التدقيق العلمي: د. دانيا صغير، م. رامي عقّاد
التدقيق اللغوي: هبة الله فلّاحة
في المقال السّابق (معالجة النّصوص باستخدام بايثون Python: العمليّات الأساسيّة) ناقشنا معالجة النّصوص بمفهومها العامّ، وتطبيقاتها المختلفة، وما أهمّيتها والحاجة إليها في عصرنا الحاليّ الذي على الرّغم من كلّ التطوّر والتنوّع المتوافر فيه لوسائل التّواصل، إلّا أنّ النّص المكتوب ما زال يمثّل وسيلة أساسيّة من وسائل التّواصل وتبادل المعلومات وتخزينها.
ومع ظهور الحاجة لمعالجة الكم الهائل من البيانات النصية بدأ البحث والتّنقيب عن الحلول، وبدأ الحلم بـ: آلة قادرة على الفهم والاستيعاب الكامل للنّص، إلّا أنّ المشاكل والمعوّقات والحدود ظهرت لتحوْل ما بيننا وبين هذا الحلم، وأبرز هذه المشاكل _كما قد يتبادر لذهنك عزيزي القارئ_ هي تنوّع اللّغات البشريّة، إذ أنّ الدّراسات تُظهر أنّ عدد اللّغات في العالم يُقدّر بـ 6,909 لغة 1 وهذا الرّقم كبير بشكل مخيف، فإن أردنا أن نكون أكثر عمليّة وبحثنا عن رقم يجعل الحلم أكثر قابليّةً للتّطبيق، فسنجد مثلًا أنّ 98.4% من الإنترنت مكتوب بـ18 لغة 2 وعلى الرّغم من كونه ما زال رقمًا كبيرًا إلا أنّه أكثر واقعيّة وببعض الجهد بالإمكان تحقيقه، صحيح؟ يؤسفني القول عزيزي القارئ أنّ عدد اللّغات ليست المشكلة الوحيدة، فهناك مشكلة أخرى ولعلّها تبادرت لذهنك كذلك بحكم معرفتك واستخدامك للإنترنت في أوقات فراغك؛ إنّها مشكلة اللّهجات المختلفة، حيث أنّ النّصوص في بعض المواقع بالأخصّ مواقع التّواصل الاجتماعيّة والمنتديات مثلًا، ليست على سويّة واحدة حتّى وإن كانت مكتوبة باللّغة نفسها، فمستخدمو هذه المواقع يلجأون إلى استخدام لهجاتهم المختلفة في الكتابة، أو يعمدون لاستخدام تعبيرات مختصرة غير متواجدة في اللّغات الرّسمية أو يعبّرون باستخدام بعض الرّموز.
ولا تتوقّف موجة المعوّقات على الكم وحسب بل إنّها تصل للنّوع، حيث أنّ اللّغات المختلفة تتمايز بشكل كبير في قواعدها النّحوية، ممّا يعني الحاجة لتطوير خوارزميّات مستقلّة لكلّ لغة على حدة.
ومن عمق هذه المشاكل برزت الخوارزميّات الإحصائيّة كحلّ، إذ أنّها لا تعتمد في بنيتها على لغةٍ بحدّ ذاتها وإنّما هي عبارة عن نموذج رياضيّ يتمّ تطبيقه على كلمات النّص بغضّ النّظر عن اللّغة أو الكيفيّة التي كُتبت بها، ممّا يعني أنّه بالإمكان تطبيق خوارزميّات كهذه على أيّ لغة كانت والحصول على النّتائج المرغوبة، ولمّا كان هذا تقدّم كبير إلّا أنّ النّماذج الإحصائيّة لمعالجة النّصوص لن تصل بنا إلى الحلم تمامًا، فمع الاستقلال التّامّ عن اللّغة فسيكون من العسير جدًّا استيعاب النّص كاملًا من قبل الآلة، صحيح؟ ليس تمامًا في الواقع، وسنعرف أكثر عن هذا وعن الخوارزميّات الإحصائيّة من خلال مقالنا هذا الّذي سنناقش فيه واحدة من أفضل التّقنيات الإحصائيّة المتواجدة حاليًّا _ برأيي الشّخصيّ _ في معالجة النّصوص، ألا وهي نمذجة المواضيع.
المحتويات
ما هي نمذجة المواضيع Topic Modeling؟
نمذجة المواضيع هي إحدى تقنيّات تعلّم الآلة Machine learning ومعالجة اللّغات الطبيعيّة NLP، وهي عبارة عن نماذج إحصائيّة احتماليّة رياضيّة تُستخدم لاستخراج الموضوعات Topics من مجموعة من المستندات النّصيّة.
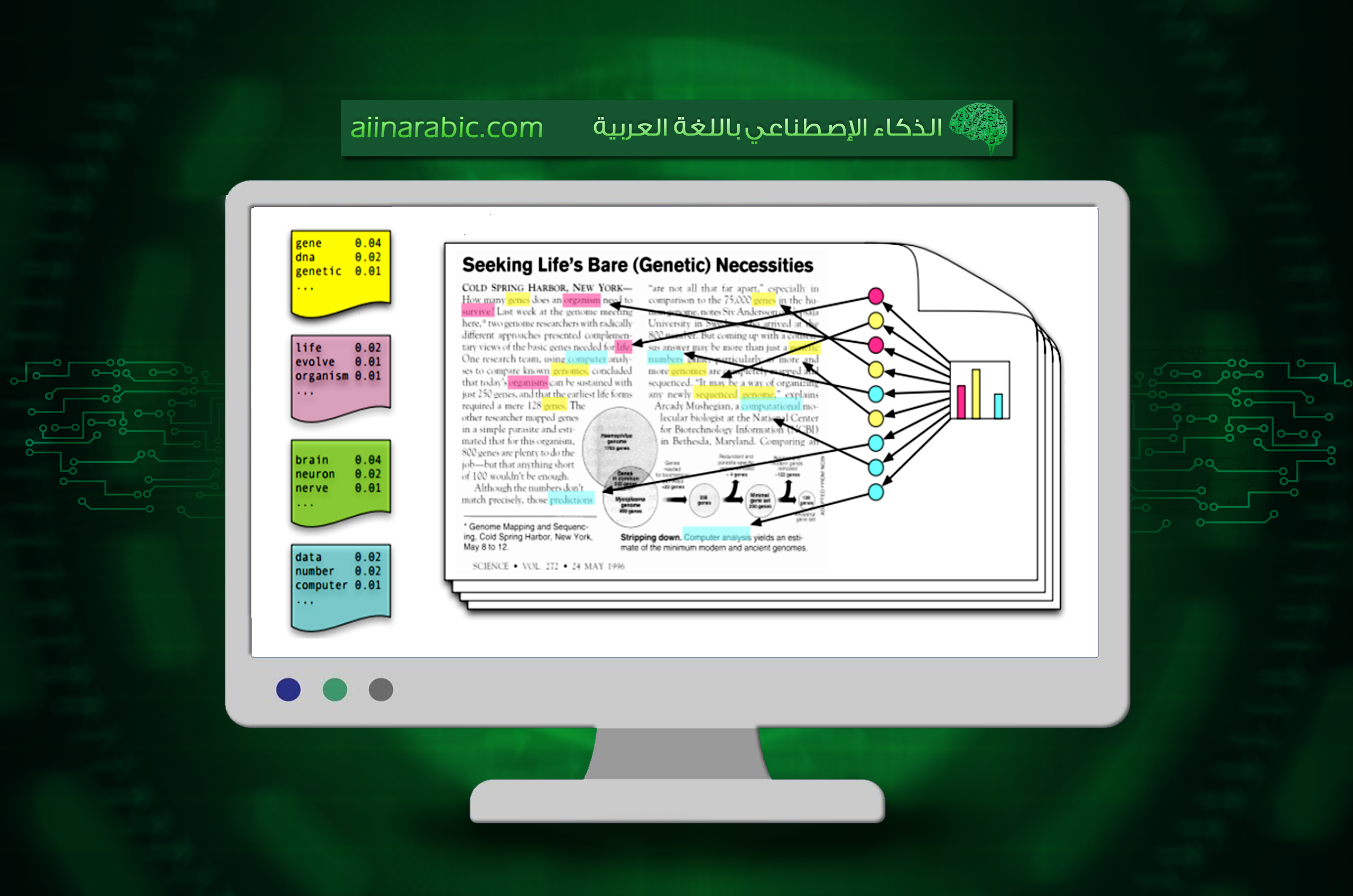
إن أخذنا ملفًّا نصيًّا يتحدّث عن موضوع معيّن، فإنّ مجموعة من الكلمات ستظهر فيه أكثر من غيرها وهذه الكلمات تكون ممثّلة لموضوع النّص، وتعمل خوارزميّات نمذجة المواضيع على استخراج هذه الأنماط من النّص.
غالبًا ما يتمّ استخدام خوارزميّات نمذجة المواضيع في مجالات تنقيب النّصوص Text Mining حيث تستخدم لاكتشاف البنى الدّلاليّة المخفيّة في النّصوص، ولتجميع النّصوص أو تلخيصها أو البحث فيها.
وكمثال بسيط لتوضيح آليّة عمل نمذجة المواضيع، لنفرض أنّ لدينا نصًّا يتحدّث عن كورونا، هذا النّص سيحوي على كلماتٍ من قبيل: حجر، جائحة، لقاح، إصابات… إلخ، بينما نجد أنّ نصًّا آخر يتحدّث عن البورصة سيحوي على كلمات مثل: ارتفاع، هبوط، سهم… إلخ، في حين أنّ كلماتٍ مثل: إنّ، هذا، ثمّ، أو، قال… إلخ تظهر بشكل متساوٍ في الاثنين، ونمذجة المواضيع تعمل على التعرّف على الكلمات المميّزة للمواضيع و استخراجها، إلّا أنّ النّص الواحد غالبًا يحتوي على عدّة مواضيع فمثلًا: نص يناقش البورصة في 90% من كلماته، بينما في الـ 10% المتبقيّة يناقش أثر كورونا على البورصة العالميّة، وبهذا تتمّ نمذجة المواضيع إحصائيّة حيث أنّها تستخلص في نتيجتها نسبة كلّ موضوع في النّص.
أشهر خوارزميّات نمذجة المواضيع:
- توزيع ديريتشليت الكامن (Latent Dirichlet Allocation LDA):
وهو النّموذج الأشهر والأكثر استخدامًا، المبدأ الأساسيّ لعمل هذا النّموذج هو أنّه يعتبر كلّ نصٍّ عبارة عن خليط من عدّة موضوعات، حيث أنّ كلّ نصّ في الدّيوان النّصيّ corpus يحتوي على كلّ موضوعٍ بنسبة ما، وفي هذا النّموذج يحدَّد مسبقًا عدد المواضيع التي سيتمّ البحث عنها وعدد الكلمات الممثّلة لكلّ موضوع، ويتمّ استخراج المواضيع بناءً على نموذج إحصائيّ احتماليّ.
سنناقش هذا النّموذج باستفاضة في الفقرة الثّانية من المقال، كما أنّنا سنختتم بتطبيق عمليّ على هذا النّموذج. - الفهرس المنوية الكامنة (Latent Semantic Indexing LSI):
يتشارك هذا النّموذج مع النّموذج السّابق في منطق تعدّد المواضيع في النّصّ، ولكنّه يعمل بطريقة مختلفة تمامًا، حيث أنّه متمثّل بنموذج رياضيّ مبنيّ على الجبر الخطّيّ (المصفوفات Arrays)، ولا يعتمد في حساباته على التّوزيعات الاحتماليّة.
وسنناقش هذا النّموذج بتفصيل أكبر في مقالنا القادم إن شاء الله. - معالجة ديريتشليت الهرمية (Hierarchical Dirichlet Process HDP):
وهو عبارة عن تعميم وتطوير للنّموذج الأوّل LDA، يعتمد على هيكليّة من التّوزيعات الاحتماليّة، بَيد أنّه على العكس من LDA لا يحتاج لتحديد مسبق لعدد المواضيع والكلمات، حيث أنّ النّموذج يتعلّم آليًّا عدد المواضيع والكلمات من الدّيوان النّصيّ corpus.
استخدامات نمذجة المواضيع في معالجة النّصوص:
لنمذجة المواضيع لتطبيقات متعدّدة؛ حيث يتمّ الاستفادة من نتائج نمذجة المواضيع في:
- تصنيف النّصوص: فإن كان لدينا ديوان نصّيّ ضخم _ مثلًا مقالات في مدوّنة _ فإنّه يمكن الاستفادة بشكلٍ مباشر من نمذجة المواضيع لتحديد تصنيف أيّ نصّ وارد جديد _ مقال _ من خلال تحديد موضوعه ومن ثمّ إضافته للصّنف المناسب.
- تجميع النّصوص: في حال توافر مجموعة نصيّة كبيرة مجهولة المعالم، يمكن الاستفادة من نمذجة المواضيع لتحديد الموضوعات المختلفة ضمن المجموعة النّصيّة ومن ثمّ تقسيمها وفقًا للنّتائج، إضافة لاكتساب المعرفة الإجماليّة عن النّصوص وعمّا تناقشه.
- التّحليل الدّلاليّ: إنّ تجرّد خوارزميّات نمذجة المواضيع عن اللّغة والكلمات، إضافةً لمبدأ عملها الأساسيّ الذي يفترض احتواء النّص الواحد على عدّة مواضيع، يساعدها على استخراج الأنماط والعلاقات المخفيّة بين النّصوص والكلمات، ولذا فإنّها كثيرًا ما تستخدم في التّحليل الدّلاليّ وتطبيقاته.
- البحث: تستفيد محرّكات البحث من نمذجة المواضيع، ومحرّك البحث جوجل واحد من هذه المحرّكات، فلعلّك لاحظت عند إدخالك لكلمة واحدة أو جملة قصيرة سيكون محرك البحث قادرًا على جلب نتائج متعدّدة، بعضها لا يحوي أيًّا من الكلمات التي كتبتها في بحثك في العنوان أو النّص صراحةً، بَيد أنّه جزءٌ مما كنت تبحث عنه ولعله ما كنت تبحث عنه بالضبط؛ وما هذا إلّا نتيجة مباشرة لقدرة نمذجة المواضيع على استخلاص العلاقات الخفيّة ما بين الكلمات والنّصوص المختلفة.
- تلخيص النّصوص: حيث أنّ تلخيص النّصوص يهدف بشكل أساسيّ لاختصار النّص بإزالة الجمل قليلة الأهميّة. وخوارزميّات المواضيع التي تحدّد الكلمات الممثّلة لكلّ موضوع؛ هي أداة مهمّة في تحديد الكلمات والجمل ذات الأهميّة في النّص، والتي يجب الاحتفاظ بها جزءًا منه حتى لا يفقد معناه.
استخدامات نمذجة المواضيع في مجالات أخرى:
آليّة عمل نمذجة المواضيع الرّياضيّة المجرّدة عن طبيعة البيانات، فتحت الباب لاستخدامها في مجالات تنقيب معلومات سوى النّصوص:
- المعلوماتيّة الحيويّة bioinformatics: حيث أنّ استخدامها في هذا المجال هو موضوع بحثيّ لكنه أظهر نتائج واعدة حتّى الآن فيما يتعلّق بتخفيض حجم البيانات، والأبحاث جارية للاستفادة منه في قراءة واستخلاص المعلومات من البيانات البيولوجيّة.
- الرؤية الحاسوبيّة: حيث تبحث العديد من الدّراسات استخدام خوارزميّات نمذجة المواضيع في تصنيف الصّور وتقطيعها واسترجاعها.
نموذج توزيع ديريتشليت الكامن Latent Dirichlet Allocation:
نموذج توزيع ديريشلت الكامن Latent Dirichlet Allocation أو LDA كاختصار هو: نموذج إحصائيّ احتمالي يُستخدم في معالجة اللّغات الطّبيعيّة للحكم على تشابه النّصوص، كما أنّه النّموذج الأشهر لتحقيق نمذجة المواضيع Topic Modeling.
تم اقتراح هذا النموذج في عام 2000 وذلك لاستخدامات في تحليلات الجينات، وفي عام 2003 تم تبنيه لاستخدامات في مجالات الذكاء الصنعي.
مبدأ عمل هذا النّموذج تُوضِحه الجملة التّالية:
يمكن وصف كلّ مستند كتوزيع احتماليّ للمواضيع، ويمكن توصيف كلّ موضوع كتوزيع احتماليّ للكلمات؛ بحيث أنّ التّوزيع الاحتماليّ المستخدم هو نموذج ديريتشليت Dirichlet الاحتماليّ.
وهذا المبدأ هو أحد التّمثيلات الرّياضيّة للفكرة التي شرحناها أعلاه؛ عن أنّ كلّ مستند هو عبارة عن مجموعة من المواضيع، وكلّ موضوع عبارة عن مجموعة من الكلمات.
كما أنّ النّموذج لا يكترث بترتيب الكلمات؛ حيث أنّه يعمل مع مستندات نصيّة ممثّلة كحقيبة كلمات (Bag Of Words BOW)، مما يجعل في تطبيقه حرّيّة أكبر لاكتشاف المواضيع والعلاقات الخفيّة ما بين الكلمات والمستندات، ومن هنا جاءت الكلمة Latent في تسميته حيث أنّها تعني الكامن، المتخفّيّ أو المتستّر.وبالتّالي فإنّه وفق هذا النّموذج يتمّ تمثيل الموضوع لمجموعة من الكلمات، فمثلًا موضوع كورونا الّذي ناقشناه سابقًا يتمّ تمثيله بالشّكل التّالي:(0.1 حجر، 0.4 جائحة، 0.2 لقاح، 0.3 إصابات)، والرقم المرافق للكلمة يعبر عن مدى ارتباط الكلمة بالموضوع.
آليّة عمل النّموذج:
قبل أن نخوض في آليّة عمل النّموذج فلنبدأ أوّلًا بتوضيح المتغيّرات:
k: عدد المواضيع في المستند، وهو عدد ثابت محدّد مسبقًا.
M: عدد المستندات.
N: عدد الكلمات في كلّ مستند.
w: كلمة في المستند.
z: موضوع من المواضيع k.
التّوضيح لتنفيذ الخوارزميّة وطريقة عملها:
- يتمّ اختيار M توزيع احتماليّ θ بحيث يكون هناك لكلّ مستند توزيع ديريتشليت احتماليّ:
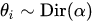
بحيث أنّ α معامل التّوزيع يكون أقلّ من الصّفر. - اختيار k توزيع احتماليّ φ بحيث يكون هناك لكلّ موضوع توزيع ديريتشليت احتماليّ:
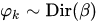
بحيث أنّ العامل β أقلّ من الصّفر.
![]() .
. ![]() .
.
ثمّ يتمّ تكرار المرور على كلّ الكلمات في كلّ مستند i,j حيث:
في كلّ دورة يتمّ اختيار:
a. الموضوع الّذي تنتمي له الكلمة في المستند وفق توزيع categorical distribution 3 (التّوزيع غير المقيّد التّطبيقيّ)، بالاعتماد على توزيع المواضيع في الخطوة 1.
b. توليد الكلمة نفسها من الموضوع وفق توزيع (التّوزيع غير المقيّد التّطبيقيّ)، بالاعتماد على توزيع كلمات المواضيع في الخطوة 2.
وما سبق يمثّل المنطق الرّياضيّ الذي يعمل عليه النّموذج، أمّا من ناحيّة التّطبيق العمليّ له كخوارزميّة 4 تعلّم فإنّ ذلك يكون بالشّكل التّالي:
- اختيار عدد ثابت من المواضيع k.
- تعيين كلّ كلمة في كلّ مستند لموضوع ما من المواضيع بشكل عشوائيّ.
- تكرار المرور على كلّ كلمة w في الدّيوان النصي (corpus):
- لكلّ موضوع c من k:
- حساب احتمال الكلمات في المستند m الّتي تنتمي للموضوع c
p1(topic c | document d) - حساب احتمال اختيار الموضوع c بسبب الكلمة w
p2(word w | topic c) - تعيين موضوع جديد للكلمة w وفق: p1 * p2
- حساب احتمال الكلمات في المستند m الّتي تنتمي للموضوع c
- لكلّ موضوع c من k:
وذلك وفق التّوزيع الاحتماليّ المستخدم وهو في حالة LDA توزيع ديرشليت الاحتمال.
- يتمّ تكرار هذه الخطوات عددًا كبيرًا من المرّات حتى نصل إلى الاستقرار في القيم.
وننوّه أنّ الدّيوان النّصيّ والمستندات الّتي تتعامل معها الخوارزميّة والنّموذج، تكون ممثّلة بحقيبة كلمات BOW ولذا فإنّ ترتيب الكلمات في المستند لا يؤثر على هذا النّموذج كما بينّا سابقَا أثر في حالة هذا النّموذج كما بيّنا سابقًا.
مميّزات النّموذج:
إنّ المميّزات الّتي لاحظناها للنّموذج من ناحية عمليّة تتلخّص في النّقاط التّالية:
- سريع التّنفيذ.
- الاعتماد على التّوزيعات الاحتماليّة يجعله مستقلًّا عن لغة الدّيوان النّصيّ corpus.
- ترابط كبير بين الكلمات المحدّدة للموضوع؛ ممّا يسمح باستخدام هذه الكلمات لاستخراج عنوان للموضوع مثلًا.
- القدرة على تعميم النّموذج على مستندات جديدة.
- لا يأخذ ترتيب الكلمات في المستند بعين الاعتبار.
- وفرة المراجع والمكتبات البرمجيّة والأبحاث بخصوصه.
عيوب النّموذج:
وكما تتواجد المميّزات فلا بدّ أن تتواجد العيوب، وقد لاحظنا العيوب التّالية مع هذا النّموذج:
- الحاجة لتحديد عدد المواضيع بشكلٍ مسبق، ممّا يجعل استخدام النّموذج صعبًا على الدّواوين النّصيّة التي نجهل عدد مواضيعها.
- كونها تعتمد على توزيع احتماليّ لكلمات كلّ نصّ على الموضوع، فإنّ المواضيع تتأثّر بالأطوال المتباينة للنّصوص.
- لا تأخذ ترتيب الكلمات بعين الاعتبار؛ وإن كنّا قد عددْنا هذه النّقطة من المميّزات إذ توفّر مرونة وتساعد على اكتشاف المواضيع المخفيّة والعلاقات الكامنة ما بين الكلمات، إلّا أنّها في بعض الحالات تشكّل عائقًا أمام استخلاص مواضيع دقيقة؛ كما هو الحال مع الكينونات التي تحمل اسمًا من كلمتين أو أكثر كالبيت الأبيض أو الأمم المتّحدة أو منظمة الصحّة العالميّة … إلخ.
تطبيقات:
تحليل مثال مشكلة حقيقيّة:
المشكلة:
لنفترض أنّنا بحاجة للحصول على معلومات إحصائيّة عن المحتوى في منشورات صفحة علميّة على الفيس بوك، الصفحة تنشر كمًّا مقبولًا من المعلومات في كلّ منشور، والمنشورات تطرح مواضيع مختلفة وتحرص على الدّقة العلميّة باستخدامها للمصطلحات العلميّة والإحصاءات الدّقيقة وإيراد المراجع.
تحليل المشكلة:
أوّلًا نمثّل المشكلة كما سيتعامل معها نظام برمجيّ (مدخلات وخرج):
المدخلات: ديوان نصيّ corpus يحتوي على مجموعة من منشورات من صفحة فيس بوك علميّة.
الخرج المتوقّع: إحصاءات عن محتوى المنشورات.
لتحديد آليّة المعالجة المناسبة للمشكلة السّابقة فلننظر لها عن كثب:
الخرج المطلوب هو إحصاءات عن المحتوى، وهذا يعني أنّ الإحصاءات ليست رقميّة بحيث لا يمكن لنا أن نكتفي بإيراد عدد المنشورات بالشهر أو السّنة ونحوه من الإحصاءات، لكن المتوقّع أن يشمل الإحصاء نوعيّة المحتوى وذلك يعني بالضّرورة الحاجة لتحليل نصّ المحتوى.
النّصوص المشمولة في المشكلة السّابقة تمثّل تحدّيًا في طبيعتها، ونرى هذا التحدّي في النّقاط التّالية:
- حقيقة أنّ البيانات (الدّيوان النصّيّ) عشوائيّة وغير مهيكلة إطلاقًا، فمنشورات الفيس بوك بطبيعتها العامّة تفتقر للعناوين كما أنّها تفتقر للتبويبات ولا تشترط أوسمة tags من أيّ نوع؛ وإذ أنّ بعض المنشورات قد تكتب آخذةً بعين الاعتبار عنونة المنشور واستخدام أوسمة فيه، إلّا أنّ ذلك ليس شرطًا لنشر منشور ولذا فلا يمكن الاعتماد عليها.
- النّص يشتمل على كلمات بلغات مختلفة (ذلك أنّ المصطلحات العلميّة غالبًا تكتب باللّغة اللّاتينية).
- يحتوي كلّ نص على روابط إلكترونيّة.
- قد تحتوي بعض النّصوص على أرقام ونسب مئويّة.
طبيعة التحدّيات في هذه البيانات والخرج المتوقّع منها تفرض علينا استخدام نمذجة المواضيع لخوارزميّة LDA بالذّات للمعالجة، وذلك للأسباب التّالية:
- احتواء النّصوص على عدّة لغات يجعل استخدام محلّلات موجّهة للغة واحدة صعبًا، إذ وإن هو خرج بنتائج سيكون في واقع الأمر يتجاهل جزءًا من كلمات النّص مما يجعل النّتائج غير دقيقة.
- اللّغات المتعدّدة كذلك قد تؤثّر على هيكل الجملة؛ ممّا يعني أنّ المحلل المرتبط بلغة معيّنة _مثلًا العربيّة _ سيكون عاجزًا عن فهم تركيب جملة يتوسّطها كلمة لاتينيّة لا تنتمي للقاموس العربيّ، وبالتّالي لن يتعرّف عليها المحلّل الصّرفيّ إطلاقًا؛ ممّا يعني أنّ نتائج التّحليل ستحمل هامش خطأ كبير.
- الخرج المتوقّع هو بيانات إحصائيّة عن المحتوى، وهذا هو الخرج المباشر لخوارزميّات المواضيع؛ ممّا يعني أنّ تطبيقها سيصل بنا إلى الخرج المتوقّع دون معالجة إضافيّة تقريبًا.
- يمكن اختيار خوارزميّة LDA لمميّزاتها من سرعة وإمكانيّة التّطبيق على النّصوص الجديدة (يمكن دمج المنشورات الجديدة والحصول على إحصائيّاتها دون الحاجة لإعادة تدريب النّموذج).
كما أنّ البيانات لا تشمل نقاط ضعف LDA فالمنشورات متقاربة الأطوال كما يبدو.
ملاحظة: كون البيانات غير مهيكلة، ووجود روابط إلكترونيّة وأرقام ونسب مئوية في الدّيوان النصّي لم يدخل في اعتبارات اختيار الخوارزمية؛ ذلك لأنّ البيانات غير المهيكلة واحتواء البيانات على قيم ضجيج (قيم لا تمثل فائدة بحسب طبيعة المشكلة) هي تحدّيات متكرّرة في كلّ مشكلة معالجة نصوص.
لذا بناءً على ما سبق يمكن تطبيق نمذجة المواضيع لحلّ المشكلة السّابقة بالشّكل التّالي:
- قراءة المدخلات (الدّيوان النصّيّ corpus): منشورات الصّفحة.
- تنظيف وهيكلة البيانات:
- استبعاد كلمات التوقف (والّتي يجب أن تشمل الرّوابط الإلكترونيّة والأرقام).
- إنشاء حقيبة كلمات BOW من المدخلات.
- تطبيق خوارزميّة tfidf.
- تطبيق LDA
- عرض النّتائج التي تشمل: أكثر عشرة موضوعات (مثلًا) تمّ ذكرها في المنشورات، حجم المواضيع (نسبة النّصوص في كلّ موضوع)، الكلمات الممثّلة لكلّ موضوع (ويمكن ذكر نسبتها).
مثال تطبيق برمجيّ مبسّط:
لا يكتمل التّوضيح للخوارزميّة بلا تطبيق برمجيّ عليها، لذا سأقدّم هنا مثالًا برمجيًّا ببيانات بسيطة لتوضيح تطبيق خوارزميّة LDA باستخدام مكتبة gensim:
أوّلًا يجب قراءة وتهيئة البيانات:
نُعرف أولًا ديوان النص:
# define the corpus
corpus = [
"معالجة اللغات الطبيعة فرع من فروع الذكاء الصنعي، يدرس معالجة النصوص والكلام والكتابة",
"معالجة الصورة من فروع الذكاء الصنعي، تدرس التعرف على الأجسام في الصور وتحديد ماهيتها، وذلك يشمل التعرف على النصوص",
"قراءة الكتب ممتعة ومسلية جدا، أحلى الكتب هي التي تروي حكايات واقعية",
"الكتاب هو مصدر المعرفة، الحكايات التي يرويها رائعة، تخفف هواية القراءة من قسوة واقعية الحياة"
]
ثم نبدأ عملية تهيئة البيانات، باستخلاص الكلمات (Tokenization) وحذف كلمات الوقف:
# pre-process
# get the corpus tokenized
corpusTokens = []
for text in corpus:
corpusTokens.append(nltk.word_tokenize(text))
# remove stopwords
filteredCorpusTokens = []
stopWords = set(stopwords.words('arabic'))
for doc in corpusTokens:
filteredDoc = []
for w in doc:
if w not in stopWords:
filteredDoc.append(w)
filteredCorpusTokens.append(filteredDoc)
تنتهي عملية التهيئة بإنشاء قاموس الكلمات ومنه يتم استخلاص حقيبة الكلمات الخاصة بالديوان:
# create dictionary
dictionary = Dictionary(filteredCorpusTokens)
# create bag of words
corpus_bow = [dictionary.doc2bow(doc) for doc in filteredCorpusTokens]
لمزيد من التفاصيل عن خطوات التهيئة هذه، يمكن الرّجوع إلى هذا المقال ضمن مقالات معالجة اللغات الطبيعية في هذه المدونة.
ثمّ نبدأ بتهيئة معاملات النّموذج ومن ثمة تدريبه:
# initialize LDA modal
# Set training parameters.
num_topics = 2
عدد المواضيع يمثل المتغير k الذي أشرنا له في خطوات الخوارزمية أعلاه.
التهيئات التالية مرتبطة بالمكتبة وغير مرتبطة بالنموذج بشكل مباشر تم توضيحها بشكل مفصل أدناه:
chunksize = 10
passes = 0
iterations = 2000
eval_every = None
قبل بدء تدريب النموذج نحتاج خطوة أخيرة ألا وهي تحويل القاموس إلى قاموس مرتبط بالفهرس، هذا فقط سيسهل مرور دالّة التدّريب على القاموس.
# Make a index to word dictionary.
temp = dictionary[0] # This is only to "load" the dictionary.
id2word = dictionary.id2token
للبدء بتدريب النموذج سنحتاج لتمرير المدخلات التالية:
- عدد النّصوص التي تتمّ معالجتها في المرّة الواحدة عند تدريب النّموذج، يؤثر هذا المعامل على سرعة تدريب النّموذج.عدد المرّات التي يتمّ تدريب النّموذج فيها على كامل الدّيوان النّصيّ.
- عدد النّصوص التي تتمّ معالجتها في المرّة الواحدة عند تدريب النّموذج، يؤثر هذا المعامل على سرعة تدريب النّموذج.
- عدد المرّات التي يتمّ تدريب النّموذج فيها على كامل الدّيوان النّصيّ.
- عدد مرّات تكرار حلقة التّنفيذ على كلّ نص.
- عدد مرّات تقييم النّموذج، حيث تقيّم المكتبة النّموذج وتظهر النّتائج للمستخدم لتساعد على تحديد أفضل قيم لـعدد النصوص والتكرارات، ويفضّل عدم استخدامه إلّا في حالات الاختبار لأنّ التّقييم يستهلك وقتًا طويلًا.
- المتغيّران الأخيران (β) و(α) هي القيم التي تمثّل التّوزيع الاحتماليّ θ ومعامل التّوزيع الاحتماليّ على التّرتيب _ تمّ مناقشتهما عند شرح آليّة عمل النّموذج _ وبإعطائهما قيمة (auto) تقوم المكتبة بحسابهما وتعديلهما أي تتعلّمهما مع التّكرار للوصول لأفضل نتيجة.5
# train the modal
model = LdaModel(
corpus=corpus_bow,
id2word=id2word,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
num_topics=num_topics,
passes=passes,
eval_every=eval_every
)
# view results
# print documents topics
for doc, doc_bow in zip(corpus, corpus_bow):
print(doc)
print(model.get_document_topics(doc_bow))
# print topics words
top_topics = model.top_topics(corpus_bow, topn=5)
from pprint import pprint
pprint(top_topics)
وأخيرًا نأتي لعرض النّتائج:
# train the modal
model = LdaModel(
corpus=corpus_bow,
id2word=id2word,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
num_topics=num_topics,
passes=passes,
eval_every=eval_every
)
الكلمات الخمس الأولى الّتي تمثّل كلّ موضوع:

الشكل 1
نسبة المواضيع في كلّ نصّ (جملة):

الشكل 2
حيث تعرض بأزواج الطّرف الأوّل هو دليل الموضوع في المصفوفة والثّاني هو نسبة هذا الموضوع في النّص؛ كما شرحنا سابقًا فإنّ كلّ موضوع يتواجد بشكل صغير في كلّ نص.
طبعًا النّتائج التي ظهرت لدينا ساذجة؛ وذلك لأنّنا لم نطبّق على ديوان حقيقيّ وإنّما على نموذج بسيط للبيانات لتوضيح كيفيّة استخدام دوال المكتبة وتدريب النّموذج.
الخاتمة:
نمذجة المواضيع تقنيّة قويّة ذات تطبيقات واسعة، وإنّ تطبيقاتها في مجال معالجة النّصوص، وإمكانيّة استخدامها لحلّ مشاكل مختلفة، وتوفير خصائص مختلفة، تجعلها تتواجد في مقدّمة تقنيّات معالجة النّصوص في زمننا هذا.
ومع لغة بايثون والمكتبات الّتي يوفّرها المجتمع البرمجيّ عامّةً، فهي في متناول اليد للتّطبيق والاختبار.
في المقال القادم سنستمرّ في رحلتنا مع نمذجة المواضيع، وسنتطرّق إلى شرح الطّرق الممكن اتّباعها للتّدريب والاختبار مع البيانات الواقعيّة، كما سنذكر بعض النّقاط المختلفة للمعالجة المسبقة للبيانات، إضافة إلى شرح مفصّل لنموذج الفهرس المنوية الكامنة (Latent Semantic Indexing LSI) فكونوا بانتظارنا.



تعليقان
السلام عليكم ممكن ترسلين الملف الذي يحتوي المشروع للضروره
مشكورة الف تحية