المَحتويَات
- المقدّمة.
- ماهو الهاكينغ فيس Hugging Face.
- المحوّلات كمكتبة Transformers as a Library.
- تثبيت مكتبة المحوّلات Transformers.
- مسار التّدفق pipeline في مكتبة المحوّلات.
- التّصنيف بدون أمثلةٍ مسبقة Zero-Shot Classification.
- المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer والنّموذج التّلقائيّ AutoModel.
- ولكن مع المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer:
- الضّبط الدّقيق للنّماذج Fine-tuning models.
- الخاتمة.
- المراجع.
إعداد: م. نور شوشرة
التّدقيق العلميّ: م. محمّد سرميني، م. ماريّا حماده
المقدّمة.
في عالم التّكنولوجيا المتغيّر بسرعةٍ في أيّامنا الحاليّة، يبرز الذّكاء الإصطناعيّ كمجالٍ بالغ الأهميّة وحاضرٍ دائمًا، حيث يشقّ طريقه بسهولةٍ إلى تجاربنا اليوميّة. ويشكّل مجال معالجة اللّغات الطّبيعيّة محور هذه الموجة من الذّكاء الإصطناعيّ؛ فهو منطقةٌ متطوّرةٌ تدعم أدوات المحادثة الشّائعة مثل ChatGPT و Bard.
ماذا لو كانت معظم النّماذج الّتي تجعل هذه الأدوات ممكنة متاحة للجميع وفي مكانٍ واحد؟
من خلال مكتبة معالجة اللّغة الطّبيعيّة الأكثر شهرة في Python، وقد برزت كواحدةٍ من المنصّات المحوريّة لعشّاق الذّكاء الاصطناعيّ والمحترفين؛ لتجربة نماذجهم الخاصّة ونشرها وتوسيع نطاقها، كما ويمكن للآخرين التّعديل عليها Fine tune لتناسب بيانات أخرى ومهمّات أخرى.
سواء أكنت محترفًا في البيانات أو مجرّد مبتدئٍ؛ فإنّ هاكينغ فيس Hugging Face لديه الأدوات والموارد اللّازمة لإضفاء الحيويّة على مشاريع الذّكاء الاصطناعيّ الخاصّة بك.
لذا، دعنا نكتشف ما يقدّمه هاكينغ فيس Hugging Face!
ماهو الهاكينغ فيس Hugging Face.
هو منصّةٌ تعاونيّةٌ مليئةٌ بالأدوات الّتي تمكّن أيّ شخصٍ من إنشاء نماذج معالجة اللّغات الطّبيعيّة والتّعلّم الآليّ وتدريبها ونشرها باستخدام شيفرةٍ برمجيّةٍ مفتوحة المصدر، كما وأنّها تعمل أيضًا على توفير ما يقارب 2000 مجموعة بيانات.
تأتي هذه النّماذج مدرّبةً مسبقًا، أي لم يعد المطوّرون يبدؤون من الصّفر بعد الآن؛ بل إنّهم ببساطةٍ يقومون بتحميل نموذجٍ مدرّبٍ مسبقًا من مركز هاكينغ فيس Hugging Face، وضبطه بدقّةٍ Fine tune لمهامهم المحدّدة، والبدء من هنا.
وهناك سببٌ آخر لنموّها السّريع وهو سهولة استخدام المنصّة، حيث إنّ توفير واجهةٍ بسيطةٍ يجعل البدء أمرًا سهلًا للمبتدئين والمحترفين على حدٍّ سواء.
يمكن تطبيق هذه النّماذج على:
- النّصوص Text وبأكثرَ من 100 لغةٍ: لأداء مهام، مثل التّصنيف واستخراج المعلومات والإجابة على الأسئلة والتّوليد والتّرجمة.
- الكلام Speech: لمهام مثل تصنيف الصّوت والتّعرّف على الكلام.
- الرّؤية Vision: لاكتشاف الأشياء وتصنيف الصّور والتّجزئة.
- البيانات الجدوليّة Tabular data: لمشاكل الانحدار والتّصنيف [1] [2].
- يمكن زيارة المنصّة عبر الرّابط الآتي: huggingface
المحوّلات كمكتبة Transformers as a Library.
إنّ مكتبة المحوّلات Transformers الخاصّة بـهاكينغ فيس Hugging Face، هي مكتبةٌ مفتوحة المصدر لمعالجة اللّغات الطّبيعيّة والتّعلم الآليّ. توفّر مجموعةً كبيرةً ومتنوّعةً من النّماذج والمعماريّات المدرّبة مسبقًا، مثل بيرت BERT والإصدار الثّاني من الجي بي تي GPT-2 والإصدار الخامس من المحوّل T5 والعديد من النّماذج الأخرى. كما وأنّها تدعم مهام متعدّدة، مثل تصنيف النّصوص والإجابة على الأسئلة وتوليد النّصوص وتلخيصها والتّرجمة وغيرها [3].
تثبيت مكتبة المحوّلات Transformers.
يمكن تثبيت مكتبة المحوّلات بسهولةٍ باستخدام pip، مثبّت الحزمة في بايثون Python وفق التّعليمة التّالية:
pip install transformers
تعدّ بايتورش PyTorch ومكتبة تنسور فلو للتَّعلُّمِ العميقِ من جوجل TensorFlow شرطًا أساسيًّا لاستخدام مكتبة المحوّلات من هاكينغ فيس Transformers Hugging Face [3].
من أجل تثبيت بايتورش PyTorch يمكن استخدام التّعليمة التّالية:
pip install torch
pip install tensorflow
ليتمّ استدعاءها بالشّكل التّالي:
import transformers
مسار التّدفق pipeline في مكتبة المحوّلات.
يُعدّ استخدام مسار التّدفق pipeline من مكتبة المحوّلات أسرعَ وأسهل طريقةٍ لبدء تجربة النّماذج. قم بتزويد كائن pipeline باسم مهمّة، وسيتمّ تنزيل نموذجٍ مناسبٍ تلقائيًّا من مستودع نماذج هاكينغ فيس Hugging Face، حيث يكون جاهزًا للاستخدام.هناك العديد من المهام الّتي تديرها المكتبة بالفعل، على سبيل المثال:
تحليل المشاعر، تصنيف النّصوص، الإجابة على الأسئلة، التّرجمة، التّلخيص، إنشاء النّصوص وغيرها.
ليكن لدينا المثال التّالي المعبّرعن تحليل المشاعر:
from transformers import pipeline
# Load a sentiment analysis model
sentiment_analyzer = pipeline('sentiment-analysis')
في حال عدم تمرير نموذجٍ model، يتمّ تلقائيًّا تحميل distilbert-base-uncased-finetuned-sst-2-english، ولكنّ كفاءته ليست جيّدةً بالنّسبة للّغة العربيّة:
from transformers import pipeline
# Load a sentiment analysis model
sentiment_analyzer = pipeline('sentiment-analysis')
text = "I'm thrilled with this tutorial. It's amazing!"
result = sentiment_analyzer(text)
print(result)
يكون الخرج لما سبق كالتّالي:
[{'label': 'POSITIVE', 'score': 0.9998817443847656}]
في حال تمرير جملةٍ عربيّةٍ للنّموذج كالتّالي :
text = "أنا سعيد جدًا بهذا البرنامج التعليمي. إنه مذهل!!"
result = sentiment_analyzer(text)
print(result)
تكون النّتيجة وفق الآتي:
{'label': 'POSITIVE', 'score': 0.6083588004112244}]
لذلك نحن بحاجةٍ لنموذجٍ تكون كفاءته جيّدةً في اللّغة العربيّة. لنستخدم أحد النّماذج الموجودة بالفعل في هاكينغ فيس Hugging Face حيث سنأخذ هذا النّموذج من الرّابط التّالي:
https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment
بالضّغط على use this model، تظهر التّعليمات لاستخدامه فورًا في تحليل المشاعر وتصنيف النّصوص:
from transformers import pipeline
# إنشاء pipeline لتصنيف النصوص باستخدام نموذج "CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment"
# هذا النموذج مخصص لتحليل المشاعر باللغة العربية
pipe = pipeline("text-classification", model="CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
# تحليل الجملة العربية "أنا سعيد جدًا بهذا البرنامج التعليمي. إنه مذهل!!" وتصنيف المشاعر المتعلقة بها
result = pipe("أنا سعيد جدًا بهذا البرنامج التعليمي. إنه مذهل!!")
# طباعة نتيجة التصنيف، التي تحتوي على التصنيف مثل "إيجابي" أو "سلبي" مع درجة الثقة (probability)
print(result)
تكون النّتيجة:
[{'label': 'positive', 'score': 0.9957026839256287}]
التّصنيف بدون أمثلةٍ مسبقة Zero-Shot Classification.
هو أسلوبٌ متقدّمٌ في معالجة اللّغات الطّبيعيّة NLP يسمح للنّموذج بتصنيف النّصوص إلى فئاتٍ جديدةٍ دون الحاجة إلى تدريبٍ مسبقٍ على تلك الفئات. بعبارةٍ أخرى، يمكن للنّموذج التّعامل مع تصنيف النّصوص حتّى إذا لم يتمّ تدريبه صراحةً على الفئات المراد استخدامها، ممّا يجعله قادرًا على التّعامل مع مهام جديدة بمرونةٍ كبيرةٍ. يعتمد النّموذج على المعرفة المكتسبة من البيانات الكبيرة والمتنوّعة الّتي تمّ تدريبه عليها، بالإضافة إلى فهمه السّياقيّ للنّصّ.
لدينا المثال الآتي:
from transformers import pipeline
# إنشاء pipeline باستخدام نموذج XLM-RoBERTa
classifier = pipeline("zero-shot-classification", model="joeddav/xlm-roberta-large-xnli")
# النص العربي الذي تريد تصنيفه
input_text = "الذكاء الاصطناعي يسهم في تحسين جودة الحياة."
# الفئات المحتملة لتصنيف النص
labels = ["تكنولوجيا", "صحة", "رياضة"]
# تصنيف Zero-Shot
result = classifier(input_text, candidate_labels=labels)
يتمّ تمرير الفئات المراد تصنيف النّصّ ضمنها في معامل candidate_labels.
تكون النّتيجة كالتّالي:
# عرض النتيجة
print(result)
{'sequence': 'الذكاء الاصطناعي يسهم في تحسين جودة الحياة.', 'labels': ['رياضة', 'صحة', 'تكنولوجيا']
, 'scores': [0.8476353287696838, 0.15050333738327026, 0.0018613002030178905]}
[6]
المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer والنّموذج التّلقائيّ AutoModel.
إنّ كلمة تلقائي Auto في المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer أو النّموذج التّلقائيّ AutoModel لا تعني أنّ الأداة ستختار النّموذج المناسب بالكامل من تلقاء نفسها بدون أيّ تدخلٍ. وإنّما ما تعنيه هو أنّه بمجرد أن تقدّم اسم النّموذج (مثل “bert-base-uncased”)؛ فإنّ الأداة ستتولّى الباقي بشكلٍ تلقائيٍّ.
ستقوم بتحميل المقسّم إلى وحداتٍ لغويّةٍ Tokenizer المناسب لهذا النّموذج تلقائيًّا.
ستقوم بتحميل النّموذج المناسب تلقائيًّا (في حالة النّموذج التّلقائيّ AutoModel).
إذًا، لماذا نقول أنّه “تلقائيٌّ”؟
على الرّغم من أنّك تمرّر اسم النّموذج (مثل “bert-base-uncased”)، فإنّ ما يحدث وراء الكواليس تلقائيًّا هو:
المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer: يقوم بتحميل المقسّم إلى وحداتٍ لغويّةٍ Tokenizer المناسب للنّموذج الّذي اخترته بناءً على مواصفاته الدّاخلية. أنت لا تحتاج إلى معرفة التّفاصيل الفنّيّة الخاصّة بطريقة تقسيم الكلمات إلى وحداتٍ لفظيّةٍ tokens. مثلًا نموذج بيرت BERT يستخدم التّقسيم إلى جزءٍ من كلمة WordPiece Tokenizer، بينما نموذج جي بي تي GPT يستخدم ترميز أزواج البايت Byte-Pair Encoding (BPE)، والمقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer يعتني بكلّ هذه التّفاصيل.
النّموذج التّلقائيّ AutoModel: يقوم بتحميل النّموذج الملائم تلقائيًّا بناءً على اسم النّموذج الّذي مرّرته. مثلًا إذا اخترت بيرت BERT أو جي بي تي GPT أو روبيرتا RoBERTa، سيقوم بتحميل النّموذج المناسب وتصنيفه لمهام معيّنة (مثل تصنيف النّصوص، أو توليد النّصوص، إلخ).
لدينا المثال الآتي:
إذا كنت تستخدم BertTokenizer يدويًّا بدون Auto:
from transformers import BertTokenizer, BertModel
# هنا يجب عليك معرفة أن النموذج المستخدم هو BERT وأنك بحاجة لاستخدام BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
ولكن مع المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# AutoTokenizer التقسيم التلقائي إلى وحدات لغوية سيختار Tokenizer المناسب بناءً على اسم النموذج دون الحاجة لمعرفة التفاصيل التقنية
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer والنّموذج التّلقائيّ AutoModel يسمحان لك بتحميل الأدوات المناسبة تلقائيًّا بعد أن تمرّر اسم النّموذج (مثل “bert-base-uncased”).
كلمة تلقائي Auto لا تعني أنّك لا تحتاج لتمرير اسم النّموذج، ولكن تعني أنّ الأداة ستقوم بتحديد النّوع المناسب من المقسّم إلى وحداتٍ لُغويَّةٍ Tokenizer أو النّموذج Model استنادًا إلى الاسم الّذي تقدّم به النّموذج من دون أن تتدخل في التّفاصيل الأخرى.
لنعيد المثال الأوّل لتحليل المشاعر باستخدام المقسّم التّلقائيّ إلى وحداتٍ لغويّةٍ AutoTokenizer والنّموذج التّلقائيّ AutoModel:
# Load model directly
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
text = "أنا سعيد جدًا بهذا البرنامج التعليمي. إنه مذهل!!"
tokens = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = model(**tokens)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)
label_ids = torch.argmax(probabilities, dim=1)
config = model.config
print(config.id2label)
labels = ['positive', 'negative', 'neutral']
label = labels[label_ids]
print(f"The sentiment is: {label}")
- تحميل المقسّم إلى وحداتٍ لغويّةٍ tokenizer والنّموذج المدرّبين مسبقًا: يقوم المقسّم إلى وحداتٍ لُغويَّةٍ tokenizer بتحويل النّصوص إلى مدخلاتٍ رقميّةٍ يمكن للنّموذج فهمها. و AutoModelForSequenceClassification هو النّموذج المسؤول عن تصنيف النّصوص (مثل تحديد المشاعر).
- تحويل النّصّ العربيّ إلى وحداتٍ لفظيّةٍ tokens باستخدام المقسّم إلى وحداتٍ لُغويَّةٍ tokenizer: يتمّ استخدام خيارات padding=True لضمان أنّ المدخلات كلّها بنفس الطّول، و truncation=True لقصّ المدخلات الطّويلة، في حين return_tensors=”pt” لتحويلها إلى مصفوفةٍ متعدّدة الأبعاد tensor ليعمل مع مكتبة بايتورش PyTorch.
- تمرير الرّموز إلى النّموذج للحصول على المخرجات: يتمّ تمرير المدخلات إلى النّموذج مع تفعيل torch.no_grad() لتجنّب تتبّع التّدرّجات gradient descent، لأنّنا لا نقوم بتحديث أو إعادة تدريب النّموذج؛ ومن ثمّ يتمّ استخراج القيم logits، وهي مخرجات النّموذج الّتي لم تُحوّل بعد إلى احتمالاتٍ.
- تحويل المخرجات إلى احتمالاتٍ باستخدام سوفت ماكس softmax: يتمّ تطبيق دالّة سوفت ماكس softmax لتحويل القيم logits إلى احتمالاتٍ (قيمٍ بين 0 و 1)، تمثّل احتماليّة أن ينتمي النّصّ إلى كلّ تصنيفٍ (إيجابيٍّ، سلبيٍّ، محايدٍ).
- تحديد التّصنيف الأعلى احتماليّة: يتمّ استخدام دالّة argmax للحصول على الفهرس index الّذي يمثّل التّصنيف الأكثر احتماليّة، أي التّصنيف الّذي يحتوي على أعلى احتمالٍ.
- الحصول على إعدادات النّموذج الّتي تحتوي على القاموس id2label الّذي يربط بين الفهارس indices والتّصنيفات labels: هذا يمكن أن يظهر تصنيفات النّموذج إذا كانت معرّفةً ضمن النّموذج.
- استخراج التّصنيف المناسب: ويتمّ ذلك بناءً على الفهرس label_ids، ثمّ طباعته [4] [5] [6].
الضّبط الدّقيق للنّماذج Fine-tuning models.
الضّبط الدّقيق هو عمليّة أخذ نموذجٍ مُدرَّبٍ مسبقًا وتحديث معاملاته من خلال التّدريب على مجموعة بياناتٍ خاصّةٍ بمهمّتك. يتيح لك هذا الاستفادة من التّمثيلات الّتي تعلّمها النّموذج، وتكييفها مع المهمّة الخاصّة بك.
فيما يلي مثالٌ بسيطٌ لضبط نموذجٍ لتصنيف النّصوص:
اختر نموذجًا مدرّبًا مسبقًا ومجموعة بيانات: حدّد بنية نموذجٍ مناسبةٍ لمهمّتك. في هذه الحالة، نريد الاستمرار في استخدام نموذج تحليل المشاعر نفسه. ومع ذلك، نحتاج الآن إلى بعض البيانات لتدريب نموذجنا.
رابط مجموعة البيانات المستخدمة: مجموعة البيانات
الآن بعد تحديد مجموعة البيانات الّتي يجب اختيارها، يمكننا ببساطةٍ تهيئة كلٍّ من النّموذج ومجموعة البيانات.
from transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer=AutoTokenizer.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
model=AutoModelForSequenceClassification.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
dataset = load_dataset("arbml/Arabic_Sentiment_Twitter_Corpus")
print(dataset )
ليكون الخرج وفق الشّكل الآتي:
DatasetDict({
train: Dataset({
features: ['tweet', 'label'],
num_rows: 47000
})
test: Dataset({
features: ['tweet', 'label'],
num_rows: 11751
})
})
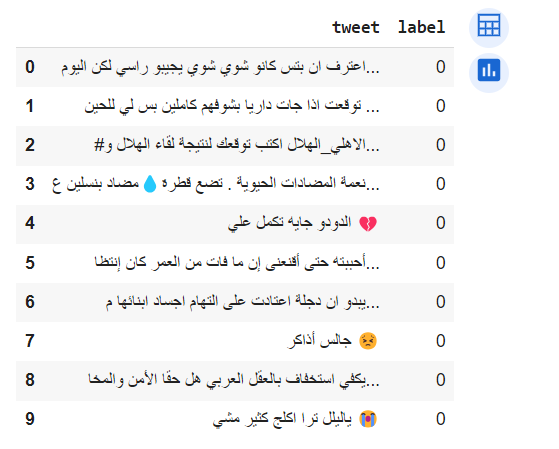
إذا حوّلنا جزءًا من مجموعة البيانات إلى إطار بياناتٍ dataframe باستخدام التّعليمات التّالية:
df = pd.DataFrame(dataset['train'][:10])
نحصل على الخرج الموضّح في الشّكل (2):
تحضير مجموعة البيانات الخاصّة بنا: نحتاج إلى المقسّم إلى وحداتٍ لُغويَّةٍ tokenizer لتجهيز مجموعة البيانات من أجل تحليلها بواسطة نموذجنا، وعليه يتمّ تحميل المقسّم إلى وحداتٍ لُغويَّةٍ tokenizer المدرّب مسبقًا لتقسيم مجموعة البيانات الخاصّة بنا إلى مجموعاتٍ حتّى يمكن استخدامها للضّبط الدّقيق.
tokenizer = AutoTokenizer.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment")
def tokenize_function(examples):
return tokenizer(examples["tweet"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
- تمّ تعريف دالّة tokenize_function: وهي دالّةٌ تأخذ مجموعةً من النّصوص (أو النّصوص) وتقوم بتطبيق عمليّة التَّقسيم إلى وحداتٍ لُغويَّةٍ tokenization عليها باستخدام المقسّم إلى وحداتٍ لُغويَّةٍ tokenizer.
- نختار من البيانات المدخلة عمودًا يسمّى “tweet”، وهو يحتوي على النّصوص (التّغريدات) الّتي سيتمّ ترميزها.
- padding=”max_length”: يعني أنّ النّصوص سيتمّ حشوها padding لتصل إلى الطّول الأقصى المحدّد مسبقًا في النموذج. هذا يضمن أنّ جميع النّصوص لها نفس الطّول.
- truncation=True: يعني أنّه إذا كانت التّغريدات أطول من الحدّ الأقصى المحدّد، فسيتمّ تقصيرها truncate لتناسب الطّول المطلوب.
- يتمّ استخدام دالّة map لتطبيق دالّة tokenize_function على جميع الأمثلة في مجموعة البيانات dataset.
- batched=True: يعني أنّ الدّالة سيتمّ تطبيقها على دفعاتٍ batches من البيانات بدلًا من تطبيقها على كلّ عنصرٍ بشكلٍ فرديٍّ. وهذا من شأنه تحسين الأداء والسّرعة عند معالجة كميّاتٍ كبيرةٍ من البيانات.
- النّتيجة ستكون نسخةً من مجموعة البيانات dataset الأصليّة، ولكن مع إضافة الأعمدة الجديدة الّتي تمثّل المدخلات المرمّزة (مثل input_ids و attention_mask) الّتي يحتاجها النّموذج للقيام بالتّنبؤات.
DatasetDict({
train: Dataset({
features: ['tweet', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 47000
})
test: Dataset({
features: ['tweet', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 11751
})
})
إنشاء مجموعة بيانات بايتورش PyTorch باستخدام التّرميزات encoding: إنشاء مجموعة بياناتٍ للتّدريب والاختبار، حيث سيتمّ استخدام مجموعة التّدريب هذه لضبط نموذجنا بدقّةٍ، بينما سيتمّ استخدام مجموعة الاختبار من أجل تقييمه.
عادةً ما تستغرق عمليّة الضّبط الدّقيق الكثير من الوقت. ولتسهيل البرنامج التّعليميّ، نقوم بأخذ عيّناتٍ عشوائيّةٍ من كلتا مجموعتي البيانات لتقليل وقت الحساب.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
الضّبط الدّقيق للنّموذج: خطوتنا الأخيرة هي إعداد وسطاء التّدريب وبدء عمليّة التّدريب. تحتوي مكتبة المحوّلات على فئة trainer()، الّتي تتولّى كلّ شيء.
from transformers import Trainer, TrainingArguments
import numpy as np
training_args = TrainingArguments(output_dir="trainer_output", evaluation_strategy="epoch")
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
- “: تحديد مسار المجلّد الّذي سيتمّ تخزين نتائج التّدريب فيه، مثل النّماذج المدرّبة والبيانات.
- evaluation_strategy=”epoch”: يعني أنّه سيتمّ تقييم النّموذج في نهاية كلّ “epoch” (دورةٍ تدريبيّةٍ كاملةٍ على البيانات).
لم يتم تحديد عدد الدّورات التّدريبيّة الّتي سيتمّ تدريب النّموذج عليها (الافتراضي 3 دورات)، يمكن تغييرها باستخدام:
training_args = TrainingArguments( output_dir="trainer_output", evaluation_strategy="epoch", num_train_epochs=10 )
- تحميل معيار التّقييم أي الدّقة accuracy من مكتبة evaluate: سيتمّ استخدام هذا المعيار لاحقًا لتقييم أداء النّموذج خلال التدريب.
- تمّ تعريف دالّة compute_metrics الّتي ستحسب الدّقة بناءً على مخرجات النّموذج (التّوقعات).
- يحتوي eval_pred على اثنين من المتغيّرات:
- logits: المخرجات غير المحوّلة للنّموذج (القيم النّاتجة قبل تطبيق سوفت ماكس softmax).
- labels: التّصنيفات الحقيقيّة (المعروفة) الّتي نستخدمها لمقارنة التّوقعات.
- predictions = np.argmax(logits, axis=-1): يستخدم argmax للحصول على الفهرس الّذي يحتوي على أعلى قيمةٍ احتماليّةٍ (أي التّصنيف المتوقّع من قبل النّموذج).
- metric.compute(predictions=predictions, references=labels): يتمّ حساب الدّقة باستخدام معيار التّقييم، حيث يتمّ مقارنة التّوقعات predictions مع التّصنيفات الحقيقيّة labels.
تقييم النّموذج: أخيرًا، يتمّ تقييم النّموذج باستخدام التّعليمة التّالية:
trainer.evaluate()
يكون الخرج بالشّكل التّالي:
{'eval_loss': 1.464263916015625,
'eval_accuracy': 0.655,
'eval_runtime': 29.9709,
'eval_samples_per_second': 33.366,
'eval_steps_per_second': 4.171,
'epoch': 3.0}
بالطّبع يمكننا التّعديل على الوسطاء وعدد الدّورات التّدريبيّة للحصول على دقّةٍ أفضل أو اختيار نموذجٍ آخر وإعادة الضّبط الدّقيق عليه [2] [7].
الخاتمة.
تعدّ مكتبة هاكينغ فيس Hugging Face والمحوّلات Transformers من الأدوات القويّة الّتي أحدثت تغييرًا كبيرًا في مجال معالجة اللّغات الطّبيعيّة والتّعلّم الآليّ. لقد جعلت هذه المكتبة تقنيّات الذّكاء الإصطناعيّ المتقدّمة متاحةً للجميع، ممّا سمح للمطوّرين _من المبتدئين إلى الخبراء_ بالاستفادة من نماذج مدرّبةٍ مسبقًا والتّعديل عليها بمرونةٍ وسهولة.
بفضل مكتبة المحوّلات Transformers، أصبح بالإمكان إنجاز المهام المختلفة من تحليل النّصوص إلى التّرجمة وتوليد النّصوص بدقّةٍ وسرعةٍ عاليةٍ. ومع تزايد الاهتمام بدمج النّماذج اللّغويّة الذّكيّة في التّطبيقات اليوميّة؛ يتوقّع أن تلعب هذه المكتبة دورًا محوريًّا في تطوير حلول مبتكرة تعزّز من فهم وتفاعل الآلات مع اللّغة البشريّة.