
يعتبر علم الكشف عن الوجوه Face Detection أحد أهم علوم الرؤية الحاسوبية Computer Vision ويعد المبحث الأساس لعلم التعرف على الوجوه Face Recognition، حيث أن أول خطوة من إنجاز تعرف آلي على الوجوه هي كشفه، وحيث أنه إذا تم الكشف عن مكان الوجه بشكل صحيح أصبح التعرف عليه أمراً أبسط نسبياَ.
تعرف ويكيبديا علم الكشف عن الوجوه بأنه تقنية حاسوبية تستخدم في مختلف تطبيقات التعرف على الوجوه البشرية في الصور الرقمية. تتفاوت هذه التطبيقات من الألعاب الرقمية إلى البطاقات الذكية والتطبيقات الأمنية، تأتي أهمية الكشف عن الوجه أو التعرف على الوجوه من حقيقة أنه لا يحتاج لتواصل فيزيائي مع المستخدم، وأن الأدوات المستخدمة هي كاميرات وهي أدوات متوفرة أصلاً.
المحتويات
التحديات والمشاكل
أنظمة الكشف على الوجوه تحاول التغلب على عدة مشاكل وتحديات فمثلا العمر و التعابير الوجهية للشخص الواحد تغير الكثير من خصائص الصور كما أن اللحية، النظارات والمكياج تؤثر سلبا على الكشف على الوجه لأنها تستر قسم هام من الوجه لوناً وشكلاً. وأخيرا زاوية الرؤية وتغير الإضاءة للوجه الواحد تحدث تغييرا أكبر من التغير بين الأوجه المختلفة (وفق أولمان، أديني وموسس Moses, Adini, Ullman المرجع رقم [1])
التقنيات الموجودة للكشف على الوجوه
تتركز الأبحاث في مجال الكشف على الوجوه في ثلاث مجالات رئيسية:
أولاً – الأبحاث المعتمدة على اللون Color-based Approaches: تعتمد هذه الأبحاث بشكل رئيسي على تقنيات تجعل من لون الوجه معرّف له مثل تطابق الهستوغرام Histogram Matching و الإسقاط الخلفي للهسيتوغرام Histogram Backprojection.
ثانياً – الأبحاث المعتمدة على تدريب الشبكات العصبونية Neural Network-based Approaches: تعتمد هذه الأبحاث على تقنيات الشبكات العصبونية من حيث التدريب والاختبار.
ثالثاً – الأبحاث المعتمدة على خصائص الوجه Features-based Approaches: تعتمد هذه الأبحاث بشكل رئيسي على تقنيات تجعل من شكل الوجه معرف له بدل اللون.
حيث يمكننا تقسيم الأنظمة في هذا المجال إلى نوعين أساسيين من حيث منطق العمل:
- النظام يحدد من هو الشخص الذي يظهر بالصورة Close Set.
- النظام يحدد أولاً هل هذه الصورة هي صورة وجه؟ ثم يقرر من هو هذا الشخص؟ Open-set
أولاً – الأبحاث المعتمدة على اللون Color-based Approaches
تعتبر الأبحاث المعتمدة على اللون من أوائل الأبحاث المتعلقة بمجال الكشف على الوجوه حيث تم استخدام تقنيات الهيستوغرام من أجل استخراج خصائص الوجه اللونية والتي يتم اعتبارها البصمة اللونية الخاصة بالوجوه البشرية.
بشكل رئيسي تنقسم هذه الأبحاث إلى:
1 – الإسقاط الخلفي للهيستوغرام Histogram Back Projection
حيث يتم تشكيل ثنائيات من قيمة البكسل اللونية وقيمة احتمال أن يكون جلد. يتم تشكيل هذه الثنائيات بناء على صور معروفة لدينا بشكل مسبق بمعنى أننا نأخذ صور لوجوه البشر ونأخذ قيمة كل بكسل من بكسلات الوجه، ونأخذ صور لغير وجوه مع قيمة كل بكسل لينتج لدينا بالنهاية مجموعة الثنائيات.
المرحلة الثانية عندما تأتينا صورة جديدة ننظر في الهستوغرام و نقارنه مع الجدول فإذا كان الاحتمال أكبر من قيمة معيارية محددة Threshold عندها تصنف أنها بكسل جلد وإذا كان أقل نصنفه أنه ليس بكسل جلد. يتم استخدام تقنيات مثل Support vector machine SVM لإجراء هذا التصنيف.
2- مطابقة الهيستوغرام Histogram Matching
في هذه التقنية يتم إنجاز هستوغرام خاص بكل صور الوجوه التي لدينا ليتكون لدينا موديل خاص غوصي مثلاً ثم عندما تأتينا صورة جديدة نقارن الهيستوغرام الخاص بكل قسم منها Patch مع الهستوغرام المعياري الذي لدينا وبناء على حسابات للمسافات بينهما نقرر هل لدينا بكسلات (قسم Patch) جلد أم لا.
بعد أن نصبح قادرين على تحديد كل بكسل هل هو جلد أم لا يبقى لدينا أن نقرر هل هو من بكسلات الوجه أم لا ويمكننا عمل ذلك من خلال إجراء عمليات المورفولوجي الخاصة بالصور إغلاق-فتح Close-Open.
مشكلة هذه الطرق هي عدم مقاومتها لتغيير الإضاءة حيث أن أي تغيير سيؤدي لتغيير كبير في القيم اللونية للبكسلات وبالتالي سيؤدي لتغيير بالهيستوغرام.
ثانياً – الأبحاث المعتمدة على تدريب الشبكات العصبونية Neural Network-based Approaches
هذه الأبحاث تحاول أن تحاكي الرؤية البشرية حيث تحاكي عمل العصبونات الدماغية من خلال تعليمها شكل/لون الوجه البشري بشكل مشابه تقريبا لتعليم العصبونات الدماغية في الإنسان.
المرحلة الأولى: هي تهيئة الصور من خلال تصحيح الإضاءة عن طريق تسوية الهستوغرام Histogram Equalization وذلك بتقليل إضاءة البكسلات المشعة وزيادتها في البكسلات الخافتة.
المرحلة الثانية التدريب: هي تدريب شبكتنا العصبونية على مجموعتين من الصور، المجموعة الأولى هي صور تحوي على وجوه والمجموعة الثانية هي صور لا تحوي وجوه. الهدف من هذه المرحلة هي الحصول على الأوزان الخاصة بشبكتنا. لا يتم هنا تدريب الشبكة على الصور التي لدينا بشكل مباشر وإنما على أقسام الصور Subimages.
المرحلة الثالثة الاختبار: عندما نريد اختبار صورة جديدة هل تحوي على وجه أم لا نقوم بذلك من خلال إدخال أقسامها بشبكتنا المدربة لينتج لدينا هل تحوي وجه أم لا بحسب قيمة معيارية محددة يتم تحديدها مسبقاً Threshold.
ثالثاً – الأبحاث المعتمدة على خصائص الوجه Features-based Approaches
نظراً لاعتماد الأبحاث المعتمدة على اللون Color-based Approaches على الألوان لتمييز الوجه تظهر عندنا مشكلة كبيرة وهي تغيير الإضاءة حيث أن تغير الإضاءة للوجه الواحد تحدث تغييرا أكبر من التغير بين الأوجه المختلفة. للتغلب على هذه المشكلة ظهرت فكرة اعتماد خصائص الوجه الشكلية بدلا من اللونية.
تعرف هذه الطريقة أيضا باسم فيولا وجونز Viola & Jones ويمكن تقسيمها لأربع تقنيات رئيسية:
1 – التقنية الأولى إيجاد الخصائص Features Selection

في الشكل رقم (1) نجد على اليمين بعض الخصائص المستخدمة للكشف على الوجوه، تحوي هذه الخصائص على قيم 1 و 0 فقط بحسب شكلها فمثلاً الخاصية B فيها البكسلات العلوية 0 والبكسلات السفلى 1.
الخاصية B مثلاً تملك مثيلات لها بالشكل مختلفة عنها بالحجم فقط ويتم تمثيل اللون الأبيض فيها بالقيمة (1) والاسود بالقيمة (0).
سنقوم هنا بتطبيق هذه الخصائص على الصورة التي لدينا حيث نبدأ بالخاصة B مثلاً ونقوم بتمريها على كل الصورة من الأعلى-اليسار وحتى الأسفل-اليمين. بعد إيجاد المتوسط الحسابي لجداءات بكسلات الصورة (جزء الصورة المساوي لحجم الخاصية عادة تكون بأبعاد 24*24) مع بكسلات الخاصية (عادة 1 و 0 ) نحصل على قيمة معينة.
في مرحلة تدريب الخوارزمية: يتم الاستفادة من هذه القيمة لتعيين القيمة المرجعية.
في مرحلة الاختبار: يتم الاستفادة منها بتصنيفها على أنها خاصية وجه أو لا بناء على مقارنتها مع القيمة المرجعية التي لدينا.
2 – التقنية الثانية الصورة المتكاملة Integrated Image
إن وجود عدد كبير جدا من الخصائص المستخدمة بسبب تعدد الأشكال والأحجام يؤدي إلى عدد كبير جدا من الحسابات. لتقليل عدد هذه الحسابات نستخدم تقنية الصورة المتكاملة.
تم تقديم هذه التقنية للمرة الأولى عام 1984 كمفهوم رياضي ولكن لم يتم استخدامها في مجال الرؤية الحاسوبية حتى عام 2001 بخوارزمية فيولا وجونزViola & Jones التي نتكلم عنها الآن.
بداية يمكننا الحصول على الصورة المتكاملة من تراكم مجموع البكسلات التي تسبقها عمودياً وأفقياً أي من البكسل (0,0) حتى البكسل الحالي مما يؤدي إلى تقليل عدد الحسابات المطلوبة عند إيجاد المتوسط الحسابي لجداءات قيم الخاصية مع قيم بكسلات النافذة التي وصلنا لها من الصورة Window.
ولكن كيف تعمل هذه التقنية على تقليل عدد الحسابات؟ سنوضح ذلك بهذا المثال.
لنفرض أن لدينا مصفوفة 5*5 التي تمثل الصورة التي نعمل عليها ولنفرض أن النافذة Window هنا هي بأبعاد 3*3 و وصلت بعملية الإنزياح إلى الوسط أي إلى البكسلات المضاءة بالأزرق كما في الشكل رقم (2).
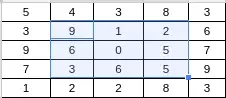
والآن إذا أردنا حساب المتوسط نقوم بما يلي:
9 + 1 + 2 + 6 + 0 + 5 + 3 + 6 + 5 = 37
37 / 9 = 4.11
أي نحتاج 9 عمليات حسابية فإذا أردنا تنفيذ 100 عملية مثل التي قمنا بها يكون لدينا 900 عملية. 100 * 9 = 900.
دعنا الآن نقوم بعمل الصورة المتكاملة الشكل رقم (3) ونرى عدد الحسابات التي سنحتاجها.
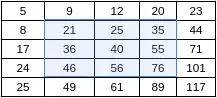
نحتاج 56 عملية لعمل هذه الصورة المتكاملة عن طريق جمع قيم البكسلات السابقة عمودياً وأفقياً ولحساب المتوسط الحسابي عند التركيز على المنطقة الوسطى (المنطقة الزرقاء) الآن يكفي أن نقوم بما يلي:
(76 – 20) – (24 – 5) = 37
37 / 9 = 4.11
وهذه يتطلب 4 عمليات فقط وإذا قمنا ب 100 عملية مماثلة 56 + 100 * 4 = 456.
بالمحصلة يكون لدينا اختصار حسابات 50% من أجل مصفوفة صورة صغيرة 5*5 يمكنك أن تتخيل الاختلاف الكبير بعدد الحسابات في الصور الكبيرة والعمليات الكثيرة.
3 – التقنية الثالثة المسرع Ada boost
نحاول أن نجعل خوارزميتنا أكثر ذكاء وسرعة عن طريق هذه التقنية التي تتلخص باختيار الخصائص الأفضل ودمج عدد من المصنفات الضعيفة Weak Classifier بمصنف واحد قوي. هذا التصنيف يقوم على مبدأ تعديل الأوزان بالتركيز على العينات التي تم تصنيفها بشكل خاطئ.
4 – التقنية الرابعة سلسلة المصنفات Classifier Cascade
لتقليل زمن التصنيف نقوم بتقسيم المصنف على طبقات، الطبقة الأولى هي مصنف يعتمد على عدد بسيط من الخصائص يعمل على تصنيف سطحي ويعمل على إبقاء كل الأمثلة الصحيحة (الصور التي تحوي وجوه) وبعض الأمثلة الخاطئة (الصور التي لا تحوي وجوه). الطبقة الثانية هي مصنف يعتمد على عدد أكبر من الخصائص وبالتالي يضمن استبعاد المزيد من الأمثلة الخاطئة. وهكذا كل طبقة هي مصنف يعتمد على عدد أكبر من الطبقة التي تسبقها وتعمل على تقليل الأمثلة الخاطئة أي تزيد من دقة التصنيف.
خاتمة
قمنا في هذا المقال بتقديم موجز عن أهم الأبحاث في مجال الكشف عن الوجوه حيث بدأنا بعرض الأبحاث التي تتخذ من لون بكسلات الصور دليلا على التفريق بين الوجه أو غيره ثم عرضنا مشكلتها عند تغيير الإضاءة. قمنا بعد ذلك بتقديم الأبحاث التي تعتمد على الشبكات العصبونية وأخيرا قمنا بشرح أهم التقنيات التي تعتمدها الأبحاث التي تعتمد على خصائص الوجه.
المراجع
- Moses, Yael et al. “Face Recognition: the Problem of Compensating for Changes in Illumination Direction.” ECCV (1994).
- Phung et al, Skin Segmentation Using Color Pixel Classification: Analysis and Comparison, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 27, 1, Jan. 2005
- Michael J. Swain and Dana H. Ballard, Color Indexing, International Journal on Computer Vision, 7:1, 11-32 (1991)
- H. Rowley, S. Baluja, and T. Kanade, Neural Network-Based Face Detection, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 20, No. 1, January, 1998, pp. 23-38.
- Paul Viola & Michael Jones, Rapid Object Detection Using a boosted cascade of simple features, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2001
- Paul Viola & Michael Jones. Robust real-time object detection, Cambridge Research Laboratory, Technical Report,, February 2001, CRL 2001/01




