إعداد: م. نادية عبد الجواد
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. ماريّا حماده
المَحتويَات
- 1. المقدّمة
- 2. النّماذج اللّغويَة-النّصّيَة
- 3. السّمات المميّزة لنموذج اللّغة–الرّؤية كوين 2.5
- 4. بنية نموذج لغة-رؤية كوين 2.5
- 5. كيف يعمل نموذج لغة-رؤية كوين 2.5 خطوةً بخطوة.
- 6. المميّزات والتّحسيَنات الّتي طرأت على البنية المعماريّة لكوين نسخة 2.5
- 7. مقارنةٌ بين كوين نسخة 2.5 ونماذج اللّغة–الرّؤية المنافسة
- 8. الابتكارات والقدرات التّقنيَة لنموذج لغوي-بصري كوين نسخة 2.5
- 9. الخاتمة
- 10. المراجع
1. المقدّمة
تخيّل أن تطلب من مساعدٍ ذكيٍّ أن «يبحث عن صورٍ لمدنٍ عند الغسق» أو «يولّد مشهدًا لزاوية قراءةٍ مريحةٍ بإضاءةٍ دافئةٍ». هذه المهام تتجاوز حدود التّعامل مع النّصوص أو الصّور بوصفها كياناتٍ منفصلة؛ إذ تتطلّب منظومةً ذكيّةً قادرةً على استيعاب البعد البصريّ والمضمون اللّغويّ في آنٍ واحدٍ.
وهنا يبرز الدّور الثّوري لما يُعرف بـ نماذج الرّؤية-اللّغة Vision-Language Models – VLMs، الّتي تمثّل نقلةً نوعيّةً في ميدان الذّكاء الاصطناعيّ عبر دمجها مجالين لطالما عُولجا بمعزلٍ عن بعضهما ألا وهما: معالجة اللّغة الطّبيعيّة Natural Language Processing – NLP لفهم النّصوص والرّؤية الحاسوبيّة Computer Vision-CV لفهم الصّور. بفضل هذا الدّمج، تغدو الآلات قادرةً على تفسير البيانات المتعدّدة الوسائط والتّفاعل معها بذكاءٍ يحاكي، بل يقترب تدريجيًّا من القدرات الإدراكيّة البشريّة [1].
إنَ هذه القدرة الفريدة تفتح آفاقًا رحبة لتطبيقاتٍ رائدةٍ في طيفٍ واسعٍ من الصّناعات، بدءًا من منصّات التّواصل الاجتماعي، مرورًا بـ الرّعاية الصّحيّة والتّجارة الإلكترونيّة، وصولًا إلى الفنون الإبداعيّة الّتي تستثمر في توليد المحتوى المرئيّ والنّصّيّ على حدٍّ سواء.
وانطلاقًا من هذا التحوّل الجذريّ، دعونا نغوص معًا في عالم نماذج الرّؤية-اللّغة؛ لنكتشف مكوّناتها الجوهريّة وأهمّ المفاهيم المرتبطة بها، ونرصد كيف تعيد رسم ملامح التّفاعل بين الإنسان والآلة في عصر الذّكاء الاصطناعي؛ للانتقال بعدها إلى أهمّ نموذجٍ لغويٍّ-بصريٍّ قدّم العديد من الابتكارات المتقدّمة من أجل أن يعالج بها أوجه القصور في النّماذج السّابقة وهو كوين بإصدارهQwen2.5-VL 2.5.
2. النّماذج اللّغويَة-النّصّيَة
تُعرَّف نماذج الرّؤية-اللّغة VLMs على أنَها أحد أبرز أشكال النّماذج متعدّدة الوسائط Multimodal Models؛ إذ تمتلك القدرة على التّعلّم المشترك من الصّور والنّصوص معًا، بما يجعلها تجسّد نقلةً نوعيّةً في ميدان الذّكاء الاصطناعي. وتُصنَّف هذه النّماذج ضمن النّماذج التّوليديّة Generative Models، حيث تستقبل صورًا ونصوصًا كمدخلاتٍ لتولّد في المقابل مخرجاتٍ نصّيّةٍ دقيقةٍ وذات معنى.
وتتميّز هذه النّماذج بقدرتها على إنجاز مهام التّعلّم بدون أمثلةٍ Zero-shot learning، ممّا يمنحها قابليّةً عاليةً على التّعميم والتّكيّف مع أنماط بصريّة متعدّدة، بدءًا من الوثائق وصفحات الويب وصولًا إلى الصّور المعقّدة. وتشمل تطبيقاتها العمليّة التّفاعلات الحواريّة حول الصّور والإجابة عن الأسئلة البصريّة وفهم وتحليل المستندات، فضلًا عن توليد أوصافٍ نصّيّةٍ غنيّةٍ للصّور والتّعرّف على الكائنات تبعًا للتّعليمات.
ولم تتوقف قدرات هذه النّماذج عند الفهم اللّغويّ–البصريّ فحسب، بل امتدّت لتشمل التقاط الخصائص المكانيّة داخل الصور؛ إذ بإمكانها إنتاج مربَعات الإحاطة Bounding Boxes أو أقنعة التّجزئة Segmentation Masks عند توجيهها لاكتَشاف كائنٍ بعينه، كما تستطيع تحديد مواقع الكيانات المختلفة والإجابة عن أسئلةٍ ترتبط بمواضعها المطلقة أو النّسبيَة.
وعلى الرّغم من هذا التّقدّم اللّافت، فإنَ نماذج الرّؤية-اللّغة القائمة اليوم تتباين بشكلٍ كبيرٍ في بنيتها وإمكاناتها؛ ويعود ذلك إلى اختلاف نوعيّة البيانات المستخدمة في تدريبها وتنوّع آليّات ترميز الصّور، الأمر الّذي ينعكس بدوره على مستوى أدائها وعمق قدراتها عبر مختلف السّيناريوهات التّطبيقيّة .[2]
1.2. ما هي الرّكائز الجوهريَة الّتي تقوم عليها نماذج الرّؤية–اللّغة؟
تطوَرت بنية نماذج اللّغة-الرّؤية من مرحلة التّدريب المسبق من الصّفر إلى الاعتماد على نماذج اللّغات الكبيرة المدرّبة مسبقًا، والّتي تعتبر بالنّسبة لها كقاعدةٍ أساسيّةٍ لعمليّة اتساق المعلومات البصريّة واللّغويّة معاً. [3]
لننتقل الآن إلى استعراض الفارق بين البُنى التّقليديّة والبُنى الحديثة الّتي تستند إلى نماذج اللّغات الكبيرة، قبل الانتقال إلى المكوّنات الأساسيّة.
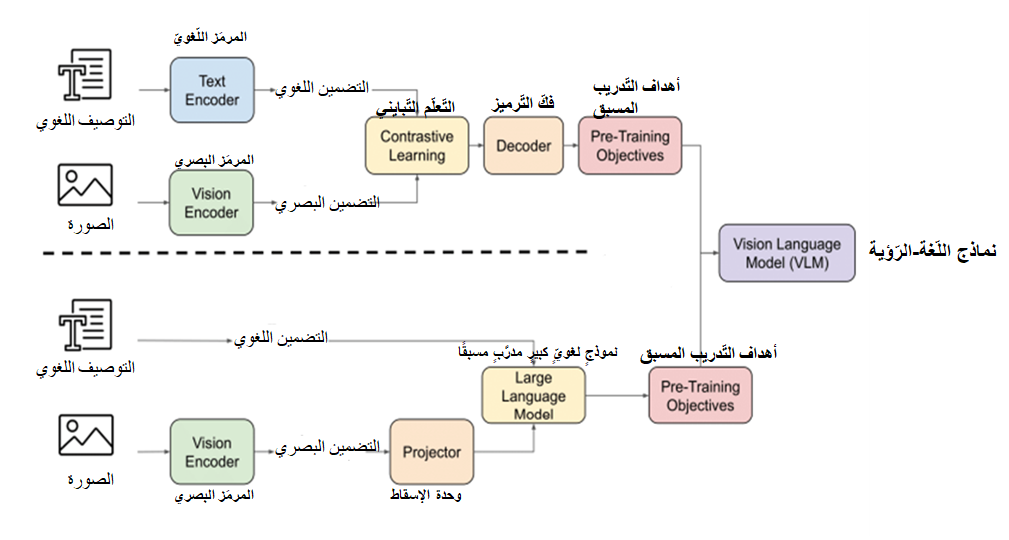
- تدريب النّموذج من الصّفر: من الأمثلة البارزة على هذا النّهج نماذج التّدريب المسبق المقارن بين اللّغة والصّورة (كليب) Contrastive Language-Image pretraining – CLIP والتّدريب المسبق للّغة والصّورة بطريقة التّمهيد الذّاتي Bootstrapping Language-Image pretraining – BLIP.
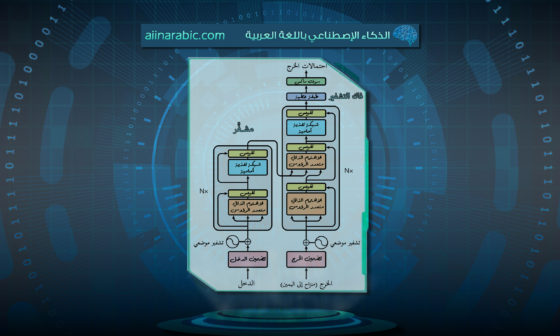
وللتّعمّق أكثر في الخطوات (وفق الشّكل 1):
-
-
- في مرحلة التّوصيف النّصّيّ، يُولّد تضمينٌ نصّيٌّ ضمن فضاء التّضمينات عبر المرمَز اللّغويّ Text Encoder.
- وفي المقابل، يتمّ ترميز الصّورة المدخلة لتُمثَّل في فضاء التّضمينات البصريّة.
- بعد ذلك، يُستخدم التّعلّم التّبايني Contrastive Learning؛ لربط التّمثيلين (اللّغويّ والبصريّ) داخل فضاءٍ مشتركٍ موحَّدٍ، بحيث تتقارب التّمثيلات المتناظرة (صورة مع نصّها) وتبتعد التّمثيلات غير المرتبطة.
- أخيرًا، يُنقَل النّموذج إلى مرحلة فكّ التّرميز؛ لإنتاج المخرجات المستهدفة.
- في مرحلة التّوصيف النّصّيّ، يُولّد تضمينٌ نصّيٌّ ضمن فضاء التّضمينات عبر المرمَز اللّغويّ Text Encoder.
-
- تدريب النّموذج بالاعتماد على نموذجٍ لغويٍّ كبيرٍ جاهزٍ: مثال كنماذج كوين نموذج لغوي-بصري، المساعد الكبير للّغة والرّؤية Large Language and Vision Assistant – LLaVA.
وللتعمّق أكثر في الخطوات (وفق الشّكل 1):
يقوم هذا النّهج على مكوّنين أساسيّين:
-
- نموذجٍ لغويٍّ كبيرٍ مدرَّبٍ مسبقًا.
- وحدة الإسقاط Projector، والّتي غالبًا ما تُبنى على شكل شبكة تغذيةٍ أماميَةٍ متعدَدة الطّبقات Multilayer Perceptron-MLP.
- نموذجٍ لغويٍّ كبيرٍ مدرَّبٍ مسبقًا.
تتولَى وحدة الإسقاط مهمّة تحويل التّمثيلات البصريّة عالية الأبعاد إلى رموز تضمينيَةٍ مضغوطةٍ تتوافق مع النّمط النّصّيّ. ويمكن تدريب هذه الوحدة جنبًا إلى جنب مع باقي مكوّنات النّموذج لتحقيق الأهداف متعدّدة الأنماط Multimodal Objectives، أو إبقاء بعض الأجزاء مجمّدة للحفاظ على المعرفة المكتسبة خلال تدريبه المسبق. [3]
بعد ذلك، يدخل كلٌّ من التّمثيل اللّغويّ والتّمثيل البصريّ إلى النّموذج اللّغويّ الكبير ليتمّ فهمهما بشكلٍ تكامليٍّ. يلي ذلك، تطبيق أهداف التّدريب المسبق Pre-Training Objectives الّتي تُستخدم لتكييف النّموذج مع المهام متعدّدة الوسائط.[3]
تكمن ميزة هذا الأسلوب في اعتماده على نموذجٍ لغويٍّ كبيرٍ موجودٍ مسبقًا Large Language Models – LLMs، ممّا يقلّل الحاجة إلى التّدريب من الصّفر ويوفّر موارد حاسوبيّة ضخمة، مع الاستفادة الكاملة من المعرفة الغنيّة الّتي يمتلكها الـنّموذج.
ذكرنا أعلاه مفاهيم، مثل المرمَز اللّغويّ والمرمَز النّصّيّ وهما مكوّنان نماذج اللّغة-الرّؤية، حيث تُحقّق فهمًا متكاملًا للمدخلات متعدّدة الوسائط عبر المزج الذّكي بين هذه المرمِّزات، مدعومًا بآليّات الدّمج عبر الوسائط.
وانطلاقًا من ذلك، سنفصّل الآن كلّ مكوّنٍ على حدة، لنكشف كيف يسهم كلٌّ منها في بناء تمثيلاتٍ دقيقةٍ وموحَّدةٍ تمكّن النّموذج من استيعاب المعنى الكامن خلف النّصوص والصّور معًا.
1.1.2. المرمَزات البصريّة
تُعنى المرمِّزات البصريّة Vision Encoders بمعالجة البيانات الصّورية عبر خوارزميّاتٍ متقدّمةٍ في مجال الرّؤية الحاسوبيّة، حيث تستند غالبًا إلى هياكل متطوّرة، مثل شَبَكَات الطَّيِّ العُصبُونِيَّة Convolutional Neural Networks – CNNs أو محوّلات الرّؤية Vision Transformers – ViTs. تقوم هذه النّماذج بتمثيل الصّور على شكل متّجهاتٍ عالية الأبعاد تحمل في طيَاتها ثراء الخصائص البصريّة، بما في ذلك الألوان والأشكال والملمس، فضلًا عن العلاقات المكانيَة الدّقيقة بين العناصر.
لا يقتصر عمل هذه النّماذج على التّمييز البصريّ فحسب، بل تتعمّق أيضًا في استكشاف الخصائص السّياقيَة والعلاقات الدّلاليَة داخل الصّور، ممّا يعزّز قدرتها على إدراك المشاهد البصريّة المعقدة بعمقٍ ووعيٍ شموليٍّ .
وتلعب المرمِّزات دورًا محوريًّا في إسقاط المكوّنات البصريّة إلى فضاء التَضمين Embedding Space، بما يتوافق مع التّمثيلات المستخرجة من نماذج اللّغات الكبيرة؛ إذ يتمّ تدريبها على استخلاص ميّزاتٍ بصريّةٍ ذات قيمةٍ عاليةٍ من الصّور ومقاطع الفيديو، ليتمّ دمجها بسلاسةٍ مع التّمثيلات اللّغويَة، بما يفتح آفاقًا واسعةً نحو فهمٍ متعدّدِ الأبعاد يجمع بين البصيرة البصريّة والفهم اللّغويّ العميق. [3]
2.1.2. المرمَزات اللّغويّة
تسعى المرمَزات اللّغويّة Language Encoders إلى معالجة النّصوص عبر تقنيّاتٍ متقدّمةٍ في معالجة اللّغة الطّبيعيّة، مستندةٍ في ذلك غالبًا إلى هياكل قويّة، مثل المحوّلات ثنائيّة الاتجاه كـمحوَل بيرت Bidirectional Encoder Representatives From Transformers – BERT أو المحوّل التّوليديّ المُدرّب مسبقًا جي بي تي Generative pre-trained Transformer – GPT.
تقوم هذه النّماذج بتحويل الجمل والكلمات إلى تضمينات عدديَة غنيَة تلتقط المعاني الدّلاليَة والعلاقات السّياقيَة والخصائص النّحويَة للّغة، ممّا يمكّنها من إدراك النّصوص وفهمها على مستويات متعدّدة من التّجريد والتّحليل.
وفي الاتجاه الحديث، لا تعتمد غالبيّة النّماذج المتقدَمة على مرمَزٍ نصيٍّ مستقلٍّ، بل تستعين بنماذج اللّغات الكبيرة مباشرةً لفهم النّصوص ودمجها مع المدخلات البصريّة عبر طبقات الإسقاط. ويعكس هذا التّحوّل استراتيجيّةً متناميةً نحو الاستفادة الكاملة من القدرات المعرفيّة لنماذج اللّغة الكبيرة مفضّلةً إياها على المكوّنات النّصّيّة التّقليديّة، بهدف تمكين أنظمة الذّكاء الاصطناعي من أداء مهام أكثر تنوّعًا وتعقيدًا في مجالات الاستدلال والتّوليد متعدّد الأنماط.[3]
3.1.2. الدّمج عبر الوسائط
يُعدّ الدّمج عبر الوسائط Cross-Modal Fusion المرحلة الأساسيّة الّتي يتمّ فيها دمج التّمثيلات البصريّة واللّغويَة ضمن فضاءٍ مشتركٍ. [1]
عادةً ما تُوظّف نماذج اللّغة–الرّؤية إحدى التّقنيات الثلاث التّالية لدمج المدخلات البصريّة والنّصّيّة بكفاءةٍ عاليةٍ:
- التّعلّم التّبايني Contrastive Learning:
يُعدّ هذا النّهج من أبرز أساليب الدّمج، ويُستخدم في نماذج التّدريب المسبق التّبايني للّغة–الصّورة. يقوم النّموذج بمحاذاة أزواج الصّور والنّصوص ضمن فضاء تمثيلٍ مشتركٍ، حيث يعمل على زيادة التّشابه بين الأزواج الصّحيحة عبر تقليل المسافات بينها، وفي الوقت ذاته تقليل التّشابه بين الأزواج غير الصّحيحة من خلال توسيع المسافات، ممّا يعزّز دقة الرّبط بين الرّؤية واللّغة. - آليّات الاهتمام المتقاطع Cross-Attention Mechanisms:
تستعين بعض النّماذج بآليّات الاهتمام المتقاطع لتمكين النّموذج من التّركيز على أجزاءٍ محدّدةٍ من الصّورة بناءً على الاستعلام اللّغوي. هذا الأسلوب يعزّز الفهم العميق للعلاقة بين الخصائص البصريّة والعناصر النّصّيّة، ويُتيح معالجة السّياق المشترك بدقةٍ أكبر. - فضاء التَضمين المشترك Joint Embedding Space: في هذا النّهج، يتمّ إسقاط كلٍّ من البيانات البصريّة واللّغويّة داخل فضاء تمثيلٍ موحدٍ، ممّا يتيح مطابقةً واسترجاعًا فعالًا بين الصّور والنّصوص. يُستخدم هذا الأسلوب بكثرة في مهام، مثل استرجاع الصّورة–النّصّ، حيث يصبح بإمكان النّموذج فهم السّياق البصريّ والنّصّي كوحدةٍ متكاملةٍ.
2.2. مجموعة من المفاهيم والتّقنيّات الأساسيّة المرتبطة بنماذج اللّغة–الرّؤية
1.2.2. نماذج اللّغة–الرّؤية متعدّدة اللّغات
مع الانتشار الواسع للذّكاء الاصطناعي على الصّعيد العالميّ، تتّجه جهود تطوير نماذج اللّغة–الرّؤية نحو تمكينها من فهم ومعالجة عدّة لغات لكي تسمَى بنماذج اللّغة–الرّؤية متعدّدة اللّغات Multilingual Vision-Language Models، بحيث تصبح قادرةً على تفسير الصّور والنّصوص عبر طيفٍ واسعٍ من اللّغات المتنوّعة. هذا التّوسَع في دمج اللّغات يعزَز بشكلٍ ملحوظٍ من آفاق استخدام هذه النّماذج في مناطق غير ناطقةٍ بالإنجليزيّة، ويفتح المجال أمام جعل تقنيّات الذّكاء الاصطناعي أكثر شمولًا. [1]
2.2.2. التّعلّم بدون أمثلةٍ
تتميّز نماذج اللّغة–الرّؤية بقدرتها على التّعلّم بدون أمثلةٍ، ما يعني قدرتها على أداء مهامٍ جديدةٍ لم يتمّ تدريبها عليها بشكلٍ صريحٍ. تعتمد هذه النّماذج في ذلك على المعرفة العامّة المكَتسبة خلال تجربتها في مهامٍ أو تدريباتٍ سابقةٍ، ممّا يمكّنها من الاستدلال والتّعميم باستخدام تمثيَلاتها السّابقة. يعزّز هذا النّهج من مرونة النّماذج وقدرتها على التّكيّف مع سيناريوهاتٍ غير مألوفةٍ، ويفتح آفاقًا واسعةً لتطبيقات الذّكاء الاصطناعي متعدّدة الأبعاد في بيئاتٍ متنوّعةٍ ومعقّدةٍ.[1]
3.2.2. تعلّم الإشراف الذّاتي
تُستخدم تقنيّة تعلّم الإشراف الذّاتي Self-Supervised Learning لتقليل الاعتماد على البيانات الموسومة Labeled data، والّتي يعتبر تجميعها مكلفًا ويستغرق وقتًا طويلًا. تستطيع نماذج اللّغة-الرّؤية تعلَم العلاقات بين البيانات البصريّة واللّغويّة من خلال مهام توقَع الكلمة المحجوبة في وصف صورٍ، أو توقَع المقطع البصريّ المرتبط بكلمةٍ معيّنةٍ. هذا يوفَر تمثيلات غنيَة يمكن إعادة استخدامها في مهام متعدّدة، كما ويُمكَن من تدريب نماذج قويّة على نطاقٍ واسعٍ.[1]
4.2.2. الاتساق عبر الأنماط
تستفيد نماذج اللّغة–الرّؤية بشكلٍ كبيرٍ من ضمان اتساق التّمثيلات البصريّة والنّصّيّة وهو الاتساق عبر الأنماط Cross-Modality Consistency؛ إذ تسهم عمليّات التّحقق من هذا الاتساق عبر الأنماط المختلفة في تعزيز قدرة النّموذج على محاذاة التّمثيلات البصريّة مع النّصّيّة بدقةٍ عاليةٍ. يؤدي ذلك إلى رفع مستوى الأداء في مهام متقدّمة، مثل توليد الأوصاف النّصّيّة للصّور Image Captioning والإجابة عن الأسئلة البصريّة، ممّا يجعل التّجربة التّفاعليّة مع المحتوى البصريّ أكثر دقةً وثراءً.[1]
5.2.2. استخدام مخططات المشهد
تعتمد نماذج اللّغة–الرّؤية على تقنيّة استخدام مخططات المشهد Use of Scene Graphs لتمثيل العناصر داخل الصّورة والعلاقات المتبادلة بينها بأسلوبٍ منظّمٍ يسهل قراءته وتحليله. تمكّن هذه المعالجة النّموذج من تقديم فهمٍ أعمق وأدق لبنية المشاهد البصريّة، ممّا يعزّز أداء النّماذج في المهام الّتي تتطلّب إدراكًا دقيقًا للسّياق والقدرة على التّمييز بين التّفاصيل الدّقيقة داخل الصّورة.[1]
في هذا السّياق، سنسلّط الضّوء على نموذج كوين، وبخاصّة نسخة 2.5 منها. تُعدّ عائلة كوين سلسلةً متطوّرةً من نماذج اللّغة–الرّؤية واسعة النّطاق الّتي طوّرتها شركة علي بابا كلاود Alibaba Cloud، وتُمثّل خطوةً نوعيّةً في دفع حدود التّكامل بين المعالجة البصريّة واللّغويّة.
3. السّمات المميّزة لنموذج اللّغة–الرّؤية كوين 2.5
1- قدرات قويّة في تحليل المستندات: يرتقي نموذج اللّغة-الرّؤية كوين نسخة 2.5 بمهمّة التّعرّف على النّصوص إلى مهمّة تحليلٍ شاملٍ للمستندات، حيث يتفوّق في معالجة المستندات متعدّدة السّياقات واللّغات، بما في ذلك المستندات اليدويّة والمضمَنة (مثل الجداول، الرّسوم البيانيّة، الصّيغ الكيميائيّة، والنّوتات الموسيقيّة). [4]
2- تثبيت دقيق للكائنات Objects عبر مختلف الصّيغ: يتيح النّموذج دقةً محسّنةً في اكتشاف الكائنات وتحديد مواقعها وعدّها، مع دعم صيغ الإحداثيّات المطلقة لتمكين الاستدلال المكانيّ المتقدّم.[4]
3- فهم الفيديوهات فائقة الطّول والتّأطير الدّقيق للأحداث: يوسّع النّموذج آليَة الدّقة الدّيناميكيّة الأصليّة لتشمل البُعد الزّمني، ممّا يعزّز قدرته على فهم مقاطع فيديو تمتد لساعاتٍ مع إمكانيّة استخراج مقاطع الأحداث خلال ثوانٍ.[4]
4- تعزيز وظائف الوكيل Agent على الأجهزة الحاسوبيّة والمحمولة: يستفيد النّموذج من قدرات متقدّمة في تحديد موقع مكوّنات التّوصيف في الصّورة Grounding والاستدلال واتخاذ القرار، ممّا يمنحه وظائف وكيل أكثر تطوّرًا على الهواتف الذّكيّة وأجهزة الكمبيوتر.[4]
لننتقل الآن لاستكشاف البنية الكاملة لنموذج اللّغة–الرّؤية كوين 2.5.
4. بنية نموذج لغة-رؤية كوين 2.5
1.4. نموذج اللّغات الكبيرة
سلسلة نماذج كوين 2.5 تعتمد على نماذج اللّغات الكبيرة كأساسٍ محوريٍّ. يبدأ النّموذج بأوزانٍ مُدرّبةٍ مسبقًا مأخوذةٍ من نموذج كوين 2.5 اللّغويّ الكبير Qwen2.5 LLM، ممّا يمنحه ثروةً من المعرفة المسبقة الّتي اكتسبها قبل دمجه مع مكوَن الرّؤية. من أجل تعزيز قدرته على فهم البيانات متعدّدة الوسائط كالنّصوَص، الصّور والفيديو، تمَ تعديل آليّة التَضمين الموضعيّ الدّورانيّ Rotary Position Embedding – RoPE إلى إصدارٍ متطوّرٍ يُعرف بـ التّضمين الموضعيّ الدّورانيّ متعدّد الوسائط والمحاذي للزّمن المطلق Multimodal Rotary Position Embedding Aligned to Absolute Time. هذه التّقنيّة المبتكرة تمكّن النّموذج من استيعاب البُنى المكانيّة والزّمانيّة للمعلومات بدقةٍ فائقةٍ، ممّا يتيح له معالجة البيانات في سياقٍ زمنيٍّ ومكانيٍّ متكاملٍ وأكثر ثراءً. [4]
2.4. المرمَز البصري
يعتمد نموذج اللّغة–الرّؤية كوين نسخة 2.5 على بنية محوّل الرّؤية ViT المعاد تصميمها بعنايةٍ، مع التّركيز على ثلاث نقاط أساسيّة: [4]
1.2.4. التّضمين الموضعي الدّوراني ثنائيّ الأبعاد
تُمكّن تقنيّة التَضمين الموضعي الدّوراني ثنائيّ الأبعاد 2D-RoPE النّموذج من إدراك المواقع المكانيَة للعناصر داخل الصّورة بدقةٍ عاليةٍ على مستوى ثنائيّ الأبعاد، ممّا يعزّز فهم السّياق البصريّ.
2.2.4. آليّة الاهتمام المعتمدة على النّوافذ
تُقلّل تقنيّة آليّة الاهتمام المعتمدة على النّوافذ Window Attention من التّكلفة الحسابيّة من خلال تركيز الانتباه على أقسامٍ محدّدةٍ (نوافذ) من الصّورة بدلًا من معالجة جميع البكسلات، ممّا يرفع كفاءة الأداء دون التّضحية بالدّقة.
3.2.4. إجراءات التّدريب والاستدلال
يعاد تحجيم أبعاد الصّور (الارتفاع والعرض) لتكون من مضاعفات العدد 28 قبل إدخالها إلى بنية المحوَل، حيث تُولَّد دفعات الصورة باستخدام خطوة انتقال Stride مقدارها 14 كأساسٍ لاستخراج سماتٍ بصريّةٍ ذات قيمةٍ عاليةٍ للمعالجة اللّاحقة.
3.4. دمج سمات الرّؤية واللّغة المعتمد على الشّبكات متعدّدة الطّبقات
لمعالجة التّحدّيات الحسابيَة النّاتجة عن طول سلاسل السّمات الصّوريّة، يستخدم نموذج اللّغة-الرّؤية كوين 2.5 أسلوبًا بسيطًا وفعّالًا لضغَط هذه السّلاسل قبل تمريرها إلى نموذج اللّغة الكبير. فبدلًا من استخدام السّمات الأوّليّة النّاتجة مباشرةً عن الـمحوَل البصريّ فيَت، يتمّ أوّلًا تجميع كلّ أربع دفعاتٍ Patches متجاورةٍ مكانيًّا. بعد ذلك، تُدمج هذه السّمات المجمّعة وتُمرّر عبر شبكةٍ عصبيّةٍ متعدّدة الطّبقات مكوّنةٍ من طبقتين، تقوم بإسقاطها إلى بُعدٍ يتماشى مع تمثيلات النّصوص في نموذج اللّغة الكبير. هذه العمليّة لا تقلّل فقط من التّكلفة الحسابيّة، بل تمنح أيضًا مرونةً ديناميكيّةً لضغط سلاسل السّمات الصّوريّة مهما كان طولها. [4]
5. كيف يعمل نموذج لغة-رؤية كوين 2.5 خطوةً بخطوة.
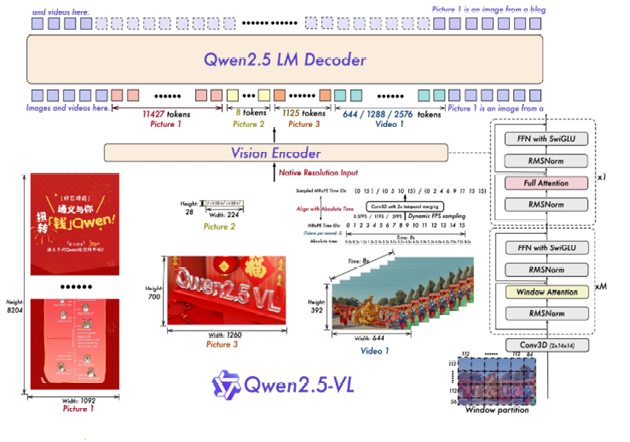
لنستعرض بشكلٍ شاملٍ بنية النّموذج مع شرحٍ مفصَلٍ لعمل كلّ مكوَنٍ، كما هو موضَحٌ في الشّكل (2):
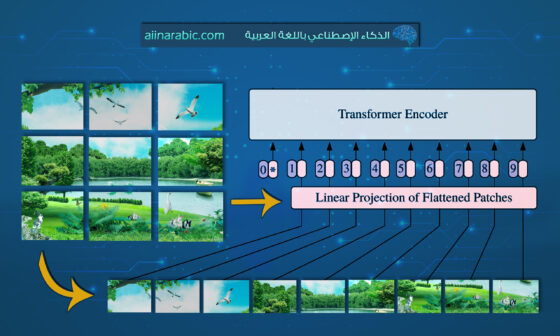
- المدخلات (البيانات): إمَا أن تكون صور مفردة، فيديوهات أو مجموعة صور. أهمّ نقطةٍ وهي إعادة تحجيم المدخلات قبل عمليّة المعالجة، حيث تعاد الأبعاد لتصبح من مضاعفات العدد 28.
- تقسيم الصّورة إلى دفعاتٍ: تُقسَم الصّورة إلى دفعات بخطوةٍ مقدارها 14.
- المرمَز البصريّ: وهو بنية المحوَل البصريّ فيت المعدَل الّتي تدعم الدّقة الأصليّة، ويحوي المكوّنات الرّئيسيّة:
التّضمين الموضعي الدّوراني ثنائيّ الأبعاد، آليّة الاهتمام عبر النّوافذ مع طبقاتٍ معياريّةٍ تحوي دالّة التّفعيل الوحدة الخطيَة البوابيَة باستخدام دالةSwish
Swish-Gated Linear Uni- SwiGLU ولعمليّة التّطبيع جذر متوسط مربع الانتشار Root Mean Square Normalization- RMSNorm.
-
معالجة الفيديو والبعد الزّمني: عند وجود فيديو، يُستخدم مرشّحٌ ثلاثيّ الأبعاد Three-Dimensional Convolution- Conv3D لالتقاط العلاقات الزّمنيّة القصيرة بين الإطارات. مع الأخذ بعين الاعتبار الموقع الزّمني المطلق لكلّ تمثيلٍ بصريٍّ ، وهو مهمٌّ للفيديوهات الطويلة ولتحديد متى حدث حدثٌ معيّنٌ بالضّبط في الزّمن.
- ضغط السّمات (الميّزات): تجميع كلّ أربع دفعاتٍ متجاورةٍ، حيث يتمّ دمجها ثمّ تمريرها عبر شبكةٍ عصبيّةٍ متعدّدة الطّبقات لإسقاطها إلى نفس بُعد التّضمينات (التّمثيلات) النّصّيّة.
- مواءمة الأبعاد: تُصبح السّمات البصريّة في فضاءٍ يطابق فضاء اللّغة للنموذج اللّغوي الكبير. يسمح بإدخال التّمثيلات البصريّة إلى النّموذج اللّغوي الكبير كـوحداتٍ لفظيةٍ أو كمعلوماتٍ، ويمكن للـنموذج اللّغوي الكبير التّعامل معها مباشرةً أثناء التّوليد أو الاستدلال.
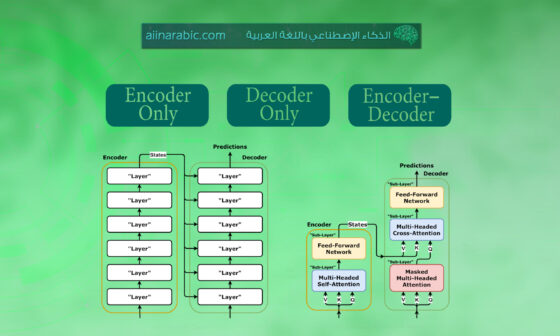
- دمج مع فاكّ تَرميز اللّغة:
-
- التّهيئة: فاكّ التَرميز decoder يبدأ بأوزانٍ مُدرّبةٍ مسبقًا من نموذج كوين 2.5 نموذج لغوي كبير؛ لذلك يستفيد من المعرفة اللّغويّة الكبيرة بالفعل.
- تغذية الرّموز: تمثيلات الصّور/مقاطع الفيديو المضغوطة تُدخل إلى جانب الوحدات اللفظية النّصّ، الشّكل (2) يُظهر توزّعًا إلى وحدات لفظية صور/فيديو بين وحداتٍ لفظيةٍ نصّيّةٍ.
- آليّات الاهتمام: يستطيع النّموذج اللّغوي الكبير الآن إجراء عمليّات الاهتمام الدّاخليّة self-attention على كلّ الوحدات اللفظية، وبهذا يربط المعلومات البصريّة مع النّصّيّة ويولّد مخرجاتٍ، مثل وصفٍ نصّيٍّ وإجابة على سؤالٍ.
والسّؤال الأهم ما هي الابتكارات المعماريّة والتّحسينات الّتي تجعل كوين نسخة 2.5 نموذج اللّغة-الرّؤية مميّزًا في القدرات الوظيفيّة وكفاءة المعالجة مقارنةً بسوابقه؟
6. المميّزات والتّحسيَنات الّتي طرأت على البنية المعماريّة لكوين نسخة 2.5
1.6. المرمَز البصريّ الفعَال والسّريع
نظرًا لازدياد أهميّة التّعامل مع الصّور والفيديوهات عالية الدّقة، فقد شهدت بنية كوين نسخة 2.5 إعادة تصميمٍ معمّقةٍ لمعالجة التّحدّيات المرتبطة بالعمليّات الحسابيّة الضّخمة، والّتي غالبًا ما تؤدي إلى استهلاكٍ غير متوازنٍ للموارد خلال مرحلتي التّدريب والاستدلال.
من أبرز التّحسينات آليّة الاهتمام المُجزَّأ إلى نوافذ، الّتي تُوزَّع عبر عدّة طبقاتٍ ضمن البنية. تعمل هذه الآليّة على تقليل التّعقيد الحسابي عند معالجة الصّور بأحجامٍ متنوعةٍ عبر تقسيم الصّورة إلى نوافذ صغيرة، ما يجعل تكلفة الحسابات تنمو بشكلٍ خطّيٍّ مع عدد الدفعات بدلًا من النّمو التّربيعي. إنّ حجم النّافذة المستخدم هو 112×112 بكسل (أي ما يعادل 8×8 دفعة)، حيث تُعالج المناطق الأصغر من هذا الحجم بدون حشو Padding، ممّا يحافظ على الدّقة الأصليّة للصّورة.
فيما يخصّ التّرميز الموضعي Positional Encoding، فقد تمّ اعتماد التّضمين الموضعي الدّوّار ثنائيّ الأبعاد لالتقاط العلاقات المكانيَة بدقةٍ عاليةٍ داخل الصّور. أمّا بالنّسبة لمعالجة مدخلات الفيديو، فقد تمّ اعتماد تقسيمٍ ثلاثيّ الأبعاد، حيث تُجمع إطارات متتالية معًا، ممّا يقلّل بشكلٍ كبيرٍ عدد الرّموز الّتي تدخل إلى النّموذج ويضمن توافقًاَ سلسًاَ مع البنى الحاليّة، مع تحسينٍ كبيرٍ في كفاءة معالجة البيانات المتسلسلة للفيديو.
كما تمّ استخدام التّطبيع RMSNorm ودالّة التّفعيل SwiGLU؛ لتعزيز الأداء ودقَّة الاستنتاج.
كما تُطبَّق تقنيّة العيّنة الدّيناميكيّة Dynamic Sampling أثناء التّدريب، حيث تُغذّى الصّور إلى النّموذج بأحجامها الأصليّة ونسبها المتنوّعة. هذه التّقنية تُعزّز قدرة النّموذج على التّعميم وتمكّنه من التّعامل مع صورٍ متعدّدة الأحجام بكفاءةٍ، مع ضمان استقرار عمليّة التّدريب. [4]
2.6. محاذاة تضمين الموقع الدّوراني متعدّد الوسائط
هذه التّقنيّة تُطبَّق على بياناتٍ متعدّدة الوسائط (مثل نصوص وصور وصوت)، مع إضافة خطوة محاذاةٍ مع الزّمن المطلق. هذه المحاذاة تُنفَّذ باستراتيجيّةٍ جديدةٍ تجعل النّموذج يفهم كيف تتغيّر البيانات مع الوقت (ديناميكيّات زمنيّة) بطريقةٍ ذكيّةٍ ودون الحاجة لمزيدٍ من العمليّات الحسابيّة الثّقيلة، ممّا يحافظ على كفاءَة الأداء. [5]
3.6. الدّقة ومعدّل الإطارات الدّيناميكي الأصليّين
يُقدّم كوين نسخة 2.5 تحسيناتٍ متميّزةٍ على المستويين المكانيّ والزّمنيّ؛ لتمكين معالجةٍ فعّالةٍ لمدَخلاتٍ متعدّدة الوسائط. [4]
- على المستوى المكانيّ: يقوم النّموذج بتحويل الصّور ذات الأحجام المختلفة بشكلٍ ديناميكيٍّ إلى تسلسلاتٍ من الرّموز بأطوالٍ مناسبةٍ، ما يعزّز قدرة النّموذج على التقاط التّفاصيل البصريّة بدقّةٍ عاليةٍ.
- على المستوى الزّمنيّ: يدَرك النّموذج أنَ معدّل الإطارات في مقاطع الفيديو قد لا يكون ثابتًا، لذا يستخدم تقنيّة العيّنات بمعدل إطاراتٍ ديناميكيٍّ Dynamic FPS Sampling؛ للتّكيَف مع التّغيّرات الزّمنيَة. يتيح هذا للنموذج فهم تطوَرات الأحداث وحركة الفيديو بدقةٍ أعلى، ممّا يعزّز أداءه في تحليل السّيناريوهات الزّمنيَة المعقدة.[5]
ما الّذي يميّز نموذج اللّغة–الرّؤية كوين نسخة 2.5عن غيره من نماذج الذّكاء الصّنعي؟
7. مقارنةٌ بين كوين نسخة 2.5 ونماذج اللّغة–الرّؤية المنافسة
- مقارنةً بـ جي بي تي فور أف GPT-4V: بينما يتفوَق نموذج أوبن أي آي OpenAI في المهام الإبداعيّة، يتفوَق كوين نسخة 2.5 في السّيناريوهات المؤسّسيّة، لا سيّما في السّياقات غير الإنجليزيّة (مثل تحليل الخطّ الصّينيّ أو اللّهجات الإقليميّة).[6]
- مقارنةً بجيميني Gemini: بينما تتميَز جوجل بقوّة معالجة الفيديو في الوقت الفعلي، يتفوَق كوين في دقّة التّعرّف الضّوئي على الحروف وتحليل الصّور المتعدّدة.[6]
- مقارنةً بالنّماذج مفتوحة المصدر، مثل إل-لافا LLaVA: يوفّر كوين تدريبًا مخصّصًا للصّناعة وقابليّةً توسَع غائبةً في المشاريع المجتمعيّة.[6]
8. الابتكارات والقدرات التّقنيَة لنموذج لغوي-بصري كوين نسخة 2.5
1.8. الفهم البصريّ المتقدَم
يمتلك كوين2.5 قدرةً فائقةً على التّعرّف على النّصوص المكتوبة بخط اليدّ، الخطوط ذات الأنماط المميّزة، اللّافتات متعدّدة اللّغات، حتّى في الصّور منخفضة الدّقة. ينبع تميّز هذه القدرة من الفهم الدّلالي العميق المبني على بنيةٍ معماريّةٍ متقدّمةٍ ترتكز إلى المحوّلات البصريّة التّقليديّة، الّتي تمّ تدريبها على مجموعات بياناتٍ متنوّعةٍ وثريّةٍ، ممّا يمكّنها من الانتقال بالمعلومة من مستوى البكسل الخام إلى مستوى المعنى السّياقي.
على سبيل المثال، عند معالجة صورةٍ لسوقٍ شعبيٍّ مكتظٍ، لا يقتصر دور النّموذج على تحديد الأكشاك فحسب، بل يربط بين لغات اللّافتات (مثل الصّينيّة والإنجليزيّة) وديناميكيّات الحشود ليستنتج العناصر الأكثر شيوعًا.[6]
2.8. قابليّة التّوسّع ومعالجة السّياقات الطّويلة
لدى النّموذج قدرةٌ على المعالجة والتّعرّف على مدخلاتٍ طويلةٍ ومعقدةٍ وذات سياقاتٍ طويلةٍ، مثال (مستندات ضخمة أو محادثات مطوَلة أو مقاطع فيديو طويلة)، مع الحفاظ على ترابط المعنى ودقّة الفهم بحيث يركَز على المعلومات المهمّة وليس بالتّركيز على كامل التّفاصيل. والسّبب يعود في البنى المعماريّة الّتي تعتمد على آليّة الاهتمام الهرميّ Hierarchical Attention.
على سبيل المثال: لو كان هناك مصمّم يعمل على شعار ويكرّر تعديلاتٍ استنادًا إلى مراجع سابقة للوحاتٍ مرجعيّة، فإنَ النّموذج يستطيع تتبَع كلّ الملاحظات بشكلٍ منطقيٍّ وإعطاء الأولويّة للمعلومات المهمّة عبر تسلسل البيانات. النّموذج أيضًا يدعم كمدخلاتٍ أكثر من 10000 وحدةٍ لفظيّةٍ Tokens بدون فقدان التّرابط.[6]
3.8. التّحسين بمستوى المؤسّسات
يعتمد النّموذج عند النّشر على تقنيّاتٍ متقدّمةٍ، مثل تكميم النّماذج وآليّة التّفريغ الدّيناميكيّ للحوسبة Dynamic Computation Offloading، ممّا يعزّز كفاءتَه ويقلّل من التّكلفة الحسابية. هذه التّقنيّات تجعل النّموذج ملائمًا تمامًا للتّطبيقات الّتي تتطلّب معالجةً فوريّةً في الزّمن الحقيقي، حيث يضمن أداءً عالي السّرعة مع الحفاظ على دقّة الاستنتاج، ممّا يفتح آفاقًا واسعةً لاستخدامه في البيئات المؤسّسيّة الّتي تحتاج إلى استجاباتٍ دقيقةٍ وسريعةٍ.[6]
4.8. الاستدلال متعدّد الوسائط
من خلال البنية المعماريّة الجوهريّة الّتي يتمتّع بها النّموذج لعمليّة دمج السّمات اللّغويّة مع السّمات البصريّة في فضاء تمثيلٍ مشتركٍ واحدٍ.
على سبيل المثال: إذا كان الدّخل للنّموذج هو عبارة عن استفسارٍ معقَدٍ: “أيَ منتجٍ في هذه الصّور يمتلك أعلى التّقييمات؟”، النّموذج لديه القدرة على الإجابة من خلال دمج الاستدلال للسّمات البصريّة كتصميم العلبة مع المراجعات النّصّيّة المجمّعة من الإنترنت. [6]
9. الخاتمة
في ظل تسارع وتيرة التّطوّرات التّقنيّة والابتكارات في مجال النّماذج اللّغويّة-البصريّة الذّكيَة، تتنافس الشّركات لإثبات تفوّق نماذجها عبر تطوير بنى معماريّة مبتكرةٍ وإضافة تقنيّاتٍ متقدَمةٍ لمعالجة تحدّياتٍ عانت منها النّماذج السّابقة. وقد طوَرت شركة علي بابا كلاود نموذجًا لغويًّا-بصريًّا باسم كوين إصداره 2.5، بأحجامٍ مختلفةٍ لتلبية احتياجات سيناريوهات عملٍ متنوّعةٍ، مع تباينٍ في الأداء والكفاءة.
يمتاز كوين بنسخته 2.5 بقدراتٍ تقنيّةٍ متقدّمةٍ تمكّنه من تنفيذ مهامٍ متنوّعةٍ، مثل تحليل المستندات ذات السّياقات الطّويلة، الإجابة على استفساراتٍ معقَدةٍ، فهم مقاطع الفيديو الطّويلة وتحديد مواقع الكائنات بدقّةٍ عاليةٍ.
من أبرز مميّزاته آليّة الاهتمام المُجزّأ إلى نوافذ والّتي تُمكّنه من العمل بكفاءةٍ وسرعةٍ دون فقدان التّفاصيل الهامّة، وتقنيّة التّضمين الموقعي الدّوراني متعدّد الوسائط لترميز الزّمن المطلق، ما يمنحه القدرة على فهم المعلومات الزّمنية بدقّةٍ، إضافةً إلى معالجة الدّقَة الدّيناميكيّة الّتي تمنَحه مرونةً في التّعامل مع بياناتٍ لغويّةٍ وبصريّةٍ متنوّعةٍ من حيث الدّقّة والحجم، ممّا يجعله مناسبًا للتّطبيقات الزّمنيّة الحقيقيّة.
يضع هذا النّموذج معيارًا جديدًا للنّماذج اللّغويّة-البصريّة، حيث يُظهر قدرةً استثنائيّةً على التّعميم وأداء المهام عبر مجالاتٍ متعدّدةٍ. تُمهّد ابتكاراته الطّريق نحو أنظمة أكثر ذكاءً وتفاعليَة، تربط بين الإدراك البصريّ واللّغويّ وتطبيقاتهما في العالم الواقعيّ.
يمكن القول إنَ النّماذج اللّغويّة-البصريّة الكبيرة تتطوّر بسرعةٍ هائلةٍ عبر دمج تقنيّاتٍ متقدَمةٍ وآليّاتٍ ذكيّةٍ، ممّا يعزّز قدرتها على محاكاة الفهم البشريّ المتكامل للنّصوص والصّور والفيديو في آنٍ واحدٍ.
10. المراجع
- Vision-Language Models: Redefining AI by Bridging Visual and Linguistic Intelligence | by Jagadeesan Ganesh | Medium
- Vision Language Models Explained
- arXiv:2501.02189v6 [cs.CV] 6 Apr 2025
- arXiv:2502.13923v1 [cs.CV] 19 Feb 2025
- Qwen2.5-VL: Architecture, Benchmarks and Inference
- Unlocking the Future of AI with Qwen 2.5 VL: Where Vision Meets Language – Alibaba Cloud Community