الاسماء كلها …
الاسماء هي الجزء الاهم في الجملة فهي الكينونة التي تنسب اليها باقي الجملة سواء كانت تخبرنا بوصف لهذا المسمى او تخبرنا عن فعل يقوم به …
اتمنى ان تقومي ببحث وبرمجة كود يستخرج قائمة التناسب بين الحروف في القرآن ، ففي القرآن لا تبدأ كلمة الا بصوت يناسب الصوت السابق مما يعطي النص سلاسة لدى السامع ، فلو قمنا بعمل جدول بكل حروف والحروف التي يمكن ان تعقبه لاستطعنا عمل متنبيء نصي يخبر الكاتب بالحرف المحدد الذي ينبغي ان تبدأ به الكلمة التالية بناءا على الحرف الذي انتهت به الكلمة السابقه ويكون اطلاق هذا الاجراء عندما يقوم المستخدم بضغط المسطرة لعمل فاصلة بين الكلمتين ، كنت قد عملت بدايات لهذه الفكرة بالجافا سكربت لكني توقفت لانها لا تفي بالغرض حتى النهاية ، شكرا لاتاحة الفرصة لعرض الفكرة
قيل في الاثر كلموا الناس على قدر عقولهم …
اذا كنت لا احدث الطالب الا بمستوى معين ، ولا احدث الطفل الا بمستواه ، واتحدث مع المبرمج باسلوب يختلف عن حديثي مع جارتي فوزية ذات السبعين عاما …اذا كان ذلك كذلك فلماذا نطمع ان نصنع برنامج يفهم كل كلام بغض النظر عن تصنيف الكلام ؟ نفس الخطأ الذي وقع فيه مترجم قوقل فهو يترجم من خلال قاموس عام ، فما اكثر ما اشاهد فيديوات في اليوتيوب عن الذكاء الاصطناعي واستعين بالترجمة التلقائية فيصر مترجم قوقل على ان يترجم AI الى “منظمة العفو الدولية” ولو انهم جعلوا المترجم يقوم باحصاء سريع لفئة النص وعندما يعرف ان النص يتحدث عن تكنولوجيا المعلومات فسوف تأخذ الكلمات معانيها من خلال السياق وليس معانيها القاموسية ، فهذا التصنيف من شأنه ان ينتج برامج متخصصة تفهم الادب ونطور فيها تحليل ودراسة الاستعارة البلاغية ، بينما في النصوص العلمية المتعلقة بالفيزياء والكيمياء فلا توجد استعارة بلاغية فلا جهد يبذل هناك في هذا الصدد ، واما اللغة العربية فينبغي ان نرجع فيها الى لغة قياسية لان العرب اصبحوا يستخدمون لغتهم بشكل سيء وصارت المعاني فضفاضة تفسر باكثر من طريقة ، بينما لغة القرآن هي اللغة القياسية التي يجب ان ننطلق منها لوضع المعاني للالفاظ ، فنتابع مثلا كلمة عاد ورجع في القرآن سنجد ان الصحيح استعمال رجع بينما عاد تعني redo والعرب يخلطون بينهما .. واعتقد انه لو اخذنا هذا النص المقدس كمدخلات لحصلنا على بيانات نموذجية قياسية نستطيع ان نعرف من خلال انماطها شكل العلاقة بين اجزاء الكلام …
شكرا لأفكارك ومداخلاتك استاذ اسماعيل
شكرا لقراءتك واقتراحاتك
مواضيع الترجمة الآلية ما زالت قيد الأبحاث العلمية…
مقال جدا ممتاز – خاصة للباحثين
شكرا لقراءتك وتعليقك..
أرجو الفائدة لجميع الباحثين والطلاب…
السلام علكيم، شكرا لمجهودك الرائع. هل يوجد مكتبات للغة العربية؟ لاحظت في المثال تطبيقك على جملة انجليزية وانا ابحث عن تحليل للغة العربية لمشروعي الشخصي. هل يوحد شي كهذا؟