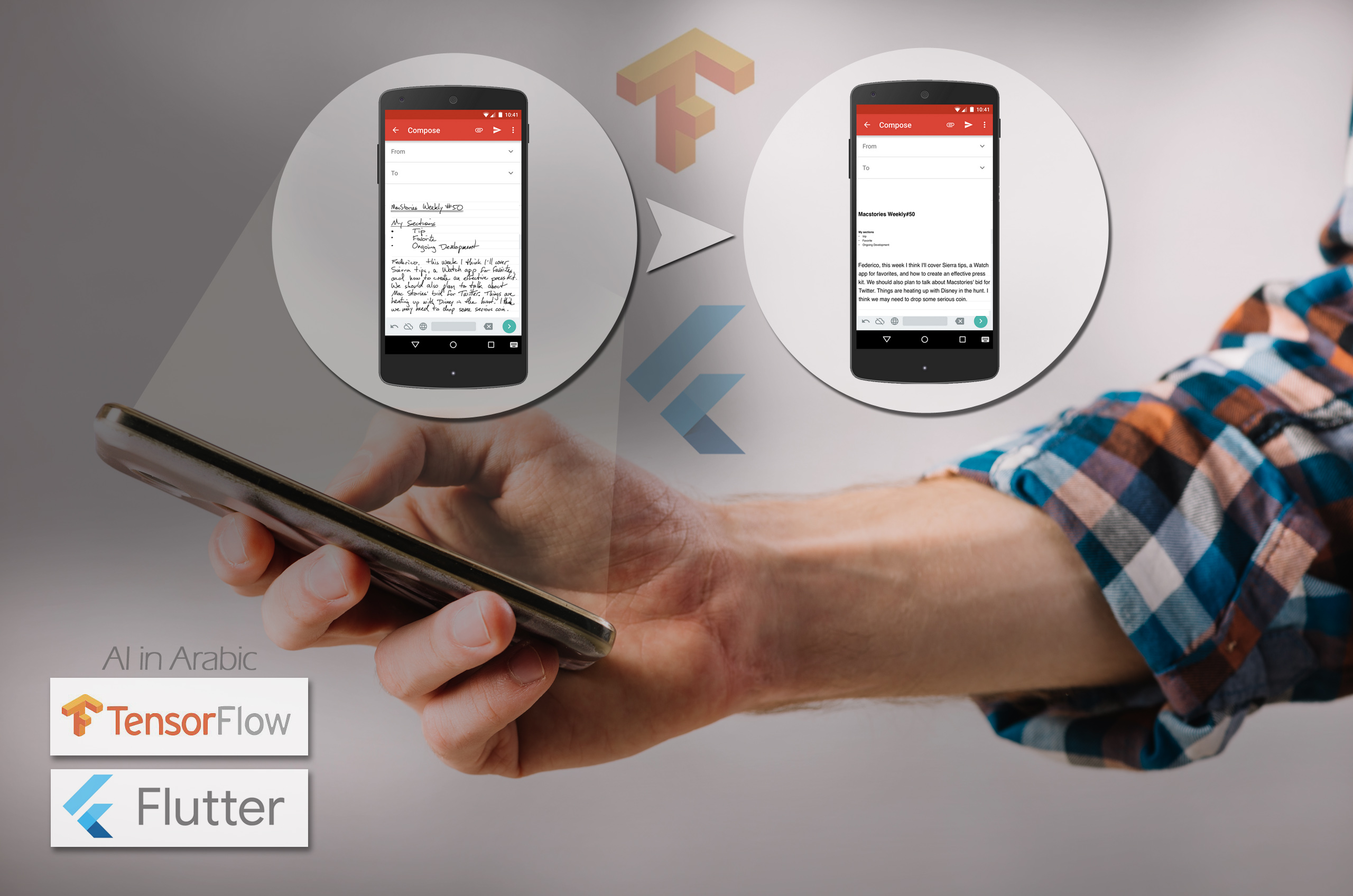
هنالك تداخل لطيف بين تعلَم الآلة وتطوير الواجهات Front-End . وإنه لمن الممتع اكتساب المهارة في كلا المجالين ورؤية ما يمكن أن يفعلا معاً. هدف هذا المقال (مع بقية أجزاءه) مساعدتك على إنشاء نموذج بلغة الآلة وكيفية تطبيق هذا النموذج على تطبيق فلاتر Flutter (فلاتر هو حزمة تطوير تطبيقات الهواتف الذكية، يسمح لك بكتابة تطبيق في قاعدة بيانات واحدة وتترجم لكل من أنظمة التشغيل أندرويد Android و نظام تشغيل آي فون IOS . يعتبر فلاتر إطار عمل حسب التعريف الرسمي لإطار العمل من ويكيبيديا [1] )
المحتويات
ماذا سوف نقوم ببنائه؟
سنقوم ببناء معرف للأرقام المكتوبة بخط اليد باستخدام فلاتر على جهازك المحمول. بعد اتباعك لهذا الجزء والأجزاء القادمة، سيكون التطبيق النهائي بالشكل التالي:
خطوات العمل ستكون مقسمة إلى عدة مراحل (مقالات). بعض الأعمال التي سوف ننجزها:
- إنشاء نموذج باستخدام مكتبة تنسورفلو Tensorflow (وهي مكتبة مفتوحة المصدر للحساب الرقمي وتعلم الآلة على نطاق واسع. يجمع مجموعة من نماذج تعلم الآلة والتعليم العميق (المسمى أيضاً بالشبكات العصبونية) والخوارزميات التي تسهل عملية الحصول على البيانات ونماذج التدريب وتخدم التنبؤات وتساعد في تحسين النتائج المستقبلية [2]).
- إنشاء تطبيق فلاتر باستخدام النموذج السابق وواجهة للرسم على الشاشة بالإصبع.
- معالجة الرسم (الرقم المكتوب بالإصبع) وتحويله إلى صورة رقمية يمكن اعتبارها دخل للنموذج المنشأ.
سأقوم أيضاً بذكر بعض المصاعب التي قد تواجهنا عند ادخال قيم حقيقية إلى النموذج.
أما الآن، سنركز فقط على إنشاء نموذج بالاعتماد على مكتبة تنسورفلو Tensorflow وتصديره إلى (Tensorflow Lite) تنسورفلو المُخفف لاستخدامه على أجهزتنا الخلوية.
أحب أن أنوه أنك تستطيع عزيزي القارئ مشاهدة الكود كاملاً في نهاية كل مقال.
هيا لنبدأ..
كما ذكرت سابقاً، سنركز على إنشاء نموذج صغير باستخدام مكتبة تنسورفلو وتصديره.
لا تقلق في حال لم تكن لديك معرفة سابقة بلغة بايثون أو بتعلم الألة، إن هذه الأجزاء كافية لتعلم ما الذي يحدث.
قبل الخوض في هذه التجربة يجب أن أنوه أن هنالك طريقتين لكتابة وتنفيذ الكود:
– الأولى: عن طريق جهازك المحلي المزود بالبايثون.
– الثانية: عن طريق استخدام منصة جوبيتور Jupiter NoteBook.
نصيحتي لكم إذا لم تكن لديك معرفة تامة ببايثون ونظام إدارة الحزم الخاص به (بيب pip) فيستحسن استخدام منصة جوبيتور لتجنب المخاطرة بجهازك المحلي وتشويش اعداداته.
لتشغيله محلياً..
للتشغيل المحلي، يجب أن يكون بايثون مثبت على جهاز الحاسوب لديك بالإضافة إلى مكتبة تنسورفلو، في حال لم يكن لديك مكتبة تنسورفلو يمكنك اتباع التعليمات لتثبيته من هنا. قبل تثبيته ينصح باستخدام بيئة افتراضية معزولة عن بيئة العمل الأساسية للحد من الأخطاء التي يمكن أن تواجهنا أثناء العمل. إذا لم تكن تريد قراءة المستند بالكامل، لا تقلق، كل ما ستحتاجه لتثبيته هي الأسطر التالية:
# For python 2
pip install tensorflow
# For python 3
pip3 install tensorflow
لتشغيله عبر منصة جوبيتور
يمكنك استخدام المفكرة، ومن ثم تشغيل البايثون من خلال المتصفح الذي بدوره يتصل بالمخدم. إن هذه المنصة مفيدة جداً، فهي تساعد على تحميل أجزاء من الكود دون الحاجة لتشغيله بشكل كامل مرة أخرى. يوجد بعض الخيارات الأخرى يمكنك العمل عليها، مثل: كولاب Colab من شركة جوجل، و منصة آزور Azure Notebook من شركة مايكروسوفت. هذه الخيارات طبعاً مجانية وتساعد عملية التدريب على التنفيذ بسرعة أكبر على الجهاز.
إذا قمت باختيار العمل على المفكرة فلن تحتاج إلى تثبيت مكتبة تنسورفلو، ففي هذه الحالة يمكنك تخطي بعض الخطوات التالية حتى استدعاء النموذج.
بنية المشروع
بعد إتمام كافة الخطوات السابقة، سنقوم أولاً بإنشاء مجلد خاص بالمشروع من أجل نموذج تعلم الآلة البسيط الخاص بنا، سأعتمد الصيغة التالية:
your_project_directory/
> models/
> numbers_mnist.py
في الوقت الحالي، سيكون مجلد models فارغاً، قمنا فقط بإنشائه وسيتم حفظ النماذج فيه لاحقاً. تأكد من وجوده من البداية 😉
كتابة نموذج تعلم الألة الخاص بنا
استيراد مكتبة تنسورفلو:
يمكنك فتح الملف numbers_mnist.py باستخدام أي محرر تفضله، وتبدأ باستيراد مكتبة تنسورفلو. في حال كنت تستخدم المفكرة، سيكون عليك إضافة التعليمة التالية لاستيراد المكتبة المطلوبة.
import tensorflow as tf
تحميل مجموعة البيانات
هنالك مجموعة من البيانات تأتي ضمن مكتبة تنسورفلو فلا داعي لتحميلهن أو معالجتهن، مما يسهل هذه المهمة ويسرعها. يمكننا تحميل مجموعة بيانات إم نيست MNIST بالشكل التالي:
mnist = tf.keras.datasets.mnist
تحوي مجموعة بيانات إم نيست MNIST بشكل أساسي على مجموعة من الصور، كل صورة تحتوي على عدد ما (من 0 إلى 9) مكتوبة بخط اليد ( يمكنك التعرف عليها أكثر من هنا )، إن أهم النقاط التي نحتاج إلى معرفتها هي:
- تؤلف هذه المجوعة، مجموعة من الصور ذات بُعد 28×28 بكسل.
- العدد موجود في منتصف الصورة ويشغل أبعاد 20×20 بكسل مع زيادة 4 بكسل للحواف. (هكذا حصلنا على 28×28 بكسل)
- الصور بتدرج رمادي، حيث أن لون الخلفية أسود والخط المرسوم باللون الأبيض.
الشكل (2) التالي يوضح كيفية توزيع بكسلات العدد 8 ضمن الصورة.

يمكننا تحميل البيانات وإسنادها مباشرة إلى متحولات التدريب والاختبار بالطريقة التالية:
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train و x_text تحتوي على صور إم نيستMNIST، والمتحول خاص به y تحتوي على عنونة هذه الصور. بمعنى آخر، إذا كانت الصورة تحتوي على العدد 3 فإن عنوانها هو 3.
التقييس
يجب علينا أولاً تقييس قيم هذه الصور كما يلي:
x_train, x_test = x_train / 255.0, x_test / 255.0
التقييس هي عملية التي يتغير فيها القيم المختلفة إلى قيم جديدة ضمن مجال محدد. هنا سنقوم بتحويل قيم الألوان التي مجالها من 0 إلى 255 (أي 256 قيمة) إلى قيم المجال [ من 0 إلى 1].
فائدة هذه التحويلات هي إمكانية تقبل أي نوع من البيانات المحولة. لفهم هذه الفكرة أكثر، تخيل أننا نقوم ببناء نموذج يقبل الصور التي فيها كل بكسل قيمة لونية من 0 إلى 255.
ثم أتينا بعد عدة أسابيع وأردنا استخدام النموذج ذاته من أجل صور القيم اللونية للبكسل الواحد تأخذ 16 قيمة لونية، سنجد أنه لا يوجد تطابق في حجم الدخل. فلو كانا المجموعتان مطبق عليهما التقييس ضمن مجال [0،1] لكانا متوافقين لنفس النموذج.
النموذج
سنقوم بإنشاء نموذج متسلسل مبسط، لتفادي التعقيد والبطء في العمل، ولتكون مناسبة لهذه التجربة. في هذه الحالة سنستخدم طبقة دخل تطابق حجم الصور الموجودة ضمن مجموعة البيانات إم نيست Mnist، يتبعها طبقة كاملة الاتصال، ومن ثم طبقة ” تعطيل عمل العصبونات” التي تحمل معدل تعطيل نسبته 20%، وبعدها طبقة كاملة الاتصال.
إن هذه الطبقة الأخيرة، لديها فقط 10 وحدات تتوافق مع كمية الخرج الذي نبحث عنه في نموذجنا (من 0 إلى 9) .
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')])
من وجهة نظر مطوري الواجهات، لا يؤثر كثيراً بساطة النموذج من تعقيده. ما يهمهم فعلياً شكل الدخل الآتي من الطبقة الأولى وشكل الخرج الناتج من الطبقة النهائية. بذلك يكون من المهم معرفة نوع الدخل الذي سنحتاج إليه في أي نموذج سنعمل عليه، وما هو الخرج المتوقع ظهوره. كما يمكننا بسهولة استنتاج المخاطر المحتملة من النموذج دون التعمق بالطبقات الداخلية للنموذج.
الترجمة
بالطريقة التالية نقوم بترجمة النموذج:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
عند ترجمة النموذج يجب تعريف المُحسّن وتابع الخسارة، كما يجب التصريح عن دقة النموذج بالنظام المتري.
الملائمة
إن مفهوم ملائمة النموذج تعني تدريب النموذج لدينا مع معطيات التدريب الذي حصلنا عليها من مجموعة البيانات إم نيست MNIST في البداية.
عند القيام بعملية التدريب فإننا ضمنياً نخبر مكتبة تنسورفلو لتشغيل التدريب عدد من المرات ، التي تعرف بدورة التدريب epochs . على سبيل المثال، يمكن تحديد عدد دورات التي ستقوم بها مكتبة تنسورفلو بـ 100 دورة تدريب.
هنالك احتمالية تحقيق الدقة المطلوبة قبل الوصول إلى آخر دورة تدريب، يمكننا استخدام ما يسمى بـ إعادة الاستدعاء Callback لتوقيف عملية التدريب.
قد يستغرق زمن تدريب النموذج عدة ساعات أو حتى عدة أيام!
لا تقلق! فإن النموذج الذي نقوم ببنائه سيقوم بعملية التدريب بشكل سريع. بما أننا نستهدف دقة 99%، فمن المتوقع الوصول إليه بعد 20 دورة تدريب بشكل تقريبي.
سنعرف تعليمة إعادة الاستدعاء كما يلي:
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('acc')>0.99):
print("\nReached 99.0% accuracy so cancelling training!")
self.model.stop_training = True
ملاحظة: إذا كنت تستخدم الإصدار الثاني من مكتبة تنسورفلو 2، يجب تبديل كلمة ‘acc’ بــ ‘accuracy’ في التعليمة السابقة.
بعد الانتهاء من كتابة تعليمات إعادة الاستدعاء، يمكننا ملائمة النموذج بالشكل التالي:
model.fit(x_train,
y_train,
epochs = 50,
callbacks = [myCallback()])
يمكن ملاحظة أن إعادة الاستدعاء الموجودة ضمن تعليمة الملائمة موجودة بشكل مصفوفي. ففي هذه الحالة، يمكن أن نستدعي عدة تعليمات إعادة الاستدعاء في ذات الوقت.
عند تنفيذ هذا الكود، ستكون قادراً على معاينة تغيرات تابع الخسارة والدقة من أجل كل دورة تدريب.
Epoch 15/25
60000/60000 [==============================] - 2s 32us/sample - loss: 0.0322 - acc: 0.9890
Epoch 16/25
60000/60000 [==============================] - 2s 32us/sample - loss: 0.0304 - acc: 0.9897
التقييم
بعد القيام بتدريب أي نموذج، يتوجب علينا تقييم أدائه بالمقارنة مع بيانات الفحص. في بداية المقال، عندما قمنا بتحميل مجموعة البيانات إم نيست MNIST، تم تحميل كلا نوعي البيانات (التدريب و الاختبار). تستخدم بيانات الاختبار لمعاينة مدى جودة النموذج عند تحميله بيانات لم يتعرض إليها من قبل ( أي في فترة التدريب). فهي بيانات جديدة كلياً بالنسبة للنموذج.
يتم تقييم النموذج بطريقة سهلة جداً كالآتي:
model.evaluate(x_test, y_test)
خلال فترة التقييم يمكننا مراقبة تقدم النموذج في العمل:
10000/10000 [==============================] - 0s 25us/sample - loss: 0.0782 - acc: 0.9800
هنالك عدة فوائد نستخلصها منها:
-
- حجم بيانات الاختبار أقل بكثير من بيانات التدريب، بالتالي ستكون عملية التقييم سريعة في حالتنا.
- تابع الخسارة والدقة لا يتطابقان مع النتائج التي حصلنا عليها خلال فترة التدريب. إن هذه النتيجة طبيعية جداً لأن البيانات التي تدخل إلى النموذج جديدة كلياً ولم يتعامل معه من قبل.
ليس من الضرورة تقييم النموذج في هذه المرحلة من العمل، ولكنه من المفيد مشاهدة مدى فعالية وتقدم النموذج.
تنسورفلو المُخفّف Tensorflow Lite
أصبح لدينا نموذج مترجم ونريد الآن إنشاء نسخة باستخدام مكتبة تنسورفلو المُخفف لنستخدمه على جهازنا الخلوي. إن هذه العملية تتطلب خطوتين أساسيتين: حفظ النموذج ومن ثم تحويله.
مرحلة الحفظ
سنقوم بحفظ النموذج ( الذي بنيناه باستخدام مكتبة كيراس keras) ضمن مجلد النماذج الذي أنشأناه في البداية:
# tensorflow 1.x
model.save('models/my_mnist_model.h5')
إذا كنت تستخدم الإصدار الثاني مكتبة تنسورفلو 2 يمكنك حفظ النموذج بالشكل التالي:
# tensorflow 2.x
tf.saved_model.save(model, "./models/mnist")
مرحلة التحويل
عند حفظ النموذج، يمكننا تحويله ببضعة تعليمات. بداية، ننشأ محوّل TFLite وتحميل النموذج المحفوظ سابقاً معه:
# tensorflow 1.x
converter = tf.lite.TFLiteConverter.from_keras_model_file('models/my_mnist_model.h5')
إذا قمت بحفظ النموذج عن طريق الإصدار الثاني مكتبة تنسورفلو، يمكنك تحميل النموذج إلى المُحوّل بالطريقة التالية:
# tensorflow 2.x
converter = tf.lite.TFLiteConverter.from_saved_model('models/mnist')
ومن ثم نقوم بتحويل النموذج:
tflite_model = converter.convert()
الحفظ مرة أخرى
سنقوم بحفظ نموذجنا الجديد ( المحفوظ عن طريق مكتبة تنسورفلو المخفف TFLite) ضمن مجلد النماذج لدينا:
open("models/converted_mnist_model.tflite", wb").write(tflite_model)
تهانينا لقد أنجزت المطلوب!
بعد آخر عملية حفظ للنموذج، سنقوم بتحميله في الجزء الثاني عبر تطبيق فلاتر .
كما ذكرنا سابقاً .. الكود كاملاً سيكون متاحاً على مستودع جيت هب الخاص بمنصة الذكاء الاصطناعي باللغة العربية (هنا) بالشكل التالي:
- في حال استخدام الإصدار الأول من مكتبة تنسورفلو:
# If you are using Tensorflow 1.x
import tensorflow as tf
# Load the MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# Normalize the training values
x_train, x_test = x_train / 255.0, x_test / 255.0
# A callback to stop our training when reaching enough accuracy
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('acc')>0.99):
print("\nReached 99.0% accuracy so cancelling training!")
self.model.stop_training = True
# Create a basic model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
model.fit(x_train,
y_train,
epochs=25,
callbacks=[myCallback()])
# Evaluate the model
model.evaluate(x_test, y_test)
# Save the model
model.save('models/my_mnist_model.h5')
# Convert the model.
converter = tf.lite.TFLiteConverter.from_keras_model_file('models/my_mnist_model.h5')
tflite_model = converter.convert()
open("models/converted_mnist_model.tflite","wb").write(tflite_model)
- في حال استخدام الإصدار الثاني من مكتبة تنسورفلو:
# If you are using Tensorflow 2.x
import tensorflow as tf
# Load the MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# Normalize the training values
x_train, x_test = x_train / 255.0, x_test / 255.0
# A callback to stop our training when reaching enough accuracy
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>0.99):
print("\nReached 99.0% accuracy so cancelling training!")
self.model.stop_training = True
# Create a basic model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
model.fit(x_train,
y_train,
epochs=25,
callbacks=[myCallback()])
# Evaluate the model
model.evaluate(x_test, y_test)
# Save the model
tf.saved_model.save(model, "./models/mnist")
# Convert the model.
converter = tf.lite.TFLiteConverter.from_saved_model('models/mnist')
tflite_model = converter.convert()
open("models/converted_mnist_model.tflite", wb").write(tflite_model)




