
إعداد: م. ماريّا حماده
التّدقيق اللّغويّ: م. ماريّا حماده
التّدقيق العلميّ: م. محمّد سرميني، م. رامي عقّاد
ملخّص البحث (Abstract)
يعتبر توصيف الصّورة (Image Captioning) أحد مجالات البحث الأساسيّة للذّكاء الإصطناعيّ (Artificial Intelligence) والّذي يتضمّن التّفسير المرئيّ والبصريّ (visual interpretation) مع وصفٍ لغويٍّ (linguistic description) للصّورة المقابلة. يعتمد توصيف الصّورة النّاجح على التقاط واكتساب أكبر قدرٍ ممكنٍ من المعلومات من الصّورة الأصليّة. وأحد هذه الأجزاء الأساسيّة من المعرفة هو الموضوع (topic) أو المفهوم (concept) الّذي ترتبط به الصّورة. في الآونة الأخيرة، تمّ استخدام تقنيّة نمذجة المفهوم (Concept Modeling Technique) في توصيف الصّور باللّغة الإنجليزيّة من أجل التقاط سياقات الصّور بالكامل (image contexts) والاستفادة من هذه السّياقات في إنتاج أوصافٍ للصّور أكثر دقّة. في هذه الورقة، تمّ اقتراح نموذج قائمٍ على المفهوم (concept-based model) من أجل توصيف الصّور باللّغة العربيّة (Arabic Image Captioning=AIC). وأيضًا تمّ اقتراح بنيةٍ جديدةٍ لمحوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (Vision-based Multi-Encoder Transformer Architecture=ViMETA) للتّعامل مع نتيجة المخرجات المتعدّدة من تقنيّة نمذجة المفهوم أثناء إنتاج توصيف الصّورة. تمّ استخدام المعايير القياسيّة، معيار تقييم التّطابق ثنائي اللّغة (BiLingual Evaluation Understudy=BLEU) ومعيار تقييم جودة النّصوص التّوليديّة (Recall-Oriented Understudy for Gisting Evaluation=ROUGE) من أجل تقييم النّموذج المقترح باستخدام مجموعة البيانات فليكر (Flickr8K) مع أوصافٍ عربيّةٍ. علاوة على ذلك، تمّ إجراء تحليلٍ نوعيٍّ (qualitative analysis) لمقارنة الأوصاف المنتجة (produced captions) للنّموذج المقترح مع الأوصاف المرجعيّة الحقيقيّة (ground truth descriptions). واعتمادًا على النّتائج التّجريبيّة، تفوّق النّموذج المقترح على الأعمال ذات الصّلة من النّاحية الكمّيّة (quantitatively)، باستخدام معايير التّقييم المتمثّلة بمعيار تقييم التّطابق ثنائي اللّغة (BLEU) ومعيار تقييم جودة النّصوص التّوليديّة (ROUGE)، وأيضًا من النّاحية النّوعيّة (qualitatively).
الكلمات المفتاحيّة: توصيف الصّورة باللّغة العربيّة، المحوّل، المفهوم، الرّؤية الحاسوبيّة.
1. المقدّمة (Introduction)
نرى العديد من الصّور كلّ يومٍ من مصادر متنوّعةٍ، بما في ذلك الإنترنت، الأخبار والوثائق. وتُترك الصّور من هذه المصادر ليتمّ تفسيرها من قبل المشاهدين. وعلى الرّغم من أنّ غالبيّة هذه الصّور تفتقر للأوصاف، إلّا أنّ أغلب الأشخاص يستطيعون فهمها من دون وصفٍ. يتضمّن توفير تعليقٍ توضيحيٍّ للصّورة إعطاء وصفٍ واضحٍ (clear) ومختصرٍ (brief) للصّورة الموافقة.
إنّ توصيف الصّور يعتبر مهمّةً ضروريّةً لأنّها أصبحت مطلوبةً في العديد من التّطبيقات (applications). ففي السّنوات العشرين الماضية، استخدمت مجالات فهرسة الصّور (image indexing)، استرجاع المعلومات (information retrieval)، الرّوبوتات (robotics) والطّبّ (medicine) على نطاقٍ واسعٍ توصيف الصّور [13]. كما ويعتبر هذا المجال تحدّيًا قائمًا بذاته لأنّه يتطلّب فهمًا عميقًا (depth comprehension) للعناصر الدّلاليّة (semantic elements) للصّورة والقدرة على التّعبير عن هذه العناصر بكلماتٍ تبدو طبيعيّةً. لذلك، فإنّ توصيف الصّورة يتضمّن استخدام أساليب الرّؤية الحاسوبيّة (Computer Vision approaches) لاستخراج سمات الصّورة (image’s features) بالإضافة إلى أساليب معالجة اللّغة الطّبيعيّة (Natural Language Processing approaches) لإنتاج الأوصاف [28].
إنّ توصيف الصّور باللّغة العربيّة (AIC) هي مهمّةُ وصف صورة الدّخل بجملةٍ عربيّةٍ. غالبيّة مشاريع البحث في مجال توصيف الصّورة تركّز على إنتاج أوصافٍ باللّغة الإنجليزيّة، ويرجع ذلك في المقام الأوّل بسبب نقص مجموعات البيانات العامّة المتاحة للّغات الأخرى وخاصّةً العربيّة. إنّ اللّغة العربيّة معقدةٌ للغاية، ونتيجةً لذلك، فإنّ التّعامل والعمل معها يشكّل تحدّيًا كبيرًا. تحتوي اللّغة على لهجاتٍ (dialects) مختلفةٍ ويرجع ذلك في المقام الأول بسبب استخدام علامات التّشكيل (diacritics). وبذلك تحتاج نماذج التّوصيف (captioning models) للتّعرّف على دلالات النّصّ (text’s semantics) المضمّنة في اللّغة المقصودة [1].
يجب إيلاء اهتمامٍ كبيرٍ باللّغة العربيّة لأنّها اللّغة الأولى في 22 دولةٍ ويتحدّث بها حوالي 430 مليون شخص في العالم العربيّ [8]. بالإضافة إلى ذلك، تعدّ اللّغة العربيّة رابع أكثر اللّغات استخدامًا على الإنترنت. علاوةَ على ذلك، كانت اللّغة العربيّة أسرع اللّغات نموًّا في السّنوات الثّماني الماضية. لذلك، على الرّغم من التّحسينات الكبيرة في نماذج توصيف الصّورة باللّغة الإنجليزيّة، إلّا أنها غير قابلةٍ للتّطبيق على الفور من أجل اللّغات الأخرى، مثل العربيّة. وهذا ما يجعل توصيف الصّورة باللّغة العربيّة قيد التّطوير [8].
يعتمد توصيف الصّورة النّاجح على التقاط واكتساب أكبر قدرٍ ممكنٍ من المعلومات من الصّورة الأصليّة. وأحد هذه الأجزاء الأساسيّة من المعرفة هو الموضوع (topic) أو المفهوم (concept) الّذي ترتبط به الصّورة. ومن أجل إنتاج هذه المفاهيم، تأخذ تقنيّة نمذجة المفاهيم كلًّا من بيانات التّوصيف (caption data) والصّور (images) في عين الاعتبار أثناء تحديد المفاهيم الّتي يجب استخراجها. تمّ استخدام تقنيّة نمذجة المفهوم (Concept Modeling Technique) في توصيف الصّور من أجل التقاط سياقات الصّور بالكامل (image contexts) والاستفادة من هذه السّياقات في إنتاج أوصافٍ للصّور أكثر دقّة.
تمّ تطوير تقنيّة نمذجة المفهوم منذ عامين بواسطة جروتندورست (Grootendorst) [11]. وهي تقنيّةٌ متعدّدة الوسائط (multimodal technique) تعمل على توليد مجموعةٍ من متّجهات المفاهيم (concept vectors) وذلك بناءً على الصّور المدخلة والنّصوص الموافقة لها باستخدام نموذج كليب وهو نموذج التّدريب المسبق المقارن بين الصّورة واللّغة (Contrastive Language-Image Pre-Training model=CLIP) [24] ونموذج بيرتوبيك (BerTopic model) [10]. تكمن الفكرة وراء تقنيّة نمذجة المفاهيم في التقاط المعلومات الدّلاليّة (semantic information) للصّورة بشكلٍ دقيقٍ. كما وأنّها تستطيع العمل على أكثر من 50 لغةٍ [11].
في هذه الورقة، تمّ استخدام تقنيّة نمذجة المفاهيم من أجل اقتراح نموذجٍ قائمٍ على المفهوم (concept-based model) من أجل توصيف الصّور باللّغة العربيّة (AIC) . حيث استُخدمت هذه التقنيّة على صور مجموعة البيانات والأوصاف العربيّة (arabic captions) من أجل استخراج مجموعةٍ من متّجهات المفاهيم الجديدة وتضمين الصّور (image embedding). بعد ذلك، يتمّ إرسال مخرجات نموذج المفاهيم إلى فاكّ التّرميز (decoder).
في الآونة الأخيرة، تمّ استخدام المحوّل (transformer) [29] في توصيف الصّورة كفاكٍ للتّرميز (decoder) من أجل توفير توصيفاتٍ أكثر دقّة مع تعقيدٍ أقل. حيث يستخدم المحوّل التّقليدي مرمّزًا واحدًا (encoder) لتمثيل سمات الصّورة (image’s features) بالإضافة إلى فاكّ ترميزٍ واحدٍ (decoder) من أجل فكّ ترميز الأوصاف الجزئيّة عن طريق الاهتمام وأخذ عين الاعتبار بالسّمات المرمّزة (encoded features).
يقترح هذا العمل البحثي بنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (Vision-based Multi-Encoder Transformer Architecture=ViMETA). حيث تمّت إضافة مرمّزٍ جديدٍ للمحوّل ليعكس معلومات المفهوم. وعلاوةً على ذلك، يتمّ تعديل فاكّ ترميز المحوّل (transformer decoder) من خلال إضافة طبقة اهتمامٍ مرّمز-فاكّ ترميز (Encoder-Decoder attention layer) وبالتّالي يمكن توجيه الاهتمام إلى معلومات المفهوم والّتي يتمّ تمثيلها من قبل المرمّز الجديد. إنّ المرمّزات المقترحة في بنية هذا المحوّل المتعدّد المرمّزات (ViMETA) مستوحاةٌ من مرمّز محوّل الرّؤية (Vision Transformer Encoder) [7].
تمّ اقتراح بنية محوّل متعدّد المرمّزات قائمٍ على الرّؤية (ViMETA) هنا في هذه الورقة كفاكّ ترميزٍ لنموذج التّوصيف. حيث يتضمّن مرمّزين وفاكّ ترميزٍ واحدٍ. مرمّز المحوّل الأوّل يتلقّى متّجهات المفاهيم (concept vectors) في حين يستقبل مرمّز المحوّل الآخر سمات نموذج كليب (CLIP). بعد ذلك، يتمّ استخدام فاكّ ترميز المحوّل من أجل توليد الكلمات التّالية في التّوصيف بالاعتماد على المعلومات المقدّمة من قبل المرمّزين والتّضمينات الخاصّة (embeddings) بالأوصاف الجزئيّة.
تمّ تقييم نموذج التّوصيف باللّغة العربيّة المقترح (AIC)_المعتمد على نموذج المفهوم (concept model) وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (Vision-based Multi-Encoder Transformer Architecture) أي (Ar-CM-ViMETA)_على مجموعة البيانات فليكر (Flickr8k) [12] وذلك باستخدام معيار تقييم التّطابق ثنائي اللّغة (BiLingual Evaluation Understudy=BLEU) [23] ومعيار تقييم جودة النّصوص التّوليديّة (Recall-Oriented Understudy for Gisting Evaluation=ROUGE) [18].
إنّ إسهامات هذا البحث هي كالتّالي:
- بنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (ViMETA).
- توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (Ar-CM-ViMETA).
وهيكل هذه الورقة هو كما يلي: في القسم (2)، تمّ مناقشة الأعمال ذات الصّلة، تمّ تقديم النّموذج المقترح في القسم (3)، تمّ تقديم العمل التّجريبي والنّتائج في القسم (4) وتمّ الإنتهاء من العمل المقترح في القسم (5).
2. الأعمال ذات الصّلة (Related Works)
تُمثّل أحدث التّطوّرات والتّقنيات في مهام توصيف الصّورة من خلال الأساليب والمناهج القائمة على الاهتمام (attention-based approaches) [22]. حيث تمّ استخدام طرق الاهتمام لأوّل مرّةٍ في مشكلة التّرجمة الآليّة (machine translation) [4]. وبناءً على النّتائج المحسّنة بشكلٍ واضحٍ في مهمّة التّرجمة الآليّة، تمّ استخدام طرق الاهتمام لاحقًا في مهمّة التّوصيف (captioning task) بالإضافة إلى العديد من المهام الأخرى مثل تصنيف سرطان الثّدي (breast cancer classification) [5]. تركّز طرق الاهتمام على الأجزاء الرّئيسيّة والسّمات المفيدة للصّورة ثمّ تستفيد من هذه المعلومات من أجل تحديد المكان الّذي يجب التّركيز عليه بعد ذلك في أثناء إنتاج التّوصيف المناسب. تمّ إنشاء العديد من الطّرق المعتمدة على الاهتمام من أجل تحسين جودة الأوصاف النّهائيّة.
استنادًا إلى الأدبيّات الّتي قدّمها عثمان وآخرون [22]، فإنّ فئات الاهتمام (attention categories) الأساسيّة والّتي حقّقت تحسّنًا كبيرًا في مجال توصيف الصّورة هي الاهتمام الموجّه (guided-attention) والطّرق المعتمدة على المحوّل (transformer-based methods). قد تسترشد مهمّة توصيف الصّورة إمّا بالمعلومات المستمدّة من النّصوص أو بالمعلومات المستمدّة من سمات الصّور. وغالبًا ما يتمّ توجيه مهمّة توصيف الصّورة من خلال تقنيّات نمذجة الموضوع [6, 30]. تمّ إنشاء نمذجة الموضوع للبيانات المعتمدة على النّصّ من أجل استخراج المتغيّرات الكامنة في مجموعة بياناتٍ ضخمة.
في الآونة الأخيرة، تمّ توجيه توصيف الصّور باستخدام تقنيّة نمذجة المفهوم من أجل التقاط المعلومات الدّلاليّة (semantic information) المضمّنة في الصّورة. حيث تمّ استخدام هذه التّقنيّة من أجل استخراج مجموعةٍ من متّجهات المفاهيم (concept vectors) بالإضافة إلى تضمينات الصّورة (image’s embeddings). وبعد ذلك يتمّ إرسال مخرجات تقنيّة نمذجة المفهوم إلى بنية محوّلٍ متعدّد المرمّزات لإنتاج توصيف الخرج.
تمّ تطوير بنى المحوّلات متعدّدة التّرميز للمهام القائمة على النّصّ [20, 25, 26, 27]. حيث تمّ اقتراحها من أجل مهمّة التّعديل التّلقائي اللّاحقة بحيث تمّ تعديل المحوّل ليشمل اثنين من المرمّزات (encoders) [26]. يمثّل المرمّز الأوّل جملة التّرجمة الآليّة (mt) في حين يمثّل المرمّز الآخر جملة المصدر (src). وأيضًا تمّ تعديل فاكّ ترميز المحوّل (transformer decoder) في [26] بحيث يتمّ تضمين ثلاث طبقاتٍ من الاهتمام المتقاطع (cross-attention).
إنّ بنية المرمّزات الخاصّة بالمحوّل متعدّد المرمزّات، والّتي تمّ اقتراحها سابقًا، مطابقةٌ تمامًا لبنية المرمّزات الخاصّة بالمحوّل القياسي. حيث أنّ هذه البنى تعمل بشكلٍ جيّدٍ مع بيانات النّصوص ولكنّها تحتاج إلى التّحديث لتعمل بشكلٍ جيّدٍ مع الصّور. ولهذا الغرض، تمّ اقتراح بنية محوّل متعدّد التّرميز جديدة في هذه الورقة من خلال تحديث بنية المرمّز ليكون لها ذات بنية مرمّز محوّل الرّؤية (Vision Transformer Encoder) [7].
بالنّسبة لتوصيفات الصّور باللّغة العربية (AIC)، قام المزيني وآخرون [2] ببناء مجموعة بياناتٍ عربيّةٍ تعتمد على مجموعات بيانات كوكو (MS COCO) [19] وفليكر (Flickr8k) [12]. بالإضافة إلى ذلك، استخدموا نموذج دمج لإنتاج الأوصاف باستخدام شبكات الطّيّ العصبونيّة (CNN) والشّبكات العصبونيّة الإرجاعيّة (RNN) وهي الشّبكة العصبونيّة ذات الذّاكرة الطّويلة قصيرة المدى (LSTM).
تمّ استخدام نظام التّرجمة الذّكية بواسطة معلّا والخيّر [21] من أجل إنتاج أوصافٍ عربيّةٍ. حيث يتمّ استخدام شبكة (CNN) لاستخراج السّمات (feature extraction) ليتمّ بعد ذلك إرسال هذه السّمات المستخرجة بالإضافة إلى الأوصاف المترجمة إلى شبكة (LSTM). لاحظ المؤلّفون بأنّ مجرّد ترجمة الأوصاف من الإنجليزيّة إلى العربيّة ليست فكرةً جيّدةً بسبب البنية السّيئة للجمل العربيّة النّاتجة (generated arabic sentences).
استخدم جندل [15] تأثير كلمة الجذر القويّة للّغة العربيّة لبناء كلمات الجذر باستخدام الصّور بدلًا من الأوصاف حيث يتمّ استخدام شبكة (CNN) لاستخراج مجموعةٍ من كلمات الجذر (root words). وبعد ذلك يتمّ تحويل كلمات الجذر إلى تصريفاتٍ مورفولوجيّةٍ (morphological inflections) ثمّ يتمّ التّحقّق من ترتيب الكلمات في البيان بواسطة شجرة التّبعيّة (dependency tree). تشير النّتائج إلى أنّ إنتاج أوصافٍ باللّغة العربيّة بخطوةٍ واحدةٍ بدلًا من ترجمة الأوصاف باللّغة الإنجليزيّة إلى العربيّة بخطوتين أعطى نتائج أفضل.
قام الجندي وآخرون [8] ببناء بياناتٍ مترجمةٍ للّغة العربيّة لأوصاف مجموعة البيانات فليكر (Flickr8k) وجعلها عامّة. كما قام المؤلّفون ببناء نهجٍ شاملٍ يحوّل الصّور إلى جملٍ عربيّةٍ وقارنوها مع نهجٍ أساسيٍّ للتّوصيف العربيّ يعتمد على ترجمة النّصوص من أوصاف الصّور الإنجليزيّة. حقّق نموذجهم المقترح (33.2, 19.3, 10.5, 5.7) الموافقة لمعايير (BLEU1, BLEU2, BLEU3, BLEU4) والّتي هي معيار تقييم التّطابق ثنائي اللّغة المعتمد على الكلمات المفردة وأزواج وثلاثيّات ورباعيّات الكلمات على التّوالي [8].
لم تستخدم أي من الأعمال المذكورة سابقًا الاهتمام (attention) أو المحوّل (transformer) في نموذج توصيف الصّورة باللّغة العربيّة (AIC) حيث قدّم إمامي وآخرون [9] نموذج توصيفٍ قائمٍ على المحوّل. استخدم المؤلّفون شبكة (CNN) لاستخراج السّمات ثمّ تمّ استخدام محوّلٍ ثنائي الاتّجاه مدرّبٍ مسبقًا (pre-trained bidirectional transformer) كنموذجٍ لغويٍّ لتوليد كلمات التّوصيف. وحقّق نموذجهم المقترح أرابيرت (AraBERT32) قيمًا (39.1, 24.6, 15.0, 9.2, 33.1) لمعايير (BLEU1, BLEU2, BLEU3, BLEU4 and ROUGE) والّتي هي معيار تقييم التّطابق ثنائي اللّغة المعتمد على الكلمات المفردة وأزواج وثلاثيّات ورباعيّات الكلمات ومعيار تقييم جودة النّصوص التّوليديّة على التّوالي.
في هذا العمل البحثيّ، تمّ اقتراح نموذج توصيفٍ للصّورة قائمٍ على المفهوم (concept-based image captioning model) من أجل توصيف الصّور باللّغة العربيّة (AIC). كما وتمّ اقتراح بنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (ViMETA) كنموذجٍ لغويٍّ من أجل إنتاج وصف الصّورة بالنّظر إلى تقنيّة نمذجة المفهوم (concept modeling technique).
3. اقتراح توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (Proposed Arabic Image Captioning based on Concept Model and Vision-based Multi-Encoder Transformer Architecture)
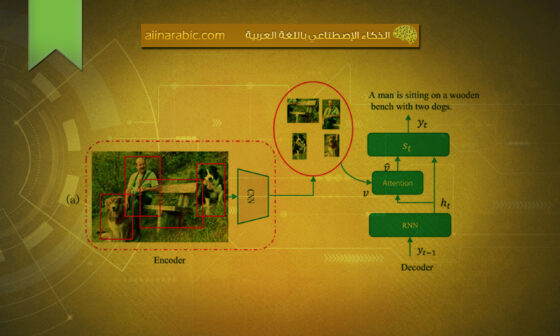
يتمّ تقديم نموذج توصيف الصّور باللّغة العربيّة (AIC) المقترح القائم على نموذج المفهوم ونموذج بنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية (ViMETA) في الشّكل (1). يبدأ نموذج (Ar-CM-ViMETA) المقترح_ والّذي يعبّر عن توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية_ من خلال تطبيق تقنيّة نمذجة المفهوم على الصّور المدخلة والأوصاف العربيّة الموافقة.
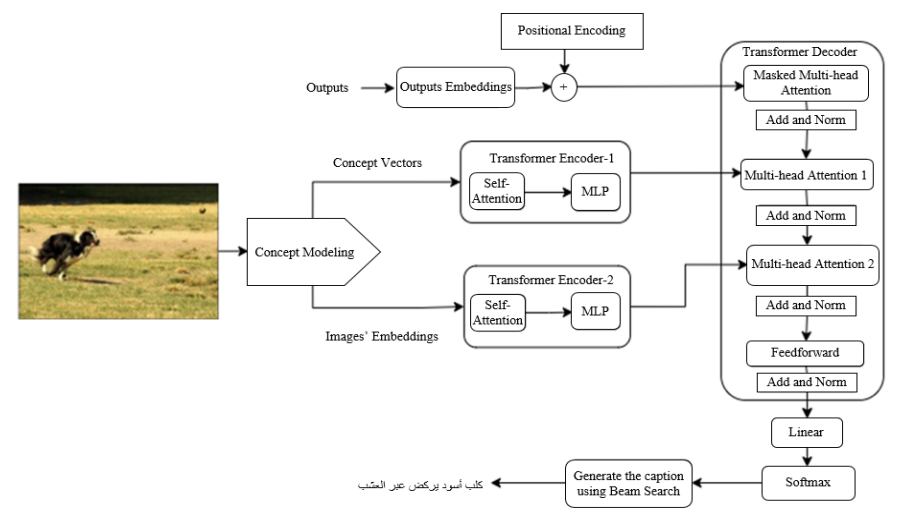
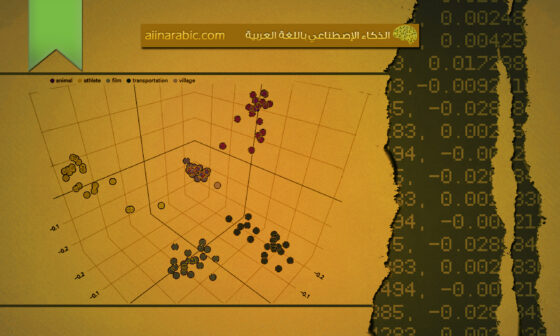
تظهر المفاهيم (concepts) النّاتجة بعد تطبيق تقنيّة نمذجة المفهوم على الأوصاف العربيّة الخاصّة بمجموعة البيانات فليكر (Flickr8k) [9] في الشّكل (2). حيث أنّ مخرجات هذه التّقنيّة تتلخّص بمجموعةٍ من متّجهات المفاهيم (concept vectors) بالإضافة إلى تضمينات (embeddings) الصّورة بواسطة نموذج كليب (CLIP). كلّ متّجه مفهوم يتوافق مع صورةٍ ما لديه طول يساوي عدد المفاهيم (concepts). يمثّل هذا المتّجه توزيع المفاهيم (concept distribution) للصّورة المقابلة. ثمّ يتمّ إرسال مخرجات تقنيّة نمذجة المفهوم إلى فاكّ التّرميز (decoder) من أجل إنتاج كلمات التّوصيف.

من أجل غرض إنتاج تعليقاتٍ توضيحيّةٍ أكثر تعبيرًا وبتعقيدٍ حسابيٍّ أقل، يتمّ استخدام المحوّل (transformer) في هذا العمل البحثيّ نظرًا لقدرته على تجاوز التّكرار وتصميمه المتوازي. يتضمّن المحوّل القياسي (standard transformer) مرمّزًا واحدًا للتّعامل مع سمات صورة الدّخل بالإضافة لفاكّ ترميزٍ واحدٍ لإنتاج توصيف الخرج بالاعتماد على السّمات المرمّزة (encoded features) والأوصاف الجزئيّة.
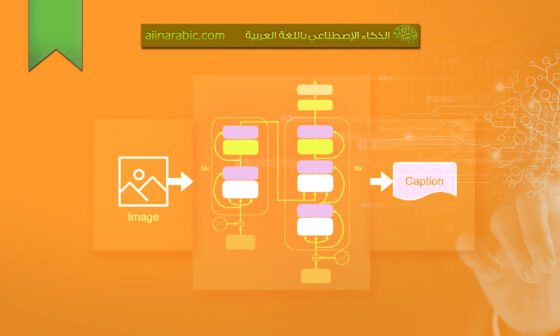
في هذه الورقة، تمّ اقتراح تعديل المحوّل التّقليدي من خلال الحصول على بنيةٍ متعدّدة المرمّزات (multi-encoder) من أجل تمثيل متّجهات المفهوم في عمليّة التّوصيف. لذلك، تّم اقتراح بنية محوّلٍ جديدة من خلال تغيير المحوّل التّقليدي ليكون به مرمّزات متعدّدة، سيرمّز لعددها في المعادلات بالحرف (M). بالإضافة إلى ذلك، تمّت إضافة طبقة اهتمام المرّمز-فاكّ التّرميز (encoder-decoder attention layer) لكلٍّ من المرمّزات المضافة، أي عدد المرمّزات يساوي عدد طبقات اهتمام المرمّز-فاكّ التّرميز وسوف يستخدم نفس الحرف للتّرميز (M). ويظهر نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) المقترح في الشّكل (3).
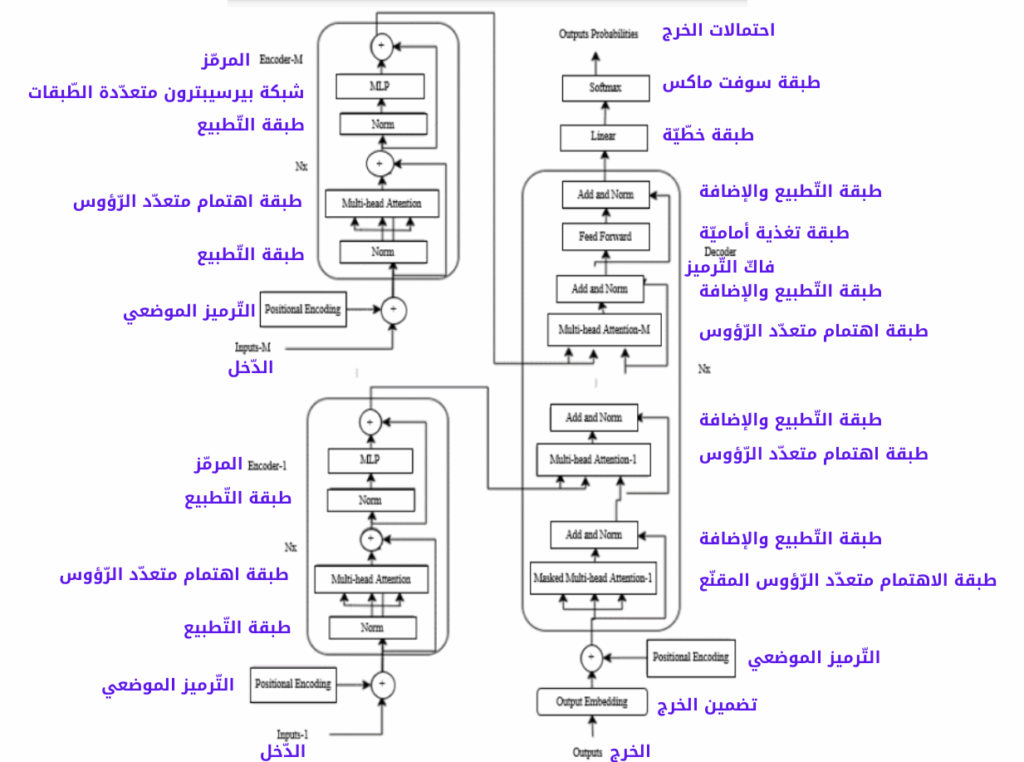
إنّ المرمّزات المستخدمة في نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) مستوحاةٌ من بنية محوّل الرّؤية (Vision Transformer) [7] والّتي تمّ تصميمها خصّيصًا لمهام الرّؤية الحاسوبيّة (CV). يتضمّن مرمّز محوّل الرّؤية على وحدة الاهتمام الذّاتي (self-attention) ووحدة بيرسيبترون متعدّدة الطّبقات (Multi-layer Perceptron=MLP). بالإضافة إلى ذلك، يتمّ استخدام تسوية الطّبقة (layernorm) قبل كلّ وحدةٍ والوصلات المختصرة (residual connections) بعد كلّ وحدةٍ.
في هذه الورقة، يتضمّن تصميم نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) المقترح كحالةٍ خاصّةٍ هنا على مرمّزين ويتمّ تضمين طبقتي اهتمام المرمّز-فاكّ التّرميز في فاكّ التّرميز (decoder). تمّ تجهيز المرمّز الأوّل بوحدة اهتمامٍ ذاتيٍّ (self-attention)، والّتي تستمدّ مدخلاتها وهي الاستعلام (Query Q)، المفاتيح (Keys K) والقيم (values V) من متّجه المفاهيم، حيث تأتي كتلة (MLP) بعد ذلك المتمثّلة بشبكة بيرسيبترون متعدّدة الطّبقات. تتضمّن هذه الكتلة على طبقتين مع وحدات خطأ خطّيّة غاوسيّة (Gaussian Error Linear Units=GELU) غير خطّيّة. وبالنّسبة للمرمّز الثّاني أيضًا تمّ تجهيزه بوحدة اهتمامٍ ذاتيٍّ، والّتي تستمدّ مدخلاتها وهي الاستعلام (Query Q)، المفاتيح (Keys K) والقيم (values V) من متّجه سمات الصّورة، كما وتأتي كتلة (MLP) أيضًا بعد ذلك والّتي هي شبكة بيرسيبترون متعدّدة الطّبقات.
بالنّسبة لنموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) المقترح، يتمّ تغذية متّجهات المفاهيم المستمدّة من تقنيّة نمذجة المفهوم إلى المرمّز الأوّل الخاصّ بنموذج (ViMETA) المقترح، في حين يتمّ تغذية تضمينات الصّورة المتشكّلة بنموذج كليب (CLIP) إلى المرمّز الثّاني الخاصّ بنموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA). بعد ذلك، يتمّ تغذية مخرجات المرمّزين إلى فاكّ ترميز نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) المقترح من أجل إنتاج الوصف كلمة بكلمة بالاعتماد على المدخلات المرمّزة وتضمينات (embeddings) الأوصاف. حيث يتمّ تمرير مخرجات المرمّز الأوّل إلى وحدة الاهتمام متعّددة الرّؤوس (multi-head attention) الأولى لفاكّ التّرميز، في حين يتمّ تمرير مخرجات المرمّز الثّاني إلى وحدة الاهتمام متعدّدة الرّؤوس الثّانية لفاكّ التّرميز (decoder).
4. العمل التّجريبي والنّتائج (Experimental Work and Results)
في هذه الورقة، تمّ استخدام مجموعة البيانات فليكر (Flickr8k) [12] مع أوصافٍ باللّغة العربيّة، والّتي نشرها الجندي وآخرون [8]، من أجل تقييم أداء النّموذج المقترح. تتضمّن مجموعة البيانات العربيّة فليكر (Flickr8k) على (8000) صورةٍ. تحتوي كلّ صورةٍ على (3) أوصافٍ باللّغة العربيّة مترجمةٌ من الأوصاف باللّغة الإنجليزيّة بواسطة ترجمة واجهة برمجة تطبيقات جوجل (google API translation)، ثمّ تمّ التّحقّق من صحّة الأوصاف المترجمة من خلال المتخصّصين في التّرجمة العربيّة.
نتبع الإرشادات الخاصّة بالمعالجة المسبقة (preprocessing) للنّصوص العربيّة، والّتي تتضمّن إضافة مسافاتٍ بعد حرف “و”، إزالة أداة التّعريف “ال”، إزالة علامات التّرقيم، إزالة الكلمات المكوّنة من حرفٍ واحدٍ وتطبيق التّقسيم على المسافات البيضاء. يبلغ عدد الكلمات في المفردات (vocabulary) بما في ذلك علامتي البداية (start) والنّهاية (end) حوالي (10435).
يتمّ إجراء التّدريب للنّموذج المقترح بغرض تقليل خسارة الإنتروبيا المتقاطعة (Cross Entropy Loss). ويتمّ حساب خسارة الإنتروبيا المتقاطعة على النّحو التّالي:
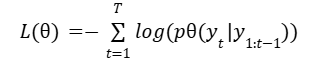
تمّ تعديل تقنيّة نمذجة المفهوم عن طريق تحديد نموذج تضمينٍ (embedding model) قادرٍ على العمل على أكثر من (50) لغةٍ، أي (clip-ViT-B-32-multilingual-v1) [14]، حيث كان عدد المفاهيم النّاتجة (28) مفهومًا. يبلغ بعد التّضمين (512) وعدد طبقات المحوّل والرّؤوس كان على التّوالي (3) و (8). يتمّ استخدام محسّن آدم [16] بمعدّل تعلّم 2e(-5). يتمّ تشغيل تدريب النّماذج حوالي (20) دورةٍ تدريبيّةٍ. يتمّ استخدام البحث الشّعاعي (beam search) في مرحلة الاختبار بحيث حجم الشّعاع هو (2).
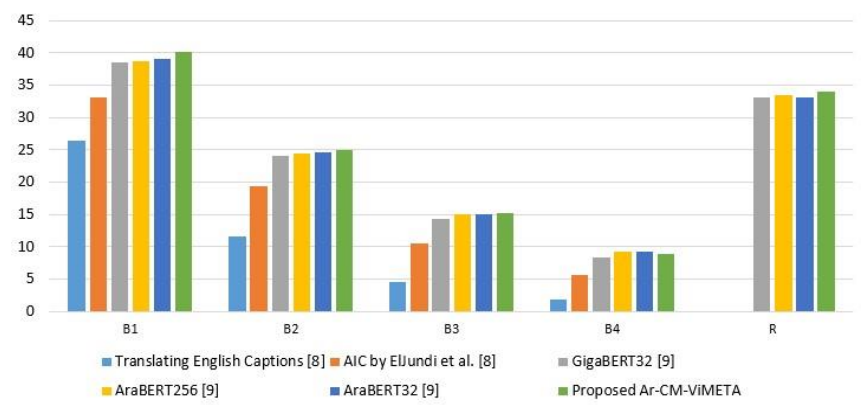
تمّ الحصول على النّتائج الكميّة (quantitative results) باستخدام معايير تقييم التّطابق ثنائي اللّغة بإصداراتها الأربعة (BLEU1, BLEU2, BLEU3, BLEU4) [23] ومعيار تقييم جودة النّصوص التّوليديّة (ROUGE) [18]. حيث يقارن الجدول (1) النّتائج الكميّة للتّقنيّات الحديثة والنّتائج الكميّة لنموذج (Ar-CM-ViMETA) المقترح. ويتضمّن الجدول نتائج الأوصاف الإنجليزيّة المترجمة إلى العربيّة والمقدّمة من قبل الجندي وآخرون [8]. كما وتمّ تضمين نهج التّوصيف باللّغة العربيّة المقترح من قبل الجندي وآخرون [8].بالإضافة إلى ذلك، تمّ تضمين (3) نماذج أخرى اقترحها إمامي وآخرون [9] في الجدول والّتي استخدمت نموذجي أرابيرت (AraBERT) [3] وجيغابيرت (GigaBERT) [17] بأحجام دفعاتٍ (batch sizes) مختلفةٍ.
تشير النّتائج المقدّمة في الجدول (1) والشّكل (4) إلى أنّ نموذج (Ar-CM-ViMETA) المقترح_ المعبّر عن توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية_ يتفوّق على الطّرق والأساليب الحديثة فيما يتعلّق بمقاييس التّقييم (B1, B2, B3, R).
يتضمّن الجدول (2) النّتائج النّوعيّة (qualitative results) لنموذج (Ar-CM-ViMETA) المقترح. حيث يظهر النّموذج (Ar-CM-ViMETA) المقترح_ المعبّر عن توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية_ أوصافًا أفضل وأكثر تعبيرًا بالمقارنة مع الأوصاف المرجعيّة. لقد أنتج هذا النّموذج المقترح أوصافًا لصور الكلب، الطّفل الّذي يرتدي سترةً حمراء والرّجل العجوز والّتي كانت أكثر دقّة وتعبير من الأوصاف الحقيقيّة. بالإضافة إلى ذلك، كان النّموذج قادرًا على بناء جملةٍ عربيّةٍ أفضل من الوصف الحقيقيّ من خلال شرح أنّ الرّجل في الصّورة الثّانية “يرتدي” القميص الأحمر. وبالتّالي تؤدي الطّريقة المقترحة إلى تشكيل تسمياتٍ توضيحيّةٍ أفضل مقارنةً بالأعمال ذات الصّلة بسبب الدّلالات (semantics) الغنيّة المضمّنة في متّجهات المفاهيم (concept vectors).
إنّ نموذج (Ar-CM-ViMETA) المقترح_ المعبّر عن توصيف الصّور باللّغة العربيّة بالاعتماد على نموذج المفهوم وبنية محوّلٍ متعدّد المرمّزات قائمٍ على الرّؤية_ يتفوّق على الأعمال ذات الصّلة نتيجة دمج تقنيّة نمذجة المفهوم والّتي تتمتّع بالقدرة على التقاط سياقات الصّورة (image contexts). وهذه السّياقات تمّ ترميزها باستخدام نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) المقترح وتمّ تغذيتها لفاكّ التّرميز مع سمات الصّورة لأخذها بعين الاعتبار أثناء التّنبؤ بتوصيف الصّورة. تشير النّتائج الجيدة إلى قدرة النّموذج المقترح على أن يكون فعّالًا ومعبّرًا من حيث الأوصاف المنتجة.
5. الخاتمة (Conclusions)
في هذه الورقة، تمّ اقتراح نموذجٍ جديدٍ قائمٍ على المفهوم (concept) من أجل نموذج (AIC). حيث يتمّ تطبيق تقنيّة نمذجة المفهوم من أجل استخراج مجموعةٍ من متّجهات المفاهيم وتضمينات الصّور. وتمّ اقتراح أيضًا نموذج بنية محوّلٍ متعدّد المرمّزات (ViMETA) الجديد للتّعامل مع المخرجات المتعدّدة لتقنيّة نمذجة المفهوم في أثناء توليد تعليق الصّورة. تمّت مقارنة النّموذج المقترح كمّيًّا مع أحدث التّقنيّات. وقد عزّز النّموذج المقترح النّتائج فيما يتعلّق بالمقاييس القياسيّة. بالإضافة إلى ذلك، تمّت مقارنة النّموذج المقترح نوعيًّا مع الأوصاف المرجعيّة الحقيقيّة حيث أنتج أوصافًا أكثر تعبيرًا. لوحظ أنّ النّموذج المقترح يستطيع أن يحقّق أداءً عالٍ في حالة تجربته على مجموعة بياناتٍ أكبر. وبالتّالي في الأبحاث المستقبليّة، يمكن توفير مجموعة بياناتٍ أكبر تحتوي على أوصافٍ باللّغة العربيّة للمستخدمين عامّةً، وهكذا يمكن تنفيذ تجارب إضافيّة للنّموذج المقترح باستخدام هذه المجموعة الأكبر من البيانات. بالإضافة إلى ذلك، قد تساعد المعالجة المسبقة (preprocessing) الإضافيّة للأوصاف العربيّة في تحقيق أداءٍ أفضل.
ملحقٌ خاصٌّ بالجداول
الجدول (1): مقارنةٌ بين نتائج التّقنيّات الحديثة ونموذج (Ar-CM-ViMETA) المقترح.
الجدول (2): النّتائج النّوعيّة لنموذج (Ar-CM-ViMETA) المقترح. عيّنةٌ من الأوصاف النّاتجة باستخدام نموذج (Ar-CM-ViMETA) المقترح مقارنةً بالأوصاف الحقيقيّة.

المراجع (References)
- Afyouni I., Azhar I., and Elnagar A., “AraCap: A Hybrid Deep Learning Architecture for Arabic Image Captioning,” Procedia Computer Science, vol. 189, pp. 382-389, 2021. https://doi.org/10.1016/j.procs.2021.05.108
- Al-Muzaini H., Al-Yahya T., and Benhidour H., “Automatic Arabic Image Captioning Using RNN-LSTM-based Language Model and CNN,” International Journal of Advanced Computer Science and Applications, vol. 9, no. 6, pp. 67-73, 2018. DOI:10.14569/IJACSA.2018.090610
- Antoun W., Baly F., and Hajj H., “AraBERT: Transformer-based Model for Arabic Language Understanding,” in Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, pp. 9-15, 2020. https://aclanthology.org/2020.osact-1.2
- Bahdanau D., Cho K., and Bengio Y., “Neural Machine Translation by Jointly Learning to Align and Translate,” arXiv Preprint, vol. arXiv:1409.0473, pp. 1-16, 2014. https://doi.org/10.48550/arXiv.1409.0473
- Bangalore M., Bharathi S., and Ashwin M., “Classification of Breast Cancer using Ensemble Filter Feature Selection with Triplet Attention Based Efficient Net Classifier,” The International Arab Journal of Information Technology, vol. 21, no. 1, pp. 17-31, 2024. DOI: 10.34028/iajit/21/1/2
- Dash S., Acharya S., Pakray P., Das R., and Gelbukh A., “Topic-based Image Caption Generation,” Arabian Journal for Science and Engineering, vol. 45, no. 4, pp. 3025-3034, 2020. https://link.springer.com/article/10.1007/s13369- 019-04262-2
- Dosovitskiy A., Beyer L., Kolesnikov A., Weissenborn D., Zhai X., Unterthiner T., and Dehghani M., “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” in Proceedings of the 9th International Conference on Learning Representations, Austria, pp. 1-21, 2021. https://openreview.net/forum?id=YicbFdNTTy
- ElJundi O., Dhaybi M., Mokadam K., Hajj H., and Asmar D., “Resources and End-to-End Neural Network Models for Arabic image Captioning,” in Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, SciTePress, Valletta, pp. 233-241, 2020. DOI:10.5220/0008881202330241
- Emami J., Nugues P., Elnagar A., and Afyouni I., “Arabic Image Captioning using Pre-training of Deep Bidirectional Transformers,” in Proceedings of the 15th International Conference on Natural Language Generation, Waterville, pp. 40-51, 2022. https://aclanthology.org/2022.inlg-main
- Grootendorst M., “BERTopic: Neural Topic Modeling with a Class-based TF-IDF Procedure,” arXiv Preprint, vol. arXiv:2203.05794, pp. 1-10, 2022. http://arxiv.org/abs/2203.05794
- Grootendorst M., https://github.com/MaartenGr/Concept, Last Visited, 2024.
- Hodosh M., Young P., and Hockenmaier J., “Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics,” Journal of Artificial Intelligence Research, vol. 47, pp. 853- 899, 2013. https://doi.org/10.1613/jair.3994
- Hossain M., Sohel F., Shiratuddin M., and Laga H., “A Comprehensive Survey of Deep Learning for Image Captioning,” ACM Computing Surveys, vol. 51, no. 6, pp. 1-36, 2019. https://doi.org/10.1145/3295748
- HuggingFace, https://huggingface.co/sentencetransformers/clip-ViT-B-32-multilingual-v1, Last Visited, 2024.
- Jindal V., “Generating Image Captions in Arabic Using Root-Word Based Recurrent Neural Networks and Deep Neural Networks,” in Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, New Orleans, pp. 144-151, 2018. https://aclanthology.org/N18-4020
- Kingma D. and Ba J., “Adam: A Method for Stochastic Optimization,” in Proceedings of the International Conference on Learning Representations, San Diego, pp. 1-15, 2016. https://doi.org/10.48550/arXiv.1412.6980
- Lan W., Chen Y., Xu W., and Ritter A., “An Empirical Study of Pre-trained Transformers for Arabic Information Extraction,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing, Maine, pp. 4727-4734, 2020. https://aclanthology.org/2020.emnlp-main.382
- Lin C., “ROUGE: A Package for Automatic Evaluation of Summaries,” in Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, pp. 74-81, 2004. https://typeset.io/papers/rouge-a-package-forautomatic-evaluation-of-summaries-2tymbd14i8
- Lin T., Maire M., Belongie S., Hays J., Perona P., Ramanan D., Dollar P., and Zitnick C., “LNCS 8693-Microsoft COCO: Common Objects in Context,” in Proceedings of the Computer VisionECCV 13th European Conference, Zurich, pp. 740- 755, 2014. https://doi.org/10.1007/978-3-319- 10602-1_48
- Littell P., Lo C., Larkin S., and Stewart D., “MultiSource Transformer for Kazakh-Russian-English Neural Machine Translation,” in Proceedings of the 4th Conference on Machine Translation, Florence, pp. 267-274, 2019. https://aclanthology.org/W19-5326
- Mualla R. and Alkheir J., “Development of an Arabic Image Description System,” International Journal of Computer Science Trends and Technology, vol. 6, no. 3, pp. 205-213, 2018. https://www.ijcstjournal.org/volume-6/issue3/IJCST-V6I3P27.pdf
- Osman A., Shalaby M., Soliman M., and Elsayed K., “A Survey on Attention-based Models for Image Captioning,” International Journal of Advanced Computer Science and Applications, vol. 14, no. 2, pp. 403-412, 2023. DOI:10.14569/IJACSA.2023.0140249
- Papineni K., Roukos S., Ward T., and Zhu W., “BLEU: A Method for Automatic Evaluation of Machine Translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, pp. 311- 318, 2002. https://aclanthology.org/P02-1040.pdf
- Radford A., Kim J., Hallacy C., Ramesh A., Goh G., Agarwal S., Sastry G., Askell A., Mishkin P., Clark J., Krueger G., and Sutskever I., “Learning Transferable Visual Models from Natural Language Supervision,” in Proceedings of the 38th International Conference on Machine Learning, Virtual, pp. 8748-8763, 2021. http://arxiv.org/abs/2103.00020
- Rikters M. and Nakazawa T., “Revisiting Context Choices for Context-aware Machine Translation,” arXiv Preprint, vol. arXiv:2109.02995, pp. 1-6, 2021. https://doi.org/10.48550/arXiv.2109.02995
- Shin J. and Lee J., “Multi-Encoder Transformer Network for Automatic Post-Editing,” in Proceedings of the 3rd Conference on Machine Translation: Shared Task Papers, Brussels, pp. 840-845, 2018. https://www.statmt.org/wmt18/pdf/WMT098.pdf
- Shin Y., “Multi-Encoder Transformer for Korean Abstractive Text Summarization,” IEEE Access, vol. 11, pp. 48768-48782, 2023. DOI:10.1109/ACCESS.2023.3277754
- Stefanini M., Cornia M., Baraldi L., Cascianelli S., Fiameni G., and Cucchiara R., “From Show to Tell: A Survey on Deep Learning-based Image Captioning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 539-559, 2023. DOI:10.1109/TPAMI.2022.3148210
- Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A., and Kaiser L., “Attention is all you Need,” in Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, pp. 6000-6010, 2017. https://dl.acm.org/doi/10.5555/3295222.3295349
- Zhu Z., Xue Z., and Yuan Z., “Topic-Guided Attention for Image Captioning,” in Proceedings of the 25th IEEE International Conference on Image Processing, Athens, pp. 2615-2619, 2018. DOI:10.1109/ICIP.2018.8451083
تعليقان
اريد التواصل معكم لان عندى نفس التاسك وهو توصيف الصور باللغه العربيه هل هناك اى طريقة تواصل ؟.
يمكنك التواصل مع الكاتب عن طريق الإيميل. يمكنك الوصول إلى الإيميل من صفحة من نحن