إعداد: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. رامي عقّاد
ملخّص البحث (Abstract).
في هذه الورقة، نرى مهمّة توصيف الصّورة (Image Captioning) من تصّورٍ ومنظورٍ جديدٍ ألا وهو التّنبؤ بسلسلة إلى سلسلة (sequence-to-sequence prediction)، حيث نقترح محوّل التّوصيف (CaPtion TransformeR=CPTR) الّذي يأخذ الصّور الخام المتسلسلة بمثابة دخلٍ للمحوّل (Transformer). وبالمقارنة مع نموذج تصميم “شبكة الطّيّ العصبونيّة + المحوّل” (CNN+Transformer)، فبمقدور نموذجنا العمل على نمذجة السّياق العام (global context) في كلّ طبقة مرمّزٍ (encoder layer) من البداية كما وأنّه خالٍ تمامًا من عمليّات الطّيّ (convolution-free). أثبتت العديد من التّجارب فعّاليّة النّموذج المقترح حيث تفوّقنا على أساليب (CNN+Transformer) التّقليديّة الّتي تستخدم قاعدة بيانات مايكروسوفت كوكو (MS COCO). بالإضافة إلى ذلك، نقدّم تصّوراتٍ تفصيليّةٍ حول الاهتمام الذّاتيّ (self-attention) بين الدّفعات (patches) في المرمّز (encoder) والكلمات إلى الدّفعات (words-to-patches) في فاكّ الترّميز (decoder) بفضل معماريّة المحوّل الكاملة.
الكلمات المفتاحيّة: توصيف الصّورة، المحوّل، سلسلة إلى سلسلة.
1. المقدّمة (Introduction).
تعتبر مهمّة توصيف الصّورة تحدّيًا قائمًا بذاته، تتعلّق بتوليد لغةٍ طبيعيّةٍ لوصف صورة الدّخل بشكلٍ تلقائيٍّ. حاليًّا، تتبع معظم خوارزميات التّوصيف معماريّة المرمّز-فاكّ التّرميز (Encoder-Decoder)، حيث يتمّ استخدام شبكة فاكّ التّرميز (decoder) من أجل التّنبؤ بالكلمات وفقًا للسّمات المستخرجة من قبل شبكة المرمّز (encoder) عبر آليّة الاهتمام (attention mechanism). بفضل النّجاح الكبير الّذي حقّقه المحوّل (Transformer) [1] في مجال معالجة اللّغات الطّبيعيّة (NLP)، تميل نماذج التّوصيف الحديثة إلى استبدال نموذج الشّبكات العصبونيّة الإرجاعيّة (RNN) بمحوّلٍ في جزء فاكّ التّرميز لقدرته على التّدريب المتوازي (parallel training) والأداء الممتاز، في حين يظلّ جزء المرمّز دائمًا دون أيّ تغييرٍ، أي مثلًا كاستخدام نموذج شبكات الطّيّ العصبونيّة (CNN) كشبكة الرّواسب (ResNet) [2] المدرّبة مسبقًا على مهمّة تصنيف الصّور (image classification task) لاستخراج السّمات المكانيّة (spatial features)، أو استخدام شبكة الطّيّ العصبونيّة المناطقيّة الأسرع (Faster-RCNN) [3] المدرّبة مسبقًا على مهمّة الكشف عن الأغراض (object detection task) لاستخراج سماتٍ من الأسفل إلى أعلى [4].
في الآونة الأخيرة، جذبت الأبحاث حول تطبيق المحوّل في مجال الرّؤية الحاسوبيّة (computer vision) اهتمامًا هائلًا واسع النّطاق. على سبيل المثال، يستخدم نموذج (DETR) [5] المحوّل لفكّ ترميز تنبّؤات الكشف (detection predictions) من دون معرفةٍ مسبقةٍ مثل مقترحات المنطقة (region proposals) وإزالة التّداخل غير الأقصى (non-maximal suppression). يستخدم محوّل (ViT) [6] أيضًا المحوّل من دون أيّ تطبيقاتٍ لعمليّة الطّيّ (convolution operation) من أجل تصنيف الصّور، حيث يظهر أداءً واعدًا خاصّةً عندما يتمّ تدريبه مسبقًا على مجموعات بياناتٍ ضخمةٍ جدًّا مثل (ImageNet21k) و (JFT). وبالنّسبة للمهام عالية المستوى ومنخفضة المستوى لدينا محوّل (SETR) [7] من أجل التّجزئة الدّلاليّة للصّور (image semantic segmentation)، ومحوّل (IPT) [8] من أجل معالجة الصّور (image processing).
إذًا من خلال الأعمال السّابقة آنفة الذّكر، ننظر لحلّ مهمّة توصيف الصّورة من منظورٍ جديدٍ ألا وهو سلسلة إلى سلسلة (sequence-to-sequence)، ونقترح محوّل التّوصيف (CaPtion TransformeR=CPTR) حيث أنّه عبارةٌ عن شبكة محوّلاتٍ كاملةٍ يتمّ من خلالها استبدال شبكة (CNN) في جزء المرمّز بمرمّز محوّلٍ خالٍ تمامًا من عمليّات الطّيّ (convolution-free). وبالمقارنة مع نماذج التّوصيف التّقليديّة الّتي تأخذ كمدخلاتٍ السّمات المستخرجة من قبل شبكة (CNN) أو كاشف الكائنات (object detector)، فإنّنا هنا نأخذ الصّور الخام المتسلسلة بمثابة الدّخل. على وجه التّحديد، نقوم بتقسيم الصّورة إلى دفعاتٍ (patches) صغيرةٍ ذات حجمٍ ثابتٍ (على سبيل المثال 16*16)، ثمّ نقوم بتسطيح كلّ دفعةٍ منها وإعادة تشكيلها إلى تسلسل دفعاتٍ أحادي البعد (1D patch sequence). يمرّ تسلسل الدّفعات هذا عبر طبقة تضمين الدّفعات (patch embedding layer) وطبقة التّضمين الموضعيّ القابلة للتّعلّم (learnable positional embedding layer) قبل أن تتمّ تغذية مرمّز المحوّل (transformer encoder) بها.
بالمقارنة مع نموذج (CNN+Transformer)، يُعتبر محول التوصيف (CPTR) طريقةً فعّالةً وأكثر بساطةً كونها تتجنّب تمامًا عمليّة الطّيّ (convolution). في حين يملك مرمّز (CNN) الّذي يعتمد على عمليّة الطّيّ قيودًا على نمذجة السّياق العام (global context modeling) والّتي لا يمكن تحقيقها إلّا من خلال توسيع المجال الاستقباليّ تدريجيًّا كلّما تمّ التّعمّق أكثر في طبقات الطّيّ. يستطيع مرمّز (CPTR) الاستفادة من التّبعيّات طويلة المدى بين الدّفعات المتسلسلة (sequentialized patches) منذ البداية عن طريق آليّة الاهتمام الذّاتي (self-attention mechanism). كما وأنّه في أثناء توليد الكلمات، يقوم نموذج (CPTR) بنمذجة الاهتمام من الكلمات إلى الدّفعات (words-to-patches) في طبقة الاهتمام المتقاطع (cross attention layer) من فاكّ التّرميز (decoder). نقوم بتقييم طريقتنا على مجموعة بيانات توصيف الصّور (MS COCO) واستطاعت التّفوّق على كلا نموذجي التّوصيف (CNN+RNN) و (CNN+Transformer).
2. إطار العمل (FrameWork).
1.2 المرمّز (Encoder).
كما هو موضّحٌ في الشّكل (1)، بدلًا من استخدام نموذج (CNN) المدرّب مسبقًا أو نموذج شَبَكَةُ الطَّيِّ العُصبُونِيَّة المناطِقيَّةِ الأسرع (Faster R-CNN) لاستخراج السّمات المكانيّة (spatial features) أو سمات من الأسفل إلى أعلى (bottom-up features) مثل الطّرق السّابقة، نختار في هذا العمل تحويل صورة الدّخل إلى شكلٍ متسلسلٍ ومعالجة توصيف الصّورة وكأنّه بمثابة مهمّة تنبّؤ سلسلة إلى سلسلة (sequence-to-sequence prediction task). حيث أنّنا نقوم بتقسيم الصّورة الأصليّة إلى سلسلةٍ من دفعات الصّورة (image patches) للتّكيّف مع شكل الإدخال المطلوب للمحوّل (transformer).
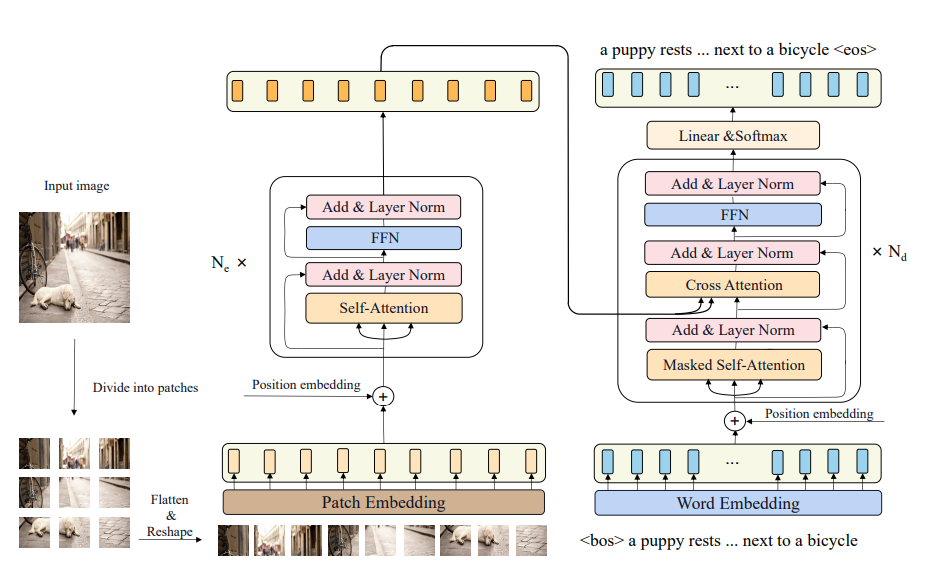
في بادئ الأمر، تتمّ إعادة ضبط حجم صورة الدّخل (input image) إلى دقّةٍ ثابتةٍ (fixed resolution) حيث لدينا X∈RH*W*3 (مع 3 قنوات ألوانٍ)، ثمّ يتمّ تقسيم الصّورة الّتي أعيد ضبط حجمها إلى (N) دفعةٍ أي (divide into patches)، حيث N=(H/P)*(W/P) وتكون (P) هي حجم الدّفعة (patch size) وفي إعدادات تجربتنا تكون (P=16). وبعد ذلك، نقوم بتسطيح كلّ دفعةٍ وإعادة تشكيلها (flatten & reshape) إلى تسلسل دفعاتٍ أحادي البعد (1D patch sequence) حيث أنّ XP∈RN*(p2.3). نستخدم طبقة تضمينٍ خطّيّةٍ (linear embedding layer) من أجل ربط سلسلة الدّفعة المسطّحة (flattened patch sequence) إلى الفضاء الكامن (latent space) وإضافة تضمينٍ موضعيٍّ أحادي البعد (1D position embedding) قابلٍ للتّعلّم إلى سمات الدّفعة (patch features)، ثمّ نحصل في النّهاية على الدّخل النّهائيّ لمرمّز المحوّل (Transformer Encoder) والّذي يشار إليه بالشّكل Pa=[p1,…..,pN].
يتاّلّف مرمّز نموذج (CPTR) من Ne من الطّبقات المتطابقة والمكدّسة، كلّ واحدةٍ منها تتكوّن من:
- طبقةٍ فرعيّةٍ للاهتمام الذّاتيٍّ متعدّد الرّؤوس (multi-head self-attention =MHA sublayer).
- طبقةٍ فرعيّةٍ للتّغذية الأماميّة الموضعيّة (positional feed-forward sublayer).
تحتوي (MHA) على (H) من رؤوس الاهتمام المتوازية وكلّ رأسٍ (hi) منها يوافق (independent scaled dot-product attention function) والّتي تسمح للنّموذج بالتّركيز على مساحاتٍ فرعيّةٍ مختلفةٍ. ثمّ يتمّ استخدام تحويلٍ خطّيٍّ (Wo) من أجل تجميع نتائج الاهتمام لعدّة رؤوسٍ مختلفةٍ، وهذه العمليّة يمكن صياغتها على النّحو التّالي:
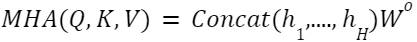
يعتبر (scaled dot-product attention) اهتمامًا خاصًّا مقترحًا في نموذج المحوّل (Transformer)، والّذي يمكن حسابه كالتّالي من خلال المعادلة (2):
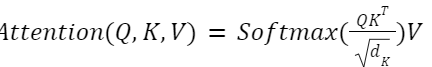
حيث Q∈RNq*dk, K∈RNk*dk و V∈RNk*dv هي على التّوالي: مصفوفة الطّلب (query)، مصفوفة المفتاح (key) مصفوفة القيمة (value).
يتمّ تنفيذ الطّبقة الفرعيّة ذات التّغذية الأماميّة الموضعيّة (positional feed-forward sublayer) كطبقتين فرعيّتين (linear layers) مع تابع التّفعيل (GELU activation function) وطبقة تعطيل عمل العصبونات (dropout) بينهما وذلك للمزيد من تحويل السّمات. يمكن صياغتها على النّحو التّالي:
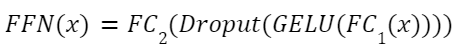
في كلّ طبقةٍ فرعيّةٍ، توجد الوصلات المختصرة (residual connections)، المتبوعة بطبقة التّطبيع (normalization layer).
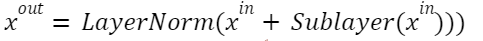
حيث أنّ (xin) و (xout) هما الدّخل والخرج لطبقةٍ فرعيّة واحدةٍ والّتي من الممكن أن تكون طبقة اهتمامٍ (attention layer) أو طبقة تغذيةٍ أماميّةٍ (feed forward layer).
بعض الملاحظات حول ما تمّ ذكره سابقًا من معادلات:
- جميع المعادلات الواردة في فقرة المرمّز (Encoder) مستمدّةٌ من العمل البحثيّ الشّهير المقترح من قبل فاسواني وآخرون عام (2017) تحت عنوان “Attention Is All You Need”، والّذي أحدث ثورةً بكيفيّة عمل النّماذج اللّغويّة (Language Models). يمكن الاطّلاع على تفاصيل هذه الورقة من هنا.
- في المعادلة (1) يكون (MHA) عبارةً عن عدّة طبقات اهتمامٍ (attention layers) بحيث تعمل على التّوازي، أي بدلًا من تنفيذ دالّة اهتمامٍ (attention function) واحدة يتمّ إسقاط جميع مصفوفات (الطّلب، المفتاح، القيمة) خطّيًّا لــ (H) مرّةٍ، ليتمّ بعد ذلك تنفيذ دالّة الاهتمام على التّوازي لهذه النّسخ المسقطة خطّيًّا من المصفوفات وهو ما يعادل ((hi. يتمّ فيما بعد تجميع النّتائج المتشكلة من (H) رأس اهتمامٍ بشكلٍ متسلسلٍ (concatenate) لتسقط خطّيًّا مرّةً أخرى باستخدام مصفوفة الوزن (Wo) وبالتّالي نحصل على القيم النّهائيّة من هذه العمليّة والّتي لوحظ بأنّ تكلفتها الحسابيّة الإجماليّة مشابهة تمامًا لعمل رأسٍ واحدٍ بأبعادٍ كاملة (full dimensionality).
- من الدّوال السّريعة والمعروف استخدامها في حساب الاهتمام هي دالّة اهتمام الجداء النّقطي (dot-product attention) والّتي تمّ تطبيقها في المعادلة (2). هنا يتمّ تنفيذ الجداء النّقطي (dot-product) للطّلب مع جميع المفاتيح (K) ثمّ ضرب كلٍّ منها بعامل القياس (scaling factor) وهو (dk√)/(1) حيث dk بعد كل من مصفوفتي الطّلب والمفتاح_ وتطبيق دالّة (softmax) عليها. بالنّسبة للقيمة (v) يتمّ تخصيصها استنادًا إلى قيمة الاهتمام النّاتجة إذا كانت عالية أو منخفضة والّتي يجب أن تكون بين (0) و (1).
- يتمّ استخدام وصلات التّخطي (skip connections) والمعروفة بمسمّاها الآخر الوصلات المختصرة (residual connections) ضمن هيكليّة المحوّل بشقّيه المرمّز وفاكّ التّرميز حول كلٍّ من الطّبقتين الفرعيّتين (Sublayers) للدّخل (xin) وهما طبقة الاهتمام (attention) وطبقة التّغذية الأماميّة (FFN). تكون هذه الوصلات متبوعةً على الدّوام بطبقة التّطبيع (LayerNorm) لتمرير قيمة دخل الطّبقة الفرعيّة الأصلي (xin) إليها والحصول على قيمة خرجها (xout) وهذا ما توضّحه المعادلة (4) والّذي من شأنه الإسهام بشكلٍ كبيرٍ في التّخفيف من مشكلة تلاشي المشتق (vanishing gradient problem).
2.2 فاكّ التّرميز (Decoder).
في جانب فاكّ التّرميز، نضيف تضمينًا موضعيًّا (positional embedding) لسمات تضمين الكلمة (word embedding features) ونأخذ كلًّا من نتائج الإضافة وسمات خرج المرمّز كمدخلاتٍ. يتألّف فاكّ التّرميز من Nd من الطّبقات المتطابقة والمكدّسة، حيث تحتوي كلٌّ منها على:
- طبقةٍ فرعيّةٍ للاهتمام الذّاتيّ متعدّد الرّؤوس المقنّع (masked multi-head self-attention sublayer).
- طبقةٍ فرعيّةٍ للاهتمام المتقاطع متعدّد الرّؤوس (multi-head cross attention sublayer).
- طبقةٍ فرعيّةٍ للتّغذية الأماميّة الموضعيّة (positional feed-forward sublayer).
يتمّ استخدام سمات الخرج (output features) من آخر طبقةٍ لفاكّ التّرميز من أجل التّنبّؤ بالكلمة التّالية عبر طبقةٍ خطّيةٍ (linear layer) يكون بعد الخرج فيها مساويًا لحجم المفردات (vocabulary size). بالنّظر إلى الجملة المرجعيّة (ground truth sentence) y1:T* والتّنبّؤ yt* لنموذج التّوصيف مع المعاملات θ، فإنّنا نعمل على تقليل خسارة الإنتروبيا المتقاطعة التّالية (cross entropy loss):
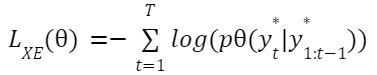
كما هو الحال مع طرق التّوصيف الأخرى، نقوم أيضًا بضبط نموذجنا (finetune) باستخدام التّدريب النّقديّ الذّاتيّ (self-critical training) [9].
3. التّجارب (Experiments).
1.3 مجموعة البيانات وتفاصيل التّنفيذ (Dataset and Implementation Details).
نقوم بتقييم نموذجنا على قاعدة بيانات مايكروسوفت كوكو (MS COCO) [15] والّتي تعدّ المعيار الأكثر استخدامًا في توصيف الصّورة (Image Captioning). للتّوافق مع الأعمال السّابقة، نستخدم تقسيمات كارباثي (Karpathy splits) [16] والّتي تحتوي على 113,287, 5,000 و 5,000 صورةٍ للتّدريب، التّحقّق والاختبار على التّوالي. تمّ تقرير النّتائج على كلٍّ من تقسيم اختبار كارباثي (Karpathy test split) للتّقييم غير المتّصل بالإنترنت (offline evaluation) وخادم اختبار (MS COCO) للتّقييم عبر الإنترنت (online evaluation).
نقوم بتدريب نموذجنا (end-to-end) مع تهيئة المرمّز بواسطة نموذج محوّل الرّؤية (ViT) المدرّب مسبقًا. تتمّ إعادة ضبط حجم الصّور المدخلة إلى دقّة (384*384) كما ويتمّ ضبط حجم الدّفعة (patch size) إلى (16). يحتوي المرمّز (encoder) على (12) طبقةٍ، بينما يحتوي فاكّ التّرميز (decoder) على (4) طبقاتٍ. أبعاد السّمة هي (768)، وعدد رؤوس الاهتمام (attention heads) هو (12) لكلٍّ من المرمّز وفاكّ التّرميز.
يتمّ تدريب النّموذج بالكامل أوّلًا باستخدام خسارة الإنتروبيا المتقاطعة (cross-entropy loss) من أجل (9) دورة تدريبٍ (epochs) باستخدام معدّل تعلّمٍ أوّليٍّ (learning rate) يبلغ حوالي (3*10-5) وينخفض بمقدار (0.5) في آخر دورتين تدريبيّتين. بعد ذلك، نقوم بضبط النّموذج من خلال التّدريب النّقديّ الذّاتيّ (self-critical training) [9] من أجل (4) دورات تدريبٍ وبمعدّل تعلّمٍ أوّليٍّ (7.5*10-6) وينخفض بمقدار (0.5) بعد دورتين تدريبيّتين. نستخدم محسّن آدم (Adam optimizer) وحجم الدّفعة (40). يتمّ استخدام البحث الشّعاعي (beam search) بحيث حجم الشّعاع هو (3).
نستخدم درجات (BLEU-1,2,3,4) و (METEOR) و (ROUGE) و (CIDEr) [17] من أجل تقييم طريقتنا والّتي يشار إليها بــ (B1,2,3,4, M, R and C) على التّوالي.
2.3 مقارنة الأداء (Performance Comparison).
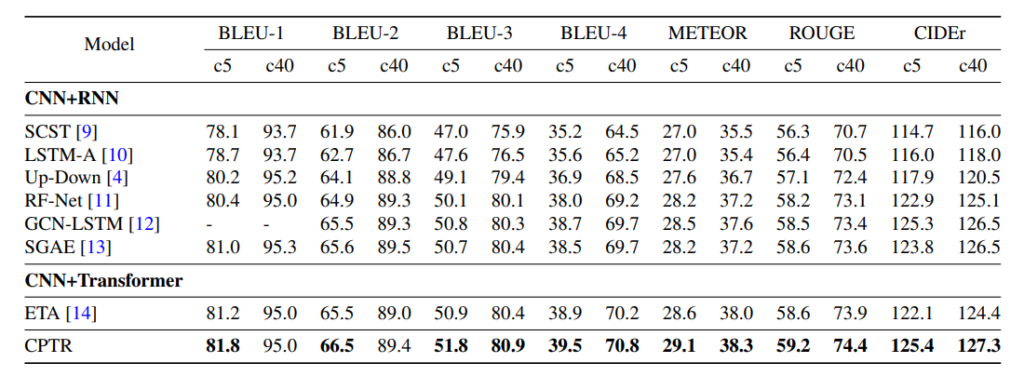
نقوم بمقارنة النّموذج المقترح محوّل التّوصيف (CPTR) بنماذج (CNN+RNN) بما في ذلك: الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى (LSTM) [18]، نموذج التّدريب التّسلسلي النّقدي الذّاتي (SCST) [9]، (LSTM-A) [10]، شبكة الاندماج المدركة للمنطقة (RFNet) [11]، نموذج أعلى-أسفل (Up-Down) [4]، شبكة الطّيّ ذات الرّسم البيانيّ-الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى(GCN-LSTM) [12]، (LBPF) [19]، المرمّز التّلقائي للرّسم البياني للمشهد (SGAE) [13]، وأيضًا نماذج (CNN+Transformer) بما فيها: محوّل علاقة الكائن (ORT) [20]، محوّل التّنبؤ بالوقت المقدّر للوصول إلى الوجهة (ETA) [14]. تستخدم كلّ هذه الطّرق المذكورة سابقًا سمات الصّورة (image features) المستخرجة من قبل شبكة (CNN) أو كاشف الأغراض (object detector) كمدخلاتٍ، في حين يأخذ نموذجنا مباشرةً الصّورة الخام (raw image) كدخلٍ.
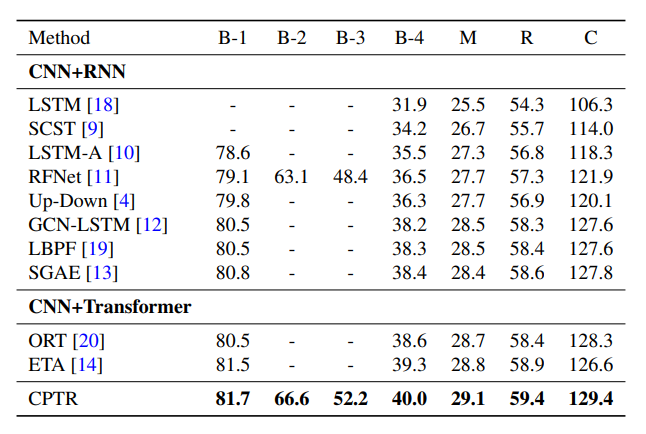
يظهر الجدول (2)، نتائج مقارنة الأداء على تقسيم اختبار كارباثي (Karpathy test split) غير المتّصل بالإنترنت، حيث يحقّق نموذج محوّل التّوصيف (CPTR) درجة (129.4) على مقياس الأداء (CIDEr) هذا ما يجعله يتفوّق على كلٍّ من نموذجي (CNN+RNN) و (CNN+Transformer). نعزو سبب تفوّق نموذج (CPTR) على بنية (CNN+) التّقليديّة لقدرته على نمذجة السّياق العام في كلّ طبقات المرمّز. وأمّا بالنّسبة للجدول (1)، فيوضّح نتائج تقييم خادم اختبار (MS COCO) عبر الإنترنت والّتي تظهر فعاليّة نموذج محوّل التّوصيف (CPTR) الخاصّ بنا.
3.3 دراسة الاستئصال (Ablation Study).
نقوم بإجراء دراسات الاستئصال من الجوانب التّالية:
- استخدام نماذج مختلفة مدرّبةٍ مسبقًا (pre-trained models) من أجل تهيئة مرمّز المحوّل (Transformer Encoder).
- استخدام دقّةٍ (resolution) مختلفةٍ لصورة الدّخل (input image).
- عدد الطّبقات (number of layers) وأبعاد السّمة (feature dimension) في فاكّ ترميز المحوّل (Transformer Decoder).
يتمّ إجراء جميع هذه التّجارب على مجموعة تحقّق كارباثي (Karpathy validation set)، ويتمّ تحسينها من خلال خسارة الإنتروبيا المتقاطعة (cross-entropy loss) فقط.
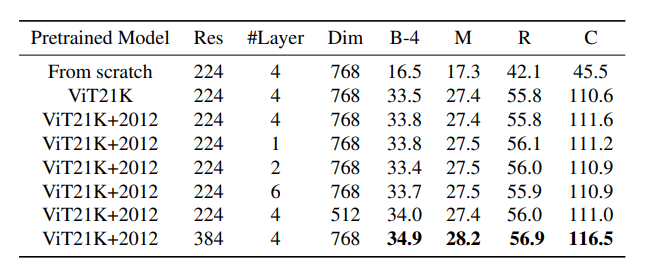
من خلال نتائج التّجربة المدوّنة في الجدول (3) نستطيع استخلاص الاستنتاجات التّالية. أوّلًا، بالمقارنة مع التّدريب من الصّفر (training from scratch)، فإنّ استخدام معاملات نموذج (ViT) المدرّب مسبقًا على مجموعة البيانات (ImageNet21K) من أجل تهيئة مرمّز محوّل التّوصيف (CPTR) يعزّز الأداء بشكلٍ كبيرٍ. وإلى جانب ذلك، فإنّ استخدام معاملات نموذج (ViT) المضبوطة بدقّةٍ على مجموعة البيانات (ImageNet 2012) لتهيئة المرمّز من شأنه أن يجلب تحسّنًا بمقدار نقطةٍ واحدةٍ في درجة (CIDEr). ثانيًا، يظهر نموذج (CPTR) حساسيّةً قليلةً للمعاملات الأساسيّة (hyperparameter ) الخاصّة بفاكّ التّرميز (decoder) بما في ذلك: عدد الطّبقات (number of layers) وأبعاد السّمة (feature dimension)، حيث أنّ (4) طبقاتٍ و (768) بعدًا تُظهر أفضل أداءٍ (111.6 درجةٍ لمقياس CIDEr). فيما يتعلّق بدقّة صورة الدّخل (input image resolution)، وجدنا أنّ زيادتها من (224 × 224) إلى (384 × 384) مع الحفاظ على حجم الدّفعة مساويًا لــ (16) يمكن أن يعزّز الأداء بشكلٍ كبيرٍ (من 111.6 درجةٍ لــ CIDEr إلى 116.5 درجةٍ لــ CIDEr). ومن المنطقيّ أن يزداد طول سلسلة الدّفعة (patch sequence) من (196) إلى (576) بسبب الزّيادة في دقّة (resolution) الدّخل، كما ويمكن تقسيم الصّورة بشكلٍ أكثر تحديدًا وتوفير المزيد من السّمات (features) للتّفاعل مع بعضها البعض عبر طبقة الاهتمام الذّاتيّ للمرمّز (encoder self-attention layer).
4.3 عرض وتصوّر الاهتمام (Attention Visualization).
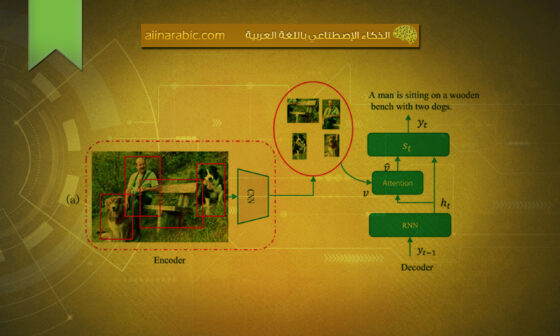
في هذا القسم، نأخذ صورة مثالٍ واحدٍ لإظهار الوصف المتنبأ به من قبل نموذج محوّل التّوصيف (CPTR)، ونعرض كلًّا من أوزان الاهتمام الذّاتيّ لتسلسلات الدّفعة في المرمّز وأوزان الاهتمام المتقاطع الخاصّ بــ (words-to-patches) في فاكّ التّرميز.
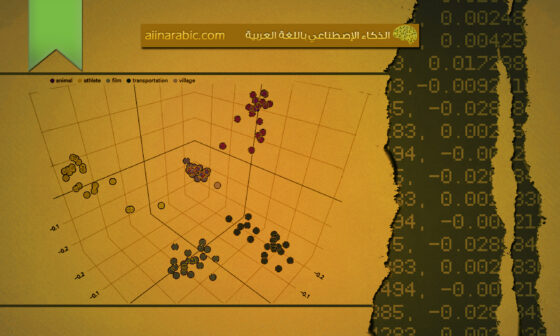
فيما يتعلّق بالاهتمام الذّاتيّ للمرمّز، نختار دفعة صورةٍ من أجل عرض أوزان اهتمامها لجميع الدّفعات. وكما هو موضّحٌ في الشّكل (2) في الطّبقات السّطحيّة (shallow layers)، يتمّ استغلال كلا السّياقين العام والمحليّ بواسطة رؤوس اهتمامٍ مختلفةٍ وذلك بفضل تصميم المحوّل الكامل والّذي لا يمكن تحقيقه من خلال المرمّزات المتمثّلة بشبكات الطّيّ العصبونيّة (CNN) التّقليديّة. في الطّبقة الوسطى (middle layer)، يميل النّموذج لصبّ جلّ اهتمامه على العنصر الأساسيّ والأوّلي، مثل لعبة الدّبّ (teddy bear) في الصّورة. تستخدم الطّبقة الأخيرة (last layer)، تستخدم السّياق العام بشكلٍ كاملٍ، كما وأنّها تهتم بكلّ الكائنات في الصّورة، أي لعبة الدّبّ (teddy bear)، الكرسيّ (chair) والكمبيوتر المحمول (laptop).

بالإضافة إلى ذلك، نقوم بعرض أوزان الاهتمام الخاصّة بــ (words-to-patches) في فاكّ التّرميز (decoder) في أثناء عمليّة توليد التّوصيف. وكما هو موضّحٌ في الشّكل (3)، يستطيع نموذج محوّل التّوصيف (CPTR) الاهتمام بشكلٍ صحيحٍ بالدّفعات المناسبة من الصّورة عند التّنبّؤ بكلّ كلمةٍ.

4. الخاتمة (Conclusions).
في هذه الورقة، نعيد التّفكير والنّظر في توصيف الصّورة (Image Captioning) باعتبارها مهمّة تنبّؤ سلسلة إلى سلسلة (sequence-to-sequence prediction task) ونقترح نموذج محوّل التّوصيف (CPTR)، نموذج محوّلٍ كاملٍ من أجل استبدال (CNN+Transformer) التّقليديّة. إنّ شبكتنا خاليةٌ تمامًا من عمليّات الطّيّ (convolution-free)، كما وأنّها تتمتّع بالقدرة على نمذجة معلومات السّياق العامّ (modeling global context information) في كلّ طبقة مرمّزٍ منذ البداية. تظهر نتائج التّقييم على قاعدة بيانات مايكروسوفت كوكو (MS COCO) الشّهيرة فعاليّة طريقتنا ونتفوّق على شبكات (CNN+Transformer). وتظهر التّصوّرات التّفصيليّة أنّ نموذجنا قادرٌ على استغلال التّبعيّات طويلة المدى منذ البداية، ويمكن لاهتمام فاكّ التّرميز المتمثّل بربط الكلمات إلى الدّفعات (words-to-patches) أن يميل بدقّةٍ وبشكلٍ صحيحٍ إلى الدّفعات المرئيّة الموافقة للتّنبّؤ بالكلمات.
ملحقٌ خاصٌّ بالجداول.
الجدول (1): مقارنات الأداء على خادم اختبار (MS COCO) عبر الإنترنت. يتمّ ضبط جميع النّماذج من خلال التّدريب النّقديّ الذّاتيّ (self-critical training). يشير (c5/c40) إلى إعدادات الاختبار الرّسميّة مع توصيفاتٍ مرجعيّةٍ بنسبة (5/40).
الجدول (2): مقارنات الأداء على تقسيم اختبار كارباثي (MS COCO Karpathy). يتمّ ضبط جميع النّماذج من خلال التّدريب النّقديّ الذّاتيّ (self-critical training).
الجدول (3): دراسات الاستئصال في مرحلة تدريب الإنتروبيا المتقاطعة. تمثّل (Res) دقّة الصّورة. وتمثّل (#Layer) عدد طبقات فاكّ التّرميز، في حين تمثّل (Dim) بعد السّمة لفاكّ التّرميز.
5. المراجع (References).
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137–1149, 2016.
- Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6077–6086.
- Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko, “End-to-end object detection with transformers,” arXiv preprint arXiv:2005.12872, 2020.
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al., “An image is worth 16×16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al., “Rethinking semantic segmentation from a sequence-tosequence perspective with transformers,” arXiv preprint arXiv:2012.15840, 2020.
- Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao, “Pre-trained image processing transformer,” arXiv preprint arXiv:2012.00364, 2020.
- Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel, “Self-critical sequence training for image captioning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7008–7024.
- Ting Yao, Yingwei Pan, Yehao Li, Zhaofan Qiu, and Tao Mei, “Boosting image captioning with attributes,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4894–4902.
- Lei Ke, Wenjie Pei, Ruiyu Li, Xiaoyong Shen, and YuWing Tai, “Reflective decoding network for image captioning,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 8888–8897.
- Ting Yao, Yingwei Pan, Yehao Li, and Tao Mei, “Exploring visual relationship for image captioning,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 684–699.
- Xu Yang, Kaihua Tang, Hanwang Zhang, and Jianfei Cai, “Auto-encoding scene graphs for image captioning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 10685– 10694.
- Guang Li, Linchao Zhu, Ping Liu, and Yi Yang, “Entangled transformer for image captioning,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 8928–8937.
- Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755.
- Andrej Karpathy and Li Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3128–3137.
- Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollar, and C Lawrence Zitnick, “Microsoft coco captions: Data collection and evaluation server,” arXiv preprint arXiv:1504.00325, 2015.
- Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164.
- Yu Qin, Jiajun Du, Yonghua Zhang, and Hongtao Lu, “Look back and predict forward in image captioning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 8367–8375.
- Simao Herdade, Armin Kappeler, Kofi Boakye, and Joao Soares, “Image captioning: Transforming objects into words,” in Advances in Neural Information Processing Systems, 2019, pp. 11137–11147.