
“الموسيقى هي اللغة العالمية للبشر” ، لطالما سمعنا هذا، ولا عجب في أن يقال هذا إذ أننا نجد الموسيقى متواجدة لدى كل شعوب العالم من قديم الزمان، وإن هم تمايزوا بالأدوات ولكن الأساس واحد وهو وجود الموسيقى، ونحن الآن لا نحيد بعيدًا عن درب أسلافنا بل لعلنا قد استثمرنا الموسيقى كما لم يفعلوا هم يومًا، فنحن الآن نستخدمها في كل مكانٍ وزمانٍ تقريبًا ولم نعد نقتصر في استخدامنا لها على الحفلات وسهرات السمر، بل إننا نستمع لها في السيّارة والعمل وفي النّادي الرياضي وللبعض عند النّوم بل وإن العديد من الدراسات الطبية تتحدث عن استخدام الموسيقى للعلاج، فحق لها في عصر الذّكاء الصناعي هذا أن تأخذ حيزًا من فضاء أبحاثه واستخداماته الواسعة.
لعلّ المثال الأشهر للتطبيقات التي تستخدم الذكاء الصناعي وتقنيات التعلّم العميق في معالجة الموسيقى هو سبوتي-فاي Spotify، فهل تساءلت يومًا كيف يعمل؟ هل تساءلت يومًا كيف يمكن له وللتطبيقات المشابهة أن تقترح لك الموسيقى التي تتلاءم مع ذوقك؟ أو تصنف لك الموسيقى لتتناسب مع مزاج معين؟
إن كانت هذه الأسئلة تثير اهتمامك أو تؤرق ليلك اسمح لي صديقي القارئ أن أضعك على أول الطريق الذي سلكه سبوتي-فاي والتطبيقات المشابهة حتى وصلت لما ترى.
المحتويات
الموجات الصّوتية في لغة البرمجة بايثون
الأصوات تمثل إلكترونيًا بما يعرف بالموجة الصوتية Audio وهذه الموجة تمتلك عدة مُعلِمات كالتردد وعرض الحزمة والشدة. الموجة الصوتية تمثل عادةً بتابع للشدة Amplitude خلال الزمن Time.

وهذه الأصوات تخزن بعدة صيغ من أشهرها:
- MP3: طبقة الصوت الثالثة لمجموعة خبراء الصورة المتحركة MPEG Audio Layer-3.
- ملف ويندوز الصوتي WMA (Windows Media Audio)
- ملف الشكل الموجي الصوتي wav (Waveform Audio File)
المكتبات الصوتية
لغة البرمجة بايثون صارت من اللغات الرائدة في معالجة الصوت حيث تتواجد فيها عدة مكتبات لمعالجة الصوت، بالإضافة إلى عدة نماذج افتراضية متوافرة ضمن لغة البايثون للمعالجات الأساسية للصوت.
في مقالنا هذا سنركز على مكتبتين أساسيتين:
مكتبة تحليل الصوت والموسيقى” روزا” Librosa
وهي مكتبة لمعالجة الصوت بشكل عام ولكنها تملك بعض التوجه نحو الموسيقى بشكل خاص، فهي تمتلك ما يلزم لبناء نظام استعادة المعلومات الموسيقية (MIR(Music information retrieval system، هذا بالإضافة إلى كونها موثقة بشكل جيد، وهناك العديد من الأمثلة والمصادر التعليمية لها.
لمزيد من المعلومات عن المكتبة ومبادئ عملها بإمكانكم الإطلاع على الورقة البحثية التي تناقشها من هنا.
التثبيت:
pip install librosa
أو عن طريق نظام إدارة الحزم كوندا
conda install -c conda-forge librosa
ويمكن الاستفادة من مكتبة (ffmpeg) لإمكانيات إضافية في فك ترميز الملفات الصوتية.
تحميل ملف صوتي:
import librosa
audio_path = 'audio.wav'
x , sr = librosa.load(audio_path)
وهذه الدالة ستُحَمِل سلسلة صوت زمنية تمثل برمجيًا بمصفوفة من مكتبة بايثون العددية numpy بمعدل تقطيع 22KHZ وحيد النمط (موجة واحدة) ويمكن تعديل هذا باستخدام الأمر:
librosa.load(audio_path, sr=44100)
أو يمكن إلغاء إعادة التقطيع تمامًا باستخدام الأمر التالي:
librosa.load(audio_path, sr=None)
حيث أن معدل التقطيع هو عدد العينات الصوتية التي يتم تشغيلها كل ثانية، وتقاس بالهيرتز Hz أو بالكيلو هيرتز KHz.
أما لتشغيل الصوت فيمكن استخدام الأمر التالي:
import IPython.display as ipd
ipd.Audio(audio_path)
والذي سيرجع أداة الصوت التي يمكننا تشغيل الصوت من خلالها.
تمثيل الصوت
التمثيل البياني Waveform:
يمكننا رسم الموجة الصوتية باستخدام الأوامر التالية
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr)
plt.show()
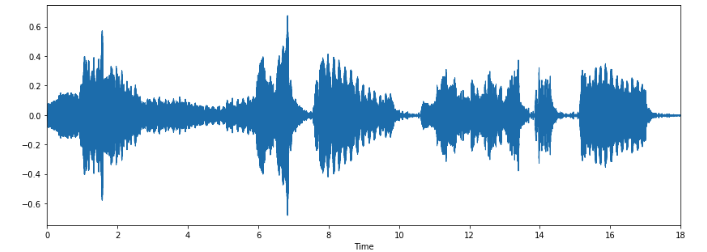
التمثيل الطيفي Spectrogram:
حيث أننا في شكل التمثيل هذا نقوم بتصوير طيف الإشارة الصوتية خلال الزمن، وذلك من خلال مصفوفة ثنائية البعد يمثل البعد الأول فيها التردد أما الثاني فيمثل الزمن.
وبإمكاننا إظهار طيف الإشارة باستخدام الأوامر التالية:
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
plt.figure(figsize=(14, 5))
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz')
plt.colorbar()
plt.show()

وكما نلاحظ أن أغلب الإشارة متوضعة في الجزء السفلي من الطيف؛ لذا بإمكاننا استخدام تابع تمثيل لوغرتمي لمحور التردد (y)
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='log')

كتابة الصوت
ويمكن تخزين الصوت باستخدام الأمر التالي:
librosa.output.write_wav('example.wav', x, sr)
إنشاء موجة صوتية:
الموجة الصوتية ما هي في الواقع إلا مصفوفة من مكتبة بايثون العددية numpay، لذا يمكننا في الواقع إنشاء هذه المصفوفة ومن ثمة تمريرها إلى تابع الإشارة الصوتية كالتالي:
import numpy as np
sr = 22050 # sample rate
T = 5.0 # seconds
t = np.linspace(0, T, int(T*sr), endpoint=False) # time variable
x = 0.5*np.sin(2*np.pi*220*t)# pure sine wave at 220 Hz
# Playing the audio
ipd.Audio(x, rate=sr) # load a NumPy array
# Saving the audio
librosa.output.write_wav('tone_220.wav', x, sr)
وبهذا تكون قد أنشأت موجتك الصوتية الأولى
استخلاص المزايا الصوتية Feature extraction
كل موجة صوتية تحتوي على الكثير من المزايا ، ولكننا يجب أن نركز حال عملنا على المشكلة التي نحاول حلها والمزايا أو الخواص المرتبطة بها؛ عملية انتقاء المميزات هذه تسمى استخلاص المزايا Feature extraction. في السطور القليلة القادمة سنناقش بعض أهم هذه الخواص بشيء من الاستفاضة؛ لكي ندخل إلى حل مشكلتنا على بينة.
معدل العبور الصفري Zero Crossing Rate
وهي قيمة تمثل معدل المرات التي تتغير فيها الإشارة الصوتية من السالب إلى الموجب أو بالعكس، وهذه الخاصية من أكثر الخواص التي تم اسخدامها خصوصًا في عمليات التعرف على الصوت واسترجاع المعلومات الموسيقية.
فمثلًا معدل العبور الصفري يكون أعلى في الموسيقى ذات الإيقاع العالي كموسيقى الروك Rock أو الميتل Metal.
وبإمكاننا استخلاص عدد مرات العبور الصفري من خلال التابع التالي:
zero_crossings = librosa.zero_crossings(x, pad=False)
ومن ثمة بالقسمة على طول الإشارة نحصل على معدل العبور الصفري:
print("the zero crossing:", sum(zero_crossings)/len(x))
نقطة مركز الطيف Spectral Centroid
وهي تشيبر إلى نقطة تمركز «كتلة» الإشارة الصوتية، ويتم حسابه عن طريق استخلاص
الوسط الحسابي الموزون (Weighted arithmetic mean) للترددات الواردة في الإشارة الصوتية.
ونجد مثلاً أن في موسيقى الميتل Metal يكون مركز الطيف أقرب إلى نهاية المقطع الموسيقي، بينما في مقطع موسيقي لموسيقى البلوز Blues سيقع في موقع أقرب للوسط.
وبإمكاننا استخلاص نقطة مركز الطيف من خلال التعليمات التالية، وبالاستعانة بالتابع «librosa.feature.spectral_centroid» والذي يقوم بحساب نقطة مركز الطيف لكل إطار في الإشارة الصوتية:
#spectral centroid
spectral_centroids = librosa.feature.spectral_centroid(x, sr=sr)[0]
spectral_centroids.shape
(775,)
# Computing the time variable for visualization
frames = range(len(spectral_centroids))
t = librosa.frames_to_time(frames)
# Normalising the spectral centroid for visualisation
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis)
#Plotting the Spectral Centroid along the waveform
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_centroids), color='r')
plt.show()

نلاحظ أن المركز يرتفع عند كل بداية مقطع من الإشارة الصوتية.
تدحرج الطيف Spectral Rolloff
وهو يرسم شكل الإشارة الصوتية وفق التردد الذي تقع نسبة معينة من الطيف – مثلاً: 85% – أسفل منه، ويستخدم ليساعد على تحديد الإيقاع والضروب الموسيقية؛ حيث أنها يصعب ملاحظتها في الطيف الكامل لكنها تظهر بوضوح بعد تنفيذ دالة التدحرج الطيفي.
ويمكن حسابه وفق التعليمات التالية، حيث أن التابع «librosa.feature.spectral_rolloff» يحسب تدحرج الطيف لكل إطار:

معاملات ميل التردد mel-frequency cepstral coefficients
وهي تمثل الإشارة بمجموعة محددة صغيرة من الترددات ما بين [10 -20] تردد، حيث هذه الترددات تماثل ترددات الصوت البشري، والتي يدركها الإنسان بوضوح.
ولحسابها:
#Mel-Frequency Cepstral Coefficients
mfccs = librosa.feature.mfcc(x, sr=sr)
print(mfccs.shape)
#Displaying the MFCCs:
librosa.display.specshow(mfccs, sr=sr, x_axis='time')
plt.show()

النتيجة لهذا الأمر ستكون (20, 591) حيث أنه تم تمثيل الطيف ذي الـ 591 إطاربـ20 معامل MFCC.
الترددات الكروماتية Chroma Frequencies
وهي طريقة قوية لتمثيل الموجة الصوتية وفق السلم الكروماتي الموسيقي، حيث يتم إسقاط الطيف الموسيقي كاملاً على 12 نقطة تمثل نغمات السلم الكروماتي.
ويمكن الحصول على هذا التمثيل في Librosa وفق التعليمات التالية:
hop_length = 512
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=hop_length)
plt.figure(figsize=(15, 5))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm')

حالة دراسية: تصنيف الأغاني إلى فئات مختلفة
بعد أن تعرفنا على الموجة الصوتية وخواصها واستخلاصهم بشيء من التفصيل، حان الوقت لنطبق ما تعلمناه على نموذج مشكلة حقيقية، مشكلة تعلم آلة.
الهدف
في هذه المهمة سنقوم بتصنيف مجموعة من الملفات الصوتية وفقًا لفئاتها الموسيقية، حيث أننا سنفترض أن بين أيدينا مجموعة الملفات هذه التي لا نمتلك أي معلومات عن تصنيفها وسنحاول أن نجد طريقة لتصنيفها في مجلدات مختلفة بحسب الفئة هل هي الروك Rock أو الجاز Jazz … إلخ.
مجموعة البيانات
للبيانات سنستخدم مجموعة (GTZAN Genre Collection)، وهي مجموعة تم استخدامها في ورقة بحثية شهيرة
بعنوان (Musical genre classification of audio signals) والتي صدرت عام 2002 [5].
مجموعة البيانات هذه تحتوي على ألف مقطع موسيقي كل منها بطول ثلاثين ثانية، وتحتوي المجموعة على عشرة فئات موسيقية مسماة وهي (blues, classical, country, disco, hiphop, jazz, reggae, rock, metal, pop) وذلك بحيث أن كل فئة تملك 100 مقطع صوتي.
تصنيف المقاطع الموسيقية إلى فئات
استخلاص المزايا :
سنبدأ أولًا باستخلاص المزايا من الملفات الصوتية، والمزايا التي سنستخلصها هي كل المميزات الخمسة التي شرحناها أعلاه، وبعد استخلاصها سنقوم بتخزين هذه البيانات في ملف CSV لكي تتمكن الخوارزمية لاحقًا من استخدام هذه المعلومات لتقوم بعملية التصنيف.
إتمام عملية التصنيف:
وأخيرًا سنصل إلى مرحلة التصنيف، حيث سنطبق خوارزمية تصنيف معرفة مسبقًا، وبإمكاننا التطبيق إما على مخططات التمثيل الطيفي (spectogram) أو على المميزات المستخلصة.
الدقة تختلف وبإمكاننا التجريب والتكرار حتى نحصل على دقة أعلى.
والآن سننتقل إلى الشيفرة البرمجية حيث نوضح الخطوات التي أسلفنا ذكرها بشكل عملي. يمكنك عزيزي القارئ الوصول إلى ورقة جوبيتر هنـــا.
الخاتمة
إن هذا التطبيق إنما هو عينة صغيرة لحقل استخلاص المعلومات الموسيقية، فهناك تطبيقات عديدة لهذا المجال من أنظمة التوصية إلى التعرف على الآلات الموسيقية ووصولاً إلى توليد الموسيقى، كل هذه المجالات وغيرها تنتظر منا البحث والاكتشاف والتطوير.
وإنما هدفنا في هذا المقال إلى اقتياد المبتدئين إلى موضع القدم الأول لهم في هذا المجال.
المراجع
- Music Genre Classification with Python
- https://en.wikipedia.org/wiki/Weighted_arithmetic_mean
- https://musicinformationretrieval.com/spectral_features.html
- Mel Frequency Cepstral Coefficient (MFCC) tutorial
- Musical genre classification of audio signals



تعليق واحد
شكرا جزيلا على هذه المعلومات القيمة ..