المَحتويَات
- مقدمة
- فهم نماذج اللغة الكبيرة :
- كيف تعمل نماذج اللّغة الكبيرة؟ [1]
- هندسة المحول [1]
- آليات الانتباه [1][4]
- مراحل تدريب نماذج اللّغة الكبيرة [1][3]
- كيف تتعلم نماذج اللغة الكبيرة؟ [1]
- من أين تتعلم نماذج اللغة الكبيرة ؟ [1]
- ما الجديد عن التّنبّؤ بالكلمات [1]
- تطبيقات نماذج اللّغة الكبيرة [1]
- التجريب باستخدام نماذج اللّغة الكبيرة [1]
- التحدّيات والاعتبارات الأخلاقيّة [1]
- المراجع :
- مقدمة
- فهم نماذج اللغة الكبيرة :
- كيف تعمل نماذج اللّغة الكبيرة؟ [1]
- هندسة المحول [1]
- آليات الانتباه [1][4]
- مراحل تدريب نماذج اللّغة الكبيرة [1][3]
- كيف تتعلم نماذج اللغة الكبيرة؟ [1]
- من أين تتعلم نماذج اللغة الكبيرة ؟ [1]
- ما الجديد عن التّنبّؤ بالكلمات [1]
- تطبيقات نماذج اللّغة الكبيرة [1]
- التجريب باستخدام نماذج اللّغة الكبيرة [1]
- التحدّيات والاعتبارات الأخلاقيّة [1]
- المراجع :
مقدمة
في الأونة الأخيرة وبفضل نماذج اللّغة الكبيرة (LLMs)، لفت الذّكاء الاصطناعي انتباه الجميع تقريبًا.وارتفعت شعبية شات جي بي تي ChatGPT، الذي ربما يُعتبر من أكثر نماذج اللّغة الكبيرة LLM شهرة، وعلى الفور جعل الاستخدامات الكثيرة للذكاء الاصطناعي في متناول الجميع. ومع ذلك، لا يزال فهم كيفية عمل هذه النّماذج أقل شيوعًا.تهدف هذه المقالة إلى تقديم مقدّمة شاملة لنماذج اللّغة الكبيرة، ومناقشة أصولها، وكيفيّة عملها، وتطبيقاتها، والاعتبارات الأخلاقية التي تنطوي عليها.ولكن أولاً، دعونا نحاول فهم مكانة نماذج اللّغات الكبيرة في عالم الذّكاء الاصطناعي. [1]
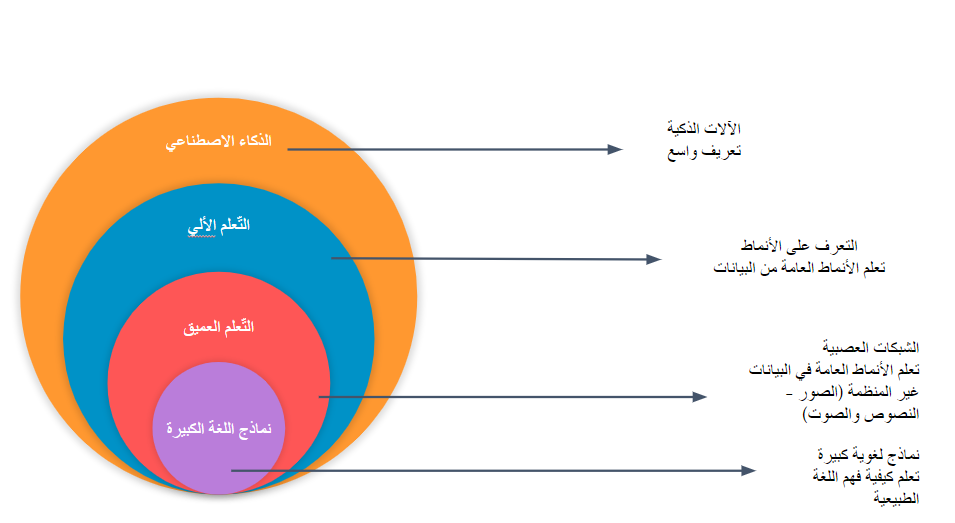
غالبًا ما يتمّ تصور مجال الذّكاء الاصطناعي في طبقات موضّحة في الشكل (1) :
- الذّكاء الاصطناعي (AI) هو مصطلح واسع جدًا، ولكنه يتعامل عمومًا مع الآلات الذّكية.
- التعلم الآلي (ML) هو مجال فرعي من الذّكاء الاصطناعي يركز بشكل خاص على التّعرف على الأنماط في البيانات. و بمجرد التّعرف على نمط، يمكن تطبيق هذا النمط على ملاحظات جديدة.
- التعلم العميق وهو المجال داخل التّعلم الآلي يركز على البيانات غير المنظّمة، والتي تتضمن النصوص والصور. يعتمد على الشّبكات العصبيّة الاصطناعيّة، وهي طريقة مستوحاة من الدماغ البشري.
- تتعامل نماذج اللّغة الكبيرة (LLMs) مع النص على وجه التحديد، وسيكون هذا هو محور هذه المقالة.[2]
فهم نماذج اللغة الكبيرة :
ذكرنا سابقأً أن نماذج اللّغة الكبيرة هي أحد أنواع الذّكاء الاصطناعي الذي يتم تدريبه على فهم اللغة البشرية وتوليدها والتفاعل معها بطريقة متماسكة وذات صلة بالسياق.
ماتعنيه كلمة “كبيرة” في هذه النّماذج ليس فقط في حجمها، حيث تمتد إلى مليارات المعلّمات (البارامترات)، ولكن أيضًا في الكمية الهائلة من البيانات التي يتمّ تدريبها عليها. يتضمن هذا التدريب تحليل مجموعة واسعة من مصادر النّصوص، من الكتب والمقالات إلى مواقع الويب ومنشورات وسائل التّواصل الاجتماعي. [1][3]
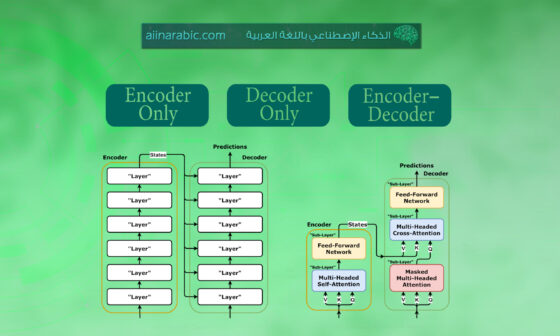
كيف تعمل نماذج اللّغة الكبيرة؟ [1]
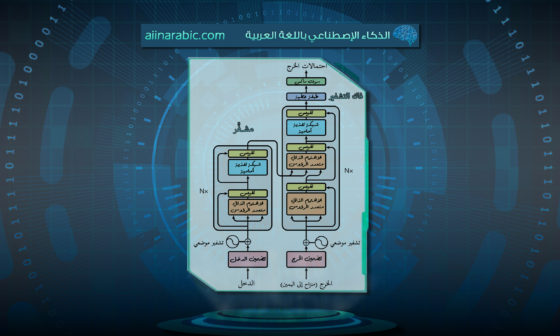
إن التّكنولوجيا الأساسية وراء نماذج اللّغة الكبيرة هي ما يُعرف بنموذج المحوّل Transformer، والذي تم تقديمه لأول مرة في ورقة بحثيّة عام 2017 بعنوان “الانتباه هو كل ما تحتاجه”. Attention Is All You Need يمكنكم الإطّلاع على هذه المقالة للفهم الأعمق لنموذج المحوّل المحوّل يستخدم هذا النّموذج آليات تسمّى الانتباه attention والانتباه الذّاتي self-attention لإعطاء وزن يعبر عن أهمية الكلمات المختلفة في الجملة. من خلال القيام بذلك، فإنه يلتقط الفروق الدقيقة في اللّغة، بما في ذلك السّياق والنحو. تتضمّن عمليّة التّدريب تغذية النّموذج بمجموعة كبيرة من النصوص واستخدام خوارزميات التعلّم الآلي لضبط معاملاات النّموذج حتى يتمكّن من التّنبؤ بالكلمة التالية في الجملة.
هندسة المحول [1]
يمثل نموذج المحوّل Transformer، وهو حجر الأساس لنماذج اللّغة الكبيرة الحديثة، تطوراً كبيراً عن الأساليب السّابقة في معالجة اللّغة الطّبيعية. وعلى عكس النّماذج السابقة، التي اعتمدت على معالجة البيانات المتسلسلة (مثل الشّبكات العصبيّة المتكرّرة recurrent neural networks RNNs)، يتبنى المحوّل نهج المعالجة المتوازية. ويُحسن هذا التغيير بشكل كبير من الكفاءة وقابليّة التوسع، مما يسمح للنّموذج بالتّعامل مع تسلسلات أطول من البيانات بشكل أكثر فعاليّة.
آليات الانتباه [1][4]
آليّة الانتباه attention: توجد “آلية الانتباه” في قلب نموذج المحول. وهذا يسمح للنّموذج بالتّركيز على أجزاء مختلفة من تسلسل الإدخال عند إنتاج كل كلمة من تسلسل الإخراج. على سبيل المثال، عند ترجمة جملة، قد يركّز النّموذج بشكل أكبر على موضوع الجملة عند ترجمة فعل.
الانتباه الذاتي self-attention: هو نوع معيّن من الانتباه attention، يُسمى الانتباه الذاتي، يمكّن كل موضع في تسلسل الإدخال من الاهتمام بجميع المواضع في نفس التسلسل. هذه الآليّة ضروريّة لفهم السياق والعلاقات بين الكلمات في الجملة. وهي تسمح للنّموذج بالتقاط التّبعيّات طويلة المدى وفهم السياق بما يتجاوز الكلمات المباشرة.
مراحل تدريب نماذج اللّغة الكبيرة [1][3]
- البيانات والمعالجة المُسبقة Data and Preprocessing: تبدأ عملية التدريب بجمع ومعالجة مسبقة لمجموعة ضخمة من بيانات النصوص حيث يتم تنظيف هذه البيانات وهيكلتها لتكون مناسبة للتدريب.
- التّقسيم Tokenization إلى وحدات أصغر، أو “وحدات” Tokens، والتي يمكن أن تكون كلمات أو أجزاء من كلمات أو حتى أحرف فردية. يعد هذا التّقسيم إلى وحدات أساسيًا لكي يتمكن النموذج من معالجة النص.
- تدريب النّموذج Model Training: أثناء التّدريب، يتعلّم النّموذج التّنبّؤ بالوحدة التالية في تسلسل معين بالنظر إلى الوحدات السابقة. يتم تحقيق ذلك من خلال عمليّة تُعرف باسم “التّعلم غير الخاضع للإشراف” unsupervised learning، حيث لا يتم إعطاء النموذج تعليمات صريحة ولكنه يتعلم الأنماط من البيانات نفسها.
- ضبط معاملات النّموذج Adjusting Model Parameters: يتألف النموذج من ملايين أو حتى مليارات المعاملات. يتم ضبطها من خلال خوارزميات الانتشار العكسي backpropagation والتّحسين مثل الانحدار التدرجي العشوائي (SGD) Stochastic Gradient Descent لتقليل الفرق بين الوحدة التالية المتوقّعة والفعليّة في بيانات التدريب.
- دالة الخسارة Loss Function: تُستخدم دالة الخسارة لقياس أداء النّموذج أثناء التدريب. الهدف هو تقليل هذه الخسارة، والتي تمثل الخطأ في توقعات النّموذج.
كيف تتعلم نماذج اللغة الكبيرة؟ [1]
تتعلّم هذه النماذج على مرحلتين – التّدريب المُسبق pre-training والضّبط الدّقيق Fine-tuning.
- التّدريب المُسبق
في مرحلة التّدريب المُسبق، يكون الهدف هو تعليم النّموذج دلالات اللّغة وبنيتها وقواعدها من خلال عرض الكثير من الأمثلة (مليارات الأمثلة). وكما هو الحال مع التّعلمّ الآلي، فإننا ببساطة نعرض الأمثلة على النموذج ونتركه يتعلّم القواعد بنفسه.التّدريب المسبق هو الجزء الأطول والأكثر تكلفة من الناحية الحسابية في عملية التّعلّم. يتم عرض الأمثلة على النّموذج مرارًا وتكرارًا وفي النهاية يتعلم القواعد.من خلال القيام بذلك مرارًا وتكرارًا على مجموعة بيانات ضخمة جداّ ، تتعلم هذه النّماذج تمثيلات غنية للّغة.
- الضّبط الدّقيق
في مرحلة الضّبط الدّقيق، يمكننا أن نأخذ نموذجًا مدربًا مسبقًا ونعرض عليه أمثلة للمهمة التي نريده أن يحلها. يمكن أن يكون هذا إجابة على سؤال (من هو أينشتاين)، أو تحليل المشاعر (هل كانت تلك التغريدة سيئة؟)، وما إلى ذلك. تستغرق هذه المرحلة عادةً وقتًا وبيانات أقل بكثير مقارنة بمرحلة ما قبل التّدريب
من أين تتعلم نماذج اللغة الكبيرة ؟ [1]
إذا أخذت كلّ الكتب في العالم، وكلّ محتويات موقع ويكيبيديا wikipedia، وكلّ النّصوص التي يمكنك الحصول عليها من خلال البحث في الويب واستيعاب تلك المعرفة، هذا ما يتم تغذيته بهذه النّماذج. في مرحلة ما قبل التّدريب، يتم تدريب هذه النّماذج على كلّ مجموعات البيانات هذه (التي تعادل أقل بقليل من الوعي البشري الجماعي). وهذا سبب آخر لكونها كبيرة من حيث التصميم. النّماذج الأصغر محدودة فيما يمكنها تعلّمه. في مرحلة الضّبط الدّقيق، يتم استخدام مجموعات بيانات أصغر داخليّة ذات صلة بتطبيقك.
ما الجديد عن التّنبّؤ بالكلمات [1]
في حين ركزت الإصدارات المبكّرة من برامج تعلّم اللّغة في المقام الأول على التّنبّؤ بالكلمة التالية في التسلسل، فإن النّماذج الأحدث مُصممة لأداء مجموعة من المهام اللّغويّة. تتضمن هذه المهام الإجابة على الأسئلة وتلخيص النص وحتى إنشاء فقرات متماسكة وذات صلة بالسياق من النص.
تطبيقات نماذج اللّغة الكبيرة [1]
تتمتع نماذج اللّغة الكبيرة بمجموعة واسعة من التطبيقات:
- إنشاء المحتوى: من كتابة المقالات والقصائد إلى إنشاء الخيال الإبداعي، يمكن لنماذج اللّغة الكبيرة إنتاج أشكال متنوعة من المحتوى المكتوب.
- ترجمة اللغة: يمكن لهذه النّماذج ترجمة النص بين لغات مختلفة بدقة عالية.
- برامج الدّردشة الآليّة والمساعدون الافتراضيون: تعمل نماذج اللّغة الكبيرة على تشغيل برامج الدّردشة الآليّة المتطوّرة التي يمكنها التعامل مع استفسارات خدمة العملاء المعقّدة و التفاعل معهم مما يضمن خدمة أفضل و على مدار الوقت
- استخراج المعلومات وتحليلها: تُستخدم لاستخراج المعلومات من مجموعات البيانات الكبيرة، وتلخيص النصوص، وحتى تحليل المشاعر.
- الأدوات التعليميّة: في التعليم، تساعد نماذج اللّغة الكبيرة في إنشاء مواد تعليمية مخصصة وأنظمة تعليمية
- كتابة الكود التلقائية: يمكن للنماذج مساعدة المطورين على كتابة أكواد برمجية بفعالية. على سبيل المثال، يمكنها تقديم اقتراحات، إكمال الأكواد بشكل تلقائي، أو حتى كتابة تطبيقات كاملة بناءً على وصف معين. و اكتشاف الأخطاء البرمجية وتصحيحها. يُدخل المبرمج الكود، وتقوم النماذج بتحليل الأخطاء المحتملة واقتراح حلول. بالإضافة لترجمة الأكواد بين لغات البرمجة: يمكن لهذه النماذج ترجمة الكود المكتوب بلغة برمجة معينة إلى لغة برمجة أخرى، مما يسهل على المطورين التبديل بين اللغات البرمجية.
- توليد الصور من النصوص أو شرح الصور: يمكن لهذه النماذج تحويل وصف نصي (مثل “غروب الشمس فوق بحر هادئ”) إلى صورة مرئية تعكس هذا الوصف. تُستخدم هذه التقنية في مجالات مثل تصميم الألعاب والفن الرقمي. بالإضافة إلى شرح وتحليل الصور: يمكن للنماذج تحليل الصور وتقديم وصف دقيق لمحتواها. هذه الخاصية مفيدة في تطبيقات مثل التعرف على الكائنات في الصور وتحليل المواقف المختلفة في مقاطع الفيديو.
التجريب باستخدام نماذج اللّغة الكبيرة [1]
بالنسبة لأولئك المهتمّين باستكشاف قدرات نماذج اللّغة الكبيرة بشكل مباشر، هناك العديد من المنصات والنماذج التي يمكن الوصول إليها أشهرها:
- GPT-3.5 من OpenAI: توفر OpenAI إمكانية الوصول إلى إصدارات مختلفة من نماذج جي بي تي GPT الخاصة بها، بما في ذلك جي بي تي-4 GPT-4، والتي يمكن تجربتها من خلال واجهة برمجة التّطبيقات الخاصة بها. يمكن للمستخدمين التّسجيل على منصة OpenAI (مثل chat.openai.com) لبناء التّطبيقات أو ببساطة التفاعل مع الموذج لفهم قدراته في توليد النّص أو الإجابة على الأسئلة أو حتى الترميز.
- النّماذج المفتوحة من Hugging Face: تستضيف Hugging Face، وهي مركز شائع لنماذج الذّكاء الاصطناعي، مجموعة كبيرة من النّماذج مفتوحة المصدر. يمكن للمطوّرين استخدام هذه النّماذج لمجموعة واسعة من المهام مثل إنشاء النصوص وتحليل المشاعر والمزيد. بفضل واجهتها سهلة الاستخدام تُمكّن المبتدئين البدء في التّجربة على الفور.
التحدّيات والاعتبارات الأخلاقيّة [1]
على الرغم من قدراتها الرائعة، فإن نماذج اللّغة الكبيرة تواجه تحدّيات واعتبارات أخلاقيّة:يجب التعامل معها بعناية لضمان استخدامها بشكل مسؤول أهمها:
- التحيز والإنصاف:
- التدريب على بيانات متحيزة: نظرًا لأن نماذج اللّغة الكبيرة تعتمد في تدريبها على مجموعات ضخمة من البيانات التي تم إنشاؤها من قبل البشر، فهي عرضة لعكس التحيزات الاجتماعية والثقافية والسياسية الموجودة في هذه البيانات. على سبيل المثال، يمكن للنماذج توليد محتوى يعزز التمييز على أساس الجنس أو العرق أو الدين دون قصد. هذه التحيزات قد تكون ضارة إذا لم يتم التعامل معها بشكل صحيح.
- التضليل والإساءة:
- توليد الأخبار الكاذبة: يمكن استخدام نماذج اللّغة الكبيرة لإنشاء نصوص تبدو واقعية ومقنعة، مما يسهل انتشار الأخبار الكاذبة والمعلومات المضللة. قد يُستخدم ذلك في التأثير على الرأي العام أو التلاعب بالانتخابات أو نشر نظريات المؤامرة.
- الإساءة في المحتوى: يمكن استخدام هذه النماذج بشكل سيء لتوليد محتوى غير لائق، كخطاب الكراهية أو الترويج للعنف، مما يشكل خطرًا على الأفراد والمجتمعات. يجب على الشركات التي تطور هذه النماذج وضع ضوابط صارمة للحد من هذه الاستخدامات الضارة.
تتطلب هذه التحديات الأخلاقية اهتمامًا كبيرًا من الباحثين، المطورين، والمجتمع ككل، لضمان أن استخدام نماذج اللغة الكبيرة يتم بطريقة تخدم البشرية وتعزز الإنصاف والشفافية في جميع التطبيقات.


تعليق واحد