
التدّقيق العلمي: د. م. حسن قزّاز، م. محمد سرميني
التدّقيق اللّغوي: هبة الله فلّاحة
المَحتويَات
- المقدّمة:
- تعزيز البيانات:
- كيفيّة تطبيق تعزيز بيانات الصّورة باستخدام كيراس (Keras):
- التّعزيز بالإزاحة العموديّة والأفقيّة (Horizontal and Vertical Shift Augmentation):
- التّعزيز بالانعكاس العموديّ والأفقيّ (Horizontal and Vertical Flip Augmentation):
- التّعزيز بالتّدوير العشوائيّ (Random Rotation Augmentation):
- التّعزيز بضبط مستوى السّطوع بشكل عشوائيّ (Random Brightness Augmentation):
- التّعزيز بالتّكبير والتّصغير العشوائيّ للصّورة (Random Zoom Augmentation):
- دمج كلّ تقنيّات التّعزيز:
- الخاتمة:
- المراجع:
المقدّمة:
“تعزيز بيانات الصّورة “عنوانٌ عريضٌ رنّانٌّ استحوذ اهتمام العديد من مجالات الذّكاء الاصطناعيّ وآفاقه الشّاسعة، مثل التّعلّم العميق (Deep Learning) والرّؤية الحاسوبيّة (Computer Vision) ومعالجة اللّغات الطّبيعيّة (Natural Language Processing) وغيرها الكثير.
إنّ التّقنيّات المتّبعة لتعزيز البيانات في المجالات آنفة الذّكر، تعدّ إحدى وسائل الولوج نوعًا ما إلى برّ الأمان للتّعامل بشكلٍ جيّدٍ مع مشكلة الملاءمة الزّائدة (Overfitting) بصدد التّخلّص منها، والّتي من المؤكّد أنّها ستؤثّر بشكلٍ أو بآخر على أداء النّموذج المدرّب وقدرته في الحصول على دقّةٍ عاليةٍ في عمليّة التّنبّؤ.
إذًا لنعرج الآن إلى سراديب مقالتنا، لنكتشف سويّةً ماهيّة هذا التّعزيز والفوائد الكامنة خلف استخدامه مع سردٍ للتّقنيّات المضمّنة بداخله وإجراء تطبيقٍ عمليٍّ للبعض منها باستخدام مكتبة كيراس (Keras).
تعزيز البيانات:
إنّ تعزيز البيانات بتقنيّاته المختلفة، عمليّةٌ متّبعةٌ لزيادة عيّنات مجموعة التّدريب بشكلٍ مصطنعٍ من خلال إنشاء نسخٍ معدّلةٍ من مجموعة البيانات الأصليّة اعتمادًا على البيانات الموجودة، وهذا الأمر يتضمّن إمّا القيام بتغييراتٍ طفيفةٍ على مجموعة البيانات أو الاستعانة بنماذج التّعلم العميق القادرة على توليد نقاط بياناتٍ جديدةٍ. [3]
2-1- الفرق بين البيانات المعزّزة (Augmented Data) والبيانات الاصطناعيّة (Synthetic Data):
إنّ الكثيرين يغالطون بمعنى هذين المصطلحين على حدٍّ سواء، ولكنّهما كمثل وجهين لعملةٍ واحدةٍ (زيادة كميّة البيانات اصطناعيًّا) والفرق بينهما كالتّالي:
البيانات المعزّزة كما نعلم مقادةٌ من قبل البيانات الأصليّة (أي مستمدّةٌ منها) مع إجراء نوعٍ من التّغييرات الطّفيفة عليها، وفي حالتنا المدروسة هذه والّتي هي تعزيز بيانات الصّورة، نقوم بإجراء تحويلاتٍ هندسيّةٍ وأيضًا للفضاء اللّونيّ مثل الانعكاس (flipping)، تغيير الحجم (resizing)، الاقتصاص (cropping)، التّحكّم بدرجة السّطوع (brightness)، التّدوير (rotation)، التّحكّم بدرجة التّباين (contrast)، وذلك لزيادة حجم وتنوّع واختلاف مجموعة بيانات التّدريب. [3]
أمّا بالنّسبة للبيانات الاصطناعيّة فيتمّ توليدها بشكلٍ مصطنعٍ أيضًا، ولكن من دون تدخّل أو استخدام مجموعة البيانات الأصليّة، حيث يُعتمد في توليد مثل هذه البيانات على نماذج تعلّمٍ عميقٍ جاهزةٍ كأمثلةٍ عنها لدينا الشّبكات العصبيّة العميقة (Deep Neural Networks=DNNs)، و شبكات الخصومة التّوليديّة (Generative Adversarial Networks=GANs)، ونقل الأسلوب العصبيّ (Neural Style Transfer)، الّذي من شأنه زيادة متانة ودقّة ونوعيّة النّموذج المدرّب. [3]
2-2- الوقت الأمثل لتعزيز البيانات:
يفضّل استخدامه وأخذ عين الاعتبار في الحالات التّالية:
- تجنّب مشكلة الملاءمة الزّائدة (Overfitting) في النّماذج المدرّبة.
- مجموعة بيانات التّدريب الأوّليّة صغيرة للغاية.
- تحسين دقّة وأداء النّموذج.
- تقليل كلفة جمع البيانات وتخصيصها لعدّة عناوينٍ (labels) والحاجة لتنقيّية البيانات الخام [3].
2-3- تقنيّات تعزيز البيانات:
- التّحويلات الهندسيّة (Geometric transformations): مثل القيام بشكلٍ عشوائيٍّ بعمليّة الانعكاس، الاقتصاص، التّدوير، التّمديد والتّوسيع، التّكبير والتّصغير المطبّقة على الصّور، ولكن من الجيّد توخّي الحذر حول تطبيق تحويلاتٍ عديدةٍ على الصّورة ذاتها؛ لأنّ من شأن ذلك أن يقلّل أداء النّموذج الّذي يعتمد على نوعيّة وحجم بيانات الدّخل.
- تحويلات الفضاء اللّونيّ (color space transformations): مثل القيام بشكلٍ عشوائيٍّ بتغيير قيمة درجات الألوان الخاصّة بقنوات النّظام اللّوني الثّلاثيّ الأحمر والأخضر والأزرق (RGB)، أو تغيير التّباين أو السّطوع والإضاءة.
- مرشّح الطّيّ (Kernel filter): مثل القيام بشكلٍ عشوائيٍّ بتغيير حدّة الصّورة (sharpness) أو غباشتها (blurring) .
- المسح العشوائيّ (random erasing): يتمّ ذلك من خلال حذف جزء من الصّورة الأوّليّة.
- مزج الصّور (Mixing images): يتمّ ذلك من خلال دمج ومزج صورٍ متعدّدةٍ. [3]
كيفيّة تطبيق تعزيز بيانات الصّورة باستخدام كيراس (Keras):
قبل الخوض في القسم العمليّ الخاصّ بتعزيز البيانات، أودّ التّنويه عزيزي القارئ على أنّ هذه التّقنيات المستخدمة ليست محدودةً ضمن نطاق الصّور فقط، وإنّما نستطيع تعزيز البيانات للصّوت والفيديو والنّص وأنواع أخرى أيضًا من البيانات على اختلافها، كما وأنّه من المعتاد تطبيق هذه التّقنيّات على مجموعة بيانات التّدريب (training)، وليس على مجموعة بيانات التّحقّق (validation) أو الاختبار (testing)؛ والسّبب وراء ذلك يعزى في الحصول على تقييمٍ واقعيٍّ وحقيقيٍّ للنّموذج منعًا من تشويه النّتائج، وللتّحقّق من طريقة تصرّف نموذجنا على بياناتٍ غير مرئيّةٍ له من قبل، وكلّ هذا يختلف عن مرحلة تحضير وإعداد البيانات؛ مثل إعادة ضبط حجم الصّورة (image resizing) و تقييس قيمة البكسل (pixel scaling)؛ والّتي يجب إجراؤها بشكلٍ مستمرٍّ على كلّ مجموعات البيانات التّي تتعامل وتتفاعل مع النّموذج.
طبعًا توفّر مكتبة كيراس _مكتبة الشّبكة العصبيّة للتّعلم العميق الغنيّة عن التّعريف_ القدرة على ملاءمة النّماذج باستخدام تعزيز بيانات الصّورة من خلال الصّنف المعرّف مسبقًا ضمن هذه المكتبة؛ وهو مولّد بيانات الصّورة (ImageDataGenerator) الّذي سنوضّحه في الخطوات القليلة القادمة.
دعونا الآن _بعد أن اتّضحت معالم هذا النّوع من تعزيز البيانات_ إسقاط السّرد النّظري السّابق بتطبيقٍ عمليٍّ لبعض التّقنيات مع توضيحٍ بسيطٍ لكلّ شيفرةٍ برمجيّةٍ منها.
بدايةً يجب علينا استيراد المكتبات والتّوابع الضروريّة للعمل، مكتبة بايثون العدديّة (Numpy)، مجموعة التّوابع الموجودة ضمن مكتبة الرّسم الرّياضيّ في بايثون ماتبلوت (matplotlib)، مولّد بيانات الصّورة التّابع لمكتبة كيراس (ImageDataGenerator)، تابع تحميل الصّورة في كيراس (load_img)، تابع تحويل الصّورة لمصفوفة في كيراس (img_to_array)، مع التّنويه على أنّ هذه الشّيفرات البرمجيّة المستخدمة مأخوذة من المرجع [1] ضمن قائمة المراجع المعرّفة في نهاية مقالتنا.
# import libraries or modules
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing.image import load_img
# from tensorflow.keras.utils import load_img
from tensorflow.keras.utils import img_to_array
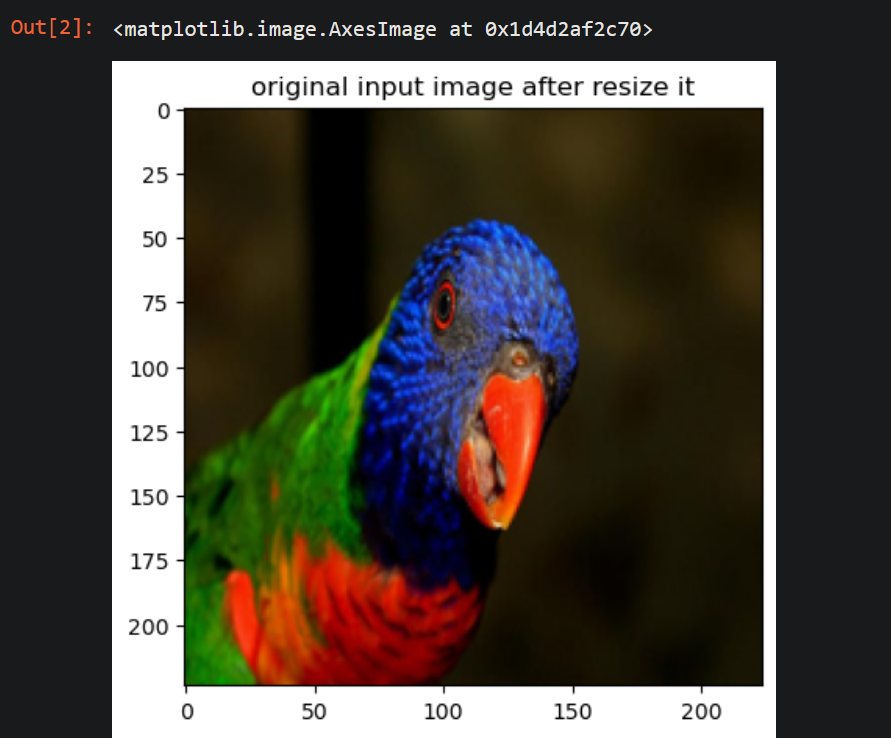
سنقوم بعد ذلك بتحميل العيّنة (الصّورة) المراد تطبيق تحويلاتٍ عليها (الّتي هي صورة لطائرٍ تمّ التقاطها من قبل (AndYaDontStop) الموضّحة وفق الشّكل (1) والمشار إليها في المرجع [1] ) من خلال تابع تحميل الصّورة (load_img) الّذي يعيدها ككائن صورة من (PIL=Python Imaging Library) أي مكتبة التّلاعب ومعالجة الصّور في بايثون، وبصيغة (JPEG) مع قنواتٍ لونيّةٍ بنظام (RGB) .
بالنّسبة لحجم الصّورة كانت بحدود 640 بكسل عرضٍ و 399 بكسل طولٍ، ولكن قمنا بإعادة ضبط الحجم ل 224 بكسل عرضٍ و مثله للطّول، وهذه الخطوة ليست مهمّة بسبب وجود صورةٍ واحدةٍ، وإنّما هي للتّنويه على أنّه عند وجود كميّةٍ هائلةٍ من العيّنات يجب جعل هذه الصّور وفق حجمٍ ثابتٍ لتقليل عدد المعاملات (parameters) وتسهيل عمليّة تدريب النّموذج وفق المهمّة المطلوبة.
يجب ألاّ ننسى أنّه من المهمّ تحويل الصّورة إلى مصفوفةٍ ثلاثيّة الأبعاد ليتمّ استخدامها في نماذج التّعلّم العميق، وهذا باستخدام تابع تحويل الصّورة لمصفوفةٍ (img_to_array)، ثمّ نقوم بتوسيع الأبعاد لبعدٍ رابعٍ وهو عدد العيّنات المدخلة أي حجم الدّفعة في حالتنا (1=batch_size) وفق تابع توسيع الأبعاد (expand_dims) من مكتبة بايثون العدديّة، حيث الوسيط الأوّل للتّابع هو المصفوفة أمّا الثّاني هو رقم الفهرس لإضافة هذا البعد الرّابع للمصفوفة، وأخيراً قمنا بعرض العيّنة بعد ضبط حجمها وفق الشّكل (1) الآتي:
# first of all we have to load the image
img=load_img('bird.jpg')
# print(img.format) #the output will be'JPEG'
# print(img.getdata)
size=img.size
print('image_size =',size,'\n')
resized_img=img.resize((224,224))
# covert it to numpy array with 3 dimensions
data=img_to_array(resized_img)
print(data.shape,"",data.ndim,"\n")
# expand dimension to one sample to be 4D array
sample=np.expand_dims(data,0)
print(sample.shape,"",sample.ndim)
plt.title('original input image after resize it')
plt.imshow(resized_img)
كما أسلفنا سابقًا سنقوم بتطبيق تعزيز البيانات على الصّورة من خلال أخذ غرضٍ (object) من صنف مولّد بيانات الصّورة (ImageDataGenerator) الّذي يستخدم لتوليد دفعاتٍ من بيانات صورٍ بشكل مصفوفةٍ متعدّدة الأبعاد (tensor images)، ليس هناك داعٍ للخوف من مصطلح تينسور فنحن نستخدمه كثيرًا وهو طريقة تمثيلنا للأعداد وبيانات الدّخل والخرج وكلّ شيٍ بينهما في نماذج تعلّم الآلة وفق شكل (shape)ورتبة (rank) معيّنة، وبإسقاطه على مثالنا نتج لدينا في الشّيفرة البرمجيّة السّابقة (1,224,224,3) الّذي يعتبر (tensor shape) أمّا الرّتبة فهي (tensor rank=4) وهكذا… طبعًا مولّد البيانات يحتوي على مجموعة من المعاملات والّتي تساعدنا في تحديد سلوك وطريقة أداء عمليّة التّعزيز.
سنبدأ بتطبيق بعض التّقنيّات على العيّنة الخاصّة بنا بشكلٍ مستقلٍّ كلٍّ على حدةٍ باستخدام مولّد البيانات، ومن الشّائع أيضًا استخدام مجال من تقنيّات التّعزيز في نفس الوقت عندما ندرّب نماذجنا.
التّعزيز بالإزاحة العموديّة والأفقيّة (Horizontal and Vertical Shift Augmentation):
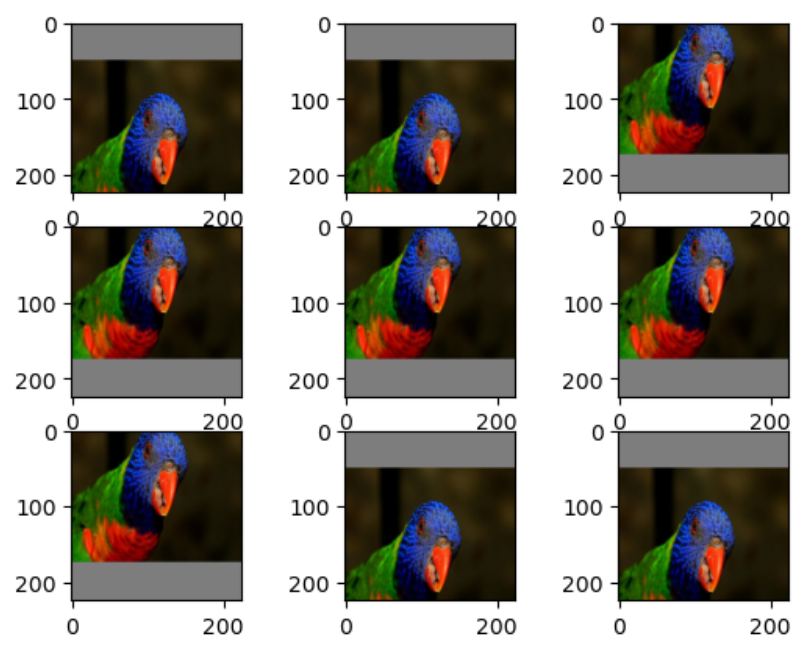
إزاحة الصّورة تعني تحريك كلّ بكسلات الصّورة وفق اتجاهٍ واحدٍ (عموديًّا أو أفقيًّا) مع الاحتفاظ بالأبعاد كما هي، وبالتّالي سيتمّ اقتصاص بعض البكسلات وستبقى منطقة من الصّورة يجب تحديد قيم البكسلات فيها. [1]
في الإزاحة العموديّة استخدمنا المعامل (width_shift_range) وقمنا بتحديد القيمة الصّغرى والقيمة الكبرى لمجال إزاحة البكسلات كقيمٍ صحيحةٍ (integer)أي [50+,50-]بكسل إزاحةٍ، ,وأيضًا اخترنا طريقة ملء البكسلات الفارغة النّاتجة عن الإزاحة من خلال المعامل التّالي (fill_mode) وفق مقدارٍ ثابتٍ (cval=125) أي بكسلاتٍ رماديّةٍ وهذا ما يوضّحه المقطع البرمجيّ التّالي:
# create image data augmentation generator
# random vertical shift augmentaion
# fill_mode: One of {"constant", "nearest", "reflect" or "wrap"}
datagen1=ImageDataGenerator(width_shift_range=[-50,+50],
fill_mode='constant',cval=125)
بعد إنشاء الغرض يجب علينا تشكيل مكرّر (iterator) لتحميل الصّور الخاصّة بمجموعة البيانات الأصليّة والمرور عليها حسب قيمة حجم الدّفعة (batch_size)، وتوليد دفعةٍ من الصّور المعزّزة وهذا باستخدام تابع (flow) التّابع للصّنف الّذي يقبل الصّورة وحجم الدّفعة، ولتوضيح العمليّة أكثر سنقوم بحفظ النّتائج ضمن مجلّد تحت اسم (result) وبملفّات صورٍ ذات بادئة (aug) وبلاحقة (jpg) :
# prepare iterator
# flow() takes just 4D array
# flow() function returns an iterator containing batch of augmented images
it=datagen1.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
في المرحلة الأخيرة قمنا بتعريف تابع (plot_samples) لاستدعاء المكرّر المنشأ 9 مرّاتٍ ضمن حلقة، وتشكيل دفعةٍ من الصّور المعزّزة من المولّد باستخدام تابع (next) ثمّ القيام بتحويل الصّورة من (float32) إلى (uint8) لسهولة عرضها بقيم بكسلاتٍ تتراوح بين 0 و 255، تظهر لدينا النّتائج بعد عمليّة الإزاحة العموديّة وفق الشّكل (2) مع ملاحظة أنّ الأجزاء الفارغة من الصّورة تمّت تعبئتها ببكسلاتٍ رماديّة اللّون كما تمّ ذكره:
def plot_samples():
# generate samples and plot
for i in range(9):
#define subplot
plt.subplot(3,3,i+1) #plt.subplot(331+i)
#get the next new augmented image in the batch
batch=it.next()
#convert to unsigned integer for viewing
image=batch[0].astype('uint8')
#plot the image
plt.imshow(image)
plt.show()
plot_samples()
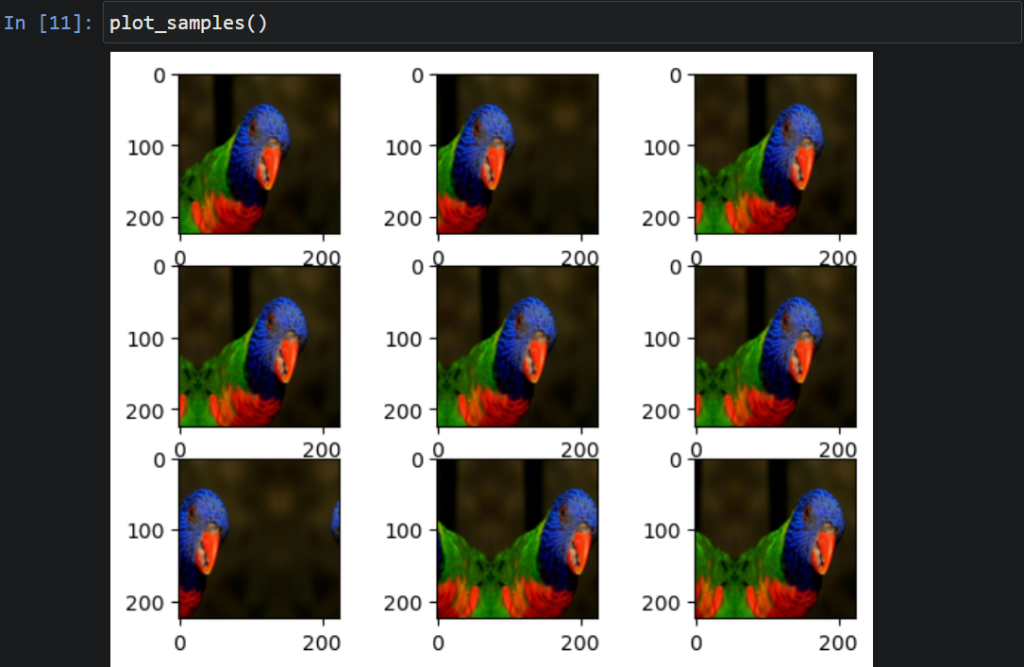
بالنّسبة للإزاحة الأفقيّة استخدمنا المعامل (height_shift_range) وجعلناه مساويًا لقيمة 0.5؛ أي سنأخذ النّسبة المئويّة للعرض الكلّيّ (محور X) كمجالٍ وبالتّالي يصبح هذا المجال بين النّسبتين [%50,%50-]، واخترنا طريقة التّعبئة (fill_mode=’reflect’) وهو ملء المناطق النّاتجة عن الإزاحة بانعكاس الصّورة، ثمّ قمنا كما السّابق بتشكيل مكرّرٍ لاستخدامه ضمن تابع توليد العيّنات والرّسم (plot_samples) وهذا ما يظهره الشّكل (3):
# random horizontal shift augmentaion
datagen2=ImageDataGenerator(height_shift_range=0.5,fill_mode='reflect')
# prepare iterator
it=datagen2.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
التّعزيز بالانعكاس العموديّ والأفقيّ (Horizontal and Vertical Flip Augmentation):
الانعكاس الأفقيّ (Horizontal flip) هو انعكاس الصّورة وفق المحور Y بينما الانعكاس العموديّ (vertical flip ) يعكس الصّورة وفق المحور x، وفي حالة الطّائر لدينا نلاحظ أنّ الانعكاس العموديّ لا يعطي أيّة معنى أو أهميّة، إذًا تطبيق هذه التّقنيّة يعتمد على نوع المهمّة المطلوبة؛ فمثلًا الصّور الجوّيّة والمجهريّة وعلم الكونيّات قد يكون من المفيد استخدام الانعكاس بنوعه العموديّ. هنا قمنا بتطبيق الانعكاس الأفقيّ على صورة الطّائر من خلال إسناد المعامل (horizontal_flip=True) لمولّد البيانات، ثمّ تشكيل مكرّر واستدعائه في تابع الرّسم كالتّالي ومن ثمّ عرض النّتائج وفق الشّكل (4):
# Horizontal and Vertical Flip Augmentation
datagen3=ImageDataGenerator(horizontal_flip=True)
# prepare iterator
it=datagen3.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
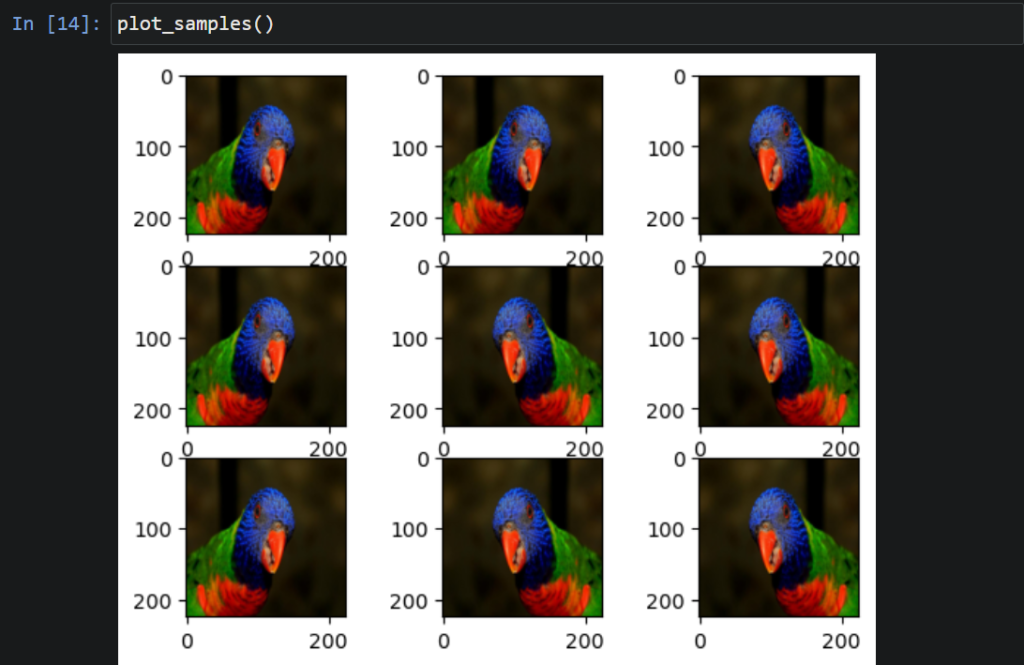
التّعزيز بالتّدوير العشوائيّ (Random Rotation Augmentation):
هو تدوير الصّورة بشكلٍ عشوائيٍّ وذلك بعددٍ معيّنٍ من الدّرجات، ومن المحتمل أن يتمّ تدوير بكسلات الصّورة خارج الإطار وهذا ما يترك خلفه مناطق من الإطار بدون بياناتٍ. استخدمنا لأجل ذلك المعامل (rotation_range=90) أي عمليّة التّدوير ستكون عشوائيّة بين –90 درجة و +90 درجة، أمّا بالنّسبة لطريقة تعبئة المناطق الفارغة خارج إطار الصّورة اعتمدنا على (fill_mode=nearest) أي الملء بقيمة الجوار الأقرب للبكسل والعمل على تمديدها، ومن ثمّ المتابعة وفق الآتي لعرض النّتائج وفق الشّكل (5):
# Random Rotation Augmentation
datagen4=ImageDataGenerator(rotation_range=90,fill_mode='nearest')
# prepare iterator
it=datagen4.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')

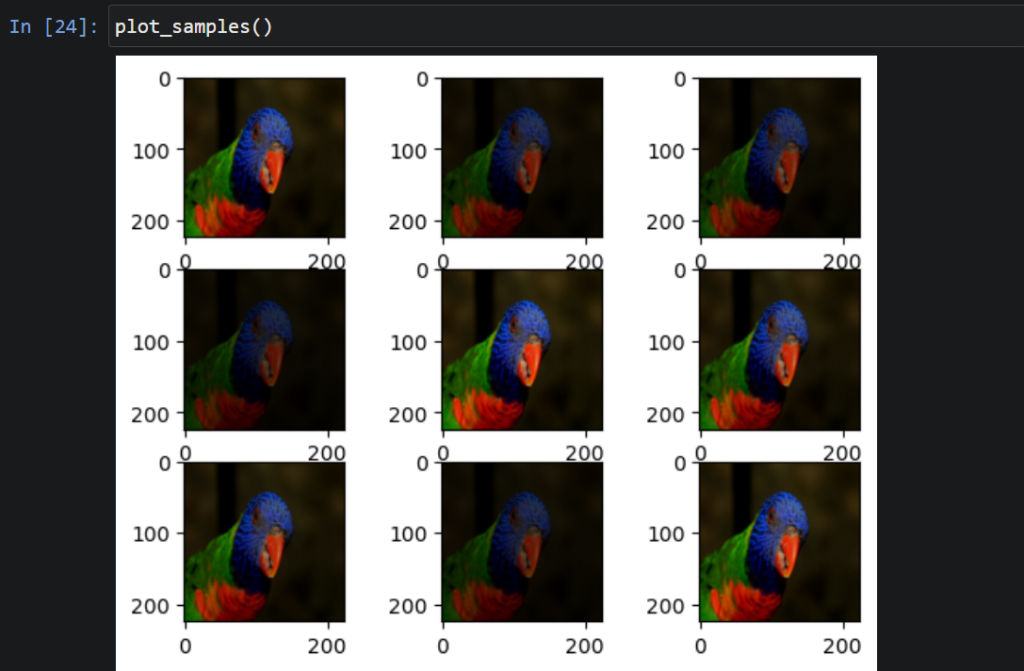
التّعزيز بضبط مستوى السّطوع بشكل عشوائيّ (Random Brightness Augmentation):
من التّقنيّات أيضًا لتعزيز البيانات التّحكّم بدرجة سطوع الصّورة، إمّا عن طريق تعتيم الصّور أو بزيادة سطوعها عشوائيًّا أو بكليهما، وذلك اعتمادًا على المعامل الّذي نمرّره لباني صنف مولّد البيانات [1].
القيم الّتي أقل من 1.0تزيد عتامة الصّورة مثل القيم بين هذا المجال [0.5,1.0]، بينما القيم الّتي أكبر من 1.0 مثل [1.0,1.5] تزيد درجة السّطوع أمّا قيمة 1.0 ليس لها أيّ تأثيرٍ على السّطوع، وهنا من خلال إسناد قيمة معامل السّطوع ([brightness_range=[0.2,1.0) سنلاحظ تطبيق درجاتٍ متفاوتةٍ من التّعتيم على الصّورة بنتائج الشّكل (6)، والموضّحة كالتّالي:
# Random Brightness Augmentation
datagen5=ImageDataGenerator(brightness_range=[0.2,1.0])
# prepare iterator
it=datagen5.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
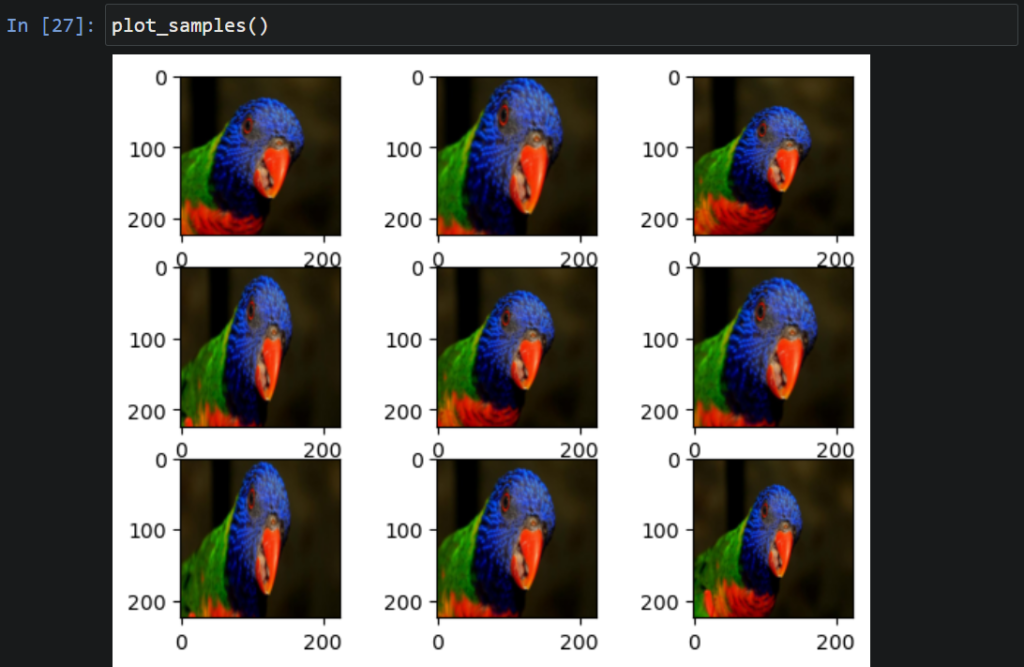
التّعزيز بالتّكبير والتّصغير العشوائيّ للصّورة (Random Zoom Augmentation):
التّقنيّة الأخيرة الّتي سنتناولها في مقالتنا هذه هي التّكبير والتّصغير (zoom in and zoom out) باستخدام المعامل (zoom_range)، حيث تستطيع تحديد النّسبة المئويّة للتّكبير أو التّصغير كرقمٍ حقيقيٍّ مفرد أو مجال مثل مصفوفة قيمٍ، في حال تمّ استخدام قيمة حقيقيّة (float) يمكن حساب المجال كالتّالي [1-value,1+value] وهكذا….ولاحظ أنّ القيم الأقل من 1.0 تجعل الكائن في الصّورة أكبر أو أقرب والقيم الأكثر من 1.0 تجعل الكائن أصغر أو أبعد من موقعه الأصليّ، أمّا 1.0 فتعني لا تغيير وأنّ هذه التّقنيّة تطبّق بشكلٍ مستقلٍّ على المحور الأفقيّ والعموديّ؛ لذلك ستتغيّر نسبة العرض إلى الارتفاع للصّور (aspect ratio). في مثالنا قمنا بإسناد المجال [0.5,1.0] أي سيظهر طائرنا كبيرًا وأقرب بدرجاتٍ متفاوتةٍ ضمن المجال المذكور وفق الشّكل (7) التّالي: [1]
# Random Zoom Augmentation
datagen6=ImageDataGenerator(zoom_range=[0.5,1.0])
# prepare iterator
it=datagen6.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
دمج كلّ تقنيّات التّعزيز:
بالطّبع عزيزي القارئ تستطيع الجمع بين جميع تقنيّات التّعزيز الّتي ناقشناها حتّى الآن.
كملاحظةٍ عمليّةٍ أخيرةٍ، من الجيّد لنا أن نلقي نظرةً عن كثبٍ لخرج عمليّة التّعزيز قبل أن نبدأ بتدريب النّموذج الخاصّ بنا؛ والسّبب في ذلك أنّنا نقوم بجمع تحويلاتٍ عديدةٍ قد تتسبّب لنا في الحصول على صور خرجٍ مشوّهةٍ كثيرًا.
قمنا بإنشاء تابع رسمٍ جديدٍ (plot_samples2) واستدعينا بداخله التّابع (subplots) من مكتبة الرّسم الرّياضيّ في بايثون، مع تحديدٍ لعدد الأسطر والأعمدة ب 8 لاستدعاء المكرّر 64 مرّةٍ وتوليد 64 صورةٍ معزّزةٍ من الأصليّة بتطبيق مختلف التّقنيّات وعرض النّتائج النّهائيّة وفق الشّكل (8)، كما توضّحه الشّيفرة البرمجيّة التّالية الموجودة ضمن المرجع [2]:
# Combining all the augmentations
datagen_all=ImageDataGenerator(width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
rotation_range=40,
brightness_range=[0.50,2.0],
zoom_range=[0.8,1.5])
# prepare iterator
it=datagen_all.flow(sample,batch_size=1,save_to_dir='result',
save_prefix='aug',save_format='jpg')
def plot_samples2():
rows = 8
columns = 8
fig, axes = plt.subplots(rows,columns)
for r in range(rows):
for c in range(columns):
batch =it.next()
image = batch[0].astype('uint8')
axes[r,c].imshow(image)
fig.set_size_inches(15,10)
plot_samples2()

الخاتمة:
كما رأينا يمكننا إنشاء مجموعةٍ واسعةٍ ورائعةٍ من التّغييرات من مجرّد عيّنةٍ واحدةٍ، وهذا مفيدٌ جدًّا لمهامّ تصنيف الصّور لتدريب وتحسين أداء أيّ نموذجٍ بشكلٍ أكثر فاعليّةٍ والتّغلّب على مشكلة الملاءمة الزّائدة (overfitting).
المراجع:
- How to Configure Image Data Augmentation in Keras – MachineLearningMastery.com
- Image Data Augmentation for Deep Learning | by Wei-Meng Lee
- A Complete Guide to Data Augmentation | DataCamp




