
المحتويات
- المقدمة Introduction
- الانحدار الخطيّ Linear Regression
- الانحدار اللوجيستيّ Logistic Regression
- خوارزميّة الجار الأقرب k-Nearest Neighbors
- خوارزميّة المصنّف البايزي السّاذج Naive Bayes classifier
- خوارزميّة آلة المتّجهات الدّاعمة Support Vector Machine
- شجرة القرار Decision Tree
- الغابات العشوائيّة Random Forest
- خوارزميّات التّعزيز Boosting:
- الخاتمة
- المراجع
المقدمة Introduction
لقد كان لتعلّم الآلة نصيب كبير من الاهتمام في السنوات الأخيرة، ولذلك دائماً تظهر العديد من الخوارزميّات التي تتراوح من البسيط إلى المعقّد في نهجها.
خوارزميّات تعلّم الآلة ماهي إلا برامج يمكنها التّعلم والتّحسين من التّجربة دون تدخلّات بشريّة.
سنقوم بشرح بعض الخوارزميّات التي يجب أن تعرفها في عام 2021، ولكن بعض الخوارزميّات سيكون شرحها أكثر من غيرها لمجرّد أنّ هذه المقالة ستكون بطول كتاب إذا شرحنا بدقّة كلّ خوارزميّة، لذا فسيتمّ التّركيز على الخوارزميّات التي نالت درجة تطوّر أكبر.
الانحدار الخطيّ Linear Regression
يعتبر من أبسط خوارزميّات تعلّم الآلة (Machine Learning) ضمن فئة التعلّم تحت الإشراف (Supervised Learning) الذي يقوم بنمذجة مفهوم الانحدار.
تستخدم في تفسير متغيّر Y عبر متغيّر آخر X (أو مجموعة من المتغييّرات x1,x2,…xp) وفق دالّة خطيّة.
يسمى المتغيّر Y بالتّابع.
وتسمى المتغيّرات X بالمتغيّرات المستقلّة أو المفسّرة بمعنى أنّها تفسّر تغيّرات المتغيّر التّابع Y.

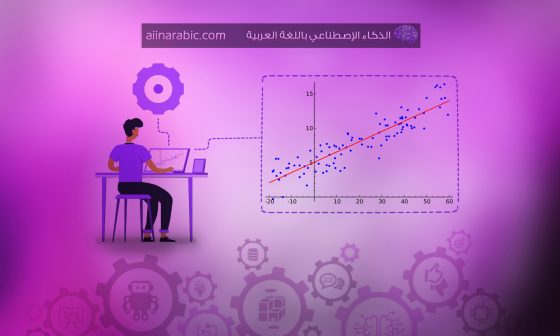
في الشكل أعلاه يوضّح علاقة خطيّة بسيطة بين متغيّرين، حيث المتغيّر(X) يمثّل عدد سنوات الخبرة، والمتغيّر (Y) يمثّل مقدار راتب الشّخص .
النّقاط الخضراء تمثّل البيانات التي لدينا، والخطّ الأحمر يمثّل الانحدار الخطيّ الذي سيقوم بالتنبّؤ لمقدار راتب الشّخص حسب سنوات خبرته؛ أي نتيجة التنبّؤ تكون قيماً مستمرّة Continuous Values.
الانحدار اللوجيستيّ Logistic Regression
هي إحدى خوارزميّات تعلّم الآلة وأحد أشهر خوارزميّات التّصنيف (Classification) وذلك لأنّ خطواتها بسيطة.
تستخدم لتصنيف البيانات إلى فئات (Classes) منفصلة،
مثلاً
لو كانت لدينا بيانات طالب وهذه البيانات هي عدد ساعات القراءة ودرجات الامتحان، فيمكننا عن طريق هذه الخوارزميّة التنبّؤ هل الطالب سينجح أم سيفشل في الامتحان اعتماداً على عدد السّاعات التي قضاها في الدّراسة،
أي النّتيجة ستكون Pass/Fail وتسمّى هذه القيم بالقيم المنفصلة Discrete Values.
خوارزميّة الجار الأقرب k-Nearest Neighbors
تعتبر خوارزميّة الجار الأقرب من خوارزميّات تعلّم الآلة ضمن مجموعة التعلّم تحت إشراف، والتي تعدّ “من أبسط الخوارزميّات نظراً لسهولة استخدامها واستهلاكها للقليل من الوقت”.
تستخدم خوارزميّة الجار الأقرب KNN مجموعة البيانات بأكملها كمجموعة تدريب بدلاً من تقسيم مجموعة البيانات إلى مجموعة تدريب واختبار، لأنّ خوارزميّة الجار الأقرب تعمل على فصل بيانات مصنّفة مسبقاً.
عندما تكون النّتيجة المطلوبة لعنصر بيانات جديد، تنتقل خوارزميّة الجار الأقرب KNN عبر مجموعة البيانات بأكملها للعثور على أقرب مثيلات k إلى العنصر الجديد،
قيمة k يحدّدها المستخدم.
يتمّ حساب التّشابه بين الحالات باستخدام مقاييس مثل مقياس المسافة الإقليديّة ومسافة هامينج.

خوارزميّة المصنّف البايزي السّاذج Naive Bayes classifier
هي طريقة تصنيف تعتمد على نظريّة بايز، تبدو Naive Bayes خوارزميّة شاقّة لأنّها تتطلّب معرفة رياضيّة أوليّة في الاحتمال الشرطيّ و نظريّة بايز لكنّها كمفهوم سهلة للغاية.
كمثال عليها بفرض لدينا المتغيّر X الذي يعبّر عن شخص سيلعب كرة قدم بناءً على حالة الطّقس، لدينا حالات الطّقس وأمام كلّ حالة المتغيّر الهدف الذي سيأخذ نعم سيلعب أو لا.
هناك ثلاث خطوات لتجهيز الخوارزميّة للتنبّؤ فيما إذا كان X سيلعب أو لا.
جمع البيانات —< حساب جدول التكرار —< حساب جدول الاحتمالات

بعد ذلك نستخدم معادلة Naive Bayesian لحساب احتمال حدوث كلّ فئة(Class)، في مثالنا هناك فئتان(Yes/No) والاحتمال الأعلى هو نتيجة التنبّؤ.

لنختبر الفرضيّة التالية(Hypothesis): سيلعب X إذا كان الطقس مشمساً، هل هذه الفرضيّة صحيحة؟ نحتاج إلى حساب حدوث نعم(Class) مع خاصيّة مشمس(Feature).

بالرّجوع إلى جدول الاحتمالات نجد أنّ
P (sunny | yes) =0.33
P (yes) =0.64
P (sunny) =0.36
ونتيجة المعادلة 0.59 لذا فإنّ الفرضييّة صحيحة.

خوارزميّة آلة المتّجهات الدّاعمة Support Vector Machine
إحدى خوارزميّات التعلّم تحت إشراف (Supervised Learning) التي يمكن استخدامها في مسائل التّصنيف(Classification) والانحدار(Regression)، وعادة تستخدم في مسائل التّصنيف لفعاليتها وحصولها على دقّة ممتازة في أغلب البيانات المستخدمة.
خوارزميّة آلة المتّجهات الدّاعمة SVM مبنيّة على فكرة إيجاد مستوٍ فائق (hyperplane) يقوم بتقسيم مجموعة البيانات إلى صنفين بأفضل طريقة كما هو موضّح في الشكل أدناه.

شجرة القرار Decision Tree
شجرة القرار هي شجرة ثنائيّة (binary tree) وهذا يعني أنّ لكلّ أب ولدين على الأكثر.
كلّ عقدة(node) في الشّجرة تمثّل متغيّراً(variable) بينما أوراق الشجرة (leaf nodes) تمثل النّتيجة(output) التي تستخدم للتنبّؤ.

الغابات العشوائيّة Random Forest
هي عبارة عن تحسين على أشجار القرار (Decision Tree) تسمى بالغابة العشوائيّة، وكما يوحي اسمها فهي تتكوّن من عدد كبير من أشجار القرار الفرديّة التي تعمل كمجموعة للحصول على تنبّؤات أكثر دقّة واستقراراً.
من نتائج تنبّؤ هذه المجموعة يتمّ الحصول على أعلى نتيجة تصويت بالتّصويت، وهي أفضل من نتيجة استخدام أفضل نموذج بمفرده.

خوارزميّات التّعزيز Boosting:
على عكس العديد من نماذج تعلّم الآلة ML التي تركّز على نموذج واحد لإكمال التنبّؤات عالية الجودة، تحاول خوارزميّة التّعزيز تحسين قدرات التنبّؤ من خلال تدريب سلسلة من النّماذج الضّعيفة، يمكن لكلّ منها تعويض نقاط ضعف سابقاتها.

التّعزيز التكيفيّ AdaBoost)Adaptive Boosting)
تعتبر أحد أنواع التّعزيز Boosting وهي خوارزميّة تعلّم آلة ويمكن استخدامها مع العديد من الأنواع الأخرى من خوارزميّات التعلّم لتحسين الأداء.
حيث في كلّ تكرار سيحدّد التّعزيز التكيفيّ AdaBoost نقطة البيانات Stumps التي تمّ تصنيفها بشكل خاطئ، وبالتالي زيادة وزنها (بمعنًى آخر تقليل وزن النّقطة الصّحيحة) بحيث يكون المصنّف التّالي أكثر انتباهاً لتصحيحها.

التّعزيز الاشتقاقيّ Gradient Boost
أحد خوارزميّات التّعزيز Boosting شيوعاً، تعمل هذه الخوارزميّة من خلال إضافة نماذج التنبّؤ بشكل متتابع، وكلّ نموذج يصحّح النموذج السّابق ولكن بدلاً من ضبط أوزان الأمثلة في كلّ خطوة كما يجري في التّعزيز التكيفيّ AdaBoost، فهذه الطّريقة تحاول أن تقوم بملاءمة نموذج التنبّؤ الجديد مع الأخطاء المتبقية من النّموذج الذي سبقه (بمعنًى آخر لا يركز تعزيز التدرّج على ضبط وزن نقاط البيانات، ولكنه يركّز على الفرق بين التنبّؤ والحقيقة الأساسيّة).

ففي التّعزيز الاشتقاقيّ(Gradient Boost(GB يتمّ تحديد نقاط الضّعف من خلال التدرّجات، وفي التّعزيز التكيفيّ AdaBoost يتمّ تحديد نقاط الضّعف من خلال البيانات عالية الوزن.
تعزيز التدرّج الشّديد XGBoost)eXtreme Gradient Boosting)
هي واحدة من خوارزميّات التّعزيز الشائعة بشكل كبير والمستخدمة على نطاق واسع لأنّها ببساطة قوية جداً، وتعتبر مشابهة لخوارزميّة التّعزيز الاشتقاقيّ Gradient Boost لكنّها تحتوي على بعض الميزات الإضافيّة التي تجعلها أقوى بكثير؛ حيث التّدريب سريع جداً ويمكن موازنته أو توزيعه عبر المجموعات.

وعلى سيبل المثال لتكن لدينا مسألة تصنيف لشخص فيما إذا كان يحب ألعاب الكمبيوتر.

تعزيز التدرّج الخفيف LightGBM
هو نوع آخر من خوارزميّات التّعزيز التي أظهرت أنّها أسرع وأحياناً أكثر دقّة من خوارزميّة تعزيز التدرّج الشديد XGBoost.
ما يجعل LightGBMمختلفاً هو أنّه يستخدم تقنيّة فريدة تسمى أخذ العيّنات من جانب واحد(GOOS) القائم على التدرّج.
يمكن أن يؤدّي استخدام أخذ العيّنات من جانب واحد GOOS إلى تقليل عدد كبير من مثيلات البيانات بتدرّجات صغيرة فقط ،وتحتفظ بجميع الحالات ذات التدرّجات الكبيرة وهذا يوفّر الكثير من الوقت والذّاكرة.

التعزيز الفئويّ CatBoost
هي أيضاً نوع من خوارزميّة عائلة التّعزيز Boosting، وتعرف هذه الخوارزميّة بأنها تؤدّي بشكل أفضل من خوارزميّات تعزيز التدرّج الشديد XGBoost و خوارزميّة التدرّج الخفيف LightGBMمن حيث دقّة الخوارزميّة.
حيث يتمّ تضمين خوارزميّات مبتكرة تعالج الميّزات الفئويّة تلقائيّاً في ميّزات رقميّة ثمّ تستخدم هذه الميّزات المدمجة للاستفادة من الاتّصالات بين الميّزات، فهذا يثري إلى حد كبير بُعد الميّزة.
ثمّ يتمّ استخدام طريقة تعزيز التّرتيب لتجنّب نقاط الضّجيج في مجموعة التّدريب، الانحراف في تقدير التدرّج، ومن ثمّ حل مشكلة إزاحة التنبّؤ.

الخاتمة
في الخلاصة لقد قمنا في هذه المقالة بتغطية بعض أهمّ خوارزميّات تعلم الآلة التي يجب علينا معرفتها.
كن متفائلاً حتى إذا واجهت صعوبة في فهم بعض الخوارزميّات المذكورة، فسيكون لكل خوارزمية مقالة توضحها بالتفصيل.




6 تعليقات
هل ممكن كتاب بالعربية لهذه الدروس
السلام عليكم ممكن كتاب يشرح هذه الدروس في ملف pdf