
المحتويات
مقدمـــــة
يُعتبر داء الكوفيد-19 الذي ظهر في أواخر عام 2019 (COVID-19) مرضًا شديد العدوى ينجم عن متلازمة الالتهاب التنفسي الحاد فيروس كورونا 2. بدأ المرض لأول مرة في كانون الأول 2019 في ووهان، الصين. ومنذ ذلك الحين انتشر في جميع أنحاء العالم وأثر على أكثر من 200 دولة. وبدا تأثيره حين صرّحت منظمة الصّحة العالمية أن الوباء المستمر لـ كوفيد-19 هي حالة طارئة للصحة العامة وذات أهمية دولية.
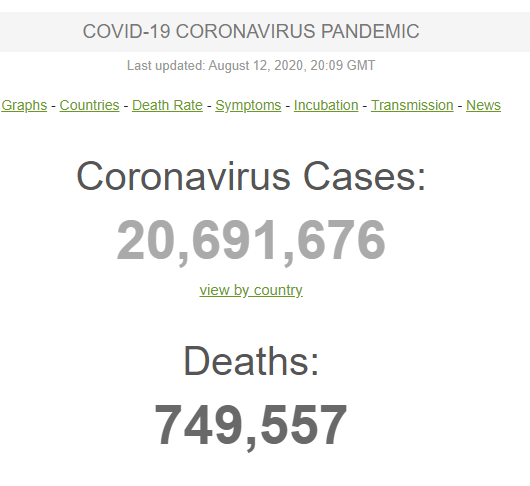
يوجد 20,691,676 حالة كوفيد-19 حتى تاريخ 12 آب، توفي منها 749,557 حالة وذلك في أكثر من 200 دولة في أنحاء العالم. (المصدر: [1])

لذا في هذا الوضع المتزايد من الإصابات، هناك شيء أساسي يجب القيام به وقد بدأ بالفعل في غالبية البلدان وهو الاختبار اليدوي أي غير الآلي، لكن الاختبارات اليدوية لها عيوب مثل اختبارات الدم المكلفة وغير الفعالة حيث يستغرق فحص الدم حوالي 5-6 ساعات لإصدار النتيجة. ولهذا نحن نريد أن نتغلب على هذه الظروف باستخدام تقانات التعلم العميق الذي يعدّ أهم فروع الذكاء الاصطناعي وذلك للحصول على العلاج في وقت مبكر وكفاءة عالية، بالاعتماد على الطرق التقنية.
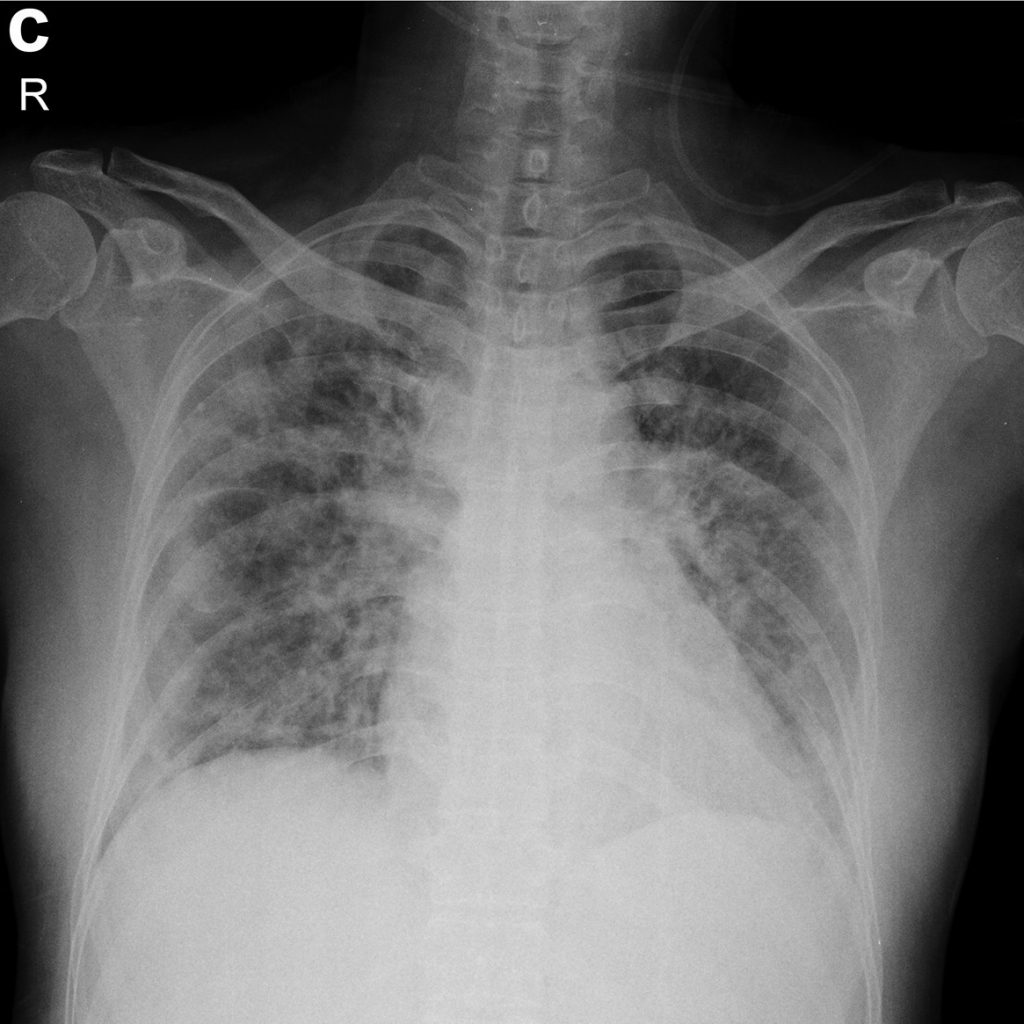
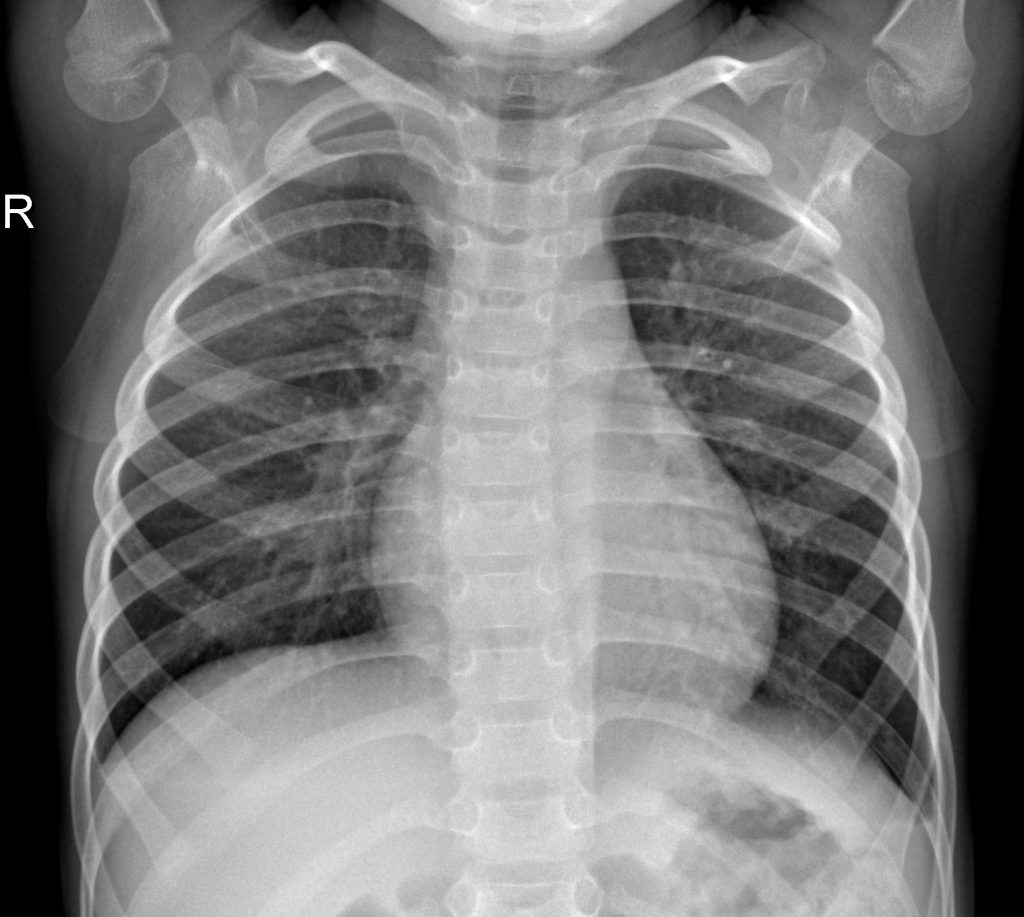
تحضير البيانات
يحتاج تعلم الآلة والتعلم العميق إلى الكثير من البيانات، وهذه البيانات في هذه الحالة هي صور الأشعة السينية الصدرية لكل من المرضى المتأثرين بالكوفيد وغير المتأثرين.
1- أتاح دكتور جوزيف باول كوهين Dr.Joseph Paul Cohen مجموعة بيانات مفتوحة المصدر للصور الصدرية المأخوذة بالأشعة السينية للمرضى الذين يعانون من داء الكوفيد-19، فمجموعة البيانات المستخدمة هي مجموعة بيانات مفتوحة المصدر تتكون من صور كوفيد-19 من الأبحاث المتاحة، بالإضافة إلى صور الرئة بأمراض مختلفة تسبب الالتهاب الرئوي مثل السارس SARS والمكورات العقدية والمكورات الرئوية [2] .
2- استخدمت أيضاً مجموعة بيانات مسابقات الأشعة السينية الصدرية الخاصة بـ كاغل Kaggle’s Chest X-ray للمرضى غير المصابين بالكوفيد [3] لتصبح البيانات متوازنة balanced.
إذاً لتصنيف بياناتنا ، سنأخذ عددًا متساوياً من الصور للمرضى المصابين بالكوفيد-19 وغير المصابين وسنقوم بدمجها وبعد ذلك سنقسم البيانات إلى بيانات اختبار وبيانات تدريب.
بناء النموذج
ها نحن قد أعددنا البيانات التي تعد الجزء الأكثر إرهاقًا في هذا المشروع، فلننتقل إلى الخطوة التالية وهي إنشاء نموذج تعلم عميق يتعلم الفرق بين الأشعة السينية الطبيعية والأشعة السينية المتأثرة بالكوفيد، أي يكون قادراً على تصنيف صور الأشعة السينية إلى صنفين ثم يصبح النموذج قادراً على التنبؤ بصنف الصور المدخلة إليه فيما إذا كانت طبيعية أو مصابة بالكوفيد-19 [4] .
عزيزي القارئ أظن أنك تعرف أساسيات بناء شبكة الطّي العصبونية، إذا أردت تعلّم ذلك يمكنك متابعة المقال [5].
ستكون بنية النموذج كما يلي:
model = Sequential()
model.add(Conv2D(32,kernel_size=(3,3),activation='relu',input_shape=(224,224,3)))
model.add(Conv2D(128,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss=keras.losses.binary_crossentropy,optimizer='adam',metrics=['accuracy'])
نرغب بإنشاء 4 طبقات طّي، وبإمكانكم تجريب طبقات أكثر أو أقل. اخترنا أيضاً حجم مرشح الطيّ بأبعاد (3،3) وأبعاد طبقات تجميع-القيمة الكبرى ببعد (2،2).
نلاحظ أن دخل الشبكة يأخذ التمثيل (224,224,3) وهذا يعني أن أبعاد الصور(224,224) وذات 3 قنوات chanels تعبر عن ألوان RGB، يمكن لنموذجنا استيعاب التفاصيل الدقيقة والميزات الضرورية من الصورة من خلال طبقات الطّي.
ثم نقوم بتسطيح الميزات من خلال طبقة التسطيح Flatten، وإدخالها إلى طبقات التصنيف. سنضع عصبون وحيد في طبقة الخرج ونطبق تابع سيغمويد Sigmoid لأن المسألة هي تصنيف ثنائي، وسنقوم بتطبيق خوارزمية آدم كخوارزمية تحسين وبالتالي تتم ترجمة النموذج compile مع الإنتروبيا المتقاطعة الثنائية.
يوضّح الشكل التالي ملخص النموذج:

تدريب البيانات
بعد أن عرّفنا النموذج، تتمثل مهمتنا الآن بتدريب بياناتنا على النموذج المعرّف.
ونظراً لصعوبة جمع البيانات الحقيقية الكثيرة فيمكننا استخدام تقنية تعزيز البيانات Data Augmentation في تدريب الشبكة العصبونية وذلك للحصول على مجموعة كبيرة من العينات نتيجة إجراء عمليات القص croping و الدوران rotation ,والتدوير flapping الأفقي والعمودي وغيرها على العينات الأصلية. لقراءة المزيد عن تقانة التعزيز [ ،[6] [7] وعن التحويلات الهندسية المستخدمة في التعزيز [8].
train_datagen = image.ImageDataGenerator(rescale = 1./255, shear_range = 0.2,zoom_range = 0.2, horizontal_flip = True)
test_dataset = image.ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'CovidDataset/Train',
target_size = (224,224),
batch_size = 32,
class_mode = 'binary')
validation_generator = test_dataset.flow_from_directory(
'CovidDataset/Val',
target_size = (224,224),
batch_size = 32,
class_mode = 'binary')
Found 224 images belonging to 2 classes.
Found 60 images belonging to 2 classes.
وعند تمثيل الصور الممعزّز، سيكون حجم الصور (224،224) وسنأخذ حجم دفعة التدريب 32 ونقوم بتدريب عينات التدريب، ، وسنطبق 10 دورات epochs وبكل دورة 8 خطوات وذلك من خلال التابع fit_generator الموجود في مكتبة كيراس للتدريب مع البيانات المعززة [9] .
يُستخدم عدد الخطوات في الدورة steps per epoch عند توليد بيانات التدريب المعززة عشوائياً فيكون حجم عينات التدريب غير ثابت فهو معامل يعبر عن عدد العينات في الدورة ويستخدم لمعرفة نهاية الدورة وبداية الدورة التالية.
بإمكانكم أن تجربوا تغيير قيم المعاملات الأساسية hyper parameters فربما تعطي نتائج أفضل.
hist_new = model.fit_generator(
train_generator,
steps_per_epoch=8,
epochs = 10,
validation_data = validation_generator,
validation_steps=2
)

summary=hist.history
print(summary)

يمكننا حفظ النموذج لإعادة استخدامه كما هو موضح في التعليمة البرمجية التالية:
model.save("model_covid.h5")
وأخيراً انتهى تدريب النموذج وحفظه يمكننا الآن اختباره على العينات التي لم يتدرب عليها كما يلي:
print(model.evaluate_generator(validation_generator))
فنرى النتيجة أن الدقة 96.6% وهي دقة جيدة، لكن يمكن تحسينها أكثر وأكثر، لأن الغاية القضاء على انتشار المرض فلا نريد تنبؤ خاطئ بحالة المريض.

مصفوفة الالتباس Confusion Matrix
لتوضيح نتائج نماذج التصنيف الثنائي يمكننا أن نرسم مصفوفة الالتباس حيث يتبين من خلالها نسبة الحالات التي توقع فيها النموذج بشكل صحيح وكذلك تبين الحالات التي فشل النموذج فيها بتوقع الخرج الصحيح.
يتوضح الشكل المعتمد لمصفوفة الالتباس كما يلي:
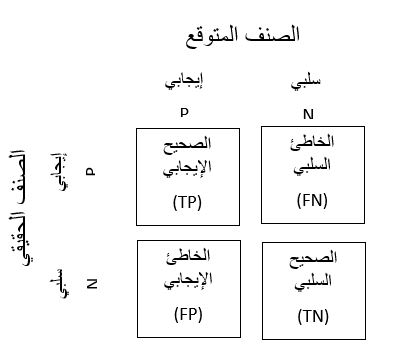
تعبر P إيجابي عن أن العينة تنتمي إلى الصنف وليكن الصنف “مصاب بالكوفيد” و تعبر N سلبي عن أن العينة لا تنتمي إلى الصنف أي “غير مصاب بالكوفيد”
TP عن الحالات المصابة والتي تنبأ النموذج بأنها مصابة، و TN عن الحالات غير المصابة والتي تنبأ النموذج بأنها غير مصابة. أي TP وTN تعبر عن نجاح النموذج في التنبؤ لذلك يجب أن تكون قيمهما كبيرة.
أما FN تعبر عن الحالات المصابة والتي تنبأ النموذج بأنها غير مصابة، و FP تعبر عن الحالات غير المصابة والتي تنبأ النموذج بأنها مصابة. وبالتالي يجب أن تكون قيمهما أقل ما يمكن.
لكتابة الشفرة البرمجية التي تنشئ مصفوفة الالتباس سنستخدم وحدة التعامل مع نظام التشغيل OS وذلك للحصول على مسارات الصور من مجموعة بيانات الاختبار وسنعرّف القائمة Y_test لتخزين قيم التصنيف التي تنبأ بها النموذج والقائمة Y_actual لتخزين قيم التصنيف الحقيقية للصور حيث تعبر القيمة “0” عن أن الصنف مصاب بالكوفيد-19 والقيمة “1” غير مصاب.
import os
train_generator.class_indices
y_actual, y_test = [],[]
سنمر على كل صورة من مجموعة الصور الطبيعية غير المصابة بالكوفيد-19 ونحولها إلى مصفوفة لتمريرها إلى تابع التنبؤ للنموذج Predict ونخزن قيمة التنبؤ في القائمة y_test من خلال تابع append أما قائمة Y_acutal سنخزن فيها القيمة “1” لأنها تعبر عن الصنف غير المصاب بالكوفيد-19.
for i in os.listdir("./CovidDataset/Val/Normal/"):
img=image.load_img("./CovidDataset/Val/Normal/"+i,target_size=(224,224))
img=image.img_to_array(img)
img=np.expand_dims(img,axis=0)
pred=model.predict_classes(img)
y_test.append(pred[0,0])
y_actual.append(1)
وكذلك الأمر بالنسبة للصور المصابة نمر على كل واحدة منها ونأخذ قيمة تنبؤ النموذج بالصنف ونخزنه في قائمة y_test ونخزن في القائمة Y_actual القيمة “0” لأنها تعبر عن الصنف المصاب.
for i in os.listdir("./CovidDataset/Val/Covid/"):
img=image.load_img("./CovidDataset/Val/Covid/"+i,target_size=(224,224))
img=image.img_to_array(img)
img=np.expand_dims(img,axis=0)
pred=model.predict_classes(img)
y_test.append(pred[0,0])
y_actual.append(0)
ثم نحول القوائم إلى مصفوفات لسهولة التعامل معها.
y_actual=np.array(y_actual)
y_test=np.array(y_test)
سنستخدم مكتبة سكي للتعلم sklearn للحصول على مصفوفة الالتباس ولإظهارها بالطريقة المعروفة نقوم بتضمين مكتبة إظهار البيانات الإحصائية seaborn.
from sklearn.metrics import confusion_matrix
import seaborn as sns
cn=confusion_matrix(y_actual,y_test)
sns.heatmap(cn,cmap="plasma",annot=True) #0: Covid ; 1: Normal
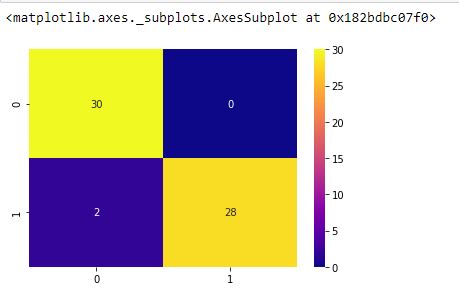
عند تفسير مصفوفة الالتباس ، نلاحظ أنّه من بين 30 مريضاً مصاباً بـالكوفيد، استطاع النموذج التنبؤ بشكل صحيح ب 30 شخصاً مريضاً و كانت قيمة التصنيفات الخاطئة لمرضى الكوفيد معدومة أي تساوي 0، وقام النموذج بتصنيف 28 مريضًا غير مصاب بالكوفيد بشكل صحيح، وأخطأ النموذج بتصنيف شخصين غير مصابين بالكوفيد على أنهم مصابين. إذاً نتائج النموذج جيدة لكن لا بدّ من تحسينها.
يمكنكم الاطلاع على كامل الشيفرة البرمجية في مستودع الجيت هب الخاص بموقع الذكاء الاصطناعي باللغة العربية.
الخاتمة
تمكن التعلم العميق من تحديد الإصابة بداء الكوفيد-19 من خلال مجموعة بيانات محدودة، تتألف مجموعة البيانات من صور صدرية مأخوذة بالأشعة السينية.
تم تطبيق تقانة تعزيز البيانات لزيادة عدد عينات التدريب، وبُني نموذج شبكة الطي العصبونية الذي يحتوي طبقات الطي لاستخلاص الميزات من الصور ويحتوي طبقات التصنيف حيث كانت المسألة عبارة عن تصنيف ثنائي، أعطت النتائج دقة جيدة بلغت 96.4% وبما أن المسألة طبية فنحتاح إلى تحسين النموذج لزيادة الدقة وتحقيق الهدف بالحد من انتشار داء الكوفيد-19.
يسرني أن أرى تعليقاتكم حول هذا المقال في عرض التعليقات في الأسفل.
المراجع
1-https://bing.com/covid/local/syria
2- https://github.com/ieee8023/covid-chestxray-dataset.
3- https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia.
4-https://towardsdatascience.com/detecting-covid-19-using-deep-learning-262956b6f981
5- https://aiinarabic.com/convolutions-with-opencv-and-python/.
6-https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
7-https://blog.paperspace.com/data-augmentation-for-object-detection-rotation-and-shearing/
8-https://www.tutorialspoint.com/computer_graphics/2d_transformation.htm
9-https://www.pyimagesearch.com/2018/12/24/how-to-use-keras-fit-and-fit_generator-a-hands-on-tutorial/





تعليقان
لقد قمت بعمل تطبيق ويب سابقا للكشف عن امراض الرئة المصابة بفيروس كوفيد 19 سابقا بامكانك الاطلاع عليه في مدونتي
https://iraqprogrammer.wordpress.com/2020/05/20/detection-system-for-covid-19-virus-or-not/
شكرا لاطلاعك.. مع تمنياتنا لك بالتوفيق