إعداد: م. نور شرباتي
التّدقيق العلميّ: د.م. حسن قزّاز، م. محمّد سرميني
المحتويات
|
أحدث ظهور الشّبكات الاجتماعية ثورةً في الاتصالات العالمية، ولكنه في المقابل أدى إلى انتشار مجموعةٍ واسعةٍ من الأخبار المزيّفة والإشاعات، التي قد تؤثّر على الأفراد والحكومات والبلدان. ولذلك كان لابد من تطوير التقنيات التي تعتمد على معالجة اللغات الطبيعيّة والذكاء الاصطناعيّ التي تساعد في كشف الأخبار الكاذبة كما استخدم الباحثون تقنياتٍ مختلفةٍ للكشف عن الأخبار المزيّفة، وعلى الرغم من النتائج الجيّدة التي حققها الباحثون في هذا المجال إلا أن مجال معالجة الأخبار باللغة العربية يبقى من المجالات الحديثة التي تتطلب التّطوير والبحث. سنقدّم في هذه المقالة دراسةً شاملةً عن معالجة الأخبار الكاذبة باللغة العربية ومقارنةً بين العديد من تقنيات الذكاء الاصطناعي التي تم استخدامها في مجال تصنيف النصوص. |
المقدمة
لقد أثّر ظهور مِنصّات التّواصل الاجتماعيّ بشكلٍ كبيرٍ على طريقةِ جمع المستخدمين للأخبار واستهلاكها، حيث بلغَ عددُهم 4.76 مليار مستخدمٍ حولَ العالم في عام 2023. وقد تمّ تصميم هذه المنصّات لتكون أكثر جاذبيةً وملاءمةً للتّواصل الاجتماعي، وأصبحت وسيلةً للشّركات والحكومات للوصول إلى الأشخاص من خلال تقديم الأخبار أو عرض الخدمات أو تقديم التّحديثات أو إطلاق الحملات التّسويقية. ومع ذلك، تنشأ القيود من استخدام وسائل التّواصل الاجتماعي، مثل انتشار الأخبار والشّائعات المزيّفة، بالإضافة إلى البريد العشوائي.
تظهر الدراسات على تويتر أن الأخبار الكاذبة تنتشر بسرعة أكبر وتصل إلى 100 ضعف عددِ القرّاء مقارنةً بالأخبار الحقيقية. ويعمل الباحثون على حلّ هذه المشكلة من خلال تحليلِ أنواع الأخبار المزيّفة وإيجادُ الطّريقةِ الأكثرِ فعاليّةً للكشف عنها.
تعدُّ اللّغة العربيّة، التي تعتبر من أكثر اللّغات انتشارًا في العالم، إلا أن مُعالجتها تواجهه العديد من التّحدّيات مثل اللهجات المختلفة والمفردات الغنية، ممّا يزيد من صعوبة اكتشاف المعلومات الخاطئة. كما يعدّ استخدام طريقتي الكتابة العاميّة والفصحى من أبرز التّحدّيات أمام معالجة النصوص باللغة العربية [1].
تقنيات استخراج الميزات
تعمل تقنيات استخراج الميزات واختيارها في استخراج النصوص على تحسين الأداء في المهام المختلفة. تتطلب الميزات الكبيرة عملياتٍ حسابيةٍ وذاكرةً قويةً، لذا يعدُّ اختيار الميزات المناسبة أمرًا بالغ الأهميةِ. وقد طبّقَ الباحثون هذه التقنيات في الكشف عن الأخبار المزيّفة، وذلك باستخدام طريقة القواعد المعرفيّة Knowledge-based Approaches (التحقق من الحقائق)، وطريقة معالجة المحتوى Content-based Approaches، وطريقة معالجة السياق Social Context-based Features . ويوضّح الشكل (1) توصيفاً أدقّ للطرق الثلاثة:
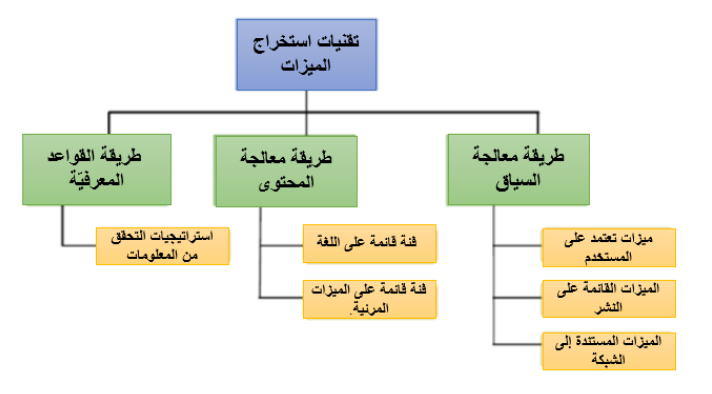
طريقةُ القواعدِ المعرفيّة Knowledge-based Approaches
تركّز على تحديد الحقائق التي تدعم ادّعاءات الأخبار، وغالبًا ما تَستخدم استراتيجياتُ التحققِ من المعلومات.
طريقة معالجة المحتوى Content-based Approaches
تركّز على المعلومات المستخرجة مباشرة من النّص، مثل السمات اللغوية. يمكن تصنيف هذه الميزات إلى فئاتٍ قائمة على اللغة Linguistic-based features وفئة قائمة على الميزات المرئية Visual features.
تقوم الميزات المستندة إلى اللغة Linguistic-based features باستخراج المحتوى على مستويات مختلفة، مثل الأحرف والكلمات والجمل والمستندات. تشمل السمات اللغويّة الشائعة السمات المعجمية والنحوية والدلالية. تَستخدم بعض الأبحاث تقنيات معالجة اللغات الطبيعية (NLP) لاستخراج المعلومات، مثل استخراج الرأي وتحليل المشاعر.
أمّا الطريقة المعتمِدةُ على الميزات المرئية Visual features فتقوم باستخراجِ الميزات من العناصر المرئية، مثل مقاطع الفيديو أو الصّور، باستخدام تقنيات التّعلم العميق. ويمكن دمج هذه الميزات مع ميزات أخرى، مثل الميزات النصّية والمرئية، لاكتشاف الأخبار المزيّفة [1].
طريقة معالجة السياق Social Context-based Features
تعدُّ الميزاتُ المستندة إلى السياق الاجتماعيّ أمرًا بالغَ الأهمية في اكتشاف الأخبار المزيّفة على منصّات التواصل الاجتماعي.
تتضمّن ميزاتٍ تعتمد على المستخدم User-based، والتي تعمل على تقييم مصداقيّة مصادر الأخبار، مثل التركيبة السّكّانية وعمر التّسجيل وعدد الأخبار.
أما الميزات القائمة على النّشرPost-based فيحددها مدى صحة الأخبار من مختلف الجوانب ذات الصّلة بمنشورات وسائل التّواصل الاجتماعيّ، مثل تعليقات المستخدمين وردود أفعالهم وآرائهم واستجاباتهم. تعتمد هذه الميزات على حكمة الجمهور في اكتشاف الأخبار المزيّفة ويمكن استخدامها كبيانات إدخال أساسية.
تُستخدم الميزات المستندة إلى الشبكة Network-based، والتي أنشأها مستخدمو وسائل التواصل الاجتماعي، للكشف عن الأنماط المميّزة المناسبة لتحديد الهويّة. يمكن تصنيف هذه الميزات إلى شبكات الموقف stance network، وشبكات التواجد المشترك co-occurrence network، وشبكات الصداقة friendship network. ومع ذلك، فإن البحث باستخدام الميزات المستندة إلى الشبكة محدود بسبب تعقيدِ تحليل الأنماط والعثور على مجموعة بياناتٍ تحتوي على معلومات كافية. على الرَّغم من هذه التّحدّيات، تعدُّ الأبحاث في هذا المجال واعدةً في اكتشاف الأخبار المزيّفة باستخدام كلّ ميزةٍ على حدةٍ أو دمجِ كلّ من ميزات المحتوى وميزات السّياق [1].
التطّبيق العمليّ
في هذا التّطبيق العملي سنقوم بمعالجةِ مجموعتين من قواعد البيانات [4] التي تتضمّن مجموعة من الأخبار الحقيقة والأخبار الكاذبة حيث سيتمُ في البداية دمج مجموعتي البيانات كما ستتم معالجة النّصوص المتضَمَّنة فيها وذلك باستخدامِ العديد من المكتبات وإنشاء العديد من التّوابع التي تساعد في معالجة وتحليل النّصّ ثم سيتم استخدام العديد من خوارزميات التّعلّم الآلي من أجل تدريب واختبار قاعدةِ البيانات السابقة والمقارنة بين هذه الطرق لاختيار الطريقة المثلى.
- المرحلة الأولى استدعاء المكتبات المهمّة
في البداية سيتمُّ استدعاء العديد من مكتبات معالجة اللّغة العربية وأهمُّ هذه المكتبات هي مكتبة باي-أرابيك PyArabic وهي مكتبةٌ برمجيةٌ للغة العربية بلغة بيثون، توفّر دوالًا للتّحكم في الحروف والنصوص، مثلًا تحديد نوع الحرف، حذف الحركات، مقارنة التشكيل ويتم استدعائها من خلال التعليمة التالية [2].
ثم نقوم باستدعاء مكتبة باي أرامورف pyaramorph وهي مكتبة خاصّة بعملية تحليل وتصريف الجمل باللّغة العربية من خلال التعليمة التالية [3]:
!pip install pyaramorph
ثم نقوم باستدعاء مكتبة تاشفين Tashaphyne وهي مكتبة خاصة بالتجذيع الخفيف للنّصوص العربية يمكن لـ Tashaphyne قبول البادئات وقوائم اللواحق المخصّصة دون تغيير التّعليمات البرمجية وذلك من خلال التعليمة التالية:
!pip install Tashaphyne
كما يتم استدعاء مكتبة NLTK وهي (مجموعة أدوات اللغة الطبيعية) حيث تستخدم لمعالجة البيانات النّصّية، ومكتبة Tkinter التي تساعد في بناء الواجهات الرسوميّة وفق التالي:
import nltk
from tkinter import *
import pyarabic.arabrepr
import re
#stem
from tashaphyne.stemming import ArabicLightStemmer
arepr=pyarabic.arabrepr.ArabicRepr()
repr=arepr.repr
arabic_stemmer=ArabicLightStemmer()
- المرحلة الثانية تحميل قاعدة البيانات:
ثم يتم تحميل قاعدتي بيانات الأولى تتضمن عدد كبير من مقالات الأخبار الكاذبة والثانية تتضمن عدد كبير من مقالات الأخبار الصحيحة 5000 مقالٍ لكلّ قاعدة بيانات حيث يتم التعامل وتدريب الشبكة بناء على هذه القواعد وتوضِّح الشيفرة التالية هذه العمليّة.
import pandas as pd
fake=pd.read_csv('fake data/fake-news.csv',encoding='utf-8')
real=pd.read_csv('fake data/real-news.csv',encoding='utf-8')
real['label']=1
fake['label']=0
real=real[:5000]
fake=fake[:5000]
df=pd.concat([real,fake])
#4999-0
df.head()

ثم يتمُّ ترتيب قاعدة البيانات الناتجة عن دمج قاعدتي البيانات التي تتضمن الأخبار الحقيقية والكاذبة بشكل عشوائي للحصول على قاعدة بيانات عامة وكلُّ سطرٍ من قاعدة البيانات هذه يتضمن عنواناً يحدّد فيما إذا كان الخبر حقيقةً حيث يكون العنوان 1 أم كذباً حيث يكون العنوان 0 كما يتمّ ترتيب قاعدة البيانات الناتجة بشكلٍ عشوائيٍّ لضمان تدريب الشّبكة بشكل صحيح، ثم يتم اعادة تسمية فهرس قاعدة البيانات بشكلٍ منظَّم.
from sklearn.utils import shuffle
df=shuffle(df)
df.head()

df=df.sample(frac=1).reset_index(drop=True)
#Return a random sample of items from an axis of object.
#frac is A random n% sample of the DataFrame with replacement
df.head()

ثم يتمُّ تضمين ملفٍ يحوي أكبرَ قائمةٍ لمستبعدات الفهرسة العربيّة وهو قائمة تتكوّن من حصيلة تجميع مستبعدات الفهرسة من عدّةِ مصادرٍ مختلفةٍ. وهي كلماتُ الربط غير المهمة التي لا تفيد ضمن سياق الكلام والملف موجود ضمن الرابط التالي [4] حيث قمنا بتضمين الملفّ ضمن الشيفرة البرمجيّة، ثمّ استدعائه وتخزين محتوياته ضمن مصفوفةٍ وذلك من خلال الشيفرة التالية:
import string
punc=list(string.punctuation)
file=open('fake data/stopwords.txt','r',encoding='utf-8')
ss=file.read()
stop_words=ss.split()
- المرحلة الثالثة بناء التوابع التي تفيد في معالجة النصوص:
التّابع الأول لفحص وحذف كلمات الربط غير المهمة في النّصّ والمعبّر عنه بالشيفرة البرمجيّة التالية:
def remove_stopwords1():
result_data.delete("1.0",END)
text=rawdata.get("1.0",END)
results=[]
for word in text.split():
if word not in stop_words:
results.append(word)
result_data.insert("1.0"," - ".join(results))
كما نقوم بإنشاء عدّة توابعٍ تفيد في معالجة السياق اللغوي للغة العربية تفيد تقسيم النص الى كلمات والفصل بين الكلمات وازالة علامات التّرقيم وإزالة التّشكيل وإعادة الكلمة إلى جذرها الأصلي باللغة العربية والمعبر عنها من خلال الشيفرة البرمجية التالية:
def splitting1():
result_data.delete("1.0",END)
text=rawdata.get("1.0",END)
results=[]
for word in text.split():
results.append(word)
result_data.insert("1.0"," - ".join(results))
def stemming1():
result_data.delete("1.0",END)
text=rawdata.get("1.0",END)
results=[]
for word in text.split():
word=u"{}".format(word)
arabic_stemmer.light_stem(word)
results.append(arabic_stemmer.get_stem())
result_data.insert("1.0"," - ".join(results))
def get_root1():
result_data.delete("1.0",END)
text=rawdata.get("1.0",END)
results=[]
for word in text.split():
word=u"{}".format(word)
arabic_stemmer.light_stem(word)
results.append(arabic_stemmer.get_root())
result_data.insert("1.0"," - ".join(results))
def segmentation1():
result_data.delete("1.0",END)
text=rawdata.get("1.0",END)
results=[]
for word in text.split('.'):
results.append(word)
result_data.insert("1.0"," - ".join(results))
كما نقوم بإنشاء تابعٍ لمعالجة الأرقامِ المضمّنة وتحويلها إلى صيغةٍ كتابيةٍ لتسهيلِ معالجة المعنى الخاصّ بها من خلال التابع التالي ونقوم بتطبيق التوابع السابقة على قاعدة البيانات المضمّنة لدينا لمعالجتها بالشكل الصحيح قبل تطبيقها على شبكات الاختبار:
def num_pre(q):
# Replacing some numbers with string equivalents (not perfect, can be done better to account for more cases)
q = q.replace(',000,000,000 ', 'بليون ')
q = q.replace(',000,000 ', 'مليون ')
q = q.replace(',000 ', 'الف ')
q = re.sub(r'([0-9]+)000000000', r'\بليون ', q)
q = re.sub(r'([0-9]+)000000', r'\مليون ', q)
q = re.sub(r'([0-9]+)000', r'\الف ', q)
azer=u"\u0660"
anine=u"\u0669"
q = re.sub(r"[0-9]([0-9a-zA-Zأ-ي{}-{}]|\W|_)+".format(azer,anine), ' ',q)
q = re.sub(r"_([0-9a-zA-Zأ-ي{}-{}]|\W|\w)+".format(azer,anine), ' ',q)
return q
df['text1']=df['text'].apply(remove_stopwords)
df['text1']=df['text1'].apply(num_pre)
df['text1']=df['text1'].apply(remove_punctuation)
df['text1']=df['text1'].apply(get_root)
new_df=df.copy()
new_df=new_df.drop(columns=['text','text1','label'])
ثمّ تتمّ إضافة حقل النّصّ بعدَ عمليةِ المعالجة إلى قاعدةِ البيانات المدروسة والإبقاءُ على النّصِّ الاصليّ والمعالج والعناوينِ وتجاهل الحقول الباقية.
- المرحلة الرابعة اختبار خوارزميات الذكاء الاصطناعي في كشف الأخبار الكاذبة:
خوارزميات التعلّم الآلي:
- الخوارزمية الأولى Naive Bayes with Tf_Idf:
غالبًا ما تُستخدم خوارزمية TF-IDF لاستخراج الكلمات الرئيسية للمقالات، ولكنها تأخذ في الاعتبار فقط معلومات تكرار الكلمات، مما يحد من اختيار الكلمات الرئيسية. ومن أجل تحسين كفاءة الخوارزمية، تم تقديم خوارزمية محسنة تضيف مرادفات الكلمات الرئيسية التي تم تدريبها بواسطة نموذج word2vec إلى ناقل الكلمات المكون من الكلمات الرئيسية. ثم يتم إعطاء الخوارزمية المحسنة أوزانًا مختلفة بناءً على جزء الكلام ومعلومات الموقع. ودمج الخوارزمية المحسنة مع خوارزمية Naive Bayes. من أجل التحقق من فعالية الخوارزمية المحسنة، أجريت تجارب على مجموعة بيانات قياسية. تظهر النتائج التجريبية أنه بالمقارنة مع الطريقة التقليدية، فإن دقة خوارزمية TFIDF المحسنة مع Naive Bayes قد تحسنت بشكل كبير. غالبًا ما تستخدم خوارزمية TF-IDF لاستخراج الكلمات الرئيسية للمقالات، ولكنها تأخذ في الاعتبار فقط معلومات تكرار الكلمات، مما يحد من اختيار الكلمات الرئيسية. ومن أجل تحسين كفاءة الخوارزمية، تم تقديم خوارزمية محسنة تضيف مرادفات الكلمات الرئيسية التي تم تدريبها بواسطة نموذج word2vec إلى ناقل الكلمات المكون من الكلمات الرئيسية. ثم يتم إعطاء الخوارزمية المحسنة أوزانًا مختلفة بناءً على جزء الكلام ومعلومات الموقع. ودمج الخوارزمية المحسنة مع خوارزمية Naive Bayes. من أجل التحقق من فعالية الخوارزمية المحسنة، أجريت تجارب على مجموعة بيانات قياسية. تظهر النتائج التجريبية أنه بالمقارنة مع الطريقة التقليدية، فإن دقة خوارزمية TFIDF المحسنة مع Naive Bayes قد تحسنت بشكل كبير.
يعدُّ المفهومُ الرّياضيّ لقياس تردّدِ الكلمة-تردّدُ المستند العكسيّ Term Frequency – Inverse Document Frequency (TF-IDF) أسلوباً إحصائياً يستخدم على نطاقٍ واسعٍ في معالجة الّلغة الطبيعية واسترجاع المعلومات. فهو يقيس مدى أهمّيّة المصطلح داخل المستند بالنسبة إلى مجموعةٍ من المستندات (أي بالنسبة إلى مجموعة الوثائق). يتمُّ تحويل الكلمات الموجودة في المستند النصي إلى أرقامٍ ذات أهمّيّةٍ من خلال عمليّة توجيه النّصّ. هناك العديد من أنظمة تسجيل نقاط توجيه النّصّ المختلفة، ويعدُّ المفهومُ الرّياضيّ لقياس تردّد الكلمة-تردّد المستند العكسيّ TF-IDF واحدًا من أكثرها شيوعًا.
كما يوحي اسمه، يقوم TF-IDF بتوجيه/تسجيل الكلمة عن طريق ضرب تردّد مصطلح الكلمة (TF) مع تردّد المستند العكسي (IDF).
تكرار المصطلح: TF للمصطلح أو الكلمة هو عدد المرّات التي يظهر فيها المصطلح في المستند مقارنةً بإجماليّ عدد الكلمات في المستند ويعبّر عنه بالعلاقة التالية:

تكرار المستند العكسي: يعكس IDF للمصطلح نسبة المستندات الموجودة في المجموعة التي تحتوي على المصطلح. الكلمات الفريدة في نسبةٍ صغيرةٍ من المستندات (على سبيل المثال، المصطلحات الفنية) تتلقى قيمًا ذات أهمية أعلى من الكلمات الشائعة في جميع المستندات.

عند ترجمته إلى اللغة الإنجليزية البسيطة، تكون أهمية المصطلح عاليةً عندما يتكرّر كثيرًا في مستندٍ معينٍ ونادرًا ما يحدث في مستندٍ آخر. باختصار، تتم موازنة القواسم المشتركة داخل الوثيقة التي يتمّ قياسها بواسطة TF من خلال الندرة بين المستندات التي يتم قياسها بواسطة IDF. تعكس نتيجة TF-IDF الناتجة أهمية المصطلح الخاص بالوثيقة في المجموعة.
يعدُّ TF-IDF مفيدًا في العديد من تطبيقات معالجة اللّغات الطّبيعية. على سبيل المثال، تستخدم محركات البحث TF-IDF لترتيب مدى صلة المستند بالاستعلام. يستخدم TF-IDF أيضًا في تصنيف النّصّ وتلخيصه ونمذجة الموضوع.[5]
حيث نقوم في البداية بتضمين التابع TF-IDF Vectorizer scikit-learn
ثمَّ تتم مرحلة استخراج المميزات من قاعدة البيانات التي نعمل عليها وتعدُّ هذه الخطوة، الخطوةَ الرئيسيةَ في معالجة البيانات المسبقة وتتم مرحلة المعالجة بناءً على الخوارزميّة المشروحة سابقاً كما يتم ربط ميزات المستخرجة من البيانات مع index الموافق لها ، ثمّ يتمُّ تقسيم البيانات إلى جزءٍ للتدريب وآخر للاختبار وفق الشيفرة التالية:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
#feature extraction
tfidf_vec=TfidfVectorizer()
tfidf_features=tfidf_vec.fit_transform(df['text1']).toarray()
temp_df=pd.DataFrame(tfidf_features,index=df.index)
final_df=pd.concat([new_df,temp_df],axis=1)
#split data into train and test
x_train,x_test,y_train,y_test=train_test_split(final_df.iloc[:,:].values,df['label'],test_size=0.25)
ثم يتم استدعاء المصنّف التالي:
# classifier
from sklearn.naive_bayes import MultinomialNB
tfidf_model=MultinomialNB()
tfidf_model.fit(x_train,y_train)
ثم بعد عملية استخراج البيانات الموضحة في الخطوة السابقة واستخلاص الميزات تطبق هذه الميزات على خوارزمية Naive Bayes متعدّدة الحدود وهي طريقة تعلم احتمالية تستخدم في الغالب في معالجة اللّغات الطبيعية (NLP). تعتمد الخوارزميّة على نظرية بايز وتتنبأ بعلامة نصٍ مثل رسالة بريدٍ إلكتروني أو مقالٍ صحفيٍ. فهو يحسب احتمالية كلِّ علامةٍ لعينةٍ معينةٍ ثمَّ يعطي العلامة ذات الاحتمالية الأعلى كمخرجات.
مُصنّف Naive Bayes عبارةٌ عن مجموعةٍ من العديد من الخوارزميات حيث تشترك جميع الخوارزميات في مبدأِ واحد مشترك، وهو أن كلَّ ميزةٍ يتم تصنيفها لا ترتبط بأيِّ ميزةٍ أخرى. إن وجود خاصية أو عدمها لا يؤثّر على وجود أو غياب الميزة الأخرى.[6]
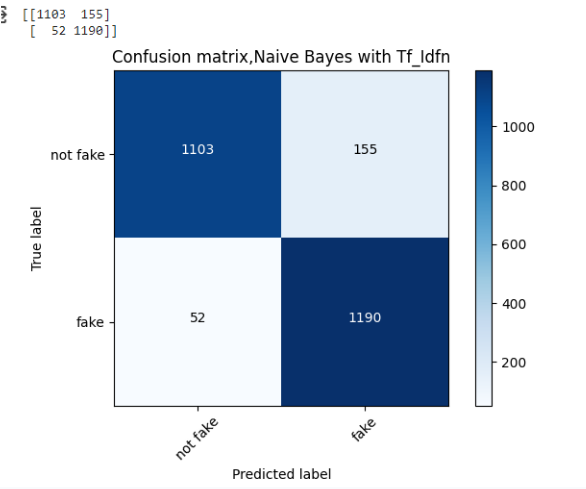
ثمَّ تتمُّ مرحلة الاختبار والتدريب للتحقق من كفاءة المصنّف ثم نقوم بعرض قيم مصفوفة الخطأ confusion matrix التي تدل على نسبة التّصنيف الصّحيح لكلِّ نوعٍ من الأنواع المقترحة وذلك من خلال الشيفرة البرمجية التالية:
import numpy as np
tfidf_predected=tfidf_model.predict(x_test)
print(np.mean(tfidf_predected==y_test))
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test,tfidf_predected))
ثم نقوم بإنشاء تابعٍ لرسم مصفوفةِ الخطأ وذلك لتوضيح النسب بشكلٍ أفضل وذلك من خلال الشيفرة البرمجية التالية:
import keras
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,tfidf_predected)
def plot_confusion_matrix(cm, classes=['not fake','fake'],
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Compute confusion matrix
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cm,
title='Confusion matrix,Naive Bayes with Tf_Idfn')
ثم نحصل على مصفوفة الخطأ الخاصّة بهذه الخوارزميّة والموضحة بالشكل (2) ونلاحظ أن عدد الأخبار الحقيقيّة والتي تم تصنيفها على أنها أخبار حقيقيّة 1103 أما عدد الأخبار الحقيقة التي تم تصنيفها على أنها أخبار كاذبة 155 وكذلك عدد الأخبار الكاذبة التي تم تصنيفها على أنها أخبار كاذبة 1190 وعدد الأخبار الكاذبة التي تم تصنيفها على أنها حقيقية 52.
- الخوارزميّة الثانية الغابة العشوائية Random Forest:
خوارزمية تعلّمٍ آلي شائعةُ الاستخدام ، تجمع بين مخرجات أشجار القرار المتعدّدة للوصول إلى نتيجةٍ واحدةٍ. وقد عزّزت سهولة استخدامه ومرونته من اعتماده، لأنه يتعامل مع مشاكل التصنيف والانحدار.
تعدُّ خوارزمية الغابة العشوائية امتدادًا لطريقة التعبئة لأنها تستخدم كلاً من التعبئة وعشوائية الميزات لإنشاء غابةٍ غير مترابطةٍ من أشجار القرار. تقوم عشوائيّة الميزات، والمعروفة أيضًا باسم: تعبئة الميزات أو “طريقة الفضاء الجزئيِّ العشوائيِّ”، بإنشاء مجموعةٍ فرعيةٍ عشوائيةٍ من الميزات، مما يضمن انخفاض الارتباط بين أشجار القرار. هذا هو الفرق الرئيسي بين أشجار القرار والغابات العشوائية. في حين أن أشجار القرار تأخذ في الاعتبار جميعَ تقسيمات الميزات المحتملة، فإن الغابات العشوائية تحدد فقط مجموعة فرعية من تلك الميزات.[7]
توضّح الشيفرة التالية طريقة استدعاء الخوارزميّة وتدريبها على قاعدة البيانات:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
rf = RandomForestClassifier()
rf.fit(x_train,y_train)
y_pred = rf.predict(x_test)
accuracy_score(y_test,y_pred)
وبعرض نسبة التصنيف الصّحيح ومصفوفة الخطأ confusion matrix نحصل على النّسب التالية الموضّحة بالشكل (3) ونلاحظ أن عدد الأخبار الحقيقيّة والتي تم تصنيفها على أنها أخبار حقيقيّة 1158 أما عدد الأخبار الحقيقة التي تم تصنيفها على أنها أخبار كاذبة 94 وكذلك عدد الأخبار الكاذبة التي تم تصنيفها على أنها أخبار كاذبة 1189 وعدد الأخبار الكاذبة التي تم تصنيفها على أنها حقيقية 59.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
print(cm)
plot_confusion_matrix(cm,
title='Confusion matrix,Random Forest with Tf_Idf')

- الخوارزميّة الثالثة الانحدار اللوجستي Logistic Regression:
الانحدار اللوجستي هو عملية نمذجة احتمالية الحصول على نتيجة منفصلة بالنّظر إلى متغير المدخلات. نماذج الانحدار اللوجستي الأكثر شيوعًا هي نتيجةٌ ثنائيةٌ؛ شيءٌ يمكن أن يأخذ قيمتين مثل صحيح/خطأ، نعم/لا، وما إلى ذلك. يمكن للانحدار اللوجستي متعدد الحدود أن يصمم سيناريوهات حيث يوجد أكثر من نتيجتين منفصلتين محتملتين. يعدُّ الانحدار اللوجستي طريقة تحليل مفيدة لمشكلات التصنيف، حيث تحاول تحديد ما إذا كانت العينة الجديدة تناسب الفئة بشكل أفضل. نظرًا لأنَّ جوانب الأمن السيبراني تمثل مشكلات تصنيفية، مثل اكتشاف الهجوم، فإن الانحدار اللوجستي يعدُّ أسلوبًا تحليليًا مفيدًا.[8]
توضح الشيفرة التالية طريقة استدعاء الخوارزميّة وتدريبها على قاعدة البيانات:
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(x_train,y_train)
# Predicting the test set results
tested_y = classifier.predict(x_test)
accuracy_score(y_test,y_pred)
وبعرض نسبة التصنيف الصحيح ومصفوفة الخطأ نحصل على النسب التالية الموضحة بالشكل(4)، ونلاحظ أن عدد الأخبار الحقيقيّة والتي تم تصنيفها على أنها أخبار حقيقيّة 1158 أما عدد الأخبار الحقيقة التي تم تصنيفها على أنها أخبار كاذبة 94 وكذلك عدد الأخبار الكاذبة التي تم تصنيفها على أنها أخبار كاذبة 1189 وعدد الأخبار الكاذبة التي تم تصنيفها على أنها حقيقية 59.
cm = confusion_matrix(y_test,y_pred)
print(cm)
plot_confusion_matrix(cm,
title='Confusion matrix,Logistic Regression')

وبالمقارنة بين الخوارزميات الثلاثة من حيث الدقة accurcy نلاحظ التقارب في الأداء حيث بلغت دقة خوارزميّة Naive Bayes with Tf_Idf حوالي 91.3% بينما بلغت دقة خوارزميّة الغابة العشوائية Random Forest و خوارزمية الإنحدار اللوجيستي 93.88 متفوقين على الخوارزميّة السابقة.
الخلاصة
مع ازدياد انتشار تطبيقات التواصل الاجتماعي وازدياد عدد المستخدمين مما يؤدي إلى زيادةٍ ملحوظةٍ في إعداد الأخبار والبيانات التي يتم تبادلها في هذه الشبكات مما يستلزم إيجاد خوارزميات ذكاءٍ تساعد في تحليل وكشف الأخبار الحقيقيّة والكاذبة وذلك من خلال معالجة واستخراج ميزاتٍ محددةٍ من النصوص وذلك بالاعتماد على العديد من التوابع والمكتبات المعنية بهذا الموضوع، وعلى الرغم من النتائج الجيّدة التي حققها الباحثون في مجال معالجة الاخبار باللغة الانكليزية إلا أن معالجة الأخبار في اللغة العربية سوف يبقى مجالاً يفتقر للدراسة والتحليل.