
1- المقدمة
سنقدم لكم في هذه المدونة دليلًا كاملًا لبناء شبكة عصبونية مهمتها التنبؤ بأسعار المنازل فيما إذا كانت مرتفعة أو منخفضة عن القيم الوسطى للأسعار. وسيتم بناء الشبكة العصبونية باستخدام لغة بايثون و بالاعتماد على مكتبة كيراس keras بحيث سيكون الكود سهلاً وواضحاً للجميع.
المحتويات
2- المتطلبات الأساسية
نفترض وجود بعض المعلومات الأساسية عن الشبكات العصبية وكيفية عملها، بما في ذلك بعض التفاصيل الجوهرية، مثل ما هي الملاءمة الزائدة overfitting واستراتيجيات معالجتها.
3- المصادر التي ستحتاجها
البيانات التي سنعتمد عليها في عملية التنبؤ مأخوذة من Zillow’s Home Value Prediction Kaggle competition data بعد إنقاص عدد المدخلات وتغيير المهمة إلى التنبؤ فيما إذا كان سعر المنازل أعلى أو أقل من القيمة الوسطية. من الرابط التالي يجب تحميل مجموعة البيانات المعدلة ومن ثم وضعها ضمن نفس مسار المشروع.
– لتحميل مجموعة البيانات database يجب الضغط هنا.
4- استخراج ومعالجة البيانات
قبل بدء أي شيفرة لأي خوارزمية من خوارزميات تعلَم الآلة Machine Learning algorithm يجب تحويل البيانات للشكل الذي يتناسب مع شكل مدخلات الخوارزمية لذلك في البداية سنحتاج للقيام بالخطوات التالية.
- قراءة ملف البيانات الذي قمنا بتحميله مسبقًا ذو الصيغة CSV وتحويله إلى مصفوفة تستطيع الخوارزمية العمل عليها.
- تقسيم مجموعة البيانات إلى مصفوفتين الأولى تحوي مزايا الدخل input features (والتي نسميها x) والثانية تحوي القيم التي نريد التنبؤ بها (التي نسميها y).
- القيام بتقييس البيانات Normalization أي جعل جميع مزايا الدخل ضمن المجال [0,1].
- تقسيم البيانات إلى ثلاث مجموعات: مجموعة التدريب Training set ومجموعة التحقق Validation set ومجموعة الاختبار test set.
لبدء كتابة الشيفرة البرمجية أول ما سنحتاج إليه هو فتح صفحة جديدة في google colab ومن ثم القيام بتضمين مكتبة تحليل البيانات في بايثون بانداس pandas.
import pandas as pd
وهذا يعني الوصول للمكتبة سيكون باستخدام الاسم pd. ولقراءة ملف البيانات housepricedata.csv وتخزينه في المتحول df ومن ثم طباعته نضيف الأسطر التالية.
df = pd.read_csv('housepricedata.csv')
df
بعد تنفيذ هذه الأسطر سيكون الخرج على الشكل التالي.

ظهرت لدينا مزايا الدخل في الأعمدة العشرة الأولى:
مساحة الأرض (بالقدم المربع) – الجودة الشاملة (مقياس من 1 إلى 10) – الحالة العامة للمنزل (مقياس من 1 إلى 10) – إجمالي مساحة الطابق السفلي (قدم مربع) – عدد الحمامات الكاملة – عدد الحمامات غير الكاملة – عدد غرف النوم فوق الأرض – إجمالي عدد الغرف فوق الأرض – عدد المواقد – مساحة المرآب (قدم مربع).
أما في العمود الأخير فتظهر القيمة التي نود التنبؤ بها إما “1” تعني أن سعر المنزل فوق القيمة المتوسطة أو “0” تعني أن سعر المنزل ليس فوق القيمة المتوسطة .
الخطوة التالية هي تحويل ما تم قراءته إلى مصفوفة وذلك يتم فقط من خلال إسناد قيم df إلى أي متحول ليكن dataset ثم طباعة المصفوفة الناتجة.
dataset = df.values
dataset
وبتنفيذ ما سبق سيكون الخرج كما في الشكل (2).

ومن ثم تقسيم المصفوفة dataset إلى مصفوفتين الأولى X والتي تحتوي مزايا الدخل والثانية Y والتي تحتوي على القيم المراد التنبؤ بها للقيام بذلك نقوم بإسناد أول عشرة أعمدة من مصفوفتنا إلى المتحول X وآخر عمود إلى المتحول Y.
X = dataset[:,0:10]
Y = dataset[:,10]
كل ما هو قبل الفاصلة ضمن الأقواس المربعة يمثل الأسطر ووجود “ : ” يعني أن المصفوفة X والمصفوفة Y ستتضمن جميع أسطر المصفوفة الأساسية. أما ما بعد الفاصلة يمثل الأعمدة ففي المصفوفة X نريد عشرة أعمدة ذات الفهارس من 0 إلى 9. أما في المصفوفة Y فنحن نريد فقط العمود الأخير الحادي عشر ذو الفهرس العاشر.
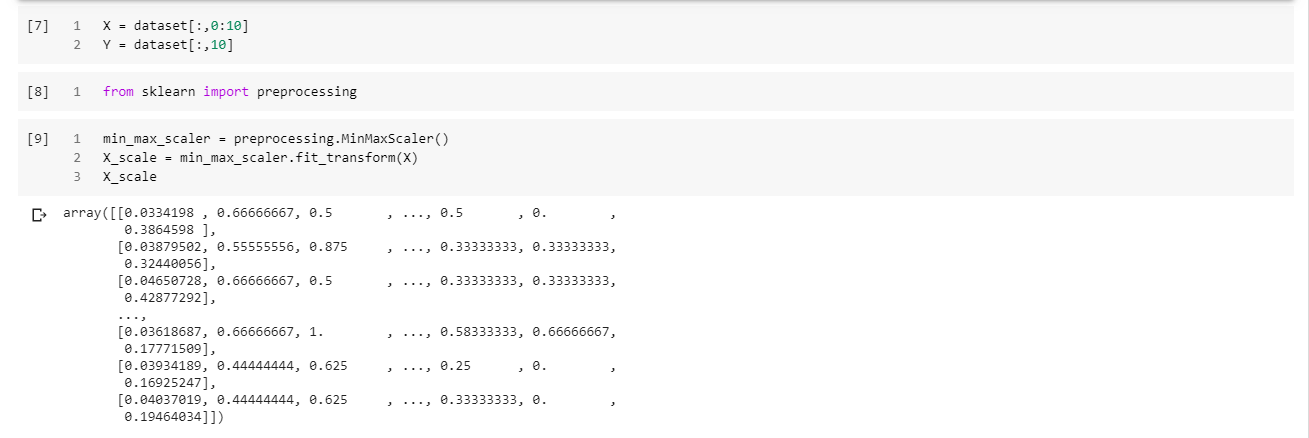
نلاحظ من القيم الظاهرة في الشكل 1 أن المساحة تصل للآلاف، ودرجة الجودة الشاملة تتراوح بين الـ 1 إلى 10، بينما عدد المواقد يأخذ إحدى القيم التالية 0،1،2. هذا الاختلاف في مجال القيم يجعل من الصعب تهيئة الشبكة العصبية والذي يتسبب ببعض المشاكل العملية، لذلك يجب إجراء عملية تقييس البيانات أي جعل جميع مزايا الدخل بين 0 و1 ويتم ذلك من خلال استخدام الشيفرات البرمجية الموجود في ‘preprocessing’ ضمن مكتبة sklearn ومن ثم استدعاء التابع التقييس min-max scaler. وأخيرًا تخزين المصفوفة الناتجة ضمن X_scale وطباعتها كما يلي.
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X_scale = min_max_scaler.fit_transform(X)
X_scale
بتنفيذ الشيفرة السابقة نحصل على الخرج التالي.
بهذا نكون قد وصلنا إلى الخطوة الأخيرة في معالجة البيانات، وهي تقسيم مجموعة البيانات الخاصة بنا إلى مجموعة تدريب ومجموعة تحقق ومجموعة اختبار وذلك باستخدام التابع train_test_split من مكتبة scikit-learn.
يقوم هذا التابع بتقسيم مصفوفة البيانات إلى قسمين فقط لكننا نريد كلا من X_scale وY بثلاثة أقسام لذلك سنقوم باستدعائه مرتين. في المرة الأولى سنمرر المصفوفة X_scale والمصفوفة Y لنحصل على مجموعة التدريب X_train وY_train كل منهما بحجم 70% من المصفوفة الأصلية، ومصفوفة التحقق والاختبار X_val_and_test وY_val_and_test كل منهما بحجم 30%.
في المرة الثانية سنمرر المصفوفة X_val_and_test والمصفوفة Y_val_and_test إلى التابع لتقسيمهما إلى قسمين متساويين الأول للتحقق والثاني للاختبار فنحصل على X_val, X_test, Y_val, Y_test جميعهم بحجم 15%.
from sklearn.model_selection import train_test_split
X_train, X_val_and_test, Y_train, Y_val_and_test = train_test_split(X_scale, Y, test_size=0.3)
X_val, X_test, Y_val, Y_test = train_test_split(X_val_and_test, X_val_and_test, test_size=0.5)
print (X_train.shape, X_val.shape, X_test.shape, Y_train.shape, Y_val.shape, Y_test.shape)
تنفيذ الشيفرة السابقة سيعطي الخرج التالي.

نلاحظ أن مجموعة التدريب تضم 1022 نقطة بيانات بينما مجموعة التحقق والاختبار تحتوي على 219 نقطة بيانات لكل منها. بهذه الخطوة تكون بيانات الشبكة أصبحت جاهزة.
5- بناء و تدريب الشبكة العصبية
نعلم أن تدريب الشبكة يتضمن تحديد نموذج الشبكة Template (بنيتها) ومن ثم إيجاد أفضل القيم من البيانات لملء النموذج.
الخطوة الأولى: إنشاء بنية الشبكة، يجب التفكير أولاً في نوع بنية الشبكة العصبونية التي نريدها. لنفترض أننا نريد الشبكة العصبية الممثلة في الشكل [5].

أي أننا نريد ثلاث طبقات كاملة الاتصال Dense وهم:
طبقة خفية 1: تحوي 32 عصبون، ونطبق عليها تابع التفعيل وحدة التصحيح الخطي ريلو ReLU وشكل الدخل هو 10 كونه لدينا عشر مزايا دخل.
طبقة خفية 2: تحوي 32 عصبون، ونطبق عليها تابع التفعيل وحدة التصحيح الخطي ريلو ReLU.
طبقة الخرج: تحوي عصبون وحيد، ونطبق عليها تابع التفعيل سيغمويد Sigmoid.
كتابة الشيفرة البرمجية تتطلب أولًا تضمين الشيفرات البرمجية الضرورية من مكتبة كيراس Keras ومن ثم تخزين النموذج في المعامل model والذي سنقوم بوصفه بالتسلسل(طبقة تلو الأخرى) بين الأقواس المربعة. كما هو مبين.
أثناء تدريب الشبكة نلاحظ انخفاض الخسارة وزيادة الدقة بمرور الوقت. لطباعة الدقة في مجموعة الاختبار الخاصة بنا، نقوم بكتابة السطر البرمجي التالي.
from keras.models import Sequential
from keras.layers import Dense
model = Sequential ([
Dense (32, activation='relu', input_shape= (10,)),
Dense (32, activation='relu'),
Dense (1, activation='sigmoid'),
])
الخطوة الثانية: إيجاد أفضل القيم من البيانات لملء النموذج. بعد إيجاد النموذج المناسب نحتاج إلى تمرير أفضل قيم له. وذلك عبر القيام بما يلي.
أولًا التهيئة من خلال تحديد خوارزمية التحسين وتابع الخسارة والمقاييس الأخرى التي نريد تطبقها. تهيئة النموذج بهذه الإعدادات تتطلب استدعاء التابع model.compile وذلك بالشكل التالي.
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy'])
تشير كلمة “sgd” إلى نسبة الانحدار العشوائية. وفي السطر الثاني تم تحديد الانتروبية المتقطعة الثنائية ‘binary_crossentropy” كتابع خسارة للمخرجات التي تأخذ القيم 1 أو 0. وأخيرًا عملية تتبع للدقة.
ثانيًا بدء عملية التدريب بكتابة سطر واحد من التعليمات البرمجية يتم فيه استدعاء التابع model.fit لتجهيز معاملات الشبكة أي تحديد البيانات التي نريد تدريب الشبكة عليها وهي X_train, Y_train ومن ثم تحديد حجم الدفعة المصغرة (mini-batch) بـ 32 واختيار فترة التدريب epochs=100. وفي النهاية، نحدد ماهية بيانات التحقق الخاصة بنا لنتمكن من قياس أداء النموذج في كل نقطة من نقاط بيانات التحقق.
hist = model.fit(X_train, Y_train,
batch_size=32, epochs=100,
validation_data=(X_val, Y_val))
بتنفيذ الكود السابق ستبدأ عملية تدريب الشبكة.

أثناء تدريب الشبكة نلاحظ انخفاض الخسارة وزيادة الدقة بمرور الوقت. لطباعة الدقة في مجموعة الاختبار الخاصة بنا، نقوم بكتابة السطر البرمجي التالي.
model.evaluate(X_test, Y_test)[1]
السبب وراء اختيار العنصر ذو الفهرس 1 بعد التابع model.evaluate هو أن التابع يرجع الخسارة كعنصر أول والدقة كعنصر ثان ولإخراج الدقة فقط قم بالوصول إلى العنصر الثاني (والذي تتم فهرسته بواسطة 1، حيث يبدأ العنصر الأول في الفهرسة من 0).
نظرًا للعشوائية في كيفية تقسيم مجموعة البيانات وكذلك تهيئة الأوزان، ستختلف الأرقام والرسم البياني قليلاً في كل مرة نقوم فيها بإعادة تنفيذ الشيفرة البرمجية ومع ذلك، يجب أن نحصل على دقة اختبار في أي مرة بين 80٪ إلى 95٪ إذا اتبعنا البنية المحددة أعلاه.

6- التمثيل البياني لكل من الخسارة والدقة
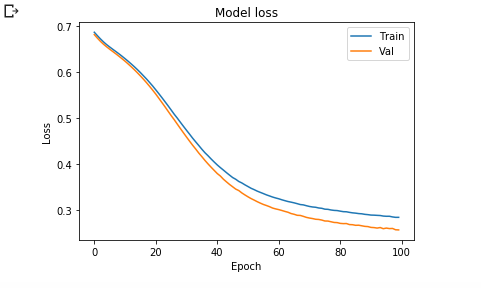
كيف يمكن معرفة فيما إذا كان نموذج الشبكة قد تمت ملاءمته بشكل زائد أو لا؟ لنعرف ذلك يجب رسم خسارة التدريب وفقدان القيمة على عدد من الفترات المنقضية. وللقيام بذلك سنستخدم مكتبة الرسم الرياضي في بايثون (ماتبلوت) matplotlib ومن ثم تمثيل كلا من خسارة التدريب وخسارة التحقق.
import matplotlib.pyplot as plt
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.show()
في السطر الثاني والثالث رسم كلا من خسارة التدريب وخسارة التحقق، السطر الرابع يحدد عنوان للرسم البياني ‘Model Loss’. أما السطران الخامس والسادس يحددان ما ينبغي أن يكون على المحورين y وx على التوالي. يتضمن السطر السابع وسيلة إيضاح للرسم البياني وسيكون موقعه في أعلى اليمين. وفي السطر الأخير تعليمة الرسم للخط البياني. وفي الشكل التالي النتيجة لتنفيذ الشيفرة السابق.
يمكننا القيام بالأمر نفسه لرسم الخط البياني لكل من دقة التدريب والتحقق على الشكل التالي:
plt.plot(hist_3.history['acc'])
plt.plot(hist_3.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
وسيكون الخرج على الشكل التالي.
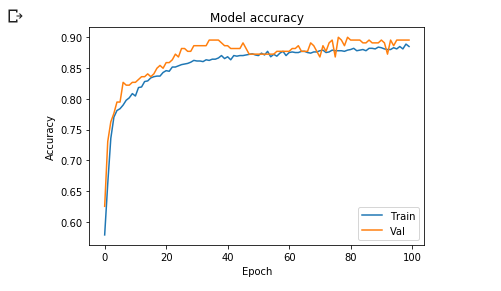
نظرًا لكون التحسينات التي طرأت على نموذجنا لمجموعة التدريب تبدو متطابقة إلى حد ما مع التحسينات على مجموعة التحقق من الصحة، هذا يعني أن الملاءمة بشكل زائد لا تمثل مشكلة كبيرة في نموذجنا.
7- إضافة التنظيم (Regularization) للشبكة العصبية
من أجل إدخال التنظيم على الشبكة العصبية سنقوم بإنشاء نموذج لشبكة عصبية أخرى ستتسبب بملاءمة زائدة على مجموعة التدريب و سندعوه Model 2.
model_2 = Sequential([
Dense(1000, activation='relu', input_shape=(10,)),
Dense(1000, activation='relu'),
Dense(1000, activation='relu'),
Dense(1000, activation='relu'),
Dense(1, activation='sigmoid'),
])model_2.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
hist_2 = model_2.fit (X_train, Y_train,
batch_size=32, epochs=100,
validation_data= (X_val, Y_val))
هنا، لقد صممنا نموذجًا أكبر من النموذج السابق بكثير، واستخدمنا مُحسِّن ادام Adam أحد أكثر المحسّنين شيوعًا، حيث يضيف بعض التعديلات على نسب الانحدار العشوائية بحيث يصل إلى أقل قيمة لتابع الخسارة بشكل أسرع. إذا قمنا بتشغيل الشيفرة البرمجية السابقة ومن ثم رسم الخطوط البيانية للخسارة لـ hist_2 باستخدام الشيفرة البرمجية أدناه (الأسطر البرمجية هي نفسها باستثناء أننا نستخدم “hist_2” بدلاً من “hist”):
plt.plot(hist_2.history['loss'])
plt.plot(hist_2.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.show()
سنحصل على الخرج التالي.

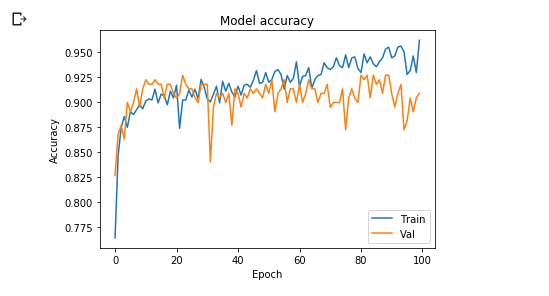
تبدو عدم الملائمة واضحة تمامًا فعلى الرغم من أن خسارة التدريب تتناقص إلا أن خسارة التحقيق أعلى بكثير منها وفي تزايد. وفي حال أردنا رسم الخط البياني للدقة من خلال كتابة الأسطر البرمجية التالية.
plt.plot(hist_2.history['acc'])
plt.plot(hist_2.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
يمكننا أن نرى اختلافًا أوضح بين دقة التدريب ودقة التحقق أيضًا:
8- تطبيق بعض استراتيجيات التقليل من الملاءمة الزائدة.
نعلم أن لدينا ثلاث استراتيجيات لتقليل الملاءمة الزائدة، لكننا هنا سنقوم بدمج استراتيجيتين فقط وهما التنظيم (L2 regularization) وتعطيل عمل العصبونات (dropout). السبب في أننا لن نستخدم استراتيجية التوقف المبكر (early stopping) هنا لأننا بعد تطبيق الاستراتيجيتين الأوليتين لن تأخذ خسارة التحقق الشكل U لذلك لن يكون استخدامه فعّال. أول ما سنقوم به هو تضمين الكود اللازم لكلتا الاستراتيجيتين.
from keras.layers import Dropout
from keras import regularizers
ثم ننشأ النموذج الثالث ليكون على الشكل التالي.
model_3 = Sequential([
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01), input_shape=(10,)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(0.01)),
])
هناك اختلافان رئيسيان بين النموذجين الثاني والثالث هما.
الاختلاف الأول. لإضافة تنظيم L2، لاحظ أننا أضفنا بعضًا من الكود الإضافي في كل طبقة من طبقاتنا كاملة الاتصال مثل:
kernel_regularizer=regularizers. l2(0.01)
هذا يخبر كيراس Keras بتضمين القيم التربيعية لتلك المعاملات في تابع الخسارة الإجمالية ووزنها بمقدار 0.01.الاختلاف الثاني. لإضافة تعطيل عمل العصبونات، أضفنا طبقة جديدة مثل هذا:
Dropout (0.3),
وهذا يعني أن العصبونات في الطبقة السابقة لديها احتمال 0.3 في التعطل أثناء التدريب. الآن لنقوم بتدريب النموذج الثالث بتطبيق الكود التالي.
model_3. compile (optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
hist_3 = model_3.fit (X_train, Y_train,
batch_size=32, epochs=100,
validation_data= (X_val, Y_val))
والآن، سنقوم بالرسم البياني لكل من للخسارة والدقة. وسنلاحظ أن الخسارة أعلى بكثير في البداية وذلك لأننا قمنا بتغيير تابع الخسارة. قبل الرسم يجب تحديد المجال بين 0 و 1.2 للخسارة لهذا الأمر سنضيف سطرًا من الكود عند الرسم وهو (plt.ylim):
plt.plot(hist_3.history['loss'])
plt.plot(hist_3.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.ylim(top=1.2, bottom=0)
plt.show()
وسيكون الخط البياني للخسارة على الشكل التالي.

نلاحظ من الخط البياني أن خسارة التحقق تتناسب بشكل وثيق مع خسارة التدريب لدينا. لنرسم الدقة باستخدام الكود التالي.
plt.plot(hist_3.history['acc'])
plt.plot(hist_3.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
وسنحصل على الخط البياني التالي.

بمقارنةً هذا النموذج بالنموذج الثاني، نلاحظ تخفيض كمية الملاءمة الزائدة بشكل كبير! إذا هذه هي الطريقة التي نطبق بها تقنيات التنظيم لتقليل الملاءمة الزائدة في مجموعة التدريب.
يمكنك عزيزي القارئ الوصول إلى الشيفرة البرمجية للتنبؤ بأسعار المنازل و تنفيذها بنفسك هنـــــا
9- الخاتمة
بهذا نكون قد قمنا ببناء و تدريب الشبكة العصبية مستخدمين مكتبة كيراس لإنجاز المهمة بأقل عدد ممكن من الأسطر البرمجية. وأيضًا قمنا بإنشاء نماذج أخرى إما من خلال المبادلة في الطبقات المختلفة أو تغيير المعاملات الأساسية لإدخال التنظيم للشبكة العصبية و فحص الملاءمة الزائدة ومن ثم تقليلها. كنتيجة لما سبق فقد قدمت كيراس الكثير من التسهيلات في بناء الشبكات العصبية لذا سنقوم باستخدامها لاحقًا في التطبيقات الأكثر تقدماً في الرؤية الحاسوبية ومعالجة اللغات الطبيعية.



تعليقان
عمل مميز
نشكر متابعتك ونتمنى لكم دوام الفائدة