إعداد: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني
ملخّص البحث (Abstract).
تُعتبر مهمّة توصيف الصّورة غايةً في الأهميّة حيث وصل امتدادها وتأثيرها إلى مجالات الرّؤية الحاسوبيّة (Computer Vision) ومعالجة اللّغات الطّبيعيّة (Natural Language Processing=NLP). بالإضافة إلى كونها تعميمًا لمهمّة الكشف عن الأغراض (Object Detection)، حيث تُجسّد فيها الأوصاف بكلمةٍ مفردة. ومؤخرًا، معظم البحث في مجال توصيف الصّورة (Image Captioning) ركز واعتمد على استخدام تقنيّات التّعلّم العميق (Deep Learning)، وبشكلٍ خاصٍّ نماذج المُرمّز-فاكّ التّرميز (Encoder-Decoder) مع شبكات الطّيّ العصبونيّة (Convolutional Neural Network=CNN) من أجل استخراج السّمات والمزايا. وعلى الرّغم من ذلك، اتجهت بعض الأعمال لمحاولة استخدام سمات الكشف عن الأغراض (Object Detection Features) غايةً منها في زيادة جودة ونوعيّة الأوصاف المولّدة. تقدّم هذه الورقة معماريّةً عميقةً ذات بنية المُرمّز-فاكّ التّرميز بالاعتماد على الاهتمام (Attention-based Encoder-Decoder Deep Architecture) الّتي تستخدم سمات الطّيّ (Convolutional Features) المستخرجة من نموذج (CNN) المدرّب مسبقًا على مجموعة البيانات (ImageNet) والمتمثّلة بشبكة (Xception)، بالإضافة إلى إشراكها لسمات الكائن (Object Features) المستخرجة من قبل نموذج يولو (YOLOv4) والمدرّب مسبقًا على قاعدة بيانات مايكروسوفت كوكو (MS COCO). أيضًا تقدّم هذه الورقة طريقةً جديدةً في التّشفير الموضعي (Positional Encoding) لسمات الكائن وهي عامل الأهميّة (Importance Factor). وفي النّهاية تمّ اختبار النّموذج الخاصّ بنا على مجموعتي البيانات (MS COCO) و (Flickr30k)، وتمّت مقارنة أداء النّموذج مع الأداء في أعمالٍ مشابهةٍ سابقة. لوحظ أنّ مخطّط استخراج السّمات الخاصّ بنا في هذا العمل قد زاد من درجة معيار الأداء (CIDEr) بنسبة (15.04%). إنّ الشّيفرة البرمجيّة لهذا البحث العلميّ متاحةٌ عبر الرّابط التّالي: abdelhadie-almalla/image_captioning – GitHub
الكلمات المفتاحيّة: توصيف الصّورة، سمات الكائن، شبكة الطّيّ العصبونيّة، التّعلّم العميق.
المقدّمة (Introduction).
لقد أثار موضوع إنتاج جملٍ وصفيّةٍ (descriptive sentences) للصّور اهتمام الباحثين في مجالي معالجة اللّغات الطّبيعيّة (NLP) والرّؤية الحاسوبيّة (CV) في السّنوات الأخيرة. حيث أنّ توصيف الصّورة (Image Captioning) اعتُبر مهمّةً مفتاحيّةً وأساسيّةً تتطلّب فهمًا دلاليًّا (Semantic Comprehension) للصّور بالإضافة إلى القدرة على توليد جملٍ وصفيّةٍ دقيقةٍ ومحدّدةٍ.
في عصر البيانات الضخمة (Big Data)، كانت الصّور واحدةً من أكثر أنواع البيانات توافرًا على الانترنت، هذا ما أدى إلى زيادة الحاجة لتوصيفها وعنونتها. وهكذا فإنّ أنظمة توصيف الصّور هي مثالٌ حقيقيٌّ لمشاكل البيانات الضّخمة لأنّها تركّز على الجانب الحجميّ من البيانات الضّخمة. على سبيل المثال، مجموعة البيانات المعياريّة (MS COCO) والّتي تحتوي قرابة (123.000) صورةٍ بحجمٍ تقديريٍّ (25GB). ما يضيف الحاجة للاستخدام الفعّال للموارد (resources)، والتّصميم الدّقيق للتّجارب (experiments).
اعتمدت الأساليب والمناهج المبكرة على استخدام طرق القوالب (template methods)، في محاولةٍ لملء قوالب نصّيّةٍ محدّدةٍ مسبقًا بسماتٍ مستخرجةٍ من الصّور [1]. في حين تستفيد الأنظمة الحاليّة من قوّة الحوسبة (computing power) المتاحة وتستخدم تقنيّات التّعلّم العميق (Deep Learning).
واحدةٌ من أكثر الطّرق نجاحًا لمهمّة توصيف الصّورة هي تنفيذ معماريّة المُرمّز-فاك التّرميز (Encoder-Decoder Architecture). يتمّ ترميز الصّورة إلى تمثيلٍ عال المستوى (high-level representation)، ثمّ يتمّ فكّ ترميز هذا التّمثيل باستخدام نموذج توليد الغة (Language Generation Model) مثل الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى (Long Short-Term Memory=LSTM) [2]، والشّبكة العصبونيّة ذات البوّابات (Gated Recurrent Unit=GRU) [3] أو أيّ شكلٍ مختلفٍ منها.
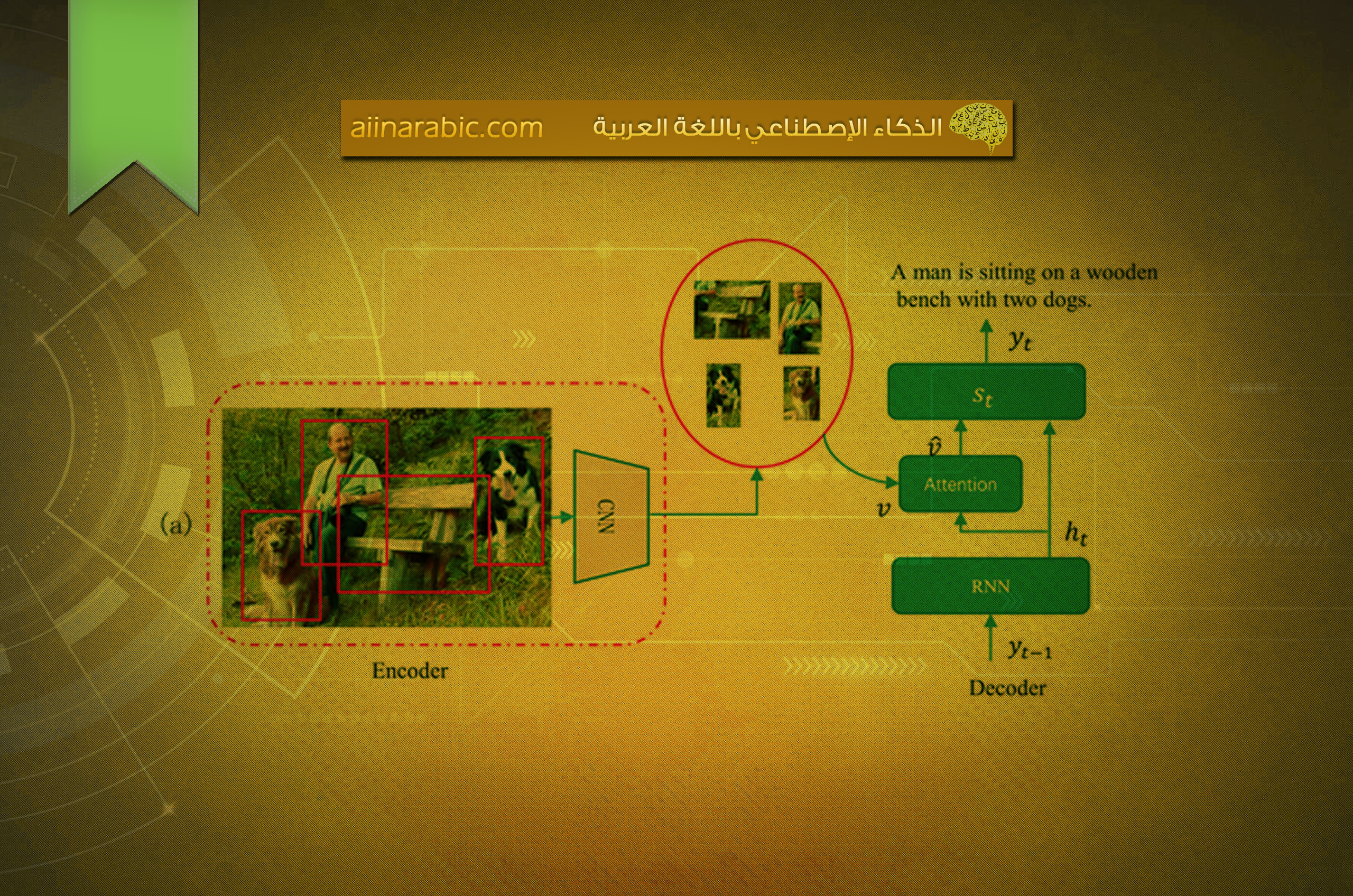
لقد أثبتت آليّة الاهتمام (Attention Mechanism) فعاليتها في تطبيقات سلسلة إلى سلسلة (sequence-to-sequence)، وخاصّةً توصيف الصّورة (Image Captioning) والتّرجمة الآليّة (Machine Translation). حيث أنّها تركّز على زيادة الدّقة من خلال إجبار النّموذج على التّركيز على الأجزاء المهمّة من صورة الدّخل في أثناء توليد سلاسل الخرج (output sequences) [4].
من أجل فهم الصّورة، فإنّ العديد من نماذج التّعلّم العميق الحديثة تستخدم شبكات الطّيّ العصبونيّة (CNNs) المدرّبة مسبقًا لاستخراج مصفوفاتٍ من السّمات المرئيّة من طبقات الطّيّ (Convolutional Layers) الأخيرة. وهذا من شأنه المساعدة في فهم العديد من الجوانب المتعلّقة بالكائنات (objects) والعلاقات فيما بينها ضمن الصّورة، بالإضافة إلى تمثيل الصّورة بمستوى أعلى [5].
في الآونة الأخيرة، حاولت بعض الأعمال استخدام سمات الكائن (object features) من أجل توصيف الصّورة. ومن بين النّماذج المستخدمة لدينا نموذج يولو الإصدار الثّالث (YOLOv3) [3]، ونموذج يولو الإصدار الرّابع (YOLOv4) [7]، ونموذج يولو 9000 (YOLO9000) [8]، وعُرفت جميعها بسرعتها ودقتها وفعاليتها في تطبيقات الزّمن الحقيقي (real-time). عادةً ما تكون سمات الكائن مصفوفةً من وسوم الكائن (object tags)، حيث أنّ كلّ وسم كائنٍ يحتوي على معلومات مربّع الإحاطة (Bounding Box Information)، صنف الكائن (object class) ومعدّل الثّقة (confidence rate). يبحث هذا العمل في الفرضيّة القائلة بأنّ استغلال مثل هذه السّمات يمكن أن يساعد في زيادة دقّة توصيف الصّورة، كما وأنّ استخدام جميع سمات الكائن يساعد بشكلٍ دقيقٍ على محاكاة فهم البشر البصريّ للمشاهد. تهدف هذه الورقة إلى تقديم نموذجٍ يستخدم هذا النّوع من السّمات من خلال معماريّةٍ بسيطةٍ لتقييم النّتائج.
سيتناول القسم الثّاني من هذه الورقة الأعمال ذات الصّلة في هذا المجال. وسيقدّم القسم الثالث منها منهجيّتنا، والّتي تتضمّن النّموذج المقترح والمعالجة المسبقة (pre-processing) لمجموعة البيانات. وأمّا بالنّسبة للقسم الرّابع، سيتضمّن شرح تصميم التّجارب والنّتائج، بالإضافة إلى مقارنةٍ مع الأعمال السّابقة. والقسم الخامس والأخير منها سيتناول ختام واستنتاج هذه الورقة وتقديم مجموعةٍ من التّوصيات والخطط للأعمال المستقبليّة القادمة.
الأعمال ذات الصّلة (Related Works).
في [9]، اقترح (Yin and Ordonez) نموذج سلسلة إلى سلسلة (sequence-to-sequence model)، حيث كانت فيه الشَّبَكَةُ العُصبُونِيَّةُ ذاتُ الذَّاكِرةِ الطَّويلةِ قصيرةِ المَدى (LSTM) مسؤولةً عن ترميز سلسلة الكائنات (objects) ومواقعها (positions) لتكون بمثابة سلسلة الدّخل (input sequence)، في حين يقوم نموذج اللّغة (LSTM Language Model) بفكّ ترميز هذا التّمثيل من أجل توليد الأوصاف. واستَخدم نموذجهم أيضًا يولو (YOLO) [8] المعروف بنموذج الكشف عن الأغراض (Object Detection Model) أوّلًا من أجل استخراج تخطيطات الكائنات (object layouts) من الصّور والمتمثّلة بفئات الكائنات (object categories) ومواقعها (locations)، وثانيًا من أجل زيادة دقة الأوصاف النّاتجة. كما وأنّهم قاموا بتقديم شكلٍ وتنوّعٍ آخر يستخدم نموذج تصنيف الصّور (VGG) [10] المدرّب مسبقًا على مجموعة البيانات (ImageNet) [11] لاستخراج السّمات المرئيّة (visual features). توصّلوا في النّهاية من خلال هذه التّجارب والسّيناريوهات إلى أنّ نموذجهم قد زاد في الدّقة بشكلٍ ملحوظٍ عندما تمّ دمجه مع وحدات (CNN) و نموذج يولو (YOLO). مع الإشارة إلى عدم استخدامهم لكامل البيانات المتاحة من سمات الكائن المسؤولة عن إنتاجها (YOLO) كمثل أبعاد الكائن (object dimensions) ومعدّل الثّقة (confidence rate).
في [12] قام (Vo-Ho et al.) بتطوير نظام توصيفٍ للصّور يعمل على استخراج سمات الكائنات بمساعدة (YOLO9000) [9] وأيضًا شبكة الطّيّ العصبونيّة المناطقيّة الأسرع (Faster R-CNN) [13]. كلّ نوعٍ من هذه السّمات يتمّ معالجته عبر وحدة اهتمامٍ (attention module) من أجل إنتاج وتكوين سماتٍ محلّيةٍ (local features) تستخدم لاحقًا لتغذية نموذج (LSTM) بها وذلك لتوليد احتمالات الكلمات في مجموعة المفردات (vocabulary set) ضمن كلّ خطوةٍ زمنيّةٍ وبالتّالي توليد اللّغة المطلوبة. وبالنّظر إلى منهجيّة استخراج السّمات من الصّورة فقاموا باستخدام شبكة (ResNet) [14]. وذُكر أيضًا في هذا العمل أنّه تمّ اعتماد استراتيجيّة البحث الشّعاعيّ (beam search) لمعالجة النّتائج من أجل اختيار أفضل توصيفٍ مرشحٍ.
في العمل البحثيّ [15]، اقترح (Lanzendörfer et al.) نموذجًا من أجل (Visual Question Answering=VQA) يعتمد على (iBOWIMG). حيث اعتمد النّموذج على استخراج السّمات المرئيّة من شبكة جوجل انسبشن (Inception v3) [16]، بالإضافة إلى سمات الكائنات المستخرجة من قبل نموذج الكشف عن الأغراض يولو (YOLO) [8]، كما وأنّه يستخدم آليّة الاهتمام (attention mechanism).
في [17]، اقترح (Herdade et al.) نموذج ترميز-فكّ ترميز (Encoder-Decoder) قائمٍ على الاهتمام المكانيّ (spatial attention) ومسؤولٍ عن دمج المعلومات حول العلاقة المكانيّة (spatial relationship) بين الكائنات المكتشفة. في هذا العمل قاموا باستخدام كاشفٍ للكائنات (object detector) من أجل استخراج سمات المظهر والهندسة من جميع الكائنات المكتشفة في الصّورة، وبعد ذلك يقوم محوّل علاقة الكائن (Object Relation Transformer) بتوليد نصّ التّوصيف. كانت شبكة (CNN) الأساسيّة لمهمّتي الكشف عن الأغراض (object detection) واستخراج السّمات (feature extraction) شبكة الطّيّ العصبونيّة المناطقيّة الأسرع (Faster R-CNN) [13] وشبكة (ResNet 101) [14] على التّوالي. يتمّ الاستفادة من خرائط السّمات الوسيطة (intermediate feature maps) المستخرجة من قبل شبكة (ResNet 101) لتكون بمثابة دخلٍ لشبكة اقتراح المناطق المهمّة (Region Proposal Network=RPN) من أجل توليد مربّعات الإحاطة (Bounding Boxes) لمقترحات الكائنات.
في [18]، قام (Wang et al.) بدراسة توصيف الصّورة (end-to-end) باستخدام تمثيلاتٍ قابلةٍ للتّفسير بدرجةٍ عاليةٍ تمّ الحصول عليها من قبل الكشف الصّريح عن الأغراض (explicit object detection). خلصوا من خلال هذه الدّراسة إلى أنّ عدد التّكرارات (frequency counts) وحجم الكائن (object size) وموقعه (location) جميعها مفيدةٌ في زيادة دقة الأوصاف المنتجة. كما وأنّهم اكتشفوا بأنّ فئاتٍ معيّنةٍ من الكائنات (object categories) لها تأثيرٌ أكبر من غيرها نسبيًّا على توصيف الصّور.
اقترح عمل (Sharif et al.) [19] الاستفادة من العلاقات اللّغويّة (linguistic relations) بين الكائنات في الصّورة. حيث استفادوا في عملهم من تضمين الكلمات (word embeddings) لالتقاط دلالات الكلمات (word semantics). كما أنّهم استخدموا شبكة (NASNet) من أجل التقاط الدّلالات العامّة (global semantics) للصّورة. وتوصّلوا كنتيجةٍ نهائيّةٍ أنّ العلاقات الدّلاليّة (semantic relations) الّتي لا تظهر في المحتوى المرئيّ للصّورة يمكن تعلّمها، هذا ما يسمح لفاكّ التّرميز (decoder) أن يركز على أهمّ علاقات الكائنات (object relations) والسّمات المرئيّة (visual features) وبالتّالي تشكيل أوصافٍ ذات معنى دلاليٍّ أكثر.
قام (Variš et al.) [20] بتقديم نهجٍ يستفيد من الطّبيعة النّصّيّة للعناوين (labels) الخاصّة بالكشف عن الأغراض (object detection)، بالإضافة إلى تمثيلات الكائنات المرئيّة (visual object representations) المبنيّة منها. كما وأنّهم قاموا بالتّحقق فيما إذا كان تحديد موقع (grounding) التّمثيلات في فضاء تضمين الكلمات لنظام التّوصيف بدلًا من تحديد موقع الكلمات أو الجمل في الصّور المرتبطة بها يمكن أن يحسّن من كفاءة نظام التّوصيف.
اقترح (Alkalouti and Masre) [21] نموذجًا لأتمتة توصيف الفيديو يعتمد على معماريّة المُرمّز-فاكّ التّرميز (Encoder-Decoder). قاموا في بادئ الأمر بتحديد الإطارات (frames) الأكثر أهميّةً في الفيديو، وقاموا بإزالة الإطارات الزّائدة والمكرّرة (redundant) منه. اعتمدوا على نموذج يولو (YOLO) من أجل اكتشاف الأغراض في إطارات الفيديو، وعلى نموذج (LSTM) من أجل توليد اللّغة.
في [22] قام (Ke et al.) بالتّحقق من أداء استخراج السّمات (feature extraction) لــ (16) شبكة (CNNs) شائعةٍ على مجموعة بيانات صور الأشعة للصّدر (chest X-ray images). لم يجدوا أيّ علاقةٍ بين الأداء على مجموعة البيانات (ImageNet) والأداء على مجموعة بيانات الصّور الطّبيّة. ولكنّهم وجدوا أنّ اختيار بنية (CNN) يؤثر على الأداء كما وأنّ التّدريب المسبق على (ImageNet) يعطي تعزيزًا للأداء في جميع البنى والمعماريّات.
في [23] اقترح (Xu et al.) طريقةً جديدةً لإنشاء الأوصاف تمثّلت من خلال البدء بتحديد الوحدات اللّفظيّة (tokens) المهمّة والّتي يجب تسليط المزيد من الاهتمام عليها من أجل استخدامها لاحقًا كمرتكزات (Anchors). بعد ذلك يتمّ تجميع النّصوص ذات الصّلة بكلّ مرتكزٍ منها على حدةٍ لإنشاء رسمٍ بيانيٍّ يتوسطه هذا المرتكز (Anchor-Centered Graph=ACG). وفي النّهاية قاموا بتوليد أوصافٍ متعدّدة الرّؤى بالارتكاز على العديد من (ACGs) لغاية تحسين تنوّع محتوى الأوصاف المولّدة.
في [24] اقترح (Chen et al.) الأدوار الدّلاليّة الخاصّة بالفعل (Verb-Specific Semantic Roles=VSR) من أجل التّحكم بتوصيف الصّورة. حيث يتكوّن من الفعل (verb) وبعض الأدوار الدّلاليّة (semantic roles) الّتي تعكس نشاطًا معيّنًا وأدوارًا للكيانات المشاركة فيه.
في [25] قدّم (Cornia et al.) إطار عملٍ (framework) فريدٍ من أجل توصيف الصّورة. حيث عملوا على إنتاج الأوصاف ذات الصّلة باستخدام بنيةٍ تكراريّةٍ (recurrent architecture) تتنبأ بشكلٍ واضحٍ وصريحٍ بالقطع النّصّية بالاعتماد على المناطق مع الالتزام بحدود التّحكم. تمّ إجراء التّجارب باستخدام مجموعة البيانات (Flickr30k Entities) والمجموعة ( COCO Entities). وتمّ التّوصّل إلى أنّ طريقتهم أعطت نتائج متطوّرة من حيث جودة وتنوّع الأوصاف.
على عكس الأعمال البحثيّة السّابقة، تستفيد منهجيّتنا من جميع سمات الكائنات المتاحة. ويُوضَّح تأثير هذا الأمر عبر قسم التّجارب (experiments section).
منهجيّة البحث (Research Methodology).
تتضمّن استخراج سمات الكائن (object features) من قبل نموذج يولو (YOLO)، وتقديمها جنبًا إلى جنب مع سمات الطّيّ لشبكة الطّيّ العصبونيّة (CNN Convolutional Features) إلى نموذج تعلّمٍ عميقٍ وبسيطٍ يعتمد على استخدام بنية المُرمّز-فاكّ التّرميز (Encoder-Decoder) مع آليّة الاهتمام (attention mechanism). يتناول قسم “النّتائج والمناقشة” إجراء مقارنةٍ للفروق والاختلافات الظّاهرة في النّتائج قبل وبعد إضافة سمات الكائن (object features).
على الرّغم من أنّ الأبحاث السّابقة قامت بترميز سمات الكائن كمتّجهٍ (vector) إلّا أنّنا قمنا في عملنا هذا بإضافة سمات الكائن بطريقةٍ تسلسليّةٍ (concatenation) بسيطةٍ وحقّقنا تحسّنًا جيّدًا وملحوظًا. أيضًا نقوم باختبار تأثير فرز وسوم الكائن (object tags) المستخرجة بواسطة يولو (YOLO) وفقًا لمقياسٍ (metric) نقترحه هنا.
مجموعات البيانات المستخدمة (Datasets)
قمنا باختبار طريقتنا على مجموعتي بياناتٍ تُستخدم عادةً في مجال توصيف الصّورة (image captioning)، وهما:
- مجموعة البيانات (MS COCO).
- مجموعة البيانات (Flickr30k).
الجدول (1) يحتوي على مقارنةٍ وجيزةٍ بين المجموعتين. وتمّ جمع كليهما من خلال موقع مشاركة الصّور (Flickr)، حيث تتكوّن هذه المجموعات من صورٍ حقيقيّةٍ تمّ التّعليق عليها من قبل البشر (5 توصيفاتٍ لكلّ صورةٍ). يمكن تحميل مجموعتي البيانات المُشار إليها في عملنا هذا من خلال الرّوابط المتاحة في قسم “توافر البيانات والمواد”.
معايير التّقييم (Evaluation Metrics).
قمنا باستخدام مجموعةٍ من مقاييس التّقييم (evaluation metrics) المستخدمة على نطاقٍ واسعٍ في مجال توصيف الصّورة (image captioning).
بدايةً لدينا مقاييس (BLEU) [26]، والّتي تُستخدم بشكلٍ شائعٍ في تقييم النّصوص (text evaluation) وحساب مدى قرب مخرجات التّرجمة الآليّة (machine translation) ومخرجات التّرجمة البشريّة (human translation)، ولدينا في حالة توصيف الصّورة: مخرجات التّرجمة الآليّة توافق التّوصيف النّاتج (produced caption)، ومخرجات التّرجمة البشريّة توافق التّوصيف البشريّ (human description) للصّورة.
أيضًا لدينا مقياس (METEOR) [27]، والّذي يُحتسب باستخدام المتوسط التّوافقي لقيمة (unigram) للتّنبؤ الإيجابي (precision) وحساسيّة التّنبؤ (recall)، وحيث يكون لــ (recall) وزنٌ أعلى من (precision) كما التّالي:
METEOR=[10*Precision*Recall/(Recall+9*Precision)]
المعادلة (1): حساب مقياس (METEOR).
بالنّسبة لمقياس (ROUGE-L) [28]، يستخدم درجة أطول تسلسلٍ فرعيٍّ مشتركٍ (Longest Common Subsequence=LCS) لتقييم كفاءة النّصّ النّاتج، في حين يركّز مقياس (CIDEr) [29] على بروز القواعد النّحويّة (grammaticality ).
وأمّا مقياس (SPICE) [30]، يقيّم دلالات (semantics) النّصّ النّاتج من خلال إنشاء رسمٍ بيانيٍّ للمشهد (scene graph) للأوصاف النّصّيّة الأصليّة والمولّدة، ثمّ يقوم بإجراء مطابقةٍ بين المصطلحات فقط في حال كانت تمثيلاتهم (lemmatized WordNet) متطابقة.
لوحظ بأنّ معايير التّقييم (BLEU, METEOR, ROUGE) لديها ارتباطاتٌ منخفضةٌ (low correlations) مع اختبارات الجودة البشريّة (human quality tests)، في حين أنّ المعيارين (CIDEr, SPICE) لديهما ارتباطاتٌ أفضل ولكن من الصّعب تحسينهما.
النّموذج (Model).
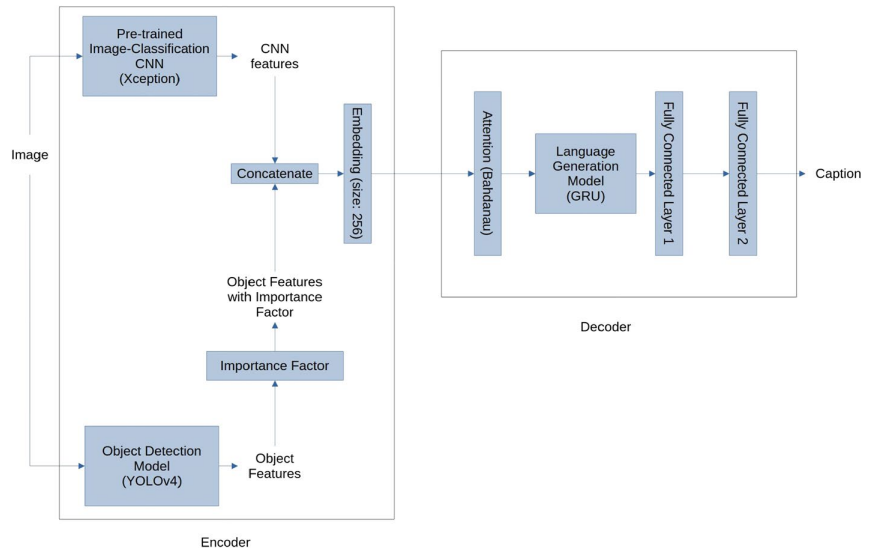
يستخدم نموذجنا معماريّة المُرمّز-فاكّ التّرميز المعتمد على تقنيّة الاهتمام (attention-based Encoder-Decoder architecture). حيث يمتلك طريقتين لاستخراج السّمات (feature extraction) من أجل توصيف الصّورة هما:
- شبكة تصنيف الصّورة (Image classification CNN) وهي نموذج (Xception) [31].
- نموذج الكشف عن الأغراض (object detection model) وهو يولو الإصدار الرّابع (YOLOv4) [7].
مخرجات هذه النّماذج يتمّ جمعها بطريقةٍ تسلسليّةٍ (concatenation) من أجل إنتاج مصفوفة سماتٍ (feature matrix) والّتي تحمل المزيد من المعلومات إلى فاكّ ترميز اللّغة (language decoder) للتّنبؤ بأوصافٍ أكثر دقّة. وعلى عكس الأعمال البحثيّة للآخرين الّتي تقوم بتضمين سمات الكائن (object features) قبل جمعها مع سمات شبكة (CNN)، نستخدم هنا معلومات تخطيط الكائن (object layout information) بشكلٍ مباشرٍ. بالنّسبة لتوليد اللّغة (language generation) يتمّ القيام بها من خلال:
- وحدة الاهتمام (attention module) وهي (Bahdanau attention) [32].
- الشّبكة العصبونيّة ذات البوابات (Gated Recurrent Unit=GRU) [3].
- طبقتين ذات اتّصالٍ كاملٍ (fully connected layers).
يتّصف هذا النّموذج بالبساطة والسّرعة في عمليّة التّدريب والتّقييم، كما أنّه قادرٌ على توليد أوصافٍ باستخدام أليّة الاهتمام (attention).
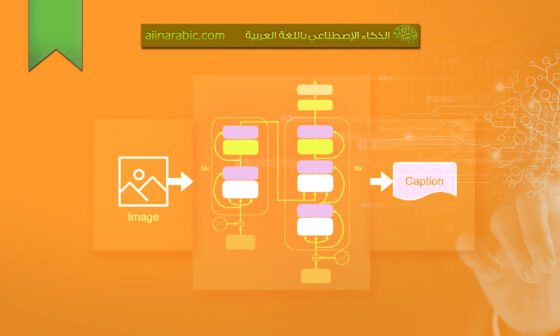
نعتقد بأنّه إذا كان بوسع البشر الاستفادة من سمات الكائن (object features) مثل: صنف الكائن (class)، موقعه (position) وحجمه (size) من أجل فهم الصّورة بشكلٍ أفضل، فإنّ النّموذج الحاسوبيّ أيضًا قادرٌ على الاستفادة من هذه المعلومات. على سبيل المثال، يشير المشهد الّذي يحتوي على مجموعةٍ من الأشخاص الواقفين بالقرب من بعضهم البعض إلى اجتماعٍ، في حين أنّ الحشود المتفرّقة والمتناثرة قد تشير إلى مكانٍ عام. يوضّح الشّكل (1) التّالي نموذجنا:
ترميز الصّورة (Image Encoding).
A. شبكة الطّيّ العصبونيّة لتصنيف الصّورة المدرّبة مسبقًا (Pre-trained image classification CNN).
في هذا العمل، نستخدم شبكة (Xception) وهي شبكة طيٍّ عصبونيّة (CNN) مدرّبةٌ مسبقًا على مجموعة البيانات (ImageNet) [11] من أجل استخراج السّمات المكانيّة (spatial features).
إنّ نموذج (Xception) نسخةٌ حديثةٌ من شبكة (Inception) ومستوحى من شبكة (Inception V3) [16]، ولكن بدلًا من وحدات (Inception)، فإنّ نموذج (Xception) يمتلك (71) طبقةٍ من طبقات الطّيّ المعدّلة بالعمق المنفصل (modified depth-wise separable convolution). يتفوّق نموذجنا على (Inception V3) بسبب الاستخدام الأفضل لمعاملات النّموذج (model parameters).
نقوم باستخراج السّمات (features) من الطّبقة الأخيرة قبل الطّبقة ذات الاتّصال الكامل (fully connected layer). هذا ما يسمح للنّموذج بأن يكتسب نظرةً ثاقبةً عن الكائنات في الصّورة والعلاقات بينها بدلًا من مجرّد التّركيز على صنف الصّورة (image class).
في عملٍ سابقٍ، تمّت مقارنة العديد من نماذج (CNN) المختلفة من أجل استخراج السّمات لتطبيقات توصيف الصّورة. وأظهرت النّتائج بأنّ شبكة (Xception) كانت من بين النّماذج الأكثر متانةً وقوّةً في استخراج السّمات (feature extraction)، ولهذا السّبب تمّ اختيارها في هذه الدّراسة كنموذجٍ لاستخراج السّمات. وخرج هذه المرحلة من الشّكل (10*10*2048)، والّذي يتمّ ضغطه إلى (100*2048) لسهولة التّعامل مع المصفوفة.
B. نموذج الكشف عن الأغراض (Object Detection Model).
تستخدم طريقتنا نموذج يولو الإصدار الرّابع (YOLOv4) [7] نظرًا لسرعته ودقته الجيّدة، هذا ما يجعله مناسبًا لتطبيقات الزّمن الحقيقي والبيانات الضّخمة. والسّمات المستخرجة من قبله عبارةٌ عن قائمة من سمات الكائن (object features)، وكلّ واحدةٍ منها تحتوي على:
- إحداثيّات (X).
- إحداثيّات (Y).
- العرض (width).
- الطّول (height).
- معدّل الثّقة (confidence rate)، يتراوح من 0 إلى 1 ضمنًا.
- رقم الصّنف (class number).
- عامل الأهميّة (importance factor=IF).
وفقًا للحدس البشريّ، تميل الكائنات الموجودة في المقدّمة عادةً إلى أن تكون أكبر وأكثر أهميّة أثناء توصيف الصّورة، في حين تميل الكائنات الموجودة في الخلفيّة عادةً إلى أن تكون أصغر وأقلّ أهميّة. وبالتّالي يحاول عامل الأهميّة (IF) لدينا القيام بتحقيق التّوازن (balance) بين أهميّة الكائنات الكبيرة الموجودة في المقدّمة (foreground large objects)، والكائنات الّتي لديها معدّلات ثقة عالية (high confidence rates). الصّيغة التّالية تعبّر عن حساب عامل الأهميّة (IF) من أجل كائنٍ واحدٍ كما يلي:
Importance Factor=Confidence Rate*Object Width*Object Height
المعادلة (2): حساب عامل الأهميّة (IF).
ومن خلال المعادلة السّابقة، نلاحظ أنّ عامل الأهميّة (IF) يعطي درجةً أعلى للكائنات الكبيرة الموجودة في المقدّمة مقارنةً بالكائنات الصّغيرة الموجودة في الخلفيّة، ودرجةً أعلى للكائنات ذات الثّقة العالية مقارنةً بالكائنات ذات الثّقة الأقل.
بعد استخراج سمات الكائن، يتمّ احتساب قيمة عامل الأهميّة (IF) لكلّ كائنٍ وربطه بالوسم الخاصّ به. ثمّ بعد ذلك، يتمّ فرز جميع الكائنات الموجودة في القائمة وفقًا لعامل الأهميّة هذا باستخدام خوارزميّة الفرز السّريع (quick sort algorithm). وعلى عكس الأعمال السّابقة، تستفيد طريقتنا من جميع معلومات كائن الصّورة. بسبب قيود الحجم على مخرجات شبكة (CNN)، نستخدم إلى ما يصل (292) كائنًا، كلّ واحدٍ منها يحتوي على (7) سماتٍ بما فيها عامل الأهميّة (IF)، وتعتبر عادةً كافية من أجل تمثيل الكائنات المهمّة في الصّورة.
يتمّ تسطيح قائمة السّمات إلى مصفوفةٍ أحاديّة البعد (1D array) وبطولٍ أقل من (2048). ثمّ بعد ذلك يتمّ حشوها بقيمٍ صفريّةٍ بطول (2048) لتكون متوافقةً مع مخرجات وحدة (CNN). وبالتّالي فإنّ مخرجات هذه المرحلة تكون عبارةً عن مصفوفةٍ ذات البعد (1*2048).
بالنّسبة لاحتساب درجة الثّقة (confidence score)، فإنّ خوارزميّة يولو (YOLO) تقوم بتقسيم الصّورة إلى شبكةٍ (grid). ضمن كلّ خليّةٍ من خلايا هذه الشّبكة يتمّ التّنبّؤ بمربّعات الإحاطة (bounding boxes) بالإضافة إلى درجات الثّقة (confidence scores) لهذه المربّعات. تشير درجة الثّقة إلى مدى ثقة النّموذج بأنّ المربّع يتضمّن كائنًا، بالإضافة إلى مدى دقّة اعتقاد النّموذج بالمربّع الّذي تنبّأ به. يتمّ تقييم خوارزميّة الكشف عن الأغراض (object detection) باستخدام التّقاطع على الاتّحاد (Intersection Over Union=IoU) بين المربّع المتنبّأ به والمربّع المرجعي. حيث يقوم بتحليل مدى تشابه المربّع المتنبّأ به والمربّع المرجعي من خلال حساب التّداخل (overlap) بينهما. يجب أن تكون درجة الثّقة لخليّةٍ ما صفرًا إذا لم يكن هنالك أيّ كائنٍ متواجدٍ فيها. الصّيغة التّالية تعبّر عن حساب درجة الثّقة (confidence score):
C=Pr(object)*IoU
المعادلة (3): حساب درجة الثّقة (confidence score).
C. الجمع بالتّسلسل والتّضمين (Concatenation and Embedding).
من أجل الاستفادة من سمات تصنيف الصّور (image classification features) وسمات الكشف عن الأغراض (object detection features)، نقوم بإضافة خطوة التّجميع هذه حيث نقوم بإلحاق خرج النّظام الفرعيّ (YOLOv4) كسطرٍ أخيرٍ في خرج المرحلة الأولى. ويكون خرج هذه المرحلة على شكل (101*2048).
يتمّ إجراء التّضمين (embedding) من خلال استخدام طبقةٍ واحدةٍ ذات الاتّصال الكامل (fully connected layer) بطول (256). وتؤكّد هذه المرحلة على استخدام حجمٍ ثابتٍ ومعيّنٍ من السّمات (features) وربط فضاء السّمات (feature space) بفضاءٍ أصغر مناسبٍ أكثر لفاكّ ترميز اللّغة (language decoder).
D. الاهتمام (Attention).
تستخدم طريقتنا نظام الاهتمام (Bahdanau attention system) [32]. تجعل آليّة الاهتمام الحتميّة هذه النّموذج ككل أكثر سلاسةً. كما أنّها تسلّط الضّوء على الأجزاء الأكثر أهميّة من بيانات الدّخل، وبالتّالي يجب على الشّبكة أن تخصّص موارد حاسبٍ أكبر لذلك الجزء الصّغير ولكن الأكثر أهميّة من البيانات. يتمّ تحديد المكوّن الأكثر صلة من غيره من خلال السّياق (context) حيث يتمّ تعلّمه من قبل خوارزميّة انحدار المشتقّ (Gradient Descent) باستخدام بيانات التّدريب (training data). إنّ معالجة اللّغات الطّبيعيّة (NLP) والرّؤية الحاسوبيّة (Computer Vision) تعتمد على استخدام الاهتمام في العديد من مهام التّعلّم الآلي (Machine Learning).
تمّ إنشاء آليّة الاهتمام من أجل زيادة أداء معماريّة المُرمّز-فاكّ التّرميز (Encoder-Decoder) للتّرجمة الآليّة (Machine Translation). وبما أنّه يمكن اعتبار توصيف الصّورة (Image Captioning) حالةً خاصّةً من التّرجمة الآليّة، فثبت أنّ الاهتمام مفيدٌ أيضًا عند تحليل (analysing) الصّور. وكانت الغاية من الاهتمام السّماح لفاكّ التّرميز باستخدام الأجزاء الأكثر صلة من سلسلة الدّخل (input sequence) من خلال جمع كلّ متجهات الدّخل المُرمّزة إلى تركيبٍ موزونٍ (weighted combination) حيث أنّ المتجهات الأكثر صلة تحصل على أوزانٍ أعلى.
إنّ تقنيّة الاهتمام تتبع الحدس البشريّ في التّركيز على أجزاءٍ مختلفةٍ من الصّورة عند وصفها. كما وأنّ استخدام سمات الكشف عن الأغراض أيضًا يتبع الحدس في أنّ معرفة الكائنات ومواقعها يساعد في فهم المزيد حول الصّورة أكثر من مجرّد سمات الطّيّ (convolutional features). يوضّح الشّكل (2) استخدام الاهتمام لتوصيف الصّورة:

فاكّ ترميز اللّغة (Language Decoder).
من أجل فكّ التّرميز (decoding)، يتمّ استخدام الشَّبَكَةُ العُصبونِيَّة ذاتُ البوَّاباتِ (GRU) [3] لاستغلال سرعتها واستخدامها المنخفض للذّاكرة (low memory usage). يقوم بإنتاج التّوصيف من خلال توليد كلمةٍ واحدةٍ في كلّ خطوةٍ زمنيّةٍ بالاعتماد على متجه السّياق (context vector)، والحالة المخفيّة السّابقة (previous hidden state)، والكلمات المولّدة مسبقًا (previously generated words). كما ويتمّ تدريب النّموذج باستخدام خوارزميّة الانتشار الخلفيّ (backpropagation ).
تتبع الشَّبَكَةُ العُصبونِيَّة ذاتُ البوَّاباتِ (GRU) بطبقتين ذات الاتّصال الكامل (fully connected layers). يبلغ طول الأولى حوالي (512)، بينما الثّانية فهي بحجم المفردات (vocabulary size) من أجل إنتاج نصّ الخرج.
تتمّ عمليّة تدريب فاكّ التّرميز (Decoder) على النّحو التّالي:
- يتمّ استخراج السّمات ليتمّ فيما بعد تمريرها عبر المُرمّز.
- يستقبل فاك التّرميز (Decoder): خرج المُرمّز (Encoder)، والحالة المخفيّة (hidden state) المهيّأة بالصّفر، بالإضافة إلى دخل فاكّ التّرميز والمعبّر عنه برمز البداية (start token).
- يعيد فاكّ التّرميز التّنبّؤات (prediction) بالإضافة إلى الحالة المخفيّة لفاكّ التّرميز.
- يتمّ إعادة تمرير الحالة المخفيّة لفاكّ التّرميز مرّةً أخرى للنّموذج، ويتمّ حساب الخسارة (loss) باستخدام هذه التّنبّؤات.
- من أجل تحديد دخل فاكّ التّرميز التّالي، يتمّ استخدام تقنيّة التّعلّم بالفرض (teacher forcing)، الّتي تعمل على تمرير الكلمة الهدف (target word) لتكون بمثابة الدّخل التّالي لفاكّ التّرميز.
المعالجة المسبقة (Pre-processing).
يوضّح هذا القسم خوارزميّة المعالجة المسبقة والّتي تمّ إجراؤها على البيانات (data):
- فرز مجموعة البيانات بشكلٍ عشوائيٍّ إلى أزواج من (الصّور، التّوصيفات). هذه الخطوة تساعد في تقارب عمليّة التّدريب بشكلٍ أسرع وتمنع من وجود أيّ انحيازٍ أثناء عمليّة التّدريب. وبالتّالي منع النّموذج من تعلّم ترتيب عيّنات التّدريب.
- قراءة الصّور وفكّ ترميزها.
- إعادة ضبط حجم الصّور وفقًا لمتطلّبات شبكة (CNN): أيًّا كان حجم الصّورة، يتمّ تغيير حجمها إلى (299*299) كما هو مطلوبٌ بواسطة نموذج (Xception).
- تقسيم النّصّ إلى وحداتٍ لغويّةٍ (tokenization): يتمّ تقسيم النّصّ الخام إلى كلماتٍ تكون مفصولةً بعلامات التّرقيم (punctuations)، أو أحرفٍ خاصّةٍ (special characters) أو مسافاتٍ بيضاء (white space). هذه الفواصل يتمّ تجاهلها.
- يتمّ إحصاء عدد الوحدات اللّفظيّة (tokens) ليتمّ ترتيبها على حسب تكرارها (frequency)، ثمّ اختيار أفضل (15000) كلمةٍ شائعةٍ لتكون بمثابة مفردات النّظام (system’s vocabulary). وهذا يساعد في تجنبّ الملاءمة الزّائدة (over-fitting) من خلال إزالة المصطلحات الّتي من غير المرجّح أن تكون مفيدة.
- إنشاء بنى كلمة لدليل (word-to-index) ودليل لكلمة (index-to-word). من أجل استخدامها لاحقًا في ترجمة سلاسل الوحدات اللّفظيّة (token sequences) إلى سلاسل معرّفات الكلمات (word identifier sequences).
- الحشو (padding). نظرًا لأنّ الجمل قد تختلف في الطّول (length)، فنحنن بحاجة إلى أن تكون المدخلات بذات الحجم (size)، وبالتّالي يكون الحشو هنا ضروريًّا. يتمّ حشو سلاسل المعرّفات في النّهاية بوحداتٍ لفظيّةٍ فارغةٍ (null tokens) للتّأكيد على أنّها جميعها بذات الطّول.
النّتائج والمناقشة (Results and Discussion).
تمّ كتابة الشّيفرة البرمجيّة الخاصّة بنا بلغة البرمجة (Python) باستخدام مكتبة تنسور فلو للتَّعلُّمِ العميقِ من جوجل (Tensorflow) المتوفّرة عبر الرّابط: https://www.tensorfow.org. تمّ استيراد تنفيذ شبكة (CNN) والنّموذج المدرّب من مكتبة (keras) المتوفّرة عبر الرّابط: https://keras.io/api/applications/. وتمّ استيراد نموذج يولو الإصدار الرّابع (YOLOv4) المدرّب مسبقًا على مجموعة البيانات (MS COCO) من مكتبة (yolov4) المتوفّرة عبر الرّابط: https://pypi.org/project/yolov4/. يستخدم هذا العمل أداة التّقييم (MS COCO) من أجل حساب النّتائج.
تُجرى الاختبارات على مجموعتي بياناتٍ مستخدمتين على نطاقٍ واسعٍ من أجل توليد توصيف الصّورة وهما: (MS COCO) و (Flickr30K). تملك كلّ صورةٍ في كلا مجموعتي البيانات (5) توصيفاتٍ مرجعيّةٍ (reference captions)، حيث كلّ مجموعةٍ منها تحتوي على (123000) صورةٍ و (31000) صورةٍ على التّوالي. من أجل مجموعة البيانات (MS COCO)، يتمّ حجز (5000) صورةٍ للتّحقّق (validation) ومثلها للتّحقّق (cheking) وفقًا لتقسيم (Karpathy) [33]. أمّا بالنّسبة لمجموعة البيانات (Flickr30k)، يتمّ استخدام (29000) صورةٍ للتّحضير (preparation) و (1000) صورةٍ للتّحقّق (validation) ومثلها للاختبار (testing). تمّ تدريب النّموذج على (20) دورة تدريبٍ (epochs)، واستُخدمت الانتروبيا المتقاطعة الفئويّة المتناثرة (Sparse Categorical Cross Entropy) كتابعٍ للخسارة (loss function). ومن أجل المحسّن (optimizer)، تمّ استخدام محسّن آدم (Adam optimizer).
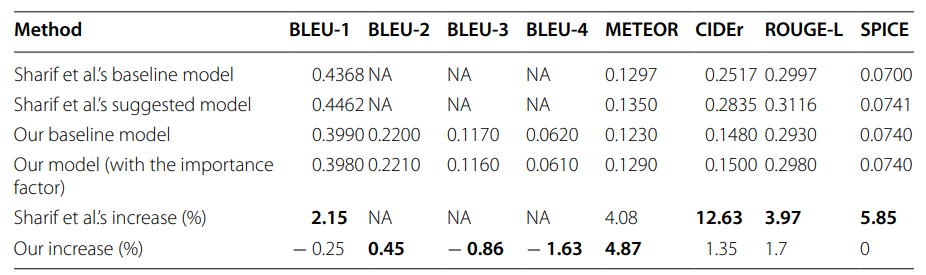
يقدّم الجدول (2) نتائج النّموذج المقترح (proposed model) على مجموعة بيانات (MS COCO) وفقًا لتقسيم (Karpathy)، ويقارنها بنتائج النّموذج الأساسيّ (baseline model) مع السّمات فقط المستخرجة من قبل (Xception). يمكن ملاحظة مدى زيادة درجات التّقييم (evaluation scores) بعد إضافة سمات الكائن (object features) إلى النّموذج، وخاصّةً درجة مقياس (CIDEr) الّذي ازداد بنسبة (15.04%). وهذه الزّيادة تعكس تحسّنًا جيّدًا في التّرابط مع الحكم والقرار البشريّ عند استخدام سمات الكائن الكاملة، وتعزّز السّلامة والبروز القواعديّ والنّحويّ. يبدو أنّ عامل الأهميّة (IF) يزيد من مقاييس (BLEU) ويقلّل من (METEOR) قليلًا بينما تظلّ قيم المقاييس الأخرى كما هي. على عكس نتائج (Herdade et al) [17]، لم يقلّل مخطّط التّشفير الموضعيّ (positional encoding) الخاصّ بنا من درجة (CIDEr).
لإظهار فعاليّة طريقتنا، قمنا بمقارنة الزّيادة الظّاهرة لدينا في النّتائج (مع عامل الأهميّة) بالزّيادة في نتائج (Yin and Ordonez) [9] على مجموعة البيانات (MS COCO) وفقًا لتقسيم (Karpathy) في الجدول (3). قاموا أيضًا بقياس تأثيرات دمج سمات الكائن (object features) على نتائج توصيف الصّورة. حيث تقوم طريقة استخراج سمات الكائن الخاصّة بهم باستخراج تخطيطات الكائن (object layouts) من نموذج (YOLO9000)، ثمّ ترميزها من خلال وحدة (LSTM)، لتستخرج أيضًا سمات (CNN) من نموذج (VGG16)، ليتمّ ترميز هذه السّمات عبر وحدة (LSTM) أخرى. وفي النّهاية يتمّ جمع المتّجهين المُرمّزين النّاتجين. ومن جهةٍ أخرى، نستخدم في نموذجنا (object features) ونجمعها بطريقةٍ تسلسليّةٍ إلى (CNN features) قبل التّضمين (embedding). قمنا لاحقًا بإجراء التّجارب على مجموعة البيانات (MS COCO) وفقًأ لتقسيم (Karpathy) [33] للاختبار أي (5000 صورة اختبارٍ). تمّ رصد أعلى فرقٍ في الدّرجات في كلّ عمودٍ بخطٍّ غامقٍ في الجدول (3). لوحظ أنّ نموذجهم يعطي أهميّةً متساويةً لسمات (CNN) وسمات الكائن (object features)، من خلال تمرير كلّ نوعٍ من السّمات إلى شبكة ترميز منفصلةٍ (LSTM) ومن ثمّ تتمّ إضافتهم. نموذجهم الأساسيّ يمتلك دقّةً أعلى من نموذجنا ممّا قد يفسّر الفرق بين نتائجنا ونتائجهم. لم يقدّموا أيّ تقريرٍ حول درجات (BLEU1) و (BLEU2) و (BLEU3) و (SPICE).
نلاحظ في الجدول (3)، أنّ نتائجنا قابلةٌ للمقارنة إلى حدٍّ ما مع نتائج (Yin and Ordonez) [9]. ومن خلال هذا الجدول نقدّم جميع نتائج التّقييم القياسيّة الثّمانية. تمّ التّوصّل إلى أنّ تقديم هذا النّوع من استخراج السّمات يؤدّي إلى تحسين درجات التّقييم مقارنةً بنموذجنا الأساسيّ (baseline model). تعكس الزّيادة في درجة (SPICE) وهي (5.88%) زيادة التّرابط الدّلالي (semantic correlation) عند استخدام سمات الكائن. ويعتبر هذا المقياس أحد تلك المقاييس الّتي من الصّعب تحسينها. وبالتّالي نخلص إلى أنّ الفرق في النّتيجة بين نموذجنا ونموذجهم قد يكون مرتبطًا بمزيج السّمات (feature combination) وطريقة التّرميز (encoding method). حيث يقومون بترميز كلّ نوعٍ مختلفٍ من السّمات في متّجهٍ (vector)، ومن ثمّ يقومون بإضافة هذين المتّجهين، بينما نموذجنا يقوم بجمع مجموعتي السّمات بشكلٍ مباشرٍ وبطريقةٍ تسلسليّةٍ.
أيضًا قمنا بمقارنة عملنا مع عمل (Sharif et al) [19]، الّذين حاولوا الاستفادة من العلاقات اللّغويّة (linguistic relations) بين الكائنات في الصّورة، حيث تمّت المقارنة بين نموذجنا ونموذجهم على مجموعة البيانات (Flickr30k) [34] في الجدول (4). يمكننا الملاحظة من خلال هذا الجدول أنّ طريقتنا تؤدي أيضًا إلى تحسّنٍ على المجموعة (Flickr30K) مع وجود التّحسّن الأكبر في درجة (METEOR).
يعرض الشّكل (3) التّالي مقارنةً بين النّموذج الأساسيّ (baseline model) والنّموذج المعزّز بسمات الكائن على مجموعات الاختبار والتّحقّق الخاصّة بمجموعة (MS COCO) وفقًا لتقسيم (Karpathy) [33]. نرى من خلال هذا الشّكل زيادةً واضحةً في النّتائج على جميع مقاييس التّقييم في كلا المجموعتين، والّذي يشير إلى خطأ تعميمٍ أقل (low generalization error) بالإضافة إلى إثبات فرضيّتنا القائلة بأنّ تعزيز نموذج الرّؤية بسمات الكشف عن الأغراض يحسّن من دقة (accuracy) النّموذج.
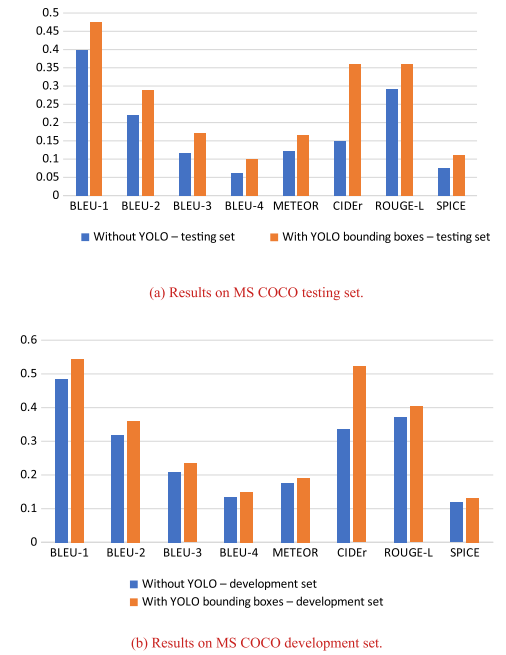
(a) النّتائج على مجموعة الاختبار (MS COCO). (b) النّتائج على مجموعة التّطوير (MS COCO).
يوضّح الشّكل (4)، مقارنةً نوعيّةً بين النّتائج مع استخدام سمات الكائن وبدونها. نلاحظ أنّ الفرق ملحوظٌ وأنّ إضافة سمات الكائن تجعل الجمل أكثر بروزًا من النّاحية النّحويّة مع وجود أخطاءٍ أقل في الكائن. على سبيل المثال:
(d): النّموذج بدون استخدام سمات الكائن قد حدّد بشكلٍ خاطئ وجود رجلٍ في الصّورة.
(e): لم يستطع النّموذج التّعرّف على الدّبّ الثّالث بدون سمات الكائن.
(f): ساعدت سمات الكائن في التّعرّف على مجموعةٍ من الأشخاص بدلًا من مجرّد امرأتين فقط.

الخاتمة والاستنتاجات (Conclusions).
في هذه الورقة، قمنا بتقديم نموذجٍ لتوصيف الصّورة ذي بنية مرمّز-فاكّ التّرميز بالاعتماد على الاهتمام (attention-based Encoder-Decoder image captioning model)، والّذي يستخدم طريقتين لاستخراج السّمات (feature extraction)، شبكة طيٍّ عصبونيّة (CNN) لتصنيف الصّور وهي (Xception) ووحدة الكشف عن الأغراض (object detection) وهي يولو الإصدار الرّابع (YOLOv4)، وأثبتنا فعاليّة هذا المخطّط. وقمنا أيضًا بتقديم عامل الأهميّة (IF) والّذي يعطي الأولويّة للكائنات الكبيرة الموجودة في المقدّمة على الكائنات الصّغيرة الموجودة في الخلفيّة، كما أنّه يفضّل الكائنات ذات الثّقة العالية على تلك ذات الثّقة المنخفضة، وأظهرنا تأثيره في زيادة النّتائج (scores). لقد أظهرنا كيف أنّ طريقتنا أدّت إلى تحسين النّتائج وقمنا بمقارنتها مع الأعمال السّابقة في زيادة النّتائج، وخاصّةً مقياس (CIDEr) الّذي ازداد بنسبة (15.04%)، ممّا يعكس تحسّنًا في البروز القواعدي والنّحوي.
وعلى عكس الأعمال السّابقة، اقترح عملنا الاستفادة من جميع سمات الكشف عن الأغراض المستخرجة من قبل يولو (YOLO) كما وأنّه أظهر تأثير ترتيب وسوم الكائنات المستخرجة. يمكن تحسين ذلك بشكلٍ أكبر من خلال طرقٍ أفضل للجمع بين سمات الكشف عن الكائنات (object detection features) وسمات الطّيّ (convolutional features).
يمكن أن تستفيد الأعمال المستقبليّة أيضًا من المعلومات الدّلاليّة للكائنات (object semantic information) من نصوص التّوصيفات بدلًا من تخطيطات الكائنات (object layouts) فقط، ممّا يزيد من دقّة توصيف الصّور. علاوةً على ذلك، يمكن استخدام طرقٍ أكثر تعقيدًا وتطوّرًا لترميز سمات الكائنات قبل إدخالها إلى فاكّ التّرميز (decoder)، كما وأنّه يمكن استخدام نماذج لغويّة أكثر تعقيدًا مثل محوّلات الذّاكرة المتشابكة (Meshed-Memory Transformers) [35].
الاختصارات (Abbreviations).
CNN: Convolutional Neural Network, LSTM: Long Short-Term Memory, GRU: Gated Recurrent Unit, VQA: Visual Question Answering, RPN: Region Proposal Network, IoU: Intersection-over-Union, ACG: Anchor-Centered Graph, VSR: Verb-specific Semantic Roles, CIC: Controllable Image Captioning, GSRL: Grounded Semantic Role labeling, SSP: Semantic Structure Planer, LCS: Long Common Subsequence.
ملحقٌ خاصٌّ بالجداول.
الجدول (1): مقارنةٌ لمجموعات البيانات المستخدمة.

الجدول (2): نتائج إضافة سمات الكائن إلى النّموذج الأساسيّ على مجموعة البيانات (MS COCO) وفق تقسيم (Karpathy).
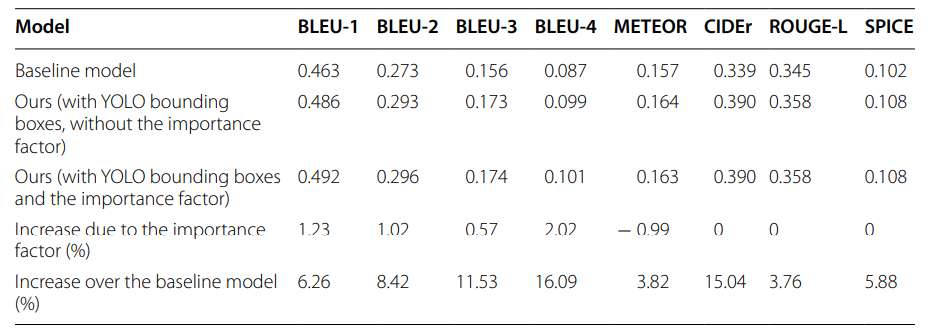
الجدول (3): مقارنة نتائج (Yin and Ordonez) [9] على مجموعة اختبار (MS COCO) وفق تقسيم (Karpathy.
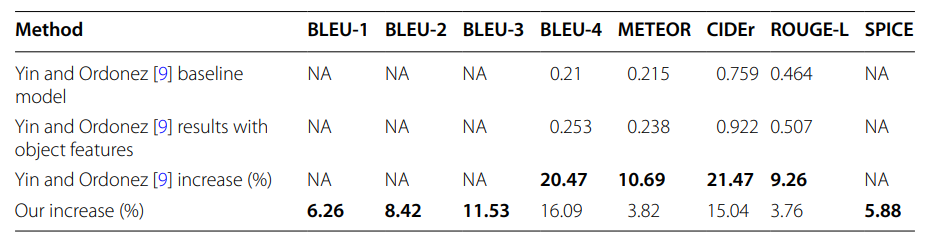
الجدول (4): مقارنة نتائج (Sharif et al) [19] على مجموعة اختبار (Flickr30k).
توافر البيانات والمواد (Availability of data and materials).
تتوفّر مجموعة البيانات (MS COCO) عبر الرّابط: COCO dataset. في حين يمكن طلب مجموعة البيانات (Flickr30K) من هنا: https://shannon.cs.illinois.edu/DenotationGraph/.
المراجع (References).
- Farhadi A, Hejrati M, Sadeghi MA, Young P, Rashtchian C, Hockenmaier J, Forsyth D. Every picture tells a story: generating sentences from images. In: European conference on computer vision. Berlin: Springer; 2010. p. 15–29.
- 2. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735–80.
- Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. https://arxiv.org/abs/1406.1078. Accessed 3 Jun 2014.
- Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y. Show, attend and tell: neural image caption generation with visual attention. In: International conference on machine learning. New York: PMLR; 2015. p. 2048–57.
- Katiyar S, Borgohain SK. Image captioning using deep stacked LSTMs, contextual word embeddings and data augmentation. https://arxiv.org/abs/2102.11237. Accessed 22 Feb 2021.
- 6. Redmon J, Farhadi A. Yolov3: an incremental improvement. https://arxiv.org/abs/1804.02767. Accessed 8 Apr 2018.
- Bochkovskiy A, Wang CY, Liao HY. Yolov4: optimal speed and accuracy of object detection. https://arxiv.org/abs/ 2004.10934. Accessed 23 Apr 2020.
- Redmon J, Farhadi A. YOLO9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2017. p. 7263–71.
- Yin X, Ordonez V. Obj2text: generating visually descriptive language from object layouts. https://arxiv.org/abs/1707. 07102. Accessed 22 Jul 2017.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. https://arxiv.org/ abs/1409.1556. Accessed 4 Sep 2014.
- Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L. ImageNet: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2009. p. 248–55.
- Vo-Ho VK, Luong QA, Nguyen DT, Tran MK, Tran MT. A smart system for text-lifelog generation from wearable cameras in smart environment using concept-augmented image captioning with modified beam search strategy. Appl Sci. 2019;9(9):1886.
- Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst. 2015;28:91–9.
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2016. p. 770–8.
- Lanzendörfer L, Marcon S, der Maur LA, Pendulum T. YOLO-ing the visual question answering baseline. Austin: The University of Texas at Austin; 2018.
- Szegedy C, Vanhoucke V, Iofe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2016. p. 2818–26.
- Herdade S, Kappeler A, Boakye K, Soares J. Image captioning: transforming objects into words. https://arxiv.org/abs/ 1906.05963. Accessed 14 Jun 2019.
- Wang J, Madhyastha P, Specia L. Object counts! bringing explicit detections back into image captioning. https:// arxiv.org/abs/1805.00314. Accessed 23 Apr 2018.
- Sharif N, Jalwana MA, Bennamoun M, Liu W, Shah SA. Leveraging Linguistically-aware object relations and NASNet for image captioning. In: 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ). Piscataway: IEEE; 2020. p. 1–6.
- Variš D, Sudoh K, Nakamura S. Image captioning with visual object representations grounded in the textual modality. https://arxiv.org/abs/2010.09413. Accessed 19 Oct 2020.
- Alkalouti HN, Masre MA. Encoder-decoder model for automatic video captioning using yolo algorithm. In: 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS). Piscataway: IEEE; 2021. p. 1–4.
- Ke A, Ellsworth W, Banerjee O, Ng AY, Rajpurkar P. CheXtransfer: performance and parameter efficiency of ImageNet models for chest X-Ray interpretation. In: Proceedings of the Conference on Health, Inference, and Learning. Harvard: CHIL; 2021. p. 116–24.
- Xu G, Niu S, Tan M, Luo Y, Du Q, Wu Q. Towards accurate text-based image captioning with content diversity exploration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE; 2021. p. 12637–46.
- Chen L, Jiang Z, Xiao J, Liu W. Human-like controllable image captioning with verb-specifc semantic roles. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE; 2021. p. 16846–56.
- Cornia M, Baraldi L, Cucchiara R. Show, control and tell: a framework for generating controllable and grounded captions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE; 2019. p. 8307–16.
- Papineni K, Roukos S, Ward T, Zhu WJ. Bleu: a method for automatic evaluation of machine translation. In: Proceengs of the 40th annual meeting of the Association for Computational Linguistics. Philadelphia: ACL; 2002. p. 311–8.
- Banerjee S, Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. Philadelphia: ACL; 2005. p. 65–72.
- Lin CY. Rouge: a package for automatic evaluation of summaries. In: Text summarization branches out. Barcelona: Association for Computational Linguistics; 2004. p. 74–81.
- Vedantam R, Lawrence Zitnick C, Parikh D. Cider: consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2015. p. 4566–75.
- Anderson P, Fernando B, Johnson M, Gould S. Spice: semantic propositional image caption evaluation. In: European conference on computer vision. Cham: Springer; 2016. p. 382–98.
- Chollet F. Xception: deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2017. p. 1251–8.
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. https://arxiv.org/ abs/1409.0473. Accessed 1 Sep 2014.
- Karpathy A, Fei-Fei L. Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Piscataway: IEEE; 2015. p. 3128–37.
- Plummer BA, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models. In: Proceedings of the IEEE international conference on computer vision. Piscataway: IEEE; 2015.
- Cornia M, Stefanini M, Baraldi L, Cucchiara R. Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE; 2020. p. 10578–87.