
المقدمة
تتضمن مهمة اكتشاف الأغراض في مجال الرؤية الحاسوبية تحديد وجود غرض أو أكثر في صورة معيّنة مع تحديد موقعه ونوعه. وهي من المشاكل الصعبة التي تنطوي على الاستفادة من أساليب التعرف على الأغراض ( أين هي) ومكانها (ما هو موقعها) و تصنيفها (ما هي). تحقق خوارزميات الكشف في السنوات الأخيرة نتائج جديدة منها خوارزمية يولو YOLO التي طورها جوزيف ريدمون وآخرون عام 2015. وهي عبارة عن شبكة طي عصبونية Convolution Neural Network CNN قادرة على اكتشاف أغراض متعددة في الزمن الحقيقي بمرور واحد فقط لذلك سميت بهذا الاسم أنت تنظر مرة واحدة فقط “You Look Only Once”.
سنقوم في هذه التدوينة بتطبيق الإصدار الثالث من خوارزمية يولو YOLOv3 مفتوحة المصدر باستخدام كيراس Keras.
المحتويات
- خوارزمية يولو للكشف عن الأغراض.
- مخزن الشيفرة البرمجية لكيراس الإصدار 3 من يولو .
- استخدام الإصدار 3 من يولو للكشف عن الأغراض.
- إنشاء وحفظ نموذج يولو 3.
- عملية التنبؤ.
- تفسير النتائج.
خوارزمية يولو للكشف عن الأغراض
تستخدم خوارزمية يولو شبكة طيّ عصبونية لتقسيم الدخل إلى شبكة من الخلايا تتنبأ كلٍ منها بشكل مباشر بمربع الإحاطة وتصنيف الغرض. النتيجة ستكون عدد كبير من المربعات المرشحة التي يتم دمجها في التنبؤ النهائي بخطوة ما بعد المعالجة.
هناك ثلاثة إصدارات لهذه الخوارزمية. اقترح يولو الإصدار 1 – YOLOv1 البنية العامة بينما قام يوليو الإصدار 2 – YOLOv2 بتحسين التصميم والاستفادة من مربعات الارتكاز anchor boxes المحددة مسبقًا لتحسين مربع الإحاطة المقترح أما يوليو الإصدار 3 – YOLOv3 فقد حسنّ بنية النموذج وعملية التدريب.
على الرغم من أن نتائج هذه الخوارزمية دقيقة إلا أن شبكات الطي العصبونية المناطقية convolutional neural network region R-CNNs تعطي نتائج أدق. لكن تعتبر يولو شائعة الاستخدام لسرعتها فهي تعرض النتائج في الزمن الحقيقي. سنركز في هذه المدونة على الإصدار الثالث منها.
مخزن الشيفرة البرمجية لكيراس يولو الإصدار الثالث
يعتبر نموذج يولو صعب التنفيذ من الصفر وخاصة للمبتدئين كونه يتطلب تطوير العديد من عناصر النماذج المخصصة للتدريب والتنبؤ. على سبيل المثال عند استخدام نموذج مدرب مسبقًا يتطلب كتابة كتلة معقدة من الشيفرة البرمجية لترشيح وتفسير مربعات الإحاطة الناتجة من النموذج. لذلك قدمت داركنت مخزن على الجيت هب يدعى DarkNet GitHub يضم الشيفرات البرمجية لجميع اصدارات يولو مكتوبة بلغة السي C. مع المراجع الضرورية لكيفية استخدام هذه الشيفرات في الكشف عن الأغراض. بالتالي يمكن الاعتماد على أحد المشاريع التالية الموجودة في المخزن التي سهلت استخدام يولو بشكل كبير.
- مشروع كيراس-داركنت YAD2K Yet Another Darknet 2 Keras: يعتبر المعيار المعتمد ليولو الإصدار2 فقد وفر برامج نصية لتحويل الأوزان المدربة سابقًا إلى نسق كيراس واستخدم النموذج المدرب مسبقًا للقيام بالتنبؤ. وقدم أيضًا الشيفرة البرمجية المطلوبة لترشيح مربعات الإحاطة. اعتبرت العديد من تطبيقات الطرف الثالث هذه الشيفرة البرمجية كنقطة بداية وطوروها لتدعم يولو الإصدار 3.
- مشروع كيراس-يولو2 keras-yolo2: الذي يوفر شيفرة برمجية مشابهة ل YOLOv2 بالإضافة إلى شرح مفصل لكيفية استخدامها.
- مشروع كيراس-يولو3 keras-yolo3 : المشروع الأكثر شيوعا لتدريب وكشف الاغراض باستخدام نماذج يولو المدربة مسبقًا وقد تم توفير الشيفرة البرمجية الموجودة في المشروع بموجب ترخيص مفتوح المصدر لمعهد ماساتشوستس للتكنولوجيا MIT . وهو ما سنعتمده في هذه المدونة.
استخدام يولو الإصدار الثالث للكشف عن الأغراض
سنستخدم نموذج مدرب مسبقًا موجود ضمن ملف بايثون يدعى ” yolo3_one_file_to_detect_them_all.py” من مشروع كيراس-يولو3 keras-yolo3 لأداء عملية الكشف عن الأغراض. يحتوي هذا الملف على حوالي 435 سطرًا، يستخدم الأوزان المدربة مسبقًا لإعداد نموذج واستخدامه في عملية الكشف وإخراج نموذج آخر. وهو يعتمد أيضًا على المكتبة المفتوحة للرؤية الحاسوبية أوبن سيفي OpenCV.
سنقوم فيما يلي بإعادة استخدام عناصر من هذا الملف والتعديل عليها لإعداد نموذج كيراس-يولو 3 “Keras YOLOv3” وحفظه ثم تحميله للقيام بعملية التنبؤ على صورة جديدة ومن ثم تفسير نتائج عملية التنبؤ وأخيرًا عرض النتائج.
إنشاء وحفظ النموذج
تتضمن هذه المرحلة مجموعة من الخطوات:
- تحميل الأوزان التي تم تدريبها مسبقًا باستخدام الشيفرة البرمجية الأساسية لدارك نت على قاعدة بيانات مايكروسوفت كوكو MSCOC ووضعها في مسار العمل الحالي باسم “yolov3.weights.” يبلغ حجم هذه الأوزان 237 ميغا بايت لذلك سيتطلب تحميلها بعض الوقت.
- تحديد نموذج كيراس الذي يضم عدد ونوع طبقات موافق لأوزان النموذج التي قمنا بتحميلها. هذا النموذج هو دارك نت “DarkNet” والذي يعتمد بالأساس على نموذج مجموعة الهندسة البصرية Visual Geometry Group “VGG-16”.
- استدعاء التابع make_yolov3_model() الموجود في ملف بايثون “yolo3_one_file_to_detect_them” لإنشاء النموذج وتابع آخرمساعد يدعى function _conv_block() لبناء كتل الطبقات.
- تحميل نموذج الأوزان المخزن بالشكل الذي اختارته دارك نت. وفك تشفيره وتحميل الأوزان إلى الذاكرة بتنسيق يمكن استخدامه في نموذج كيراس وذلك باستخدام WeightReader من الصف WeightReader وتمرير النموذج له لتعيين الأوزان في الطبقات.
- سنقوم بحفظ نموذج الإصدار 3 من يولو الجاهز للاستخدام في ملف من نوع H5 ليتوافق مع كيراس.
فيما يلي الشيفرة البرمجية الكاملة لجميع الخطوات السابقة متضمنة توابع منسوخة تمامًا كما هي من ملف بايثون المذكور سابقًا.
#create a YOLOv3 Keras model and save it to file
# based on https://github.com/experiencor/keras-yolo3
import struct
import numpy as np
from keras.layers import Conv2D
from keras.layers import Input
from keras.layers import BatchNormalization
from keras.layers import LeakyReLU
from keras.layers import ZeroPadding2D
from keras.layers import UpSampling2D
from keras.layers.merge import add, concatenate
from keras.models import Model
def _conv_block(inp, convs, skip=True):
x = inp
count = 0
for conv in convs:
if count == (len(convs) - 2) and skip:
skip_connection = x
count += 1
if conv['stride'] > 1: x = ZeroPadding2D(((1,0),(1,0)))(x) # peculiar padding as darknet prefer left and top
x = Conv2D(conv['filter'],
conv['kernel'],
strides=conv['stride'],
padding='valid' if conv['stride'] > 1 else 'same', # peculiar padding as darknet prefer left and top
name='conv_' + str(conv['layer_idx']),
use_bias=False if conv['bnorm'] else True)(x)
if conv['bnorm']: x = BatchNormalization(epsilon=0.001, name='bnorm_' + str(conv['layer_idx']))(x)
if conv['leaky']: x = LeakyReLU(alpha=0.1, name='leaky_' + str(conv['layer_idx']))(x)
return add([skip_connection, x]) if skip else x
def make_yolov3_model():
input_image = Input(shape=(None, None, 3))
# Layer 0 => 4
x = _conv_block(input_image, [{'filter': 32, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 0},
{'filter': 64, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 1},
{'filter': 32, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 2},
{'filter': 64, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 3}])
# Layer 5 => 8
x = _conv_block(x, [{'filter': 128, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 5},
{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 6},
{'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 7}])
# Layer 9 => 11
x = _conv_block(x, [{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 9},
{'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 10}])
# Layer 12 => 15
x = _conv_block(x, [{'filter': 256, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 12},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 13},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 14}])
# Layer 16 => 36
for i in range(7):
x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 16+i*3},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 17+i*3}])
skip_36 = x
# Layer 37 => 40
x = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 37},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 38},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 39}])
# Layer 41 => 61
for i in range(7):
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 41+i*3},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 42+i*3}])
skip_61 = x
# Layer 62 => 65
x = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 62},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 63},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 64}])
# Layer 66 => 74
for i in range(3):
x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 66+i*3},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 67+i*3}])
# Layer 75 => 79
x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 75},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 76},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 77},
{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 78},
{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 79}], skip=False)
# Layer 80 => 82
yolo_82 = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 80},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 81}], skip=False)
# Layer 83 => 86
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 84}], skip=False)
x = UpSampling2D(2)(x)
x = concatenate([x, skip_61])
# Layer 87 => 91
x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 87},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 88},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 89},
{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 90},
{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 91}], skip=False)
# Layer 92 => 94
yolo_94 = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 92},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 93}], skip=False)
# Layer 95 => 98
x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 96}], skip=False)
x = UpSampling2D(2)(x)
x = concatenate([x, skip_36])
# Layer 99 => 106
yolo_106 = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 99},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 100},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 101},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 102},
{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 103},
{'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 104},
{'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 105}], skip=False)
model = Model(input_image, [yolo_82, yolo_94, yolo_106])
return model
class WeightReader:
def __init__(self, weight_file):
with open(weight_file, 'rb') as w_f:
major, = struct.unpack('i', w_f.read(4))
minor, = struct.unpack('i', w_f.read(4))
revision, = struct.unpack('i', w_f.read(4))
if (major*10 + minor) >= 2 and major < 1000 and minor < 1000:
w_f.read(8)
else:
w_f.read(4)
transpose = (major > 1000) or (minor > 1000)
binary = w_f.read()
self.offset = 0
self.all_weights = np.frombuffer(binary, dtype='float32')
def read_bytes(self, size):
self.offset = self.offset + size
return self.all_weights[self.offset-size:self.offset]
def load_weights(self, model):
for i in range(106):
try:
conv_layer = model.get_layer('conv_' + str(i))
print("loading weights of convolution #" + str(i))
if i not in [81, 93, 105]:
norm_layer = model.get_layer('bnorm_' + str(i))
size = np.prod(norm_layer.get_weights()[0].shape)
beta = self.read_bytes(size) # bias
gamma = self.read_bytes(size) # scale
mean = self.read_bytes(size) # mean
var = self.read_bytes(size) # variance
weights = norm_layer.set_weights([gamma, beta, mean, var])
if len(conv_layer.get_weights()) > 1:
bias = self.read_bytes(np.prod(conv_layer.get_weights()[1].shape))
kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape))
kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))
kernel = kernel.transpose([2,3,1,0])
conv_layer.set_weights([kernel, bias])
else:
kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape))
kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))
kernel = kernel.transpose([2,3,1,0])
conv_layer.set_weights([kernel])
except ValueError:
print("no convolution #" + str(i))
def reset(self):
self.offset = 0
# define the model
model = make_yolov3_model()
# load the model weights
weight_reader = WeightReader('yolov3.weights')
# set the model weights into the model
weight_reader.load_weights(model)
# save the model to file
model.save('model.h5')
قد يستغرق تنفيذ الشيفرة البرمجية السابقة أقل من دقيقة واحدة على الأجهزة الحديثة. أثناء تحميل ملف الأوزان، سنرى معلومات الخرج للصف WeightReader حول ما تم تحميله على الشكل التالي.
loading weights of convolution #99
loading weights of convolution #100
loading weights of convolution #101
loading weights of convolution #102
loading weights of convolution #103
loading weights of convolution #104
loading weights of convolution #105
في نهاية التنفيذ، يتم حفظ الملف model.h5 في مسار العمل الحالي بنفس حجم ملف الوزن الأصلي تقريبًا (237 ميجابايت)، لكن جاهز للتحميل واستخدامه مباشرة كنموذج كيراس Keras.
عملية التنبؤ
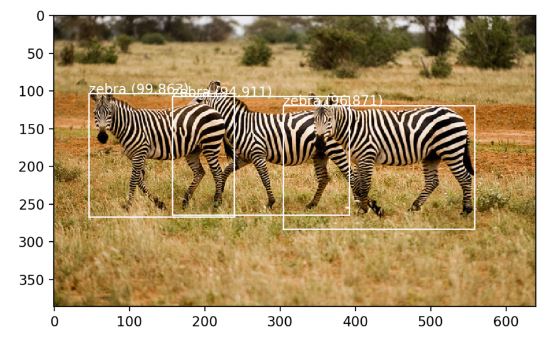
- اختيار صورة جديدة بحيث تكون الأغراض الموجودة فيها معلومة سابقا لدى النموذج وذلك في قاعدة بيانات مايكروسوفت كوكو. سنختار صورة تحتوي على ثلاثة من الحمر الوحشية تم التقاطها من قبل بوغ Boegh كما في الشكل(1). سنقوم بتحميلها ووضعها في مسار العمل الحالي تحت اسم “zebra.jpg”.

- تحميل نموذج كيراس وقد تكون الخطوة الأبطأ في هذه المرحلة.
- تحميل الصورة باستخدام تابع كيراس load_img() و تغيير حجمها وذلك لأن النموذج يتوقع الدخل صورة ملونة مربعة بأبعاد 416×416 بيكسل.
- استخدام التابع img_to_array() لتحويل الصورة من نمط بايثون للصور Python Imaging Library (PIL) إلى مصفوفة بايثون العددية NumPy.
- تقييس قيم البيكسلات من 0-255 إلى 0- 1 باستخدام 32 بت لقيم النقطة العائمة.
- سنحتاج لإعادة اظهار الصورة الأصلية وذلك يعني أننا بحاجة لتقييس مربعات الإحاطة لجميع الأغراض المكتشفة من الشكل المربعي للعودة للشكل الأصلي.
سنقوم بكتابة وباستدعاء التابع load_image_pixels () لتحميل وتجهيز الصورة لتلائم دخل نموذج كيراس ومن ثم تمرير الخرج للتابع model.predict لتبدأ عملية التنبؤ وذلك كما يلي.
# load yolov3 model and perform object detection
# based on https://github.com/experiencor/keras-yolo3
from numpy import expand_dims
from keras.models import load_model
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
# load and prepare an image
def load_image_pixels(filename, shape):
# load the image to get its shape
image = load_img(filename)
width, height = image.size
# load the image with the required size
image = load_img(filename, target_size=shape)
# convert to numpy array
image = img_to_array(image)
# scale pixel values to [0, 1]
image = image.astype('float32')
image /= 255.0
# add a dimension so that we have one sample
image = expand_dims(image, 0)
return image, width, height
# load yolov3 model
model = load_model('model.h5')
# define the expected input shape for the model
input_w, input_h = 416, 416
# define our new photo
photo_filename = 'zebra.jpg'
# load and prepare image
image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h))
# make prediction
yhat = model.predict(image)
# summarize the shape of the list of arrays
print([a.shape for a in yhat])
بتنفيذ الشيفرة البرمجية السابقة سيكون الخرج ثلاثة من مصفوفات بايثون العددية. تتنبأ هذه المصفوفات بمربعات الإحاطة مع التسميات لكنها مشفرة لذلك سنقوم بالمرحلة التالية بعملية تفسير أو فك تشفير ما تم التنبؤ به.
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
تفسير النتائج
حصلنا من عملية التنبؤ على مجموعة مربعات الإحاطة المرشحة من ثلاثة أحجام مختلفة للشبكة المحددة بالاعتماد على مربعات الارتكاز التي تم اختيارها بناءًا على تفسير حجم الغرض في قاعدة بيانات مايكروسوفت كوكو.ولكن بشكل مشفر لذلك سنفك تشفير هذه النتائج ونفسرها بالخطوات التالية.
- فك تشفير مربعات الإحاطة المرشحة وتنبؤات الصنف. ليتم فيما بعد تجاهل أي من هذه المربعات التي لا تصف الغرض بالشكل الدقيق (عندما تكون جميع احتمالات الصنف لهذا الغرض أقل من القيمة المعيارية المحددة Threshold والتي سنحددها هنا بـ 60% هي 0.6). وللقيام بذلك سنستدعي التابع decode_netout() ليعيد instances – BoundBox التي تحدد زوايا كل مربع إحاطة موجود في الصورة المدخلة مع احتمالات الصنف.
الشيفرة البرمجية لهذه الخطوة مع نصوص لتوابع منسوخة كما هي من المخزن على الشكل التالي:
class BoundBox:
def __init__(self, xmin, ymin, xmax, ymax, objness = None, classes = None):
self.xmin = xmin
self.ymin = ymin
self.xmax = xmax
self.ymax = ymax
self.objness = objness
self.classes = classes
self.label = -1
self.score = -1
def get_label(self):
if self.label == -1:
self.label = np.argmax(self.classes)
return self.label
def get_score(self):
if self.score == -1:
self.score = self.classes[self.get_label()]
return self.score
def _sigmoid(x):
return 1. / (1. + np.exp(-x))
# summarize the shape of the list of arrays
# define the anchors
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
# define the probability threshold for detected objects
class_threshold = 0.6
boxes = list()
def decode_netout(netout, anchors, obj_thresh, net_h, net_w):
grid_h, grid_w = netout.shape[:2]
nb_box = 3
netout = netout.reshape((grid_h, grid_w, nb_box, -1))
nb_class = netout.shape[-1] - 5
boxes = []
netout[..., :2] = _sigmoid(netout[..., :2])
netout[..., 4:] = _sigmoid(netout[..., 4:])
netout[..., 5:] = netout[..., 4][..., np.newaxis] * netout[..., 5:]
netout[..., 5:] *= netout[..., 5:] > obj_thresh
for i in range(grid_h*grid_w):
row = i / grid_w
col = i % grid_w
for b in range(nb_box):
# 4th element is objectness score
objectness = netout[int(row)][int(col)][b][4]
if(objectness.all() <= obj_thresh): continue
# first 4 elements are x, y, w, and h
x, y, w, h = netout[int(row)][int(col)][b][:4]
x = (col + x) / grid_w # center position, unit: image width
y = (row + y) / grid_h # center position, unit: image height
w = anchors[2 * b + 0] * np.exp(w) / net_w # unit: image width
h = anchors[2 * b + 1] * np.exp(h) / net_h # unit: image height
# last elements are class probabilities
classes = netout[int(row)][col][b][5:]
box = BoundBox(x-w/2, y-h/2, x+w/2, y+h/2, objectness, classes)
boxes.append(box)
return boxes
for i in range(len(yhat)):
# decode the output of the network
boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w)
print('Number of Objects',len(boxes))
for i in range(len(boxes)):
print(boxes[i].xmin,boxes[i].xmax,boxes[i].ymin,boxes[i].ymax)
for i in range(len(boxes)):
print(boxes[i].classes)
بتنفيذ ما سبق سنحصل على أبعاد مربعات الإحاطة بعد فك تشفيرها:

أما التصنيفات لجميع مربعات الإحاطة فهي متماثلة كمايلي:

تمديد مربعات الإحاطة لرسمها على الصورة الأصلية باستخدام التابع correct_yolo_boxes() حيث سنمرر له قائمة مربعات الإحاطة مع أبعاد الصورة الأصلية والمعدّلة كمايلي:
def correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w):
new_w, new_h = net_w, net_h
for i in range(len(boxes)):
x_offset, x_scale = (net_w - new_w)/2./net_w, float(new_w)/net_w
y_offset, y_scale = (net_h - new_h)/2./net_h, float(new_h)/net_h
boxes[i].xmin = int((boxes[i].xmin - x_offset) / x_scale * image_w)
boxes[i].xmax = int((boxes[i].xmax - x_offset) / x_scale * image_w)
boxes[i].ymin = int((boxes[i].ymin - y_offset) / y_scale * image_h)
boxes[i].ymax = int((boxes[i].ymax - y_offset) / y_scale * image_h)
# correct the sizes of the bounding boxes for the shape of the image
correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w)
print('Number of Objects',len(boxes))
for i in range(len(boxes)):
print(boxes[i].xmin,boxes[i].xmax,boxes[i].ymin,boxes[i].ymax)
أبعاد مربعات الإحاطة بعد التمديد، ستكون كما يلي:
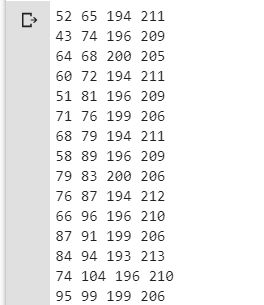
ترشيح ودمج المربعات المتداخلة والتي تشير جميعها لنفس الغرض بعملية تدعى (كبت الحد اللا النهائي) non-maximal suppression من خلال استدعاء التابع do_nms() وتحديد معامل التداخل بـ 0.5% أو 50 ليقوم هذا التابع بتنبؤ احتمالية التداخل بدلًأ من حذف المربعات المتداخلة ليسمح في استخدامها في اكتشاف نوع غرض آخر.ستحافظ هذه العملية على عدد المربعات ولكن البعض بأهمية أقل. الشيفرة البرمجية لهذه المرحلة تتضمن نصوص لتوابع منسوخة كما هي من المخزن وذلك كما يلي:
def _interval_overlap(interval_a, interval_b):
x1, x2 = interval_a
x3, x4 = interval_b
if x3 < x1:
if x4 < x1:
return 0
else:
return min(x2,x4) - x1
else:
if x2 < x3:
return 0
else:
return min(x2,x4) - x3
def bbox_iou(box1, box2):
intersect_w = _interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax])
intersect_h = _interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax])
intersect = intersect_w * intersect_h
w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin
w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin
union = w1*h1 + w2*h2 - intersect
return float(intersect) / union
def do_nms(boxes, nms_thresh):
if len(boxes) > 0:
nb_class = len(boxes[0].classes)
else:
return
for c in range(nb_class):
sorted_indices = np.argsort([-box.classes[c] for box in boxes])
for i in range(len(sorted_indices)):
index_i = sorted_indices[i]
if boxes[index_i].classes[c] == 0: continue
for j in range(i+1, len(sorted_indices)):
index_j = sorted_indices[j]
if bbox_iou(boxes[index_i], boxes[index_j]) >= nms_thresh:
boxes[index_j].classes[c] = 0
# suppress non-maximal boxes
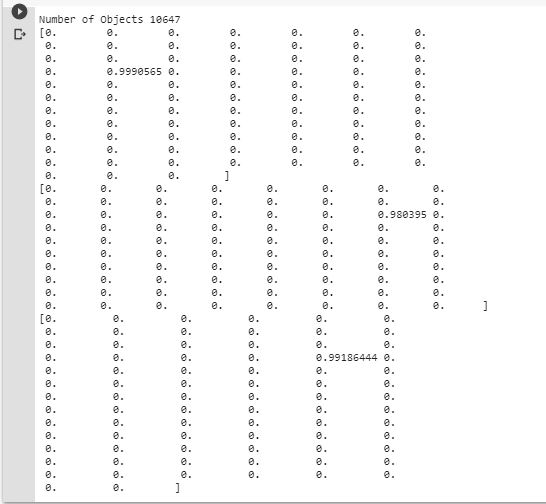
do_nms(boxes, 0.5)
print('Number of Objects',len(boxes))
for i in range(len(boxes)):
if boxes[i].classes.any() != 0:
print(boxes[i].classes)
الخرج سيكون نفس عدد مربعات الإحاطة السابقة لكن باختلاف قيم الصنف لثلاثة منها كما هو موضح في الشكل التالي:
- استرداد مجموعة المحارف التي تضم تسميات الصنف في الترتيب والشكل الصحيح المستخدم أثناء التدريب وخاصة تلك التسميات المأخوذة من قاعدة بيانات مايكروسوفت كوكو ولحسن الحظ هي متوفرة في مخزن اكسبيرين-كور experiencor.
- المرور على جميع المربعات والتحقق من قيم التنبؤ للصنف وارجاع فقط المربعات التي لها احتمالية تنبؤ أكبر من 60% وذلك بكتابة التابع get_boxes() و تمرير المربعات والتسميات المعرفة و معامل التداخل. ثم البدء بعملية البحث عن تسمية للصنف المقابل للمربع و إضافته للقائمة. معيدا بذلك قائمة المربعات النهائية مع التسميات والاحتمالات المقابلة لها ومن ثم القيام بطباعة ما تم استرداده من التابع.
# get all of the results above a threshold
def get_boxes(boxes, labels, thresh):
v_boxes, v_labels, v_scores = list(), list(), list()
# enumerate all boxes
for box in boxes:
# enumerate all possible labels
for i in range(len(labels)):
# check if the threshold for this label is high enough
if box.classes[i] > thresh:
v_boxes.append(box)
v_labels.append(labels[i])
v_scores.append(box.classes[i]*100)
# don't break, many labels may trigger for one box
return v_boxes, v_labels, v_scores
# define the labels
labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck",
"boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench",
"bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe",
"backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard",
"sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana",
"apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake",
"chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator",
"book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"]
# get the details of the detected objects
v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold)
# summarize what we found
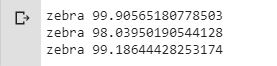
for i in range(len(v_boxes)):
print(v_labels[i], v_scores[i])
بتنفيذ الشيفرة البرمجية السابقة سنجد أنه تم الكشف عن وجود ثلاثة من الحمير الوحشية بدرجات تنبؤ أكبر من 90%
رسم الصورة الأصلية ومربعات الإحاطة حول الأغراض المكتشفة من خلال الحصول على احداثياتها و أيضًأ إضافة التسميات ودرجة التنبؤ. وذلك بكتابة التابع draw_boxes() واستدعاؤه.
def draw_boxes(filename, v_boxes, v_labels, v_scores):
# load the image
data = pyplot.imread(filename)
# plot the image
pyplot.imshow(data)
# get the context for drawing boxes
ax = pyplot.gca()
# plot each box
for i in range(len(v_boxes)):
box = v_boxes[i]
# get coordinates
y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax
# calculate width and height of the box
width, height = x2 - x1, y2 - y1
# create the shape
rect = Rectangle((x1, y1), width, height, fill=False, color='white')
# draw the box
ax.add_patch(rect)
# draw text and score in top left corner
label = "%s (%.3f)" % (v_labels[i], v_scores[i])
pyplot.text(x1, y1, label, color='white')
# show the plot
pyplot.show()
# draw what we found
draw_boxes(photo_filename, v_boxes, v_labels, v_scores)
النتيجة ستكون رسم الصورة ومربعات الإحاطة الثلاثة. بهذا نكون قد حصلنا على جميع العناصر المطلوبة للقيام بالتنبؤ باستخدام نموذج ايولو الإصدار الثالث مع تفسير وعرض النتائج. وفي الشكل (2) نرى أن النموذج قد اكتشف بالفعل ثلاثة حمير وحشية.
الخاتمة
تعرفنا في هذه المدونة على الخطوات اللازمة لكشف الأغراض في الصور الجديدة من خلال تطبيق الإصدار الثالث من خوارزمية يولو ضمن كيراس. وذلك انطلاقًا من اختيار الصورة إلى اختيار نموذج كيراس ومن ثم البدء بعملية التنبؤ وأخيرًا تفسير النتائج لنحصل في النهاية على الصورة المختارة محدد عليها مربعات الإحاطة النهائية مرفقة بالتسمية ودرجة قوة التنبؤ.





4 تعليقات
هل يمكن استخدماها في مقاطع الفيديو الحية او يقتصر استخدامها على الصور ؟
اهلا..
ايوا يمكن استخدامها في الreal_time اي يمكن تطبيقها للكشف عن الأغراض في مقاطع الفيديو .
اهلا..
ايوا يمكن استخدامها في الreal_time اي يمكن تطبيقها للكشف عن الأغراض في مقاطع الفيديو .