إعداد: م. نادية عبد الجواد
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. رامي عقّاد
المَحتويَات
1. المقدّمة
تتميّز نماذج اللّغات القويّة متعدّدة الأغراض بتنوّعها الهائل، ولكن في أنظمة الإنتاج عالية الحجم سرعان ما يصبح زمن الوصول والتّكلفة عاملين مقيّدين.
يتطلّب تدريب النّماذج اللّغويّة الكبيرة LLMs أجهزةً باهظة الثّمن، حيث تتطلّب ذاكرةً ضخمةً بالإضافة إلى عددٍ كبيرٍ من وحدات معالجة الرّسومات القويّة GPUs. كما وأنّها تحتاج لتقنيّات تدريبٍ متطوّرة، مثل: التّدريب الموازي كتقسيم البيانات بشكلٍ كاملٍ. يتمّ تدريب مثل هذه النّماذج على مرحلتين: الأولى وهي مرحلة ما قبل التّدريب Pretraining والّتي تعرف بأنّها المرحلة الأكثر تكلفة، وأمّا المرحلة الثّانية فهي مرحلة الضّبط الدّقيق Finetuning وتعتبر أقلّ تكلفة نسبيًّا. حاليًّا، يتمّ التّركيز من قبل مستخدمي الذّكاء الإصطناعيّ على تحميل النّماذج المدرّبة مسبقًا والتّركيز فقط على عمليّة الضّبط الدّقيق أي تعديل النّموذج وفقًا لمهمّةٍ محدّدةٍ ما. [1]
على سبيل المثال في أطر العمل متعدّدة الوكلاء Multi-Agent Frameworks قد يكون من المنطقي استخدام نموذجٍ كبيرٍ، مثل: جيميني لتنسيق وتنظيم العمل، لكن الوكلاء الفرديّين أنفسهم يمكن (ويُفضَّل) أن يكونوا نماذج أصغر ومتخصّصة تمّ تدريبها بشكلٍ دقيقٍ؛ لأداء مهام محدّدة. هذا التّصميم لا يُحسّن فقط سرعة الاستجابة، بل أيضًا يُقلّل من تكاليف الحوسبة ويُبسّط عمليّة التّوسّع. ومن هنا نستنتج أهمّيّة مصطلح الضّبط الدّقيق للمعاملات بكفاءةٍ Parameter-Efficient Fine-Tuning.
2. الضّبط الدّقيق في النّماذج اللّغويّة الكبيرة
إنّ الضّبط الدّقيق في النّماذج اللّغويّة الكبيرة LLMs مهمٌّ عندما تكون هناك حاجةٌ لتكييف نموذجٍ مدرّبٍ مسبقًا؛ لأداء مهمّةٍ محدّدةٍ أو حالة استخدامٍ معيّنةٍ. ومن خلال استخدام تقنيّات الضّبط الدّقيق، يمكن أن يُظهر النّموذج أداءً أفضل في مهمّةٍ أو مجالٍ معيّنٍ.
يتطلّب ضبط النّموذج بدقّةٍ كمّيةً كبيرةً من بيانات التّدريب، الذّاكرة، الجهد، والوقت. ومن أحد العيوب الرّئيسيّة في هذه العمليّة أنّ النّموذج النّاتج يحتوي على عددٍ كبيرٍ من المعاملات parameters يوازي تقريبًا عدد معاملات النّموذج الأصليّ، حيثأنّ ضبط النّماذج الكبيرة من البداية إلى النّهاية ليس بالأمر السّهل.
والسّؤال هنا: هل من الممكن أن يتمّ ضبط النّماذج الكبيرة بطريقةٍ أكثر كفاءة في الحوسبة والبيانات، وتقليل استهلاك الذّاكرة مع المحافظة على أداء الضّبط الشّامل الدّقيق؟
الحل:[2] نحن بحاجةٍ إلى نهجٍ مرنٍ يتجنّب تعديل جميع المعاملات، ممّا يُتيح استخدام موارد بنيةٍ تحتيّةٍ أقل وبياناتٍ أقل أيضًا. وهذا ما يسمّى بالضّبط الدّقيق بكفاءةٍ للمعاملات PEFT=Parameter-Efficient Fine-Tuning.
بمعنى آخر، يتمّ تعديل جزءٍ صغيرٍ من معاملات النّموذج أو إضافة معاملاتٍ أثناء عمليّة الضّبط الدّقيق، حيث يحتوي كلّ نموذجٍ مضبوطٍ بدقّةٍ على عددٍ صغيرٍ من المعاملات الخاصّة بمهمّةٍ محدّدةٍ والّتي تخزّن أو تُحمّل، ممّا يؤدّي إلى تخفيف الحمل على الذّاكرة وعمليّات الحوسبة وتبسيط عمليّة التّطوير. [1]
من أجل تحقيق ضبط المعاملات بكفاءةٍ، يتمّ استخدام تقنيّتين رئيسيّتين لذلك هما: طبقات المحوّل الإضافيّة Adapter Layers والضّبط المسبق Prefix Tuning.
3. طبقات المحوّل الإضافيّة
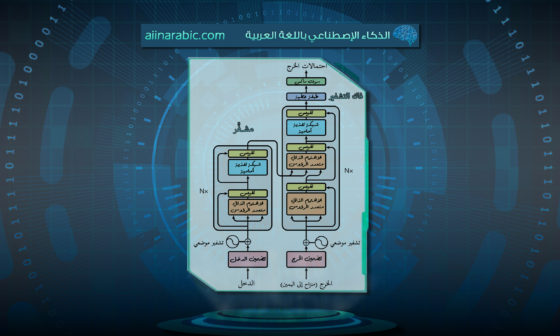
هي طريقةٌ تقوم بإضافة طبقتين للنّموذج المدرّب مسبقًا _كما هو موضّحٌ بالشّكل (1)_ وهما طبقتان من المعدّل تُضاف إلى بنية المحوّل transformer. أوزان هاتين الطّبقتين سوف يتمّ تعديلها وفقًا للمهمّة المحدّدة مع عدم إجراء أيّ تعديلٍ في الأوزان الأصليّة، وبالتّالي كلّ نسخةٍ يتمّ ضبطها بدقّةٍ Finetuned من النّموذج سوف تحتوي فقط على عددٍ محدودٍ من المعاملات المرتبطة بالمهمّة المحدّدة، ممّا يجعلها أكثر كفاءة من حيث الحجم والتّخزين. [3]
إنّ كلّ كتلة محوّلٍ Adapter هي وحدةٌ من نوع التّغذية الأماميّة Feedforward ذات نمط عنق الزّجاجة، وتعمل وفق ما يلي:[1]
- تقوم بتقليل الأبعاد Dimensionality لمدخل البيانات عبر طبقةٍ خطّيّةٍ قابلةٍ للتّدريب.
- ثمّ تطبّق دالّةً غير خطّيّةٍ Non-Linearity.
- وأخيرًا تُعيد الأبعاد الأصليّة للمدخل عبر طبقةٍ خطّيّةٍ نهائيّةٍ قابلةٍ للتّدريب أيضًا.
4. الضّبط المسبق
يُعدّ الضّبط المسبق خيارًا آخر من أساليب الضّبط الدّقيق الفعّال للمعاملات PEFT، حيث يتمّ تجميد جميع معاملات نموذج اللّغة الأساسيّ، ويُعاد ضبط عددٍ قليلٍ فقط من متّجهات الوحدة اللَفظيَة القابلة للتدّريب token vectors، والّتي يتمّ إضافتها إلى بداية تسلسل الإدخال الخاصّ بالنّموذج كما هو موضّحٌ بالشّكل (2). يمكن استبدال هذه المتّجهات وفقًا للمهمّة المطلوبة، ممّا يجعلها قابلةً لإعادة الاستخدام في مهام مختلفة بطريقةٍ مرنةٍ وفعّالةٍ. [1]
يوضح الشكل (2) كيف يتطلب الضبط الدقيق Fine-tuning تدريب نموذج منفصل لكل مهمة (مثل الترجمة، التلخيص وتحويل الجدول إلى نص)، بينما في الضبط المسبق Prefix-tuning نحتفظ بنموذج واحد مسبق التدريب مع بادئات مخصصة لكل مهمة.
إنّ كلًّا من الضّبط المسبق وطبقات المحوّل الإضافيّة يساهم في تقليل متطلّبات الحوسبة، استهلاك الذّاكرة، وعدد المعاملات القابلة للتّدريب المرتبطة بعمليّة الضّبط الدّقيق للنّماذج اللّغويّة الكبيرة.
ورغم أنّ هذه الأساليب تُعتبر بدائل فعّالةً من حيث عدد المعاملات وأداءٍ جيّدٍ مقارنةً بالضّبط الكامل للنّموذج، إلّا أنّها لا تخلو من بعض القيود: [1]
- طبقات المحوّل Adapters تُضيف طبقاتٍ جديدةٍ إلى النّموذج الأساسيّ. ورغم أنّ هذه الطّبقات تحتوي على عددٍ قليلٍ من المعاملات، إلّا أنّها تتطلّب معالجةً تسلسليّةً أثناء التّمرير الأماميّ، ممّا يؤدّي إلى زيادةٍ في زمن الاستجابة وبطءٍ في التّدريب.
- أمّا الضّبط المسبق Prefix Tuning، ففي كثيرٍ من الأحيان يكون من الصّعب تحسينه، أي أنّ عمليّة الضّبط تكون أقلّ استقرارًا من غيرها. كما أنّ تقليل حجم نافذة السّياق المتاحة للنّموذج لفهم المدخلات قد يؤثّر على الجودة والتّنبؤ، بالإضافة إلى أنّه لا يقدّم دائمًا أداءً أفضل عند زيادة عدد المعاملات القابلة للتّدريب.
إنّ التّكيّف منخفض الرّتبة Low-Rank Adaptation يسعى لمعالجة هذه التّحدّيات مع الحفاظ على أداءٍ مماثلٍ تقريبًا للضّبط الكامل للنّموذج.
نستنتج أنّنا نحتاج إلى نهجٍ متكاملٍ للضّبط الدّقيق للنّماذج اللّغويّة الكبيرة لا يقتصر فقط على كفاءة المعاملات وإنّما على:[1]
- كفاءة الحوسبة: أي أنّ عمليّة التّدريب تتمّ بسرعةٍ وبدون تكلفةٍ.
- كفاءة الذّاكرة: أي لا نحتاج إلى وحدات معالجة رسوماتٍ GPUs ضخمةٍ من أجل ضبط نموذجٍ لغويٍّ كبيرٍ LLM.
- سهل النّشر: أي لا نحتاج إلى تنفيذ ونشر عدّة نسخٍ من نموذجٍ لغويٍّ كبيرٍ ما من أجل مهمّةٍ محدّدةٍ.
مع طريقة التّكيّف منخفض الرّتبة LoRA والتّكيّف الكمّيّ منخفض الرّتبة QLoRA للضّبط الدّقيق للنّماذج اللّغويّة الكبيرة، نستطيع تحقيق كلّ ما سبق والتّبديل بسهولةٍ بين الإصدارات المختلفة للنّموذج دون زيادةٍ في زمن الاستجابة أثناء الاستدلال inference latency.
لنتعرّف أكثر على هاتين الطّريقتين وطرق عملهما.
5. التّكيّف منخفض الرّتبة
يتمّ تدريب عددٍ صغيرٍ من المعاملات فقط بدلًا من تدريب جميع معاملات النّموذج. وتُعرف هذه المجموعة الصّغيرة من المعاملات باسم مصفوفات التّكيّف منخفضة الرّتبة Low-Rank Adaptation Matrices، وهو ما اشتُقّ منه اسم تقنيّة لورا LoRA.
وسبب تسميتها بـ “منخفضة الرّتبة“ يعود إلى أنّ هذه المصفوفات تحتوي على عددٍ قليلٍ من المعاملات مقارنةً بالمصفوفات الأصليّة، ويتمّ دمجها مع نتائج معاملات النّموذج الأصليّ أثناء عمليّة التّدريب.
تُتيح لنا تقنيّة لورا LoRA تدريب بعض الطّبقات الكثيفة Dense Layers في الشّبكة العصبونيّة بشكلٍ غير مباشرٍ من خلال تحسين مصفوفات تفكيك الرّتبة Rank Decomposition Matrices الّتي تمثّل التّغيّرات الّتي تطرأ على هذه الطّبقات أثناء التّكيّف، مع إبقاء الأوزان المدرّبة مسبقًا مجمّدة دون أيّ تعديلٍ. نستطيع من خلال استبدال قيم المصفوفات منخفضة الرّتبة الإنتقال من مهمّةٍ إلى أخرى بكفاءةٍ مع المحافظة على النّموذج المشترك المدرّب مسبقًا، وأيضًا نلاحظ انخفاضًا في متطلّبات التّخزين مع إمكانيّة التّبديل بين المهام بفعّاليّةٍ وكفاءةٍ. تُقلّل تقنيّة لورا LoRA حاجز الدّخول Barrier Entry بما يصل إلى 3 مراتٍ عند استخدام خوارزميّات التّحسين التّكيّفيّة Adaptive Optimizers؛ لأنّه لم يعد هناك من حاجةٍ لحساب التّدرّجات Gradients أو الاحتفاظ بحالات المحسّن Optimizer States لمعظم المعاملات. وبدلًا من ذلك، نقوم فقط بتحسين المصفوفات منخفضة الرّتبة الصّغيرة الّتي تمّت إضافتها. يُتيح لنا التّصميم الخطّيّ البسيط دمج المصفوفات القابلة للتّدريب مع الأوزان المجمّدة عند النشر، ممّا يعني أنّه لا يتمّ إدخال أيّ تأخيرٍ إضافيٍّ أثناء الاستدلال مقارنةً بنموذجٍ مضبوطٍ بالكامل. [4]
والسّؤال هنا؟ لماذا يُظهر النّموذج أداءً جيّدًا رغم تخصيص عددٍ قليلٍ جدًّا من المعاملات لعمليّة الضّبط الدّقيق؟
ألن نستفيد أكثر لو قمنا بتدريب عددٍ أكبر من المعاملات؟
ممّا يُظهر أنّ النّماذج الكبيرة تميل إلى أن تكون ذات بُعدٍ جوهريٍّ منخفضٍ Low Intrinsic Dimension.
ورغم أنّ هذه الفكرة قد تبدو معقّدةً، إلاّ أنّها ببساطةٍ تعني أنَ مصفوفات الأوزان في هذه النّماذج الضّخمة غالبًا ما تكون منخفضة الرّتبة. وتستطيع النّماذج اللّغويّة الكبيرة التّعلّم بكفاءةٍ على الرّغم من الإسقاط العشوائيّ إلى حيّزٍ فرعيٍّ أصغر. [4]
بمعنى آخر: ليست كلّ هذه المعاملات ضروريّةً بشكلٍ فعليٍّ، حيث يمكننا تحقيق أداءٍ مماثلٍ من خلال تفكيك مصفوفات الأوزان إلى تمثيلٍ يحتوي على عددٍ أقلّ بكثيرٍ من المعاملات القابلة للتّدريب.
وبالتّالي، فإنّ التّقنيّات مثل LoRA _الّتي تُقارب تحديث الضّبط الدّقيق من خلال تفكيكٍ منخفض الرّتبة Low Rank Decomposition_ قادرةٌ على التّعلُّم بكفاءةٍ وفعّاليّةٍ، ممّا يُنتج نموذجًا ذي أداءٍ مميّزٍ رغم احتوائه على عددٍ قليلٍ من المعاملات القابلة للتّدريب.
1.5. مصفوفة تفكيك الرّتبة
أيضًا تُدعى بمصفوفة التّكيّف منخفض الرّتبة؛ للمحافظة على أداء جودة النّموذج. المصفوفتان هما مجرّد إسقاطين خطّيّين Linear Projections، حيث يتمّ تقليل أبعاد المدخلات وبعدها استعادة الأبعاد الأصليّة. ويتمّ بعد ذلك جمع ناتج هذين الإسقاطين مع ناتج النّموذج المستمدّ من الأوزان المدرّبة مسبقًا. [1]
فبدلًا من ضبط معاملات طبقات النّموذج المدرّب مسبقًا LLM بشكلٍ مباشرٍ، تقوم تقنيّة لورا LoRA فقط بـتحسين (تدريب) مصفوفات تفكيك الرّتبة، ممّا يُنتج نتيجةً تُقارب تحديث الضّبط الكامل للنّموذج.
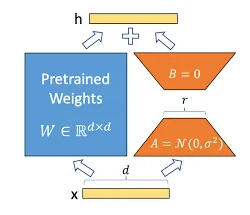
يمكننا صياغة تحديث المعاملات النّاتج عن عمليّة الضّبط الدّقيق كما هو موضّحٌ في المعادلة أدناه:

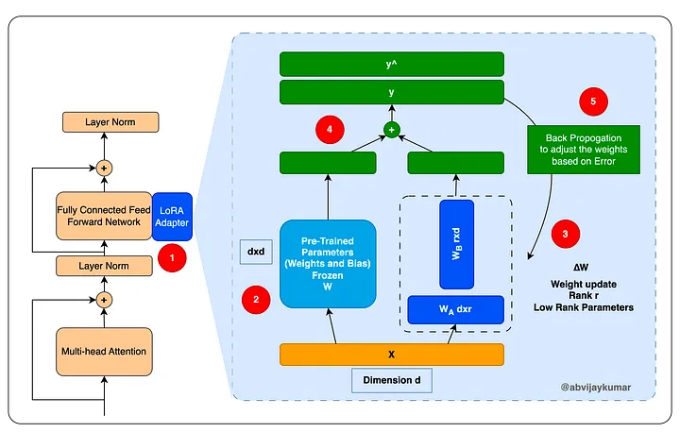
تكمن الفكرة الأساسيّة لـ لورا LoRA في دمج مجموعةٍ إضافيّةٍ من تعديلات الأوزان إلى قيم الأوزان الموجودة. يتمّ تهيئة المصفوفة A بقيمٍ صغيرةٍ وعشوائيّةٍ، بينما تُهيَّأ المصفوفة B بقيمٍ تساوي الصّفر؛ وذلك لضمان أن تبدأ عمليّة الضّبط الدّقيق من نفس أوزان النّموذج الأصليّة المدرّبة مسبقًا. كما هو موضّحٌ بالشّكل (4): [3]
يتمّ تشكيل الطّبقة المُحدّثة من خلال جمع هذين التحويلين المتوازيين كما هو موضّحٌ أدناه. وكما نرى، فإنّ إضافة لورا إلى الطّبقة يتيح تعلّم التّحديث مباشرةً لأوزان الطّبقة الأساسيّة.[1]

حيث لدينا: r الرّتبة (r ≪ min (d, k ،عادةً تكون قيمها بين 1-64؛ للحفاظ على قيم المعاملات القابلة للتّدريب صغيرًا.
2.5. معامل التّوسّع
[4] يساعد في إنقاص الحاجة الى إعادة ضبط المعاملات الأساسية hyperparameters عندما يتمّ تغيير قيم r. أيضًا يتمّ تجنّب القيم الكبيرة جدًّا أو الصغيرة جدًّا والّتي قد تؤثّر على استقرار التّدريب وتحسين سرعة وكفاءة التّدريب، خصوصًا عند استخدام محسّناتٍ مثل خُوارِزْميَّةُ توقُّعِ المُلاءمةِ اللَّحظِيَّةِ (آدم).
بمجرّد اشتقاق التّحديث منخفض الرّتبة لمصفوفة الأوزان، نقوم بالتّوسيع بواسطة عامل قياس (α) قبل إضافته إلى أوزان النّموذج المدرّبة مسبقًا كما هو موضّحٌ أدناه. يمكن تغيير قيمة α لتحقيق التّوازن بين أهمّيّة أوزان النّموذج المدرّب مسبقًا والتّكيّف الجديد الخاصّ بالمهمّة المحدّدة.[1]
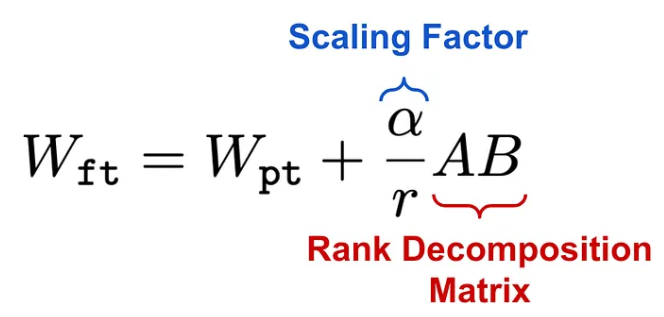
3.5. تطبيق الضّبط الدّقيق باستخدام التّكيّف منخفض الرّتبة على شبكةٍ عصبونيّةٍ
في الشّكل (3)، يتمّ تطبيق مُعدّل لورا LoRA على شبكة التّغذية الأماميّة (المشار إليها بالرّقم 1). يتمّ تجميد معاملات الشّبكة الأصليّة المدرّبة مسبقًا (الأوزان والانحياز) والممثّلة بالمصفوفة W ذات الأبعاد d × d (المشار إليها بالرّقم 2). يُطبَّق مُعدّل لورا باستخدام مصفوفاتٍ منخفضة الرّتبة، والّتي تتمثّل في المصفوفتين WA وWB بأبعادٍ جديدةٍ (المشار إليها بالرّقم 3). يتمّ توضيح كيفيّة إجراء الضّرب النّقطيّ Dot Product بين مخرجات مُعدّل لورا LoRA ومخرجات المعاملات المجمّدة من النّموذج الأصليّ (المشار إليها بالرّقم 4). يتمّ استخدام النّاتج لحساب المخرجات النّهائيّة للنّموذج، بينما يتمّ خلال التّدريب تعديل معاملات محوّل لورا LoRA فقط دون المساس بالمعاملات الأصليّة (المشار إليها بالرّقم 5). حيث أنّ نتائج الضّرب النّقطيّ سوف تكون مصفوفةً ذات الأبعاد dxd.
يُعدّ اختيار القيمة المناسبة لـ r (وهي الرّتبة المنخفضة) أحد العوامل الحاسمة في فعّاليّة تقنيّة لورا LoRA، حيث تُحدّد هذه القيمة حجم مصفوفتَي التّكيّف WA و WB.
خلال مرحلة التّدريب، يتمّ مقارنة مخرجات النّموذج مع القيم المتوقّعة لحساب دالّة الخسارة Loss Function، ويتمّ بعد ذلك تعديل المعاملات ذات الأبعاد الجديدة الخاصّة بمعدّل لورا .
وبعد انتهاء التّدريب، يتمّ دمج الأوزان المدرّبة من لورا مع الأوزان الأصليّة في النّموذج، ممّا يتيح للنّموذج أداء المهام الجديدة بكفاءةٍ دون الحاجة لتعديل جميع المعاملات الأصليّة.
مثالٌ توضيحيٌّ [2]:
لنفترض أنّ معاملات النّموذج الأصليّ W هي مصفوفة بأبعاد 512×512، وقد تمّ تدريبها مسبقًا. أثناء تطبيق تقنيّة لورا يتمّ تجميد هذه المعاملات خلال مرحلة التّدريب؛ أي أنّها لن تتغيّر. وبدلًا من ذلك، تتمّ إضافة مجموعةٍ جديدةٍ من المعاملات إلى النّموذج: وهي المصفوفتان WA وWB تكون أبعادهما كالتّالي:
- WA أبعادها d × r
- WB أبعادها r × d
حيث:
- d: يمثّل بُعد معاملات النّموذج الأصليّة وفي هذا المثال d = 512.
- r: هو البُعد المنخفض (الرّتبة المنخفضة) الّذي يتمّ اختياره كجزءٍ من إعدادات لورا.
لنأخذ مثالًا عمليًّا:
- إذا اخترنا r = 2
- إذًا:
- WA = 512 × 2
- WB = 2 × 512
بالتّالي، فإنّ إجمالي عدد المعاملات في LoRA Adapter = 512 × 2 + 2 × 512 = 2048 معاملٍ فقط وهو أقلّ بكثيرٍ من عدد معاملات المصفوفة الأصليّة W، والّذي يعادل 512 × 512 = 262,144 معاملٍ.
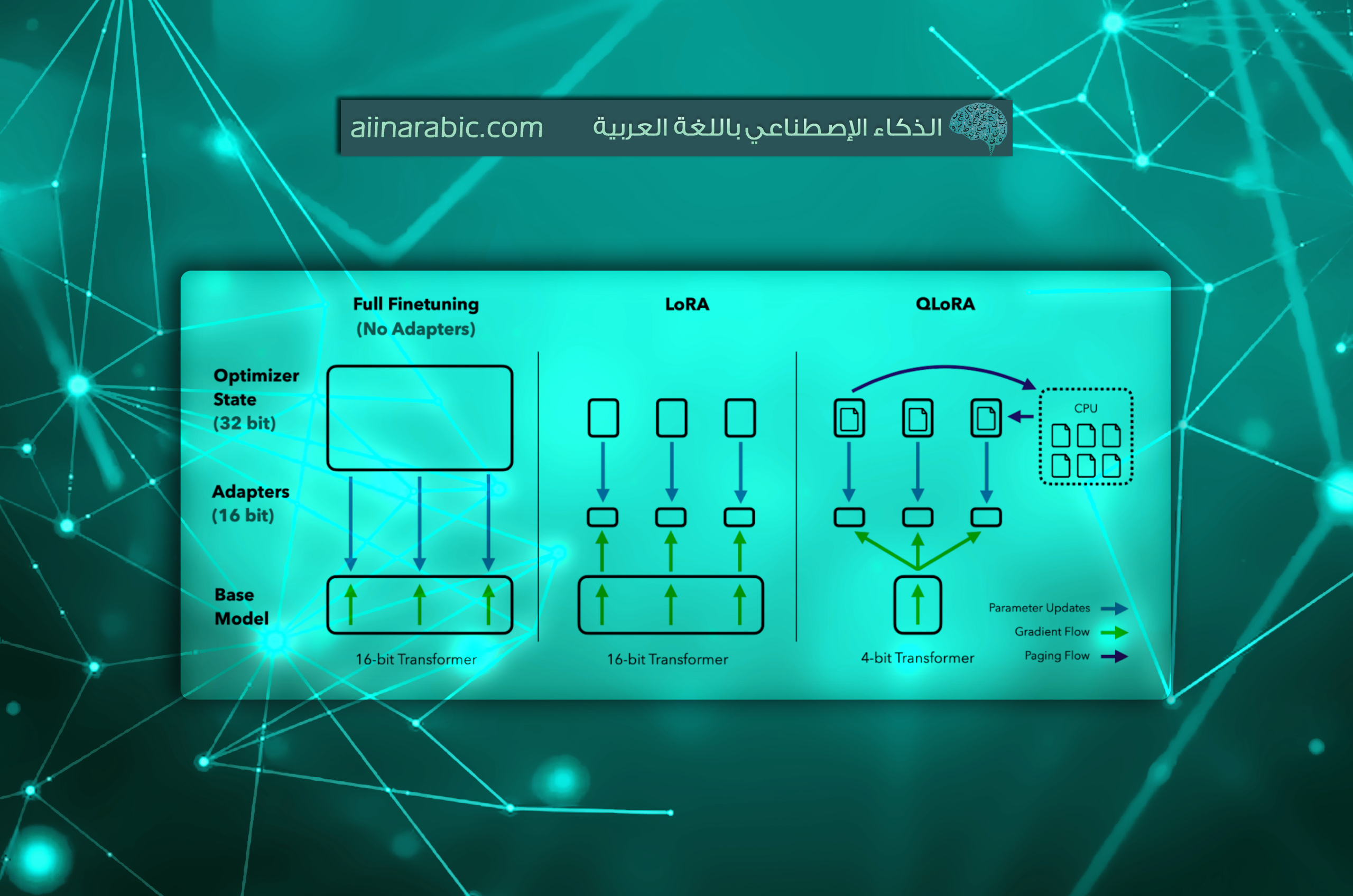
6. التّكيّف الكمّيّ منخفض الرّتبة
تقدّم هذه الطّريقة العديد من الابتكارات المصمّمة من أجل تقليل استهلاك الذّاكرة دون التضحية بالأداء [5]. تعتمد على مبدأ التّكميم Quantization وهو عمليّة تحويل البيانات من تمثيلٍ يحتوي على قدرٍ أكبر من المعلومات إلى تمثيلٍ يحتوي على قدرٍ أقلّ من المعلومات. عادةً ما يعني ذلك تحويل نوع البيانات الّذي يحتوي على عددٍ أكبر من البتات إلى نوع بياناتٍ يحتوي على عددٍ أقلّ من البتات، على سبيل المثال: تحويل القيم من أعداد عشريّة 32-بت أي 32-bit floats إلى أعداد صحيحة 8-بت أي 8-bit Integers.
من أهمّ فوائد التّكيّف الكمّيّ منخفض الرّتبة: تخفيض الذّاكرة بنسبةٍ كبيرةٍ، المحافظة على الأداء، وإمكانيّة التّطبيق على عدّة نماذج لغويّة كبيرة، مثل: روبيرت، ديبيرتا، جي بي تي 2 ، و جي بي تي 3. [6]
هنالك ثلاثة تحسيناتٍ رئيسيّةٍ [2]:
o تكميم نمطٍ عشريٍّ bit NormalFloat Quantization 4-bit-4: هذا النّمط يساهم بشكلٍ كبيرٍ في انخفاض استهلاك الذّاكرة. هذه الطّريقة تتضمّن ثلاث مراحل: مرحلتي التّطبيع Normaliztion والتّكميم Quantization، يتمّ فيها ضبط الأوزان على متوسّطٍ صفريٍّ وتباينٍ واحدٍ ثابتٍ وهذا ما يسمّى بالتّطبيع Normaliztion. بيانات 4-بت تخزّن فقط 16 رقمًا، وبالتّالي بدلًا من تخزين الأوزان يتمّ تخزين الموقع الأقرب وهذا ما يسمّى بالتّكميم. يتمّ التّكميم على بلوكاتٍ صغيرةٍ من أجل تقليل تأثير القيم الشّاذة ويتمّ توزيع قيم البيانات بشكلٍ صحيحٍ من دون التّأثّر بالقيم الشّاذة.
يتمّ تصميم نوع بياناتٍ مثاليٍّ لضغط الأوزان الموزّعة طبيعيًّا بطريقةٍ تقلّل فقدان المعلومات، وتحافظ على الأداء. من أجل توزيعاتٍ طبيعيّةٍ بمتوسّطٍ صفريٍّ وانحرافٍ معياريٍّ ضمن المجال [1, 1-] يتمّ حسابه كما يلي: [5]
- تقدير القيم الكمّيّة: يتمّ حساب 1+ 2k القيمة الكمّيّة من توزيعٍ طبيعيٍّ نظريٍّ (N(0,1 بهدف إنشاء نوع بياناتٍ كمّيٍّ Quantization Data Type بـ عدد ثابت من البتات خاصٍّ بالتّوزيعات الطّبيعيّة.
- تطبيع القيم المحسوبة: بعد الحصول على القيم الكمّيّة، يتمّ تطبيعها إلى المجال [1, 1-].
- تكميم مدخلات الشّبكة العصبونيّة (مثل الأوزان): يتمّ تكميم مصفوفة أوزان الدّخل من خلال تطبيعها إلى المجال [1, 1-] باستخدام مقياسٍ يعتمد على القيمة المطلقة العظمى.
إنّ الصّيغة التّالية تقوم بحساب مستويات التّكميم لتوزيعٍ طبيعيٍّ من خلال متوسّط القيم الكمّيَة. [5]
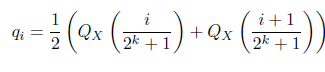
qi هو مستوى التّكميم, أي واحدةٌ من القيم الّتي سيتمّ تحويل البيانات المستمرّة إليها ضمن مجموعة القيم المتاحة.
Qx هو دالّة الكمّيَة Quantile Function، والمعروفة أيضًا بـدالّة التّوزيع العكسيّ التّراكميّ لتوزيعٍ طبيعيٍّ معياريٍّ (N(0,1.
2k هو العدد الإجماليّ لمستويات التّكميم Quantization Bins عند استخدام تكميمٍ بعدد ثابت من البتات. أي أنّه يتمّ تمثيل الأوزان أو القيم المستمرّة بـ 16 قيمةٍ فقط بدلًا من قيم غير محدودةٍ.
مثالٌ توضيحيٌّ: بيانات 4-بت سوف تقسم ما بين القيمة 1- والقيمة 1 بعدد خاناتٍ 16 رقمًا. كما هو موضّحٌ بالمصفوفة المرفقة، ولنفترض أنّ قيمة وزن بمصفوفة الأوزان هو 0.2121 القيمة الأقرب له هي 0.1997 أي رقم الخانة العاشرة. فبدلًا من تخزين عددٍ عشريٍّ بدقّة 32-بت يتمّ تخزين الرقم 10.[2]

إنّ مرحلتي التّطبيع والتّكميم تتمّان على أوزان الشّبكة الأصليّة. بعد أن يتمّ تدريب الشّبكة سوف تتمّ إزالة التّكميم وهي المرحلة الثّالثة، كما هو موضّحٌ بالشّكل التّالي (5):
o التّكميم المزدوج Double Quantization: يتمّ تطبيق التّكميم مرّتين لتقليل الحجم واستهلاك الذّاكرة.
o مثالٌ توضيحيٌّ: لنفترض أنّه لدينا نموذجٌ يحتوي على 1 مليون معامل. كلّ 64 معاملٍ يتمّ تجميعهم ضمن بلوكٍ واحدٍ، ويتمّ تطبيق تكميمٍ ثابتٍ لهم. سوف يتمّ تطبيق التّكميم ذو 32-بت. وسيتمّ استهلاك 0.5 بتٍ لكلّ معاملٍ وبالتّالي سوف يكون لدنيا 500.000 بتٍ. باستخدام التّكميم المزدوج نقوم بتجميع 256 ثابت تكميمٍ في مجموعةٍ واحدةٍ وتطبيق تكميم 8-بت. من شأن هذا التّكميم التّقليل من حجم الثّوابت إلى ما يعادل 0.127 بتٍ لكلّ وزنٍ. وبالتّالي سوف يتمّ استخدام 125.000 بتٍ لكلّ 1 مليون وزنٍ.
o محسّنات الذاكرة المجمّعة Paged Optimizers: تستفيد من ميزة الذّاكرة الموحّدة الّتي تسمح بإجراء نقلٍ سلسٍ للبيانات بين ذاكرة وحدة معالجة الرسوميات وذاكرة وحدة المعالجة المركزية عند الحاجة؛ من أجل تجنّب انهيار النّموذج أو توقّف التّدريب بسبب تجاوز الذّاكرة، ولمنع حدوث ارتفاعاتٍ مفاجئةٍ في استهلاك الذّاكرة أثناء عمليّة تخزين التّدرّجات Gradient Checkpointing، والّتي قد تتسبّب في أخطاء نفاذ الذّاكرة Out-of-Memory Errors، ممّا قد يجعل عادةً عمليّة الضّبط الدّقيق للنّماذج الكبيرة على جهازٍ واحدٍ مهمّةً صعبةً للغاية. تعمل هذه الميزة بطريقةٍ مشابهةٍ لتقسيم الذّاكرة التّقليديّ Memory Paging بين ذاكرة الوصول العشوائيّ للمعالج CPU RAM والقرص الصّلب؛ ولذلك نستخدم هذه الميزة لتخصيص ذاكرةٍ مجزّأةٍ Paged Memory لحالات المُحسِّن Optimizer States، بحيث يتمّ نقلها تلقائيًّا إلى ذاكرة الرام RAM الخاصّة بالمعالج عندما تنفد ذاكرة وحدة معالجة الرّسومات GPU، ثمّ إعادتها إلى ذاكرة وحدة معالجة الرّسومات عندما تكون هناك حاجةٌ لاستخدامها أثناء خطوة تحديث المُحسِّن Optimizer Update Step.[5]
7. الخاتمة
تشمل عمليّة تدريب النّماذج اللّغويّة، سواء النّماذج المعتمدة على المرمّزر فقط Encoder-Only أو النّماذج المعتمدة على فاكّ الترّميز فقط Decoder-Only على مرحلتين هما: التّدريب المسبق Pretraining والضّبط الدّقيق Finetuning. خلال مرحلة التّدريب المسبق، يتمّ تدريب النّموذج باستخدام هدفٍ ذاتيّ الإشراف Self-Supervised Objective على كمّيةٍ ضخمةٍ من النّصوص غير المصنّفة. ورغم أنّ التّدريب المسبق مكلفٌ جدًّا، إلّا أنّه يمكن إعادة استخدام النّموذج النّاتج عدّة مرّاتٍ كنقطة انطلاقٍ لعمليّة الضّبط الدّقيق على مهام متنوّعةٍ.
تُعتبر عمليّة الضّبط الدّقيق أقلّ تكلفة مقارنةً بتكلفة التّدريب المسبق.
ومع ذلك، فإنّ النّماذج اللّغويّة الكبيرة الحديثة تحتوي على عددٍ هائلٍ من المعاملات Parameters، ممّا يجعلنا بحاجة إلى عتادٍ مكلّفٍ، مثل: وحدات معالجة الرسوميات ذات سعة ذاكرةٍ كبيرةٍ؛ لجعل عمليّة الضّبط الدّقيق قابلةً للتّنفيذ، وبالتّالي يزيد من العوائق أمام الدّخول إلى مجال ضبط النّماذج اللّغويّة الكبيرة.
كحلٍّ لهذه المشكلة، تمّ اقتراح عدّة طرقٍ لضبط المعاملات بكفاءةٍ Parameter-Efficient Fine-Tuning، وإحدى أكثر الإستراتيجيّات اعتمادًا وانتشارًا هي استخدام تقنيّة لورا LoRA والّتي تقوم بإدخال تعديلٍ قابلٍ للتّعلّم منخفض الرّتبة على الأوزان في كلّ طبقةٍ من طبقات النّموذج الأساسيّ. إنّ الضّبط الدّقيق للنّماذج اللّغويّة الضّخمة مكلفٌ للغاية من حيث العتاد المطلوب وتكلفة التّخزين والتّنقّل (التّبديل) بين نسخٍ مستقلّةٍ لمهام مختلفة؛ لذلك، تعدّ لورا LoRA إستراتيجيّة تكيّفٍ فعّالة حيث أنّها لا تزيد من زمن الاستدلال Inference Latency، ولا تقلّل من طول تسلسل الإدخال Input Sequence Length مع الحفاظ على جودة النّموذج العالية. والأهمّ من ذلك، أنّها تُتيح التّبديل السّريع بين المهام عند نشر النّموذج كخدمة، وذلك عبر مشاركة الغالبيّة العظمى من معاملات النّموذج بين مختلف المهام.
تُعدّ لورا LoRA أداةً عمليّةً ومفيدةً تمنح (تقريبًا) أيّ شخصٍ القدرة على تدريب نموذجٍ لغويٍّ كبيرٍ LLM متخصّصٍ على بياناته الخاصّة. ونتيجةً لذلك، أصبحت لورا LoRA موضوعًا واسع الدّراسة داخل مجتمع أبحاث الذّكاء الإصطناعيّ، ممّا أدّى إلى ظهور مجموعةٍ من التّوسّعات، والبدائل، والأدوات العمليّة المرتبطة بها. ومن بين أبرز هذه التّوسّعات هي تقنيّة لورا المُكمَّمة، والّتي تقوم بدمج لورا مع تقنيّات كمّ النّموذج Model Quantization؛ لتقليل استهلاك الذّاكرة بشكلٍ أكبر أثناء ضبط النّماذج اللّغويّة الكبيرة. لكنّ هذا التّخفيض في استهلاك الذّاكرة يأتي على حساب انخفاضٍ طفيفٍ في سرعة التّدريب. [4][1]
تقنيّة لورا LoRA يتمّ استخدامها كتقنيّة الضّبط الدّقيق الفعّال. بينما تقنيّة لورا المُكمَّمة QLoRA تضاف كطبقة تقنيّاتٍ؛ لزيادة الفعّاليّة بالإضافة إلى التّقنيّة لورا LoRA في حال كانت هنالك محدوديّة في المساحة التّخزينيّة للأجهزة. [7]
8. المراجع
- Easily Train a Specialized LLM: PEFT, LoRA, QLoRA, LLaMA-Adapter, and More
- Fine Tuning LLM: Parameter Efficient Fine Tuning (PEFT) – LoRA & QLoRA-
- Understanding the LoRA fine tuning concept | by Terry Cho | Medium
- [2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
- QLORA: Efficient Finetuning of Quantized LLMs
- Parameter-Efficient Fine-Tuning of Large Language Models with LoRA and QLoRA
- LoRA vs. QLoRA