التدّقيق العلمي: د. م. حسن قزّاز، م. محمد سرميني
التدّقيق اللّغوي: هبة الله فلّاحة
المحتويات
- مقدّمة
- الشَّبَكَات العُصبُونِيَّة العميقة (Deep Neural Networks (DNNs
- الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة (Recurrent Neural Networks (RNN
- الشَّبَكَات العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى (Long Short-Term Memory (LSTM
- الشَّبَكَة العُصبونِيَّة ذات البوَّابات (Gated Recurrent Unit (GRU
- شَّبَكَات الطَّيّ العُصبُونِيَّة (Convolutional Neural Networks (CNN
- شَّبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة (Recurrent Convolutional Neural Networks (RCNN
- التّطبيق العمليّ
- التَّعَلُّم العميق مُتعدِّد النَّماذج العشوائيَّة ( Random Multimodel Deep Learning (RMDL
- التّعلّم العميق الهرميّ للنّصّ (Hierarchical Deep Learning for Text(HDLTex
- الخاتمة
- المراجع
مقدّمة
يتطلّب النّموّ الهائل في عدد مجموعات البيانات Datasets المعقّدة كلّ عام مزيدًا من التّحسين في أساليب تعلّم الآلة Machine learning لتوفير تصنيف بيانات قويّ ودقيق. في الآونة الأخيرة حقّقت تقنيّات التّعلّم العميق Deep Learning نتائج أفضل مقارنة بخوارزميّات تعلُّم الآلة، بسبب قدرتها على التّعامل مع مجموعات البيانات الكبيرة والمعقّدة؛ حيث أظهرت هذه التّقنيات أداءً فائقًا في العديد من المجالات مثل: تحليل الآراء Sentiment Analysis وتصنيف النّصوص Text Classification، وغيرها من المهام المعقّدة.[1]
إنّ أهمّ المزايا الرئيسيّة لتقنيّات التّعلّم العميق المستخدمة في تصنيف النّص هي قدرتها على التّعلم الذّاتيّ للميزات من البيانات الأوّليّة، ممّا يلغي الحاجة إلى هندسة المزايا Feature Engineering يدويًّا.
سنتحدث في مقالنا عن أهمّ تقنيّات التّعلّم العميق المستخدمة في تصنيف النّصوص وهي :
- الشَّبَكَات العُصبُونِيَّة العميقة (Deep Neural Networks (DNNs
- الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة (Recurrent Neural Networks (RNNs
- الشَّبَكَات العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى (Long Short-Term Memory (LSTM
- الشَّبَكَات العُصبُونِيَّة ذات البوَّابات (Gated Recurrent Unit (GRU
- شَّبَكَات الطَّيّ العُصبُونِيَّة (Convolutional Neural Networks (CNN
- شَّبَكَات الطَّيّ العُصبُونِيَّة الإرجاعِيَّة (Recurrent Convolutional Neural Networks (RCNNs
- التَّعَلُّم العميق مُتعدِّد النَّماذج العشوائيَّة ( Random Multimodel Deep Learning (RMDL
- التّعلّم العميق الهرميّ للنّص (Hierarchical Deep Learning for Text(HDLTex
ملاحظة : سنقوم باستخدام مجموعة البيانات 20newsgroup، وهي متوفّرة ضمن مجموعات البيانات في مكتبة اس-كي للتعلّم sklearn.
تضمّ مجموعة البيانات حوالي 18000 مشاركة لمجموعة أخبار تتحدّث حول 20 موضوعًا مقسّمة إلى مجموعتين فرعيّتين: واحدة للتّدريب (أو التّطوير) والأخرى للاختبار (أو لتقييم الأداء).[2]
الشَّبَكَات العُصبُونِيَّة العميقة (Deep Neural Networks (DNNs
ما هي الشَّبَكَات العُصبُونِيَّة العميقة ؟
هي إحدى أنواع الشَّبَكَات العُصبُونِيَّة الاصطناعيّة (ANN) التي تتكوّن من طبقات متعدٌدة من الخلايا العُصبُونِيَّة.
يطلق عليهم اسم “عميقة” لأنّ بنية الشَّبَكَات العُصبُونِيَّة العميقة تتكوّن من عدد كبير من الطّبقات، و تتكوّن كلّ طبقة من عدّة خلايا عصبونيّة مترابطة، وتتراكم الطّبقات فوق بعضها البعض، حيث تتّصل كلّ طبقة layer مع طبقة واحدة سابقة لها و طبقة واحدة تالية لها.
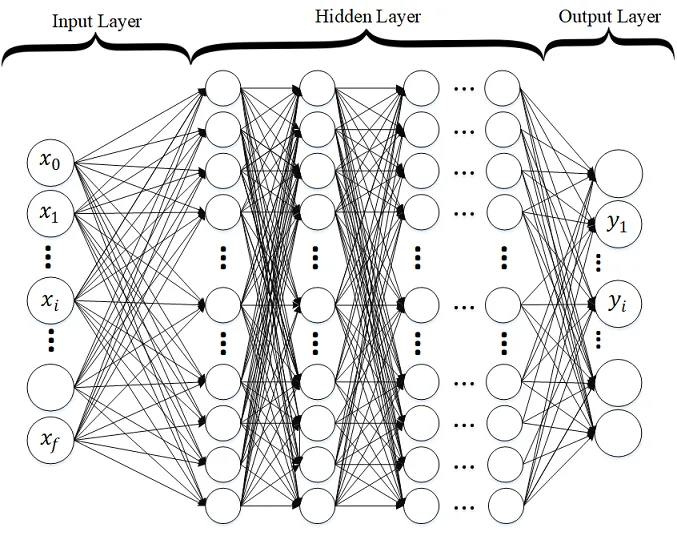
تكون طبقة الدّخل input layer عبارة عن متّجه تضمين vector embedding كما هو موضّح في الشّكل (1).
أمّا الخلايا العُصبُونِيَّة الموجودة في طبقة الخرج فعددها يساوي عدد الفئات في التّصنيف متعدّد الفئات multi-class classification وخليّة عُصبُونِيَّة واحدة فقط للتّصنيف الثّنائيّ binary classification.
يتطلّب تدريب نموذج الشَّبَكَة العُصبُونِيَّة العميقة عادةً استخدام مجموعة بيانات كبيرة لضبط أوزان وتحيّزات الخلايا العُصبُونِيَّة الفرديّة في كلّ طبقة، يتمّ ذلك باستخدام تقنيّة تسمّى الانتشار الخلفيّ backpropagation، والتي تحسب الخطأ بين النّواتج الفعليّة للشّبكة والمخرجات المتوقّعة، ثمّ تعدّل الأوزان والتّحيّزات لتقليل الخطأ، كما و يُستخدم التّابع الأسّيّ الجيبيّ (سيغمويد) sigmoid أو وحدة التَّصحيح الخطِّيّ Relu كتوابع تنشيط activation functions.
في حالة التّصنيف متعدّد الفئات يجب أن تستخدم طبقة الخرج سوفت ماكس Softmax كتابع تنشيط. [1]
الشّكل (1) يمثل شبكة عُصبُونِيَّة عميقة لمصنّف متعدّد الفئات.
التّطبيق العمليّ
بعد أن تعرّفنا على الشَّبَكَات العُصبُونِيَّة العميقة، سوف نقوم ببناء نموذج من خلال مجموعة من الخطوات البسيطة، وبالاستعانة بمجموعة البيانات 20newsgroup باستخدام لغة البرمجة بايثون Python.
إذا كنت ترغب في رؤية الشّيفرات البرمجيّة كاملة، يمكنك العثور عليه عبر هذا الرّابط.[6]
وفيما يلي خطوات العمل :
- نقوم باستدعاء المكتبات والتّوابع و الحزم packages التي سنتعامل معها، و أهمّها حزمة datasets و التّابع metrics من مكتبة اس-كي للتعلّم sklearn، و كلّ من التّابع Droupout والتّابع Dense من الحزمة layers الموجودة ضمن مكتبة كيراس keras و مكتبة بايثون العدديَّة numpy، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]:
from sklearn.datasets import fetch_20newsgroups
from keras.layers import Dropout, Dense
from keras.models import Sequential
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from sklearn import metrics
2. تحميل مجموعة البيانات النّصيّة 20newsgroup من مكتبة اس-كي للتعلّم sklearn ثمّ تقسيمها إلى مجموعات تدريب واختبار X_train, X_test, y_train, y_test، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]:
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
X_train = newsgroups_train.data
X_test = newsgroups_test.data
y_train = newsgroups_train.target
y_test = newsgroups_test.target
3. تحويل النّصوص في مجموعة البيانات إلى صيغة رقميّة حتى يتمكّن النّموذج من التّعامل معها، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، قمنا بتحويل النّصّ إلى صيغة تردُّد الكلمة – تردُّد المُستند العكسيّ Term Frequency-Inverse Document Frequency (TF-IDF)؛ و هو مقياس إحصائي يُقيّم مدى صلة كلمة ما بمستند ضمن عدّة مستندات، حيث يتمّ ذلك عن طريق ضرب مقياسين هما: عدد مرّات ظهور الكلمة في المستند، وتردّد المستند العكسيّ للكلمة عبر مجموعة من المستندات.
def TFIDF(X_train, X_test,MAX_NB_WORDS=75000):
vectorizer_x = TfidfVectorizer(max_features=MAX_NB_WORDS)
X_train = vectorizer_x.fit_transform(X_train).toarray()
X_test = vectorizer_x.transform(X_test).toarray()
print("tf-idf with",str(np.array(X_train).shape[1]),"features")
return (X_train,X_test)
X_train_tfidf, X_test_tfidf = TFIDF(X_train,X_test)
4. نقوم ببناء نموذج الشَّبَكَة العُصبُونِيَّة العميقة DNN باستخدام مكتبة كيراس keras كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، يقوم التّابع Build_Model_DNN_Text ببناء الشّبكة عن طريق استقبال مجموعة من المدخلات وهي: عدد الفئات nClasses لتحديد عدد الخلايا العصبونيّة في طبقة الخرج، ويكون عددها 20 حسب مجموعة البيانات لدينا، أمّا شكل البيانات المدخلة shape فهو لتحديد عدد الخلايا العصبونيّة في طبقة الدّخل والذي يمثّل عدد المزايا features، ويتمّ تحديده من خلال شكل البيانات بعد تحويلها باستخدام TF-IDF كما في الخطوة رقم 3، أمّا الطّبقات الخفيّة nLayers فعددها 4، و في كلّ منها 512 خليّة عصبونيّة، كما أنّنا استخدمنا تابع التّنشيط Relu في الطّبقات الخفيّة و تابع التّنشيط سوفت ماكس softmax في طبقة الخرج؛ لأنّ النّموذج هنا يُصنّف لعدّة فئات. التّابع summary يسرد ملخّص النّموذج كما هو موضّح في الشّكل (2):
def Build_Model_DNN_Text(shape, nClasses, dropout=0.5):
"""
buildModel_DNN_Tex(shape, nClasses,dropout)
Build Deep neural networks Model for text classification
Shape is input feature space
nClasses is number of classes
"""
model = Sequential()
node = 512 # number of nodes
nLayers = 4 # number of hidden layer
model.add(Dense(node,input_dim=shape,activation='relu'))
model.add(Dropout(dropout))
for i in range(0,nLayers):
model.add(Dense(node,input_dim=node,activation='relu'))
model.add(Dropout(dropout))
model.add(Dense(nClasses, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model_DNN = Build_Model_DNN_Text(X_train_tfidf.shape[1], 20)
model_DNN.summary()
يوضّح الشّكل (2) ملخّص نموذج DNN الذي قمنا ببنائه.
| Model: “sequential_1” _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_6 (Dense) (None, 512) 38400512 dropout_5 (Dropout) (None, 512) 0 dense_7 (Dense) (None, 512) 262656 dropout_6 (Dropout) (None, 512) 0 dense_8 (Dense) (None, 512) 262656 dropout_7 (Dropout) (None, 512) 0 dense_9 (Dense) (None, 512) 262656 dropout_8 (Dropout) (None, 512) 0 dense_10 (Dense) (None, 512) 262656 dropout_9 (Dropout) (None, 512) 0 dense_11 (Dense) (None, 20) 10260 ================================================================= Total params: 39,461,396 Trainable params: 39,461,396 Non-trainable params: 0 _________________________________________________________________ |
5. نقوم بتدريب النّموذج باستخدام بيانات التّدريب X_train_tfidf, y_train، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]. يستقبل التّابع fit مجموعة من المعاملات وهي : بيانات التّدريب X_train_tfidf, y_train ، بيانات التّحقّق validation_data، عدد دورات التّدريب epochs، حجم الدّفعة batch_size و verbose الذي يتمّ من خلاله تحديد الخرج الذي سيظهر أثناء تدريب النّموذج، تمّ تعيين القيمة 2 حيث سيظهر فقط عدد الدّورة الحاليّة مثال: Epoch 2/10، Epoch 1/10،..الخ كما هو موضّح في الشّكل(3).
model_DNN.fit(X_train_tfidf, y_train,
validation_data=(X_test_tfidf, y_test),
epochs=10,
batch_size=128,
verbose=2)
يوضّح الشّكل (3) الخرج النّاتج من عمليّة تدريب نموذج DNN على البيانات، حيث يمثّل مقدار الخسارة loss ومدى سوء توقّع النّموذج لمثال واحد من مجموعة بيانات التّدريب، الدّقّة accuracy تمثّل مقدار دقّة النّموذج على بيانات التّدريب، val_loss تمثّل مدى سوء توقّع النّموذج لمثال واحد من مجموعة بيانات التّحقّق و تمثّل val_accuracy مقدار دقّة النّموذج على بيانات التّحقّق.
على مدار جميع الدّورات المحدّدة للنّموذج كلّما زادت قيمة accuracy و تناقصت قيمة loss يكون أفضل والعكس ليس صحيحًا، أمّا بخصوص قيم كلّ من val_accuracy و val_loss فلها 3 حالات لا بدّ من ذكرها لفهم أداء النّموذج، وهي كالآتي:
- إذا كانت قيمة val_loss تزداد وقيمة val_acc تتناقص، هذا يعني أنّ النّموذج لا يتعلّم بل يحفظ قيم التّدريب، أي أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val_loss تزداد و قيمة val_acc تزداد أيضًا، هذا يعني أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val loss تتناقص وقيمة val_acc تزداد، هذا يعني أنّ النّموذج المبنيّ يتعلّم ويعمل بشكل جيّد.
| Epoch 1/10 89/89 – 39s – loss: 2.7524 – accuracy: 0.1137 – val_loss: 1.8437 – val_accuracy: 0.3614 – 39s/epoch – 443ms/step Epoch 2/10 89/89 – 35s – loss: 1.4153 – accuracy: 0.4815 – val_loss: 1.0858 – val_accuracy: 0.6322 – 35s/epoch – 388ms/step Epoch 3/10 89/89 – 35s – loss: 0.6719 – accuracy: 0.7561 – val_loss: 0.8082 – val_accuracy: 0.7681 – 35s/epoch – 390ms/step Epoch 4/10 89/89 – 35s – loss: 0.3183 – accuracy: 0.8958 – val_loss: 0.8342 – val_accuracy: 0.7858 – 35s/epoch – 392ms/step Epoch 5/10 89/89 – 35s – loss: 0.1588 – accuracy: 0.9495 – val_loss: 0.8589 – val_accuracy: 0.7995 – 35s/epoch – 390ms/step Epoch 6/10 89/89 – 35s – loss: 0.1225 – accuracy: 0.9648 – val_loss: 0.9616 – val_accuracy: 0.7851 – 35s/epoch – 390ms/step Epoch 7/10 89/89 – 35s – loss: 0.0888 – accuracy: 0.9739 – val_loss: 0.9427 – val_accuracy: 0.8008 – 35s/epoch – 391ms/step Epoch 8/10 89/89 – 35s – loss: 0.0616 – accuracy: 0.9831 – val_loss: 1.0256 – val_accuracy: 0.7953 – 35s/epoch – 393ms/step Epoch 9/10 89/89 – 34s – loss: 0.0627 – accuracy: 0.9836 – val_loss: 1.0260 – val_accuracy: 0.7869 – 34s/epoch – 387ms/step Epoch 10/10 89/89 – 35s – loss: 0.0453 – accuracy: 0.9878 – val_loss: 1.0428 – val_accuracy: 0.7939 – 35s/epoch – 390ms/step <keras.callbacks.History at 0x7f467d508910> |
6. نقوم بتقييم دقّة نموذج DNN باستخدام التّابع classification_report كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]:
predicted = model_DNN.predict(X_test_tfidf).argmax(axis=1)
print(metrics.classification_report(y_test, predicted))
ويكون الخرج كما هو موضّح في الشّكل (4)، وهو عبارة عن قيمة كلّ من: التنبُّؤ الإيجابيّ Precision، حساسيّة التنبُّؤ Recall، المتوسّط التّوافقيّ للتنبُّؤ الإيجابيّ و حساسية التنبُّؤ f1-score، و الدّاعم support لكلّ فئة من فئات التّصنيف (لاحظ في الشّكل (4) عدد الصّفوف من 0 إلى 19 وهي عدد الفئات 20 فئة).
- تعبّر قيمة التنبُّؤ الإيجابيّ Precision عن نسبة (tp / tp + fp) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصّحيح و fp قيمة التنبُّؤ الإيجابيّ الخاطئ؛ تستخدم للتّعبير عن قدرة المصنّف على عدم تسمية عيّنة سلبيّة على أنّها إيجابيّة.
- تعبّر قيمة حساسيّة التنبُّؤ Recall عن نسبة (tp / tp + fn) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصّحيح و fn قيمة التنبُّؤ السّلبي الخاطئ؛ تستخدم للتّعبير عن قدرة المصنّف على إيجاد جميع العيّنات الإيجابيّة.
- المتوسّط التّوافقيّ للتنبُّؤ الإيجابيّ و حساسيّة التنبُّؤ f1-score، أفضل قيمة لها هي 1 واسوأ قيمة هي 0.
- الدّاعم support هو عدد تكرارات كلّ فئة في y_test.
نلاحظ هنا أنّ دقّة accuracy نموذج الشَّبَكَات العُصبُونِيَّة العميقة DNN لمجموعة البيانات المستخدمة هي 79%.
| 236/236 [==============================] – 12s 49ms/step precision recall f1-score support 0 0.79 0.76 0.77 319 1 0.61 0.74 0.67 389 2 0.70 0.68 0.69 394 3 0.53 0.83 0.64 392 4 0.83 0.70 0.76 385 5 0.82 0.74 0.78 395 6 0.75 0.85 0.80 390 7 0.89 0.84 0.86 396 8 0.95 0.93 0.94 398 9 0.98 0.82 0.90 397 10 0.98 0.95 0.96 399 11 0.94 0.89 0.91 396 12 0.71 0.67 0.69 393 13 0.88 0.73 0.80 396 14 0.90 0.88 0.89 394 15 0.78 0.91 0.84 398 16 0.73 0.88 0.80 364 17 0.99 0.74 0.85 376 18 0.81 0.56 0.67 310 19 0.58 0.67 0.62 251 accuracy 0.79 7532 macro avg 0.81 0.79 0.79 7532 weighted avg 0.81 0.79 0.80 7532 |
الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة (Recurrent Neural Networks (RNN
ما هي الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة؟
هي إحدى الشَّبَكَات العُصبُونِيَّة المصمّمة لمعالجة البيانات المتسلسلة حيث يعتمد الدّخل الحاليّ على المدخلات السّابقة، ممّا يجعلها مناسبة لمهامّ معالجة اللّغة الطّبيعيّة NLP والتّعرّف على الكلام، حيث يكون سياق الكلمات أو الأصوات السّابقة مهمًّا في فهم الكلمة الحاليّة.
السّمة الرّئيسية للشّبكة العُصبُونِيَّة الإرجاعِيَّة RNN هي أنّها تحتوي على حلقة تغذية راجعة في بنيتها، ممّا يسمح لها باستخدام الخرج السّابق كدخل حاليّ، تخلق حلقة التّغذية الرّاجعة نوعًا من الذّاكرة قصيرة المدى في الشّبكة ممّا يسمح لها بالحفاظ على معلومات حول السّياق؛ هذا ما يجعل التنبّؤ بالبيانات التالية أكثر دقّة.
إنّ الوقت الذي يتمّ فيه الاحتفاظ بالمعلومات حول البيانات السّابقة غير ثابت، ولكنّه يعتمد على الأوزان المخصّصة لها.
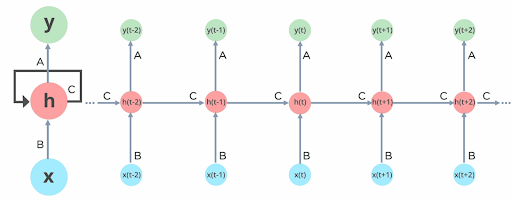
يوضّح الشّكل (5) بنية الشّبكة العُصبُونِيَّة الإرجاعيّة، حيث تعتبر X قيمة الدّخل و h تعبّر عن الطّبقة الخفيّة و y تعبّر عن قيمة الخرج،
أما A, B ,C فهي تعبّر عن المعاملات التي تؤثّر على خرج النّموذج [5].
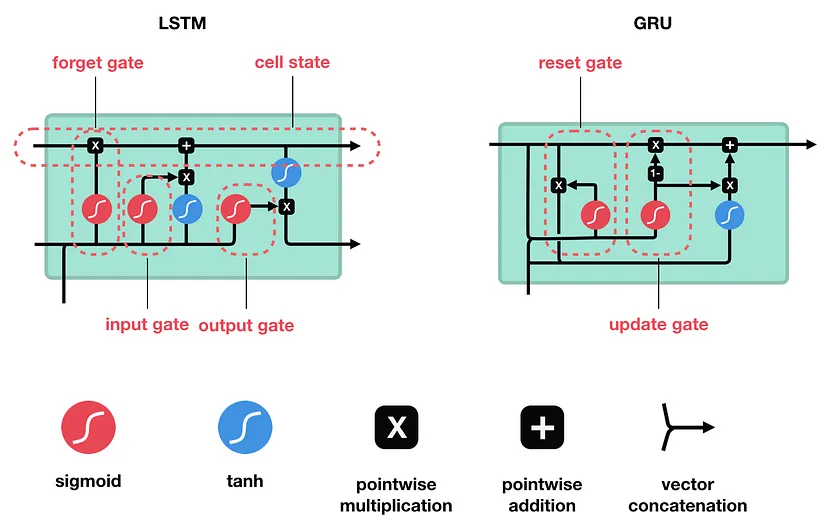
الشَّبَكَات العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى (Long Short-Term Memory (LSTM
ما هي الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى LSTM؟
تعتبر الشَّبَكَات ذات الذّاكرة الطّويلة قصيرة المدى LSTM نوعًا محسّنًا من الشَّبَكَات العصبونيّة الإرجاعيّة، ظهرت للمرّة الأولى على يد العالمَين جوزيف هورخيتر و يورغن شميتوبر Sepp Hochreiter & Jürgen Schmidhuber في العام 1997.
وكان الهدف الرّئيسيّ من تصميمها هو تفادي مشاكل الشَّبَكَات العصبونيّة الإرجاعيّة والحصول على نتائج أفضل.[4]
يوضّح الشّكل (6) بنية الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى .
الشَّبَكَة العُصبونِيَّة ذات البوَّابات (Gated Recurrent Unit (GRU
ما هي الشَّبَكَة العُصبونِيَّة ذات البوَّابات ؟
هي تطوير للشّبكة العُصبُونِيَّة الإرجاعِيَّة، تمّ تقديمها بواسطة Kyunghyun Cho et al في عام 2014.
تتشابه وحدات الشَّبَكَة العُصبونِيَّة ذات البوَّابات مع الشَّبَكَات العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى (LSTM) في بعض الحالات، و لها مزايا تفوق (LSTM). حيث تستخدم GRU ذاكرة أقلّ وأسرع من LSTM، ومع ذلك فإنّ LSTM أكثر دقّة عند استخدام مجموعات البيانات التّسلسليّة.
وهي صمّمت لحلّ مُشكِلة تلاشي المُشتقّ Vanishing Gradient التي تأتي مع الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة (RNN)، من خلال استخدام بوّابتين؛ بوّابة التّحديث update gate وبوّابة إعادة الضّبط reset gate كما هو موضّح في الشّكل (6).
التّطبيق العمليّ
بعد أن تعرّفنا على الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة RNN و الشَّبَكَة العُصبونِيَّة ذات البوَّابات GRU و الشَّبَكَة العُصبُونِيَّة ذات الذَّاكِرة الطَّويلة قصيرة المَدى LSTM، سوف نقوم ببناء نموذج من خلال مجموعة من الخطوات البسيطة وبالاستعانة بمجموعة البيانات 20newsgroup، باستخدام لغة البرمجة بايثون Python.
إذا كنت ترغب في رؤية الشّيفرات البرمجيّة كاملة، يمكنك العثور عليه عبر هذا الرّابط.[6]
وفيما يلي خطوات العمل :
- نقوم باستدعاء المكتبات والتّوابع و الحزم التي سنتعامل معها، و أهمّها حزمة datasets و التابع metrics من مكتبة اس-كي للتّعلّم sklearn، ومجموعة من التّوابع مثل Dropout, Dense, GRU, Embedding من الحزمة layers الموجودة ضمن مكتبة كيراس keras و مكتبة بايثون العدديَّة numpy، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1] :
from keras.layers import Dropout, Dense, GRU, Embedding
from keras.models import Sequential
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from sklearn import metrics
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
from sklearn.datasets import fetch_20newsgroups
2. تحميل مجموعة البيانات النّصيّة من مكتبة اس-كي للتعلُّم sklearn ثمّ تقسيمها إلى مجموعات تدريب واختبار X_train, X_test, y_train, y_test، كما هو موضّح في الشّيفرة البرمجيّة التّالية[1] :
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
X_train = newsgroups_train.data
X_test = newsgroups_test.data
y_train = newsgroups_train.target
y_test = newsgroups_test.target
3. تحويل النّصوص في مجموعة البيانات إلى صيغة رقميّة حتى يتمكّن النّموذج من التّعامل معها، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، حيث يقوم التّابع loadData_Tokenizer باستقبال بيانات التّدريب والاختبار و MAX_NB_WORDS الذي يمثّل أقصى عدد من الكلمات التي سيتمّ استخدامها، القيمة الافتراضيّة له 75000، MAX_SEQUENCE_LENGTH الذي يمثّل أقصى طول لتسلسل الكلمات في النّصّ، القيمة الافتراضيّة له 500. ثمّ تقوم بتحويل البيانات المدخلة إلى صيغة رقميّة يسهل على نموذج RNN فهمها و يتمّ ذلك باستخدام التّوابع Tokenizer و pad_sequences بالإضافة إلى استخدام Glove وهي خوارزميّة تَّعَلُّم بدون إشراف تستخدم للحصول على تمثيلات متّجهيّة للكلمات، يمكنك تحميل الملفّ الخاصّ بالخوارزميّة من الرّابط، ويكون للتّابع 4 مخرجات وهي كالتّالي:
-
- X_train_Glove: مصفوفة تحتوي على بيانات التّدريب بعد تحويلها إلى تمثيل رقميّ باستخدام Glove.
- X_test_Glove: مصفوفة تحتوي على بيانات الاختبار بعد تحويلها إلى تمثيل رقميّ باستخدام GloVe.
- embeddings_index: قاموس يحتوي على تمثيل GloVe لكلّ كلمة، حيث سيتمّ استخدامه لتحويل الكلمات إلى تمثيل GloVe أثناء تدريب نموذج RNN.
- word_index.
def loadData_Tokenizer(X_train, X_test,MAX_NB_WORDS=75000,MAX_SEQUENCE_LENGTH=500):
np.random.seed(7)
text = np.concatenate((X_train, X_test), axis=0)
text = np.array(text)
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(text)
sequences = tokenizer.texts_to_sequences(text)
word_index = tokenizer.word_index
text = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
print('Found %s unique tokens.' % len(word_index))
indices = np.arange(text.shape[0])
# np.random.shuffle(indices)
text = text[indices]
print(text.shape)
X_train = text[0:len(X_train), ]
X_test = text[len(X_train):, ]
embeddings_index = {}
f = open("/kaggle/working/glove.6B.50d.txt", encoding="utf8")
for line in f:
values = line.split()
word = values[0]
try:
coefs = np.asarray(values[1:], dtype='float32')
except:
pass
embeddings_index[word] = coefs
f.close()
print('Total %s word vectors.' % len(embeddings_index))
return (X_train, X_test, word_index,embeddings_index)
X_train_Glove,X_test_Glove, word_index,embeddings_index = loadData_Tokenizer(X_train,X_test)
4. نقوم ببناء نموذج الشَّبَكَات العُصبُونِيَّة الإرجاعيّة RNN باستخدام مكتبة كيراس Keras كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، حيث يقوم التّابع Build_Model_RNN_Text ببناء الشّبكة عن طريق مجموعة من المدخلات: word_index, embeddings_index النّاتجة من الخطوة السّابقة، عدد الفئات nClasses لتحديد عدد الخلايا العصبونيّة في طبقة الخرج، ويكون عددها 20 حسب مجموعة البيانات لدينا، MAX_SEQUENCE_LENGTH أقصى طول لتسلسل الكلمات و تمّ استخدام 500 كقيمة افتراضيّة، EMBEDDING_DIM وهي أبعاد التّضمين، أي عدد الأرقام التي يتمّ استخدامها لتمثيل كلّ كلمة في المجموعة، dropout وهي قيمة الانحراف لتطبيق Dropout الذي يتمّ استخدامه لتجنّب الملاءمة الزّائدة overfitting.
يتمّ استخدام المدخلات word_index, embeddings_index لبناء مصفوفة embedding_matrix التي تحتوي على تمثيلات متّجهيّة للكلمات، ويتمّ استخدام GRU في الطّبقات الخفيّة، كما أنّنا استخدمنا تابع التّنشيط Relu في الطّبقات الخفيّة و تابع التّنشيط سوفت ماكس softmax في طبقة الخرج؛ لأنّ النّموذج هنا يُصنّف لعدّة فئات.
التّابع summary يسرد ملخّص النّموذج كما هو موضّح في الشّكل (7).
def Build_Model_RNN_Text(word_index, embeddings_index, nclasses, MAX_SEQUENCE_LENGTH=500, EMBEDDING_DIM=50, dropout=0.5):
"""
def buildModel_RNN(word_index, embeddings_index, nclasses, MAX_SEQUENCE_LENGTH=500, EMBEDDING_DIM=50, dropout=0.5):
word_index in word index ,
embeddings_index is embeddings index,
nClasses is number of classes,
MAX_SEQUENCE_LENGTH is maximum lenght of text sequences
"""
model = Sequential()
hidden_layer = 3
gru_node = 32
embedding_matrix = np.random.random((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
if len(embedding_matrix[i]) != len(embedding_vector):
print("could not broadcast input array from shape", str(len(embedding_matrix[i])),
"into shape", str(len(embedding_vector)), " Please make sure your"
" EMBEDDING_DIM is equal to embedding_vector file ,GloVe,")
exit(1)
embedding_matrix[i] = embedding_vector
model.add(Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=True))
print(gru_node)
for i in range(0,hidden_layer):
model.add(GRU(gru_node,return_sequences=True, recurrent_dropout=0.2))
model.add(Dropout(dropout))
model.add(GRU(gru_node, recurrent_dropout=0.2))
model.add(Dropout(dropout))
model.add(Dense(256, activation='relu'))
model.add(Dense(nclasses, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model_RNN = Build_Model_RNN_Text(word_index,embeddings_index, 20)
model_RNN.summary()
يوضّح الشّكل (7) ملخّص نموذج RNN الذي قمنا ببنائه.
| Model: “sequential” _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 500, 50) 8960500 gru (GRU) (None, 500, 32) 8064 dropout (Dropout) (None, 500, 32) 0 gru_1 (GRU) (None, 500, 32) 6336 dropout_1 (Dropout) (None, 500, 32) 0 gru_2 (GRU) (None, 500, 32) 6336 dropout_2 (Dropout) (None, 500, 32) 0 gru_3 (GRU) (None, 32) 6336 dropout_3 (Dropout) (None, 32) 0 dense (Dense) (None, 256) 8448 dense_1 (Dense) (None, 20) 5140 ================================================================= Total params: 9,001,160 Trainable params: 9,001,160 Non-trainable params: 0 _________________________________________________________________ |
5. نقوم بتدريب النّموذج باستخدام بيانات التّدريب X_train_Glove, y_train، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، يستقبل التّابع fit مجموعة من المعاملات وهي : بيانات التّدريب X_train_Glove, y_train ، بيانات التّحقق validation_data، عدد دورات التّدريب epochs، حجم الدّفعة batch_size و verbose الذي يتمّ من خلاله تحديد الخرج الذي سيظهر أثناء تدريب النّموذج، تمّ تعيين القيمة 2 حيث سيظهر فقط عدد الدّورة الحاليّة مثال: Epoch 2/10، Epoch 1/10،..الخ، كما هو موضّح في الشّكل (8).
model_RNN.fit(X_train_Glove, y_train,
validation_data=(X_test_Glove, y_test),
epochs=20,
batch_size=128,
verbose=2)
ويكون الخرج النّاتج من عمليّة تدريب النّموذج على البيانات كما هو موضّح في الشّكل (8)، حيث يمثّل مقدار الخسارة loss مدى سوء توقّع النّموذج لمثال واحد من مجموعة بيانات التّدريب، الدّقة accuracy تمثّل مقدار دقّة النّموذج على بيانات التّدريب، val_loss تمثّل مدى سوء توقّع النّموذج لمثال واحد من مجموعة بيانات التّحقق و تمثّل val_accuracy مقدار دقّة النّموذج على بيانات التّحقق.
على مدار جميع الدّورات المحدّدة للنّموذج كلما زادت قيمة accuracy و تناقصت قيمة loss يكون أفضل والعكس ليس صحيحًا، أمّا بخصوص قيم كلّ من val_accuracy و val_loss فلها 3 حالات لا بدّ من ذكرها لفهم أداء النّموذج، وهي كالآتي:
- إذا كانت قيمة val_loss تزداد وقيمة val_acc تتناقص، هذا يعني أنّ النّموذج لا يتعلّم بل يحفظ قيم التّدريب، أي أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val_loss تزداد و قيمة val_acc تزداد أيضًا، هذا يعني أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val loss تتناقص وقيمة val_acc تزداد، هذا يعني أنّ النّموذج المبني يتعلّم ويعمل بشكل جيّد.
| Epoch 1/20 89/89 – 145s – loss: 2.9728 – accuracy: 0.0702 – val_loss: 2.8556 – val_accuracy: 0.1046 – 145s/epoch – 2s/step Epoch 2/20 89/89 – 130s – loss: 2.6248 – accuracy: 0.1394 – val_loss: 2.4282 – val_accuracy: 0.1592 – 130s/epoch – 1s/step Epoch 3/20 89/89 – 130s – loss: 2.1707 – accuracy: 0.2185 – val_loss: 1.9594 – val_accuracy: 0.2666 – 130s/epoch – 1s/step Epoch 4/20 89/89 – 131s – loss: 1.8266 – accuracy: 0.3006 – val_loss: 1.8354 – val_accuracy: 0.3062 – 131s/epoch – 1s/step Epoch 5/20 89/89 – 145s – loss: 1.5793 – accuracy: 0.3685 – val_loss: 1.7396 – val_accuracy: 0.3590 – 145s/epoch – 2s/step Epoch 6/20 89/89 – 139s – loss: 1.4113 – accuracy: 0.4269 – val_loss: 1.7111 – val_accuracy: 0.3906 – 139s/epoch – 2s/step Epoch 7/20 89/89 – 133s – loss: 1.2195 – accuracy: 0.4997 – val_loss: 1.7718 – val_accuracy: 0.4225 – 133s/epoch – 1s/step Epoch 8/20 89/89 – 129s – loss: 1.0565 – accuracy: 0.5736 – val_loss: 1.7723 – val_accuracy: 0.4523 – 129s/epoch – 1s/step Epoch 9/20 89/89 – 130s – loss: 0.9288 – accuracy: 0.6356 – val_loss: 1.7924 – val_accuracy: 0.4778 – 130s/epoch – 1s/step Epoch 10/20 89/89 – 131s – loss: 0.7950 – accuracy: 0.6936 – val_loss: 1.9416 – val_accuracy: 0.4862 – 131s/epoch – 1s/step Epoch 11/20 89/89 – 131s – loss: 0.6877 – accuracy: 0.7355 – val_loss: 2.0137 – val_accuracy: 0.5137 – 131s/epoch – 1s/step Epoch 12/20 89/89 – 131s – loss: 0.5757 – accuracy: 0.7865 – val_loss: 1.9733 – val_accuracy: 0.5449 – 131s/epoch – 1s/step Epoch 13/20 89/89 – 130s – loss: 0.4965 – accuracy: 0.8192 – val_loss: 2.0733 – val_accuracy: 0.5495 – 130s/epoch – 1s/step Epoch 14/20 89/89 – 131s – loss: 0.4387 – accuracy: 0.8390 – val_loss: 2.3023 – val_accuracy: 0.5354 – 131s/epoch – 1s/step Epoch 15/20 89/89 – 131s – loss: 0.4027 – accuracy: 0.8535 – val_loss: 2.2953 – val_accuracy: 0.5596 – 131s/epoch – 1s/step Epoch 16/20 89/89 – 131s – loss: 0.3490 – accuracy: 0.8718 – val_loss: 2.4302 – val_accuracy: 0.5605 – 131s/epoch – 1s/step Epoch 17/20 89/89 – 132s – loss: 0.3315 – accuracy: 0.8792 – val_loss: 2.4822 – val_accuracy: 0.5666 – 132s/epoch – 1s/step Epoch 18/20 89/89 – 139s – loss: 0.2832 – accuracy: 0.8991 – val_loss: 2.6945 – val_accuracy: 0.5576 – 139s/epoch – 2s/step Epoch 19/20 89/89 – 132s – loss: 0.2680 – accuracy: 0.9035 – val_loss: 2.7876 – val_accuracy: 0.5625 – 132s/epoch – 1s/step Epoch 20/20 89/89 – 132s – loss: 0.2483 – accuracy: 0.9119 – val_loss: 2.9371 – val_accuracy: 0.5592 – 132s/epoch – 1s/step <keras.callbacks.History at 0x7f82b6722bd0> |
6. نقوم بتقييم دقّة النّموذج باستخدام التّابع classification_report
predicted = model_DNN.predict(X_test_tfidf).argmax(axis=1)
print(metrics.classification_report(y_test, predicted))
ويكون الخرج كما هو موضّح في الشّكل (9)، وهو عبارة عن قيمة كلّ من: التنبُّؤ الإيجابيّ Precision، حساسيّة التنبُّؤ Recall، المتوسط التوافقيّ للتنبُّؤ الإيجابيّ و حساسيّة التنبُّؤ f1-score، و الدّاعم support، لكلّ فئة من فئات التّصنيف (لاحظ في الشّكل (9) عدد الصّفوف من 0 إلى 19 وهي عدد الفئات 20 فئة).
- تعبر قيمة التنبُّؤ الإيجابيّ Precision عن نسبة (tp / tp + fp) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصّحيح و fp قيمة التنبُّؤ الإيجابيّ الخاطئ، وهي تستخدم للتّعبير عن قدرة المصنّف على عدم تسمية عينة سلبيّة على أنّها إيجابيّة.
- تعبر قيمة حساسيّة التنبُّؤ Recall عن نسبة (tp / tp + fn) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصحيح و fn قيمة التنبُّؤ السلبيّ الخاطئ، وهي تستخدم للتّعبير عن قدرة المصنّف على إيجاد جميع العينات الإيجابيّة.
- المتوسط التوافقيّ للتنبُّؤ الإيجابيّ و حساسية التنبُّؤ f1-score، أفضل قيمة لها هي 1 واسوأ قيمة هي 0.
- الدّاعم support هو عدد تكرارات كلّ فئة في y_test.
نلاحظ هنا أنّ دقّة نموذج الشَّبَكَات العُصبُونِيَّة الإرجاعيّة RNN لمجموعة البيانات المستخدمة هي 56%، وهي نسبة سيئة حيث يدلّ ذلك على أنّ النّموذج غير قادر على تصنيف نسبة 46% من الحالات في مجموعة الاختبار بشكل صحيح، لاحظ في الشكل (8) أنّ خسارة التّدريب loss في تناقص و خسارة التّحقق val_loss في ازدياد، وهذا يدلّ على أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
| 236/236 [==============================] – 38s 154ms/step precision recall f1-score support 0 0.62 0.60 0.61 319 1 0.42 0.42 0.42 389 2 0.41 0.43 0.42 394 3 0.39 0.43 0.41 392 4 0.41 0.48 0.45 385 5 0.68 0.37 0.48 395 6 0.60 0.62 0.61 390 7 0.55 0.74 0.63 396 8 0.77 0.60 0.67 398 9 0.79 0.81 0.80 397 10 0.97 0.78 0.87 399 11 0.80 0.64 0.71 396 12 0.35 0.53 0.42 393 13 0.69 0.44 0.54 396 14 0.43 0.57 0.49 394 15 0.66 0.66 0.66 398 16 0.43 0.59 0.50 364 17 0.88 0.64 0.74 376 18 0.47 0.40 0.43 310 19 0.33 0.31 0.32 251 accuracy 0.56 7532 macro avg 0.58 0.55 0.56 7532 weighted avg 0.59 0.56 0.56 7532 |
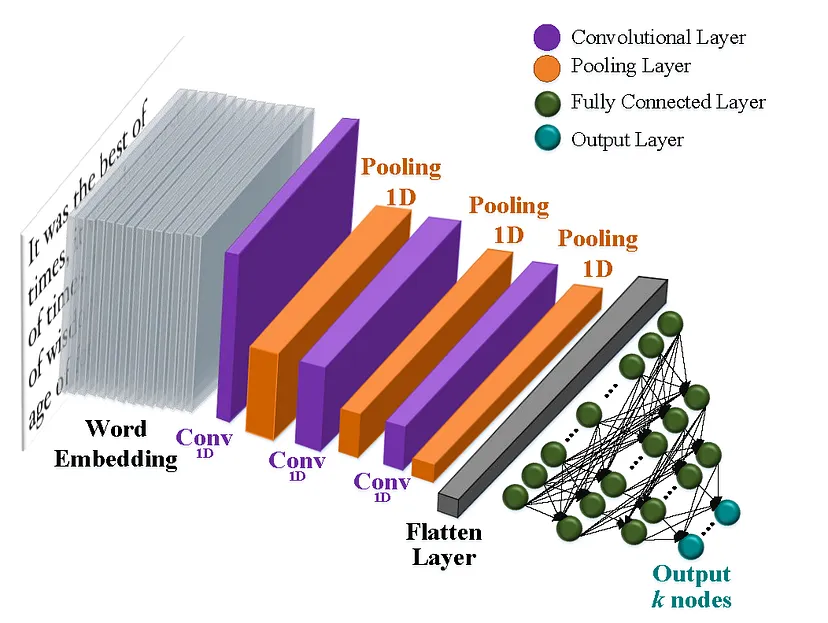
شَّبَكَات الطَّيّ العُصبُونِيَّة (Convolutional Neural Networks (CNN
ما هي شَبَكَات الطَّيّ العُصبُونِيَّة ؟
شَبَكَات الطَّيّ العُصبُونِيَّة هي إحدى معماريّات التّعلّم العميق تمّ تطويرها في البداية لمعالجة الصّور، وحقّقت نتائج مذهلة في التّعرّف على كائن من فئة محدّدة مسبقًا (على سبيل المثال قطة، درّاجة، إلخ..).
السّبب في ذلك هو قدرتها على تعلّم الميزات تلقائيًّا، ممّا يجعلها أيضًا أداة مفيدة لمهامّ معالجة اللّغة الطّبيعيّة مثل تصنيف النّصوص .
في عمليّة تصنيف النّصوص _باستخدام شَّبَكَات الطَّيّ العُصبُونِيَّة_ يتمّ تمثيل الدّخل كمصفوفة، و يتمّ الحصول على مصفوفة التّضمين من خلال تقنيّات مثل Word2Vec أو GloVe.
يتمّ بعد ذلك إدخال مصفوفات التّضمين إلى شبَكَات الطَّيّ العُصبُونِيَّة لاستخراج الميزات المهمّة لعمليّة التّصنيف.
عادةً ما تتضمّن شَّبَكَات الطَّيّ العُصبُونِيَّة عمليّتين تستخدمان في استخراج المميزات: عملِيَّة جِداء الطَّيّ convolution والتّجميع pooling.
يعدّ Max pooling الذي يقوم بالتّجمِيع وفقَ القيمةِ الكُبرى، أكثر أنواع التّجميع شيوعًا المستخدمة في تصنيف النّص، الهدف من استخدام التّجميع تقليل حجم المخرجات من طبقة إلى أخرى في الشّبكة، ممّا يساعد على تقليل التّعقيد الحسابيّ للنّموذج.
أخيرًا، يتمّ استخدام الطّبقات المتّصلة بالكامل Fully connected layer في الجزء الأخير من بنية شَّبَكَات الطَّيّ العُصبُونِيَّة لإجراء التّنبّؤ النّهائيّ، حيث تأخذ هذه الطّبقات الميّزات التي تعلّمتها الطّبقات التّلافيفيّة والتّجميعيّة وتستخدمها للتنبّؤ بتسمية فئة نصّ الإدخال.
التّطبيق العمليّ
بعد أن تعرّفنا على شَبَكَات الطَّيّ العُصبُونِيَّة CNN، سوف نقوم ببناء نموذج من خلال مجموعة من الخطوات البسيطة وبالاستعانة بمجموعة البيانات 20newsgroup باستخدام لغة البرمجة بايثون Python.
إذا كنت ترغب في رؤية الشّيفرات البرمجيّة كاملة، يمكنك العثور عليه عبر هذا الرّابط.[6]
وفيما يلي خطوات العمل :
- نقوم باستدعاء المكتبات والتّوابع والحزم التي سنتعامل معها، و أهمها مكتبة اس-كي للتعلّم sklearn، ومكتبة كيراس keras و مكتبة بايثون العدديَّة numpy، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]:
from keras.layers import Dropout, Dense,Input,Embedding,Flatten, MaxPooling1D, Conv1D
from keras.models import Sequential,Model
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from sklearn import metrics
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
from sklearn.datasets import fetch_20newsgroups
from keras.layers import Concatenate
2. تحميل مجموعة البيانات النّصيّة من مكتبة اس-كي للتعلُّم sklearn ثمّ تقسيمها إلى مجموعات تدريب و اختبار X_train, X_testt, y_train, y_test، كما هو موضّح في الشّيفرة البرمجيّة التّالية :
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
X_train = newsgroups_train.data
X_test = newsgroups_test.data
y_train = newsgroups_train.target
y_test = newsgroups_test.target
3. تحويل النّصوص في مجموعة البيانات إلى صيغة رقميّة حتى يتمكّن النّموذج من التّعامل معها، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، حيث يقوم التّابع loadData_Tokenizer باستقبال بيانات التّدريب والاختبار و MAX_NB_WORDS الذي يمثّل أقصى عدد من الكلمات التي سيتمّ استخدامها، القيمة الافتراضيّة له 75000، MAX_SEQUENCE_LENGTH الذي يمثّل أقصى طول لتسلسل الكلمات في النصّ، القيمة الافتراضيّة له 500. ثمّ تقوم بتحويل البيانات المدخلة إلى صيغة رقميّة يسهل على نموذج RNN فهمها و يتمّ ذلك باستخدام التّوابع Tokenizer و pad_sequences بالإضافة إلى استخدام Glove وهي خوارزمية تَّعَلُّم بدون إشرافِ تستخدم للحصول على تمثيلات متجهيّة للكلمات، يمكنك تحميل الملفّ الخاصّ بالخوارزميّة من الرّابط، ويكون للتابع 4 مخرجات وهي كالتالي:
-
- X_train_Glove: مصفوفة تحتوي على بيانات التّدريب بعد تحويلها إلى تمثيل رقميّ باستخدام Glove.
- X_test_Glove: مصفوفة تحتوي على بيانات الاختبار بعد تحويلها إلى تمثيل رقميّ باستخدام GloVe.
- embeddings_index: قاموس يحتوي على تمثيل GloVe لكلّ كلمة، حيث يتمّ استخدامه لتحويل الكلمات إلى تمثيل GloVe أثناء تدريب نموذج CNN.
- word_index.
def loadData_Tokenizer(X_train, X_test,MAX_NB_WORDS=75000,MAX_SEQUENCE_LENGTH=500):
np.random.seed(7)
text = np.concatenate((X_train, X_test), axis=0)
text = np.array(text)
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(text)
sequences = tokenizer.texts_to_sequences(text)
word_index = tokenizer.word_index
text = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
print('Found %s unique tokens.' % len(word_index))
indices = np.arange(text.shape[0])
# np.random.shuffle(indices)
text = text[indices]
print(text.shape)
X_train = text[0:len(X_train), ]
X_test = text[len(X_train):, ]
embeddings_index = {}
f = open("/kaggle/working/glove.6B.50d.txt", encoding="utf8")
for line in f:
values = line.split()
word = values[0]
try:
coefs = np.asarray(values[1:], dtype='float32')
except:
pass
embeddings_index[word] = coefs
f.close()
print('Total %s word vectors.' % len(embeddings_index))
return (X_train, X_test, word_index,embeddings_index)
X_train_Glove,X_test_Glove, word_index,embeddings_index = loadData_Tokenizer(X_train,X_test)
4. نقوم ببناء نموذج شَّبَكَات الطَّيّ العُصبُونِيَّة CNN باستخدام مكتبة كيراس Keras كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، حيث يقوم التّابع Build_Model_CNN_Text ببناء الشّبكة عن طريق مجموعة من المدخلات: word_index, embeddings_index الناتجة من الخطوة السّابقة، عدد الفئات nClasses لتحديد عدد الخلايا العصبونيّة في طبقة الخرج، ويكون عددها 20 حسب مجموعة البيانات لدينا، MAX_SEQUENCE_LENGTH أقصى طول لتسلسل الكلمات و تمّ استخدام 500 كقيمة افتراضيّة. EMBEDDING_DIM وهي أبعاد التّضمين؛ أي عدد الأرقام التي يتمّ استخدامها لتمثيل كلّ كلمة في المجموعة، dropout وهي قيمة الانحراف لتطبيق Dropout الذي يتمّ استخدامه لتجنّب الملاءمة الزّائدة overfitting.
يتمّ استخدام المدخلات word_index, embeddings_index لبناء مصفوفة embedding_matrix التي تحتوي على تمثيلات متجهيّة للكلمات، ويتمّ استخدام التوابع Dense و Conv1D لبناء طبقات النموذج الخفيّة، كما أنّنا استخدمنا تابع التّنشيط Relu في الطّبقات الخفيّة و تابع التّنشيط سوفت ماكس softmax في طبقة الخرج؛ لأنّ النّموذج هنا يُصنّف لعدّة فئات.
التابع summary يسرد ملخّص النموذج كما هو موضّح في الشّكل (11).
def Build_Model_CNN_Text(word_index, embeddings_index, nclasses, MAX_SEQUENCE_LENGTH=500, EMBEDDING_DIM=50, dropout=0.5):
"""
def buildModel_CNN(word_index, embeddings_index, nclasses, MAX_SEQUENCE_LENGTH=500, EMBEDDING_DIM=50, dropout=0.5):
word_index in word index ,
embeddings_index is embeddings index, look at data_helper.py
nClasses is number of classes,
MAX_SEQUENCE_LENGTH is maximum lenght of text sequences,
EMBEDDING_DIM is an int value for dimention of word embedding look at data_helper.py
"""
model = Sequential()
embedding_matrix = np.random.random((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
if len(embedding_matrix[i]) !=len(embedding_vector):
print("could not broadcast input array from shape",str(len(embedding_matrix[i])),
"into shape",str(len(embedding_vector))," Please make sure your"
" EMBEDDING_DIM is equal to embedding_vector file ,GloVe,")
exit(1)
embedding_matrix[i] = embedding_vector
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=True)
# applying a more complex convolutional approach
convs = []
filter_sizes = []
layer = 5
print("Filter ",layer)
for fl in range(0,layer):
filter_sizes.append((fl+2))
node = 128
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
for fsz in filter_sizes:
l_conv = Conv1D(node, kernel_size=fsz, activation='relu')(embedded_sequences)
l_pool = MaxPooling1D(5)(l_conv)
#l_pool = Dropout(0.25)(l_pool)
convs.append(l_pool)
l_merge = Concatenate(axis=1)(convs)
l_cov1 = Conv1D(node, 5, activation='relu')(l_merge)
l_cov1 = Dropout(dropout)(l_cov1)
l_pool1 = MaxPooling1D(5)(l_cov1)
l_cov2 = Conv1D(node, 5, activation='relu')(l_pool1)
l_cov2 = Dropout(dropout)(l_cov2)
l_pool2 = MaxPooling1D(30)(l_cov2)
l_flat = Flatten()(l_pool2)
l_dense = Dense(1024, activation='relu')(l_flat)
l_dense = Dropout(dropout)(l_dense)
l_dense = Dense(512, activation='relu')(l_dense)
l_dense = Dropout(dropout)(l_dense)
preds = Dense(nclasses, activation='softmax')(l_dense)
model = Model(sequence_input, preds)
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model_CNN = Build_Model_CNN_Text(word_index,embeddings_index, 20)
model_CNN.summary()
يوضّح الشّكل(11) ملخّص نّموذج CNN الذي قمنا ببنائه.
| Filter 5 Model: “model” __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 500)] 0 [] embedding (Embedding) (None, 500, 50) 8960500 [‘input_1[0][0]’] conv1d (Conv1D) (None, 499, 128) 12928 [’embedding[0][0]’] conv1d_1 (Conv1D) (None, 498, 128) 19328 [’embedding[0][0]’] conv1d_2 (Conv1D) (None, 497, 128) 25728 [’embedding[0][0]’] conv1d_3 (Conv1D) (None, 496, 128) 32128 [’embedding[0][0]’] conv1d_4 (Conv1D) (None, 495, 128) 38528 [’embedding[0][0]’] max_pooling1d (MaxPooling1D) (None, 99, 128) 0 [‘conv1d[0][0]’] max_pooling1d_1 (MaxPooling1D) (None, 99, 128) 0 [‘conv1d_1[0][0]’] max_pooling1d_2 (MaxPooling1D) (None, 99, 128) 0 [‘conv1d_2[0][0]’] max_pooling1d_3 (MaxPooling1D) (None, 99, 128) 0 [‘conv1d_3[0][0]’] max_pooling1d_4 (MaxPooling1D) (None, 99, 128) 0 [‘conv1d_4[0][0]’] concatenate (Concatenate) (None, 495, 128) 0 [‘max_pooling1d[0][0]’, ‘max_pooling1d_1[0][0]’, ‘max_pooling1d_2[0][0]’, ‘max_pooling1d_3[0][0]’, ‘max_pooling1d_4[0][0]’] conv1d_5 (Conv1D) (None, 491, 128) 82048 [‘concatenate[0][0]’] dropout (Dropout) (None, 491, 128) 0 [‘conv1d_5[0][0]’] max_pooling1d_5 (MaxPooling1D) (None, 98, 128) 0 [‘dropout[0][0]’] conv1d_6 (Conv1D) (None, 94, 128) 82048 [‘max_pooling1d_5[0][0]’] dropout_1 (Dropout) (None, 94, 128) 0 [‘conv1d_6[0][0]’] max_pooling1d_6 (MaxPooling1D) (None, 3, 128) 0 [‘dropout_1[0][0]’] flatten (Flatten) (None, 384) 0 [‘max_pooling1d_6[0][0]’] dense (Dense) (None, 1024) 394240 [‘flatten[0][0]’] dropout_2 (Dropout) (None, 1024) 0 [‘dense[0][0]’] dense_1 (Dense) (None, 512) 524800 [‘dropout_2[0][0]’] dropout_3 (Dropout) (None, 512) 0 [‘dense_1[0][0]’] dense_2 (Dense) (None, 20) 10260 [‘dropout_3[0][0]’] ================================================================================================== Total params: 10,182,536 Trainable params: 10,182,536Non-trainable params: 0 __________________________________________________________________________________________________ |
5. نقوم بتدريب النّموذج باستخدام بيانات التدريب X_train_Glove, y_train، كما هو موضّح في الشّيفرة البرمجيّة التّالية[1]، يستقبل التّابع fit مجموعة من المعاملات وهي : بيانات التّدريب X_train_Glove, y_train ، بيانات التّحقق validation_data، عدد دورات التّدريب epochs، حجم الدّفعة batch_size و verbose الذي يتمّ من خلاله تحديد الخرج الذي سيظهر أثناء تدريب النّموذج، تمّ تعيين القيمة 2 حيث سيظهر فقط عدد الدّورة الحاليّة مثال: Epoch 2/10، Epoch 1/10،..الخ، كما هو موضّح في الشّكل (12).
model_CNN.fit(X_train_Glove, y_train,
validation_data=(X_test_Glove, y_test),
epochs=15,
batch_size=128,
verbose=2)
يكون الخرج النّاتج من عمليّة تدريب النّموذج على البيانات كما هو موضّح في الشّكل (12)، حيث يمثّل مقدار الخسارة loss مدى سوء توقع النّموذج لمثال واحد من مجموعة بيانات التّدريب، الدّقة accuracy تمثل مقدار دقة النّموذج على بيانات التدريب، val_loss تمثل مدى سوء توقّع النموذج لمثال واحد من مجموعة بيانات التّحقق و تمثّل val_accuracy مقدار دقة النّموذج على بيانات التّحقق.
على مدار جميع الدّورات المحدّدة للنّموذج كلما زادت قيمة accuracy و تناقصت قيمة loss يكون أفضل والعكس ليس صحيحًا، أمّا بخصوص قيم كلّ من val_accuracy و val_loss فلها 3 حالات لا بدّ من ذكرها لفهم أداء النّموذج، وهي كالآتي:
- إذا كانت قيمة val_loss تزداد وقيمة val_acc تتناقص، هذا يعني أنّ النّموذج لا يتعلّم بل يحفظ قيم التّدريب، أي أنّ النّموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val_loss تزداد و قيمة val_acc تزداد أيضًا، هذا يعني أنّ النموذج في حالة الملاءمة الزّائدة overfitting.
- إذا كانت قيمة val loss تتناقص وقيمة val_acc تزداد، هذا يعني أنّ النموذج المبنيّ يتعلم ويعمل بشكل جيد.
| Epoch 1/15 89/89 – 141s – loss: 2.9482 – accuracy: 0.0760 – val_loss: 2.7416 – val_accuracy: 0.1802 – 141s/epoch – 2s/step Epoch 2/15 89/89 – 136s – loss: 2.2198 – accuracy: 0.2262 – val_loss: 2.2013 – val_accuracy: 0.3320 – 136s/epoch – 2s/step Epoch 3/15 89/89 – 149s – loss: 1.6653 – accuracy: 0.3871 – val_loss: 1.7990 – val_accuracy: 0.4809 – 149s/epoch – 2s/step Epoch 4/15 89/89 – 156s – loss: 1.2528 – accuracy: 0.5315 – val_loss: 1.5942 – val_accuracy: 0.5526 – 156s/epoch – 2s/step Epoch 5/15 89/89 – 167s – loss: 0.9694 – accuracy: 0.6399 – val_loss: 1.3932 – val_accuracy: 0.6179 – 167s/epoch – 2s/step Epoch 6/15 89/89 – 165s – loss: 0.7278 – accuracy: 0.7350 – val_loss: 1.2392 – val_accuracy: 0.6389 – 165s/epoch – 2s/step Epoch 7/15 89/89 – 156s – loss: 0.5872 – accuracy: 0.7857 – val_loss: 1.1369 – val_accuracy: 0.6673 – 156s/epoch – 2s/step Epoch 8/15 89/89 – 144s – loss: 0.4472 – accuracy: 0.8389 – val_loss: 0.9778 – val_accuracy: 0.7038 – 144s/epoch – 2s/step Epoch 9/15 89/89 – 136s – loss: 0.3209 – accuracy: 0.8906 – val_loss: 0.9571 – val_accuracy: 0.7014 – 136s/epoch – 2s/step Epoch 10/15 89/89 – 130s – loss: 0.2684 – accuracy: 0.9055 – val_loss: 0.9227 – val_accuracy: 0.7102 – 130s/epoch – 1s/step Epoch 11/15 89/89 – 128s – loss: 0.2116 – accuracy: 0.9299 – val_loss: 0.8992 – val_accuracy: 0.7094 – 128s/epoch – 1s/step Epoch 12/15 89/89 – 128s – loss: 0.1650 – accuracy: 0.9433 – val_loss: 0.8858 – val_accuracy: 0.7223 – 128s/epoch – 1s/step Epoch 13/15 89/89 – 128s – loss: 0.1484 – accuracy: 0.9514 – val_loss: 0.8532 – val_accuracy: 0.7319 – 128s/epoch – 1s/step Epoch 14/15 89/89 – 128s – loss: 0.1096 – accuracy: 0.9652 – val_loss: 0.8398 – val_accuracy: 0.7333 – 128s/epoch – 1s/step Epoch 15/15 89/89 – 128s – loss: 0.0987 – accuracy: 0.9684 – val_loss: 0.8754 – val_accuracy: 0.7245 – 128s/epoch – 1s/step <keras.callbacks.History at 0x7fe761763c90> |
6. نقوم بتقييم دقّة النّموذج باستخدام تابع classification_report
predicted = model_CNN.predict(X_test_Glove)
predicted = np.argmax(predicted, axis=1)
print(metrics.classification_report(y_test, predicted))
ويكون الخرج كما هو موضّح في الشّكل (13)، وهو عبارة عن قيمة كلّ من: التنبُّؤ الإيجابيّ Precision، حساسية التنبُّؤ Recall، المتوسط التوافقيّ للتنبُّؤ الإيجابي و حساسية التنبُّؤ f1-score، و الدّاعم support، لكلّ فئة من فئات التصنيف (لاحظ في الشكل (13) عدد الصّفوف من 0 إلى 19 وهي عدد الفئات 20 فئة).
- تعبر قيمة التنبُّؤ الإيجابيّ Precision عن نسبة (tp / tp + fp) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصحيح و fp قيمة التنبُّؤ الإيجابي الخاطئ؛ تستخدم للتعبير عن قدرة المصنف على عدم تسمية عينة سلبيّة على أنها إيجابيّة.
- تعبر قيمة حساسية التنبُّؤ Recall عن نسبة (tp / tp + fn) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصّحيح و fn قيمة التنبُّؤ السلبيّ الخاطئ؛ تستخدم للتعبير عن قدرة المصنف على إيجاد جميع العينات الإيجابيّة.
- المتوسط التوافقيّ للتنبُّؤ الإيجابيّ و حساسية التنبُّؤ f1-score، أفضل قيمة لها هي 1 واسوأ قيمة هي 0.
- الدّاعم support هو عدد تكرارات كلّ فئة في y_test.
نلاحظ هنا أنّ دقّة نموذج شبَكَات الطَّيّ العُصبُونِيَّة لمجموعة البيانات المستخدمة هي 72%، وهي نسبة جيدة حيث يدلّ ذلك على أنّ النموذج قادر على تصنيف نسبة 72% من الحالات في مجموعة الاختبار بشكل صحيح.
مقارنةً بالنماذج التي قمنا بتدريبها سابقًا، يعتبر نموذج شَبَكَات الطَّيّ العُصبُونِيَّة أقلّ دقة من نموذج الشَبَكَات العُصبُونِيَّة العميقة (79%)، و أعلى دقة من نموذج الشَبَكَات العُصبُونِيَّة الإرجاعيّة (56%).
| 236/236 [==============================] – 17s 73ms/step precision recall f1-score support 0 0.70 0.67 0.68 319 1 0.54 0.75 0.63 389 2 0.60 0.70 0.65 394 3 0.46 0.59 0.52 392 4 0.72 0.40 0.52 385 5 0.70 0.69 0.70 395 6 0.85 0.62 0.72 390 7 0.82 0.80 0.81 396 8 0.89 0.86 0.87 398 9 0.90 0.87 0.88 397 10 0.96 0.92 0.94 399 11 0.84 0.86 0.85 396 12 0.64 0.58 0.61 393 13 0.83 0.80 0.81 396 14 0.81 0.84 0.82 394 15 0.89 0.72 0.80 398 16 0.70 0.77 0.74 364 17 0.97 0.74 0.84 376 18 0.54 0.63 0.58 310 19 0.40 0.60 0.48 251 accuracy 0.72 7532 macro avg 0.74 0.72 0.72 7532 weighted avg 0.75 0.72 0.73 7532 |
شَّبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة (Recurrent Convolutional Neural Networks (RCNN
ما هي شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة؟
هي نوع من بنية الشبكة العُصبُونِيَّة التي يمكن استخدامها لتصنيف النّصوص، يجمع RCNN بين نقاط القوّة في الشَّبَكَات العُصبُونِيَّة الإرجاعيّة (RNN) وشَبَكَات الطَّيّ العُصبُونِيَّة (CNN).
السمة الرّئيسية لشَّبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة هي التقاط المعلومات السياقيّة contextual information عن طريق الشَّبَكَة العُصبُونِيَّة الإرجاعيّة RNN و إنشاء تمثيل للنصّ باستخدام شَّبَكَة الطَّيّ العُصبُونِيَّة CNN.
التّطبيق العمليّ
بعد أن تعرّفنا على شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة، سوف نقوم ببناء نموذج من خلال مجموعة من الخطوات البسيطة وبالاستعانة بمجموعة البيانات ،20newsgroup باستخدام لغة البرمجة بايثون Python.
إذا كنت ترغب في رؤية الشّيفرات البرمجيّة كاملة، يمكنك العثور عليه عبر هذا الرابط.[6]
وفيما يلي خطوات العمل :
- نقوم باستدعاء المكتبات والتّوابع التي سنتعامل معها، و أهمها مكتبة اس-كي للتعلّم sklearn، ومكتبة كيراس keras و مكتبة بايثون العدديَّة numpy، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1] :
from keras.layers import Dropout, Dense,Input,Embedding,Flatten, MaxPooling1D, Conv1D
from keras.models import Sequential,Model
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from sklearn import metrics
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
from sklearn.datasets import fetch_20newsgroups
from keras.layers import Concatenate
2. تحميل مجموعة البيانات النّصيّة من مكتبة اس-كي للتعلُّم sklearn ثمّ تقسيمها إلى مجموعات تدريب و اختبار X_train, X_test, y_train, y_test ، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]:
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
X_train = newsgroups_train.data
X_test = newsgroups_test.data
y_train = newsgroups_train.target
y_test = newsgroups_test.target
3. تحويل النّصوص في مجموعة البيانات إلى صيغة رقميّة حتى يتمكّن النّموذج من التّعامل معها، كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]، حيث يقوم التابع loadData_Tokenizer باستقبال بيانات التدريب والاختبار و MAX_NB_WORDS الذي يمثل أقصى عدد من الكلمات التي سيتمّ استخدامها، القيمة الافتراضيّة له 75000، MAX_SEQUENCE_LENGTH الذي يمثل أقصى طول لتسلسل الكلمات في النص، القيمة الافتراضيّة له 500، ثمّ تقوم بتحويل البيانات المدخلة إلى صيغة رقميّة يسهل على نموذج RNN فهمها و يتمّ ذلك باستخدام التوابع Tokenizer و pad_sequences بالإضافة إلى استخدام Glove وهي خوارزمية تَّعَلُّم بدون إشراف تستخدم للحصول على تمثيلات متجهيّة للكلمات، يمكنك تحميل الملفّ الخاص بالخوارزمية من الرّابط، ويكون للتابع 4 مخرجات وهي كالتالي:
-
- X_train_Glove: مصفوفة تحتوي على بيانات التدريب بعد تحويلها إلى تمثيل رقميّ باستخدام Glove.
- X_test_Glove: مصفوفة تحتوي على بيانات الاختبار بعد تحويلها إلى تمثيل رقميّ باستخدام GloVe.
- embeddings_index: قاموس يحتوي على تمثيل GloVe لكلّ كلمة، حيث يتمّ استخدامه لتحويل الكلمات إلى تمثيل GloVe أثناء تدريب نموذج RNN.
- word_index.
def loadData_Tokenizer(X_train, X_test,MAX_NB_WORDS=75000,MAX_SEQUENCE_LENGTH=500):
np.random.seed(7)
text = np.concatenate((X_train, X_test), axis=0)
text = np.array(text)
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(text)
sequences = tokenizer.texts_to_sequences(text)
word_index = tokenizer.word_index
text = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
print('Found %s unique tokens.' % len(word_index))
indices = np.arange(text.shape[0])
# np.random.shuffle(indices)
text = text[indices]
print(text.shape)
X_train = text[0:len(X_train), ]
X_test = text[len(X_train):, ]
embeddings_index = {}
f = open("/kaggle/working/glove.6B.50d.txt", encoding="utf8")
for line in f:
values = line.split()
word = values[0]
try:
coefs = np.asarray(values[1:], dtype='float32')
except:
pass
embeddings_index[word] = coefs
f.close()
print('Total %s word vectors.' % len(embeddings_index))
return (X_train, X_test, word_index,embeddings_index)
X_train_Glove,X_test_Glove, word_index,embeddings_index = loadData_Tokenizer(X_train,X_test)
4. نقوم ببناء نموذج شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة RCNN باستخدام مكتبة كيراس keras كما هو موضّح في الشّيفرة البرمجيّة التّالية [1]،حيث يقوم التابع Build_Model_RCNN_Text ببناء الشبكة عن طريق مجموعة من المدخلات: word_index, embeddings_index الناتجة من الخطوة السابقة، عدد الفئات nClasses لتحديد عدد الخلايا العصبونيّة في طبقة الخرج، ويكون عددها 20 حسب مجموعة البيانات لدينا، MAX_SEQUENCE_LENGTH أقصى طول لتسلسل الكلمات و تمّ استخدام 500 كقيمة افتراضيّة، EMBEDDING_DIM وهي أبعاد التضمين؛ أي عدد الأرقام التي يتمّ استخدامها لتمثيل كلّ كلمة في المجموعة. يتمّ استخدام المدخلات word_index, embeddings_index لبناء مصفوفة embedding_matrix التي تحتوي على تمثيلات متجهيّة للكلمات، ويتمّ استخدام تابع LSTM في الطبقات الخفيّة، كما أنّنا استخدمنا تابع التّنشيط Relu في الطّبقات الخفيّة و تابع التّنشيط سوفت ماكس softmax في طبقة الخرج؛ لأنّ النّموذج هنا يُصنّف لعدّة فئات.
التابع summary يسرد ملخّص النموذج كما هو موضّح في الشّكل (14).
def Build_Model_RCNN_Text(word_index, embeddings_index, nclasses, MAX_SEQUENCE_LENGTH=500, EMBEDDING_DIM=50):
kernel_size = 2
filters = 256
pool_size = 2
gru_node = 256
embedding_matrix = np.random.random((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
if len(embedding_matrix[i]) !=len(embedding_vector):
print("could not broadcast input array from shape",str(len(embedding_matrix[i])),
"into shape",str(len(embedding_vector))," Please make sure your"
" EMBEDDING_DIM is equal to embedding_vector file ,GloVe,")
exit(1)
embedding_matrix[i] = embedding_vector
model = Sequential()
model.add(Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=True))
model.add(Dropout(0.25))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(LSTM(gru_node, return_sequences=True, recurrent_dropout=0.2))
model.add(LSTM(gru_node, return_sequences=True, recurrent_dropout=0.2))
model.add(LSTM(gru_node, return_sequences=True, recurrent_dropout=0.2))
model.add(LSTM(gru_node, recurrent_dropout=0.2))
model.add(Dense(1024,activation='relu'))
model.add(Dense(nclasses))
model.add(Activation('softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model_RCNN = Build_Model_RCNN_Text(word_index,embeddings_index, 20)
model_RCNN.summary()
يوضّح الشّكل (14) ملخّص النّموذج الذي قمنا ببنائه.
| Model: “sequential_1” _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 500, 50) 8960500 dropout_1 (Dropout) (None, 500, 50) 0 conv1d_4 (Conv1D) (None, 499, 256) 25856 max_pooling1d_4 (MaxPooling (None, 249, 256) 0 1D) conv1d_5 (Conv1D) (None, 248, 256) 131328 max_pooling1d_5 (MaxPooling (None, 124, 256) 0 1D) conv1d_6 (Conv1D) (None, 123, 256) 131328 max_pooling1d_6 (MaxPooling (None, 61, 256) 0 1D) conv1d_7 (Conv1D) (None, 60, 256) 131328 max_pooling1d_7 (MaxPooling (None, 30, 256) 0 1D) lstm (LSTM) (None, 30, 256) 525312 lstm_1 (LSTM) (None, 30, 256) 525312 lstm_2 (LSTM) (None, 30, 256) 525312 lstm_3 (LSTM) (None, 256) 525312 dense (Dense) (None, 1024) 263168 dense_1 (Dense) (None, 20) 20500 activation (Activation) (None, 20) 0 ================================================================= Total params: 11,765,256 Trainable params: 11,765,256 Non-trainable params: 0 _________________________________________________________________ |
5. نقوم بتدريب النّموذج باستخدام بيانات التدريب X_train_Glove, y_train، كما هو موضّح في الشّيفرة البرمجيّة التّالية، يستقبل التابع fit مجموعة من المعاملات وهي : بيانات التدريب X_train_Glove, y_train ، بيانات التحقق validation_data، عدد دورات التدريب epochs، حجم الدّفعة batch_size و verbose الذي يتمّ من خلاله تحديد الخرج الذي سيظهر أثناء تدريب النموذج، تمّ تعيين القيمة 2 حيث سيظهر فقط عدد الدّورة الحالية مثال: Epoch 2/10، Epoch 1/10،..الخ، كما هو موضّح في الشّكل (15).
model_RCNN.fit(X_train_Glove, y_train,
validation_data=(X_test_Glove, y_test),
epochs=15,
batch_size=128,
verbose=2)
يوضّح الشّكل(15) الخرج النّاتج من عمليّة تدريب النّموذج على البيانات.
| Epoch 1/15 89/89 – 164s – loss: 2.6803 – accuracy: 0.1121 – val_loss: 2.3751 – val_accuracy: 0.1775 – 164s/epoch – 2s/step Epoch 2/15 89/89 – 157s – loss: 2.1796 – accuracy: 0.2033 – val_loss: 2.0958 – val_accuracy: 0.2369 – 157s/epoch – 2s/step Epoch 3/15 89/89 – 153s – loss: 1.8462 – accuracy: 0.3006 – val_loss: 1.7612 – val_accuracy: 0.3299 – 153s/epoch – 2s/step Epoch 4/15 89/89 – 161s – loss: 1.5602 – accuracy: 0.4002 – val_loss: 1.6437 – val_accuracy: 0.3910 – 161s/epoch – 2s/step Epoch 5/15 89/89 – 159s – loss: 1.2325 – accuracy: 0.5258 – val_loss: 1.6303 – val_accuracy: 0.4553 – 159s/epoch – 2s/step Epoch 6/15 89/89 – 164s – loss: 1.0774 – accuracy: 0.5893 – val_loss: 1.2491 – val_accuracy: 0.5542 – 164s/epoch – 2s/step Epoch 7/15 89/89 – 158s – loss: 0.8888 – accuracy: 0.6665 – val_loss: 1.1723 – val_accuracy: 0.6005 – 158s/epoch – 2s/step Epoch 8/15 89/89 – 161s – loss: 0.7604 – accuracy: 0.7218 – val_loss: 1.1212 – val_accuracy: 0.6433 – 161s/epoch – 2s/step Epoch 9/15 89/89 – 161s – loss: 0.6609 – accuracy: 0.7661 – val_loss: 1.0210 – val_accuracy: 0.6677 – 161s/epoch – 2s/step Epoch 10/15 89/89 – 147s – loss: 0.5661 – accuracy: 0.8018 – val_loss: 1.0671 – val_accuracy: 0.6782 – 147s/epoch – 2s/step Epoch 11/15 89/89 – 148s – loss: 0.4980 – accuracy: 0.8231 – val_loss: 1.0213 – val_accuracy: 0.6985 – 148s/epoch – 2s/step Epoch 12/15 89/89 – 147s – loss: 0.4358 – accuracy: 0.8494 – val_loss: 1.0147 – val_accuracy: 0.7100 – 147s/epoch – 2s/step Epoch 13/15 89/89 – 148s – loss: 0.3818 – accuracy: 0.8698 – val_loss: 1.0580 – val_accuracy: 0.7106 – 148s/epoch – 2s/step Epoch 14/15 89/89 – 146s – loss: 0.3613 – accuracy: 0.8755 – val_loss: 1.0176 – val_accuracy: 0.7307 – 146s/epoch – 2s/step Epoch 15/15 89/89 – 149s – loss: 0.2905 – accuracy: 0.9042 – val_loss: 1.1779 – val_accuracy: 0.7092 – 149s/epoch – 2s/step <keras.callbacks.History at 0x7ff481376290> |
6. نقوم بتقييم دقّة النّموذج باستخدام التابع classification_report
predicted = model_RCNN.predict(X_test_Glove)
predicted = np.argmax(predicted, axis=1)
print(metrics.classification_report(y_test, predicted))
ويكون الخرج كما هو موضّح في الشّكل (16)، وهو عبارة عن قيمة كلّ من: التنبُّؤ الإيجابيّ Precision، حساسية التنبُّؤ Recall، المتوسط التوافقيّ للتنبُّؤ الإيجابيّ و حساسية التنبُّؤ f1-score، و الدّاعم support، لكلّ فئة من فئات التصنيف (لاحظ في الشكل (16) عدد الصفوف من 0 إلى 19 وهي عدد الفئات 20 فئة).
- تعبر قيمة التنبُّؤ الإيجابيّ Precision عن نسبة (tp / tp + fp) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصحيح و fp قيمة التنبُّؤ الإيجابيّ الخاطئ، و هي تستخدم للتعبير عن قدرة المصنف على عدم تسمية عينة سلبية على أنها إيجابيّة.
- تعبرقيمة حساسية التنبُّؤ Recall عن نسبة (tp / tp + fn) حيث tp هي قيمة التنبُّؤ الإيجابيّ الصحيح و fn قيمة التنبُّؤ السلبيّ الخاطئ، و هي تستخدم للتعبير عن قدرة المصنف على إيجاد جميع العينات الإيجابيّة.
- المتوسط التوافقيّ للتنبُّؤ الإيجابيّ و حساسية التنبُّؤ f1-score، أفضل قيمة لها هي 1 واسوأ قيمة هي 0.
- الدّاعم support هو عدد تكرارات كلّ فئة في y_test.
نلاحظ هنا أنّ دقّة نموذج شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة لمجموعة البيانات المستخدمة هي 71%، وهي نسبة جيدة حيث يدلّ ذلك على أنّ النموذج قادر على تصنيف نسبة 71٪ من الحالات في مجموعة الاختبار بشكل صحيح.
مقارنةً بالنماذج التي قمنا بتدريبها سابقًا، يعتبر نموذج شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة متقاربًا في الدّقة مع نموذج شَبَكَات الطَّيّ العُصبُونِيَّة (72%)، وكلاهما أعلى دقة من نموذج الشَبَكَات العُصبُونِيَّة الإرجاعيّة (56%).
| 236/236 [==============================] – 32s 133ms/step precision recall f1-score support 0 0.51 0.62 0.56 319 1 0.48 0.70 0.57 389 2 0.73 0.64 0.68 394 3 0.54 0.73 0.62 392 4 0.58 0.65 0.61 385 5 0.76 0.66 0.71 395 6 0.77 0.73 0.75 390 7 0.68 0.83 0.75 396 8 0.96 0.66 0.78 398 9 0.86 0.84 0.85 397 10 0.97 0.91 0.94 399 11 0.90 0.80 0.84 396 12 0.53 0.54 0.54 393 13 0.89 0.80 0.84 396 14 0.89 0.71 0.79 394 15 0.80 0.81 0.81 398 16 0.66 0.79 0.72 364 17 0.95 0.74 0.83 376 18 0.86 0.38 0.53 310 19 0.34 0.48 0.40 251 accuracy 0.71 7532 macro avg 0.73 0.70 0.71 7532 weighted avg 0.74 0.71 0.72 7532 |
التَّعَلُّم العميق مُتعدِّد النَّماذج العشوائيَّة ( Random Multimodel Deep Learning (RMDL
هي تقنيّة قويّة لتصنيف النّص تتضمّن تدريب نماذج متعدّدة في وقت واحد والجمع بين تنبّؤاتهم لتصنيف النّصوص، تستخدم هذه التّقنية أنواعًا مختلفة من النّماذج مثل شَّبَكَات الطَّيّ العُصبُونِيَّة CNN والشَّبَكَات العُصبُونِيَّة الإرجاعيّة RNN.
تعدّ RMDL مفيدة بشكل خاصّ لمعالجة مجموعات البيانات النّصّيّة الكبيرة والمعقّدة، حيث أنّ استخدام مجموعة متنوّعة من النّماذج يمكن أن يحسّن دقّة التّصنيف.
يوضّح الشكل (17) بنية التَّعَلُّم العميق مُتعدِّد النَّماذج العشوائيَّة (RDML) للتّصنيف؛ يشتمل RMDL على 3 نماذج عشوائيّة، مصنّف DNN على اليسار، ومصنّف Deep CNN في المنتصف، ومصنّف Deep RNN على اليمين (يمكن أن تكون كلّ وحدة من وحدات هذه البنية LSTM أو GRU).
التّعلّم العميق الهرميّ للنّصّ (Hierarchical Deep Learning for Text(HDLTex
تتطلّب مجموعات المستندات الكبيرة أساليب معالجة معلومات محسّنة للبحث عن النّصّ واسترجاعه وتنظيمه.
و يعتبر تصنيف المستندات من أهمّ أساليب معالجة المعلومات، والذي أصبح تطبيقًا مهمًّا للتّعلّم الخاضع للإشراف supervised learning.
في الآونة الأخيرة تدهور أداء المصنّفات التّقليديّة الخاضعة للإشراف مع زيادة عدد الوثائق؛ هذا لأنّه إلى جانب التّزايد المستمرّ في عدد المستندات، كان هناك زيادة في عدد الفئات [1].
تتناول هذه الورقة المشكلة بشكل مختلف عن طريق تصنيف المستندات الحاليّة التي تنظر إلى المشكلة على أنّها تصنيف متعدّد الفئات، بدلًا من ذلك نقوم بإجراء تصنيف هرميّ باستخدام منهجيّة تدعى بالتّعلّم العميق الهرميّ لتصنيف النّصّ (HDLTex).
توظّف HDLTex العديد من بنى التّعلّم العميق لتوفير فهم متخصّص في كلّ مستوى من مستويات التّسلسل الهرميّ للوثائق. [1]
بعد أن قمنا بتدريب مجموعة من النماذج لتصنيف النصوص في مجموعة البيانات 20Newsgroup، سنلخص في نقاط نتيجة كلّ نموذج من النماذج:
- من بين النماذج التي تمّ اختبارها حققت الشَّبَكَات العُصبُونِيَّة العميقة DNN أعلى دقة 79%، يشير هذا إلى أنّ نموذج DNN كان قادرًا على تعلم تمثيلات ذات مغزى لنص الدّخل بشكل فعال وإجراء تنبؤات دقيقة. غالبًا ما تُستخدم بنية DNN في مهام تصنيف النص وقد ثبت أنها تؤدّي أداءً جيدًا في مجموعة واسعة من التطبيقات.
- حققت شَبَكَات الطَّيّ العُصبُونِيَّة CNN دقة بلغت 72%، وهي نسبة أقلّ من دقة نموذج DNN ولكنها جيدة. غالبًا ما تُستخدم شبكات CNN في مهام تصنيف الصور، ولكن تمّ تطبيقها أيضًا على تصنيف النصّ بنجاح.
- حققت شَبَكَات الطَّيّ العُصبُونِيَّة الإرجاعيّة RCNN دقة بلغت 71%، وهي نسبة أقلّ بقليل من شبكة CNN و هي مزيج من CNN و RNN، لقد ثبت أنّ هذا النموذج يعمل بشكل جيد في بعض مهام تصنيف النص، ولكن في هذه الحالة لم يتفوّق على CNN أو DNN.
- أخيرًا حققت الشَّبَكَات العُصبُونِيَّة الإرجاعِيَّة RNN أقلّ دقة 56%، غالبًا ما تُستخدم RNN في مهام معالجة اللغة الطبيعيّة لأنها يمكن أن تتعامل مع البيانات المتسلسلة في نصّ الإدخال، ومع ذلك في هذه الحالة لم يكن أداء RNN جيدًا مثل النماذج الأخرى؛ قد يكون هذا بسبب أنّ GRU ليست فعالة في التقاط التسلسلات بعيدة المدى في النص، والتي قد تكون مهمة للتمييز بين الفئات المختلفة.
بشكل عام حققت الشَّبَكَات العُصبُونِيَّة العميقة DNN أعلى دقة في مجموعة بيانات 20Newsgroup، تليها CNN و RCNN و RNN. ومع ذلك فإنه من الضروري تجربة نماذج متعدّدة للعثور على أفضل نموذج لتطبيق معين.
الخاتمة
تعرّفنا في هذا المقال على عدّة تقنيّات من تقنيّات التّعلم العميق المهمّة لتصنيف النّصوص، وطرق بنائها باستخدام لغة البرمجة بايثون Python.
إنّ التّقنيات الواردة في المقال ليست الوحيدة المستخدمة في تصنيف النّصوص ولكنّها أكثرهم شيوعًا.
إذا كنت ترغب في رؤية الشّيفرات البرمجيّة كاملة، يمكنك العثور عليه عبر هذا الرابط.
المراجع
- [1]:Deep Learning Techniques for Text Classification
- [2]:https://scikit-learn.org/0.19/datasets/twenty_newsgroups.html
- [3]:Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
- [4]:الشّبكة العصبونيَّة ذات الذَّاكرة الطَّويلة قصيرة المدى Long-Short Term Memory LSTM
- [5]:Building a Text Classifier using RNN
- [6]:Deep Learning Techniques for Text Classification