التدقيق العلمي: م. رامي عقــاد، م. محمد سرميني
التدقيق اللغوي: هبة الله فلّاحة
المحتويات
- المقدّمة
- التعرّف على إطار البيانات في بانداس Pandas وأشهر العمليّات عليها
-
- إنشاء إطار بيانات في بانداس.
- الوصول إلى بيانات سطر أو عمود ضمن إطار البيانات.
- إضافة دليل البيانات أو سطر أو عمود إلى إطار البيانات.
- حذف أسطر أو أعمدة من إطار البيانات.
- التعرّف على بيانات الزّمن ضمن مجموعة البيانات.
- تقنيّات هندسة المزايا
-
- المزايا المُتعلّقة بالتّاريخ Date-Related Features
- المزايا المُتعلّقة بالوقت Time-Related Features
- المزايا المتأخّرة Lag Features
- مزايا النّافذة المنزلقة Rolling Window Feature
- مزايا النّافذة الموسّعة Expanding Window Feature
- المزايا الخاصّة بمجال التطبيق Domain-Specific Features
- الخاتمة
المقدّمة
وفقًا لويكيبيديا، فإنّه يتمّ تعريف هندسة المزايا Feature Engineering على أنّها العمليّة التي يستخدم فيها خبير البيانات خبراته لاستخراج أهمّ المزايا ذات الارتباط الشّديد بالموضوع الذي يعمل عليه، حيث تستخرج هذه المزايا ويتمّ إنشاؤها من مجموعة البيانات الخام Raw Dataset، ومن شأنها أن تحسّن من أداء خوارزميّات تعلّم الآلة بشكل كبير جدًّا. على الرّغم من أهميّة هذه المزايا وإسهامها الكبير في تحسين الأداء، إلّا أنّ الغالبيّة تغفل عن استخدامها وإعطائها الأهميّة التي تستحقّها. تعتبر هندسة المزايا خطوة من خطوات المعالجة المسبقة للبيانات، حيث يتمّ فيها تحضير مجموعة المزايا و التأكّد من صلتها بمتغيّر الهدف Variable Target. يجب على كلّ مختصّ في علوم البيانات معرفة هذه التقنيّات وكيفيّة إجرائها و التّعامل معها، وعلى وجه التّحديد في بيانات السّلاسل الزّمنيّة نظرًا لأهميّتها وإسهامها في تحسين نتائج تنبّؤات خوارزميّات تعلّم الآلة.
في هذا المقال، سوف نتحدّث عن أهمّ ستّ تقنيّات في هندسة المزايا يتمّ استخدامها في بيانات السّلاسل الزّمنيّة، لكن قبل الحديث عن هذه التّقنيات سوف نقوم بالتعرّف على نوع من أنواع هياكل البيانات في مكتبة تحليل البيانات في بايثون (بانداس)، يدعى إطار البيانات Dataframe الذي يُعتبر الرّكيزة الأساسيّة التي سنعتمد عليها في تطبيق تقنيّات هندسة المزايا في بيانات السّلاسل الزّمنيّة.
عزيزي القارئ، في حال كان لديك الفهم الكافي عن إطار البيانات في بانداس، بإمكانك تخطّي القسم الخاصّ بإطار البيانات والبدء مباشرة بقراءة القسم المتعلّق بهندسة المزايا.
التعرّف على إطار البيانات في بانداس وأشهر العمليّات عليها
ما هو إطار البيانات في بانداس؟ هو عبارة عن بنية بيانات جدوليّة ثنائيّة البعد قابلة للتّعديل، تنظّم البيانات في جدول ثنائيّ البعد مع محاور معنونة (صفوف وأعمدة)، وتعدّ من أحد أكثر هياكل البيانات شهرة في عالم البيانات، نظرًا لمرونتها وسهولة التّعامل معها بالإضافة إلى إمكانيّة التّعديل عليها.
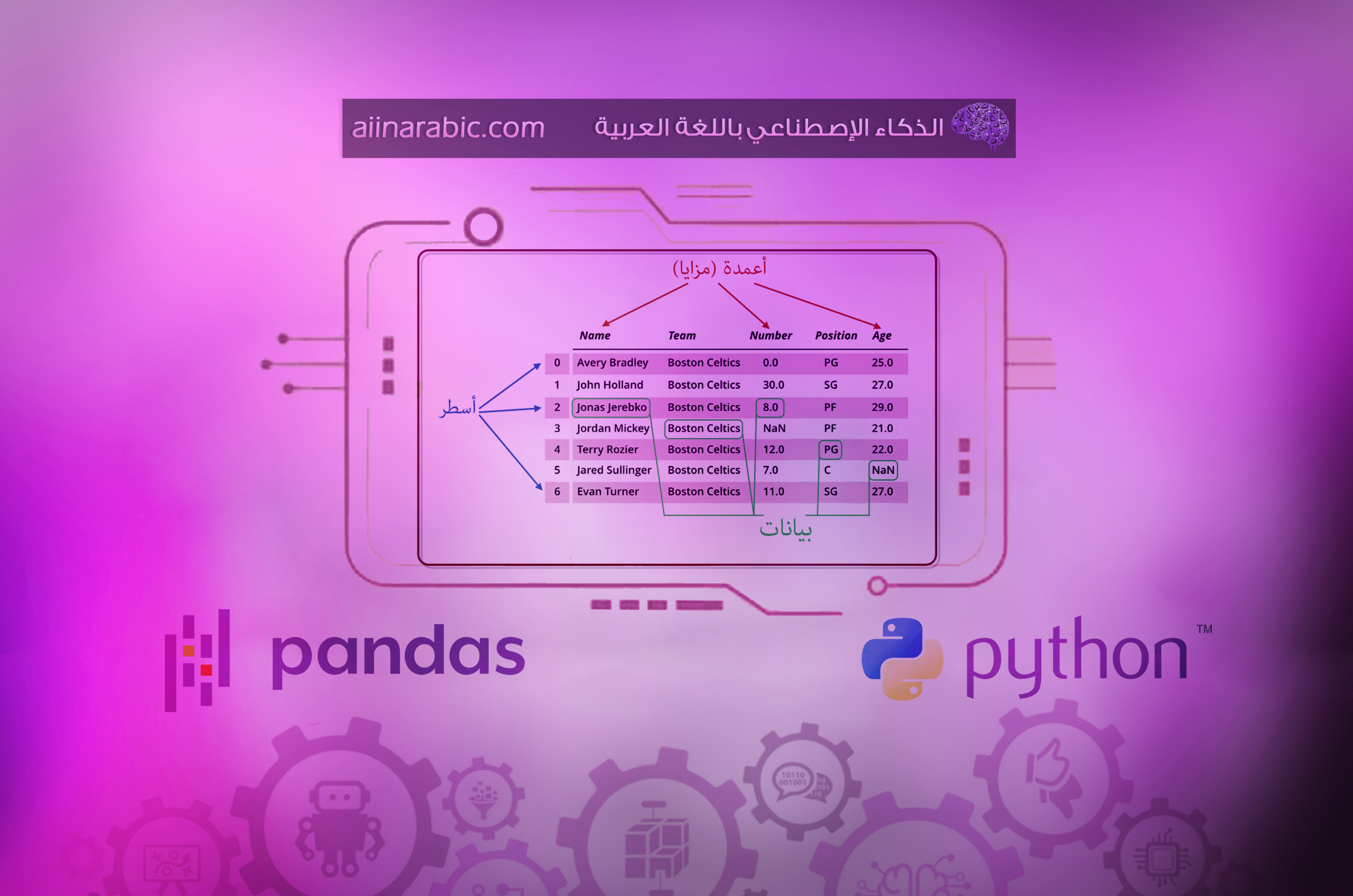
يتألّف إطار البيانات في بانداس من ثلاثة مكوّنات رئيسيّة هي: البيانات والصّفوف والأعمدة كما يوضّح الشّكل 1.
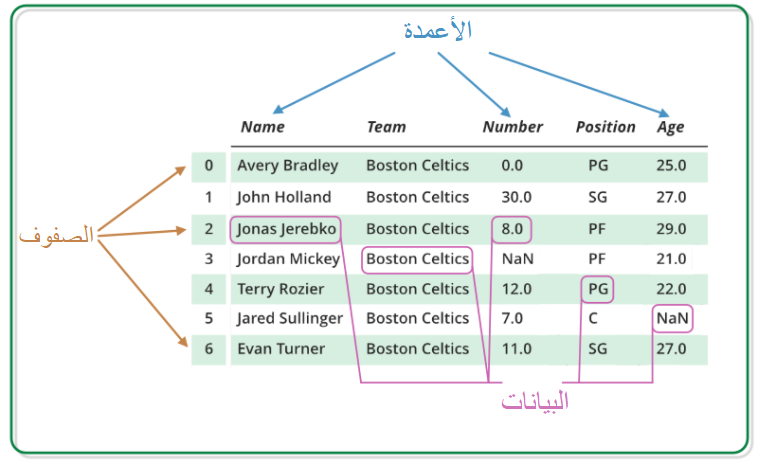
نلاحظ من الشّكل 1 العنونة المستخدمة لكلّ من الصّفوف والأعمدة، حيث تمّت عنونة الصّفوف بالأرقام من 0 إلى 6 بينما تمّت عنونة الأعمدة بالكلمات النّصيّة “Name” و “Team” و “Number” و “Position” و “Age”. هنا تمّت عنونة الأعمدة بكلمات نصّيّة، على خلاف المصفوفات الرّياضيّة التي لا تقبل سوى أعدادًا رقميّة في عنونة كلٍّ من الأسطر والأعمدة.
توضيح: فيما يتعلّق بعنونة الأسطر أو الأعمدة في إطار البيانات، من الممكن عنونتها باستخدام القيم التي نرغب بها سواء أعدادًا رقميّة أو أحرفًا أو كلماتٍ نصيّة.
الآن سوف نلقي نظرة على العمليّات الأساسيّة التي يمكن إجراؤها على إطار البيانات في بانداس و هي بالتّسلسل:
- إنشاء إطار بيانات في بانداس.
- الوصول إلى بيانات سطر أو عمود ضمن إطار البيانات.
- إضافة دليل البيانات أو سطر أو عمود إلى إطار البيانات.
- حذف أسطر أو أعمدة من إطار البيانات.
- التعرّف على بيانات الزّمن ضمن مجموعة البيانات.
أوّلًا: إنشاء إطار بيانات
من الطبيعيّ أن تكون عمليّة إنشاء إطار البيانات في بانداس هي أوّل عمليّة يجب التعرّف عليها، ولكن في الواقع ربّما لن تحتاج إلى هذه العمليّة كثيرًا، ففي الغالب سوف يتمّ استيراد إطار بيانات من بيانات مخزّنة على شكل قاعدة بيانات (كـ لغة الاستعلامات المهيكلة SQL)، أو ملفّ القيم المفصولة بفواصل csv أو ملفّ اكسل excel.
الآن دعنا نعود ونتعرّف على طرق إنشاء إطار بيانات في بانداس، فبالإمكان إنشاء إطار البيانات بواسطة قائمة list أو قاموس dictionary أو مصفوفة من نوع مكتبة بايثون العددية (نَمْباي) ndarray.. الخ.
الطريقة الأولى هي إنشاء إطار بيانات في بانداس بواسطة قائمة، حيث يتمُّ اتّباع الأسلوب التّالي:
في البداية علينا استدعاء مكتبة بانداس ومكتبة بايثون العدديَّة (نَمْباي).
الآن بعد استدعاء المكتبات، نستطيع إنشاء إطار البيانات في بانداس باستخدام الشّيفرة البرمجيّة التّالية:
List = [[1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(List, index=range(0,2), columns=['A', 'B', 'C'])
كما نلاحظ أعلاه، قمنا أوّلًا بتعريف قائمة باسم List، ثمّ تمرير هذه القائمة إلى التّابع pd.DataFrame الذي يتولّى مهمّة إنشاء إطار البيانات من القائمة المُمَرّرة له، كذلك قمنا بعنونة الأسطر بالأرقام من 0 إلى 2 وعنونة الأعمدة بالحروف A ، B ، C. يوضّح الشّكل 2 إطار البيانات الذي تمّ إنشاؤه بواسطة قائمة.
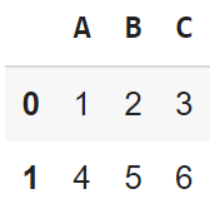
الطّريقة الثّانية هي إنشاء إطار بيانات بواسطة قاموس، حيث يتمّ إنشاء إطار البيانات في هذه الطّريقة بالأسلوب التّالي:
Dict = {"A": ['1', '300'], "B": ['1', '2'], "C": ['2', '4']}
df = pd.DataFrame(Dict)
كما نلاحظ أعلاه، قمنا أوّلًا بتعريف قاموس باسم Dict، ثمّ تمرير هذا القاموس إلى التّابع pd.DataFrame. يوضّح الشّكل 3 إطار البيانات الذي تمّ إنشاؤه بواسطة قاموس، كما نلاحظ أنّ مفاتيح القاموس Keys تمّ استخدامها لعنونة الأعمدة، بينما قيم القاموس Values هي بيانات إطار البيانات. فيما تمّت عنونة الأسطر بشكل تلقائيّ ابتداءً من القيمة 0.
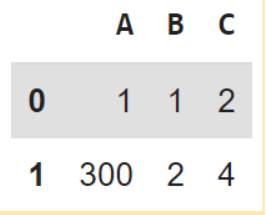
نستخدم التّابع df.index لمعرفة عناوين أسطر إطار البيانات، بينما نستخدم التّابع df.columns لمعرفة عناوين الأعمدة كما في الشّيفرة البرمجيّة التّالية:
df.index
df.columns
ثانيًا: الوصول إلى بيانات سطر أو عمود ضمن إطار البيانات
في البداية لنقم بإنشاء إطار بيانات باستخدام الشّيفرة البرمجيّة التّالية:
List = [[1, 2], [3, 4], [5, 6]]
df = pd.DataFrame(List, index=['A', 'B', 'C'], columns=["Ali","Omar"])
يكون إطار البيانات الموافق للشّيفرة البرمجيّة السّابقة بالشّكل التّالي (الشّكل 4):
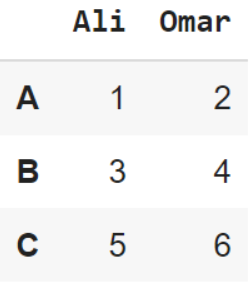
للوصول إلى بيانات أيّ سطر بإمكاننا استخدام التّابع iloc أو التّابع loc، على سبيل المثال بإمكاننا الوصول إلى بيانات السّطر “A” بواسطة الشّيفرة البرمجيّة التّالية:
# باستخدام التابع ‘iloc’
print(df.iloc[0,:])
#باستخدام التابع ‘loc’
print(df.loc["A",:])
إنَّ الفرق بين استخدام التّابعين السّابقين، هو أنّه مع التّابع iloc يتمّ الوصول إلى البيانات بواسطة موقعها في السّطر والعمود، (مشابه لطريقة الوصول إلى القيم في المصفوفة الرّياضيّة) بينما مع التّابع loc يتمّ الوصول إلى البيانات بواسطة تسمية السّطر والعمود (أي العناوين).
بالنسبة للوصول إلى بيانات الأعمدة، أيضًا بإمكاننا استخدام التّابع iloc أو التّابع loc، فمن أجل الوصول إلى بيانات أيّ عمود (على سبيل المثال العمود “Ali”) نقوم باستخدام الشّيفرة البرمجيّة التّالية:
# باستخدام التابع ‘iloc’
print(df.iloc[:,0])
# باستخدام التابع ‘loc’
print(df.loc[:,"Ali"])
بإمكاننا الوصول إلى البيانات الموجودة في تقاطع السّطر “A” مع العمود “Ali” أيضًا باستخدام إحدى التّابعين loc أو iloc بالشّكل التالي:
# باستخدام التابع ‘iloc’
print(df.iloc[0][0])
# باستخدام التابع ‘loc’
print(df.loc["A"]['Ali'])
ثالثًا: إضافة دليل بيانات أو سطر أو عمود إلى إطار البيانات
تعلمنا سابقًا كيفيّة الوصول إلى قيمة في إطار البيانات، الآن سوف نتعرّف على كيفيّة إضافة دليل أو سطر أو عمود إلى إطار البيانات في بانداس.
- إضافة دليل إلى إطار البيانات:
عندما نقوم بإنشاء إطار بيانات في بانداس باستخدام التّابع pd.DataFrame، لدينا خياران اثنان إمّا أن نقوم بتمرير دليل البيانات التي نرغب بها إلى بارامتر الفهرس Index الموجود ضمن التّابع من أجل عنونة البيانات في إطار البيانات، أو أن لا نعطي بارامتر الفهرس أي قيم دخل، وفي هذه الحالة سوف تتمّ عنونة البيانات بشكل تلقائيّ بواسطة قيم عدديّة، ابتداءً من القيمة 0 للسّطر الأوّل حتى آخر سطر في إطار البيانات.
على أيّة حال، في الحالة التي يكون فيها دليل البيانات محدّدًا بشكل افتراضيّ، يكن لدينا إمكانيّة لإعادة ضبط قيم دليل البيانات بالقيم التي نرغب بها وذلك باستخدام التّابع set_index. الذي تتجلّى مهمّتهفي ضبط أيّ عمود موجود ضمن إطار البيانات كدليل لها. أو لدينا خيار ثانٍ وهو ضبط قيم دليل إطار البيانات بواسطة مصفوفة مكتبة بايثون العدديَّة (نَمْباي) narray نمرّرها إلى التّابع set_index، لكن بشرط أن يكون عدد عناصر المصفوفة مساويًا لعدد الأسطر.
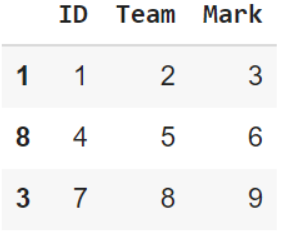
توضّح الشّيفرة البرمجيّة التّالية كيفيّة ضبط دليل إطار البيانات باستخدام تابع set_index أوّلًا باستخدام العمود ID الموجود ضمن إطار البيانات ثمّ باستخدام مصفوفة بايثون العدديّة نمباي.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["ID", "Team", "Mark"])
# ضبط دليل إطار البيانات باستخدام العمود ID
df.set_index("ID")
# ضبط دليل إطار البيانات باستخدام مصفوفة بايثون العدديّة نمباي
array = np.array([1,8,3])
df.set_index(array)
يوضّح الشّكل 5 خرج عمليّة ضبط دليل إطار البيانات باستخدام قيم العمود ID.

بينما يوضّح الشّكل 6 خرج عمليّة ضبط دليل إطار البيانات باستخدام مصفوفة مكتبة بايثون العدديَّة (نَمْباي) التي تمّ تعريفها في الشّيفرة البرمجيّة السّابقة.
بإمكاننا إعادة ضبط دليل إطار البيانات، واستخدام دليل يأخذ قيمه بشكل تلقائيّ ابتداءً من القيمة 0 وذلك باستخدام التّابع reset_index كما توضّح الشّيفرة البرمجيّة التّالية:
df.reset_index()
- إضافة سطر إلى إطار البيانات:
يتمّ إضافة سطر إلى إطار البيانات بالطّريقة المغايرة للشّيفرة البرمجيّة التّالية:
# الشيفرة البرمجية هنا سوف تنشأ سطر جديد بعنوان 10 وإضافة القيم الجديد
df.loc[10] = [14, 15, 16]
الشّيفرة البرمجيّة السّابقة سوف تقوم بعنونة السّطر الجديد بالرّقم 10 وإضافة القيم الجديدة كما يوضّح الشّكل 7.
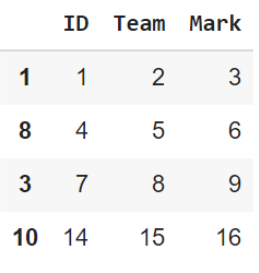
- إضافة عمود جديد إلى إطار البيانات:
يتمّ إضافة عمود جديد إلى إطار البيانات بطريقة مغايرة للشّيفرة البرمجيّة التّالية:
df.loc[:, "Perfor"] = [1,2,3,4]
الشّيفرة البرمجيّة السّابقة سوف تقوم بعنونة العمود الجديد بالكلمة النّصيّة “Perfor”، وإضافة القيم الجديدة كما يوضّح الشّكل 8.
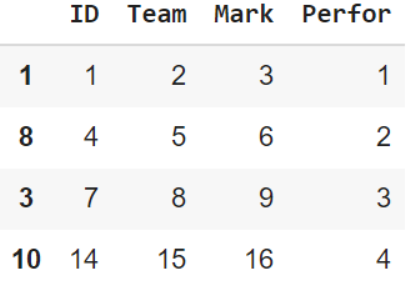
رابعًا: حذف أسطر أو أعمدة من إطار البيانات
يتمّ حذف سطر أو عمود من إطار البيانات باستخدام التّابع drop. في البداية سوف نقوم بإلقاء نظرة على كيفيّة حذف عمود من إطار البيانات، لدينا أسلوبان مختلفان نستطيع من خلالهما حذف عمود من إطار البيانات، أوّلًا بواسطة اسم العمود (أي عنوان العمود) كما توضّح الشّيفرة البرمجيّة التالية، حيث نقوم بحذف العمود “A” من إطار البيانات.
# حذف العمود ذو الدليل "A" من إطار البيانات
df.drop('A', axis=1, inplace=True)
بالنّسبة للأسلوب الثّاني نستطيع حذف عمود من إطار البيانات بواسطة موقعه، حيث نقوم بتمرير موقع العمود إلى التّابع df.columns، كما توضّح الشّيفرة البرمجيّة التّالية حيث نقوم بحذف العمود بالموقع 1 من إطار البيانات.
# حذف العمود بالموقع 1
df.drop(df.columns[[1]], axis=1)
نلاحظ مما سبق (الشّيفرتان البرمجيّتان السّابقتان) وجود بعض البارامترات الإضافيّة التي تمّ تمريرها إلى التّابع drop وهي على التّرتيب:
- بارامتر المحور axis: تكون قيمة هذا البارامتر 0 أو 1 (القيمة الافتراضيّة هي 0)، حيث تشير القيمة 0 إلى الأسطر أمّا القيمة 1 تشير إلى الأعمدة. أي في حال أردنا حذف سطر نقوم بضبط بارامتر المحور بالقيمة 0، أمّا في حال أردنا حذف عمود نقوم بضبطه بالقيمة 1.
- بارامتر “التغيير في المكان” inplace: يتمّ تعيين قيمة هذا البارامتر باستخدام قيمة بوليانيّة False أو True (القيمة الافتراضيّة هي False). في حال كانت قيمة البارامتر تساوي False، بالتّالي لن يتمّ تعديل البيانات في نفس إطار البيانات، وإنّما يتمّ إنشاء نسخة عن إطار البيانات يتمّ إجراء التّعديلات عليها مع الاحتفاظ بالنّسخة الأصليّة لإطار البيانات. في هذه الحالة سوف يُرجع التّابع نسخة عن إطار البيانات التي تتضمّن التّعديلات، لذلك نحتاج إلى الاحتفاظ بهذه النسخة في متحوّل جديد، أمّا عندما تكون قيمة البارامتر تساوي True، فسيتمّ تعديل البيانات في نفس إطار البيانات دون إنشاء نسخة أخرى، وفي هذه الحالة لا يُرجع التّابع أيّ شيء.
الآن سوف نلقي نظرة على كيفيّة حذف سطر من إطار البيانات، بإمكاننا أيضًا حذف سطر من إطار البيانات باستخدام التّابع drop، وذلك عن طريق تمرير موقع السّطر المراد حذفه إلى التّابع df.index وضبط بارامتر المحور بالقيمة 0. توضّح الشّيفرة البرمجيّة التّالية كيفيّة حذف سطر في إطار البيانات.
# حذف العمود بالموقع 1
df.drop(df.index[1], axis=0, inplace=True)
خامسًا: التعرّف على بيانات الزّمن ضمن مجموعة البيانات
يعتبر تحليل بيانات السّلاسل الزّمنيّة والتنبّؤ بها واحدة من أكثر تطبيقات تعلّم الآلة انتشارًا، ومن المؤكّد عند التّعامل مع مثل هذا النّوع من التّطبيقات أن تحوي مجموعة البيانات على عمود أو أكثر خاصّ بالزّمن. تكون بيانات الزّمن في ملفّ مجموعة البيانات بصيغة سلسلة نصّيّة String، وهذا ما يتطلّب منّا -عند قراءة ملفّ مجموعة البيانات- إجراء تحويل لصيغة الزّمن من صيغة السّلسلة الزّمنيّة إلى الصّيغة datetime، حتى نتمكّن من القيام بعمليّات تحليل ومعالجة لبيانات السّلاسل الزّمنيّة.
لدى مكتبة بانداس القدرة على التعرّف على بيانات الزّمن الموجودة ضمن مجموعة البيانات، حيث توفّر مكتبة بانداس البارامتر prase_date ضمن التّابع pd.DataFrame؛ الذي يتيح إمكانيّة تحويل بيانات الزّمن من أيّ صيغة كانت إلى صيغة datetime.
يتمّ ضبط البارامتر parse_date بقيمة بوليانيّة أو قائمة من الأرقام والأسماء، حيث القيمة الافتراضيّة لهذا البارامتر هي False، في حال تمّ ضبط قيمة البارامتر على القيمة True سوف يتمّ تحويل دليل إطار البيانات إلى صيغة الزّمن datetime، كما توضّح الشّيفرة البرمجيّة التّالية:
# قراءة ملف البيانات وتحويل الدليل لصيغة الزّمن
pd.read_csv('YourDataset', parse_dates=True)
في حال تمّ تمرير قائمة من الأرقام أو الأسماء إلى البارامتر parse_date، فستشير الأرقام أو الأسماء إلى أرقام أو أسماء الأعمدة المراد تحويل بياناتها إلى صيغة datetime. توضّح الشّيفرة البرمجيّة التّالية كيفيّة تحويل بيانات العمود “TheDate” إلى صيغة datetime.
# قراءة ملف البيانات واختيار اي عمود لتحويله الى صيغة الزّمن
pd.read_csv('YourDataset', parse_dates=['TheDate'])
تقنيّات هندسة المزايا
في هذا المقال سوف نوضّح أهمّ ست تقنيّات في هندسة المزايا تُستخدم مع بيانات السّلاسل الزّمنيّة. من أجل تبسيط الشّرح وإيصال الأفكار بشكل جيّد، أثناء توضيح تقنيّات هندسة المزايا في بيانات السّلاسل الزّمنيّة سوف نقوم بالاعتماد على بيانات الاستهلاك الكهربائيّ.
ما هي السّلاسل الزّمنيّة؟ وفقًا لويكيبيديا، يتمّ تعريف السّلاسل الزّمنيّة على أنّها مجموعة من القياسات المُسجّلة لمتغيّر واحد أو أكثر مرتّبةً حسب زمن وقوعها.
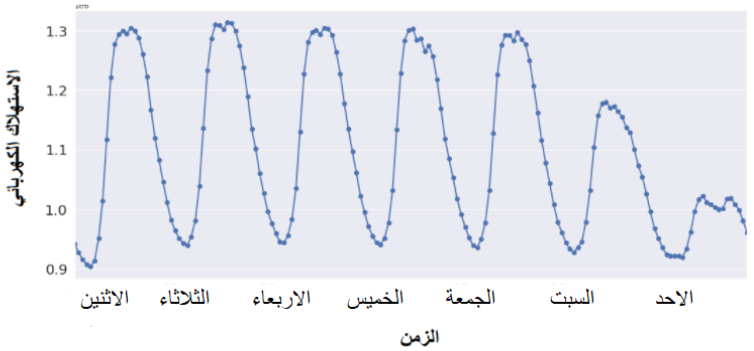
بالنّظر إلى الشّكل 9 فإنّه يوضّح كميّة الاستهلاك الكهربائيّ خلال شهرٍ واحد. هذه البيانات مسجّلة وفق فاصلٍ زمنيّ ساعيّ، حيث تمثّل كلّ نقطة كميّة الاستهلاك الكهربائيّ عند السّاعة المقابلة، بالتّدقيق أكثر في هذا الشّكل نلاحظ وجود فترات يتفاوت فيها الاستهلاك الكهربائيّ، حيث تارةً يكون منخفضًا وتارةً يكون مرتفعًا. نهاية السّلسلة الزّمنيّة على اليمين (يوما السّبت والأحد) يكون الاستهلاك الكهربائيّ منخفضًا مقارنةً بباقي الأيّام، فهي تمثّل أيّام عطل نهاية الأسبوع وكما هو معروف يقلّ الطّلب على الكهرباء في أيّام العطل؛ نظرًا لكون المصانع والجامعات والمؤسّسات .. الخ في هذه الأيّام متوقّفة، بالمقابل في أيّام الأسبوع الأخرى يكون الاستهلاك الكهربائيّ مرتفعًا، وهي تمثّل أيّامَ دوام أيّ أيّامًا مشغولة تعمل فيها المصانع والجامعات .. الخ. بالتّدقيق أيضًا في الشّكل 9 نلاحظ أيضًا تفاوت قيمة الاستهلاك الكهربائيّ خلال نفس اليوم، وهذا يعود إلى اختلاف ساعات اليوم فأوقات النّهار تمثّل أوقاتًا مشغولة والطّلب على الكهرباء فيها عالٍ، بينما في أوقات اللّيل تكون أوقات الرّاحة لذا يكون الطّلب على الكهرباء منخفضًا. مما سبق نلاحظ وجود تأثير كبير للزّمن على الطّلب على الكهربائيّ، عامل الزّمن في مثل هذه التطبيقات هو عامل مهمّ خاصّة عند تطبيق خوارزميّات تعلّم الآلة.
هذه بعض التّوضيحات عن البيانات المستخدمة في هذا المقال، كان لابدّ من إيضاحها قبل الحديث عن تقنيّات هندسة المزايا في بيانات السّلاسل الزّمنيّة.
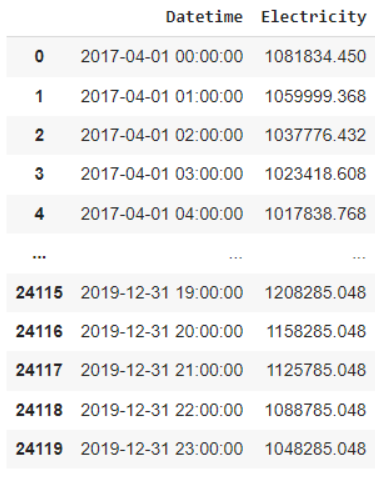
لنلقِ الآن نظرةً سريعة على إطار بيانات الاستهلاك الكهربائيّ (الشّكل 10)، وفقًا للشّكل 10 نلاحظ وجود عمودَين في إطار البيانات؛ العمود الأوّل هو باسم “Datetime” وهو يمثّل عمود الزّمن، العمود الثّاني باسم “Electricity” وهو يمثّل كميّة الاستهلاك الكهربائيّ.
الآن عزيزي القارئ دعنا نبدأ بتوضيح تقنيّات هند سة المزايا.
1- المزايا المُتعلّقة بالتّاريخ Date-Related Features
بالعودة إلى الشّكل 10 وبالنّظر إلى عمود الزّمن، نلاحظ أنّه بإمكاننا استخراج ثلاث مزايا مرتبطة بالتّاريخ وهي:
- دليل السّنة.
- دليل الشّهر.
- دليل اليوم.
الدّليل هنا مطابق لرقم السّنة أو الشّهر، على سبيل المثال في حال كان لدينا التّاريخ “02-04-2017” بالتّالي يكون دليل السّنة هو 2017 ودليل الشّهر هو 4 وهكذا. بإمكاننا إضافة هذه المزايا إلى مجموعة البيانات لدينا، ومن شأنها أن تحسّن تنبّؤات خوارزميّات تعلّم الآلة.
المزايا المُتعلّقة بالتّاريخ تعتمد إضافتها إلى مجموعة البيانات على موسميّة البيانات Seasonality، أي في حال كانت البيانات تحتوي على موسميّة أسبوعيّة، فإنّ إضافة دليل اليوم يحسّن من أداء الخوارزميّة، وفي حال كانت البيانات تحتوي على موسميّة سنويّة فإنّ إضافة دليل الشّهر هو أمر مهمّ أيضًا.
توضيح: الموسميّة تعني تكرار نمط معيّن خلال فترة زمنيّة محدّدة.
دعنا الآن نوضّح التّفسير وراء تحسين المزايا المُتعلّقة بالتّاريخ لأداء خوارزميّات تعلّم الآلة، بالنّسبة لدليل اليوم فكما تحدّثنا سابقًا أنّ كميّة الاستهلاك الكهربائيّ تتأثّر باليوم، في حال كان اليوم هو عطلة نهاية الأسبوع أو يوم دوام، وهذا النّمط من الاستهلاك الكهربائيّ يتكرّر كلّ أسبوع، بالتّالي هنا البيانات تحتوي على موسميّة أسبوعيّة وهذا الدّليل لخوارزميّة تعلّم الآلة من شأنه أن يحسّن من أدائها في التنبّؤات، كذلك الأمر بالنّسبة لدليل الشّهر حيث يختلف الاستهلاك الكهربائيّ أيضًا حسب تفاوت الشّهور، ففي فصول الصّيف والشّتاء يكون الطّلب على الكهرباء عالٍ نظرًا لاستخدام وسائل تدفئة وتبريد، بينما يكون الطّلب على الكهرباء أقلّ في فصول الرّبيع والخريف، فهذه فصول يكون فيها الطقس دافئًا وأيضًا هذا النّمط يتكرّر كلّ سنة، بالتّالي بيانات الاستهلاك الكهربائيّ تحتوي على موسميّة سنويّة.
بإمكاننا إضافة دليل السّنة، الشّهر، اليوم إلى مجموعة البيانات كما توضّح الشّيفرة البرمجيّة التّالية:
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
df['Year']=df['Datetime'].dt.year
df['Month']=df['Datetime'].dt.month
df['DayOfWeek']=df['Datetime'].dt.dayofweek
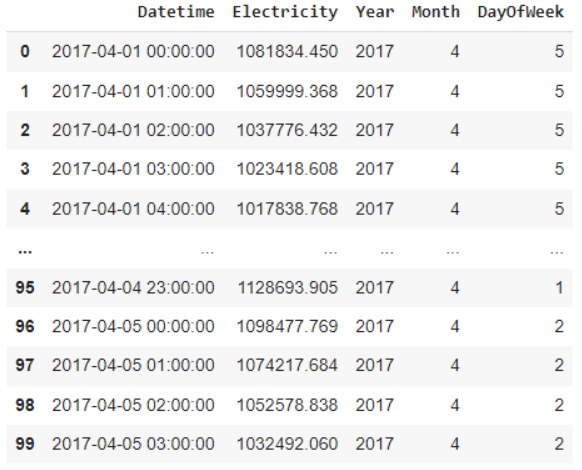
يوضّح الشّكل 11 المزايا المُتعلّقة بالتّاريخ التي تمّت إضافتها إلى مجموعة البيانات، وفقًا للشّكل 11 يمثّل العمود “Year” دليل السّنة، والعمود “Month” دليل الشّهر بينما العمود “DayOfWeek” يمثل دليل اليوم. أمر بسيط يجب توضيحه في الشّكل 11 بالنّسبة إلى عمود دليل اليوم نلاحظ أنّ قيم العمود ضمن المجال من القيمة 0 إلى 6، بخلاف دليل السّنة والشّهر الذي يكون فيها الدّليل مطابقًا لرقم السّنة والشّهر، حيث تمثّل القيمة 0 في عمود دليل اليوم يوم الاثنين، والقيمة 1 تمثّل يوم الثّلاثاء، وهكذا حتّى القيمة 6 التي تمثّل يوم الأحد.
2– المزايا المُتعلّقة بالوقت Time-Related Features
بالعودة مرةً أخرى إلى الشّكل 10 بإمكاننا أيضًا استخراج مزايا مرتبطة بالوقت من عمود الزّمن وهي:
- دليل السّاعة.
- دليل الدّقيقة.
- دليل الثّانية.
بالنّسبة لبيانات الاستهلاك الكهربائيّ التي نعمل عليها في هذا المقال، فإنّ دليل السّاعة هو أمر مهمّ ويتوجّب إضافته إلى مجموعة البيانات، ويعود ذلك كما وضّحنا سابقًا أنّ الاستهلاك الكهربائيّ يتأثّر بساعات اليوم (أوقات النّهار والليل)، وهو أيضًا نمط متكرّر أي مجموعة البيانات تحتوي على موسميّة يوميّة، الشّيفرة البرمجيّة التّالية توضّح آليّة إضافة دليل السّاعة، الدّقيقة، الثّانية إلى مجموعة البيانات.
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
df['Hour'] = df['Datetime'].dt.hour
df['Minute'] = df['Datetime'].dt.minute
df['Second'] = df['Datetime'].dt.second
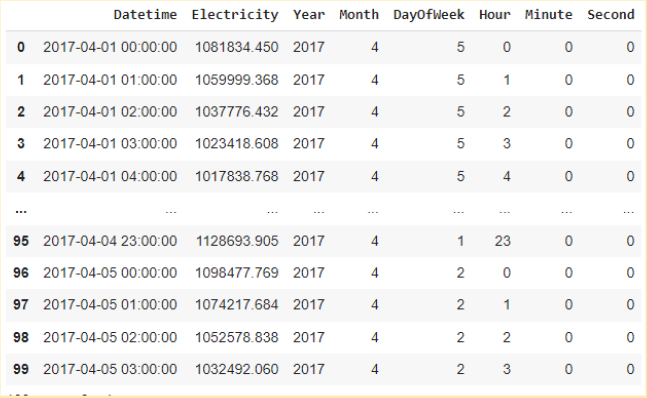
يوضّح الشّكل 12 المزايا المتعلّقة بالوقت المضافة إلى مجموعة البيانات، هنا في مجموعة البيانات هذه دليل الدّقيقة والثّانية غير مفيد نظرًا لأنّ هذه البيانات مسجّلة وفق فاصل زمنيّ ساعيّ، قمنا فقط بإضافة دليل الدّقيقة والثّانية من أجل توضيح الطّريقة فقط لاغير.
الذي نرغب بقوله عزيزي القارئ هو أنّه يتوجّب عليك انتقاء المزايا التي ترغب بإضافتها إلى مجموعة البيانات بحذر، وأن تكون هذه المزايا شديدة الارتباط بمتغيّر الهدف Target variables.
3- المزايا المتأخّرة Lag Features
بفرض أردنا التنبّؤ بالقيم المستقبليّة للاستهلاك الكهربائيّ، فإنّ قيم الاستهلاك الكهربائيّ في السّاعات السّابقة مهمّة جدًّا في تحسين التنبّؤات، بمعنى آخر تتأثّر قيمة الاستهلاك الكهربائيّ في الوقت الحالي t بشكل كبير بالاستهلاك الكهربائيّ في الوقت السابق t-1، هذه القيم السّابقة تدعى المزايا المتأخّرة Lag Features أيضًا ممكن أن تكون المزايا المتأخّرة t-4 ، t-3 ، t-2 … الخ. يعتمد إضافة المزايا المتأخّرة إلى مجموعة البيانات على اتجاه السّلسلة الزّمنيّة Trend، أي في حال كانت البيانات تحتوي على اتّجاه أسبوعي فإنّ إضافة المزايا المتأخّرة قبل أسبوع يحسّن من أداء خوارزميّات تعلّم الآلة في التنبّؤات، على سبيل المثال من أجل التنبّؤ بقيم الاستهلاك الكهربائيّ في يوم الإثنين، فإنّ استخدام قيم الاستهلاك الكهربائيّ في يوم الاثنين السّابق هو أمر مهم.
توضيح: الاتّجاه يمثّل الاتّجاه العام للسّلسلة الزّمنيّة خلال فترة معيّنة هل هو يزداد أم ينقص أم كان مستقرًّا.
لنتعرّف الآن على كيفيّة إنشاء المزايا المتأخّرة باستخدام لغة البرمجة بايثون، حيث توضّح الشّيفرة البرمجيّة التّالية آليّة إنشاء المزايا المتأخّرة.
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
df['lag_1'] = df['Electricity'].shift(1)
df = df[['Datetime', 'lag_1', 'Electricity']]
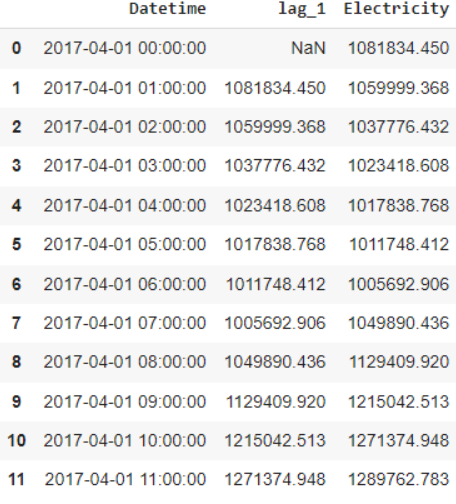
في السّطر 10 من الشّيفرة البرمجيّة السّابقة، قمنا بإزاحة قيم الاستهلاك الكهربائيّ بمقدار سطر واحد (أي ساعة واحدة)، وإضافتها إلى عمود جديد سمّيناه “Lag_1”. بالطّبع بإمكاننا إزاحة القيم حسب ما نرغب، ففي حال أردنا الاعتماد على قيم الاستهلاك الكهربائيّ بيوم سابق علينا أن نقوم بالإزاحة بمقدار 24. الشّكل 13 يوضّح مزايا التّأخير المضافة إلى مجموعة البيانات.
بإمكاننا إنشاء العديد من مزايا التّأخر وإضافتها إلى مجموعة البيانات، بفرض نريد إنشاء مزايا متأخّرة من ساعة إلى سبع ساعات أي من t-1 إلى t-7، الشّيفرة البرمجيّة المقابلة تكون بالشّكل التّالي:
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
df['lag_1'] = df['Electricity'].shift(1)
df['lag_2'] = df['Electricity'].shift(2)
df['lag_3'] = df['Electricity'].shift(3)
df['lag_4'] = df['Electricity'].shift(4)
df['lag_5'] = df['Electricity'].shift(5)
df['lag_6'] = df['Electricity'].shift(6)
df['lag_7'] = df['Electricity'].shift(7)
df = df[['Datetime', 'lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6', 'lag_7', 'Electricity']]
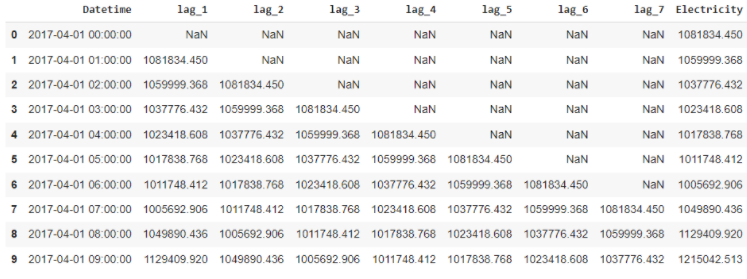
الشّكل 14 يوضّح مزايا التّأخير العديدة المضافة إلى مجموعة البيانات.
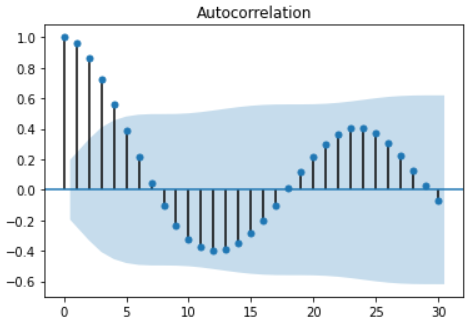
هنالك العديد من الطرق لاختبار مدى ارتباط المزايا المتأخّرة بمتغيّر الهدف، على سبيل المثال بإمكاننا استخدام تابع الارتباط التّلقائيّ Autocorrelation Function يُرمز له اختصارًا بـ ACF لقياس مدى الارتباط مع متغيّر الهدف، الشّيفرة البرمجيّة التّالية توضّح آليّة تنفيذ التّابع ACF.
from statsmodels.graphics.tsaplots import plot_acf
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
plot_acf(df['Electricity'], lags=30)
يوضّح الشّكل 15 خرج تابع الارتباط التّلقائيّ، كما نلاحظ من هذا الشّكل ابتداءً من القيمة المتأخّرة t-5 وحتى النّهاية أنّ الارتباط يكون ضعيفًا، بالتّالي نستنتج أنّ القيم ابتداءً من القيمة t-5 وحتّى النّهاية غير مرتبطة ولا تؤثّر على متغيّر الهدف، في المقابل القيم t-4 ، t-3 ، t-2 ، t-1 مرتبطة بمتغيّر الهدف، و تعتبر مزايا مفيدة لتحسين التنبّؤات بالقيم المستقبليّة للاستهلاك الكهربائيّ.
4- مزايا النّافذة المنزلقة Rolling Window Feature
تعلمنا في القسم السّابق كيفيّة إنشاء مزايا القيم المتأخّرة وإضافتها إلى مجموعة البيانات، الآن سوف نقوم بالاطّلاع على كيفيّة إنشاء قيم إحصائيّة وإضافتها إلى مجموعة البيانات، هذه القيم الإحصائيّة تعتمد على القيم المتأخّرة (السّابقة)، كما يوضّح الشّكل 16 فمن أجل كلّ نافذة منزلقة نطبّق تابعًا إحصائيًّا على القيم السّابقة الموجودة داخل النّافذة، ونضيف خرج التّابع إلى مجموعة البيانات في عمود جديد، وهذه الطّريقة تدعى النّافذة المنزلقة لأنّ النّافذة تنزلق عند كلّ نقطة بيانات تالية كما يوضّح الشّكل 16.
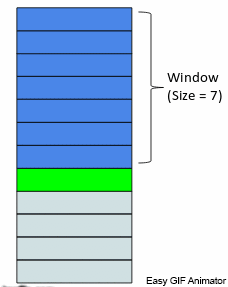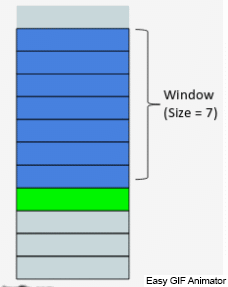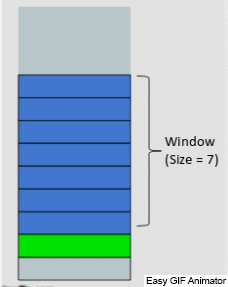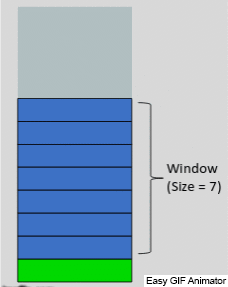
توضّح الشّيفرة البرمجيّة التّالية آليّة إنشاء مزايا النّافذة المنزلقة، حيث نقوم في البداية بتحديد حجم النّافذة، ولنقم مثلًا باختيار القيمة 3 وأيضًا نختار نوع العمليّة الإحصائيّة المراد تطبيقها على القيم داخل النّافذة، دعنا نختار المتوسّط الحسابيّ بالتّالي ابتداءً من نقطة البيانات الثّالثة سوف يتمّ حساب قيمة المتوسّط.
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
df['rolling_mean']=df['Electricity'].rolling(window=3).mean()
df=df[['Datetime', 'rolling_mean', 'Electricity']]
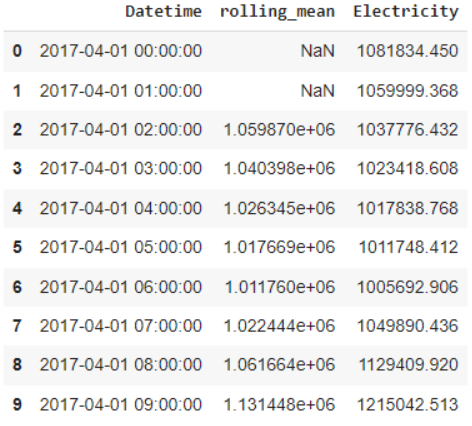
df.head(10)
يوضّح الشّكل 17 مزايا النّافذة المتحرّكة المضافة إلى مجموعة البيانات، بشكل مشابه أيضًا بإمكاننا استخدام تابع إحصائيّ آخر، مثلًا حساب مجموع القيم داخل النّافذة أو حساب أكبر قيم في النّافذة أو أصغر قيمة … الخ.
بالنّسبة لمجموعة بيانات الاستهلاك الكهربائيّ المستخدمة في هذا المقال، يكون متوسّط حجم الاستهلاك الكهربائيّ في اليوم السّابق مفيدًا للتنبّؤ بالقيم المستقبليّة للاستهلاك الكهربائيّ، بالتّالي في هذه الحالة نحدّد حجم النّافذة المنزلقة بالقيمة 24.
ملاحظة مهمّة: الحداثة Recency هي عامل مهمّ في السّلاسل الزّمنيّة، أي بمعنى آخر تتضمّن القيم الأقرب لنقطة البيانات معلومات أكثر مقارنة بالقيم الأبعد منها، من أجل ذلك بإمكاننا استخدام المتوسّط الموزون Weighted Average، في هذه الحالة سوف يتمّ إسناد أوزان أكبر من أجل البيانات القريبة، وأقلّ من أجل البيانات البعيدة، بفرض أنّ حجم النّافذة هو 7 يتمّ التّعبير عن المتوسّط الموزون عند نقطة البيانات t بالصّيغة الرّياضيّة التّالية:
w_avg = w1*(t-1) + w2*(t-2) + . . . . + w7*(t-7)
حيث w1>w2>w3> . . . . >w7
5- مزايا النّافذة الموسّعة Expanding Window Feature
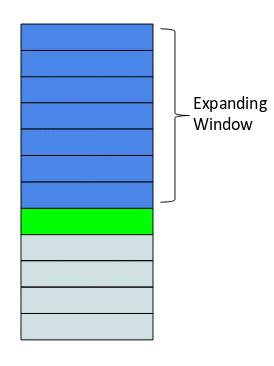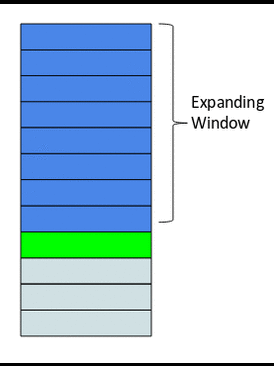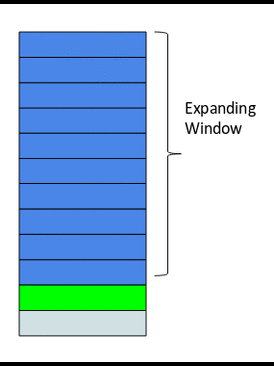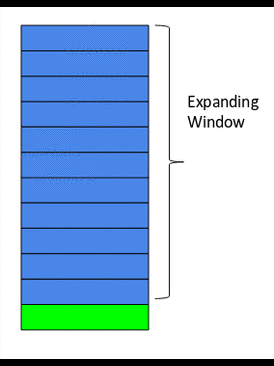
هي ببساطة مجرّد إصدار متقدّم عن مزايا النّافذة المنزلقة، ففي حال النّافذة المنزلقة كان حجم النّافذة ثابتًا ويتمّ تطبيق التّابع الإحصائيّ على القيم داخل النّافذة فقط وتجاهل القيم الأخرى، أمّا هنا في حالة النّافذة الموسّعة فإنّه يتمّ تطبيق التّابع الإحصائيّ على جميع القيم السّابقة لنقطة البيانات، أي هنا حجم النافذة متغيّر وليس ثابتًا ويتزايد عند كلّ نقطة بيانات جديدة كما يوضّح الشّكل 18.
الشّيفرة البرمجيّة التّالية توضّح آليّة إيجاد مزايا النّافذة الموسّعة.
df=pd.read_csv('/content/drive/MyDrive/Dataset.csv',parse_dates=['Datetime'])
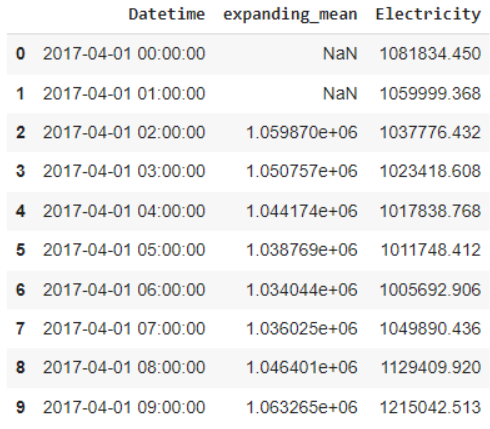
df['expanding_mean']=df['Electricity'].expanding(3).mean()
df=df[['Datetime','expanding_mean' ,'Electricity']]
يوضّح الشّكل 19 مزايا النّافذة الموسّعة المضافة إلى مجموعة البيانات.
6- المزايا الخاصّة بمجال التطبيق Domain-Specific Features
تعتبر المزايا الخاصّة بمجال التطبيق جوهر هندسة المزايا، فوجودها فهم جيّد للمشكلة التي يتمّ معالجتها، و وضوح الهدف النهائيّ ومعرفة البيانات المتاحة تعتبر أمور ضروريّة للمزايا الخاصّة بالمجال، في حال كان العمل مع بيانات الاستهلاك الكهربائيّ. الذي نريد قوله هو أنّ الاستهلاك الكهربائيّ يتأثّر بعوامل كثيرة، على سبيل المثال يتأثّر بالطّقس سواء كان درجة الحرارة أو الرّطوبة أو الضّغط الجويّ .. الخ. علاوة على ذلك يتأثّر الاستهلاك الكهربائيّ بالتّعداد السّكانيّ وعدد الأجهزة الكهربائيّة الموجودة في كلّ المنزل وعدد أفراد الأسرة .. الخ، جميعها مزايا خاصّة بالمجال يمكن إضافتها إلى مجموعة البيانات، ومن شأنها أن تحسّن من تنبّؤات خوارزميّات تعلّم الآلة بشكل كبير جدًّا.
عزيزي القارئ لمشاهدة الشفرة البرمجية كاملة يمكنك الرجوع إلى مستوع الجت_هب الخاص بالمدونة.
الخاتمة
تعرّفنا في هذا المقال على تقنيّات هندسة المزايا المستخدمة في بيانات السّلاسل الزّمنيّة، ورأينا كيف يتمّ التّعامل مع أحد أهمّ هياكل البيانات المستخدمة في عالم البيانات الذي هو إطار البيانات في بانداس، شرحنا بعض العمليّات الأساسيّة على إطار البيانات في بانداس، استخدمنا بيانات الاستهلاك الكهربائيّ من أجل توضيح تقنيّات هندسة المزايا في بيانات السّلاسل الزّمنيّة، وأخيرًا قمنا باستعراض أهمّ 6 تقنيّات لهندسة المزايا في بيانات السّلاسل الزّمنيّة.
المراجــــع
- .Six Powerful Feature Engineering Techniques For Time Series Data (using Python)
- Basic Feature Engineering With Time Series Data in Python
- What is Feature Engineering — Importance, Tools and Techniques for Machine Learning
- Python | Pandas DataFrame
- DataFrames in Python