إعداد: م. رند عبد الله
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. رامي عقّاد
المَحتويَات
يتّجه العالم اليوم بطريقةٍ غير مسبوقةٍ نحو كلّ ما يخصّ الذّكاء الإصطناعيّ، ابتداءً بالأبحاث العلميّة وتطوير النّماذج وانتهاءً بتصميم الأدوات الّتي استطاعت الدّخول بقوّةٍ إلى مجالات العمل المختلفة.
وتتسابق عمالقة شركات التّكنولوجيا في توليد نماذج قادرة على تلبية مختلف الاحتياجات بطريقةٍ تقترب قدر الإمكان من التّفكير البشريّ،
و يخوض هذا السّباق شركات كبرى أهمّها أَوْبَن أيه آي Open ai بنموذجها المعروف شات جي بي تي Chat GPT وجوجل Google بنموذج جيميناي Gemini وبالطّبع ميتا من خلال نماذج عائلة لاما LLaMA والّتي هي بطلة مقالنا لليوم ، والعديد من الشّركات الأخرى.
ونستعرض في هذا المقال معلومات موسّعة حول نموذج لاما LLaMA، بالإضافة إلى بنية هذا النّموذج وإصداراته، أحجام النّماذج وقدرتها، أهمّ ميّزات نماذج لاما LLaMA، استخدامات النّموذج وأيضاً معلوماتٍ أخرى.
مقدّمةٌ علميّةٌ
منذ صدور الورقة البحثيّة بعنوان الانتباه وحده يكفي ” Attention is all you need” تغيّر مفهوم الذّكاء الإصطناعيّ بشكلٍ كبيرٍ، حيث تمّ إطلاقها من قبل مجموعةٍ من الباحثين في جوجل عام 2017 وقامت بتقديم بنيةٍ جديدةٍ للنّماذج اللّغوية تعتمد بشكلٍ أساسيٍّ على المحوّلات Transformers بمختلف أنواعها.
يمكنك الاطّلاع على المزيد حول هذه المعماريّة في هذا المقال
وبالفعل، أصبحنا نلاحظ نماذج بقدراتٍ هائلةٍ تسمّى النّماذج اللّغويّة الكبيرة Large Language Model. وهي عبارةٌ عن شبكاتٍ عصبونيّةٍ عميقةٍ مدرّبةٍ على مجموعاتٍ ضخمةٍ من البيانات؛ لفهم اللّغة الطّبيعيّة وتوليدها.
إنّ الأساس في هذه النّماذج يكمن في القدرة على التّنبّؤ بتسلسلٍ صحيحٍ، بحيث تعتمد على التّركيز على تسلسل المدخلات؛ لتوليد مخرجاتٍ منطقيّةٍ تناسب الأوامر Prompts. ومن خلال هذه القدرات أصبحنا نرى نماذج قادرةً على الكتابة، التّحليل، توليد الصّور والفيديو وغيرها من المهام.
تتميّز هذه النّماذج عن بعضها البعض بالحجم، القدرة على الحوسبة، الكفاءة والسّرعة، مجموعة البيانات المستخدمة في التّدريب وغيرها. وسنركّز اليوم على نموذج لاما LLaMA المقدّم من قبل شركة ميتا META بشكلٍ خاصٍّ.
ما هي نماذج عائلة لاما LLaMA؟
بدأت أوّل إصدارات لاما عام 2023 من قبل شركة ميتا META. تعتبر لاما Large Language Model Meta AI) LLaMA) عائلةً من النّماذج اللّغويّة مفتوحة المصدر open source، مصمّمة لإنتاج نصوصٍ تشبه النّصوص البشريّة بالاعتماد على على علوم تعلّم الآلة وخصوصاً معالجة اللّغات الطّبيعيّة NLP.
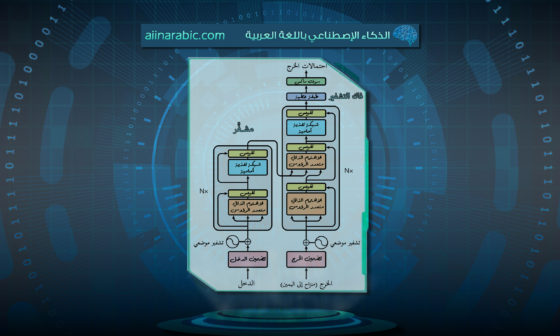
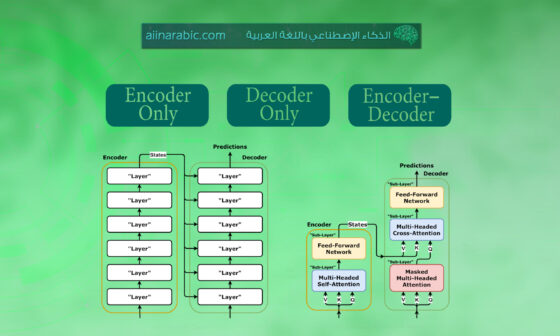
تصنّف عائلة اللاما LLaMA على أنّها نماذج انحدارٍ ذاتيٍّ، تعتمد على فاكّ التّشفير فقط (auto-regressive decoder-only models). وتعتمد في بنيتها على المحوّلات Transformers بشكلٍ أساسيٍّ.
سنبدأ بدراسة بنية الإصدار الأول من اللاما LLaMA 1 ومناقشة اختلافاتها مقارنةً بنموذج المحوّل، ثمّ سننتقل من هناك إلى نموذجي لاما 2 ، لاما 3 حيث سنركّز بشكلٍ خاصٍّ على بنية MLLaMA اللاما متعدّد الوسائط.
لاما LLaMA_1 1
يعمل اللاما 1 LLaMA من خلال التّنبّؤ بالوحدة اللّفظيّة التّالية (TOKEN) بناءً على تسلسل الوحدات اللّفظيّة المدخلة، حيث يقوم بمعالجة تسلسل المدخلات؛ ليتمكّن من إعطاء خرجٍ يناسب هذا التّسلسل من أجل أن يصبح منطقيّاً بشكلٍ مماثلٍ لأيّ نموذجٍ لغويٍّ يعتمد على المحوّلات transformers.
مع ذلك يتضمّن اللاما 1 1 LLaMA بعض التّعديلات الّتي تميّزه في الهيكليّة، بما في ذلك التّطبيع المسبق للمدخلات بواسطة RMSNorm واستخدام دالّة التّفعيل SwiGLU والتّضمين الموضعيّ الدّورانيّ “Rotary Position Embedding “RoPE.
لاما 2 و لاما 3
باختصارٍ، تشترك عائلة نماذج LLaMA في معظم بنيتها. ونقدّم فيما يلي الاختلافات بين الإصدارات الثّلاثة للنّموذج:
- يبلغ طول السّياق في إصدار لاما 1 حوالي ألفي وحدةٍ لفظيّةٍ tokens، بينما في لاما 2 يبلغ حوالي أربعة آلاف وحدةٍ لفظيّةٍ، أمّا في إصدار لاما3 الأحدث فيبلغ طول السّياق حوالي ثماني آلاف وحدةٍ لفظيّةٍ Token.
- يعتمد كلّ من LLaMA 2 و LLaMA 3 على استعلام الاهتمام الجماعي GQA، حيث يستخدم LLaMA 2 استعلام الاهتمام الجماعيّ (GQA) فقط في نماذج المعاملات الأكبر، بينما LLaMA 3 يستخدمه في جميع إصداراته.
لاما متعدّد النّماذج MLLaMA
على الرّغم من وجود عدّة نماذج في عائلة لاما، إلّا أنّه حتّى الآن يبقى نموذج لاما متعدّد النماذج MLLaMA هو الأفضل بين الجميع، بحيث يدمج بين قدرات الرّؤية واللّغة. أي يستطيع التّعامل مع النّصوص والصّور معاً وليس النّصوص فقط.
لاتزال التّفاصيل التّقنيّة لكيفيّة ربط هذا النّموذج بين الفهم البصريّ واللّغويّ غير واضحةٍ إلى حدٍّ كبير، وتركّز معظم المناقشات على المعايير والقدرات تاركةً وراءها فجوةً في فهم ابتكاراته المعماريّة.
يرى الباحثون والخبراء في مجال الذّكاء الإصطناعيّ متعدّد الوسائط عدّة أساليب لدمج الرّؤية الحاسوبيّة مع نماذج اللّغة المعروفة اختصاراً بـ (VLM). على سبيل المثال يستخدم مساعد اللّغة والرّؤية Large Language and Vision” LLaVA” مخرجات مرمَّز الرّؤية (Vision Encoder)، ثمّ يعرضها كمدخلٍ لنموذج اللّغة، كما في الرّسم البيانيّ التّالي:
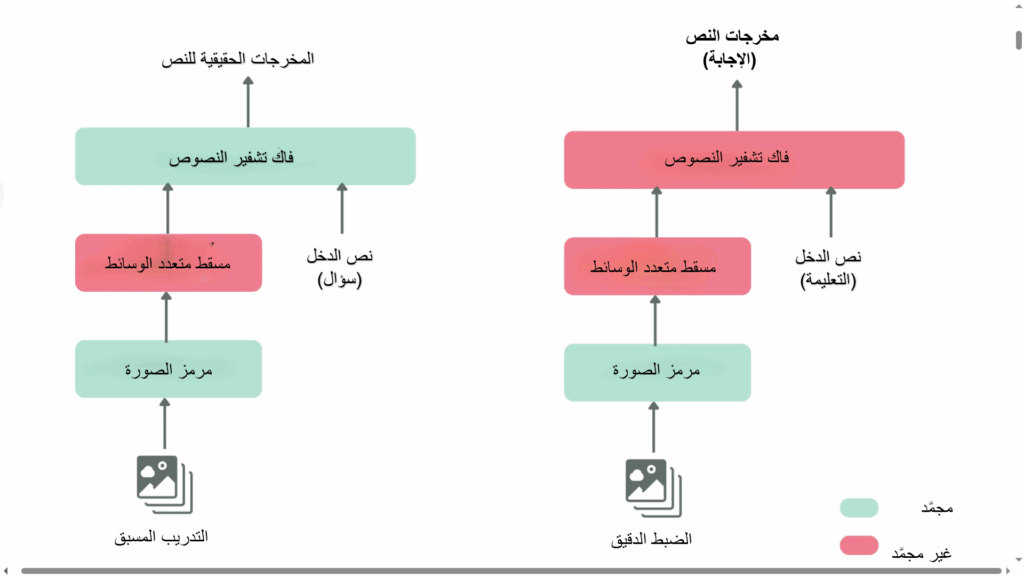
الشكل (1) يوضح آلية دمج الرؤية الحاسوبية مع نماذج اللغة
بينما يعمل اللاما متعدد النماذج بأسلوبٍ مميّزٍ في معالجة الصّور، حيث يستخدم مرحلتين منفصلتين لفهم الرّؤية.
تشمل هاتين المرحلتين على تحليلٍ أوّليٍّ، ثمّ تعالج مرّة ثانية، وبعد ذلك يتمّ دمج المعلومات البصريّة مع النّصّ عبر آليّةٍ تسمّى الانتباه التّبادليّ (cross-attention).
قام الباحثون بتحليل بنية النّموذج والاطّلاع على الشّيفرة المصدريّة (الكود)؛ لفهم سبب التّصميم بهذه الطّريقة وتأثير هذا الأسلوب على الأداء. كان التّركيز اللاما متعدد النماذج 3.2 بحجم 11 مليار مُعامل (11B) والمتوفّر على منصّة هاغينغ فيس Huggingface.
سنناقش فيما يلي، كيف تختلف الطّريقة الّتي يفهم بها النّموذج الصّور (مرمَّز الرّؤية) عن طريقة عمل المحوّلات البصريّة التّقليديّة (Vision Transformers – ViT).
أثناء معالجة الصّورة لا يكتفي نموذج لاما متعدد النماذج 3.2 بالمخرجات النّهائية فقط، بل يحتفظ بعدّة نتائج خلال المراحل الدّاخلية من الشّبكة، ممّا يساعده على فهم الصّورة من عدّة زوايا أو مستويات (مثل التّفاصيل الدّقيقة أو المظهر العامّ للصّورة) وهذا أمرٌ غير شائع في النّماذج متعدّدة الوسائط.
ما يجعل هذا النّموذج مميّزاً هو أنّه لايدمج الصّورة والنّصّ بشكلٍ تقليديٍّ (دمج في البداية early fusion أو النّهاية late fusion)، وإنّما يستخدم آليّة الانتباه التّبادلي (cross- attention) في مراحل معيّنة ومدروسة من النّموذج. وهذا ما يجعله أكثر مرونة ودقّة في فهم العلاقة بين الصّورة والنّصّ.إنّ آليّة الانتباه التّبادلي (cross-attention) هذه تُمكّن النّموذج من التّركيز على المعلومات المهمّة من مصدرٍ مختلفٍ (مثلاً: من الصّورة أثناء قراءة النّصّ).
يتكوّن اللاما متعدد النماذج MLLaMA 3.2 من ثلاثة مكوّناتٍ رئيسيّةٍ:
أولاً: المرمَّز البصريّ (vision Encoder) وينقسم لمرحلتين
- المرحلة الأولى: مرحلة ترميزٍ محلّيٍ يتكوّن من 32 طبقةٍ لمعالجة التّفاصيل الدّقيقة في الصّورة، حيث كلّ جزءٍ يعالج على حدةٍ.
- المرحلة الثّانية: مرحلة ترميز موسّع من 8 طبقات، حيث أنّه يعطي تركيزاً على الصّورة ككل لفهم السّياق العام.
وهذا يعني أنّ النّموذج لا يكتفي بفهم أجزاء الصّورة فقط، وإنّما يعتمد أيضاً على السّياق.
ثانياً: النّموذج اللّغويّ
وهو مبنيٌّ على اللاما 3.1، يتألّف من 40 طبقة محوّلٍ 8 منها طبقات انتباهٍ تبادليٍّ (cross-attention). إنّ الهدف من هذه الطّبقات هو دمج المعلومات البصريّة بالنّصّ. وأيضاً يوجد 32 طبقة انتباهٍ ذاتيٍّ ( self-attention)؛ لمعالجة النّصّ بشكلٍ مستقلٍّ.
أي أنّ النّموذج يستخدم نسخةً من اللاما 3.1 فهم النّصوص، ولكنّه أضاف طبقاتٍ خاصّةٍ تسمح بالتّفاعل مع الصّورة خلال مراحل معيّنة.
ثالثاً: آليّةٌ متقدّمةٌ لدمج الصّورة مع النّصّ
يستخدم النّموذج هنا طريقةً تدعى إسقاط المميزات المدمجة projected concatenated features، وتعني ربط معلومات الصّورة والنّصّ بشكلٍ مدروسٍ وتحويلها لشكلٍ موحّدٍ؛ ومن ثمّ يتمّ تمرير المعلومات المدمجة عبر طبقات الانتباه التّبادليّ (cross-attention) في أماكن استراتيجيّة داخل النّموذج.
وهذا يعني أنّه بدلاً من دمج الصّورة مع النّصّ بشكلٍ تقليديٍّ، يتمّ دمج المعلومات بشكلٍ ذكيٍّ يسمح بالتّفاعل بين الصّورة والنّصّ بشكلٍ تدريجيٍّ ومنظّمٍ.
خلال هذا المقال، سنقوم بتحليل كلّ جزءٍ من هذه المكوّنات بشكلٍ تقنيٍّ مفصّلٍ، وندرس كيف صُمّمت وكيف تتواصل مع بعضها، وسبب اختيار المصمّمين لهذه البنية. وسنستخدم الكود المصدريّ؛ لتحليل التّنفيذ الفعليّ للنّموذج.
ملاحظة: يمكن تحميل النّموذج والأكواد المصدريّة من هاغينغ فيس Huggingface واختبار النّتائج.
نظرةٌ عامّةٌ على بنية اللاما متعدد النماذج MLLaMA
كما ذكرنا سابقاً، يمكن تقسيم بنية اللاما متعدد النماذج MLLaMA إلى ثلاثة مكوّناتٍ رئيسيّةٍ وهي:
المرمَّز البصريّ (Vision Encoder)، النّموذج اللّغويّ (Language Model) وآليّة الدّمج بين الصّورة والنّصّ (Integration Mechanism). وهذه البنية تشبه الكثير من بنية النّماذج البصريّة_اللّغويّة (VLMS).
- مُرمّز الرّؤية (Vision Encoder): يختلف عن طريقة عمل المحوّلات البصريّة التّقليديّة بحيث يستخدم مرحلتين للمعالجة:
- المرحلة الأولى: عبارةٌ عن مرمّزٍ محليٍّ من 32 طبقة، يعالج الصّورة بعد تقسيمها إلى دفعات صغيرةٍ (patches)، ويحافظ على مخرجات الطّبقات الدّاخلية؛ ممّا يسمح بفهم معلومات الصّورة على عدّة مستوياتٍ.
- المرحلة الثّانية: عبارةٌ عن مرمّزٍ عام بـ 8 طبقاتٍ، يستخدم آليّة الانتباه المتحكّم فيه (Gated Attention).
هذه الطّريقة في المعالجة تسمح بدمج التّمثيلات الوسيطة (1280 بعد) مع المخرجات النّهائيّة؛ لينتج تمثيل بصريّ غنيٌّ يمكّن النّموذج من فهم مستوياتٍ متعدّدةٍ من تفاصيل الصّورة.
- النّموذج اللّغويّ: تمّ بناؤه على معماريّة اللاما LLaMA 3.1، يتكوّن من محولٍ بـ 40 طبقة، وهو قائمٌ على وحدة فكّ التّشفير فقط (decoder only)؛ وهذا يعني أنّه مصمّمٌ لإنتاج نصٍّ بناءً على التّسلسل المعطى وليس على تحليل المدخلات. يبلغ حجم التّمثيل الدّاخلي لهذا النّموذج 7096 بُعداً.
تكمن مهمّة هذا النّموذج في دمج معلومات الصّورة (كلّ 5 طبقاتٍ) باستخدام الانتباه التّبادليّ، ممّا يسمح بربط النّصّ بالصّورة بطريقةٍ منظّمةٍ أثناء توليد الجمل.
- آليّة الدّمج بين النّصّ والصّورة: يتمّ استخدام طبقةٍ تدعى طبقة إسقاط (Projection layer)، حيث تأخذ هذه الطّبقة الميّزات المستخرجة من الصّورة وتحوّلها إلى نفس أبعاد النّموذج اللّغويّ (4096 بعداً).
إنّ الهدف هنا ليس في تقليل الأبعاد فقط، وإنّما في تعلّم كيفيّة تطابق المعاني البصريّة مع المعاني النّصّيّة.
يوضّح الرّسم البيانيّ التّالي طريقة ارتباط هذه المكوّنات الثّلاثة ببعضها:
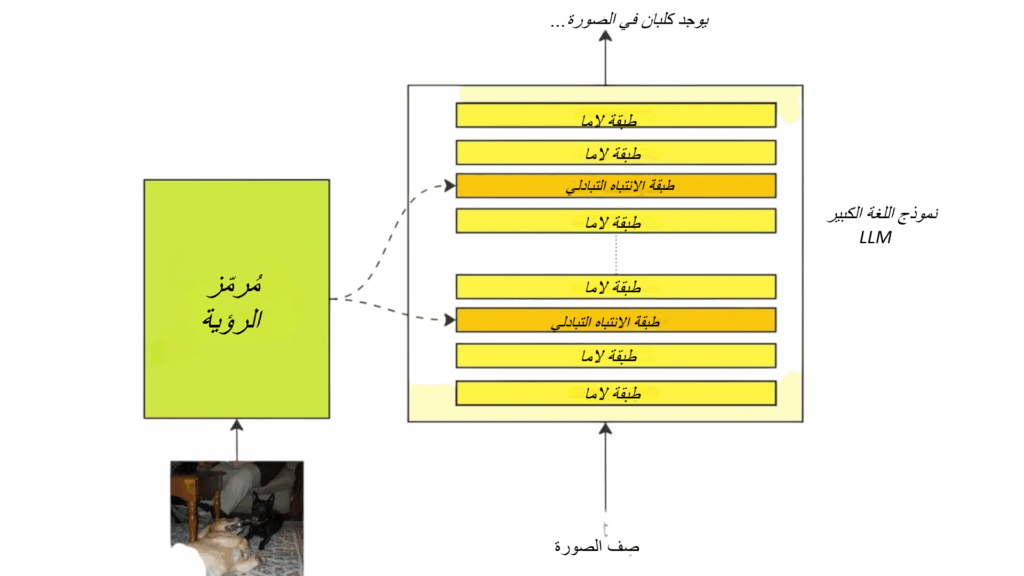
الشكل (2) يوضح بنية النموذج اللغوي-البصري (VLM)
أوّلاً: مُرمّز الرّؤية
بعد فحص طريقة تنفيذ اللاما متعدد النماذج لمكوّن الرّؤية (Vision Encoder)، يتّضح أنّه يستخدم هيكلاً من مرحلتين الأولى لفهم التّفاصيل الدّقيقة والثّانية لفهم الصّورة من منظورٍ شاملٍ. وهذه البنية مختلفةٌ عن الطّريقة التّقليديّة في نماذج المحوّلات البصريّة التّقليديّة Vision Transformer-ViT، الّتي تستخدم مرحلةً واحدةً فقط لتحليل الصّورة.
وكما ذكرنا سابقاً، سيساعد هذا التّصميم على فهم المحتوى البصريّ على أكثر من مستوى، ممّا يجعله أكثر كفاءة عند دمج الصّورة مع النّصّ.
هيّا بنا لنغوص بعمقٍ أكثر من أجل فهم طريقة عمل هذا النّظام في معالجة الصّور، ولماذا هذا الأسلوب في التّصميم مهمٌّ للغاية.
بدايةً، سنعرض نموذج الرّؤية أدناه لنستخدمه كمرجعٍ واضحٍ في الشّرح.
(vision_model): MLLaMAVisionModel(
(patch_embedding): Conv2d(3, 1280, kernel_size=(14, 14), stride=(14, 14), padding=valid, bias=False)
(gated_positional_embedding): MLLaMAPrecomputedPositionEmbedding(
(tile_embedding): Embedding(9, 8197120)
)
(pre_tile_positional_embedding): MLLaMAPrecomputedAspectRatioEmbedding(
(embedding): Embedding(9, 5120)
)
(post_tile_positional_embedding): MLLaMAPrecomputedAspectRatioEmbedding(
(embedding): Embedding(9, 5120)
)
(layernorm_pre): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(layernorm_post): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(transformer): MLLaMAVisionEncoder(
(layers): ModuleList(
(0-31): 32 x MLLaMAVisionEncoderLayer(
(self_attn): MLLaMAVisionSdpaAttention(
(q_proj): Linear(in_features=1280, out_features=1280, bias=False)
(k_proj): Linear(in_features=1280, out_features=1280, bias=False)
(v_proj): Linear(in_features=1280, out_features=1280, bias=False)
(o_proj): Linear(in_features=1280, out_features=1280, bias=False)
)
(mlp): MLLaMAVisionMLP(
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1280, out_features=5120, bias=True)
(fc2): Linear(in_features=5120, out_features=1280, bias=True)
)
(input_layernorm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
)
)
)
(global_transformer): MLLaMAVisionEncoder(
(layers): ModuleList(
(0-7): 8 x MLLaMAVisionEncoderLayer(
(self_attn): MLLaMAVisionSdpaAttention(
(q_proj): Linear(in_features=1280, out_features=1280, bias=False)
(k_proj): Linear(in_features=1280, out_features=1280, bias=False)
(v_proj): Linear(in_features=1280, out_features=1280, bias=False)
(o_proj): Linear(in_features=1280, out_features=1280, bias=False)
)
(mlp): MLLaMAVisionMLP(
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1280, out_features=5120, bias=True)
(fc2): Linear(in_features=5120, out_features=1280, bias=True)
)
(input_layernorm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
)
)
)
)
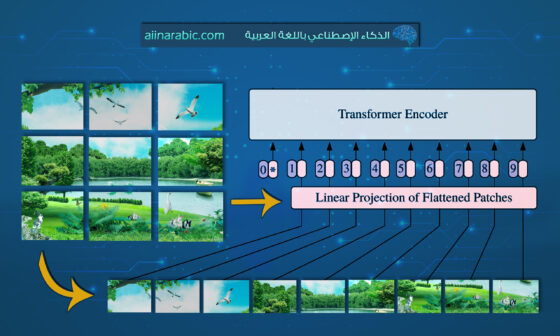
قبل الحديث عن المرمَّزات (Encoders)، من المهمّ أن نفهم كيف يقوم اللاما متعدد النماذج MLLaMA بمعالجة الصّورة قبل إدخالها إلى النّموذج. وفقاً لإعدادات النّموذج configuration، فإنّ الصّورة لا تدخل دفعةً واحدةً، وإنّما يقسّمها إلى دفعات (patches) حجم كلّ دفعةٍ هو 14×14 بيكسل علماً أنّ حجم الصّورة المدخلة هو 448×448 بيكسل.
وبالتّالي، عندما نقسّم الصّورة بهذه الطّريقة سنحصل على شبكةٍ من 32×32 = 1024 دفعة (patches)، وكلّ قطعةٍ سيتمّ تحويلها إلى متّجهٍ (vector) بعده 1280.
هذه الطّريقة بالتّقسيم تجعل النّموذج يرى الصّورة بدقّةٍ أعلى من النّماذج الأخرى متعدّدة الوسائط (VLM)، حيث أنّ معظم النّماذج الأخرى تقسّم الصّورة إلى 24×24 = 576 قطعةٍ فقط.
المرحلة الأولى من مُرمًّز الرّؤية
self.transformer = MLLaMAVisionEncoder(config, config.num_hidden_layers, is_gated=False)
يحافظ بها النّموذج على المعلومات أثناء عمليّة المعالجة، بحيث يحتفظ بمخرجات الطّبقة الوسيطة خلال المراحل المختلفة من التّحليل. بينما عادةً النّماذج التّقليديّة تتجاهل الطّبقات الوسطى، وتركّز فقط على آخر مخرجاتٍ.
# Collect intermediate layer outputs from encoder output
all_intermediate_hidden_states = output[1]
intermediate_hidden_states =torch.stack(all_intermediate_hidden_states, dim=-1)
intermediate_hidden_states=intermediate_hidden_states[...,self.intermediate_layers_indices]
نجد في إعدادات النّموذج (config) متغيّراً يسمّى “intermediate_layers_indices”، والّذي سيحدّد الطّبقات الّتي سيتمّ الاحتفاظ بمخرجاتها الوسيطة، وتحديداً مخرجات الطّبقات 3, 7, 15, 23, 30؛ لينتج ما يعرف بـ ” هرميّة الميّزات متعدّدة المستويات” (multi-scale feature hierarchy).
هذه الطّريقة في التّصميم تتيح للنّموذج الاحتفاظ بمعلوماتٍ بصريّةٍ على مستوياتٍ مختلفةٍ من التّجريد والفهم. فهذه الصّور تحتوي على معلوماتٍ مهمّةٍ بمستوياتٍ مختلفةٍ، والاحتفاظ بهذه المخرجات يسمح للنّموذج بفهم التّفاصيل الدّقيقة، مثل: الحواف والألوان والأنماط المتكرّرة كالوجه والمعنى العامّ للصّورة.
وبالتّالي سيصبح لدينا سلّم من التّمثيلات من البسيط إلى المجرّد ومن التّفاصيل الصّغيرة إلى الفهم الشّامل.
المرحلة الثّانية: المُرمّز الموسّع (الدّمج وآليّة التّقييد)
self.global_transformer = MLLaMAVisionEncoder(config,config.num_global_layers, is_gated=True)
إنّ المرمَّز الموسّع global encoder يقدّم ابتكارين معماريّين رئيسيّين هما:
الأوّل: آليّة الانتباه المقيّد (Gated Attention Mechanisms):
class MLLaMAVisionEncoderLayer(nn.Module):
def __init__(self, config: MLLaMAVisionConfig, is_gated: bool = False):
super().__init__()
self.hidden_size = config.hidden_size
self.num_attention_heads = config.attention_heads
self.is_gated = is_gated
self.intermediate_size = config.intermediate_size
self.self_attn = MLLaMA_VISION_ATTENTION_CLASSES[config._attn_implementation](config)
self.mlp = MLLaMAVisionMLP(config)
self.input_layernorm = nn.LayerNorm(self.hidden_size, eps=config.norm_eps)
self.post_attention_layernorm = nn.LayerNorm(self.hidden_size, eps=config.norm_eps)
if is_gated:
self.gate_attn = nn.Parameter(torch.ones(1) * math.pi / 4)
self.gate_ffn = nn.Parameter(torch.ones(1) * math.pi / 4)
تُستخدم هذه الآليّة للتّحكّم في كيفيّة انتقاء المعلومات الأكثر أهميّة خلال المعالجة، خصوصاً أثناء عمليّة الانتباه (attention) من خلال تحديد أيّ جزءٍ من المعلومات يجب أن يركّز عليه النّموذج وأيّ جزءٍ يمكن تجاهله. هذه الآليّة تساعد في زيادة الكفاءة من خلال التّركيز على الأجزاء الأهمّ فقط.
الثّاني: آليّة دمج المميّزات
حيث يتمّ دمج كلّ التّفاصيل المستخلصة من المرحلة السّابقة ويعاد تشكيلها؛ لفهم الصّورة ككل.
وذلك من خلال معالجة المخرجات مع الحفاظ على الاتّصال مع الميّزات الوسيطة المحفوظة؛ أي يتمّ الدّمج بين الفهم العامّ (مثل سياق الصّورة ككل) والمعلومات التّفصيليّة (مثل الحواف أو الألوان)، حتّى يتمكّن النّموذج من إنشاء تمثيلٍ بصريٍّ غنيٍّ، ممّا يسمح بتفسير الصّورة بشكلٍ أكثر دقّة وكفاءة.
استراتيجيّة دمج الميّزات
# Concatenate final hidden state and intermediate hidden states<br>hidden_state = torch.cat([hidden_state, intermediate_hidden_states], dim=-1<br>
ينتج عن هذا الدّمج (concatenation) متّجه بعده 7680 (أي 1280×6) ويتكوّن من:
- مخرجات المرمَّز الموسّع النّهائيّة (global encoder).
- خمس مجموعاتٍ من الميّزات الوسطيّة (intermediate features).
يحتوي هذا التّمثيل على مستوياتٍ متعدّدةٍ من الفهم البصريّ، ابتداءً من الميّزات منخفضة المستوى (مثل الحواف والألوان) وصولاً إلى المفاهيم عالية المستوى (مثل ماهيّة الأشياء في الصّورة).
هذا ما يوفّر للنّموذج اللّغويّ مجموعةً غنيّةً من الميّزات البصريّة يمكنه الاستفادة منها خلال توليد النّصوص.
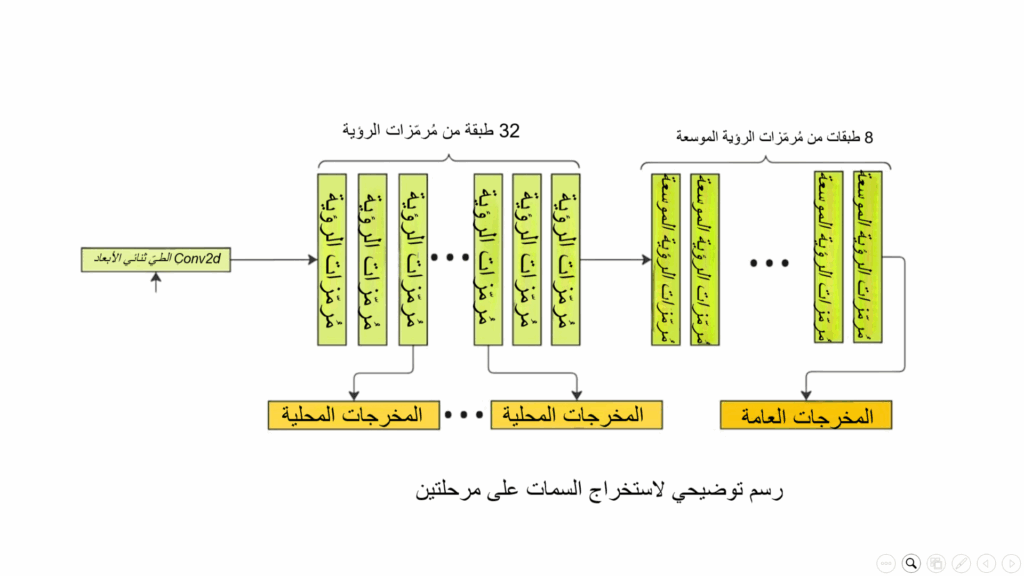
الشكل (3) يوضح مرحلتي استخراج المميزات من الصورة
الآثار المعماريّة
إنّ تصميم النّموذج بالاعتماد على مرحلتين مع الاحتفاظ بالميّزات الوسيطة يقدّم عدّة فوائد منها :
- فهمٌ متعدّد المستويات (Multi-scale Understanding): يستطيع النّموذج الوصول إلى مستوياتٍ مختلفةٍ من التّجريد البصريّ، وهذا مفيدٌ لأداء أنواعٍ مختلفةٍ من الاستدلال (مثل فهم التّفاصيل الدّقيقة أو المفاهيم العامّة).
- الحفاظ على المعلومات (Information Preservation): يُحافظ على التّفاصيل البصريّة الهامّة الّتي قد تضيع أثناء المعالجة ضمن الميّزات الوسيطة المحفوظة.
- دمجٌ متحكّمٌ به (Controlled Integration): آليّة الانتباه المقيّد المستخدمة في المرمَّز الموسّع توفّر تحكّماً قابلاً للتّعلّم حول كيفيّة دمج المستويات المختلفة من المعلومات البصريّة، بحيث تسمح للنّموذج أن يختار بذكاءٍ أيّ مستوى من المعلومات يحتاجه أثناء تحليل الصّورة وربطه بالنّصّ.
يظهر مرمّز الرّؤية في اللاما متعدد النماذج MLLaMA القدرة على دمجٍ متعدّد المستويات للميّزات البصريّة، ومن المرجّح أنّ زيادة دقّة الصّورة (الصّورة المكبّرة) تساعد النّموذج على التقاط المزيد من التّفاصيل البصريّة.
ثانياً: النّموذج اللّغوي
كما شاهدنا سابقاً، معالجة الرّؤية في اللاما متعدد النماذج MLLaMA تقدّم ابتكاراتٍ ملحوظةٍ، إلّا أنّ مكوّن النّموذج اللّغوي يعتمد على بنية الإصدار الثالث من اللاما المعروفة مع بعض التّعديلات والتّصميمات الخاصّة أثناء التّنفيذ؛ ليصبح ملائماً بشكلٍ خاصٍّ لمعالجة المهام متعدّدة الوسائط (الّتي تجمع بين الرّؤية واللّغة).
سنقوم الآن بتحليل كيفيّة بناء هذا المكوّن اللّغويّ وكيف تمّ تكييفه لمعالجة المهام متعدّدة الوسائط.
فيما يلي نظرةٌ عامّةٌ على النّموذج اللّغوي، حيث سنركّز فقط على تفاصيل أوّل طبقتين:
- الطبقة الأولى: طبقة انتباه ذاتي ضمن وحدة فك التشفير لنموذج لاما متعدد النماذج MLLaMASelfAttentionDecoderLayer مسؤولة عن فهم النّصّ نفسه كأيّ نموذجٍ لغويٍّ عادي.
- الطبقة الثانية: طبقة انتباه متبادل ضمن وحدة فك التشفير لنموذج لاما متعدد النماذج MLLaMACrossAttentionDecoderLayer تسمح للنّموذج بالانتباه إلى التّمثيل البصريّ القادم من الصّورة ودمجه مع النّصّ من خلال الفهم أو توليد الإجابة.
هذا النّموذج لا يدمج الصّورة مع النّصّ من البداية ولا يؤجّل حتّى النّهاية، بل يستخدم طبقات الانتباه التّبادليّ (cross attention) موزّعة في مواضع محدّدة، ممّا يحقّق تفاعلاً تدريجيّاً منظّماً بين الصّورة والنّصّ.
هذه البنية تجعل النّموذج مرناً ومناسباً جداً للتّعامل مع محتوى بصريٍّ_لغويٍّ معقّدٍ.
(language_model): MLLaMAForCausalLM(
(model): MLLaMATextModel(
(embed_tokens): Embedding(128264, 4096, padding_idx=128004)
(layers): ModuleList(
(0-2): 3 x MLLaMASelfAttentionDecoderLayer(
(self_attn): MLLaMATextSelfSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): MLLaMATextMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MLLaMATextRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): MLLaMATextRMSNorm((4096,), eps=1e-05)
)
(3): MLLaMACrossAttentionDecoderLayer(
(cross_attn): MLLaMATextCrossSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(q_norm): MLLaMATextRMSNorm((128,), eps=1e-05)
(k_norm): MLLaMATextRMSNorm((128,), eps=1e-05)
)
(input_layernorm): MLLaMATextRMSNorm((4096,), eps=1e-05)
(mlp): MLLaMATextMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(post_attention_layernorm): MLLaMATextRMSNorm((4096,), eps=1e-05)
)
(4-7): 4 x MLLaMASelfAttentionDecoderLayer
(8): MLLaMACrossAttentionDecoderLayer
(9-12): 4 x MLLaMASelfAttentionDecoderLayer
(13): MLLaMACrossAttentionDecoderLayer
(14-17): 4 x MLLaMASelfAttentionDecoderLayer
(18): MLLaMACrossAttentionDecoderLayer
(19-22): 4 x MLLaMASelfAttentionDecoderLayer
(23): MLLaMACrossAttentionDecoderLayer
(24-27): 4 x MLLaMASelfAttentionDecoderLayer
(28): MLLaMACrossAttentionDecoderLayer
(29-32): 4 x MLLaMASelfAttentionDecoderLayer
(33): MLLaMACrossAttentionDecoderLayer
(34-37): 4 x MLLaMASelfAttentionDecoderLayer
(38): MLLaMACrossAttentionDecoderLayer
(39): MLLaMASelfAttentionDecoderLayer
(norm): MLLaMATextRMSNorm((4096,), eps=1e-05)
(rotary_emb): MLLaMARotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
نظرةٌ عامّةٌ على البنية الأساسيّة
يتألّف هذا النّموذج اللّغويّ من 40 طبقة محوّل بحجمٍ مخفيٍّ يبلغ 4096 بعداً. ما يجعل هذه البنية مثيرة للاهتمام هو طريقة تنقّلها بين طبقات الاهتمام الذّاتي القياسيّة وطبقات الاهتمام المتبادل.
وهنا الميزة الأساسيّة في تنفيذ هذه البنية:
class MLLaMATextModel(MLLaMAPreTrainedModel):
config_class = MLLaMATextConfig
base_model_prefix = "language_model.model"
def __init__(self, config: MLLaMATextConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size + 8, config.hidden_size, self.padding_idx)
self.cross_attention_layers = config.cross_attention_layers
layers = []
for layer_idx in range(config.num_hidden_layers):
if layer_idx in self.cross_attention_layers:
layers.append(MLLaMACrossAttentionDecoderLayer(config, layer_idx))
else:
layers.append(MLLaMASelfAttentionDecoderLayer(config, layer_idx))
self.layers = nn.ModuleList(layers)
self.norm = MLLaMATextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = MLLaMARotaryEmbedding(config=config)
self.gradient_checkpointing = False
self.post_init()
يظهر النّمط المتناوب بين الانتباه المتبادل والانتباه الذّاتيّ في كلّ 5 طبقاتٍ ( 3,8,13,23,28,33,38)، ممّا ينشئ نقاط دمجٍ بين الصّورة والنّصّ تسمح للمعلومات البصريّة أن تؤثّر على توليد النّصوص.
كما ويمكننا أيضاً رؤية المبادئ التّصميميّة من مدوّنة لاما LLaMA 3.2 من شركة ميتا.
لدعم إدخال الصّورة، قمنا بتدريب مجموعةٍ من أوزان المحوّل (adapter weights) الّتي تدمج مرمّز الصّور المدرّب مسبقاً داخل نموذج اللّغة المدرّب سابقاً أيضاً.
يتكوّن المحوّل من سلسلةٍ من طبقات الانتباه المتبادل (cross-attention) الّتي تدخل تمثيلات مرمّز الصّورة إلى نموذج اللّغة.
تمّ تدريب هذا المحوّل (adapter) على أزواج نصوص-صور؛ لتوحيد التّمثيل البصريّ مع التّمثيل اللّغويّ، وخلال عمليّة التّدريب تمّ تحديث معاملات مرمّز الصّور مع الحفاظ على معلومات نموذج اللّغة كما هي.
وبالتّالي، تمّ الحفاظ على قدرات النّصّ الأصليّة كما هي ممّا يتيح للمطوّرين استخدام هذا النّموذج كبديلٍ لنماذج اللاما 3.1.
ّتم تحميل طبقات الانتباه الذّاتي في نموذج اللّغة من نماذج لاما Lama 3.1 مباشرة، بحيث ركّزت الأهداف الرّئيسيّة للتّدريب على مرمّز الصّور وطبقات الانتباه المتبادل، وسيتمّ التّوسّع أكثر في شرح هذه الطّبقات في القسم التّالي.
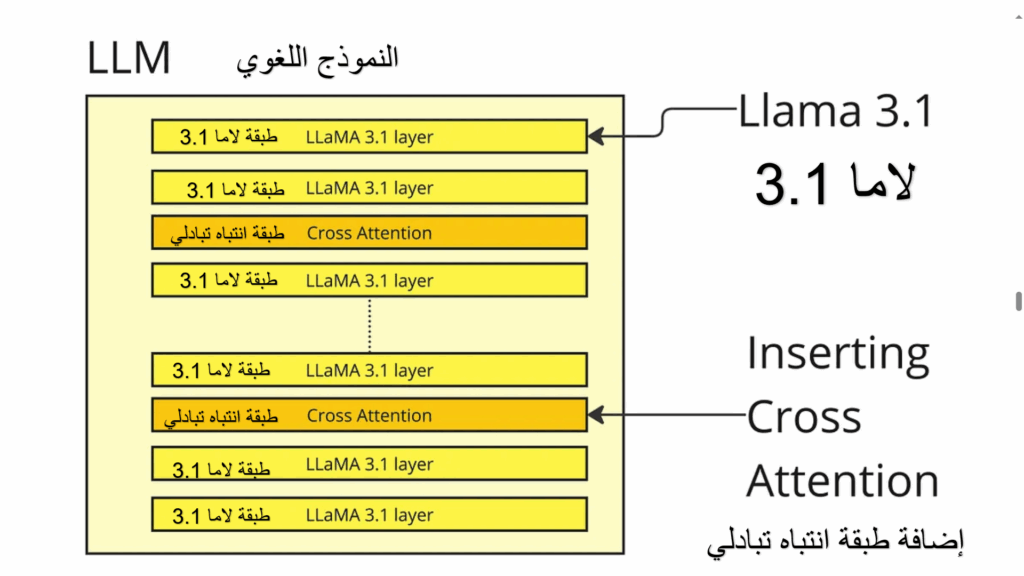
الشكل (4) يوضح طبقات المحول
ثالثاً: استراتيجيّة دمج الصّورة مع النّصّ
إنّ آليّة الدّمج بين ميّزات الصّورة والنّصّ واحدةٌ من أهمّ القرارات في تصميم معماريّة النّماذج متعدّدة الوسائط.
وتعتبر الطّريقة الّتي يستخدمها لاما متعدد النماذج في الدّمج مثيرةً للاهتمام؛ لأنّه لا يكتفي بعمليّة دمجٍ بسيطةٍ، مثل: وضع ميّزات الصّورة والنّصّ سويّةً ثمّ إدخالهم إلى النّموذج، وإنّما يستخدم استراتيجيّة دمجٍ متعدّدة المراحل، ممّا يعطي فهماً أعمق ونتائج أفضل.
دعونا نرى كيف يربط اللاما متعدد النماذج MLLaMA بين الصّور والكلام بطريقةٍ فعّالةٍ.
طبقة الإسقاط متعدّدة الوسائط
في قلب استراتيجيّة الدّمج الخاصّة باللاما متعدد النماذج LLaMAs، نجد جهاز الإسقاط متعدّد الوسائط والّذي يمثّل أوّل جسرٍ يربط بين ميّزات الصّورة والنّصّ.
self.multi_modal_projector = nn.Linear(
config.vision_config.vision_output_dim,
config.text_config.hidden_size,
bias=True,
)
إنّ هذا الإسقاط معقدٌ أكثر ممّا يبدو عليه، والبيانات ذات الـ 7680 بعد قبل الإسقاط (التّحويل) تحتوي العديد من المعلومات حول الصّور، حيث أنّها تشمل:
- النّتائج النّهائيّة من مرحلة معالجة البيانات في المرمَّز الموسّع (Global Encoder)، حيث يتمّ استخراج الفهم الكامل للصّورة.
- الميّزات الوسيطة الّتي تمّ الحصول عليها في مرحلة معالجةٍ مختلفةٍ.
- جمع البيانات البصريّة الّتي تشمل التّفاصيل الصّغيرة والتّصوّرات الموسّعة للصّور.
إذاً، عمليّة الإسقاط (projection) لا تقتصر على تقليص الأبعاد إلى 4096 بعد، بل الهدف هو مزامنة الفهم البصريّ مع الفهم اللّغويّ في نموذج اللّغة؛ حتّى يتمكّن النّموذج من تعلّم ربط مفاهيم الصّور بالكلمات أو الجمل بطريقةٍ تمكّنه من التّفكير انطلاقاً من الصّور والنّصوص معاً، ممّا يساعد على تحقيق فهمٍ موحّدٍ للصّور والنّصوص في آنٍ معاً.
الدّمج الاستراتيجيّ للاهتمام المتبادل
تحدث عمليّة الرّبط بين الفهم البصريّ من الصّور والفهم اللّغويّ من النّصوص المعروفة بالانتباه المتبادل (Cross-Attention)، حيث صُمِّمَت هذه الطّبقات خصّيصاً لمعالجة المعلومات البصريّة. يتمّ تنفيذ آليّة الاهتمام المتبادل من خلال طبقة الانتباه الذاتي ضمن وحدة فك التشفير لـ لاما متعدد النماذج MLLaMACrossAttentionDecoderLayer، ثمّ يتمّ تحويل مخرجات نموذج الرّؤية إلى cross_attention_states، والّتي تُستخدم لحساب المفتاح (key) والقيمة (value) في وحدة الانتباه المتبادل للنص لنموذج لاما متعدد النماذج MLLaMATextCrossAttention.
لقد صُمّمت عمليّة الانتباه التبادلي بهذه الطّريقة التّالية:
- الاستفسارات (queries) تأتي من معالجة النّصوص في نموذج اللّغة؛ أي النّصّ الّذي يتمّ تحليله.
- المفاتيح والقيم يتمّ استخلاصها من المعلومات البصريّة الّتي تمّ تحويلها أو إسقاطها إلى أبعادٍ معيّنةٍ.
- تتحكّم آليّات البوابّات (gating) في تدفّق المعلومات بين النّصّ والصّورة، ممّا يسمح للنّظام بتحديد أيّ المعلومات يجب أن تركّز عليها.
- التّوحيد المنفصل (separate normalization) وهو تقنيّةٌ تضمن أنّ التّدريب على النّموذج يبقى مستقرّاً بحيث لا تحدث مشاكل أثناء تعلّم النّموذج.
باختصارٍ، تهدف العمليّة إلى جعل النّموذج يفهم العلاقة بين الصّور والكلمات، بحيث يستطيع التّعامل مع البيانات متعدّدة الأنماط (مثل النّصوص والصّور) بشكلٍ فعالٍّ.
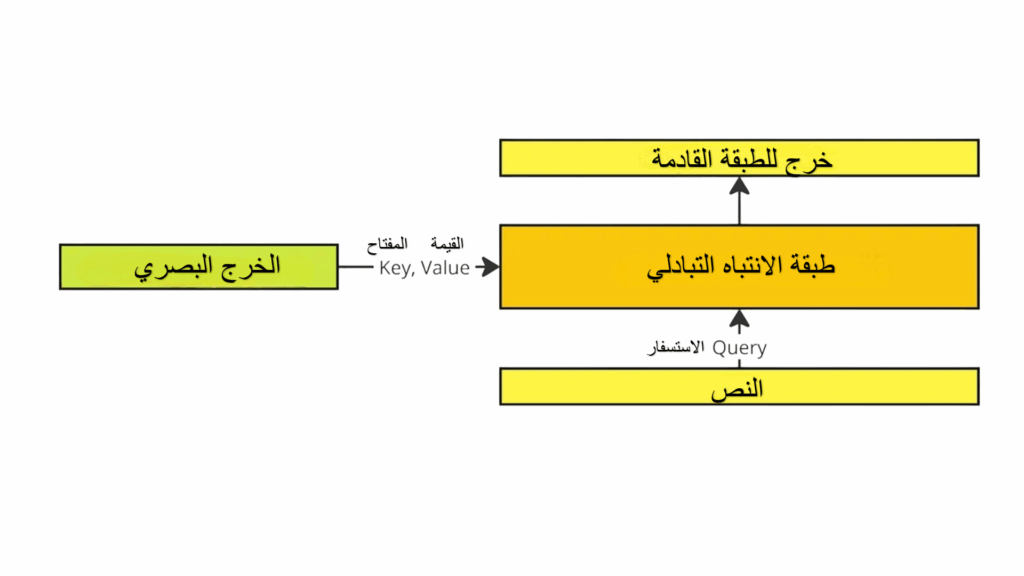
الشكل (5) يوضح آلية الانتباه التبادلي
استراتيجيّة الدّمج متعدّدة النّقاط
إنّ استخدام استراتيجيّة الاهتمام المتبادل في أماكن معيّنة من النّموذج (كلّ 5 طبقاتٍ) ساعدت في تحقيق نتائج أفضل في دمج النّصوص والصّور. ومن أهمّ هذه المزايا:
- التّحسين التّدريجيّ:
- يمكن لطبقات الاهتمام المبكرة أن تدعم ربط النّصوص بالسّياق البصريّ المبكر.
- يمكن للطّبقات المتوسّطة المساهمة في تحسين الفهم متعدّد الأنماط.
- يمكن للطّبقات الأخيرة أن تضمن أنّ يظلّ التّوليد مرتبطاً بالصّورة.
- إعادة استخدام الميّزات:
- حيث يمكن للنّموذج استخدام نفس المعلومات البصريّة عدّة مرّاتٍ عبر طبقاتٍ مختلفةٍ من النّموذج، ممّا يحسّن الكفاءة الحسابيّة.
التّداعيات المعماريّة
تؤدّي هذه الاستراتيجيّة في الدّمج إلى العديد من القدرات المهمّة:
- الاهتمام المرن:
- يمكن للنّموذج أن يركّز على أجزاء معيّنة من الصّورة في مراحل التّوليد المختلفة.
- تتعلّم آليّات البوّابات (gating) أنماط الدّمج الأمثل أثناء التّدريب.
- حفظ المعلومات:
- تحافظ الميّزات البصريّة ذات الأبعاد العالية على عدّة مستوياتٍ من الفهم البصريّ.
- تمنع نقاط الدّمج المنتظمة فقدان السّياق البصريّ أثناء التّوليد.
- التّحكّم في التّوليد:
- يمكن للنّموذج تعديل التّأثير البصريّ على النّصّ بناءً على المهمّة الّتي يقوم بها.
- تُمكّن أقنعة الاهتمام المتبادل من استخدام المعلومات البصريّة بشكلٍ انتقائيٍّ.
إنّ النّجاح الكبير لقدرات اللاما متعدد النماذج MLLaMA ينبع بشكلٍ رئيسيٍّ من هذه الاستراتيجيّة المتطوّرة للدّمج. هذه الاستراتيجيّة المتطوّرة تجعل النّموذج قادراً على التّعامل مع كلٍّ من النّصوص والصّور بكفاءةٍ، مع ضمان الحفاظ على السّياق البصريّ وتحسين التّفاعل بين الأنماط المختلفة.
دمج المعلومات البصريّة واللّغويّة :
بعد أن تعرّفنا على كلّ جزءٍ من اللاما متعدد النماذج MLLaMA بالتّفصيل، سنعرض هنا تدفّق العمليّة من البداية إلى النّهاية؛ لنفهم سبب اتّخاذ بعض القرارات الخاصّة بهيكليّة النّموذج وكيف ساهمت في رفع قدرات النّموذج.
عندما تقوم بإدخال صورةٍ وتسأل “ماذا يوجد في هذه الصّورة”، إليك ما سيحدث بالضّبط:
- مرحلة معالجة الرّؤية: تمرّ الصّورة عبر خط أنابيب معالجة الرّؤية.
- يتمّ تقسيم الصّورة إلى قطعٍ صغيرةٍ (شبكة 32×32).
- يتمّ معالجتها عبر المرمَّز المحلّيّ المكوّن من 32 طبقةٍ لاستخلاص الميّزات البصريّة.
- يتمّ حفظ بعض الميّزات الوسيطة الهامّة في الطّبقات (3,7,15,23,30).
- يتمّ معالجتها عبر المرمَّز الموسّع المكوّن من 8 طبقات.
- في النّهاية، يتمّ دمج هذه الميّزات لتشكيل تمثيلٍ رقميٍّ معقّدٍ للصّورة (يتكوّن من 7680 بعد).
- مرحلة إسقاط الميّزات: ثمّ يتمّ إسقاط الميّزات البصريّة الغنيّة في مساحةٍ دلاليّةٍ لنموذج اللّغة، ممّا يعني تحويل الصّورة إلى تمثيلٍ يمكن للنّموذج فهمه باستخدام اللّغة.
- مرحلة معالجة النّصوص: عندما يتمّ إدخال النّصّ “ماذا يوجد في هذه الصّورة” يبدأ النّموذج بمعالجته:
- يتمّ تقسيم النّصّ إلى رموزٍ (tokens) وترميزها.
- يقوم النّموذج بتمرير النّصّ عبر طبقات المحوّل (transformers) لتحليل معانيه.
- في الطّبقات الخاصّة بالاهتمام المتبادل (كلّ خمس طبقات)، يقوم النّموذج “بالنّظر” إلى الصّورة لمعرفة المعلومات البصريّة الّتي يمكن أن تساعده في توليد الإجابة.
باختصارٍ، يعمل النّموذج على دمج الصّور والنّصوص بشكلٍ ذكيٍّ؛ لتوليد إجابةٍ منطقيّةٍ ومدعومةٍ بالصّور بناءً على السّؤال المدخل.
مثالٌ عمليٌّ
لنرَ كيف يعمل ذلك من خلال مثالٍ محدّدٍ. تخيّل معالجة صورةٍ لقطٍّ يجلس على عتبة النّافذة:
- فهم الرّؤية:
- الطّبقات الأولى من المرمَّز المحلّيّ تكتشف التّفاصيل الأساسيّة للصّورة (الحواف والأنسجة والأشكال الأساسيّة).
- الطّبقات المتوسّطة تحدّد مميّزات القطّة وإطار النّافذة وأنماط الضّوء.
- الطّبقات اللاّحقة تفهم العلاقة المكانيّة بين القطّة وعتبة النّافذة.
- المرمَّز الموسّع يدمج هذه الميّزات لفهم مشهدٍ متكاملٍ.
- دمج الميّزات:
- الميّزات المُسقطة تحافظ على معلوماتٍ حول:
- مظهر القطّة ووضعها.
- هيكل النّافذة وإضاءتها.
- التّخطيط المكانيّ للمشهد.
- المفاهيم المجرّدة، مثل: “الاسترخاء” أو “المراقبة”.
- الميّزات المُسقطة تحافظ على معلوماتٍ حول:
- توليد النصوص: عندما يولّد النّموذج الوصف، يمكنه:
- الوصول إلى التّفاصيل البصريّة منخفضة المستوى عند وصف الميّزات المحدّدة.
- استخدام الفهم عالي المستوى لتفسير المشهد العام.
- الحفاظ على التّناسق من خلال الرّبط البصريّ المنتظم.
- توليد أوصافٍ تناسب السّياق من خلال الانتباه الانتقائيّ إلى الميّزات البصريّة ذات الصّلة.
الخاتمة
بعد التّعمّق في بنية اللاما متعدد النماذج MLLaMA، يمكننا رؤية كيف يشكّل نهج ميتا في الذّكاء الإصطناعيّ متعدّد الأنماط تطوّراً ملموساً في تصميم نماذج الرّؤية_اللّغة.
تقدّم الرّؤى الرّئيسية من تصميم اللاما متعدد النماذج MLLaMA عدّة دروسٍ مهمّةٍ حول تصميم الهندسة المعماريّة متعدّدة الأنماط.
أوّلاً، يُظهر الحفاظ على الميّزات البصريّة متعدّدة المستويات أنّ الاحتفاظ بالوصول إلى مستويات فهمٍ مختلفةٍ أمرٌ بالغ الأهمّيّة للتّفكير البصريّ القويّ؛ لأنّ قدرة النّموذج على الرّجوع إلى كلٍّ من التّفاصيل منخفضة المستوى والمفاهيم عالية المستوى تسمح له بتوليد أوصافٍ أكثر دقّة من تلك الّتي تعتمد فقط على ميّزات الطّبقات النّهائيّة.
ثانياً، تُظهر استراتيجيّة الدّمج في اللاما متعدد النماذج MLLaMA أهمّية تدفق المعلومات المُتحكّم فيه والاستراتيجيّ. بدلاً من محاولة دمج المعلومات البصريّة واللّغويّة دفعةً واحدةً أو الانتظار حتّى المراحل النّهائيّة، تسمح نقاط الاهتمام المتبادل المنتظمة مع البوابات القابلة للتّعلم النّموذج بتطوير أنماطٍ معقّدةٍ من التّفكير متعدّد الأنماط.
بالنّسبة للممارسين الّذين يعملون على أنظمة الذّكاء الإصطناعيّ متعدّدة الأنماط، يقدّم تصميم اللاما متعدد النماذج LLaMA عدّة رؤى عمليّة بخلاف تصميمات النّماذج الّتي تدمج المعلومات مبكراً.
فهو يعمل بشكلٍ جيّدٍ ويكشف عن إمكانيّة دمجٍ متعدّد المستويات بين المركز البصريّ ونموذج اللّغة. علاوةً على ذلك، يمكننا تجميد نموذج اللّغة بالكامل أثناء التّدريب.
مع الاستمرار في دفع حدود الذّكاء الإصطناعيّ متعدّد الأنماط، يتطلّب الأمر المزيد من الجهود المفتوحة المصدر للمشاركة مع المجتمع. لا يكفي مجرّد إصدار النّموذج والكود، بل يجب أيضاً مشاركة التّفاصيل المعماريّة، والمبادئ التّصميميّة، وتفاصيل التّدريب، واستخدامات البيانات.
هذا هو المفتاح لتضمين المزيد من الأشخاص في البحث وإلهامهم.