
المحتويات
- المقدّمة
- الرؤية الحاسوبيّة
- تقنيات الرؤية الحاسوبيّة :
- تصنيف الصور.
- تحديد الكائنات.
- تتبع الكائن.
- التجزئة الدلاليّة
- تجزئة المثيل
- الخاتمة
- المراجع
المقدمة
إذا كنت من محبي أفلام الخيال العلميّ، ربما تستهويك فكرة روبوت يستطيع التعرّف على الأشياء من حوله. في عام 2008 أصدرت بيكسار فيلم WALL-E وهو عبارة عن روبوت لديه عينان، مع تجاهل فكرة أنّ الرّوبوتات بشكلٍ عام يمكن أن تفكر/تتحدّث مثلنا أو أن يكون لديها أيّ نوعٍ من المعرفة أو المشاعر، هل تستطيع الحواسيب التعرّف على من حولها إذا زوّدناها بكاميرا رقميّة؟
قبل أن نبحر في عالم الرّوبوتات أو الحواسيب، انظر لغرفتك تأملها هل تتعرّف على الأشياء بالغرفة، هل لاحظت كيف يبدو أثاثك؟ وكيف تعرّفت على كل هذه الأشياء وفرّقت بينها ولم يختلط عليك الأمر، بحيث أن لا تكلم جهاز الكمبيوتر على أنه صديقك وألا تخرج من النافذة ظنًّا منك على أنها باب الغرفة ….. إلخ.
كلّ هذا من خلال عين الإنسان لأنها واحدةٌ من الأجهزة الأكثر تعقيدًا وإبداعا، والتي تساعد بشكلٍ كبيرٍ جدّاً على جعل الصورة التي يراها الإنسان واضحةً ونقيةً.
حسناً الأمر ليس بهذه السهولة، فالحاسوب لا يرى الأشياء بنفس الطريقة التي نراها. بشكل مختصر الحاسب الرقميّ يستطيع معالجة الأرقام 0، 1، وباستخدام هذه الوحدات البنائيّة بإمكاننا تمثيل أشياء أكثر تعقيدًا مثل الأعداد الطبيعيّة، النسبيّة والحقيقيّة، كذلك يمكننا تمثيل الصور بنفس الطريقة وذلك باستخدام ثلاثة ألوان رئيسيّة وهي الأحمر، الأخضر والأزرق. بإعطاء أرقام معينة لكلّ لون، وبذلك يمكننا تمثيل أيّ صورة في مجال رؤيتنا.

الشكل -1 تمثيل الصورة الملوّنة
الرؤية الحاسوبيّة (Computer vision)
هي من مجالات علوم الحوسبة الحديثة، تساعد هذه التقنيّة على رؤية العالم وتحليل البيانات المرئيّة ثمّ اتخاذ قراراتٍ منها أو اكتساب فهم حول البيئة والعالم، بالإضافة إلى تحديد ومعالجة الأشياء مثل الصور ومقاطع الفيديو بنفس الطريقة التي يَفعلها البشر. حتى وقتٍ قريبٍ كانت الرؤية الحاسوبيّة تعمل بقدرة محدودة، إلّا أنَّ كمية البيانات الرقميّة الهائلة التي نُنتجها اليوم مثّلت إحدى العوامل الرئيسيّة الدّافعة وراء تطوّر الرؤية الحاسوبيّة لتصبح واحدة من أهم مجالات البحث في التعلم العميق في الوقت الحاليّ.
لمَ كلّ هذه الأبحاث في مجال الرؤية الحاسوبيّة؟
الجواب الأكثر وضوحًا هو أنّ هناك مجموعة من التطبيقات المفيدة المشتقة من هذا المجال وهي سريعة التطوّر، سنذكر فيما يلي بعضاً منها:
- التعرّف على الوجه (Face recognition): إنّ تطبيقات الــ Snapchat و Facebook تستخدم خوارزميّات تحديد الوجه (اكتشاف الوجه) لتطبيق الفلاتر والتعرّف عليك في الصور. تأتي الصين في طليعة استخدام هذه التقنيّة بين جميع دول العالم، حيث تستخدمها في عمل الشرطة وبوّابات الدّفع ونقاط التفتيش الأمنيّة في المطار، والمواقع الحكوميّة وغيرها من التطبيقات الأخرى.
- استرجاع الصور (Image retrieval): تستخدم صور جوجل Google الاستعلامات القائمة على المحتوى للبحث في الصور ذات الصلة، فتقوم الخوارزميّات بتحليل المحتوى في صورة الاستعلام وإرجاع النتائج بناءً على أفضل محتوى مطابق.
- الألعاب وعناصر التحكم (Gaming and controls): منتج تجاريّ رائع في الألعاب، مثلًا تطوير واجهات قائمة على الرؤية للعديد من ألعاب الكمبيوتر مما يسمح لللاعب بالتحرّك أو الإيماءة للتأثير على اللعبة، بدلًا من الضغط على الأزرار، فقد تقلد الشخصيات في اللعبة تلك الحركات أو تستجيب وفقًا لذلك فتسمح هذه الواجهات بألعاب مثيرة وجذابة.
- المراقبة: تنتشر كاميرات المراقبة في كلّ مكان في الأماكن العامة، وتُستخدم لاكتشاف السلوكيّات المريبة.
- القياسات الحيويّة: لا تزال مطابقة بصمات الأصابع وقزحيّة العين والوجه وغيرها، من الأساليب الشائعة في تحديد الهويّة باستخدام القياسات الحيويّة.
- السيارات الذكيّة: تظل الرؤية هي المصدر الرئيسيّ للمعلومات للكشف عن إشارات المرور والأضواء وغيرها من الميزات المرئيّة.
أدّت التطوّرات الأخيرة في الشبكاتالعصبونية وأساليب التعلُّم العميق، إلى تطوير أداء أنظمة التعرّف المرئيّ الحديثة بشكلٍ كبير. سنتحدث عن تقنيات الرؤية الحاسوبيّة الرئيسيّة، بالإضافة إلى نماذج وتطبيقات التعلم العميق الرئيسيّة المستخدمة فيها.
1- تصنيف الصور (Image Classification)

الشكل -2 تصنيف صور ملتقطة
هو عمليّة التعرّف على محتوى صورة ما وتصنيفه إلى صنف أو أكثر من الكائنات أو الأشياء على هيئة مخرجات، على سبيل المثال (قطة، كلب، طائر، غروب الشمس، سيارة.. إلخ) أو توقع احتماليّة وجود تلك الأصناف التي تصف الصورة على أفضل وجهٍ ممكن (P_cat = 80%, P_dog =15%, P_bird = 5% …).
بالتالي مسألة تصنيف الصور آلت على النحو التالي:
- الدّخل: N صور من مجموعة بيانات التدريب، كلٌّ منها مُصنَّف لواحد من K صنف مختلف
- استخدام مجموعة التدريب هذه لتدريب المصنِّف على تعلم الأصناف ومعرفة شكل كلِّ صنف.
- تقييم جودة المصنف من خلال مطالبته بالتنبؤ بمعرفة أصناف مجموعة جديدة من الصور لم يسبق إدخالها إلى المُصنف من قبل، ومقارنة تسمية الأصناف الحقيقيّة لهذه الصور بتلك التي تنبأ بها المصنف.
تعتبر مهمة التعرّف هذه واحدةً من أولى المهارات التي نتعلمها منذ لحظة ولادتنا، وهي التي تستخدم بشكل طبيعيّ ودون أدنى مجهود ، فبدون التفكير مطوّلاً بإمكاننا تحديد البيئة التي نتواجد فيها وكذلك الأشياء التي تحيط بنا بسرعةٍ وسلاسة فائقتين. وعندما نرى صورة أو عندما ننظر إلى العالم من حولنا، فإننا في معظم الأوقات نكون قادرين على تحديد خصائص المشهد على الفور وإعطاء كلّ كائن تسمية، وكلّ ذلك بشكلٍ لا واعٍ ولكن ما الفرق بين ما نشاهده وبين ما يشاهده الحاسب؟!

الشكل -3 الفرق بين ما نشاهده وبين ما يشاهده الحاسب
ما نريد أن يفعله الحاسب هو أن يكون قادرًا على التمييز بين جميع الصور التي نقدّمها له، ومعرفة الميزات الفريدة التي تجعل من الكلب كلبًا أو من القطة قطة، هذه العمليّة أيضًا تجري في أذهاننا بشكلٍ لا شعوريّ، فعندما ننظر إلى صورة كلب فإنه بالإمكان تصنيفها بسهولة من خلال ما تحتويه الصورة على ميزات محدّدة مثل الأرجل الأربعة، شكل الفم والأذنين وغيرها من التفاصيل الأخرى. بطريقة مماثلة، يكون الحاسب قادرًا على إجراء تصنيف للصور من خلال البحث عن ميزات منخفضة المستوى مثل الحوافّ والمنحنيات، ثمّ بناء المزيد من المفاهيم المجرّدة من خلال سلسلة من طبقات الطّي وهذه نظرة عامة على ما تفعله الشبكات الطّي الالعصبونيّة CNN لذا دعونا ندخل في التفاصيل أكثر.
كلّ ما تفعله شبكات الطيّ العصبونيّة CNN هي أنها تلتقط الصورة وتمرّرها عبر سلسلة من طبقات الطيّ والطّبقات غير الخطية، وطبقات التجميع والطبقات تامة الاتصال، منتهيةً بطبقة الخرج أو النتائج. وكما قلنا سابقًا، يمكن أن يكون الناتج صنف واحد أو احتماليّة للأصناف التي تصف الصورة على أفضل وجهٍ ممكن.

الشكل -4 مثال يوضح شبكة الطي (CNN)
الآن بعد أن قمنا بالتمهيد النظريّ لشبكات الطّي العصبونيّة ، سنقوم في الأجزاء القادمة بشرح هذه الطبقات بمزيد من التفصيل، ليتسنى لكم معرفة محتويات الصندوق الأسود لهذه الشبكات وكيفيّة عملها في الخلفيّة.
من الضروريّ جدًا فَهم شكل عيّنات التدريب (بيانات الدّخل). إنّ الصورة بالنسبة إلى الحاسوب عبارة عن مصفوفة ثلاثيّة الأبعاد (العرض×الارتفاع×العمق) من قيم تتراوح بين 0-255؛ إنّها ببساطة نقاط لونيّة (pixels) متوزّعة طولًا وعرضًا وثلاث قنوات لونيّة (إذا كان النظام اللونيّ للصور هو RGB)، كما يظهر في التمثيل أدناه:

الشكل- 5 صورة 6*6*3
مع العلم أنه لو كان عدد القنوات يساوي (1) فإنّ الصورة grayscal أو بالأبيض والأسود.
تحتوي الشبكة الطي العصبونية (CNN) على ثلاثة أنواع من الطبقات الأساسيّة كما يلي:
- طبقة الطي (CONV).
- طبقة التجميع (POOL).
- طبقة ذابت الاتصال الكامل (FC).
طبقة الطيConvolutional Layer ) CONV):
هذه الطبقة هي الأكثر أهميّة في بنية شبكة CNN حيث أنه يتمّ فيها استخدام المرشّحات لتعلّم الميزات من صورة الدّخل، فتتكوّن خريطة المميزات من جداء الطيّ بين قيم المرشّح والمنطقة الممسوحة بحجم المرشّح المقابلة من صورة الدّخل؛ أي كلّ عصبون من هذه الطبقة سيتصل بمنطقة محدّدة من الدّخل وفقاً لحجم المرشّح.
يُعاد ضبط قيم المُرشِّح خلال عمليّة التدريب الدّوريّة، وعند تدريب الشبكة لعدد مُعيّن من دورات التدريب (epochs) وكلّ دورة تدريب يعني إدخال كلّ أمثلة التدريب مرّةً واحدة، تشرع هذه المُرشِّحات البحثَ عن مزايا مُتمايزة في الصورة.
توظَّف الطبقات الخفيّة الأولى في استخراج المزايا البسيطة والواضحة، مثل الحوافّ في الاتجاهات المُختلفة وما إلى ذلك، ومع التعمّق أكثر في الطبقات الخفيّة في الشبكة، تزداد درجة تعقيد المزايا التي يجب تحديدها واستخراجها.

الشكل – 6 مزايا مختلفة تمّ تعرُّفها في طبقات مُختلفة
هناك ثلاثة بارامترات مطلوبة لضبط طبقة الطّي CONV، هذه البارامترات: هي عدد المرشّحات، الخطوة، وحشو الأصفار padding.
يشير بارامتر الخطوة إلى عدد القفزات التي يجب أن تتخذها الخليّة العصبونيّة قبل أن تختار المنطقة المحليّة في حجم الطبقة السابقة.
أما بارامتر الحشوّ الصفريّ فإنه يشير إلى إضافة أصفار حول حدود حجم الإدخال، إذا لزم الأمر.
هناك ثلاثة بارامترات مطلوبة لضبط طبقة الطّي CONV، هذه البارامترات: هي عدد المرشّحات، الخطوة، وحشو الأصفار padding.
يشير بارامتر الخطوة إلى عدد القفزات التي يجب أن تتخذها الخليّة العصبونيّة قبل أن تختار المنطقة المحليّة في حجم الطبقة السابقة.
أما بارامتر الحشوّ الصفريّ فإنه يشير إلى إضافة أصفار حول حدود حجم الإدخال، إذا لزم الأمر.
هناك ثلاثة بارامترات مطلوبة لضبط طبقة الطّي CONV، هذه البارامترات: هي عدد المرشّحات، الخطوة، وحشو الأصفار padding.
يشير بارامتر الخطوة إلى عدد القفزات التي يجب أن تتخذها الخليّة العصبونيّة قبل أن تختار المنطقة المحليّة في حجم الطبقة السابقة.
أما بارامتر الحشوّ الصفريّ فإنه يشير إلى إضافة أصفار حول حدود حجم الإدخال، إذا لزم الأمر.
هناك ثلاثة بارامترات مطلوبة لضبط طبقة الطّي CONV، هذه البارامترات: هي عدد المرشّحات، الخطوة، وحشو الأصفار padding.
يشير بارامتر الخطوة إلى عدد القفزات التي يجب أن تتخذها الخليّة العصبونيّة قبل أن تختار المنطقة المحليّة في حجم الطبقة السابقة.
أما بارامتر الحشوّ الصفريّ فإنه يشير إلى إضافة أصفار حول حدود حجم الإدخال، إذا لزم الأمر
W2= (W1 –F + 2P) / S + 1
H2= (H1 –F + 2P) / S + 1
D2= K

الشكل -7 تمثيل لعمليّة طّي المرشح على الصورة
- طبقة التجميع (Pool: Pooling Layer):
- إنّ الغاية من طبقة التجميع هي تقليص حجم خرائط التفعيل (قلنا خرائط لإمكانيّة استخدام أكثر من مُرشِّح). لا يُقلل ذلك من كميّة الحسابات الضروريّة فحسب، بل يقي من الوقوع في حالة الملائمة الزائدة overfitting.
- الفكرة الكامنة وراء التجميع بسيطة جدًا: تقليص حجم المصفوفات الكبيرة، وتتمّ العمليّة من خلال تطبيق إحدى الدّالتين الآتيتين:
- Max: تحديد القيم العُظمى في كلّ نافذة.
- Average: حساب المتوسط الحسابيّ للقيم الموجودة في النافذة الواحدة.
إلا أنّ التقنيّة الأكثر رواجًا هي الأولى؛ Max-pooling: مفادُ هذه الطريقة هو مسح خريطة التفعيل (أو مصفوفة المزايا) بفي طبقة التجميع POOL يتمّ تمثيل حجم الدّخل على أنه [W2× H2× D2] المطابق للأبعاد المكانيّة لحجم المدخلات، ويتمّ تمثيل بارامترين [F1، S1] المقابلة لحجم المنطقة التي سيتمّ تجميعها والخطوة، ويمثل حجم الخرج وفق الأبعاد المكانيّة التالية [W3 × H3 ×D3] والموضحة بالعلاقات التالية: نافذة صغيرة، والإبقاء على القيم الأكبر ضمن كلّ نافذة مُقلّصين بذلك حجم الخريطة.
W3= (W2 –F1) / S1 + 1
H3= (H2 –F1) / S1 + 1
D3= D2

الشكل -8 Max Pooling
إذن يتمّ في طبقات التجميع استخراج أفضل القيم المزايا الموجودة في مصفوفة المزايا التي نتجت عن طبقة الطّي.
- طبقة ذات الاتصال الكامل (FC: Fully Connected Layer):
تكون هذه الطبقة هي الأخيرة في شبكة الطي وهي من نوع (multi-layer perceptron)، حيث العصبونات مُرتبطة بالكامل مع كُلّ عُقد الطبقة السابقة لها. سبب وجودها في النهاية لأنّ عمليّة التصنيف النهائيّة تتمّ فيها، تُطبق فيها عمليّة بَسْط (flattening operation): بَسط الدّخل إلى شُعاع مزايا، ومن ثَمّ تمريره إلى شبكة من العصبونات للتنبؤ باحتمالات الخرج.
تحتوي الطبقة ذات الاتصال الكامل FC في شبكات الطّي CNN كما في ANNs، على عصبونات متصلة بالكامل بالخلايا العصبونيّةفي الطبقة السابقة. غالبًا ما يتمّ الاحتفاظ بطبقة FC كطبقة نهائيّة لشبكة CNN مع طبقة “SOFTMAX” كدالة التفعيل في مسائل التصنيف لعدّة أصناف.
تكون الطبقة ذات الاتصال الكامل FC مسؤولة عن التنبؤ بالصنف النهائيّ، ويكون بُعد الخرج [1×1×N] حيث تشير N إلى عدد الأصناف.
دخل الطبقة:
هو مصفوفة تتضمن معلومات عن مواقع توضّع أشكال (أنماط مُعقدة مُعينة في الصورة)، ونُطلق على هذه الأنماط المُعقدة اسم (مُصنِّفات قابلة للتدريب trainable classifiers) هي المُرشِّحات ذاتها أو (kernals) أو مصفوفة الأوزان.
خرج الطبقة:
هو شعاعُ قيم تمثِّل كلّ منها احتمال صنف من التصنيفات التي تُدرَّب الشبكة عليها (أي الأوزان)، فمثلاً: بفرض لدينا كلّ من التصنيفين “cat” و” car”، سيكون خرج الطبقة [0.91, 0.01]، هذا يعني احتمال أن تكون الصورة لقطة هو 0.91، أما احتمال كونها لِسيارة هو 0.01، وباختيار الاحتمال الأكبر تكون الصورة من صنف “cat”
تعرّفنا إلى المكوّنات الأساسيّة في شبكة الطي العصبونيّة، لكن ما من فائدة تُرجى منها دون دمج بعضها مع بعض بطريقة مُناسبة بغية تصنيف الصورة المُعطاة.
- دالة التفعيل:
هي دالة لا خطيّة ولها عدّة أنواع تجدها في الصورة أدناه:

الشكل -9 بعض أنواع دالة التفعيل
إن أكثر الدّوالّ استخدامًا في هذه الأيام هي وحدة التصحيح الخطي (Rectified Linear Unit: ReLU) وذلك للميّزة الأكثر أهمية فيها و هي عدم تفعيل كلّ العصبونات في نفس الوقت، ما يُساهم في تقليل كميّة الحسابات المُنجزة إذ تُصفِّر القيم السالبة.
ببساطة كلّ القيم المساوية إلى الصفر أو أصغر منه تُصبح صفرًا، بينما تبقى القيم الموجبة كما هي.
تصميم نموذج الشبكة:
- إدخال صورة إلى طبقة طّي.
- تطبيق دالة التفعيل على خرج طبقة الطّي.
- إرسال خرج الدّالة إلى طبقة طّيأُخرى، وتكرار العمليّة عدّة مرّات.
- إرسال الخرج إلى طبقة تجميع.
- تكرار الخطوات (1-4) عدّة مرّات وإنتاج المُصنِّفات القابلة للتدريب.
- إرسال مصفوفة الخرج إلى طبقة كاملة الاتّصال، التي بدورها تردّ شعاع الأوزان فيه احتمال كلّ تصنيف نريد تدريب الشبكة عليه.
من البُنى التصميميّة الشهيرة لها نذكر منها: LeNet،AlexNet، GoogLeNet،VGGNet. والبنية الموضحة أدناه لـ AlexNet
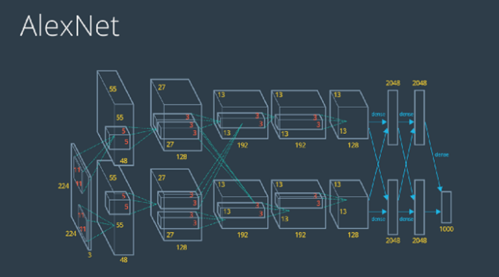
الشكل -10 معماريية شبكة AlexNet
أهمّ المتطلبات الحاسوبيّة العتاديّة لبرمجيّات التعلُّم العميق
نظرًا إلى أنّ العمليّات الحسابيّة – التي تلزم لتدريب شبكات التعلم العميق وطبقاتها المتعدّدة وعصبوناتها الكثيرة – كثيرة ومعقدة، وجب توفير العديد من الإمكانات العتاديّة الحاسوبيّة الملائمة لهذه العمليّات، ومكاملة هذه العتاديّات مع نظام التشغيل أو مجموعة نظم تشغيل تعمل بشكل تفرّعيّ متكامل. إنّ الاختلاف الكبير في أداء وأسعار هذه العتاديّات الممكن إضافتها، قد يؤدّي في بعض الحالات إلى اختيار عتاديّات قد تكون أكثر تكلفةً وأقل أداءً لتدريب شبكات التعلم العميق.
نذكر في هذه الفقرة بعض العتاديّات التي يمكن مكاملتها – بشكل إضافيّ – مع نظام التشغيل أو مجموعة نظم التشغيل العاملة بشكل تفرّعيّ، وذلك للمساعدة على تسريع عمليّات التدريب الخاصة بهذه الشبكات، وتقليل الزّمن اللازم للحصول على شبكات مدرَّبة تدريبًا جيدًا.
– وحدة المعالجة الرسوميّة (Graphics processing unit GPU): وحدة متخصصة في معالجة الرّسوم والبيانيّات الحاسوبيّة، يمكن استعمالها على نطاقٍ واسع في تحسين أداء شبكات التعلم العميق. عند اختيار وحدات معالجة رسوميّةإضافيّة يجب تجنب الأخطاء الثلاثة التالية: 1) عدم ملاءمة التكلفة مع سرعة وحدة المعالجة، 2) طريقة تعامل وحدة المعالجة الرسوميّةمع الذّاكرة، 3) تبريد ضعيف لوحدة المعالجة (سواءً في ذلك تقنيات التبريد المدمجة مع وحدة المعالجة، أو تقنيات التبريد المنفصلة عن وحدة المعالجة.
– ذاكرة النفاذ العشوائيّ (Random Access Memory RAM): من الأخطاء الشائعة عند إضافة وحدة ذاكرة نفاذ عشوائيّ، اختيار ذاكرة ذات حجم منخفض عند اختبار نماذج شبكات عصبونيّة صغيرة نسبيًّا (بنى بسيطة أو معطيات تدريب ذات أحجام صغيرة) بغية الاقتصاد في السعر. هذا الاختيار لن يؤدّي إلى نتائج جيدة عند تدريب الشبكة ولو كان حجمها صغيرًا نسبيًّا.
– وحدة المعالجة المركزيّة (Central Processing Unit CPU): من أهمّ الأخطاء عند إضافة وحدة معالجة مركزيّة عدم تجانسها مع اللوحة الأم (Motherboard).
– القرص الصُّلب (Hard Disk): لا يحتلُّ القرصُ الصُّلب الأهميةَ نفسها التي تحتلها وحدات الذّاكرة الأخرى، ولكن نظرًا إلى تخزين كميات كبيرة من المعطيات الخاصة بتدريب الشبكة العصبونيّة فيه (أو في مجموعة متكاملة من الأقراص الصُّلبة)، فإنّ أداء القرص الصُّلب يُعَدُّ من العوامل المؤثرة في أداء عمليات التدريب للشبكات العصبونيّة.
2- تحديد الكائن (Object Detection)

الشكل -11 مثال عن تقنيّة تحديد الكائنات
هي تقنيّة من تقنيّات الرؤية الحاسوبيّة التي تسمح لنا بتحديد نوع وموقع الأشياء في صورة أو فيديو، فهي تفصل بين كلّ كائن مع مربع محيط تقريبيّ، يمكن لهذه التقنيّة عدّ مجموع الأشياء في مشهد معين وتحديد مواقعها بدقة.
خُلط في بعض الأحيان بين الكشف عن الأغراض و تصنيف الصور image classification، لذلك سوف أوضّح الفرق بين هاتين التقنيتين بشكلٍ مختصر، في تصنيف الصور يتمّ تصنيف صورة معينة ضمن أصناف مجدولة مسبقًا، حيث تمثل الصورة دخل التقنية ويمثل الخرج اسم العنصر الموجود في الصورة. فمثلًا إذا كان الدّخل صورة تحتوي على قطة سيكون الخرج كلمة ” قطة”، وإذا كان الدّخل صورة تحتوي على قطتين سوف يكون الخرج أيضاً ” قطة”، من ذلك يمكننا أن نستنتج أنّ عمليّة تصنيف الصور رغم أهميّتها فهي محدودة بالنتائج التي تعطينا إيَاها. عكس ذلك في عمليّة تحديد الكائنات حيث يتمّ تحديد كلّ عنصر من العناصر المكتشفة ضمن إطار، إضافة إلى ذلك يتمّ تحديد موقع هذا العنصر في المشهد المُعطى. من هذا نستنتج أنّ تحديد الكائنات هي عمليّة أعقد من تصنيف الصور، وتعطينا معلومات أكثر عن الصورة وبالتالي يمكننا الاستفادة منها بشكل أكبر.
تتمثل أهميّة تحديد الكائنات بقدرة الخوارزميّة المطبّقة على تحديد نوع وموقع جسم معين في صورة أو فيديو، والسرعة المطلوبة للقيام بذلك وكذلك كميّة الكائنات التي يمكن لهذه الخوارزميّة كشفها.
استخدام خوارزميّات التعلم العميق في تحديد الكائنات:
إذا استخدمنا تقنيّة Sliding Window مثلًا في تصنيف الصور، لكن مع تحديد الكائنات كونها تعطينا معلومات أكثر عن الصورة فإننا نحتاج إلى تطبيق CNN على عدد كبير من المواقع والمقاييس، وهو أمر مكلف للغاية من الناحية الحسابيّة.
يمكن تمييز تحدَّيين رئيسين لمعظم الخوارزميّات المستخدمة: أوّلاً نحتاج تقسيم الصورة إلى أقسام، بحيث يحتوي كلّ قسم على كائن من الكائنات التي نريد التعرّف عليها. ثانياً تصنيف هذا الجزء من الصورة. لهذا الغرض تُدخل هذه الأجزاء من الصورة في شبكة طيّ عصبونيّة Convolution Neural Network CNN مدرّبة مسبقاً، وستتحوّل العمليّة إلى تصنيف الصور فاقترح باحثو الشبكات العصبونية استخدام المناطق حيث نجد مناطق صور من المحتمل أن تحتوي على كائنات.
فكان النموذج الأوّل الذي أُطلق هو R-CNN شَبَكَةُ الطَّيِّ العُصبُونِيَّةِ المناطِقيَّةِ، تقوم أوّلاً بمسح صورة الدّخل بحثًا عن كائنات محتملة باستخدام خوارزميّة تسمى البحث الانتقائيّ، مما يؤدّي إلى إنشاء 2000 اقتراحِ منطقةٍ تقريبًا. ثمّ تقوم بتشغيل CNN فوق كلّ من مقترحات المنطقة هذه، وأخيرًا تأخذ خرج كلّ CNN وتغذّيه في آلة المُتَّجه الداعم SVM لتصنيف المنطقة.
بالتالي تتكون بنية الشبكة من ثلاث وحدات: مقترحات المنطقة المستقلة عن الصنف التي تحدّد مجموعة من المناطق المرشحة، وشبكة الطي العصبونية الكبيرة (CNN) التي تستخرج الميزات من المناطق، ومجموعة من مُصنّفات آلة المُتَّجه الداعم ( Support Vector Machine (SVM

الشكل -12 معماريّة شبكة R-CNN
نذكر مثالًا بسيطًا:
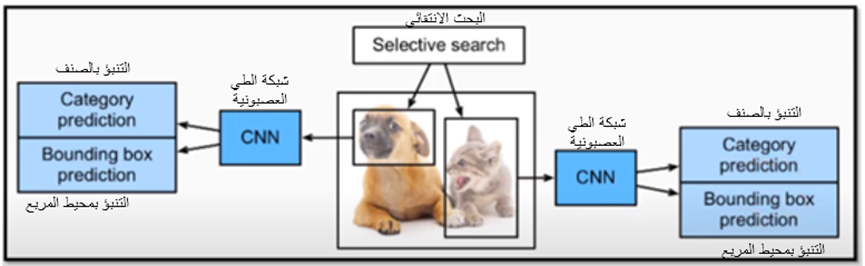
الشكل-13 مثال تطبيق شبكة R-CNN
لدينا صورة فيها قطة وكلب، فمن خلال خوارزميّات البحث الانتقائيّ يتمّ تحديد المناطق؛ أي منطقة تواجد الكلب ومنطقة تواجد القطة، من ثمّ تدخل المنطقة المحدّدة في الصورة على شبكة الطي العصبونية CNN وتحدّد أن هذه المنطقة هي الكلب والأخرى هي القطة، وتعمل أيضاً صندوق إحاطة لكلّ منطقة.
كوننا في الأساس قمنا بتحويل عمليّة تحديد الكائنات إلى عمليّة تصنيف الصور، ومع ذلك هناك بعض المشاكل نذكر منها:
- بطيئة تتطلب وقت كبير لتدريب الشبكة
- الحاجة إلى مساحة كبيرة على القرص.
- خوارزميّة التعلم الانتقائيّ هي خوارزميّة ثابتة، لذلك لا يحدث تعلم في تلك المرحلة لأن ذلك يؤدّي لتوليد مقترحات خاطئة.
اقترح Girshick (2015) شبكة طي سريعة تستند إلى المنطقة تدعى شَبَكَةُ الطَّيِّ العُصبُونِيَّة المناطِقيَّةِ السَّريعةِ Fast R-CNN وتستخدم بنية R-CNN لتوليد النتائج بسرعة، والذي يحسن سرعة الكشف من خلال زيادتين: الأولى تنفيذ استخراج الميزات قبل اقتراح المناطق، وبالتالي تشغيل شبكة CNN واحدة فقط على الصورة بأكملها، والثانية استبدال SVM بطبقة softmax، وبالتالي توسيع الشبكة العصبونية للتنبؤات بدلًا من إنشاء نموذج جديد.

الشكل -14 معمارييّة شبكة Fast R-CNN
لقد كان أداء شَبَكَةُ الطَّيِّ العُصبُونِيَّة المناطِقيَّةِ السَّريعةِ Fast R-CNN أفضلَ بكثير من حيث السرعة، لأنه يقوم بتمرير كلّ صورة مرّة واحدة فقط إلى CNN، وتُستخدم خارطة الميزات Feature maps للكشف عن الكائنات، ويُستخدم نموذج واحد من R-CNN، وبالتالي هي أسرع من R-CNN في كلّ من وقت التدريب والاختبار، ومع ذلك، لا تزال خوارزميّة البحث الانتقائيّ تستغرق الكثير من الوقت لإنشاء مقترحات المنطقة.
بتطبيق Fast R-CNN على المثال السابق، يظهرفي الصورة أدناه حيث تدخل الصورة على شبكة الطيّ العصبونيّة CNN، ومن خلال خوارزميّات البحث الانتقائيّ يتمّ إيجاد المناطق ثمّ نجري لها عمليّة التجميع، ومن ثمّ المرور الى الطبقة الكثيفة – طبقة ذات الاتصال الكامل (Dense Layer) وتُجرى عمليّة تحديد الكلب والقطة وتشكيل صندوق إحاطة لكلّ منطقة.

الشكل -15 مثال تطبيق شَبَكَةُ الطَّيِّ العُصبُونِيَّة المناطِقيَّةِ السَّريعةِFast R-CNN
مشاكل شبكة Fast R-CNN:
يُستخدم البحث الانتقائيّ كأسلوب اقتراح للعثور على مناطق الاهتمام، وهي عمليّة بطيئة وتستغرق وقتًا طويلًا، طبعًا هو أفضل بكثير مقارنة مع R-CNN لكن عندما تستخدم مجموعات كبيرة من البيانات الواقعيّة فإنها تأخذ بعض الوقت لإتمام العمليّة.
هكذا تأتي شبكة الطي العصبونية المناطقية الأسرع Faster R-CNN، والتي تعدّ الآن نموذجًا أساسيًا لاكتشاف الكائنات القائمة على التعلم العميق. تُستبدل خوارزمية البحث الانتقائيّ البطيء بشبكة عصبيّة سريعة عن طريق إدخال شبكة المناطق المقترحة (RPN) للتنبؤ بالمقترحات من الميزات، يتمّ استخدام شبكة المناطق المقترحة RPN لتحديد “مكان” البحث من أجل تقليل المتطلبات الحسابيّة لعمليّة الاستدلال الشاملة. يقوم RPN بمسح كلّ موقع بسرعة وكفاءة من أجل تقييم ما إذا كان يلزم إجراء مزيد من المعالجة في منطقة معينة، وذلك عن طريق إخراج مقترحات الصندوق المحيط لكلّ منها بدرجتين تمثلان احتمال وجود كائن أو لا في كلّ موقع.
وبالتالي باتت شبكة الطي العصبونية المناطقية الأسرع Faster R-CNN أسرع من سابقتها؛ لأنها تستخدم شبكة منفصلة للتنبؤ بمقترحات المنطقة بدلًا من خوارزميّة البحث الانتقائيّ، ومن ثمّ يتمّ إعادة تشكيل المناطق المقترحة المتوقعة، والتي يتمّ استخدامها بعد ذلك لتصنيف الصورة داخل المنطقة المقترحة والتنبؤ بقيم الإزاحة في المربعات المحيطة.
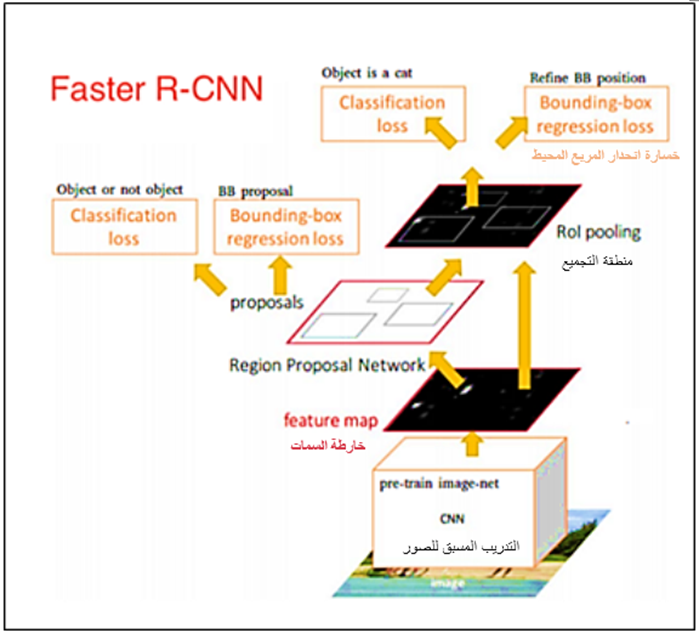
الشكل -16 معمارييّة شبكة Faster R-CNN
بمجرّد أن نحصل على مقترحات منطقتنا، نقوم بإدخالها مباشرة إلى ما هو في الأساس Fast R-CNN، نضيف طبقة تجميع وبعض الطبقات المتصلة بالكامل، وأخيرًا طبقة تصنيف softmax ومربع انحدار.
إجمالاً، حققت شبكة الطيّ العصبونية المناطقية الأسرع Faster R-CNN سرعات أفضل ودقة أعلى، وتجدر الإشارة إلى أنه على الرّغم من أنّ النماذج المستقبليّة قد فعلت الكثير لزيادة سرعات الكشف، إلا أنّ القليل منها تمكنت من التفوّق على Faster R-CNN بهامش كبير، أي بمعنى آخر قد لا تكون شبكة الطيّ العصبونية المناطقية الأسرع Faster R-CNN هي الطريقة الأسهل أو الأسرع لاكتشاف الأشياء، لكنها لا تزال واحدة من أفضل الطرق أداءً.
بتطبيق شبكة الطيّ العصبونية المناطقية الأسرع Faster R-CNN على المثال السابق الموضّح في الصورة أدناه، حيث لدينا الصورة التي فيها الكلب والقطّة تدخل على شبكة الطي العصبونية ومن ثمّ تطبيق شبكة المناطق المقترحة، ثمّ نجري لها عمليّة التجميع ومن ثمّ المرور الى طبقة Dense Layer وتُجرى عمليّة تحديد الكلب والقطة وتشكيل صندوق إحاطة لكلّ منطقة.

الشكل -17 مثال تطبيق شبكة Faster R-CNN
في السنوات الأخيرة تحوّلت اتجاهات اكتشاف الكائنات الرئيسيّة نحو أنظمة كشف أسرع وأكثر كفاءة، مثل: YOLO وSSD و R-FCN كخطوة نحو مشاركة الحساب على كامل الصورة، وهذا ما يميزها عن الشبكات الفرعيّة المكلفة المرتبطة بتقنيّات R-CNN الثلاثة. والسبب الأساسيّ والمنطقيّ وراء الاتجاه نحو هذه الطرق؛ هو تجنب وجود خوارزميّات منفصلة تركز على المشاكل الفرعيّة الخاصة بكلّ منها بمعزل عن غيرها، لأنّ هذا عادةً ما يزيد من وقت التدريب ويمكن أن يقلل من دقة الشبكة.
3- تتبّع الكائن (Object Tracking)

الشكل -18 مثال عن تتبع الكائنات
وهي عمليّة اتباع كائن معين هو موضع اهتمامك، أو كائنات متعدّدة، في مشهد معين. تطبيقاته التقليديّة تكون إما من خلال تتبع الكائن في مقطع فيديو أو تتبع الكائن في الزّمن الحقيقيّ. هذا الأمر في غاية الأهميّة في أنظمة القيادة المستقلة مثل شركات المركبات ذاتيّة القيادة كشركة Tesla و Uber.
يمكن تقسيم طرق تتبع الكائن إلى صنفين وفقًا لنموذج المراقبة:
- الطريقة التوليديّة: تستخدم النموذج التوليديّ لوصف الخصائص الظاهرة وتقليل خطأ إعادة البناء للبحث عن الكائن مثل تحليل المكون الرئيسي Principal component analysis PCA.
- الطريقة التمييزيّة: يمكن استخدامها للتمييز بين الكائن والخلفيّة، وأداؤها أكثر قوّة، لتصبح تدريجيّاً الطريقة الرئيسة في التتبع. يُشار إلى الطريقة التمييزيّة أيضًا باسم التتبع عن طريق الكشف، وينتمي التعلم العميق إلى هذا الصنف. لتحقيق التتبع عن طريق الكشف، يتمّ الكشف عن الكائنات المرشحة لجميع الإطارات، ويُستخدم التعلم العميق للتعرّف على الكائن المطلوب من المرشحين. هناك نوعان من نماذج الشبكات الأساسيّة التي يمكن استخدامها هي: التشفير التلقائي المكدس ( stacked auto encoders:SAE) وشبكة الطي العصبونية (CNN).
الشبكة العميقة الأكثر شيوعًا في مسألة التتبع SAE والتي تقترح التدريب المُسبق في وضع عدم الاتصال، والضبط الدّقيق للشبكة عبر الانترنت، وتعمل على النحو التالي:
- إجراء التدريب المسبق، باستخدام مجموعات بيانات الصورة الطبيعيّة على نطاق واسع للحصول على التمثيل العام للكائن. يمكن لهذا التشفير الحصول على قدرة تعبيريّة أكثر قوّة، عن طريق إضافة ضجيج في صور الدّخل وإعادة بناء الصور الأصليّة.
- الدّمج بين جزء الترميز من الشبكة المدرّبة مسبقًا مع المصنف للحصول على شبكة التصنيف، ثمّ استخدام العينات الإيجابيّة والسلبيّة التي تمّ الحصول عليها من الإطار الأوليّ لضبط الشبكة، والتي يمكن أن تميز الكائن الحاليّ والخلفيّة. يستخدم متتبع التعلم العميق (Deep Learning Tracker ) DLT مرشح الجسيمات كنموذج حركة لإنتاج بقع مرشحة للإطار الحاليّ. تقوم شبكة التصنيف بإعطاء درجات الاحتماليّة لهذه البقع، مما يعني الثقة في تصنيفاتها، ثمّ تختار أعلى هذه البقع ككائن.
- في نموذج التحديث يستخدم متتبع التعلم العميق DLT طريقة العتبة المحدودة.

الشكل -19 عدّة أمثلة لتتبع الكائن
بسبب تفوق هذه التقنية في تصنيف الصور وتحديد الكائنات، أصبحت شبكة الطيّ العصبونية CNN النموذج العميق السائد في الرؤية الحاسوبيّة وفي التتبع البصريّ. بشكل عام، يمكن تدريب شبكة الطيّ العصبونية CNN واسعة النطاق كمصنف وكمتتبع. تمثيلان لـشبكة الطيّ العصبونية CNN قائمان على خوارزميّات التتبع وهي: شبكة الملائمة ذات الطي بالكامل (FCNT Fully Convolutional Adaptation Network) وشبكة الطي متعدّدة النطاقات (MD Net).
إنّ شبكة الملائمة ذات الطي بالكامل (FCNT Fully Convolutional Adaptation Network) تحلل وتأخذ مميزات خارطة الميزات (feature maps) لنموذج VGG المُدرّب مسبقاً على قاعدة البيانات ImageNet والذي أعطى الملاحظات التالية:
- إمكانيّة استخدام خارطة ميزات شبكة الطيّ العصبونية CNN في التتبع.
- العديد من خرائط ميزات شبكة الطيّ العصبونية CNN مزعجة أو غير مرتبطة بمسألة تمييز كائنٍ معين من خلفيته.
- تلتقط الطبقات العليا المفاهيم الدلاليّة في أصناف الكائنات، بينما تقوم الطبقات السفليّة بتشفير المزيد من الميزات التمييزيّة لالتقاط التباين داخل الصنف.
بسبب هذه الملاحظات، تصمم شبكة الملائمة ذات الطي بالكامل (FCNT Fully Convolutional Adaptation Network) شبكة اختيار الميزات لتحديد خرائط الميزات الأكثر صلة في طبقات conv4–3 و conv5–3 لشبكة VGG، ثمّ لتجنب الملائمة الزائدة overfitting فإنها تصمم أيضًا قناتين إضافيتين (تسمى SNet و GNet لخرائط الميزات المحدّدة من طبقتين منفصلتين. تلتقط GNet معلومات عن صنف الكائن، بينما يميز SNet الكائن من الخلفيّة.
تتمّ تهيئة كلتا الشبكتين باستخدام المربع المحيط المحدّد في الإطار الأوّل للحصول على خرائط حراريّة للكائن، وبالنسبة للإطارات الجديدة يتمّ اقتصاص منطقة الاهتمام (ROI) المتمركزة في موقع الكائن في الإطار الأخير ونشرها. أخيرًا، من خلال SNet و GNet يحصل المصنف على خريطتي حرارة للتنبؤ، ويقرّر المتعقب أي خريطة حراريّة سيتمّ استخدامها لتوليد نتيجة التتبع النهائيّة وفقًا لما إذا كانت هناك عوامل تشتيت. يتمّ عرض تسلسل الوحدات المستخدمة في شبكة الملائمة ذات الطي بالكامل (FCNT Fully Convolutional Adaptation Network) أدناه.

الشكل -20 تصمم شبكة الملائمة ذات الطي بالكامل (FCNT Fully Convolutional Adaptation Network)
إنّ شبكة الطي متعدّدة النطاقات MD Net تستخدم جميع تسلسلات الفيديو لتتبع الحركات فيها. فهذه الشبكة تستخدم بيانات صور غير ذات صلة لتقليل طلب التدريب على بيانات التتبع، وهذه الفكرة لها بعض الانحراف عن فكرة التتبع المعروفة، فكائن أحد الأصناف في هذا الفيديو ممكن أن يكون خلفيّة في فيديو آخر، لذلك شبكة MD Net تقترح تعدّد النطاقات لتمييز الكائن والخلفيّة في كلّ مجال بشكلٍ مستقل، ويشير النطاق إلى مجموعة من مقاطع الفيديو التي تحتوي على نفس نوع الكائن.
يتمّ تقسيم شبكة MD Net إلى جزأين كما هو موضح أدناه: الطبقات المشتركة وK فرع لطبقات النطاق المحدد. يحتوي كلّ فرع على طبقة تصنيف ثنائيّة مع تابع الخسارة softmax، والتي تُستخدم لتمييز الكائن والخلفيّة في كلّ نطاق، وتتشارك الطبقات المشتركة مع جميع المجالات لضمان التمثيل العام.

الشكل -21 تصميم شبكة MD Net
في السنوات الأخيرة، جرّب باحثو التعلم العميق طرقًا مختلفة للتكيف مع ميزات مهمة التتبع البصريّ، هناك العديد من الاتجاهات التي تمّ استكشافها: تطبيق نماذج الشبكة الأخرى مثل الشبكة العصبونية الإرجاعية Recurrent Neural Net و Deep Belief Net وتصميم بنية الشبكة للتكيف مع معالجة الفيديو والتعلم من النهاية إلى النهاية، وتحسين سير العمليّة والبنية والبارمترات، أو حتى الجمع بين التعلم العميق والأساليب التقليديّة للرؤية الحاسوبيّة أو المناهج في مجالات أخرى مثل معالجة اللغة والتعرّف على الكلام.
4- التجزئة الدلاليّة (Semantic Segmentation)

الشكل -22 مثال عن التجزئة الدّلاليّة
إنّ التقسيم الدّلاليّ للصورة هو تصنيف كلّ بكسل في الصورة المدخلة إلى صنف دلاليّ للحصول على تصنيف كثيف مقسم. على وجه الخصوص، يحاول التقسيم الدّلاليّ فهم دور كلّ بكسل في الصورة بشكل دلاليّ (على سبيل المثال، هل هي سيارة أم درّاجة ناريّة أم نوع آخر من الأصناف؟). على سبيل المثال، في الصورة أعلاه، بصرف النظر عن التعرّف على الشخص والطريق والسيارات والأشجار وما إلى ذلك، يتعين علينا أيضًا تحديد حدود كلّ كائن. لذلك على عكس التصنيف، نحتاج إلى تنبؤات كثيفة من حيث البكسل .
كما هو الحال مع مهام الرؤية الحاسوبيّة الأخرى، حققت شبكات الطيّ العصبونية CNN نجاحًا هائلًا في التجزئة. كانت إحدى الطرق الأوليّة الشائعة هي تصنيف التصحيح من خلال نافذة منزلقة، حيث تمّ تصنيف كلّ بكسل بشكل منفصل إلى أصناف باستخدام جزء من الصور حولها. ومع ذلك، يعدّ هذا غير فعال للغاية من الناحية الحسابيّة لأننا لا نعيد استخدام الميزات المشتركة بين الأجزاء المتداخلة.
الحل بدلًا من ذلك، هو شبكات ذات الطي الكامل FCN التابعة لجامعة كاليفورنيا في بيركلي، والتي عممت بنى شبكات الطيّ العصبونية CNN الشاملة للتنبؤات الكثيفة دون أيّ طبقات متصلة بالكامل. سمح هذا بإنشاء خرائط تجزئة للصور من أيّ حجم، وكان أيضًا أسرع بكثير مقارنة بنهج تصنيف الجزء. اعتمدت جميع الأساليب اللاحقة للتجزئة الدّلاليّة تقريبًا هذا النموذج.

الشكل -23 تصميم شبكة ذات الطي الكامل FCN
ومع ذلك تبقى مشكلة واحدة، الطي في الصورة الأصليّة ستكون مكلفة، للتعامل مع هذا الأمر، تستخدم شبكة الطي الكامل FCN الاختزال من الأسفل والاختزال من الأعلى داخل الشبكة. تُعرف طبقة الاختزال الأسفل باسم الطيّ المخطط، بينما تُعرف طبقة الاختزال الأعلى باسم الطيّ المنقول.
على الرّغم من طبقات تصغير الأبعاد / تكبير الأبعاد، تنتج شبكة الطيّ الكامل FCN خرائط تجزئة تقريبيّة بسبب فقد المعلومات أثناء التجميع. شبكة الطي العميقة المشفرة SegNet: A Deep Convolutional التشفير-فك التشفير Encoder-Decoder هي بنية ذاكرة أكثر كفاءة من شبكة الطيّ الكامل FCN التي تستخدم تجمِيعٌ وفقَ القيمةِ الكُبرى (max pooling) وإطار عمل تشفير-فكّ التشفير. في SegNet، يتمّ تقديم اتصال الاختصار / التخطيّ من خرائط ميزات عالية الدّقة لتحسين خشونة تصغير الأبعاد / تكبير الأبعاد.

الشكل -24 تصميم شبكة SegNet
تعتمد الأبحاث الحديثة في التقسيم الدّلاليّ بشكل كبير على شبكات ذات الطي الكامل مثل Dilated Convolutions و DeepLab و RefineNet.
5- تجزئة المثيل (Instance Segmentation)

الشكل -25 مثال عن تجزئة المثيل
إنّ تجزئة المثيل تقسم حالات مختلفة من الأصناف، مثل تصنيف خمس سيارات بخمس ألوان مختلفة. في التصنيف، توجد بشكل عام صورة بها كائن واحد كمحور التركيز، والمهمة هي تحديد ماهيّة تلك الصورة. لكن من أجل تقسيم الحالات، نحتاج إلى تنفيذ مهام أكثر تعقيدًا. نرى مشاهد معقدة مع كائنات متعدّدة متداخلة وخلفيّات مختلفة، ولا نصنف هذه الكائنات المختلفة فحسب، بل نحدّد أيضًا حدودها واختلافاتها وعلاقاتها مع بعضها البعض.
لقد رأينا حتى الآن كيفيّة استخدام ميزات شبكات الطّي العصبونيّة CNN بعدّة طرق مثيرة للاهتمام، لتحديد موقع كائنات مختلفة بشكل فعال في صورة ذات مربعات إحاطة. هل يمكننا توسيع هذه التقنيات لتحديد موقع وحدات البكسل الدّقيقة لكلّ كائن بدلًا من مجرّد مربعات إحاطة؟ يتمّ استكشاف مشكلة تجزئة المثيل هذه في Facebook AI باستخدام بنية تُعرف باسم شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN.

الشكل -26 مثال عن تطبيق شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN
يشبه إلى حدّ كبير شبكة الطيّ العصبونية المناطقية السريعة والأسرع Fast R-CNN و Faster R-CNN، فإنّ الحدس الأساسيّ لـشبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN واضح ومباشر نظرًا لأنّ شبكة الطيّ العصبونية الأسرع Faster R-CNN يعمل جيدًا لاكتشاف الكائنات، فهل يمكننا توسيعه لإجراء تجزئة على مستوى البكسل؟
تقوم شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN بذلك عن طريق إضافة فرع إلى شبكة الطيّ العصبونية المناطقية الأسرع Faster R-CNN الذي ينتج قناعًا ثنائيًا يوضح ما إذا كان بكسل معين جزءًا من كائن أم لا. الفرع عبارة عن شبكة ذات الطي بالكامل أعلى خريطة ميزات قائمة على شبكة الطيّ العصبونية CNN. بالنظر إلى خريطة ميزات CNN كدخل، تقوم الشبكة بإخراج مصفوفة بـ 1 في جميع المواقع التي ينتمي إليها البكسل إلى الكائن و0 في مكان آخر (يُعرف هذا باسم القناع الثنائيّ).

الشكل -27 تصميم شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN
بالإضافة إلى ذلك، عند التشغيل بدون تعديلات على بنية Faster R-CNN الأصليّة، كانت مناطق خريطة الميزات المحدّدة بواسطة RoIPool (منطقة تجمع الاهتمامات) المنحرفة قليلاً عن مناطق الصورة الأصليّة. نظرًا لأنّ تجزئة الصورة تتطلب تحديدًا على مستوى البكسل، على عكس المربعات المحيطة، فقد أدّى ذلك بطبيعة الحال إلى عدم الدّقة. تحلّ شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN هذه المشكلة عن طريق ضبط RoIPool ليكون أكثر دقة باستخدام طريقة تُعرف باسم RoIAlign (منطقة الاهتمامات Align). بشكل أساسيّ، تستخدم RoIAlign الاستيفاء الثنائيّ الخطيّ لتجنب الخطأ في التقريب، مما يؤدّي إلى عدم الدّقة في الكشف والتجزئة.
بمجرّد إنشاء هذه الأقنعة، تقوم شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN بدمجها مع التصنيفات والمربعات المحيطة من Faster R-CNN لإنشاء مثل هذه التقسيمات الدّقيقة الرّائعة.

الشكل -28 بعض الأمثلة عن تطبيق شبكة الطي العصبونية المناطقية ذات القناع Mask R-CNN
الخاتمة
مازال لدينا الكثير لنكتشفه في مجال الرؤية الحاسوبيّة. التطبيقات ما زالت محدودة ولكن مع التطوّر الكبير من ناحية المعالجات الرسوميّة GPU وتوفر البيانات، يمكن أن نصل إلى أشياء لم نشاهدها إلا في أفلام الخيال العلمي، فمع استمرار تطوّرها وتفوّقها في المهام التي تحتاج إلى دقة عالية في التحليل وسرعة الاستجابة مقارنةً بالرؤية البشريّة، ، سنصل إلى أتمتة جميع العمليّات التي تعتمد على مفهوم التعرّف على الصور وتحليلها في القطاعات الحكوميّة والخاصة.
المراجع:
- https://heartbeat.fritz.ai/the-5-computer-vision-techniques-that-will-change-how-you-see-the-world-1ee19334354b
- GOGUL, I., KUMAR, S., 2017- Flower Species Recognition System using Convolution Neural Networks and Transfer Learning. 2017 IEEE, 2017 4th International Conference on Signal Processing, Communications and Networking. (ICSCN -2017), March 16 – 18, 2017, Chennai, INDIA
- GIRSHICK, R., 2015 – Fast R-CNN. arxiv.org/pdf/ /1504.08083v2





تعليق واحد
رائع هذا البوح